mirror of
https://github.com/FoundationAgents/MetaGPT.git
synced 2026-07-23 17:01:08 +02:00
Merge branch 'main' into feature-openai-v1
This commit is contained in:
commit
9a4f0d555c
260 changed files with 10576 additions and 3191 deletions
|
|
@ -1,39 +1,34 @@
|
|||
# Dev container
|
||||
# Dev Container
|
||||
|
||||
This project includes a [dev container](https://containers.dev/), which lets you use a container as a full-featured dev environment.
|
||||
This project includes a [Dev Container](https://containers.dev/), offering you a comprehensive and fully-featured development environment within a container. By leveraging the Dev Container configuration in this folder, you can seamlessly build and initiate MetaGPT locally. For detailed information, please refer to the main README in the home directory.
|
||||
|
||||
You can use the dev container configuration in this folder to build and start running MetaGPT locally! For more, refer to the main README under the home directory.
|
||||
You can use it in [GitHub Codespaces](https://github.com/features/codespaces) or the [VS Code Dev Containers extension](https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.remote-containers).
|
||||
You can utilize this Dev Container in [GitHub Codespaces](https://github.com/features/codespaces) or with the [VS Code Dev Containers extension](https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.remote-containers).
|
||||
|
||||
## GitHub Codespaces
|
||||
<a href="https://codespaces.new/geekan/MetaGPT"><img src="https://github.com/codespaces/badge.svg" alt="Open in GitHub Codespaces"></a>
|
||||
[](https://codespaces.new/geekan/MetaGPT)
|
||||
|
||||
You may use the button above to open this repo in a Codespace
|
||||
Click the button above to open this repository in a Codespace. For additional information, refer to the [GitHub documentation on creating a Codespace](https://docs.github.com/en/free-pro-team@latest/github/developing-online-with-codespaces/creating-a-codespace#creating-a-codespace).
|
||||
|
||||
For more info, check out the [GitHub documentation](https://docs.github.com/en/free-pro-team@latest/github/developing-online-with-codespaces/creating-a-codespace#creating-a-codespace).
|
||||
|
||||
## VS Code Dev Containers
|
||||
<a href="https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/geekan/MetaGPT"><img src="https://img.shields.io/static/v1?label=Dev%20Containers&message=Open&color=blue&logo=visualstudiocode" alt="Open in Dev Containers"></a>
|
||||
[](https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/geekan/MetaGPT)
|
||||
|
||||
Note: If you click this link you will open the main repo and not your local cloned repo, you can use this link and replace with your username and cloned repo name:
|
||||
https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/geekan/MetaGPT
|
||||
Note: Clicking the link above opens the main repository. To open your local cloned repository, replace the URL with your username and cloned repository's name: `https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/<your-username>/<your-repo-name>`
|
||||
|
||||
If you have VS Code and Docker installed, use the button above to get started. This will prompt VS Code to install the Dev Containers extension if it's not already installed, clone the source code into a container volume, and set up a dev container for you.
|
||||
|
||||
If you already have VS Code and Docker installed, you can use the button above to get started. This will cause VS Code to automatically install the Dev Containers extension if needed, clone the source code into a container volume, and spin up a dev container for use.
|
||||
Alternatively, follow these steps to open this repository in a container using the VS Code Dev Containers extension:
|
||||
|
||||
You can also follow these steps to open this repo in a container using the VS Code Dev Containers extension:
|
||||
1. For first-time users of a development container, ensure your system meets the prerequisites (e.g., Docker installation) as outlined in the [getting started steps](https://aka.ms/vscode-remote/containers/getting-started).
|
||||
|
||||
1. If this is your first time using a development container, please ensure your system meets the pre-reqs (i.e. have Docker installed) in the [getting started steps](https://aka.ms/vscode-remote/containers/getting-started).
|
||||
|
||||
2. Open a locally cloned copy of the code:
|
||||
|
||||
- Fork and Clone this repository to your local filesystem.
|
||||
2. To open a locally cloned copy of the code:
|
||||
- Fork and clone this repository to your local file system.
|
||||
- Press <kbd>F1</kbd> and select the **Dev Containers: Open Folder in Container...** command.
|
||||
- Select the cloned copy of this folder, wait for the container to start, and try things out!
|
||||
- Choose the cloned folder, wait for the container to initialize, and start exploring!
|
||||
|
||||
You can learn more in the [Dev Containers documentation](https://code.visualstudio.com/docs/devcontainers/containers).
|
||||
Learn more in the [VS Code Dev Containers documentation](https://code.visualstudio.com/docs/devcontainers/containers).
|
||||
|
||||
## Tips and tricks
|
||||
## Tips and Tricks
|
||||
|
||||
* If you are working with the same repository folder in a container and Windows, you'll want consistent line endings (otherwise you may see hundreds of changes in the SCM view). The `.gitattributes` file in the root of this repo will disable line ending conversion and should prevent this. See [tips and tricks](https://code.visualstudio.com/docs/devcontainers/tips-and-tricks#_resolving-git-line-ending-issues-in-containers-resulting-in-many-modified-files) for more info.
|
||||
* If you'd like to review the contents of the image used in this dev container, you can check it out in the [devcontainers/images](https://github.com/devcontainers/images/tree/main/src/python) repo.
|
||||
* When working with the same repository folder in both a container and on Windows, it's crucial to have consistent line endings to avoid numerous changes in the SCM view. The `.gitattributes` file in the root of this repository disables line ending conversion, helping to prevent this issue. For more information, see [resolving git line ending issues in containers](https://code.visualstudio.com/docs/devcontainers/tips-and-tricks#_resolving-git-line-ending-issues-in-containers-resulting-in-many-modified-files).
|
||||
|
||||
* If you're curious about the contents of the image used in this Dev Container, you can review it in the [devcontainers/images](https://github.com/devcontainers/images/tree/main/src/python) repository.
|
||||
|
|
|
|||
|
|
@ -4,4 +4,4 @@ sudo npm install -g @mermaid-js/mermaid-cli
|
|||
|
||||
# Step 2: Ensure that Python 3.9+ is installed on your system. You can check this by using:
|
||||
python --version
|
||||
pip install -e.
|
||||
pip install -e .
|
||||
|
|
@ -1,7 +1,6 @@
|
|||
workspace
|
||||
tmp
|
||||
build
|
||||
workspace
|
||||
dist
|
||||
data
|
||||
geckodriver.log
|
||||
|
|
|
|||
27
.gitattributes
vendored
27
.gitattributes
vendored
|
|
@ -1,2 +1,29 @@
|
|||
# HTML code is incorrectly calculated into statistics, so ignore them
|
||||
*.html linguist-detectable=false
|
||||
|
||||
# Auto detect text files and perform LF normalization
|
||||
* text=auto eol=lf
|
||||
|
||||
# Ensure shell scripts use LF (Linux style) line endings on Windows
|
||||
*.sh text eol=lf
|
||||
|
||||
# Treat specific binary files as binary and prevent line ending conversion
|
||||
*.png binary
|
||||
*.jpg binary
|
||||
*.gif binary
|
||||
*.ico binary
|
||||
|
||||
# Preserve original line endings for specific document files
|
||||
*.doc text eol=crlf
|
||||
*.docx text eol=crlf
|
||||
*.pdf binary
|
||||
|
||||
# Ensure source code and script files use LF line endings
|
||||
*.py text eol=lf
|
||||
*.js text eol=lf
|
||||
*.html text eol=lf
|
||||
*.css text eol=lf
|
||||
|
||||
# Specify custom diff driver for specific file types
|
||||
*.md diff=markdown
|
||||
*.json diff=json
|
||||
|
|
|
|||
30
.github/workflows/pre-commit.yaml
vendored
Normal file
30
.github/workflows/pre-commit.yaml
vendored
Normal file
|
|
@ -0,0 +1,30 @@
|
|||
name: Pre-commit checks
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
branches:
|
||||
- '**'
|
||||
push:
|
||||
branches:
|
||||
- '**'
|
||||
|
||||
jobs:
|
||||
pre-commit-check:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout Source Code
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: '3.9.17'
|
||||
|
||||
- name: Install pre-commit
|
||||
run: pip install pre-commit
|
||||
|
||||
- name: Initialize pre-commit
|
||||
run: pre-commit install
|
||||
|
||||
- name: Run pre-commit hooks
|
||||
run: pre-commit run --all-files
|
||||
9
.gitignore
vendored
9
.gitignore
vendored
|
|
@ -59,6 +59,7 @@ cover/
|
|||
|
||||
# Django stuff:
|
||||
*.log
|
||||
logs
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
db.sqlite3-journal
|
||||
|
|
@ -143,24 +144,18 @@ cython_debug/
|
|||
allure-report
|
||||
allure-results
|
||||
|
||||
# idea
|
||||
# idea / vscode / macos
|
||||
.idea
|
||||
.DS_Store
|
||||
.vscode
|
||||
|
||||
log.txt
|
||||
docs/scripts/set_env.sh
|
||||
key.yaml
|
||||
output.json
|
||||
data
|
||||
data/output_add.json
|
||||
data.ms
|
||||
examples/nb/
|
||||
.chroma
|
||||
*~$*
|
||||
workspace/*
|
||||
*.mmd
|
||||
tmp
|
||||
output.wav
|
||||
metagpt/roles/idea_agent.py
|
||||
.aider*
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@ default_stages: [ commit ]
|
|||
|
||||
# Install
|
||||
# 1. pip install pre-commit
|
||||
# 2. pre-commit install(the first time you download the repo, it will be cached for future use)
|
||||
# 2. pre-commit install
|
||||
repos:
|
||||
- repo: https://github.com/pycqa/isort
|
||||
rev: 5.11.5
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@ COPY . /app/metagpt
|
|||
WORKDIR /app/metagpt
|
||||
RUN mkdir workspace &&\
|
||||
pip install --no-cache-dir -r requirements.txt &&\
|
||||
pip install -e.
|
||||
pip install -e .
|
||||
|
||||
# Running with an infinite loop using the tail command
|
||||
CMD ["sh", "-c", "tail -f /dev/null"]
|
||||
|
|
|
|||
2
LICENSE
2
LICENSE
|
|
@ -1,6 +1,6 @@
|
|||
The MIT License
|
||||
|
||||
Copyright (c) Chenglin Wu
|
||||
Copyright (c) 2023 Chenglin Wu
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
|
|
|
|||
34
README.md
34
README.md
|
|
@ -1,3 +1,4 @@
|
|||
|
||||
# MetaGPT: The Multi-Agent Framework
|
||||
|
||||
<p align="center">
|
||||
|
|
@ -32,7 +33,8 @@ # MetaGPT: The Multi-Agent Framework
|
|||
|
||||
<p align="center">Software Company Multi-Role Schematic (Gradually Implementing)</p>
|
||||
|
||||
|
||||
## News
|
||||
- Dec 15: v0.5.0 is released! We introduce **incremental development**, facilitating agents to build up larger projects on top of their previous efforts or exisiting human codebase. We also launch a whole collection of important features, including multilingual support (experimental), multiple programming languages support (experimental), incremental development (experimental), CLI support, pip support, enhanced code review, documentation mechanism, and optimized messaging mechanism!
|
||||
|
||||
## Install
|
||||
|
||||
|
|
@ -50,9 +52,9 @@ # Step 2: Clone the repository to your local machine for latest version, and ins
|
|||
cd MetaGPT
|
||||
pip3 install -e. # or pip3 install metagpt # for stable version
|
||||
|
||||
# Step 3: run the startup.py
|
||||
# Step 3: run metagpt cli
|
||||
# setup your OPENAI_API_KEY in key.yaml copy from config.yaml
|
||||
python3 startup.py "Write a cli snake game"
|
||||
metagpt "Write a cli snake game"
|
||||
|
||||
# Step 4 [Optional]: If you want to save the artifacts like diagrams such as quadrant chart, system designs, sequence flow in the workspace, you can execute the step before Step 3. By default, the framework is compatible, and the entire process can be run completely without executing this step.
|
||||
# If executing, ensure that NPM is installed on your system. Then install mermaid-js. (If you don't have npm in your computer, please go to the Node.js official website to install Node.js https://nodejs.org/ and then you will have npm tool in your computer.)
|
||||
|
|
@ -60,7 +62,7 @@ # If executing, ensure that NPM is installed on your system. Then install mermai
|
|||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
```
|
||||
|
||||
detail installation please refer to [cli_install](https://docs.deepwisdom.ai/guide/get_started/installation.html#install-stable-version)
|
||||
detail installation please refer to [cli_install](https://docs.deepwisdom.ai/main/en/guide/get_started/installation.html#install-stable-version)
|
||||
|
||||
### Docker installation
|
||||
> Note: In the Windows, you need to replace "/opt/metagpt" with a directory that Docker has permission to create, such as "D:\Users\x\metagpt"
|
||||
|
|
@ -78,10 +80,10 @@ # Step 2: Run metagpt demo with container
|
|||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
python startup.py "Write a cli snake game"
|
||||
metagpt "Write a cli snake game"
|
||||
```
|
||||
|
||||
detail installation please refer to [docker_install](https://docs.deepwisdom.ai/guide/get_started/installation.html#install-with-docker)
|
||||
detail installation please refer to [docker_install](https://docs.deepwisdom.ai/main/en/guide/get_started/installation.html#install-with-docker)
|
||||
|
||||
### QuickStart & Demo Video
|
||||
- Try it on [MetaGPT Huggingface Space](https://huggingface.co/spaces/deepwisdom/MetaGPT)
|
||||
|
|
@ -92,19 +94,19 @@ ### QuickStart & Demo Video
|
|||
|
||||
## Tutorial
|
||||
|
||||
- 🗒 [Online Document](https://docs.deepwisdom.ai/)
|
||||
- 💻 [Usage](https://docs.deepwisdom.ai/guide/get_started/quickstart.html)
|
||||
- 🔎 [What can MetaGPT do?](https://docs.deepwisdom.ai/guide/get_started/introduction.html)
|
||||
- 🗒 [Online Document](https://docs.deepwisdom.ai/main/en/)
|
||||
- 💻 [Usage](https://docs.deepwisdom.ai/main/en/guide/get_started/quickstart.html)
|
||||
- 🔎 [What can MetaGPT do?](https://docs.deepwisdom.ai/main/en/guide/get_started/introduction.html)
|
||||
- 🛠 How to build your own agents?
|
||||
- [MetaGPT Usage & Development Guide | Agent 101](https://docs.deepwisdom.ai/guide/tutorials/agent_101.html)
|
||||
- [MetaGPT Usage & Development Guide | MultiAgent 101](https://docs.deepwisdom.ai/guide/tutorials/multi_agent_101.html)
|
||||
- [MetaGPT Usage & Development Guide | Agent 101](https://docs.deepwisdom.ai/main/en/guide/tutorials/agent_101.html)
|
||||
- [MetaGPT Usage & Development Guide | MultiAgent 101](https://docs.deepwisdom.ai/main/en/guide/tutorials/multi_agent_101.html)
|
||||
- 🧑💻 Contribution
|
||||
- [Develop Roadmap](docs/ROADMAP.md)
|
||||
- 🔖 Use Cases
|
||||
- [Debate](https://docs.deepwisdom.ai/guide/use_cases/multi_agent/debate.html)
|
||||
- [Researcher](https://docs.deepwisdom.ai/guide/use_cases/agent/researcher.html)
|
||||
- [Recepit Assistant](https://docs.deepwisdom.ai/guide/use_cases/agent/receipt_assistant.html)
|
||||
- ❓ [FAQs](https://docs.deepwisdom.ai/guide/faq.html)
|
||||
- [Debate](https://docs.deepwisdom.ai/main/en/guide/use_cases/multi_agent/debate.html)
|
||||
- [Researcher](https://docs.deepwisdom.ai/main/en/guide/use_cases/agent/researcher.html)
|
||||
- [Recepit Assistant](https://docs.deepwisdom.ai/main/en/guide/use_cases/agent/receipt_assistant.html)
|
||||
- ❓ [FAQs](https://docs.deepwisdom.ai/main/en/guide/faq.html)
|
||||
|
||||
## Support
|
||||
|
||||
|
|
@ -117,7 +119,7 @@ ### Contact Information
|
|||
|
||||
If you have any questions or feedback about this project, please feel free to contact us. We highly appreciate your suggestions!
|
||||
|
||||
- **Email:** alexanderwu@fuzhi.ai
|
||||
- **Email:** alexanderwu@deepwisdom.ai
|
||||
- **GitHub Issues:** For more technical inquiries, you can also create a new issue in our [GitHub repository](https://github.com/geekan/metagpt/issues).
|
||||
|
||||
We will respond to all questions within 2-3 business days.
|
||||
|
|
|
|||
|
|
@ -1,15 +1,18 @@
|
|||
# DO NOT MODIFY THIS FILE, create a new key.yaml, define OPENAI_API_KEY.
|
||||
# The configuration of key.yaml has a higher priority and will not enter git
|
||||
|
||||
#### Project Path Setting
|
||||
# WORKSPACE_PATH: "Path for placing output files"
|
||||
|
||||
#### if OpenAI
|
||||
## The official OPENAI_BASE_URL is https://api.openai.com/v1
|
||||
## If the official OPENAI_BASE_URL is not available, we recommend using the [openai-forward](https://github.com/beidongjiedeguang/openai-forward).
|
||||
## Or, you can configure OPENAI_PROXY to access official OPENAI_BASE_URL.
|
||||
OPENAI_BASE_URL: "https://api.openai.com/v1"
|
||||
#OPENAI_PROXY: "http://127.0.0.1:8118"
|
||||
#OPENAI_API_KEY: "YOUR_API_KEY" # set the value to sk-xxx if you host the openai interface for open llm model
|
||||
OPENAI_API_MODEL: "gpt-4"
|
||||
MAX_TOKENS: 1500
|
||||
#OPENAI_API_KEY: "YOUR_API_KEY" # set the value to sk-xxx if you host the openai interface for open llm model
|
||||
OPENAI_API_MODEL: "gpt-4-1106-preview"
|
||||
MAX_TOKENS: 4096
|
||||
RPM: 10
|
||||
|
||||
#### if Spark
|
||||
|
|
@ -20,7 +23,7 @@ RPM: 10
|
|||
#SPARK_URL : "ws://spark-api.xf-yun.com/v2.1/chat"
|
||||
|
||||
#### if Anthropic
|
||||
#Anthropic_API_KEY: "YOUR_API_KEY"
|
||||
#ANTHROPIC_API_KEY: "YOUR_API_KEY"
|
||||
|
||||
#### if AZURE, check https://github.com/openai/openai-cookbook/blob/main/examples/azure/chat.ipynb
|
||||
#OPENAI_API_TYPE: "azure"
|
||||
|
|
@ -32,6 +35,15 @@ RPM: 10
|
|||
#### if zhipuai from `https://open.bigmodel.cn`. You can set here or export API_KEY="YOUR_API_KEY"
|
||||
# ZHIPUAI_API_KEY: "YOUR_API_KEY"
|
||||
|
||||
#### if use self-host open llm model with openai-compatible interface
|
||||
#OPEN_LLM_API_BASE: "http://127.0.0.1:8000/v1"
|
||||
#OPEN_LLM_API_MODEL: "llama2-13b"
|
||||
#
|
||||
##### if use Fireworks api
|
||||
#FIREWORKS_API_KEY: "YOUR_API_KEY"
|
||||
#FIREWORKS_API_BASE: "https://api.fireworks.ai/inference/v1"
|
||||
#FIREWORKS_API_MODEL: "YOUR_LLM_MODEL" # example, accounts/fireworks/models/llama-v2-13b-chat
|
||||
|
||||
#### for Search
|
||||
|
||||
## Supported values: serpapi/google/serper/ddg
|
||||
|
|
@ -66,8 +78,8 @@ RPM: 10
|
|||
|
||||
#### for Stable Diffusion
|
||||
## Use SD service, based on https://github.com/AUTOMATIC1111/stable-diffusion-webui
|
||||
SD_URL: "YOUR_SD_URL"
|
||||
SD_T2I_API: "/sdapi/v1/txt2img"
|
||||
#SD_URL: "YOUR_SD_URL"
|
||||
#SD_T2I_API: "/sdapi/v1/txt2img"
|
||||
|
||||
#### for Execution
|
||||
#LONG_TERM_MEMORY: false
|
||||
|
|
@ -82,8 +94,8 @@ SD_T2I_API: "/sdapi/v1/txt2img"
|
|||
# CALC_USAGE: false
|
||||
|
||||
### for Research
|
||||
MODEL_FOR_RESEARCHER_SUMMARY: gpt-3.5-turbo
|
||||
MODEL_FOR_RESEARCHER_REPORT: gpt-3.5-turbo-16k
|
||||
# MODEL_FOR_RESEARCHER_SUMMARY: gpt-3.5-turbo
|
||||
# MODEL_FOR_RESEARCHER_REPORT: gpt-3.5-turbo-16k
|
||||
|
||||
### choose the engine for mermaid conversion,
|
||||
# default is nodejs, you can change it to playwright,pyppeteer or ink
|
||||
|
|
@ -92,4 +104,9 @@ MODEL_FOR_RESEARCHER_REPORT: gpt-3.5-turbo-16k
|
|||
### browser path for pyppeteer engine, support Chrome, Chromium,MS Edge
|
||||
#PYPPETEER_EXECUTABLE_PATH: "/usr/bin/google-chrome-stable"
|
||||
|
||||
PROMPT_FORMAT: json #json or markdown
|
||||
### for repair non-openai LLM's output when parse json-text if PROMPT_FORMAT=json
|
||||
### due to non-openai LLM's output will not always follow the instruction, so here activate a post-process
|
||||
### repair operation on the content extracted from LLM's raw output. Warning, it improves the result but not fix all cases.
