5.6 KiB
TrustGraph
Tip
Full
TrustGraphdocumentation can be found at trustgraph.ai.
🚀 Get Started 💬 Join the Discord 📖 Read the Blog
Introduction
TrustGraph is a true end-to-end (e2e) knowledge pipeline that performs a Naive Extraction on a text corpus
to build a RDF style knowledge graph coupled with a RAG service compatible with cloud LLMs and open-source
SLMs (Small Language Models).
The pipeline processing components are interconnected with a pub/sub engine to maximize modularity and enable new knowledge processing functions. The core processing components decode documents, chunk text, perform embeddings, apply a local SLM/LLM, call a LLM API, and generate LM predictions.
The processing showcases the reliability and efficiences of Graph RAG algorithms which can capture contextual language flags that are missed in conventional RAG approaches. Graph querying algorithms enable retrieving not just relevant knowledge but language cues essential to understanding semantic uses unique to a text corpus.
Processing modules are executed in containers. Processing can be scaled-up by deploying multiple containers.
Features
- PDF decoding
- Text chunking
- Inference of LMs deployed with Ollama
- Inference of Cloud LLMs:
AWS Bedrock,AzureAI,Anthropic,Cohere,OpenAI, andVertexAI - Mixed model deployments
- Application of a HuggingFace embeddings models
- RDF-aligned Knowledge Graph extraction
- Graph edge loading into Apache Cassandra or Neo4j
- Storing embeddings in Milvus
- Build and load Knowledge Cores
- Embedding query service
- Graph RAG query service
- All procesing integrates with Apache Pulsar
- Containers, so can be deployed using Docker Compose or Kubernetes
- Plug'n'play architecture: switch different LLM modules to suit your needs
Architecture
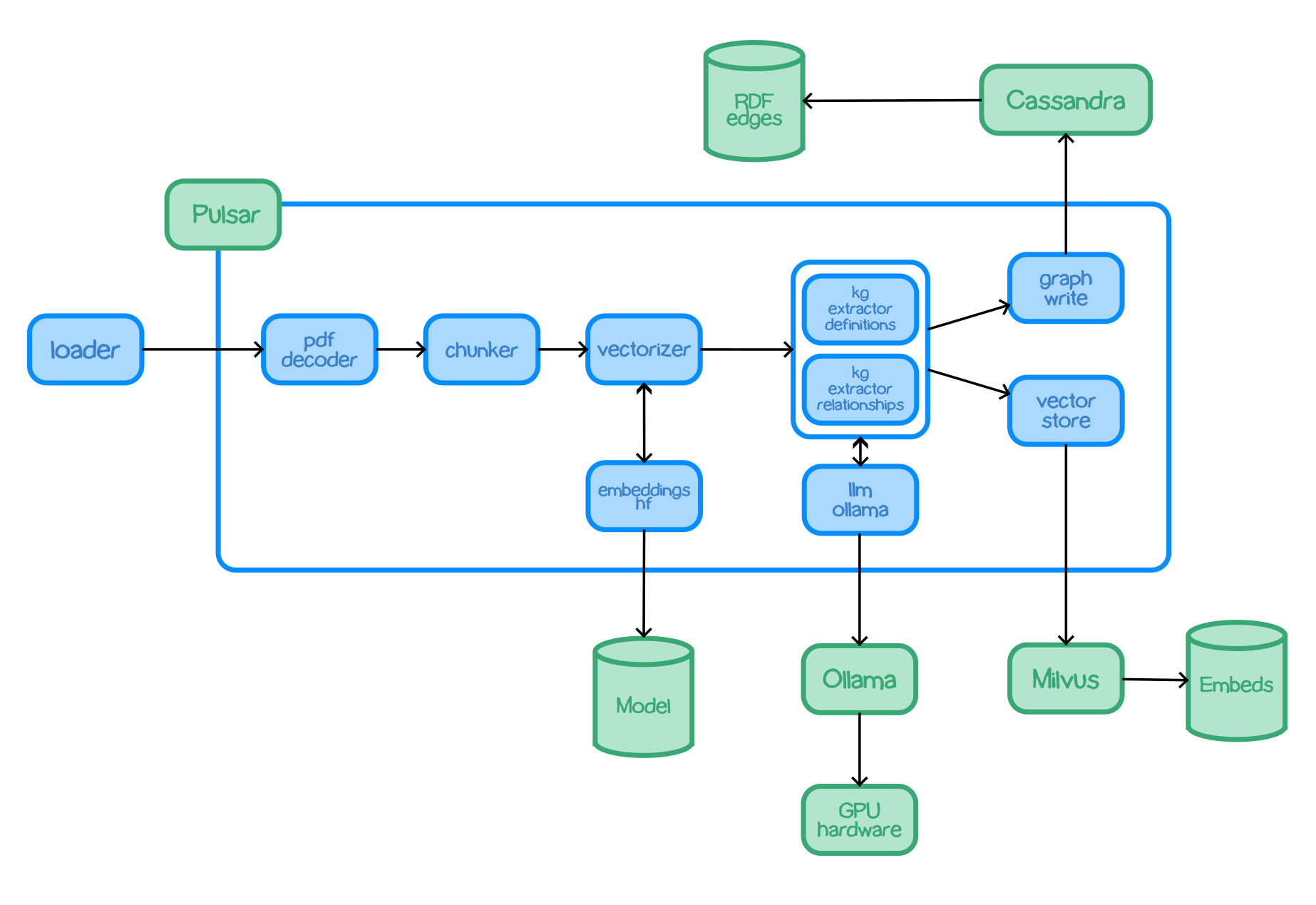
TrustGraph is designed to be modular to support as many Language Models and environments as possible. A natural fit for a modular architecture is to decompose functions into a set modules connected through a pub/sub backbone. Apache Pulsar serves as this pub/sub backbone. Pulsar acts as the data broker managing inputs and outputs between modules.
Pulsar Workflows:
- For processing flows, Pulsar accepts the output of a processing module and queues it for input to the next subscribed module.
- For services such as LLMs and embeddings, Pulsar provides a client/server model. A Pulsar queue is used as the input to the service. When processed, the output is then delivered to a separate queue where a client subscriber can request that output.