|
||||
# REPAIR_LLM_OUTPUT: false
|
||||
|
||||
# PROMPT_FORMAT: json #json or markdown
|
||||
639
docs/.pylintrc
Normal file
639
docs/.pylintrc
Normal file
|
|
@ -0,0 +1,639 @@
|
|||
[MAIN]
|
||||
|
||||
# Analyse import fallback blocks. This can be used to support both Python 2 and
|
||||
# 3 compatible code, which means that the block might have code that exists
|
||||
# only in one or another interpreter, leading to false positives when analysed.
|
||||
analyse-fallback-blocks=no
|
||||
|
||||
# Clear in-memory caches upon conclusion of linting. Useful if running pylint
|
||||
# in a server-like mode.
|
||||
clear-cache-post-run=no
|
||||
|
||||
# Load and enable all available extensions. Use --list-extensions to see a list
|
||||
# all available extensions.
|
||||
#enable-all-extensions=
|
||||
|
||||
# In error mode, messages with a category besides ERROR or FATAL are
|
||||
# suppressed, and no reports are done by default. Error mode is compatible with
|
||||
# disabling specific errors.
|
||||
#errors-only=
|
||||
|
||||
# Always return a 0 (non-error) status code, even if lint errors are found.
|
||||
# This is primarily useful in continuous integration scripts.
|
||||
#exit-zero=
|
||||
|
||||
# A comma-separated list of package or module names from where C extensions may
|
||||
# be loaded. Extensions are loading into the active Python interpreter and may
|
||||
# run arbitrary code.
|
||||
extension-pkg-allow-list=
|
||||
|
||||
# A comma-separated list of package or module names from where C extensions may
|
||||
# be loaded. Extensions are loading into the active Python interpreter and may
|
||||
# run arbitrary code. (This is an alternative name to extension-pkg-allow-list
|
||||
# for backward compatibility.)
|
||||
extension-pkg-whitelist=pydantic
|
||||
|
||||
# Return non-zero exit code if any of these messages/categories are detected,
|
||||
# even if score is above --fail-under value. Syntax same as enable. Messages
|
||||
# specified are enabled, while categories only check already-enabled messages.
|
||||
fail-on=
|
||||
|
||||
# Specify a score threshold under which the program will exit with error.
|
||||
fail-under=10
|
||||
|
||||
# Interpret the stdin as a python script, whose filename needs to be passed as
|
||||
# the module_or_package argument.
|
||||
#from-stdin=
|
||||
|
||||
# Files or directories to be skipped. They should be base names, not paths.
|
||||
ignore=CVS
|
||||
|
||||
# Add files or directories matching the regular expressions patterns to the
|
||||
# ignore-list. The regex matches against paths and can be in Posix or Windows
|
||||
# format. Because '\\' represents the directory delimiter on Windows systems,
|
||||
# it can't be used as an escape character.
|
||||
ignore-paths=
|
||||
|
||||
# Files or directories matching the regular expression patterns are skipped.
|
||||
# The regex matches against base names, not paths. The default value ignores
|
||||
# Emacs file locks
|
||||
#ignore-patterns=^\.#
|
||||
ignore-patterns=(.)*_test\.py,test_(.)*\.py
|
||||
|
||||
|
||||
# List of module names for which member attributes should not be checked
|
||||
# (useful for modules/projects where namespaces are manipulated during runtime
|
||||
# and thus existing member attributes cannot be deduced by static analysis). It
|
||||
# supports qualified module names, as well as Unix pattern matching.
|
||||
ignored-modules=
|
||||
|
||||
# Python code to execute, usually for sys.path manipulation such as
|
||||
# pygtk.require().
|
||||
#init-hook=
|
||||
|
||||
# Use multiple processes to speed up Pylint. Specifying 0 will auto-detect the
|
||||
# number of processors available to use, and will cap the count on Windows to
|
||||
# avoid hangs.
|
||||
jobs=1
|
||||
|
||||
# Control the amount of potential inferred values when inferring a single
|
||||
# object. This can help the performance when dealing with large functions or
|
||||
# complex, nested conditions.
|
||||
limit-inference-results=120
|
||||
|
||||
# List of plugins (as comma separated values of python module names) to load,
|
||||
# usually to register additional checkers.
|
||||
load-plugins=
|
||||
|
||||
# Pickle collected data for later comparisons.
|
||||
persistent=yes
|
||||
|
||||
# Minimum Python version to use for version dependent checks. Will default to
|
||||
# the version used to run pylint.
|
||||
py-version=3.9
|
||||
|
||||
# Discover python modules and packages in the file system subtree.
|
||||
recursive=no
|
||||
|
||||
# Add paths to the list of the source roots. Supports globbing patterns. The
|
||||
# source root is an absolute path or a path relative to the current working
|
||||
# directory used to determine a package namespace for modules located under the
|
||||
# source root.
|
||||
source-roots=
|
||||
|
||||
# When enabled, pylint would attempt to guess common misconfiguration and emit
|
||||
# user-friendly hints instead of false-positive error messages.
|
||||
suggestion-mode=yes
|
||||
|
||||
# Allow loading of arbitrary C extensions. Extensions are imported into the
|
||||
# active Python interpreter and may run arbitrary code.
|
||||
unsafe-load-any-extension=no
|
||||
|
||||
# In verbose mode, extra non-checker-related info will be displayed.
|
||||
#verbose=
|
||||
|
||||
|
||||
[BASIC]
|
||||
|
||||
# Naming style matching correct argument names.
|
||||
argument-naming-style=snake_case
|
||||
|
||||
# Regular expression matching correct argument names. Overrides argument-
|
||||
# naming-style. If left empty, argument names will be checked with the set
|
||||
# naming style.
|
||||
#argument-rgx=
|
||||
|
||||
# Naming style matching correct attribute names.
|
||||
attr-naming-style=snake_case
|
||||
|
||||
# Regular expression matching correct attribute names. Overrides attr-naming-
|
||||
# style. If left empty, attribute names will be checked with the set naming
|
||||
# style.
|
||||
#attr-rgx=
|
||||
|
||||
# Bad variable names which should always be refused, separated by a comma.
|
||||
bad-names=foo,
|
||||
bar,
|
||||
baz,
|
||||
toto,
|
||||
tutu,
|
||||
tata
|
||||
|
||||
# Bad variable names regexes, separated by a comma. If names match any regex,
|
||||
# they will always be refused
|
||||
bad-names-rgxs=
|
||||
|
||||
# Naming style matching correct class attribute names.
|
||||
class-attribute-naming-style=any
|
||||
|
||||
# Regular expression matching correct class attribute names. Overrides class-
|
||||
# attribute-naming-style. If left empty, class attribute names will be checked
|
||||
# with the set naming style.
|
||||
#class-attribute-rgx=
|
||||
|
||||
# Naming style matching correct class constant names.
|
||||
class-const-naming-style=UPPER_CASE
|
||||
|
||||
# Regular expression matching correct class constant names. Overrides class-
|
||||
# const-naming-style. If left empty, class constant names will be checked with
|
||||
# the set naming style.
|
||||
#class-const-rgx=
|
||||
|
||||
# Naming style matching correct class names.
|
||||
class-naming-style=PascalCase
|
||||
|
||||
# Regular expression matching correct class names. Overrides class-naming-
|
||||
# style. If left empty, class names will be checked with the set naming style.
|
||||
#class-rgx=
|
||||
|
||||
# Naming style matching correct constant names.
|
||||
const-naming-style=UPPER_CASE
|
||||
|
||||
# Regular expression matching correct constant names. Overrides const-naming-
|
||||
# style. If left empty, constant names will be checked with the set naming
|
||||
# style.
|
||||
#const-rgx=
|
||||
|
||||
# Minimum line length for functions/classes that require docstrings, shorter
|
||||
# ones are exempt.
|
||||
docstring-min-length=-1
|
||||
|
||||
# Naming style matching correct function names.
|
||||
function-naming-style=snake_case
|
||||
|
||||
# Regular expression matching correct function names. Overrides function-
|
||||
# naming-style. If left empty, function names will be checked with the set
|
||||
# naming style.
|
||||
#function-rgx=
|
||||
|
||||
# Good variable names which should always be accepted, separated by a comma.
|
||||
good-names=i,
|
||||
j,
|
||||
k,
|
||||
v,
|
||||
e,
|
||||
d,
|
||||
m,
|
||||
df,
|
||||
ex,
|
||||
Run,
|
||||
_
|
||||
|
||||
# Good variable names regexes, separated by a comma. If names match any regex,
|
||||
# they will always be accepted
|
||||
good-names-rgxs=
|
||||
|
||||
# Include a hint for the correct naming format with invalid-name.
|
||||
include-naming-hint=no
|
||||
|
||||
# Naming style matching correct inline iteration names.
|
||||
inlinevar-naming-style=any
|
||||
|
||||
# Regular expression matching correct inline iteration names. Overrides
|
||||
# inlinevar-naming-style. If left empty, inline iteration names will be checked
|
||||
# with the set naming style.
|
||||
#inlinevar-rgx=
|
||||
|
||||
# Naming style matching correct method names.
|
||||
method-naming-style=snake_case
|
||||
|
||||
# Regular expression matching correct method names. Overrides method-naming-
|
||||
# style. If left empty, method names will be checked with the set naming style.
|
||||
#method-rgx=
|
||||
|
||||
# Naming style matching correct module names.
|
||||
module-naming-style=snake_case
|
||||
|
||||
# Regular expression matching correct module names. Overrides module-naming-
|
||||
# style. If left empty, module names will be checked with the set naming style.
|
||||
#module-rgx=
|
||||
|
||||
# Colon-delimited sets of names that determine each other's naming style when
|
||||
# the name regexes allow several styles.
|
||||
name-group=
|
||||
|
||||
# Regular expression which should only match function or class names that do
|
||||
# not require a docstring.
|
||||
no-docstring-rgx=^_
|
||||
|
||||
# List of decorators that produce properties, such as abc.abstractproperty. Add
|
||||
# to this list to register other decorators that produce valid properties.
|
||||
# These decorators are taken in consideration only for invalid-name.
|
||||
property-classes=abc.abstractproperty
|
||||
|
||||
# Regular expression matching correct type alias names. If left empty, type
|
||||
# alias names will be checked with the set naming style.
|
||||
#typealias-rgx=
|
||||
|
||||
# Regular expression matching correct type variable names. If left empty, type
|
||||
# variable names will be checked with the set naming style.
|
||||
#typevar-rgx=
|
||||
|
||||
# Naming style matching correct variable names.
|
||||
variable-naming-style=snake_case
|
||||
|
||||
# Regular expression matching correct variable names. Overrides variable-
|
||||
# naming-style. If left empty, variable names will be checked with the set
|
||||
# naming style.
|
||||
#variable-rgx=
|
||||
|
||||
|
||||
[CLASSES]
|
||||
|
||||
# Warn about protected attribute access inside special methods
|
||||
check-protected-access-in-special-methods=no
|
||||
|
||||
# List of method names used to declare (i.e. assign) instance attributes.
|
||||
defining-attr-methods=__init__,
|
||||
__new__,
|
||||
setUp,
|
||||
__post_init__
|
||||
|
||||
# List of member names, which should be excluded from the protected access
|
||||
# warning.
|
||||
exclude-protected=_asdict,_fields,_replace,_source,_make,os._exit
|
||||
|
||||
# List of valid names for the first argument in a class method.
|
||||
valid-classmethod-first-arg=cls
|
||||
|
||||
# List of valid names for the first argument in a metaclass class method.
|
||||
valid-metaclass-classmethod-first-arg=mcs
|
||||
|
||||
|
||||
[DESIGN]
|
||||
|
||||
# List of regular expressions of class ancestor names to ignore when counting
|
||||
# public methods (see R0903)
|
||||
exclude-too-few-public-methods=
|
||||
|
||||
# List of qualified class names to ignore when counting class parents (see
|
||||
# R0901)
|
||||
ignored-parents=
|
||||
|
||||
# Maximum number of arguments for function / method.
|
||||
max-args=5
|
||||
|
||||
# Maximum number of attributes for a class (see R0902).
|
||||
max-attributes=7
|
||||
|
||||
# Maximum number of boolean expressions in an if statement (see R0916).
|
||||
max-bool-expr=5
|
||||
|
||||
# Maximum number of branch for function / method body.
|
||||
max-branches=12
|
||||
|
||||
# Maximum number of locals for function / method body.
|
||||
max-locals=15
|
||||
|
||||
# Maximum number of parents for a class (see R0901).
|
||||
max-parents=7
|
||||
|
||||
# Maximum number of public methods for a class (see R0904).
|
||||
max-public-methods=20
|
||||
|
||||
# Maximum number of return / yield for function / method body.
|
||||
max-returns=6
|
||||
|
||||
# Maximum number of statements in function / method body.
|
||||
max-statements=50
|
||||
|
||||
# Minimum number of public methods for a class (see R0903).
|
||||
min-public-methods=2
|
||||
|
||||
|
||||
[EXCEPTIONS]
|
||||
|
||||
# Exceptions that will emit a warning when caught.
|
||||
overgeneral-exceptions=builtins.BaseException,builtins.Exception
|
||||
|
||||
|
||||
[FORMAT]
|
||||
|
||||
# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
|
||||
expected-line-ending-format=
|
||||
|
||||
# Regexp for a line that is allowed to be longer than the limit.
|
||||
ignore-long-lines=^\s*(# )?<?https?://\S+>?$
|
||||
|
||||
# Number of spaces of indent required inside a hanging or continued line.
|
||||
indent-after-paren=4
|
||||
|
||||
# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1
|
||||
# tab).
|
||||
indent-string=' '
|
||||
|
||||
# Maximum number of characters on a single line.
|
||||
max-line-length=120
|
||||
|
||||
# Maximum number of lines in a module.
|
||||
max-module-lines=1000
|
||||
|
||||
# Allow the body of a class to be on the same line as the declaration if body
|
||||
# contains single statement.
|
||||
single-line-class-stmt=no
|
||||
|
||||
# Allow the body of an if to be on the same line as the test if there is no
|
||||
# else.
|
||||
single-line-if-stmt=no
|
||||
|
||||
|
||||
[IMPORTS]
|
||||
|
||||
# List of modules that can be imported at any level, not just the top level
|
||||
# one.
|
||||
allow-any-import-level=
|
||||
|
||||
# Allow explicit reexports by alias from a package __init__.
|
||||
allow-reexport-from-package=no
|
||||
|
||||
# Allow wildcard imports from modules that define __all__.
|
||||
allow-wildcard-with-all=no
|
||||
|
||||
# Deprecated modules which should not be used, separated by a comma.
|
||||
deprecated-modules=
|
||||
|
||||
# Output a graph (.gv or any supported image format) of external dependencies
|
||||
# to the given file (report RP0402 must not be disabled).
|
||||
ext-import-graph=
|
||||
|
||||
# Output a graph (.gv or any supported image format) of all (i.e. internal and
|
||||
# external) dependencies to the given file (report RP0402 must not be
|
||||
# disabled).
|
||||
import-graph=
|
||||
|
||||
# Output a graph (.gv or any supported image format) of internal dependencies
|
||||
# to the given file (report RP0402 must not be disabled).
|
||||
int-import-graph=
|
||||
|
||||
# Force import order to recognize a module as part of the standard
|
||||
# compatibility libraries.
|
||||
known-standard-library=
|
||||
|
||||
# Force import order to recognize a module as part of a third party library.
|
||||
known-third-party=enchant
|
||||
|
||||
# Couples of modules and preferred modules, separated by a comma.
|
||||
preferred-modules=
|
||||
|
||||
|
||||
[LOGGING]
|
||||
|
||||
# The type of string formatting that logging methods do. `old` means using %
|
||||
# formatting, `new` is for `{}` formatting.
|
||||
logging-format-style=old
|
||||
|
||||
# Logging modules to check that the string format arguments are in logging
|
||||
# function parameter format.
|
||||
logging-modules=logging
|
||||
|
||||
|
||||
[MESSAGES CONTROL]
|
||||
|
||||
# Only show warnings with the listed confidence levels. Leave empty to show
|
||||
# all. Valid levels: HIGH, CONTROL_FLOW, INFERENCE, INFERENCE_FAILURE,
|
||||
# UNDEFINED.
|
||||
confidence=HIGH,
|
||||
CONTROL_FLOW,
|
||||
INFERENCE,
|
||||
INFERENCE_FAILURE,
|
||||
UNDEFINED
|
||||
|
||||
# Disable the message, report, category or checker with the given id(s). You
|
||||
# can either give multiple identifiers separated by comma (,) or put this
|
||||
# option multiple times (only on the command line, not in the configuration
|
||||
# file where it should appear only once). You can also use "--disable=all" to
|
||||
# disable everything first and then re-enable specific checks. For example, if
|
||||
# you want to run only the similarities checker, you can use "--disable=all
|
||||
# --enable=similarities". If you want to run only the classes checker, but have
|
||||
# no Warning level messages displayed, use "--disable=all --enable=classes
|
||||
# --disable=W".
|
||||
disable=raw-checker-failed,
|
||||
bad-inline-option,
|
||||
locally-disabled,
|
||||
file-ignored,
|
||||
suppressed-message,
|
||||
useless-suppression,
|
||||
deprecated-pragma,
|
||||
use-symbolic-message-instead,
|
||||
expression-not-assigned,
|
||||
pointless-statement
|
||||
|
||||
# Enable the message, report, category or checker with the given id(s). You can
|
||||
# either give multiple identifier separated by comma (,) or put this option
|
||||
# multiple time (only on the command line, not in the configuration file where
|
||||
# it should appear only once). See also the "--disable" option for examples.
|
||||
enable=c-extension-no-member
|
||||
|
||||
|
||||
[METHOD_ARGS]
|
||||
|
||||
# List of qualified names (i.e., library.method) which require a timeout
|
||||
# parameter e.g. 'requests.api.get,requests.api.post'
|
||||
timeout-methods=requests.api.delete,requests.api.get,requests.api.head,requests.api.options,requests.api.patch,requests.api.post,requests.api.put,requests.api.request
|
||||
|
||||
|
||||
[MISCELLANEOUS]
|
||||
|
||||
# List of note tags to take in consideration, separated by a comma.
|
||||
notes=FIXME,
|
||||
XXX,
|
||||
TODO
|
||||
|
||||
# Regular expression of note tags to take in consideration.
|
||||
notes-rgx=
|
||||
|
||||
|
||||
[REFACTORING]
|
||||
|
||||
# Maximum number of nested blocks for function / method body
|
||||
max-nested-blocks=5
|
||||
|
||||
# Complete name of functions that never returns. When checking for
|
||||
# inconsistent-return-statements if a never returning function is called then
|
||||
# it will be considered as an explicit return statement and no message will be
|
||||
# printed.
|
||||
never-returning-functions=sys.exit,argparse.parse_error
|
||||
|
||||
|
||||
[REPORTS]
|
||||
|
||||
# Python expression which should return a score less than or equal to 10. You
|
||||
# have access to the variables 'fatal', 'error', 'warning', 'refactor',
|
||||
# 'convention', and 'info' which contain the number of messages in each
|
||||
# category, as well as 'statement' which is the total number of statements
|
||||
# analyzed. This score is used by the global evaluation report (RP0004).
|
||||
evaluation=max(0, 0 if fatal else 10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10))
|
||||
|
||||
# Template used to display messages. This is a python new-style format string
|
||||
# used to format the message information. See doc for all details.
|
||||
msg-template=
|
||||
|
||||
# Set the output format. Available formats are text, parseable, colorized, json
|
||||
# and msvs (visual studio). You can also give a reporter class, e.g.
|
||||
# mypackage.mymodule.MyReporterClass.
|
||||
#output-format=
|
||||
|
||||
# Tells whether to display a full report or only the messages.
|
||||
reports=no
|
||||
|
||||
# Activate the evaluation score.
|
||||
score=yes
|
||||
|
||||
|
||||
[SIMILARITIES]
|
||||
|
||||
# Comments are removed from the similarity computation
|
||||
ignore-comments=yes
|
||||
|
||||
# Docstrings are removed from the similarity computation
|
||||
ignore-docstrings=yes
|
||||
|
||||
# Imports are removed from the similarity computation
|
||||
ignore-imports=yes
|
||||
|
||||
# Signatures are removed from the similarity computation
|
||||
ignore-signatures=yes
|
||||
|
||||
# Minimum lines number of a similarity.
|
||||
min-similarity-lines=4
|
||||
|
||||
|
||||
[SPELLING]
|
||||
|
||||
# Limits count of emitted suggestions for spelling mistakes.
|
||||
max-spelling-suggestions=4
|
||||
|
||||
# Spelling dictionary name. No available dictionaries : You need to install
|
||||
# both the python package and the system dependency for enchant to work..
|
||||
spelling-dict=
|
||||
|
||||
# List of comma separated words that should be considered directives if they
|
||||
# appear at the beginning of a comment and should not be checked.
|
||||
spelling-ignore-comment-directives=fmt: on,fmt: off,noqa:,noqa,nosec,isort:skip,mypy:
|
||||
|
||||
# List of comma separated words that should not be checked.
|
||||
spelling-ignore-words=
|
||||
|
||||
# A path to a file that contains the private dictionary; one word per line.
|
||||
spelling-private-dict-file=
|
||||
|
||||
# Tells whether to store unknown words to the private dictionary (see the
|
||||
# --spelling-private-dict-file option) instead of raising a message.
|
||||
spelling-store-unknown-words=no
|
||||
|
||||
|
||||
[STRING]
|
||||
|
||||
# This flag controls whether inconsistent-quotes generates a warning when the
|
||||
# character used as a quote delimiter is used inconsistently within a module.
|
||||
check-quote-consistency=no
|
||||
|
||||
# This flag controls whether the implicit-str-concat should generate a warning
|
||||
# on implicit string concatenation in sequences defined over several lines.
|
||||
check-str-concat-over-line-jumps=no
|
||||
|
||||
|
||||
[TYPECHECK]
|
||||
|
||||
# List of decorators that produce context managers, such as
|
||||
# contextlib.contextmanager. Add to this list to register other decorators that
|
||||
# produce valid context managers.
|
||||
contextmanager-decorators=contextlib.contextmanager
|
||||
|
||||
# List of members which are set dynamically and missed by pylint inference
|
||||
# system, and so shouldn't trigger E1101 when accessed. Python regular
|
||||
# expressions are accepted.
|
||||
generated-members=
|
||||
|
||||
# Tells whether to warn about missing members when the owner of the attribute
|
||||
# is inferred to be None.
|
||||
ignore-none=yes
|
||||
|
||||
# This flag controls whether pylint should warn about no-member and similar
|
||||
# checks whenever an opaque object is returned when inferring. The inference
|
||||
# can return multiple potential results while evaluating a Python object, but
|
||||
# some branches might not be evaluated, which results in partial inference. In
|
||||
# that case, it might be useful to still emit no-member and other checks for
|
||||
# the rest of the inferred objects.
|
||||
ignore-on-opaque-inference=yes
|
||||
|
||||
# List of symbolic message names to ignore for Mixin members.
|
||||
ignored-checks-for-mixins=no-member,
|
||||
not-async-context-manager,
|
||||
not-context-manager,
|
||||
attribute-defined-outside-init
|
||||
|
||||
# List of class names for which member attributes should not be checked (useful
|
||||
# for classes with dynamically set attributes). This supports the use of
|
||||
# qualified names.
|
||||
ignored-classes=optparse.Values,thread._local,_thread._local,argparse.Namespace
|
||||
|
||||
# Show a hint with possible names when a member name was not found. The aspect
|
||||
# of finding the hint is based on edit distance.
|
||||
missing-member-hint=yes
|
||||
|
||||
# The minimum edit distance a name should have in order to be considered a
|
||||
# similar match for a missing member name.
|
||||
missing-member-hint-distance=1
|
||||
|
||||
# The total number of similar names that should be taken in consideration when
|
||||
# showing a hint for a missing member.
|
||||
missing-member-max-choices=1
|
||||
|
||||
# Regex pattern to define which classes are considered mixins.
|
||||
mixin-class-rgx=.*[Mm]ixin
|
||||
|
||||
# List of decorators that change the signature of a decorated function.
|
||||
signature-mutators=
|
||||
|
||||
|
||||
[VARIABLES]
|
||||
|
||||
# List of additional names supposed to be defined in builtins. Remember that
|
||||
# you should avoid defining new builtins when possible.
|
||||
additional-builtins=
|
||||
|
||||
# Tells whether unused global variables should be treated as a violation.
|
||||
allow-global-unused-variables=yes
|
||||
|
||||
# List of names allowed to shadow builtins
|
||||
allowed-redefined-builtins=
|
||||
|
||||
# List of strings which can identify a callback function by name. A callback
|
||||
# name must start or end with one of those strings.
|
||||
callbacks=cb_,
|
||||
_cb
|
||||
|
||||
# A regular expression matching the name of dummy variables (i.e. expected to
|
||||
# not be used).
|
||||
dummy-variables-rgx=_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|dummy|^ignored_|^unused_
|
||||
|
||||
# Argument names that match this expression will be ignored.
|
||||
ignored-argument-names=_.*|^ignored_|^unused_
|
||||
|
||||
# Tells whether we should check for unused import in __init__ files.
|
||||
init-import=no
|
||||
|
||||
# List of qualified module names which can have objects that can redefine
|
||||
# builtins.
|
||||
redefining-builtins-modules=six.moves,past.builtins,future.builtins,builtins,io
|
||||
|
|
@ -98,7 +98,7 @@
|
|||
|
||||
1. How to change the investment amount?
|
||||
|
||||
1. You can view all commands by typing `python startup.py --help`
|
||||
1. You can view all commands by typing `metagpt --help`
|
||||
|
||||
1. Which version of Python is more stable?
|
||||
|
||||
|
|
@ -134,7 +134,7 @@
|
|||
|
||||
1. Configuration instructions for SD Skills: The SD interface is currently deployed based on *https://github.com/AUTOMATIC1111/stable-diffusion-webui* **For environmental configurations and model downloads, please refer to the aforementioned GitHub repository. To initiate the SD service that supports API calls, run the command specified in cmd with the parameter nowebui, i.e.,
|
||||
|
||||
1. > python webui.py --enable-insecure-extension-access --port xxx --no-gradio-queue --nowebui
|
||||
1. > python3 webui.py --enable-insecure-extension-access --port xxx --no-gradio-queue --nowebui
|
||||
1. Once it runs without errors, the interface will be accessible after approximately 1 minute when the model finishes loading.
|
||||
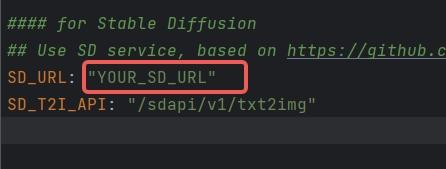
1. Configure SD_URL and SD_T2I_API in the config.yaml/key.yaml files.
|
||||
1. 
|
||||
|
|
|
|||
|
|
@ -47,9 +47,9 @@ # 第 2 步:克隆最新仓库到您的本地机器,并进行安装。
|
|||
cd MetaGPT
|
||||
pip3 install -e. # 或者 pip3 install metagpt # 安装稳定版本
|
||||
|
||||
# 第 3 步:执行startup.py
|
||||
# 第 3 步:执行metagpt
|
||||
# 拷贝config.yaml为key.yaml,并设置你自己的OPENAI_API_KEY
|
||||
python3 startup.py "Write a cli snake game"
|
||||
metagpt "Write a cli snake game"
|
||||
|
||||
# 第 4 步【可选的】:如果你想在执行过程中保存像象限图、系统设计、序列流程等图表这些产物,可以在第3步前执行该步骤。默认的,框架做了兼容,在不执行该步的情况下,也可以完整跑完整个流程。
|
||||
# 如果执行,确保您的系统上安装了 NPM。并使用npm安装mermaid-js
|
||||
|
|
@ -75,10 +75,10 @@ # 步骤2: 使用容器运行metagpt演示
|
|||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
python startup.py "Write a cli snake game"
|
||||
metagpt "Write a cli snake game"
|
||||
```
|
||||
|
||||
详细的安装请安装 [docker_install](https://docs.deepwisdom.ai/zhcn/guide/get_started/installation.html#%E4%BD%BF%E7%94%A8docker%E5%AE%89%E8%A3%85)
|
||||
详细的安装请安装 [docker_install](https://docs.deepwisdom.ai/main/zh/guide/get_started/installation.html#%E4%BD%BF%E7%94%A8docker%E5%AE%89%E8%A3%85)
|
||||
|
||||
### 快速开始的演示视频
|
||||
- 在 [MetaGPT Huggingface Space](https://huggingface.co/spaces/deepwisdom/MetaGPT) 上进行体验
|
||||
|
|
@ -88,19 +88,19 @@ ### 快速开始的演示视频
|
|||
https://github.com/geekan/MetaGPT/assets/34952977/34345016-5d13-489d-b9f9-b82ace413419
|
||||
|
||||
## 教程
|
||||
- 🗒 [在线文档](https://docs.deepwisdom.ai/zhcn/)
|
||||
- 💻 [如何使用](https://docs.deepwisdom.ai/zhcn/guide/get_started/quickstart.html)
|
||||
- 🔎 [MetaGPT的能力及应用场景](https://docs.deepwisdom.ai/zhcn/guide/get_started/introduction.html)
|
||||
- 🗒 [在线文档](https://docs.deepwisdom.ai/main/zh/)
|
||||
- 💻 [如何使用](https://docs.deepwisdom.ai/main/zh/guide/get_started/quickstart.html)
|
||||
- 🔎 [MetaGPT的能力及应用场景](https://docs.deepwisdom.ai/main/zh/guide/get_started/introduction.html)
|
||||
- 🛠 如何构建你自己的智能体?
|
||||
- [MetaGPT的使用和开发教程 | 智能体入门](https://docs.deepwisdom.ai/zhcn/guide/tutorials/agent_101.html)
|
||||
- [MetaGPT的使用和开发教程 | 多智能体入门](https://docs.deepwisdom.ai/zhcn/guide/tutorials/multi_agent_101.html)
|
||||
- [MetaGPT的使用和开发教程 | 智能体入门](https://docs.deepwisdom.ai/main/zh/guide/tutorials/agent_101.html)
|
||||
- [MetaGPT的使用和开发教程 | 多智能体入门](https://docs.deepwisdom.ai/main/zh/guide/tutorials/multi_agent_101.html)
|
||||
- 🧑💻 贡献
|
||||
- [开发路线图](ROADMAP.md)
|
||||
- 🔖 示例
|
||||
- [辩论](https://docs.deepwisdom.ai/zhcn/guide/use_cases/multi_agent/debate.html)
|
||||
- [调研员](https://docs.deepwisdom.ai/zhcn/guide/use_cases/agent/researcher.html)
|
||||
- [票据助手](https://docs.deepwisdom.ai/zhcn/guide/use_cases/agent/receipt_assistant.html)
|
||||
- ❓ [常见问题解答](https://docs.deepwisdom.ai/zhcn/guide/faq.html)
|
||||
- [辩论](https://docs.deepwisdom.ai/main/zh/guide/use_cases/multi_agent/debate.html)
|
||||
- [调研员](https://docs.deepwisdom.ai/main/zh/guide/use_cases/agent/researcher.html)
|
||||
- [票据助手](https://docs.deepwisdom.ai/main/zh/guide/use_cases/agent/receipt_assistant.html)
|
||||
- ❓ [常见问题解答](https://docs.deepwisdom.ai/main/zh/guide/faq.html)
|
||||
|
||||
## 支持
|
||||
|
||||
|
|
@ -114,7 +114,7 @@ ### 联系信息
|
|||
|
||||
如果您对这个项目有任何问题或反馈,欢迎联系我们。我们非常欢迎您的建议!
|
||||
|
||||
- **邮箱:** alexanderwu@fuzhi.ai
|
||||
- **邮箱:** alexanderwu@deepwisdom.ai
|
||||
- **GitHub 问题:** 对于更技术性的问题,您也可以在我们的 [GitHub 仓库](https://github.com/geekan/metagpt/issues) 中创建一个新的问题。
|
||||
|
||||
我们会在2-3个工作日内回复所有问题。
|
||||
|
|
|
|||
|
|
@ -41,7 +41,7 @@ ## MetaGPT の能力
|
|||
|
||||
## 例(GPT-4 で完全生成)
|
||||
|
||||
例えば、`python startup.py "Toutiao のような RecSys をデザインする"`と入力すると、多くの出力が得られます
|
||||
例えば、`metagpt "Toutiao のような RecSys をデザインする"`と入力すると、多くの出力が得られます
|
||||
|
||||

|
||||
|
||||
|
|
@ -60,16 +60,16 @@ ### 伝統的なインストール
|
|||
|
||||
```bash
|
||||
# ステップ 1: Python 3.9+ がシステムにインストールされていることを確認してください。これを確認するには:
|
||||
python --version
|
||||
python3 --version
|
||||
|
||||
# ステップ 2: リポジトリをローカルマシンにクローンし、インストールする。
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip install -e.
|
||||
|
||||
# ステップ 3: startup.py を実行する
|
||||
# ステップ 3: metagpt を実行する
|
||||
# config.yaml を key.yaml にコピーし、独自の OPENAI_API_KEY を設定します
|
||||
python3 startup.py "Write a cli snake game"
|
||||
metagpt "Write a cli snake game"
|
||||
|
||||
# ステップ 4 [オプション]: 実行中に PRD ファイルなどのアーティファクトを保存する場合は、ステップ 3 の前にこのステップを実行できます。デフォルトでは、フレームワークには互換性があり、この手順を実行しなくてもプロセス全体を完了できます。
|
||||
# NPM がシステムにインストールされていることを確認してください。次に mermaid-js をインストールします。(お使いのコンピューターに npm がない場合は、Node.js 公式サイトで Node.js https://nodejs.org/ をインストールしてください。)
|
||||
|
|
@ -178,7 +178,7 @@ # ステップ 2: コンテナで metagpt デモを実行する
|
|||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
python startup.py "Write a cli snake game"
|
||||
metagpt "Write a cli snake game"
|
||||
|
||||
# コンテナを起動し、その中でコマンドを実行することもできます
|
||||
docker run --name metagpt -d \
|
||||
|
|
@ -188,7 +188,7 @@ # コンテナを起動し、その中でコマンドを実行することもで
|
|||
metagpt/metagpt:latest
|
||||
|
||||
docker exec -it metagpt /bin/bash
|
||||
$ python startup.py "Write a cli snake game"
|
||||
$ metagpt "Write a cli snake game"
|
||||
```
|
||||
|
||||
コマンド `docker run ...` は以下のことを行います:
|
||||
|
|
@ -196,7 +196,7 @@ # コンテナを起動し、その中でコマンドを実行することもで
|
|||
- 特権モードで実行し、ブラウザの実行権限を得る
|
||||
- ホスト設定ファイル `/opt/metagpt/config/key.yaml` をコンテナ `/app/metagpt/config/key.yaml` にマップします
|
||||
- ホストディレクトリ `/opt/metagpt/workspace` をコンテナディレクトリ `/app/metagpt/workspace` にマップするs
|
||||
- デモコマンド `python startup.py "Write a cli snake game"` を実行する
|
||||
- デモコマンド `metagpt "Write a cli snake game"` を実行する
|
||||
|
||||
### 自分でイメージをビルドする
|
||||
|
||||
|
|
@ -225,11 +225,11 @@ ## チュートリアル: スタートアップの開始
|
|||
|
||||
```shell
|
||||
# スクリプトの実行
|
||||
python startup.py "Write a cli snake game"
|
||||
metagpt "Write a cli snake game"
|
||||
# プロジェクトの実施にエンジニアを雇わないこと
|
||||
python startup.py "Write a cli snake game" --implement False
|
||||
metagpt "Write a cli snake game" --no-implement
|
||||
# エンジニアを雇い、コードレビューを行う
|
||||
python startup.py "Write a cli snake game" --code_review True
|
||||
metagpt "Write a cli snake game" --code_review
|
||||
```
|
||||
|
||||
スクリプトを実行すると、`workspace/` ディレクトリに新しいプロジェクトが見つかります。
|
||||
|
|
@ -239,17 +239,17 @@ ### プラットフォームまたはツールの設定
|
|||
要件を述べるときに、どのプラットフォームまたはツールを使用するかを指定できます。
|
||||
|
||||
```shell
|
||||
python startup.py "pygame をベースとした cli ヘビゲームを書く"
|
||||
metagpt "pygame をベースとした cli ヘビゲームを書く"
|
||||
```
|
||||
|
||||
### 使用方法
|
||||
|
||||
```
|
||||
会社名
|
||||
startup.py - 私たちは AI で構成されたソフトウェア・スタートアップです。私たちに投資することは、無限の可能性に満ちた未来に力を与えることです。
|
||||
metagpt - 私たちは AI で構成されたソフトウェア・スタートアップです。私たちに投資することは、無限の可能性に満ちた未来に力を与えることです。
|
||||
|
||||
シノプシス
|
||||
startup.py IDEA <flags>
|
||||
metagpt IDEA <flags>
|
||||
|
||||
説明
|
||||
私たちは AI で構成されたソフトウェア・スタートアップです。私たちに投資することは、無限の可能性に満ちた未来に力を与えることです。
|
||||
|
|
@ -317,7 +317,7 @@ ## お問い合わせ先
|
|||
|
||||
このプロジェクトに関するご質問やご意見がございましたら、お気軽にお問い合わせください。皆様のご意見をお待ちしております!
|
||||
|
||||
- **Email:** alexanderwu@fuzhi.ai
|
||||
- **Email:** alexanderwu@deepwisdom.ai
|
||||
- **GitHub Issues:** 技術的なお問い合わせについては、[GitHub リポジトリ](https://github.com/geekan/metagpt/issues) に新しい issue を作成することもできます。
|
||||
|
||||
ご質問には 2-3 営業日以内に回答いたします。
|
||||
|
|
|
|||
|
|
@ -16,12 +16,12 @@ ### Tasks
|
|||
To reach version v0.5, approximately 70% of the following tasks need to be completed.
|
||||
|
||||
1. Usability
|
||||
1. Release v0.01 pip package to try to solve issues like npm installation (though not necessarily successfully)
|
||||
1. ~~Release v0.01 pip package to try to solve issues like npm installation (though not necessarily successfully)~~ (v0.3.0)
|
||||
2. Support for overall save and recovery of software companies
|
||||
3. Support human confirmation and modification during the process
|
||||
3. ~~Support human confirmation and modification during the process~~ (v0.3.0) New: Support human confirmation and modification with fewer constrainsts and a more user-friendly interface
|
||||
4. Support process caching: Consider carefully whether to add server caching mechanism
|
||||
5. Resolve occasional failure to follow instruction under current prompts, causing code parsing errors, through stricter system prompts
|
||||
6. Write documentation, describing the current features and usage at all levels
|
||||
5. ~~Resolve occasional failure to follow instruction under current prompts, causing code parsing errors, through stricter system prompts~~ (v0.4.0, with function call)
|
||||
6. Write documentation, describing the current features and usage at all levels (ongoing, continuously adding contents to [documentation site](https://docs.deepwisdom.ai/main/en/guide/get_started/introduction.html))
|
||||
7. ~~Support Docker~~
|
||||
2. Features
|
||||
1. Support a more standard and stable parser (need to analyze the format that the current LLM is better at)
|
||||
|
|
@ -30,31 +30,33 @@ ### Tasks
|
|||
4. Complete the design and implementation of module breakdown
|
||||
5. Support various modes of memory: clearly distinguish between long-term and short-term memory
|
||||
6. Perfect the test role, and carry out necessary interactions with humans
|
||||
7. Provide full mode instead of the current fast mode, allowing natural communication between roles
|
||||
8. Implement SkillManager and the process of incremental Skill learning
|
||||
7. ~~Allowing natural communication between roles~~ (v0.5.0)
|
||||
8. Implement SkillManager and the process of incremental Skill learning (experimentation done with game agents)
|
||||
9. Automatically get RPM and configure it by calling the corresponding openai page, so that each key does not need to be manually configured
|
||||
10. ~~IMPORTANT: Support incremental development~~ (v0.5.0)
|
||||
3. Strategies
|
||||
1. Support ReAct strategy
|
||||
2. Support CoT strategy
|
||||
1. Support ReAct strategy (experimentation done with game agents)
|
||||
2. Support CoT strategy (experimentation done with game agents)
|
||||
3. Support ToT strategy
|
||||
4. Support Reflection strategy
|
||||
4. Support Reflection strategy (experimentation done with game agents)
|
||||
5. Support planning
|
||||
4. Actions
|
||||
1. Implementation: Search
|
||||
1. ~~Implementation: Search~~ (v0.2.1)
|
||||
2. Implementation: Knowledge search, supporting 10+ data formats
|
||||
3. Implementation: Data EDA
|
||||
3. Implementation: Data EDA (expected v0.6.0)
|
||||
4. Implementation: Review
|
||||
5. Implementation: Add Document
|
||||
6. Implementation: Delete Document
|
||||
5. ~~Implementation~~: Add Document (v0.5.0)
|
||||
6. ~~Implementation~~: Delete Document (v0.5.0)
|
||||
7. Implementation: Self-training
|
||||
8. Implementation: DebugError
|
||||
8. ~~Implementation: DebugError~~ (v0.2.1)
|
||||
9. Implementation: Generate reliable unit tests based on YAPI
|
||||
10. Implementation: Self-evaluation
|
||||
11. Implementation: AI Invocation
|
||||
12. Implementation: Learning and using third-party standard libraries
|
||||
13. Implementation: Data collection
|
||||
14. Implementation: AI training
|
||||
15. Implementation: Run code
|
||||
16. Implementation: Web access
|
||||
15. ~~Implementation: Run code~~ (v0.2.1)
|
||||
16. ~~Implementation: Web access~~ (v0.2.1)
|
||||
5. Plugins: Compatibility with plugin system
|
||||
6. Tools
|
||||
1. ~~Support SERPER api~~
|
||||
|
|
@ -64,13 +66,13 @@ ### Tasks
|
|||
1. Perfect the action pool/skill pool for each role
|
||||
2. Red Book blogger
|
||||
3. E-commerce seller
|
||||
4. Data analyst
|
||||
4. Data analyst (expected v0.6.0)
|
||||
5. News observer
|
||||
6. Institutional researcher
|
||||
6. ~~Institutional researcher~~ (v0.2.1)
|
||||
8. Evaluation
|
||||
1. Support an evaluation on a game dataset
|
||||
2. Reproduce papers, implement full skill acquisition for a single game role, achieving SOTA results
|
||||
3. Support an evaluation on a math dataset
|
||||
1. Support an evaluation on a game dataset (experimentation done with game agents)
|
||||
2. Reproduce papers, implement full skill acquisition for a single game role, achieving SOTA results (experimentation done with game agents)
|
||||
3. Support an evaluation on a math dataset (expected v0.6.0)
|
||||
4. Reproduce papers, achieving SOTA results for current mathematical problem solving process
|
||||
9. LLM
|
||||
1. Support Claude underlying API
|
||||
|
|
|
|||
|
|
@ -15,7 +15,7 @@ # 第 1 步:确保您的系统上安装了 NPM。并使用npm安装mermaid-js
|
|||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
|
||||
# 第 2 步:确保您的系统上安装了 Python 3.9+。您可以使用以下命令进行检查:
|
||||
python --version
|
||||
python3 --version
|
||||
|
||||
# 第 3 步:克隆仓库到您的本地机器,并进行安装。
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
|
|
|
|||
|
|
@ -15,7 +15,7 @@ # Step 2: Run metagpt demo with container
|
|||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
python3 startup.py "Write a cli snake game"
|
||||
metagpt "Write a cli snake game"
|
||||
|
||||
# You can also start a container and execute commands in it
|
||||
docker run --name metagpt -d \
|
||||
|
|
@ -25,7 +25,7 @@ # You can also start a container and execute commands in it
|
|||
metagpt/metagpt:latest
|
||||
|
||||
docker exec -it metagpt /bin/bash
|
||||
$ python3 startup.py "Write a cli snake game"
|
||||
$ metagpt "Write a cli snake game"
|
||||
```
|
||||
|
||||
The command `docker run ...` do the following things:
|
||||
|
|
@ -33,7 +33,7 @@ # You can also start a container and execute commands in it
|
|||
- Run in privileged mode to have permission to run the browser
|
||||
- Map host configure file `/opt/metagpt/config/key.yaml` to container `/app/metagpt/config/key.yaml`
|
||||
- Map host directory `/opt/metagpt/workspace` to container `/app/metagpt/workspace`
|
||||
- Execute the demo command `python3 startup.py "Write a cli snake game"`
|
||||
- Execute the demo command `metagpt "Write a cli snake game"`
|
||||
|
||||
### Build image by yourself
|
||||
|
||||
|
|
|
|||
|
|
@ -15,7 +15,7 @@ # 步骤2: 使用容器运行metagpt演示
|
|||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
python startup.py "Write a cli snake game"
|
||||
metagpt "Write a cli snake game"
|
||||
|
||||
# 您也可以启动一个容器并在其中执行命令
|
||||
docker run --name metagpt -d \
|
||||
|
|
@ -25,7 +25,7 @@ # 您也可以启动一个容器并在其中执行命令
|
|||
metagpt/metagpt:latest
|
||||
|
||||
docker exec -it metagpt /bin/bash
|
||||
$ python startup.py "Write a cli snake game"
|
||||
$ metagpt "Write a cli snake game"
|
||||
```
|
||||
|
||||
`docker run ...`做了以下事情:
|
||||
|
|
@ -33,7 +33,7 @@ # 您也可以启动一个容器并在其中执行命令
|
|||
- 以特权模式运行,有权限运行浏览器
|
||||
- 将主机文件 `/opt/metagpt/config/key.yaml` 映射到容器文件 `/app/metagpt/config/key.yaml`
|
||||
- 将主机目录 `/opt/metagpt/workspace` 映射到容器目录 `/app/metagpt/workspace`
|
||||
- 执行示例命令 `python startup.py "Write a cli snake game"`
|
||||
- 执行示例命令 `metagpt "Write a cli snake game"`
|
||||
|
||||
### 自己构建镜像
|
||||
|
||||
|
|
|
|||
|
|
@ -19,11 +19,11 @@ ### Initiating a startup
|
|||
|
||||
```shell
|
||||
# Run the script
|
||||
python startup.py "Write a cli snake game"
|
||||
metagpt "Write a cli snake game"
|
||||
# Do not hire an engineer to implement the project
|
||||
python startup.py "Write a cli snake game" --implement False
|
||||
metagpt "Write a cli snake game" --no-implement
|
||||
# Hire an engineer and perform code reviews
|
||||
python startup.py "Write a cli snake game" --code_review True
|
||||
metagpt "Write a cli snake game" --code_review
|
||||
```
|
||||
|
||||
After running the script, you can find your new project in the `workspace/` directory.