The entire architecture, the pub/sub backbone and set of modules, is bundled into a single Python package. A container image with the package installed can also run the entire architecture.
Core Modules
chunker-recursive- Accepts text documents and uses LangChain recursive chunking algorithm to produce smaller text chunks.chunker-token- Chunks texts documents by a chosen amount of tokens.embeddings-hf- A service which analyses text and returns a vector embedding using one of the HuggingFace embeddings models.embeddings-ollama- A service which analyses text and returns a vector embedding using an Ollama embeddings model.embeddings-vectorize- Uses an embeddings service to get a vector embedding which is added to the processor payload.graph-rag- A query service which applies a Graph RAG algorithm to provide a response to a text prompt.triples-write-cassandra- Takes knowledge graph edges and writes them to a Cassandra store.triples-write-neo4j- Takes knowledge graph edges and writes them to a Neo4j store.kg-extract-definitions- knowledge extractor - examines text and produces graph edges. describing discovered terms and also their defintions. Definitions are derived using the input documents.kg-extract-relationships- knowledge extractor - examines text and produces graph edges describing the relationships between discovered terms.loader- Takes a document and loads into the processing pipeline. Used e.g. to add PDF documents.pdf-decoder- Takes a PDF doc and emits text extracted from the document. Text extraction from PDF is not a perfect science as PDF is a printable format. For instance, the wrapping of text between lines in a PDF document is not semantically encoded, so the decoder will see wrapped lines as space-separated.ge-write-milvus- Takes graph embeddings mappings and records them in the vector embeddings store.
LM Specific Modules
text-completion-azure- Sends request to AzureAI serverless endpointtext-completion-bedrock- Send request to AWS Bedrock APItext-completion-claude- Sends request to Anthropic's APItext-completion-cohere- Send request to Cohere's APItext-completion-ollama- Sends request to LM running using Ollamatext-completion-openai- Sends request to OpenAI's APItext-completion-vertexai- Sends request to model available through VertexAI API
Quickstart Guide
See Quickstart on Docker Compose