|
||||
|
|
@ -33,17 +33,17 @@ ### Preference of Platform or Tool
|
|||
You can tell which platform or tool you want to use when stating your requirements.
|
||||
|
||||
```shell
|
||||
python startup.py "Write a cli snake game based on pygame"
|
||||
metagpt "Write a cli snake game based on pygame"
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
```
|
||||
NAME
|
||||
startup.py - We are a software startup comprised of AI. By investing in us, you are empowering a future filled with limitless possibilities.
|
||||
metagpt - We are a software startup comprised of AI. By investing in us, you are empowering a future filled with limitless possibilities.
|
||||
|
||||
SYNOPSIS
|
||||
startup.py IDEA <flags>
|
||||
metagpt IDEA <flags>
|
||||
|
||||
DESCRIPTION
|
||||
We are a software startup comprised of AI. By investing in us, you are empowering a future filled with limitless possibilities.
|
||||
|
|
|
|||
|
|
@ -18,9 +18,9 @@ # 复制配置文件并进行必要的修改
|
|||
### 示例:启动一个创业公司
|
||||
|
||||
```shell
|
||||
python startup.py "写一个命令行贪吃蛇"
|
||||
metagpt "写一个命令行贪吃蛇"
|
||||
# 开启code review模式会花费更多的金钱, 但是会提升代码质量和成功率
|
||||
python startup.py "写一个命令行贪吃蛇" --code_review True
|
||||
metagpt "写一个命令行贪吃蛇" --code_review
|
||||
```
|
||||
|
||||
运行脚本后,您可以在 `workspace/` 目录中找到您的新项目。
|
||||
|
|
@ -29,17 +29,17 @@ ### 平台或工具的倾向性
|
|||
可以在阐述需求时说明想要使用的平台或工具。
|
||||
例如:
|
||||
```shell
|
||||
python startup.py "写一个基于pygame的命令行贪吃蛇"
|
||||
metagpt "写一个基于pygame的命令行贪吃蛇"
|
||||
```
|
||||
|
||||
### 使用
|
||||
|
||||
```
|
||||
名称
|
||||
startup.py - 我们是一家AI软件创业公司。通过投资我们,您将赋能一个充满无限可能的未来。
|
||||
metagpt - 我们是一家AI软件创业公司。通过投资我们,您将赋能一个充满无限可能的未来。
|
||||
|
||||
概要
|
||||
startup.py IDEA <flags>
|
||||
metagpt IDEA <flags>
|
||||
|
||||
描述
|
||||
我们是一家AI软件创业公司。通过投资我们,您将赋能一个充满无限可能的未来。
|
||||
|
|
|
|||
|
|
@ -1,22 +1,22 @@
|
|||
'''
|
||||
"""
|
||||
Filename: MetaGPT/examples/agent_creator.py
|
||||
Created Date: Tuesday, September 12th 2023, 3:28:37 pm
|
||||
Author: garylin2099
|
||||
'''
|
||||
"""
|
||||
import re
|
||||
|
||||
from metagpt.const import PROJECT_ROOT, WORKSPACE_ROOT
|
||||
from metagpt.actions import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import METAGPT_ROOT
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles import Role
|
||||
from metagpt.schema import Message
|
||||
from metagpt.logs import logger
|
||||
|
||||
with open(PROJECT_ROOT / "examples/build_customized_agent.py", "r") as f:
|
||||
# use official example script to guide AgentCreator
|
||||
MULTI_ACTION_AGENT_CODE_EXAMPLE = f.read()
|
||||
EXAMPLE_CODE_FILE = METAGPT_ROOT / "examples/build_customized_agent.py"
|
||||
MULTI_ACTION_AGENT_CODE_EXAMPLE = EXAMPLE_CODE_FILE.read_text()
|
||||
|
||||
|
||||
class CreateAgent(Action):
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
### BACKGROUND
|
||||
You are using an agent framework called metagpt to write agents capable of different actions,
|
||||
|
|
@ -34,7 +34,6 @@ class CreateAgent(Action):
|
|||
"""
|
||||
|
||||
async def run(self, example: str, instruction: str):
|
||||
|
||||
prompt = self.PROMPT_TEMPLATE.format(example=example, instruction=instruction)
|
||||
# logger.info(prompt)
|
||||
|
||||
|
|
@ -46,13 +45,15 @@ class CreateAgent(Action):
|
|||
|
||||
@staticmethod
|
||||
def parse_code(rsp):
|
||||
pattern = r'```python(.*)```'
|
||||
pattern = r"```python(.*)```"
|
||||
match = re.search(pattern, rsp, re.DOTALL)
|
||||
code_text = match.group(1) if match else ""
|
||||
with open(WORKSPACE_ROOT / "agent_created_agent.py", "w") as f:
|
||||
f.write(code_text)
|
||||
CONFIG.workspace_path.mkdir(parents=True, exist_ok=True)
|
||||
new_file = CONFIG.workspace_path / "agent_created_agent.py"
|
||||
new_file.write_text(code_text)
|
||||
return code_text
|
||||
|
||||
|
||||
class AgentCreator(Role):
|
||||
def __init__(
|
||||
self,
|
||||
|
|
@ -76,11 +77,11 @@ class AgentCreator(Role):
|
|||
|
||||
return msg
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import asyncio
|
||||
|
||||
async def main():
|
||||
|
||||
agent_template = MULTI_ACTION_AGENT_CODE_EXAMPLE
|
||||
|
||||
creator = AgentCreator(agent_template=agent_template)
|
||||
|
|
|
|||
|
|
@ -1,22 +1,22 @@
|
|||
'''
|
||||
"""
|
||||
Filename: MetaGPT/examples/build_customized_agent.py
|
||||
Created Date: Tuesday, September 19th 2023, 6:52:25 pm
|
||||
Author: garylin2099
|
||||
'''
|
||||
"""
|
||||
import asyncio
|
||||
import re
|
||||
import subprocess
|
||||
import asyncio
|
||||
|
||||
import fire
|
||||
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.actions import Action
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles import Role
|
||||
from metagpt.schema import Message
|
||||
from metagpt.logs import logger
|
||||
|
||||
|
||||
class SimpleWriteCode(Action):
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
Write a python function that can {instruction} and provide two runnnable test cases.
|
||||
Return ```python your_code_here ``` with NO other texts,
|
||||
|
|
@ -27,7 +27,6 @@ class SimpleWriteCode(Action):
|
|||
super().__init__(name, context, llm)
|
||||
|
||||
async def run(self, instruction: str):
|
||||
|
||||
prompt = self.PROMPT_TEMPLATE.format(instruction=instruction)
|
||||
|
||||
rsp = await self._aask(prompt)
|
||||
|
|
@ -38,7 +37,7 @@ class SimpleWriteCode(Action):
|
|||
|
||||
@staticmethod
|
||||
def parse_code(rsp):
|
||||
pattern = r'```python(.*)```'
|
||||
pattern = r"```python(.*)```"
|
||||
match = re.search(pattern, rsp, re.DOTALL)
|
||||
code_text = match.group(1) if match else rsp
|
||||
return code_text
|
||||
|
|
@ -67,10 +66,9 @@ class SimpleCoder(Role):
|
|||
|
||||
async def _act(self) -> Message:
|
||||
logger.info(f"{self._setting}: ready to {self._rc.todo}")
|
||||
todo = self._rc.todo # todo will be SimpleWriteCode()
|
||||
|
||||
msg = self.get_memories(k=1)[0] # find the most recent messages
|
||||
todo = self._rc.todo # todo will be SimpleWriteCode()
|
||||
|
||||
msg = self.get_memories(k=1)[0] # find the most recent messages
|
||||
code_text = await todo.run(msg.content)
|
||||
msg = Message(content=code_text, role=self.profile, cause_by=type(todo))
|
||||
|
||||
|
|
@ -94,7 +92,7 @@ class RunnableCoder(Role):
|
|||
# todo will be first SimpleWriteCode() then SimpleRunCode()
|
||||
todo = self._rc.todo
|
||||
|
||||
msg = self.get_memories(k=1)[0] # find the most k recent messages
|
||||
msg = self.get_memories(k=1)[0] # find the most k recent messages
|
||||
result = await todo.run(msg.content)
|
||||
|
||||
msg = Message(content=result, role=self.profile, cause_by=type(todo))
|
||||
|
|
@ -109,5 +107,6 @@ def main(msg="write a function that calculates the product of a list and run it"
|
|||
result = asyncio.run(role.run(msg))
|
||||
logger.info(result)
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
if __name__ == "__main__":
|
||||
fire.Fire(main)
|
||||
|
|
|
|||
|
|
@ -1,27 +1,28 @@
|
|||
'''
|
||||
"""
|
||||
Filename: MetaGPT/examples/build_customized_multi_agents.py
|
||||
Created Date: Wednesday, November 15th 2023, 7:12:39 pm
|
||||
Author: garylin2099
|
||||
'''
|
||||
"""
|
||||
import re
|
||||
import asyncio
|
||||
|
||||
import fire
|
||||
|
||||
from metagpt.actions import Action, UserRequirement
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.actions import Action, BossRequirement
|
||||
from metagpt.roles import Role
|
||||
from metagpt.team import Team
|
||||
from metagpt.schema import Message
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles import Role
|
||||
from metagpt.schema import Message
|
||||
from metagpt.team import Team
|
||||
|
||||
|
||||
def parse_code(rsp):
|
||||
pattern = r'```python(.*)```'
|
||||
pattern = r"```python(.*)```"
|
||||
match = re.search(pattern, rsp, re.DOTALL)
|
||||
code_text = match.group(1) if match else rsp
|
||||
return code_text
|
||||
|
||||
class SimpleWriteCode(Action):
|
||||
|
||||
class SimpleWriteCode(Action):
|
||||
PROMPT_TEMPLATE = """
|
||||
Write a python function that can {instruction}.
|
||||
Return ```python your_code_here ``` with NO other texts,
|
||||
|
|
@ -32,7 +33,6 @@ class SimpleWriteCode(Action):
|
|||
super().__init__(name, context, llm)
|
||||
|
||||
async def run(self, instruction: str):
|
||||
|
||||
prompt = self.PROMPT_TEMPLATE.format(instruction=instruction)
|
||||
|
||||
rsp = await self._aask(prompt)
|
||||
|
|
@ -50,12 +50,11 @@ class SimpleCoder(Role):
|
|||
**kwargs,
|
||||
):
|
||||
super().__init__(name, profile, **kwargs)
|
||||
self._watch([BossRequirement])
|
||||
self._watch([UserRequirement])
|
||||
self._init_actions([SimpleWriteCode])
|
||||
|
||||
|
||||
class SimpleWriteTest(Action):
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
Context: {context}
|
||||
Write {k} unit tests using pytest for the given function, assuming you have imported it.
|
||||
|
|
@ -67,7 +66,6 @@ class SimpleWriteTest(Action):
|
|||
super().__init__(name, context, llm)
|
||||
|
||||
async def run(self, context: str, k: int = 3):
|
||||
|
||||
prompt = self.PROMPT_TEMPLATE.format(context=context, k=k)
|
||||
|
||||
rsp = await self._aask(prompt)
|
||||
|
|
@ -87,23 +85,22 @@ class SimpleTester(Role):
|
|||
super().__init__(name, profile, **kwargs)
|
||||
self._init_actions([SimpleWriteTest])
|
||||
# self._watch([SimpleWriteCode])
|
||||
self._watch([SimpleWriteCode, SimpleWriteReview]) # feel free to try this too
|
||||
self._watch([SimpleWriteCode, SimpleWriteReview]) # feel free to try this too
|
||||
|
||||
async def _act(self) -> Message:
|
||||
logger.info(f"{self._setting}: ready to {self._rc.todo}")
|
||||
todo = self._rc.todo
|
||||
|
||||
# context = self.get_memories(k=1)[0].content # use the most recent memory as context
|
||||
context = self.get_memories() # use all memories as context
|
||||
context = self.get_memories() # use all memories as context
|
||||
|
||||
code_text = await todo.run(context, k=5) # specify arguments
|
||||
code_text = await todo.run(context, k=5) # specify arguments
|
||||
msg = Message(content=code_text, role=self.profile, cause_by=type(todo))
|
||||
|
||||
return msg
|
||||
|
||||
|
||||
class SimpleWriteReview(Action):
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
Context: {context}
|
||||
Review the test cases and provide one critical comments:
|
||||
|
|
@ -113,7 +110,6 @@ class SimpleWriteReview(Action):
|
|||
super().__init__(name, context, llm)
|
||||
|
||||
async def run(self, context: str):
|
||||
|
||||
prompt = self.PROMPT_TEMPLATE.format(context=context)
|
||||
|
||||
rsp = await self._aask(prompt)
|
||||
|
|
@ -154,5 +150,6 @@ async def main(
|
|||
team.start_project(idea)
|
||||
await team.run(n_round=n_round)
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
if __name__ == "__main__":
|
||||
fire.Fire(main)
|
||||
|
|
|
|||
|
|
@ -1,17 +1,21 @@
|
|||
'''
|
||||
"""
|
||||
Filename: MetaGPT/examples/debate.py
|
||||
Created Date: Tuesday, September 19th 2023, 6:52:25 pm
|
||||
Author: garylin2099
|
||||
'''
|
||||
@Modified By: mashenquan, 2023-11-1. In accordance with Chapter 2.1.3 of RFC 116, modify the data type of the `send_to`
|
||||
value of the `Message` object; modify the argument type of `get_by_actions`.
|
||||
"""
|
||||
import asyncio
|
||||
import platform
|
||||
|
||||
import fire
|
||||
|
||||
from metagpt.team import Team
|
||||
from metagpt.actions import Action, BossRequirement
|
||||
from metagpt.actions import Action, UserRequirement
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles import Role
|
||||
from metagpt.schema import Message
|
||||
from metagpt.logs import logger
|
||||
from metagpt.team import Team
|
||||
|
||||
|
||||
class SpeakAloud(Action):
|
||||
"""Action: Speak out aloud in a debate (quarrel)"""
|
||||
|
|
@ -31,7 +35,6 @@ class SpeakAloud(Action):
|
|||
super().__init__(name, context, llm)
|
||||
|
||||
async def run(self, context: str, name: str, opponent_name: str):
|
||||
|
||||
prompt = self.PROMPT_TEMPLATE.format(context=context, name=name, opponent_name=opponent_name)
|
||||
# logger.info(prompt)
|
||||
|
||||
|
|
@ -39,6 +42,7 @@ class SpeakAloud(Action):
|
|||
|
||||
return rsp
|
||||
|
||||
|
||||
class Debator(Role):
|
||||
def __init__(
|
||||
self,
|
||||
|
|
@ -49,19 +53,18 @@ class Debator(Role):
|
|||
):
|
||||
super().__init__(name, profile, **kwargs)
|
||||
self._init_actions([SpeakAloud])
|
||||
self._watch([BossRequirement, SpeakAloud])
|
||||
self.name = name
|
||||
self._watch([UserRequirement, SpeakAloud])
|
||||
self.opponent_name = opponent_name
|
||||
|
||||
async def _observe(self) -> int:
|
||||
await super()._observe()
|
||||
# accept messages sent (from opponent) to self, disregard own messages from the last round
|
||||
self._rc.news = [msg for msg in self._rc.news if msg.send_to == self.name]
|
||||
self._rc.news = [msg for msg in self._rc.news if msg.send_to == {self.name}]
|
||||
return len(self._rc.news)
|
||||
|
||||
async def _act(self) -> Message:
|
||||
logger.info(f"{self._setting}: ready to {self._rc.todo}")
|
||||
todo = self._rc.todo # An instance of SpeakAloud
|
||||
todo = self._rc.todo # An instance of SpeakAloud
|
||||
|
||||
memories = self.get_memories()
|
||||
context = "\n".join(f"{msg.sent_from}: {msg.content}" for msg in memories)
|
||||
|
|
@ -76,25 +79,25 @@ class Debator(Role):
|
|||
sent_from=self.name,
|
||||
send_to=self.opponent_name,
|
||||
)
|
||||
|
||||
self._rc.memory.add(msg)
|
||||
|
||||
return msg
|
||||
|
||||
|
||||
async def debate(idea: str, investment: float = 3.0, n_round: int = 5):
|
||||
"""Run a team of presidents and watch they quarrel. :) """
|
||||
"""Run a team of presidents and watch they quarrel. :)"""
|
||||
Biden = Debator(name="Biden", profile="Democrat", opponent_name="Trump")
|
||||
Trump = Debator(name="Trump", profile="Republican", opponent_name="Biden")
|
||||
team = Team()
|
||||
team.hire([Biden, Trump])
|
||||
team.invest(investment)
|
||||
team.start_project(idea, send_to="Biden") # send debate topic to Biden and let him speak first
|
||||
team.run_project(idea, send_to="Biden") # send debate topic to Biden and let him speak first
|
||||
await team.run(n_round=n_round)
|
||||
|
||||
|
||||
def main(idea: str, investment: float = 3.0, n_round: int = 10):
|
||||
"""
|
||||
:param idea: Debate topic, such as "Topic: The U.S. should commit more in climate change fighting"
|
||||
:param idea: Debate topic, such as "Topic: The U.S. should commit more in climate change fighting"
|
||||
or "Trump: Climate change is a hoax"
|
||||
:param investment: contribute a certain dollar amount to watch the debate
|
||||
:param n_round: maximum rounds of the debate
|
||||
|
|
@ -105,5 +108,5 @@ def main(idea: str, investment: float = 3.0, n_round: int = 10):
|
|||
asyncio.run(debate(idea, investment, n_round))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
fire.Fire(main)
|
||||
|
|
|
|||
|
|
@ -19,19 +19,15 @@ async def main():
|
|||
Path("../tests/data/invoices/invoice-1.pdf"),
|
||||
Path("../tests/data/invoices/invoice-2.png"),
|
||||
Path("../tests/data/invoices/invoice-3.jpg"),
|
||||
Path("../tests/data/invoices/invoice-4.zip")
|
||||
Path("../tests/data/invoices/invoice-4.zip"),
|
||||
]
|
||||
# The absolute path of the file
|
||||
absolute_file_paths = [Path.cwd() / path for path in relative_paths]
|
||||
|
||||
for path in absolute_file_paths:
|
||||
role = InvoiceOCRAssistant()
|
||||
await role.run(Message(
|
||||
content="Invoicing date",
|
||||
instruct_content={"file_path": path}
|
||||
))
|
||||
await role.run(Message(content="Invoicing date", instruct_content={"file_path": path}))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
|
||||
|
|
|
|||
|
|
@ -14,11 +14,11 @@ from metagpt.logs import logger
|
|||
async def main():
|
||||
llm = LLM()
|
||||
claude = Claude()
|
||||
logger.info(await claude.aask('你好,请进行自我介绍'))
|
||||
logger.info(await llm.aask('hello world'))
|
||||
logger.info(await llm.aask_batch(['hi', 'write python hello world.']))
|
||||
logger.info(await claude.aask("你好,请进行自我介绍"))
|
||||
logger.info(await llm.aask("hello world"))
|
||||
logger.info(await llm.aask_batch(["hi", "write python hello world."]))
|
||||
|
||||
hello_msg = [{'role': 'user', 'content': 'count from 1 to 10. split by newline.'}]
|
||||
hello_msg = [{"role": "user", "content": "count from 1 to 10. split by newline."}]
|
||||
logger.info(await llm.acompletion(hello_msg))
|
||||
logger.info(await llm.acompletion_batch([hello_msg]))
|
||||
logger.info(await llm.acompletion_batch_text([hello_msg]))
|
||||
|
|
@ -27,5 +27,5 @@ async def main():
|
|||
await llm.acompletion_text(hello_msg, stream=True)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
|
|
|
|||
|
|
@ -12,5 +12,5 @@ async def main():
|
|||
print(f"save report to {RESEARCH_PATH / f'{topic}.md'}.")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
|
|
|
|||
|
|
@ -15,5 +15,5 @@ async def main():
|
|||
await Searcher().run("What are some good sun protection products?")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
|
|
|
|||
|
|
@ -5,22 +5,40 @@
|
|||
"""
|
||||
import asyncio
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.const import DATA_PATH
|
||||
from metagpt.document_store import FaissStore
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles import Sales
|
||||
from metagpt.schema import Message
|
||||
|
||||
""" example.json, e.g.
|
||||
[
|
||||
{
|
||||
"source": "Which facial cleanser is good for oily skin?",
|
||||
"output": "ABC cleanser is preferred by many with oily skin."
|
||||
},
|
||||
{
|
||||
"source": "Is L'Oreal good to use?",
|
||||
"output": "L'Oreal is a popular brand with many positive reviews."
|
||||
}
|
||||
]
|
||||
"""
|
||||
|
||||
|
||||
async def search():
|
||||
store = FaissStore(DATA_PATH / 'example.json')
|
||||
store = FaissStore(DATA_PATH / "example.json")
|
||||
role = Sales(profile="Sales", store=store)
|
||||
|
||||
queries = ["Which facial cleanser is good for oily skin?", "Is L'Oreal good to use?"]
|
||||
role._watch({Action})
|
||||
queries = [
|
||||
Message("Which facial cleanser is good for oily skin?", cause_by=Action),
|
||||
Message("Is L'Oreal good to use?", cause_by=Action),
|
||||
]
|
||||
for query in queries:
|
||||
logger.info(f"User: {query}")
|
||||
result = await role.run(query)
|
||||
logger.info(result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(search())
|
||||
|
|
|
|||
|
|
@ -6,11 +6,12 @@ from metagpt.tools import SearchEngineType
|
|||
|
||||
async def main():
|
||||
# Serper API
|
||||
#await Searcher(engine = SearchEngineType.SERPER_GOOGLE).run(["What are some good sun protection products?","What are some of the best beaches?"])
|
||||
# await Searcher(engine = SearchEngineType.SERPER_GOOGLE).run(["What are some good sun protection products?","What are some of the best beaches?"])
|
||||
# SerpAPI
|
||||
#await Searcher(engine=SearchEngineType.SERPAPI_GOOGLE).run("What are the best ski brands for skiers?")
|
||||
# await Searcher(engine=SearchEngineType.SERPAPI_GOOGLE).run("What are the best ski brands for skiers?")
|
||||
# Google API
|
||||
await Searcher(engine=SearchEngineType.DIRECT_GOOGLE).run("What are the most interesting human facts?")
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ from semantic_kernel.planning import SequentialPlanner
|
|||
# from semantic_kernel.planning import SequentialPlanner
|
||||
from semantic_kernel.planning.action_planner.action_planner import ActionPlanner
|
||||
|
||||
from metagpt.actions import BossRequirement
|
||||
from metagpt.actions import UserRequirement
|
||||
from metagpt.const import SKILL_DIRECTORY
|
||||
from metagpt.roles.sk_agent import SkAgent
|
||||
from metagpt.schema import Message
|
||||
|
|
@ -39,7 +39,7 @@ async def basic_planner_example():
|
|||
role.import_semantic_skill_from_directory(SKILL_DIRECTORY, "WriterSkill")
|
||||
role.import_skill(TextSkill(), "TextSkill")
|
||||
# using BasicPlanner
|
||||
await role.run(Message(content=task, cause_by=BossRequirement))
|
||||
await role.run(Message(content=task, cause_by=UserRequirement))
|
||||
|
||||
|
||||
async def sequential_planner_example():
|
||||
|
|
@ -53,7 +53,7 @@ async def sequential_planner_example():
|
|||
role.import_semantic_skill_from_directory(SKILL_DIRECTORY, "WriterSkill")
|
||||
role.import_skill(TextSkill(), "TextSkill")
|
||||
# using BasicPlanner
|
||||
await role.run(Message(content=task, cause_by=BossRequirement))
|
||||
await role.run(Message(content=task, cause_by=UserRequirement))
|
||||
|
||||
|
||||
async def basic_planner_web_search_example():
|
||||
|
|
@ -64,7 +64,7 @@ async def basic_planner_web_search_example():
|
|||
role.import_skill(SkSearchEngine(), "WebSearchSkill")
|
||||
# role.import_semantic_skill_from_directory(skills_directory, "QASkill")
|
||||
|
||||
await role.run(Message(content=task, cause_by=BossRequirement))
|
||||
await role.run(Message(content=task, cause_by=UserRequirement))
|
||||
|
||||
|
||||
async def action_planner_example():
|
||||
|
|
@ -75,7 +75,7 @@ async def action_planner_example():
|
|||
role.import_skill(TimeSkill(), "time")
|
||||
role.import_skill(TextSkill(), "text")
|
||||
task = "What is the sum of 110 and 990?"
|
||||
await role.run(Message(content=task, cause_by=BossRequirement)) # it will choose mathskill.Add
|
||||
await role.run(Message(content=task, cause_by=UserRequirement)) # it will choose mathskill.Add
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
|
|
|||
|
|
@ -1,12 +1,13 @@
|
|||
'''
|
||||
"""
|
||||
Filename: MetaGPT/examples/use_off_the_shelf_agent.py
|
||||
Created Date: Tuesday, September 19th 2023, 6:52:25 pm
|
||||
Author: garylin2099
|
||||
'''
|
||||
"""
|
||||
import asyncio
|
||||
|
||||
from metagpt.roles.product_manager import ProductManager
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles.product_manager import ProductManager
|
||||
|
||||
|
||||
async def main():
|
||||
msg = "Write a PRD for a snake game"
|
||||
|
|
@ -14,5 +15,6 @@ async def main():
|
|||
result = await role.run(msg)
|
||||
logger.info(result.content[:100])
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
|
|
|
|||
|
|
@ -1,10 +1,12 @@
|
|||
#!/usr/bin/env python3
|
||||
# _*_ coding: utf-8 _*_
|
||||
|
||||
"""
|
||||
@Time : 2023/9/4 21:40:57
|
||||
@Author : Stitch-z
|
||||
@File : tutorial_assistant.py
|
||||
"""
|
||||
|
||||
import asyncio
|
||||
|
||||
from metagpt.roles.tutorial_assistant import TutorialAssistant
|
||||
|
|
@ -16,6 +18,5 @@ async def main():
|
|||
await role.run(topic)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
|
||||
|
|
|
|||
|
|
@ -9,11 +9,10 @@ from enum import Enum
|
|||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.actions.action_output import ActionOutput
|
||||
from metagpt.actions.add_requirement import BossRequirement
|
||||
from metagpt.actions.add_requirement import UserRequirement
|
||||
from metagpt.actions.debug_error import DebugError
|
||||
from metagpt.actions.design_api import WriteDesign
|
||||
from metagpt.actions.design_api_review import DesignReview
|
||||
from metagpt.actions.design_filenames import DesignFilenames
|
||||
from metagpt.actions.project_management import AssignTasks, WriteTasks
|
||||
from metagpt.actions.research import CollectLinks, WebBrowseAndSummarize, ConductResearch
|
||||
from metagpt.actions.run_code import RunCode
|
||||
|
|
@ -28,12 +27,11 @@ from metagpt.actions.write_test import WriteTest
|
|||
class ActionType(Enum):
|
||||
"""All types of Actions, used for indexing."""
|
||||
|
||||
ADD_REQUIREMENT = BossRequirement
|
||||
ADD_REQUIREMENT = UserRequirement
|
||||
WRITE_PRD = WritePRD
|
||||
WRITE_PRD_REVIEW = WritePRDReview
|
||||
WRITE_DESIGN = WriteDesign
|
||||
DESIGN_REVIEW = DesignReview
|
||||
DESIGN_FILENAMES = DesignFilenames
|
||||
WRTIE_CODE = WriteCode
|
||||
WRITE_CODE_REVIEW = WriteCodeReview
|
||||
WRITE_TEST = WriteTest
|
||||
|
|
|
|||
|
|
@ -5,36 +5,60 @@
|
|||
@Author : alexanderwu
|
||||
@File : action.py
|
||||
"""
|
||||
import re
|
||||
from abc import ABC
|
||||
from typing import Optional
|
||||
|
||||
from tenacity import retry, stop_after_attempt, wait_fixed
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Any, Optional, Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from metagpt.actions.action_output import ActionOutput
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.utils.common import OutputParser
|
||||
from metagpt.utils.custom_decoder import CustomDecoder
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.schema import (
|
||||
CodeSummarizeContext,
|
||||
CodingContext,
|
||||
RunCodeContext,
|
||||
TestingContext,
|
||||
)
|
||||
|
||||
action_subclass_registry = {}
|
||||
|
||||
|
||||
class Action(ABC):
|
||||
def __init__(self, name: str = "", context=None, llm: LLM = None):
|
||||
self.name: str = name
|
||||
if llm is None:
|
||||
llm = LLM()
|
||||
self.llm = llm
|
||||
self.context = context
|
||||
self.prefix = ""
|
||||
self.profile = ""
|
||||
self.desc = ""
|
||||
self.content = ""
|
||||
self.instruct_content = None
|
||||
class Action(BaseModel):
|
||||
name: str = ""
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM, exclude=True)
|
||||
context: Union[dict, CodingContext, CodeSummarizeContext, TestingContext, RunCodeContext, str, None] = ""
|
||||
prefix = "" # aask*时会加上prefix,作为system_message
|
||||
desc = "" # for skill manager
|
||||
# node: ActionNode = Field(default_factory=ActionNode, exclude=True)
|
||||
|
||||
def set_prefix(self, prefix, profile):
|
||||
# builtin variables
|
||||
builtin_class_name: str = ""
|
||||
|
||||
class Config:
|
||||
arbitrary_types_allowed = True
|
||||
|
||||
def __init__(self, **kwargs: Any):
|
||||
super().__init__(**kwargs)
|
||||
|
||||
# deserialize child classes dynamically for inherited `action`
|
||||
object.__setattr__(self, "builtin_class_name", self.__class__.__name__)
|
||||
self.__fields__["builtin_class_name"].default = self.__class__.__name__
|
||||
|
||||
def __init_subclass__(cls, **kwargs: Any) -> None:
|
||||
super().__init_subclass__(**kwargs)
|
||||
action_subclass_registry[cls.__name__] = cls
|
||||
|
||||
def dict(self, *args, **kwargs) -> "DictStrAny":
|
||||
obj_dict = super(Action, self).dict(*args, **kwargs)
|
||||
if "llm" in obj_dict:
|
||||
obj_dict.pop("llm")
|
||||
return obj_dict
|
||||
|
||||
def set_prefix(self, prefix):
|
||||
"""Set prefix for later usage"""
|
||||
self.prefix = prefix
|
||||
self.profile = profile
|
||||
return self
|
||||
|
||||
def __str__(self):
|
||||
return self.__class__.__name__
|
||||
|
|
@ -49,41 +73,6 @@ class Action(ABC):
|
|||
system_msgs.append(self.prefix)
|
||||
return await self.llm.aask(prompt, system_msgs)
|
||||
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_fixed(1))
|
||||
async def _aask_v1(
|
||||
self,
|
||||
prompt: str,
|
||||
output_class_name: str,
|
||||
output_data_mapping: dict,
|
||||
system_msgs: Optional[list[str]] = None,
|
||||
format="markdown", # compatible to original format
|
||||
) -> ActionOutput:
|
||||
"""Append default prefix"""
|
||||
if not system_msgs:
|
||||
system_msgs = []
|
||||
system_msgs.append(self.prefix)
|
||||
content = await self.llm.aask(prompt, system_msgs)
|
||||
logger.debug(content)
|
||||
output_class = ActionOutput.create_model_class(output_class_name, output_data_mapping)
|
||||
|
||||
if format == "json":
|
||||
pattern = r"\[CONTENT\](\s*\{.*?\}\s*)\[/CONTENT\]"
|
||||
matches = re.findall(pattern, content, re.DOTALL)
|
||||
|
||||
for match in matches:
|
||||
if match:
|
||||
content = match
|
||||
break
|
||||
|
||||
parsed_data = CustomDecoder(strict=False).decode(content)
|
||||
|
||||
else: # using markdown parser
|
||||
parsed_data = OutputParser.parse_data_with_mapping(content, output_data_mapping)
|
||||
|
||||
logger.debug(parsed_data)
|
||||
instruct_content = output_class(**parsed_data)
|
||||
return ActionOutput(content, instruct_content)
|
||||
|
||||
async def run(self, *args, **kwargs):
|
||||
"""Run action"""
|
||||
raise NotImplementedError("The run method should be implemented in a subclass.")
|
||||
|
|
|
|||
337
metagpt/actions/action_node.py
Normal file
337
metagpt/actions/action_node.py
Normal file
|
|
@ -0,0 +1,337 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/12/11 18:45
|
||||
@Author : alexanderwu
|
||||
@File : action_node.py
|
||||
|
||||
NOTE: You should use typing.List instead of list to do type annotation. Because in the markdown extraction process,
|
||||
we can use typing to extract the type of the node, but we cannot use built-in list to extract.
|
||||
"""
|
||||
import json
|
||||
from typing import Any, Dict, List, Optional, Tuple, Type
|
||||
|
||||
from pydantic import BaseModel, create_model, root_validator, validator
|
||||
from tenacity import retry, stop_after_attempt, wait_random_exponential
|
||||
|
||||
from metagpt.llm import BaseGPTAPI
|
||||
from metagpt.logs import logger
|
||||
from metagpt.provider.postprecess.llm_output_postprecess import llm_output_postprecess
|
||||
from metagpt.utils.common import OutputParser, general_after_log
|
||||
|
||||
TAG = "CONTENT"
|
||||
|
||||
LANGUAGE_CONSTRAINT = "Language: Please use the same language as the user input."
|
||||
FORMAT_CONSTRAINT = f"Format: output wrapped inside [{TAG}][/{TAG}] like format example, nothing else."
|
||||
|
||||
|
||||
SIMPLE_TEMPLATE = """
|
||||
## context
|
||||
{context}
|
||||
|
||||
-----
|
||||
|
||||
## format example
|
||||
{example}
|
||||
|
||||
## nodes: "<node>: <type> # <instruction>"
|
||||
{instruction}
|
||||
|
||||
## constraint
|
||||
{constraint}
|
||||
|
||||
## action
|
||||
Follow instructions of nodes, generate output and make sure it follows the format example.
|
||||
"""
|
||||
|
||||
|
||||
def dict_to_markdown(d, prefix="- ", kv_sep="\n", postfix="\n"):
|
||||
markdown_str = ""
|
||||
for key, value in d.items():
|
||||
markdown_str += f"{prefix}{key}{kv_sep}{value}{postfix}"
|
||||
return markdown_str
|
||||
|
||||
|
||||
class ActionNode:
|
||||
"""ActionNode is a tree of nodes."""
|
||||
|
||||
mode: str
|
||||
|
||||
# Action Context
|
||||
context: str # all the context, including all necessary info
|
||||
llm: BaseGPTAPI # LLM with aask interface
|
||||
children: dict[str, "ActionNode"]
|
||||
|
||||
# Action Input
|
||||
key: str # Product Requirement / File list / Code
|
||||
expected_type: Type # such as str / int / float etc.
|
||||
# context: str # everything in the history.
|
||||
instruction: str # the instructions should be followed.
|
||||
example: Any # example for In Context-Learning.
|
||||
|
||||
# Action Output
|
||||
content: str
|
||||
instruct_content: BaseModel
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
key: str,
|
||||
expected_type: Type,
|
||||
instruction: str,
|
||||
example: Any,
|
||||
content: str = "",
|
||||
children: dict[str, "ActionNode"] = None,
|
||||
):
|
||||
self.key = key
|
||||
self.expected_type = expected_type
|
||||
self.instruction = instruction
|
||||
self.example = example
|
||||
self.content = content
|
||||
self.children = children if children is not None else {}
|
||||
|
||||
def __str__(self):
|
||||
return (
|
||||
f"{self.key}, {self.expected_type}, {self.instruction}, {self.example}" f", {self.content}, {self.children}"
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
def add_child(self, node: "ActionNode"):
|
||||
"""增加子ActionNode"""
|
||||
self.children[node.key] = node
|
||||
|
||||
def add_children(self, nodes: List["ActionNode"]):
|
||||
"""批量增加子ActionNode"""
|
||||
for node in nodes:
|
||||
self.add_child(node)
|
||||
|
||||
@classmethod
|
||||
def from_children(cls, key, nodes: List["ActionNode"]):
|
||||
"""直接从一系列的子nodes初始化"""
|
||||
obj = cls(key, str, "", "")
|
||||
obj.add_children(nodes)
|
||||
return obj
|
||||
|
||||
def get_children_mapping(self) -> Dict[str, Tuple[Type, Any]]:
|
||||
"""获得子ActionNode的字典,以key索引"""
|
||||
return {k: (v.expected_type, ...) for k, v in self.children.items()}
|
||||
|
||||
def get_self_mapping(self) -> Dict[str, Tuple[Type, Any]]:
|
||||
"""get self key: type mapping"""
|
||||
return {self.key: (self.expected_type, ...)}
|
||||
|
||||
def get_mapping(self, mode="children") -> Dict[str, Tuple[Type, Any]]:
|
||||
"""get key: type mapping under mode"""
|
||||
if mode == "children" or (mode == "auto" and self.children):
|
||||
return self.get_children_mapping()
|
||||
return self.get_self_mapping()
|
||||
|
||||
@classmethod
|
||||
def create_model_class(cls, class_name: str, mapping: Dict[str, Tuple[Type, Any]]):
|
||||
"""基于pydantic v1的模型动态生成,用来检验结果类型正确性"""
|
||||
new_class = create_model(class_name, **mapping)
|
||||
|
||||
@validator("*", allow_reuse=True)
|
||||
def check_name(v, field):
|
||||
if field.name not in mapping.keys():
|
||||
raise ValueError(f"Unrecognized block: {field.name}")
|
||||
return v
|
||||
|
||||
@root_validator(pre=True, allow_reuse=True)
|
||||
def check_missing_fields(values):
|
||||
required_fields = set(mapping.keys())
|
||||
missing_fields = required_fields - set(values.keys())
|
||||
if missing_fields:
|
||||
raise ValueError(f"Missing fields: {missing_fields}")
|
||||
return values
|
||||
|
||||
new_class.__validator_check_name = classmethod(check_name)
|
||||
new_class.__root_validator_check_missing_fields = classmethod(check_missing_fields)
|
||||
return new_class
|
||||
|
||||
def create_children_class(self):
|
||||
"""使用object内有的字段直接生成model_class"""
|
||||
class_name = f"{self.key}_AN"
|
||||
mapping = self.get_children_mapping()
|
||||
return self.create_model_class(class_name, mapping)
|
||||
|
||||
def to_dict(self, format_func=None, mode="auto") -> Dict:
|
||||
"""将当前节点与子节点都按照node: format的格式组织成字典"""
|
||||
|
||||
# 如果没有提供格式化函数,使用默认的格式化方式
|
||||
if format_func is None:
|
||||
format_func = lambda node: f"{node.instruction}"
|
||||
|
||||
# 使用提供的格式化函数来格式化当前节点的值
|
||||
formatted_value = format_func(self)
|
||||
|
||||
# 创建当前节点的键值对
|
||||
if mode == "children" or (mode == "auto" and self.children):
|
||||
node_dict = {}
|
||||
else:
|
||||
node_dict = {self.key: formatted_value}
|
||||
|
||||
if mode == "root":
|
||||
return node_dict
|
||||
|
||||
# 遍历子节点并递归调用 to_dict 方法
|
||||
for _, child_node in self.children.items():
|
||||
node_dict.update(child_node.to_dict(format_func))
|
||||
|
||||
return node_dict
|
||||
|
||||
def compile_to(self, i: Dict, schema, kv_sep) -> str:
|
||||
if schema == "json":
|
||||
return json.dumps(i, indent=4)
|
||||
elif schema == "markdown":
|
||||
return dict_to_markdown(i, kv_sep=kv_sep)
|
||||
else:
|
||||
return str(i)
|
||||
|
||||
def tagging(self, text, schema, tag="") -> str:
|
||||
if not tag:
|
||||
return text
|
||||
if schema == "json":
|
||||
return f"[{tag}]\n" + text + f"\n[/{tag}]"
|
||||
else: # markdown
|
||||
return f"[{tag}]\n" + text + f"\n[/{tag}]"
|
||||
|
||||
def _compile_f(self, schema, mode, tag, format_func, kv_sep) -> str:
|
||||
nodes = self.to_dict(format_func=format_func, mode=mode)
|
||||
text = self.compile_to(nodes, schema, kv_sep)
|
||||
return self.tagging(text, schema, tag)
|
||||
|
||||
def compile_instruction(self, schema="markdown", mode="children", tag="") -> str:
|
||||
"""compile to raw/json/markdown template with all/root/children nodes"""
|
||||
format_func = lambda i: f"{i.expected_type} # {i.instruction}"
|
||||
return self._compile_f(schema, mode, tag, format_func, kv_sep=": ")
|
||||
|
||||
def compile_example(self, schema="json", mode="children", tag="") -> str:
|
||||
"""compile to raw/json/markdown examples with all/root/children nodes"""
|
||||
|
||||
# 这里不能使用f-string,因为转译为str后再json.dumps会额外加上引号,无法作为有效的example
|
||||
# 错误示例:"File list": "['main.py', 'const.py', 'game.py']", 注意这里值不是list,而是str
|
||||
format_func = lambda i: i.example
|
||||
return self._compile_f(schema, mode, tag, format_func, kv_sep="\n")
|
||||
|
||||
def compile(self, context, schema="json", mode="children", template=SIMPLE_TEMPLATE) -> str:
|
||||
"""
|
||||
mode: all/root/children
|
||||
mode="children": 编译所有子节点为一个统一模板,包括instruction与example
|
||||
mode="all": NotImplemented
|
||||
mode="root": NotImplemented
|
||||
"""
|
||||
|
||||
# FIXME: json instruction会带来格式问题,如:"Project name": "web_2048 # 项目名称使用下划线",
|
||||
# compile example暂时不支持markdown
|
||||
self.instruction = self.compile_instruction(schema="markdown", mode=mode)
|
||||
self.example = self.compile_example(schema=schema, tag=TAG, mode=mode)
|
||||
# nodes = ", ".join(self.to_dict(mode=mode).keys())
|
||||
constraints = [LANGUAGE_CONSTRAINT, FORMAT_CONSTRAINT]
|
||||
constraint = "\n".join(constraints)
|
||||
|
||||
prompt = template.format(
|
||||
context=context,
|
||||
example=self.example,
|
||||
instruction=self.instruction,
|
||||
constraint=constraint,
|
||||
)
|
||||
return prompt
|
||||
|
||||
@retry(
|
||||
wait=wait_random_exponential(min=1, max=20),
|
||||
stop=stop_after_attempt(6),
|
||||
after=general_after_log(logger),
|
||||
)
|
||||
async def _aask_v1(
|
||||
self,
|
||||
prompt: str,
|
||||
output_class_name: str,
|
||||
output_data_mapping: dict,
|
||||
system_msgs: Optional[list[str]] = None,
|
||||
schema="markdown", # compatible to original format
|
||||
) -> (str, BaseModel):
|
||||
"""Use ActionOutput to wrap the output of aask"""
|
||||
content = await self.llm.aask(prompt, system_msgs)
|
||||
logger.debug(f"llm raw output:\n{content}")
|
||||
output_class = self.create_model_class(output_class_name, output_data_mapping)
|
||||
|
||||
if schema == "json":
|
||||
parsed_data = llm_output_postprecess(output=content, schema=output_class.schema(), req_key=f"[/{TAG}]")
|
||||
else: # using markdown parser
|
||||
parsed_data = OutputParser.parse_data_with_mapping(content, output_data_mapping)
|
||||
|
||||
logger.debug(f"parsed_data:\n{parsed_data}")
|
||||
instruct_content = output_class(**parsed_data)
|
||||
return content, instruct_content
|
||||
|
||||
def get(self, key):
|
||||
return self.instruct_content.dict()[key]
|
||||
|
||||
def set_recursive(self, name, value):
|
||||
setattr(self, name, value)
|
||||
for _, i in self.children.items():
|
||||
i.set_recursive(name, value)
|
||||
|
||||
def set_llm(self, llm):
|
||||
self.set_recursive("llm", llm)
|
||||
|
||||
def set_context(self, context):
|
||||
self.set_recursive("context", context)
|
||||
|
||||
async def simple_fill(self, schema, mode):
|
||||
prompt = self.compile(context=self.context, schema=schema, mode=mode)
|
||||
mapping = self.get_mapping(mode)
|
||||
|
||||
class_name = f"{self.key}_AN"
|
||||
content, scontent = await self._aask_v1(prompt, class_name, mapping, schema=schema)
|
||||
self.content = content
|
||||
self.instruct_content = scontent
|
||||
return self
|
||||
|
||||
async def fill(self, context, llm, schema="json", mode="auto", strgy="simple"):
|
||||
"""Fill the node(s) with mode.
|
||||
|
||||
:param context: Everything we should know when filling node.
|
||||
:param llm: Large Language Model with pre-defined system message.
|
||||
:param schema: json/markdown, determine example and output format.
|
||||
- json: it's easy to open source LLM with json format
|
||||
- markdown: when generating code, markdown is always better
|
||||
:param mode: auto/children/root
|
||||
- auto: automated fill children's nodes and gather outputs, if no children, fill itself
|
||||
- children: fill children's nodes and gather outputs
|
||||
- root: fill root's node and gather output
|
||||
:param strgy: simple/complex
|
||||
- simple: run only once
|
||||
- complex: run each node
|
||||
:return: self
|
||||
"""
|
||||
self.set_llm(llm)
|
||||
self.set_context(context)
|
||||
|
||||
if strgy == "simple":
|
||||
return await self.simple_fill(schema, mode)
|
||||
elif strgy == "complex":
|
||||
# 这里隐式假设了拥有children
|
||||
tmp = {}
|
||||
for _, i in self.children.items():
|
||||
child = await i.simple_fill(schema, mode)
|
||||
tmp.update(child.instruct_content.dict())
|
||||
cls = self.create_children_class()
|
||||
self.instruct_content = cls(**tmp)
|
||||
return self
|
||||
|
||||
|
||||
def action_node_from_tuple_example():
|
||||
# 示例:列表中包含元组
|
||||
list_of_tuples = [("key1", str, "Instruction 1", "Example 1")]
|
||||
|
||||
# 从列表中创建 ActionNode 实例
|
||||
nodes = [ActionNode(*data) for data in list_of_tuples]
|
||||
for i in nodes:
|
||||
logger.info(i)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
action_node_from_tuple_example()
|
||||
|
|
@ -6,9 +6,7 @@
|
|||
@File : action_output
|
||||
"""
|
||||
|
||||
from typing import Dict, Type
|
||||
|
||||
from pydantic import BaseModel, create_model, root_validator, validator
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
class ActionOutput:
|
||||
|
|
@ -18,26 +16,3 @@ class ActionOutput:
|
|||
def __init__(self, content: str, instruct_content: BaseModel):
|
||||
self.content = content
|
||||
self.instruct_content = instruct_content
|
||||
|
||||
@classmethod
|
||||
def create_model_class(cls, class_name: str, mapping: Dict[str, Type]):
|
||||
new_class = create_model(class_name, **mapping)
|
||||
|
||||
@validator('*', allow_reuse=True)
|
||||
def check_name(v, field):
|
||||
if field.name not in mapping.keys():
|
||||
raise ValueError(f'Unrecognized block: {field.name}')
|
||||
return v
|
||||
|
||||
@root_validator(pre=True, allow_reuse=True)
|
||||
def check_missing_fields(values):
|
||||
required_fields = set(mapping.keys())
|
||||
missing_fields = required_fields - set(values.keys())
|
||||
if missing_fields:
|
||||
raise ValueError(f'Missing fields: {missing_fields}')
|
||||
return values
|
||||
|
||||
new_class.__validator_check_name = classmethod(check_name)
|
||||
new_class.__root_validator_check_missing_fields = classmethod(check_missing_fields)
|
||||
return new_class
|
||||
|
||||
|
|
@ -8,7 +8,8 @@
|
|||
from metagpt.actions import Action
|
||||
|
||||
|
||||
class BossRequirement(Action):
|
||||
"""Boss Requirement without any implementation details"""
|
||||
class UserRequirement(Action):
|
||||
"""User Requirement without any implementation details"""
|
||||
|
||||
async def run(self, *args, **kwargs):
|
||||
raise NotImplementedError
|
||||
|
|
|
|||
|
|
@ -1,37 +0,0 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/5/19 12:01
|
||||
@Author : alexanderwu
|
||||
@File : analyze_dep_libs.py
|
||||
"""
|
||||
|
||||
from metagpt.actions import Action
|
||||
|
||||
PROMPT = """You are an AI developer, trying to write a program that generates code for users based on their intentions.
|
||||
|
||||
For the user's prompt:
|
||||
|
||||
---
|
||||
The API is: {prompt}
|
||||
---
|
||||
|
||||
We decide the generated files are: {filepaths_string}
|
||||
|
||||
Now that we have a file list, we need to understand the shared dependencies they have.
|
||||
Please list and briefly describe the shared contents between the files we are generating, including exported variables,
|
||||
data patterns, id names of all DOM elements that javascript functions will use, message names and function names.
|
||||
Focus only on the names of shared dependencies, do not add any other explanations.
|
||||
"""
|
||||
|
||||
|
||||
class AnalyzeDepLibs(Action):
|
||||
def __init__(self, name, context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
self.desc = "Analyze the runtime dependencies of the program based on the context"
|
||||
|
||||
async def run(self, requirement, filepaths_string):
|
||||
# prompt = f"Below is the product requirement document (PRD):\n\n{prd}\n\n{PROMPT}"
|
||||
prompt = PROMPT.format(prompt=requirement, filepaths_string=filepaths_string)
|
||||
design_filenames = await self._aask(prompt)
|
||||
return design_filenames
|
||||
|
|
@ -1,53 +0,0 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/6/9 22:22
|
||||
@Author : Leo Xiao
|
||||
@File : azure_tts.py
|
||||
"""
|
||||
from azure.cognitiveservices.speech import AudioConfig, SpeechConfig, SpeechSynthesizer
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.config import Config
|
||||
|
||||
|
||||
class AzureTTS(Action):
|
||||
def __init__(self, name, context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
self.config = Config()
|
||||
|
||||
# Parameters reference: https://learn.microsoft.com/zh-cn/azure/cognitive-services/speech-service/language-support?tabs=tts#voice-styles-and-roles
|
||||
def synthesize_speech(self, lang, voice, role, text, output_file):
|
||||
subscription_key = self.config.get('AZURE_TTS_SUBSCRIPTION_KEY')
|
||||
region = self.config.get('AZURE_TTS_REGION')
|
||||
speech_config = SpeechConfig(
|
||||
subscription=subscription_key, region=region)
|
||||
|
||||
speech_config.speech_synthesis_voice_name = voice
|
||||
audio_config = AudioConfig(filename=output_file)
|
||||
synthesizer = SpeechSynthesizer(
|
||||
speech_config=speech_config,
|
||||
audio_config=audio_config)
|
||||
|
||||
# if voice=="zh-CN-YunxiNeural":
|
||||
ssml_string = f"""
|
||||
<speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xml:lang='{lang}' xmlns:mstts='http://www.w3.org/2001/mstts'>
|
||||
<voice name='{voice}'>
|
||||
<mstts:express-as style='affectionate' role='{role}'>
|
||||
{text}
|
||||
</mstts:express-as>
|
||||
</voice>
|
||||
</speak>
|
||||
"""
|
||||
|
||||
synthesizer.speak_ssml_async(ssml_string).get()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
azure_tts = AzureTTS("azure_tts")
|
||||
azure_tts.synthesize_speech(
|
||||
"zh-CN",
|
||||
"zh-CN-YunxiNeural",
|
||||
"Boy",
|
||||
"Hello, I am Kaka",
|
||||
"output.wav")
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
from pathlib import Path
|
||||
import traceback
|
||||
from pathlib import Path
|
||||
|
||||
from metagpt.actions.write_code import WriteCode
|
||||
from metagpt.logs import logger
|
||||
|
|
@ -42,7 +42,7 @@ class CloneFunction(WriteCode):
|
|||
prompt = CLONE_PROMPT.format(source_code=source_code, template_func=template_func)
|
||||
logger.info(f"query for CloneFunction: \n {prompt}")
|
||||
code = await self.write_code(prompt)
|
||||
logger.info(f'CloneFunction code is \n {highlight(code)}')
|
||||
logger.info(f"CloneFunction code is \n {highlight(code)}")
|
||||
return code
|
||||
|
||||
|
||||
|
|
@ -61,5 +61,5 @@ def run_function_script(code_script_path: str, func_name: str, *args, **kwargs):
|
|||
"""Run function code from script."""
|
||||
if isinstance(code_script_path, str):
|
||||
code_path = Path(code_script_path)
|
||||
code = code_path.read_text(encoding='utf-8')
|
||||
code = code_path.read_text(encoding="utf-8")
|
||||
return run_function_code(code, func_name, *args, **kwargs)
|
||||
|
|
|
|||
|
|
@ -4,12 +4,22 @@
|
|||
@Time : 2023/5/11 17:46
|
||||
@Author : alexanderwu
|
||||
@File : debug_error.py
|
||||
@Modified By: mashenquan, 2023/11/27.
|
||||
1. Divide the context into three components: legacy code, unit test code, and console log.
|
||||
2. According to Section 2.2.3.1 of RFC 135, replace file data in the message with the file name.
|
||||
"""
|
||||
import re
|
||||
|
||||
from metagpt.logs import logger
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import TEST_CODES_FILE_REPO, TEST_OUTPUTS_FILE_REPO
|
||||
from metagpt.llm import LLM, BaseGPTAPI
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import RunCodeContext, RunCodeResult
|
||||
from metagpt.utils.common import CodeParser
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
NOTICE
|
||||
|
|
@ -19,33 +29,57 @@ Based on the message, first, figure out your own role, i.e. Engineer or QaEngine
|
|||
then rewrite the development code or the test code based on your role, the error, and the summary, such that all bugs are fixed and the code performs well.
|
||||
Attention: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD WRITE BEFORE the test case or script and triple quotes.
|
||||
The message is as follows:
|
||||
{context}
|
||||
# Legacy Code
|
||||
```python
|
||||
{code}
|
||||
```
|
||||
---
|
||||
# Unit Test Code
|
||||
```python
|
||||
{test_code}
|
||||
```
|
||||
---
|
||||
# Console logs
|
||||
```text
|
||||
{logs}
|
||||
```
|
||||
---
|
||||
Now you should start rewriting the code:
|
||||
## file name of the code to rewrite: Write code with triple quoto. Do your best to implement THIS IN ONLY ONE FILE.
|
||||
## file name of the code to rewrite: Write code with triple quote. Do your best to implement THIS IN ONLY ONE FILE.
|
||||
"""
|
||||
|
||||
|
||||
class DebugError(Action):
|
||||
def __init__(self, name="DebugError", context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
name: str = "DebugError"
|
||||
context: RunCodeContext = Field(default_factory=RunCodeContext)
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
|
||||
# async def run(self, code, error):
|
||||
# prompt = f"Here is a piece of Python code:\n\n{code}\n\nThe following error occurred during execution:" \
|
||||
# f"\n\n{error}\n\nPlease try to fix the error in this code."
|
||||
# fixed_code = await self._aask(prompt)
|
||||
# return fixed_code
|
||||
|
||||
async def run(self, context):
|
||||
if "PASS" in context:
|
||||
return "", "the original code works fine, no need to debug"
|
||||
|
||||
file_name = re.search("## File To Rewrite:\s*(.+\\.py)", context).group(1)
|
||||
async def run(self, *args, **kwargs) -> str:
|
||||
output_doc = await FileRepository.get_file(
|
||||
filename=self.context.output_filename, relative_path=TEST_OUTPUTS_FILE_REPO
|
||||
)
|
||||
if not output_doc:
|
||||
return ""
|
||||
output_detail = RunCodeResult.loads(output_doc.content)
|
||||
pattern = r"Ran (\d+) tests in ([\d.]+)s\n\nOK"
|
||||
matches = re.search(pattern, output_detail.stderr)
|
||||
if matches:
|
||||
return ""
|
||||
|
||||
logger.info(f"Debug and rewrite {file_name}")
|
||||
logger.info(f"Debug and rewrite {self.context.test_filename}")
|
||||
code_doc = await FileRepository.get_file(
|
||||
filename=self.context.code_filename, relative_path=CONFIG.src_workspace
|
||||
)
|
||||
if not code_doc:
|
||||
return ""
|
||||
test_doc = await FileRepository.get_file(
|
||||
filename=self.context.test_filename, relative_path=TEST_CODES_FILE_REPO
|
||||
)
|
||||
if not test_doc:
|
||||
return ""
|
||||
prompt = PROMPT_TEMPLATE.format(code=code_doc.content, test_code=test_doc.content, logs=output_detail.stderr)
|
||||
|
||||
prompt = PROMPT_TEMPLATE.format(context=context)
|
||||
|
||||
rsp = await self._aask(prompt)
|
||||
|
||||
code = CodeParser.parse_code(block="", text=rsp)
|
||||
|
||||
return file_name, code
|
||||
return code
|
||||
|
|
|
|||
|
|
@ -4,214 +4,138 @@
|
|||
@Time : 2023/5/11 19:26
|
||||
@Author : alexanderwu
|
||||
@File : design_api.py
|
||||
@Modified By: mashenquan, 2023/11/27.
|
||||
1. According to Section 2.2.3.1 of RFC 135, replace file data in the message with the file name.
|
||||
2. According to the design in Section 2.2.3.5.3 of RFC 135, add incremental iteration functionality.
|
||||
@Modified By: mashenquan, 2023/12/5. Move the generation logic of the project name to WritePRD.
|
||||
"""
|
||||
import shutil
|
||||
import json
|
||||
from pathlib import Path
|
||||
from typing import List
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.actions import Action, ActionOutput
|
||||
from metagpt.actions.design_api_an import DESIGN_API_NODE
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import WORKSPACE_ROOT
|
||||
from metagpt.const import (
|
||||
DATA_API_DESIGN_FILE_REPO,
|
||||
PRDS_FILE_REPO,
|
||||
SEQ_FLOW_FILE_REPO,
|
||||
SYSTEM_DESIGN_FILE_REPO,
|
||||
SYSTEM_DESIGN_PDF_FILE_REPO,
|
||||
)
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.utils.common import CodeParser
|
||||
from metagpt.utils.get_template import get_template
|
||||
from metagpt.utils.json_to_markdown import json_to_markdown
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.schema import Document, Documents, Message
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
from metagpt.utils.mermaid import mermaid_to_file
|
||||
|
||||
templates = {
|
||||
"json": {
|
||||
"PROMPT_TEMPLATE": """
|
||||
# Context
|
||||
NEW_REQ_TEMPLATE = """
|
||||
### Legacy Content
|
||||
{old_design}
|
||||
|
||||
### New Requirements
|
||||
{context}
|
||||
|
||||
## Format example
|
||||
{format_example}
|
||||
-----
|
||||
Role: You are an architect; the goal is to design a SOTA PEP8-compliant python system; make the best use of good open source tools
|
||||
Requirement: Fill in the following missing information based on the context, each section name is a key in json
|
||||
Max Output: 8192 chars or 2048 tokens. Try to use them up.
|
||||
|
||||
## Implementation approach: Provide as Plain text. Analyze the difficult points of the requirements, select the appropriate open-source framework.
|
||||
|
||||
## Python package name: Provide as Python str with python triple quoto, concise and clear, characters only use a combination of all lowercase and underscores
|
||||
|
||||
## File list: Provided as Python list[str], the list of ONLY REQUIRED files needed to write the program(LESS IS MORE!). Only need relative paths, comply with PEP8 standards. ALWAYS write a main.py or app.py here
|
||||
|
||||
## Data structures and interface definitions: Use mermaid classDiagram code syntax, including classes (INCLUDING __init__ method) and functions (with type annotations), CLEARLY MARK the RELATIONSHIPS between classes, and comply with PEP8 standards. The data structures SHOULD BE VERY DETAILED and the API should be comprehensive with a complete design.
|
||||
|
||||
## Program call flow: Use sequenceDiagram code syntax, COMPLETE and VERY DETAILED, using CLASSES AND API DEFINED ABOVE accurately, covering the CRUD AND INIT of each object, SYNTAX MUST BE CORRECT.
|
||||
|
||||
## Anything UNCLEAR: Provide as Plain text. Make clear here.
|
||||
|
||||
output a properly formatted JSON, wrapped inside [CONTENT][/CONTENT] like format example,
|
||||
and only output the json inside this tag, nothing else
|
||||
""",
|
||||
"FORMAT_EXAMPLE": """
|
||||
[CONTENT]
|
||||
{
|
||||
"Implementation approach": "We will ...",
|
||||
"Python package name": "snake_game",
|
||||
"File list": ["main.py"],
|
||||
"Data structures and interface definitions": '
|
||||
classDiagram
|
||||
class Game{
|
||||
+int score
|
||||
}
|
||||
...
|
||||
Game "1" -- "1" Food: has
|
||||
',
|
||||
"Program call flow": '
|
||||
sequenceDiagram
|
||||
participant M as Main
|
||||
...
|
||||
G->>M: end game
|
||||
',
|
||||
"Anything UNCLEAR": "The requirement is clear to me."
|
||||
}
|
||||
[/CONTENT]
|
||||
""",
|
||||
},
|
||||
"markdown": {
|
||||
"PROMPT_TEMPLATE": """
|
||||
# Context
|
||||
{context}
|
||||
|
||||
## Format example
|
||||
{format_example}
|
||||
-----
|
||||
Role: You are an architect; the goal is to design a SOTA PEP8-compliant python system; make the best use of good open source tools
|
||||
Requirement: Fill in the following missing information based on the context, note that all sections are response with code form separately
|
||||
Max Output: 8192 chars or 2048 tokens. Try to use them up.
|
||||
Attention: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD WRITE BEFORE the code and triple quote.
|
||||
|
||||
## Implementation approach: Provide as Plain text. Analyze the difficult points of the requirements, select the appropriate open-source framework.
|
||||
|
||||
## Python package name: Provide as Python str with python triple quoto, concise and clear, characters only use a combination of all lowercase and underscores
|
||||
|
||||
## File list: Provided as Python list[str], the list of ONLY REQUIRED files needed to write the program(LESS IS MORE!). Only need relative paths, comply with PEP8 standards. ALWAYS write a main.py or app.py here
|
||||
|
||||
## Data structures and interface definitions: Use mermaid classDiagram code syntax, including classes (INCLUDING __init__ method) and functions (with type annotations), CLEARLY MARK the RELATIONSHIPS between classes, and comply with PEP8 standards. The data structures SHOULD BE VERY DETAILED and the API should be comprehensive with a complete design.
|
||||
|
||||
## Program call flow: Use sequenceDiagram code syntax, COMPLETE and VERY DETAILED, using CLASSES AND API DEFINED ABOVE accurately, covering the CRUD AND INIT of each object, SYNTAX MUST BE CORRECT.
|
||||
|
||||
## Anything UNCLEAR: Provide as Plain text. Make clear here.
|
||||
|
||||
""",
|
||||
"FORMAT_EXAMPLE": """
|
||||
---
|
||||
## Implementation approach
|
||||
We will ...
|
||||
|
||||
## Python package name
|
||||
```python
|
||||
"snake_game"
|
||||
```
|
||||
|
||||
## File list
|
||||
```python
|
||||
[
|
||||
"main.py",
|
||||
]
|
||||
```
|
||||
|
||||
## Data structures and interface definitions
|
||||
```mermaid
|
||||
classDiagram
|
||||
class Game{
|
||||
+int score
|
||||
}
|
||||
...
|
||||
Game "1" -- "1" Food: has
|
||||
```
|
||||
|
||||
## Program call flow
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant M as Main
|
||||
...
|
||||
G->>M: end game
|
||||
```
|
||||
|
||||
## Anything UNCLEAR
|
||||
The requirement is clear to me.
|
||||
---
|
||||
""",
|
||||
},
|
||||
}
|
||||
|
||||
OUTPUT_MAPPING = {
|
||||
"Implementation approach": (str, ...),
|
||||
"Python package name": (str, ...),
|
||||
"File list": (List[str], ...),
|
||||
"Data structures and interface definitions": (str, ...),
|
||||
"Program call flow": (str, ...),
|
||||
"Anything UNCLEAR": (str, ...),
|
||||
}
|
||||
"""
|
||||
|
||||
|
||||
class WriteDesign(Action):
|
||||
def __init__(self, name, context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
self.desc = (
|
||||
"Based on the PRD, think about the system design, and design the corresponding APIs, "
|
||||
"data structures, library tables, processes, and paths. Please provide your design, feedback "
|
||||
"clearly and in detail."
|
||||
)
|
||||
name: str = ""
|
||||
context: Optional[str] = None
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
desc: str = (
|
||||
"Based on the PRD, think about the system design, and design the corresponding APIs, "
|
||||
"data structures, library tables, processes, and paths. Please provide your design, feedback "
|
||||
"clearly and in detail."
|
||||
)
|
||||
|
||||
def recreate_workspace(self, workspace: Path):
|
||||
try:
|
||||
shutil.rmtree(workspace)
|
||||
except FileNotFoundError:
|
||||
pass # Folder does not exist, but we don't care
|
||||
workspace.mkdir(parents=True, exist_ok=True)
|
||||
async def run(self, with_messages: Message, schema: str = CONFIG.prompt_schema):
|
||||
# Use `git diff` to identify which PRD documents have been modified in the `docs/prds` directory.
|
||||
prds_file_repo = CONFIG.git_repo.new_file_repository(PRDS_FILE_REPO)
|
||||
changed_prds = prds_file_repo.changed_files
|
||||
# Use `git diff` to identify which design documents in the `docs/system_designs` directory have undergone
|
||||
# changes.
|
||||
system_design_file_repo = CONFIG.git_repo.new_file_repository(SYSTEM_DESIGN_FILE_REPO)
|
||||
changed_system_designs = system_design_file_repo.changed_files
|
||||
|
||||
async def _save_prd(self, docs_path, resources_path, context):
|
||||
prd_file = docs_path / "prd.md"
|
||||
if context[-1].instruct_content and context[-1].instruct_content.dict()["Competitive Quadrant Chart"]:
|
||||
quadrant_chart = context[-1].instruct_content.dict()["Competitive Quadrant Chart"]
|
||||
await mermaid_to_file(quadrant_chart, resources_path / "competitive_analysis")
|
||||
# For those PRDs and design documents that have undergone changes, regenerate the design content.
|
||||
changed_files = Documents()
|
||||
for filename in changed_prds.keys():
|
||||
doc = await self._update_system_design(
|
||||
filename=filename, prds_file_repo=prds_file_repo, system_design_file_repo=system_design_file_repo
|
||||
)
|
||||
changed_files.docs[filename] = doc
|
||||
|
||||
if context[-1].instruct_content:
|
||||
logger.info(f"Saving PRD to {prd_file}")
|
||||
prd_file.write_text(json_to_markdown(context[-1].instruct_content.dict()))
|
||||
for filename in changed_system_designs.keys():
|
||||
if filename in changed_files.docs:
|
||||
continue
|
||||
doc = await self._update_system_design(
|
||||
filename=filename, prds_file_repo=prds_file_repo, system_design_file_repo=system_design_file_repo
|
||||
)
|
||||
changed_files.docs[filename] = doc
|
||||
if not changed_files.docs:
|
||||
logger.info("Nothing has changed.")
|
||||
# Wait until all files under `docs/system_designs/` are processed before sending the publish message,
|
||||
# leaving room for global optimization in subsequent steps.
|
||||
return ActionOutput(content=changed_files.json(), instruct_content=changed_files)
|
||||
|
||||
async def _save_system_design(self, docs_path, resources_path, system_design):
|
||||
data_api_design = system_design.instruct_content.dict()[
|
||||
"Data structures and interface definitions"
|
||||
] # CodeParser.parse_code(block="Data structures and interface definitions", text=content)
|
||||
seq_flow = system_design.instruct_content.dict()[
|
||||
"Program call flow"
|
||||
] # CodeParser.parse_code(block="Program call flow", text=content)
|
||||
await mermaid_to_file(data_api_design, resources_path / "data_api_design")
|
||||
await mermaid_to_file(seq_flow, resources_path / "seq_flow")
|
||||
system_design_file = docs_path / "system_design.md"
|
||||
logger.info(f"Saving System Designs to {system_design_file}")
|
||||
system_design_file.write_text((json_to_markdown(system_design.instruct_content.dict())))
|
||||
async def _new_system_design(self, context, schema=CONFIG.prompt_schema):
|
||||
node = await DESIGN_API_NODE.fill(context=context, llm=self.llm, schema=schema)
|
||||
return node
|
||||
|
||||
async def _save(self, context, system_design):
|
||||
if isinstance(system_design, ActionOutput):
|
||||
ws_name = system_design.instruct_content.dict()["Python package name"]
|
||||
async def _merge(self, prd_doc, system_design_doc, schema=CONFIG.prompt_schema):
|
||||
context = NEW_REQ_TEMPLATE.format(old_design=system_design_doc.content, context=prd_doc.content)
|
||||
node = await DESIGN_API_NODE.fill(context=context, llm=self.llm, schema=schema)
|
||||
system_design_doc.content = node.instruct_content.json(ensure_ascii=False)
|
||||
return system_design_doc
|
||||
|
||||
async def _update_system_design(self, filename, prds_file_repo, system_design_file_repo) -> Document:
|
||||
prd = await prds_file_repo.get(filename)
|
||||
old_system_design_doc = await system_design_file_repo.get(filename)
|
||||
if not old_system_design_doc:
|
||||
system_design = await self._new_system_design(context=prd.content)
|
||||
doc = Document(
|
||||
root_path=SYSTEM_DESIGN_FILE_REPO,
|
||||
filename=filename,
|
||||
content=system_design.instruct_content.json(ensure_ascii=False),
|
||||
)
|
||||
else:
|
||||
ws_name = CodeParser.parse_str(block="Python package name", text=system_design)
|
||||
workspace = WORKSPACE_ROOT / ws_name
|
||||
self.recreate_workspace(workspace)
|
||||
docs_path = workspace / "docs"
|
||||
resources_path = workspace / "resources"
|
||||
docs_path.mkdir(parents=True, exist_ok=True)
|
||||
resources_path.mkdir(parents=True, exist_ok=True)
|
||||
await self._save_prd(docs_path, resources_path, context)
|
||||
await self._save_system_design(docs_path, resources_path, system_design)
|
||||
|
||||
async def run(self, context, format=CONFIG.prompt_format):
|
||||
prompt_template, format_example = get_template(templates, format)
|
||||
prompt = prompt_template.format(context=context, format_example=format_example)
|
||||
# system_design = await self._aask(prompt)
|
||||
system_design = await self._aask_v1(prompt, "system_design", OUTPUT_MAPPING, format=format)
|
||||
# fix Python package name, we can't system_design.instruct_content.python_package_name = "xxx" since "Python package name" contain space, have to use setattr
|
||||
setattr(
|
||||
system_design.instruct_content,
|
||||
"Python package name",
|
||||
system_design.instruct_content.dict()["Python package name"].strip().strip("'").strip('"'),
|
||||
doc = await self._merge(prd_doc=prd, system_design_doc=old_system_design_doc)
|
||||
await system_design_file_repo.save(
|
||||
filename=filename, content=doc.content, dependencies={prd.root_relative_path}
|
||||
)
|
||||
await self._save(context, system_design)
|
||||
return system_design
|
||||
await self._save_data_api_design(doc)
|
||||
await self._save_seq_flow(doc)
|
||||
await self._save_pdf(doc)
|
||||
return doc
|
||||
|
||||
@staticmethod
|
||||
async def _save_data_api_design(design_doc):
|
||||
m = json.loads(design_doc.content)
|
||||
data_api_design = m.get("Data structures and interfaces")
|
||||
if not data_api_design:
|
||||
return
|
||||
pathname = CONFIG.git_repo.workdir / DATA_API_DESIGN_FILE_REPO / Path(design_doc.filename).with_suffix("")
|
||||
await WriteDesign._save_mermaid_file(data_api_design, pathname)
|
||||
logger.info(f"Save class view to {str(pathname)}")
|
||||
|
||||
@staticmethod
|
||||
async def _save_seq_flow(design_doc):
|
||||
m = json.loads(design_doc.content)
|
||||
seq_flow = m.get("Program call flow")
|
||||
if not seq_flow:
|
||||
return
|
||||
pathname = CONFIG.git_repo.workdir / Path(SEQ_FLOW_FILE_REPO) / Path(design_doc.filename).with_suffix("")
|
||||
await WriteDesign._save_mermaid_file(seq_flow, pathname)
|
||||
logger.info(f"Saving sequence flow to {str(pathname)}")
|
||||
|
||||
@staticmethod
|
||||
async def _save_pdf(design_doc):
|
||||
await FileRepository.save_as(doc=design_doc, with_suffix=".md", relative_path=SYSTEM_DESIGN_PDF_FILE_REPO)
|
||||
|
||||
@staticmethod
|
||||
async def _save_mermaid_file(data: str, pathname: Path):
|
||||
pathname.parent.mkdir(parents=True, exist_ok=True)
|
||||
await mermaid_to_file(data, pathname)
|
||||
|
|
|
|||
74
metagpt/actions/design_api_an.py
Normal file
74
metagpt/actions/design_api_an.py
Normal file
|
|
@ -0,0 +1,74 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/12/12 22:24
|
||||
@Author : alexanderwu
|
||||
@File : design_api_an.py
|
||||
"""
|
||||
from typing import List
|
||||
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
from metagpt.logs import logger
|
||||
from metagpt.utils.mermaid import MMC1, MMC2
|
||||
|
||||
IMPLEMENTATION_APPROACH = ActionNode(
|
||||
key="Implementation approach",
|
||||
expected_type=str,
|
||||
instruction="Analyze the difficult points of the requirements, select the appropriate open-source framework",
|
||||
example="We will ...",
|
||||
)
|
||||
|
||||
PROJECT_NAME = ActionNode(
|
||||
key="Project name", expected_type=str, instruction="The project name with underline", example="game_2048"
|
||||
)
|
||||
|
||||
FILE_LIST = ActionNode(
|
||||
key="File list",
|
||||
expected_type=List[str],
|
||||
instruction="Only need relative paths. ALWAYS write a main.py or app.py here",
|
||||
example=["main.py", "game.py"],
|
||||
)
|
||||
|
||||
DATA_STRUCTURES_AND_INTERFACES = ActionNode(
|
||||
key="Data structures and interfaces",
|
||||
expected_type=str,
|
||||
instruction="Use mermaid classDiagram code syntax, including classes, method(__init__ etc.) and functions with type"
|
||||
" annotations, CLEARLY MARK the RELATIONSHIPS between classes, and comply with PEP8 standards. "
|
||||
"The data structures SHOULD BE VERY DETAILED and the API should be comprehensive with a complete design.",
|
||||
example=MMC1,
|
||||
)
|
||||
|
||||
PROGRAM_CALL_FLOW = ActionNode(
|
||||
key="Program call flow",
|
||||
expected_type=str,
|
||||
instruction="Use sequenceDiagram code syntax, COMPLETE and VERY DETAILED, using CLASSES AND API DEFINED ABOVE "
|
||||
"accurately, covering the CRUD AND INIT of each object, SYNTAX MUST BE CORRECT.",
|
||||
example=MMC2,
|
||||
)
|
||||
|
||||
ANYTHING_UNCLEAR = ActionNode(
|
||||
key="Anything UNCLEAR",
|
||||
expected_type=str,
|
||||
instruction="Mention unclear project aspects, then try to clarify it.",
|
||||
example="Clarification needed on third-party API integration, ...",
|
||||
)
|
||||
|
||||
NODES = [
|
||||
IMPLEMENTATION_APPROACH,
|
||||
# PROJECT_NAME,
|
||||
FILE_LIST,
|
||||
DATA_STRUCTURES_AND_INTERFACES,
|
||||
PROGRAM_CALL_FLOW,
|
||||
ANYTHING_UNCLEAR,
|
||||
]
|
||||
|
||||
DESIGN_API_NODE = ActionNode.from_children("DesignAPI", NODES)
|
||||
|
||||
|
||||
def main():
|
||||
prompt = DESIGN_API_NODE.compile(context="")
|
||||
logger.info(prompt)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
|
@ -13,10 +13,11 @@ class DesignReview(Action):
|
|||
super().__init__(name, context, llm)
|
||||
|
||||
async def run(self, prd, api_design):
|
||||
prompt = f"Here is the Product Requirement Document (PRD):\n\n{prd}\n\nHere is the list of APIs designed " \
|
||||
f"based on this PRD:\n\n{api_design}\n\nPlease review whether this API design meets the requirements" \
|
||||
f" of the PRD, and whether it complies with good design practices."
|
||||
prompt = (
|
||||
f"Here is the Product Requirement Document (PRD):\n\n{prd}\n\nHere is the list of APIs designed "
|
||||
f"based on this PRD:\n\n{api_design}\n\nPlease review whether this API design meets the requirements"
|
||||
f" of the PRD, and whether it complies with good design practices."
|
||||
)
|
||||
|
||||
api_review = await self._aask(prompt)
|
||||
return api_review
|
||||
|
||||
|
|
@ -1,29 +0,0 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/5/19 11:50
|
||||
@Author : alexanderwu
|
||||
@File : design_filenames.py
|
||||
"""
|
||||
from metagpt.actions import Action
|
||||
from metagpt.logs import logger
|
||||
|
||||
PROMPT = """You are an AI developer, trying to write a program that generates code for users based on their intentions.
|
||||
When given their intentions, provide a complete and exhaustive list of file paths needed to write the program for the user.
|
||||
Only list the file paths you will write and return them as a Python string list.
|
||||
Do not add any other explanations, just return a Python string list."""
|
||||
|
||||
|
||||
class DesignFilenames(Action):
|
||||
def __init__(self, name, context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
self.desc = "Based on the PRD, consider system design, and carry out the basic design of the corresponding " \
|
||||
"APIs, data structures, and database tables. Please give your design, feedback clearly and in detail."
|
||||
|
||||
async def run(self, prd):
|
||||
prompt = f"The following is the Product Requirement Document (PRD):\n\n{prd}\n\n{PROMPT}"
|
||||
design_filenames = await self._aask(prompt)
|
||||
logger.debug(prompt)
|
||||
logger.debug(design_filenames)
|
||||
return design_filenames
|
||||
|
||||
|
|
@ -1,52 +0,0 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/9/12 17:45
|
||||
@Author : fisherdeng
|
||||
@File : detail_mining.py
|
||||
"""
|
||||
from metagpt.actions import Action, ActionOutput
|
||||
from metagpt.logs import logger
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
##TOPIC
|
||||
{topic}
|
||||
|
||||
##RECORD
|
||||
{record}
|
||||
|
||||
##Format example
|
||||
{format_example}
|
||||
-----
|
||||
|
||||
Task: Refer to the "##TOPIC" (discussion objectives) and "##RECORD" (discussion records) to further inquire about the details that interest you, within a word limit of 150 words.
|
||||
Special Note 1: Your intention is solely to ask questions without endorsing or negating any individual's viewpoints.
|
||||
Special Note 2: This output should only include the topic "##OUTPUT". Do not add, remove, or modify the topic. Begin the output with '##OUTPUT', followed by an immediate line break, and then proceed to provide the content in the specified format as outlined in the "##Format example" section.
|
||||
Special Note 3: The output should be in the same language as the input.
|
||||
"""
|
||||
FORMAT_EXAMPLE = """
|
||||
|
||||
##
|
||||
|
||||
##OUTPUT
|
||||
...(Please provide the specific details you would like to inquire about here.)
|
||||
|
||||
##
|
||||
|
||||
##
|
||||
"""
|
||||
OUTPUT_MAPPING = {
|
||||
"OUTPUT": (str, ...),
|
||||
}
|
||||
|
||||
|
||||
class DetailMining(Action):
|
||||
"""This class allows LLM to further mine noteworthy details based on specific "##TOPIC"(discussion topic) and "##RECORD" (discussion records), thereby deepening the discussion.
|
||||
"""
|
||||
def __init__(self, name="", context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
|
||||
async def run(self, topic, record) -> ActionOutput:
|
||||
prompt = PROMPT_TEMPLATE.format(topic=topic, record=record, format_example=FORMAT_EXAMPLE)
|
||||
rsp = await self._aask_v1(prompt, "detail_mining", OUTPUT_MAPPING)
|
||||
return rsp
|
||||
16
metagpt/actions/fix_bug.py
Normal file
16
metagpt/actions/fix_bug.py
Normal file
|
|
@ -0,0 +1,16 @@
|
|||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023-12-12
|
||||
@Author : mashenquan
|
||||
@File : fix_bug.py
|
||||
"""
|
||||
from metagpt.actions import Action
|
||||
|
||||
|
||||
class FixBug(Action):
|
||||
"""Fix bug action without any implementation details"""
|
||||
|
||||
name: str = "FixBug"
|
||||
|
||||
async def run(self, *args, **kwargs):
|
||||
raise NotImplementedError
|
||||
25
metagpt/actions/generate_questions.py
Normal file
25
metagpt/actions/generate_questions.py
Normal file
|
|
@ -0,0 +1,25 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/9/12 17:45
|
||||
@Author : fisherdeng
|
||||
@File : generate_questions.py
|
||||
"""
|
||||
from metagpt.actions import Action
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
|
||||
QUESTIONS = ActionNode(
|
||||
key="Questions",
|
||||
expected_type=list[str],
|
||||
instruction="Task: Refer to the context to further inquire about the details that interest you, within a word limit"
|
||||
" of 150 words. Please provide the specific details you would like to inquire about here",
|
||||
example=["1. What ...", "2. How ...", "3. ..."],
|
||||
)
|
||||
|
||||
|
||||
class GenerateQuestions(Action):
|
||||
"""This class allows LLM to further mine noteworthy details based on specific "##TOPIC"(discussion topic) and
|
||||
"##RECORD" (discussion records), thereby deepening the discussion."""
|
||||
|
||||
async def run(self, context):
|
||||
return await QUESTIONS.fill(context=context, llm=self.llm)
|
||||
|
|
@ -10,8 +10,8 @@
|
|||
|
||||
import os
|
||||
import zipfile
|
||||
from pathlib import Path
|
||||
from datetime import datetime
|
||||
from pathlib import Path
|
||||
|
||||
import pandas as pd
|
||||
from paddleocr import PaddleOCR
|
||||
|
|
@ -19,7 +19,10 @@ from paddleocr import PaddleOCR
|
|||
from metagpt.actions import Action
|
||||
from metagpt.const import INVOICE_OCR_TABLE_PATH
|
||||
from metagpt.logs import logger
|
||||
from metagpt.prompts.invoice_ocr import EXTRACT_OCR_MAIN_INFO_PROMPT, REPLY_OCR_QUESTION_PROMPT
|
||||
from metagpt.prompts.invoice_ocr import (
|
||||
EXTRACT_OCR_MAIN_INFO_PROMPT,
|
||||
REPLY_OCR_QUESTION_PROMPT,
|
||||
)
|
||||
from metagpt.utils.common import OutputParser
|
||||
from metagpt.utils.file import File
|
||||
|
||||
|
|
@ -183,4 +186,3 @@ class ReplyQuestion(Action):
|
|||
prompt = REPLY_OCR_QUESTION_PROMPT.format(query=query, ocr_result=ocr_result, language=self.language)
|
||||
resp = await self._aask(prompt=prompt)
|
||||
return resp
|
||||
|
||||
|
|
|
|||
54
metagpt/actions/prepare_documents.py
Normal file
54
metagpt/actions/prepare_documents.py
Normal file
|
|
@ -0,0 +1,54 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/11/20
|
||||
@Author : mashenquan
|
||||
@File : prepare_documents.py
|
||||
@Desc: PrepareDocuments Action: initialize project folder and add new requirements to docs/requirements.txt.
|
||||
RFC 135 2.2.3.5.1.
|
||||
"""
|
||||
import shutil
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.actions import Action, ActionOutput
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import DOCS_FILE_REPO, REQUIREMENT_FILENAME
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.schema import Document
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
from metagpt.utils.git_repository import GitRepository
|
||||
|
||||
|
||||
class PrepareDocuments(Action):
|
||||
"""PrepareDocuments Action: initialize project folder and add new requirements to docs/requirements.txt."""
|
||||
|
||||
name: str = "PrepareDocuments"
|
||||
context: Optional[str] = None
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
|
||||
def _init_repo(self):
|
||||
"""Initialize the Git environment."""
|
||||
path = CONFIG.project_path
|
||||
if not path:
|
||||
name = CONFIG.project_name or FileRepository.new_filename()
|
||||
path = Path(CONFIG.workspace_path) / name
|
||||
|
||||
if path.exists() and not CONFIG.inc:
|
||||
shutil.rmtree(path)
|
||||
CONFIG.git_repo = GitRepository(local_path=path, auto_init=True)
|
||||
|
||||
async def run(self, with_messages, **kwargs):
|
||||
"""Create and initialize the workspace folder, initialize the Git environment."""
|
||||
self._init_repo()
|
||||
|
||||
# Write the newly added requirements from the main parameter idea to `docs/requirement.txt`.
|
||||
doc = Document(root_path=DOCS_FILE_REPO, filename=REQUIREMENT_FILENAME, content=with_messages[0].content)
|
||||
await FileRepository.save_file(filename=REQUIREMENT_FILENAME, content=doc.content, relative_path=DOCS_FILE_REPO)
|
||||
|
||||
# Send a Message notification to the WritePRD action, instructing it to process requirements using
|
||||
# `docs/requirement.txt` and `docs/prds/`.
|
||||
return ActionOutput(content=doc.content, instruct_content=doc)
|
||||
|
|
@ -6,36 +6,18 @@
|
|||
@File : prepare_interview.py
|
||||
"""
|
||||
from metagpt.actions import Action
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
# Context
|
||||
{context}
|
||||
|
||||
## Format example
|
||||
---
|
||||
Q1: question 1 here
|
||||
References:
|
||||
- point 1
|
||||
- point 2
|
||||
|
||||
Q2: question 2 here...
|
||||
---
|
||||
|
||||
-----
|
||||
Role: You are an interviewer of our company who is well-knonwn in frontend or backend develop;
|
||||
QUESTIONS = ActionNode(
|
||||
key="Questions",
|
||||
expected_type=list[str],
|
||||
instruction="""Role: You are an interviewer of our company who is well-knonwn in frontend or backend develop;
|
||||
Requirement: Provide a list of questions for the interviewer to ask the interviewee, by reading the resume of the interviewee in the context.
|
||||
Attention: Provide as markdown block as the format above, at least 10 questions.
|
||||
"""
|
||||
|
||||
# prepare for a interview
|
||||
Attention: Provide as markdown block as the format above, at least 10 questions.""",
|
||||
example=["1. What ...", "2. How ..."],
|
||||
)
|
||||
|
||||
|
||||
class PrepareInterview(Action):
|
||||
def __init__(self, name, context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
|
||||
async def run(self, context):
|
||||
prompt = PROMPT_TEMPLATE.format(context=context)
|
||||
question_list = await self._aask_v1(prompt)
|
||||
return question_list
|
||||
|
||||
return await QUESTIONS.fill(context=context, llm=self.llm)
|
||||
|
|
|
|||
|
|
@ -4,186 +4,125 @@
|
|||
@Time : 2023/5/11 19:12
|
||||
@Author : alexanderwu
|
||||
@File : project_management.py
|
||||
@Modified By: mashenquan, 2023/11/27.
|
||||
1. Divide the context into three components: legacy code, unit test code, and console log.
|
||||
2. Move the document storage operations related to WritePRD from the save operation of WriteDesign.
|
||||
3. According to the design in Section 2.2.3.5.4 of RFC 135, add incremental iteration functionality.
|
||||
"""
|
||||
from typing import List
|
||||
|
||||
import json
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.actions import ActionOutput
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.actions.project_management_an import PM_NODE
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import WORKSPACE_ROOT
|
||||
from metagpt.utils.common import CodeParser
|
||||
from metagpt.utils.get_template import get_template
|
||||
from metagpt.utils.json_to_markdown import json_to_markdown
|
||||
from metagpt.const import (
|
||||
PACKAGE_REQUIREMENTS_FILENAME,
|
||||
SYSTEM_DESIGN_FILE_REPO,
|
||||
TASK_FILE_REPO,
|
||||
TASK_PDF_FILE_REPO,
|
||||
)
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.schema import Document, Documents
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
|
||||
templates = {
|
||||
"json": {
|
||||
"PROMPT_TEMPLATE": """
|
||||
# Context
|
||||
NEW_REQ_TEMPLATE = """
|
||||
### Legacy Content
|
||||
{old_tasks}
|
||||
|
||||
### New Requirements
|
||||
{context}
|
||||
|
||||
## Format example
|
||||
{format_example}
|
||||
-----
|
||||
Role: You are a project manager; the goal is to break down tasks according to PRD/technical design, give a task list, and analyze task dependencies to start with the prerequisite modules
|
||||
Requirements: Based on the context, fill in the following missing information, each section name is a key in json. Here the granularity of the task is a file, if there are any missing files, you can supplement them
|
||||
Attention: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD WRITE BEFORE the code and triple quote.
|
||||
|
||||
## Required Python third-party packages: Provided in requirements.txt format
|
||||
|
||||
## Required Other language third-party packages: Provided in requirements.txt format
|
||||
|
||||
## Full API spec: Use OpenAPI 3.0. Describe all APIs that may be used by both frontend and backend.
|
||||
|
||||
## Logic Analysis: Provided as a Python list[list[str]. the first is filename, the second is class/method/function should be implemented in this file. Analyze the dependencies between the files, which work should be done first
|
||||
|
||||
## Task list: Provided as Python list[str]. Each str is a filename, the more at the beginning, the more it is a prerequisite dependency, should be done first
|
||||
|
||||
## Shared Knowledge: Anything that should be public like utils' functions, config's variables details that should make clear first.
|
||||
|
||||
## Anything UNCLEAR: Provide as Plain text. Make clear here. For example, don't forget a main entry. don't forget to init 3rd party libs.
|
||||
|
||||
output a properly formatted JSON, wrapped inside [CONTENT][/CONTENT] like format example,
|
||||
and only output the json inside this tag, nothing else
|
||||
""",
|
||||
"FORMAT_EXAMPLE": '''
|
||||
{
|
||||
"Required Python third-party packages": [
|
||||
"flask==1.1.2",
|
||||
"bcrypt==3.2.0"
|
||||
],
|
||||
"Required Other language third-party packages": [
|
||||
"No third-party ..."
|
||||
],
|
||||
"Full API spec": """
|
||||
openapi: 3.0.0
|
||||
...
|
||||
description: A JSON object ...
|
||||
""",
|
||||
"Logic Analysis": [
|
||||
["game.py","Contains..."]
|
||||
],
|
||||
"Task list": [
|
||||
"game.py"
|
||||
],
|
||||
"Shared Knowledge": """
|
||||
'game.py' contains ...
|
||||
""",
|
||||
"Anything UNCLEAR": "We need ... how to start."
|
||||
}
|
||||
''',
|
||||
},
|
||||
"markdown": {
|
||||
"PROMPT_TEMPLATE": """
|
||||
# Context
|
||||
{context}
|
||||
|
||||
## Format example
|
||||
{format_example}
|
||||
-----
|
||||
Role: You are a project manager; the goal is to break down tasks according to PRD/technical design, give a task list, and analyze task dependencies to start with the prerequisite modules
|
||||
Requirements: Based on the context, fill in the following missing information, note that all sections are returned in Python code triple quote form seperatedly. Here the granularity of the task is a file, if there are any missing files, you can supplement them
|
||||
Attention: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD WRITE BEFORE the code and triple quote.
|
||||
|
||||
## Required Python third-party packages: Provided in requirements.txt format
|
||||
|
||||
## Required Other language third-party packages: Provided in requirements.txt format
|
||||
|
||||
## Full API spec: Use OpenAPI 3.0. Describe all APIs that may be used by both frontend and backend.
|
||||
|
||||
## Logic Analysis: Provided as a Python list[list[str]. the first is filename, the second is class/method/function should be implemented in this file. Analyze the dependencies between the files, which work should be done first
|
||||
|
||||
## Task list: Provided as Python list[str]. Each str is a filename, the more at the beginning, the more it is a prerequisite dependency, should be done first
|
||||
|
||||
## Shared Knowledge: Anything that should be public like utils' functions, config's variables details that should make clear first.
|
||||
|
||||
## Anything UNCLEAR: Provide as Plain text. Make clear here. For example, don't forget a main entry. don't forget to init 3rd party libs.
|
||||
|
||||
""",
|
||||
"FORMAT_EXAMPLE": '''
|
||||
---
|
||||
## Required Python third-party packages
|
||||
```python
|
||||
"""
|
||||
flask==1.1.2
|
||||
bcrypt==3.2.0
|
||||
"""
|
||||
```
|
||||
|
||||
## Required Other language third-party packages
|
||||
```python
|
||||
"""
|
||||
No third-party ...
|
||||
"""
|
||||
```
|
||||
|
||||
## Full API spec
|
||||
```python
|
||||
"""
|
||||
openapi: 3.0.0
|
||||
...
|
||||
description: A JSON object ...
|
||||
"""
|
||||
```
|
||||
|
||||
## Logic Analysis
|
||||
```python
|
||||
[
|
||||
["game.py", "Contains ..."],
|
||||
]
|
||||
```
|
||||
|
||||
## Task list
|
||||
```python
|
||||
[
|
||||
"game.py",
|
||||
]
|
||||
```
|
||||
|
||||
## Shared Knowledge
|
||||
```python
|
||||
"""
|
||||
'game.py' contains ...
|
||||
"""
|
||||
```
|
||||
|
||||
## Anything UNCLEAR
|
||||
We need ... how to start.
|
||||
---
|
||||
''',
|
||||
},
|
||||
}
|
||||
OUTPUT_MAPPING = {
|
||||
"Required Python third-party packages": (List[str], ...),
|
||||
"Required Other language third-party packages": (List[str], ...),
|
||||
"Full API spec": (str, ...),
|
||||
"Logic Analysis": (List[List[str]], ...),
|
||||
"Task list": (List[str], ...),
|
||||
"Shared Knowledge": (str, ...),
|
||||
"Anything UNCLEAR": (str, ...),
|
||||
}
|
||||
|
||||
|
||||
class WriteTasks(Action):
|
||||
def __init__(self, name="CreateTasks", context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
name: str = "CreateTasks"
|
||||
context: Optional[str] = None
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
|
||||
def _save(self, context, rsp):
|
||||
if context[-1].instruct_content:
|
||||
ws_name = context[-1].instruct_content.dict()["Python package name"]
|
||||
async def run(self, with_messages, schema=CONFIG.prompt_schema):
|
||||
system_design_file_repo = CONFIG.git_repo.new_file_repository(SYSTEM_DESIGN_FILE_REPO)
|
||||
changed_system_designs = system_design_file_repo.changed_files
|
||||
|
||||
tasks_file_repo = CONFIG.git_repo.new_file_repository(TASK_FILE_REPO)
|
||||
changed_tasks = tasks_file_repo.changed_files
|
||||
change_files = Documents()
|
||||
# Rewrite the system designs that have undergone changes based on the git head diff under
|
||||
# `docs/system_designs/`.
|
||||
for filename in changed_system_designs:
|
||||
task_doc = await self._update_tasks(
|
||||
filename=filename, system_design_file_repo=system_design_file_repo, tasks_file_repo=tasks_file_repo
|
||||
)
|
||||
change_files.docs[filename] = task_doc
|
||||
|
||||
# Rewrite the task files that have undergone changes based on the git head diff under `docs/tasks/`.
|
||||
for filename in changed_tasks:
|
||||
if filename in change_files.docs:
|
||||
continue
|
||||
task_doc = await self._update_tasks(
|
||||
filename=filename, system_design_file_repo=system_design_file_repo, tasks_file_repo=tasks_file_repo
|
||||
)
|
||||
change_files.docs[filename] = task_doc
|
||||
|
||||
if not change_files.docs:
|
||||
logger.info("Nothing has changed.")
|
||||
# Wait until all files under `docs/tasks/` are processed before sending the publish_message, leaving room for
|
||||
# global optimization in subsequent steps.
|
||||
return ActionOutput(content=change_files.json(), instruct_content=change_files)
|
||||
|
||||
async def _update_tasks(self, filename, system_design_file_repo, tasks_file_repo):
|
||||
system_design_doc = await system_design_file_repo.get(filename)
|
||||
task_doc = await tasks_file_repo.get(filename)
|
||||
if task_doc:
|
||||
task_doc = await self._merge(system_design_doc=system_design_doc, task_doc=task_doc)
|
||||
else:
|
||||
ws_name = CodeParser.parse_str(block="Python package name", text=context[-1].content)
|
||||
file_path = WORKSPACE_ROOT / ws_name / "docs/api_spec_and_tasks.md"
|
||||
file_path.write_text(json_to_markdown(rsp.instruct_content.dict()))
|
||||
rsp = await self._run_new_tasks(context=system_design_doc.content)
|
||||
task_doc = Document(
|
||||
root_path=TASK_FILE_REPO, filename=filename, content=rsp.instruct_content.json(ensure_ascii=False)
|
||||
)
|
||||
await tasks_file_repo.save(
|
||||
filename=filename, content=task_doc.content, dependencies={system_design_doc.root_relative_path}
|
||||
)
|
||||
await self._update_requirements(task_doc)
|
||||
await self._save_pdf(task_doc=task_doc)
|
||||
return task_doc
|
||||
|
||||
# Write requirements.txt
|
||||
requirements_path = WORKSPACE_ROOT / ws_name / "requirements.txt"
|
||||
requirements_path.write_text("\n".join(rsp.instruct_content.dict().get("Required Python third-party packages")))
|
||||
async def _run_new_tasks(self, context, schema=CONFIG.prompt_schema):
|
||||
node = await PM_NODE.fill(context, self.llm, schema)
|
||||
# prompt_template, format_example = get_template(templates, format)
|
||||
# prompt = prompt_template.format(context=context, format_example=format_example)
|
||||
# rsp = await self._aask_v1(prompt, "task", OUTPUT_MAPPING, format=format)
|
||||
return node
|
||||
|
||||
async def run(self, context, format=CONFIG.prompt_format):
|
||||
prompt_template, format_example = get_template(templates, format)
|
||||
prompt = prompt_template.format(context=context, format_example=format_example)
|
||||
rsp = await self._aask_v1(prompt, "task", OUTPUT_MAPPING, format=format)
|
||||
self._save(context, rsp)
|
||||
return rsp
|
||||
async def _merge(self, system_design_doc, task_doc, schema=CONFIG.prompt_schema) -> Document:
|
||||
context = NEW_REQ_TEMPLATE.format(context=system_design_doc.content, old_tasks=task_doc.content)
|
||||
node = await PM_NODE.fill(context, self.llm, schema)
|
||||
task_doc.content = node.instruct_content.json(ensure_ascii=False)
|
||||
return task_doc
|
||||
|
||||
@staticmethod
|
||||
async def _update_requirements(doc):
|
||||
m = json.loads(doc.content)
|
||||
packages = set(m.get("Required Python third-party packages", set()))
|
||||
file_repo = CONFIG.git_repo.new_file_repository()
|
||||
requirement_doc = await file_repo.get(filename=PACKAGE_REQUIREMENTS_FILENAME)
|
||||
if not requirement_doc:
|
||||
requirement_doc = Document(filename=PACKAGE_REQUIREMENTS_FILENAME, root_path=".", content="")
|
||||
lines = requirement_doc.content.splitlines()
|
||||
for pkg in lines:
|
||||
if pkg == "":
|
||||
continue
|
||||
packages.add(pkg)
|
||||
await file_repo.save(PACKAGE_REQUIREMENTS_FILENAME, content="\n".join(packages))
|
||||
|
||||
@staticmethod
|
||||
async def _save_pdf(task_doc):
|
||||
await FileRepository.save_as(doc=task_doc, with_suffix=".md", relative_path=TASK_PDF_FILE_REPO)
|
||||
|
||||
|
||||
class AssignTasks(Action):
|
||||
|
|
|
|||
87
metagpt/actions/project_management_an.py
Normal file
87
metagpt/actions/project_management_an.py
Normal file
|
|
@ -0,0 +1,87 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/12/14 15:28
|
||||
@Author : alexanderwu
|
||||
@File : project_management_an.py
|
||||
"""
|
||||
from typing import List
|
||||
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
from metagpt.logs import logger
|
||||
|
||||
REQUIRED_PYTHON_PACKAGES = ActionNode(
|
||||
key="Required Python packages",
|
||||
expected_type=List[str],
|
||||
instruction="Provide required Python packages in requirements.txt format.",
|
||||
example=["flask==1.1.2", "bcrypt==3.2.0"],
|
||||
)
|
||||
|
||||
REQUIRED_OTHER_LANGUAGE_PACKAGES = ActionNode(
|
||||
key="Required Other language third-party packages",
|
||||
expected_type=List[str],
|
||||
instruction="List down the required packages for languages other than Python.",
|
||||
example=["No third-party dependencies required"],
|
||||
)
|
||||
|
||||
LOGIC_ANALYSIS = ActionNode(
|
||||
key="Logic Analysis",
|
||||
expected_type=List[List[str]],
|
||||
instruction="Provide a list of files with the classes/methods/functions to be implemented, "
|
||||
"including dependency analysis and imports.",
|
||||
example=[
|
||||
["game.py", "Contains Game class and ... functions"],
|
||||
["main.py", "Contains main function, from game import Game"],
|
||||
],
|
||||
)
|
||||
|
||||
TASK_LIST = ActionNode(
|
||||
key="Task list",
|
||||
expected_type=List[str],
|
||||
instruction="Break down the tasks into a list of filenames, prioritized by dependency order.",
|
||||
example=["game.py", "main.py"],
|
||||
)
|
||||
|
||||
FULL_API_SPEC = ActionNode(
|
||||
key="Full API spec",
|
||||
expected_type=str,
|
||||
instruction="Describe all APIs using OpenAPI 3.0 spec that may be used by both frontend and backend. If front-end "
|
||||
"and back-end communication is not required, leave it blank.",
|
||||
example="openapi: 3.0.0 ...",
|
||||
)
|
||||
|
||||
SHARED_KNOWLEDGE = ActionNode(
|
||||
key="Shared Knowledge",
|
||||
expected_type=str,
|
||||
instruction="Detail any shared knowledge, like common utility functions or configuration variables.",
|
||||
example="'game.py' contains functions shared across the project.",
|
||||
)
|
||||
|
||||
ANYTHING_UNCLEAR_PM = ActionNode(
|
||||
key="Anything UNCLEAR",
|
||||
expected_type=str,
|
||||
instruction="Mention any unclear aspects in the project management context and try to clarify them.",
|
||||
example="Clarification needed on how to start and initialize third-party libraries.",
|
||||
)
|
||||
|
||||
NODES = [
|
||||
REQUIRED_PYTHON_PACKAGES,
|
||||
REQUIRED_OTHER_LANGUAGE_PACKAGES,
|
||||
LOGIC_ANALYSIS,
|
||||
TASK_LIST,
|
||||
FULL_API_SPEC,
|
||||
SHARED_KNOWLEDGE,
|
||||
ANYTHING_UNCLEAR_PM,
|
||||
]
|
||||
|
||||
|
||||
PM_NODE = ActionNode.from_children("PM_NODE", NODES)
|
||||
|
||||
|
||||
def main():
|
||||
prompt = PM_NODE.compile(context="")
|
||||
logger.info(prompt)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
|
@ -3,7 +3,6 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import asyncio
|
||||
import json
|
||||
from typing import Callable
|
||||
|
||||
from pydantic import parse_obj_as
|
||||
|
|
@ -49,7 +48,7 @@ based on the link credibility. If two results have equal credibility, prioritize
|
|||
ranked results' indices in JSON format, like [0, 1, 3, 4, ...], without including other words.
|
||||
"""
|
||||
|
||||
WEB_BROWSE_AND_SUMMARIZE_PROMPT = '''### Requirements
|
||||
WEB_BROWSE_AND_SUMMARIZE_PROMPT = """### Requirements
|
||||
1. Utilize the text in the "Reference Information" section to respond to the question "{query}".
|
||||
2. If the question cannot be directly answered using the text, but the text is related to the research topic, please provide \
|
||||
a comprehensive summary of the text.
|
||||
|
|
@ -58,10 +57,10 @@ a comprehensive summary of the text.
|
|||
|
||||
### Reference Information
|
||||
{content}
|
||||
'''
|
||||
"""
|
||||
|
||||
|
||||
CONDUCT_RESEARCH_PROMPT = '''### Reference Information
|
||||
CONDUCT_RESEARCH_PROMPT = """### Reference Information
|
||||
{content}
|
||||
|
||||
### Requirements
|
||||
|
|
@ -73,11 +72,12 @@ above. The report must meet the following requirements:
|
|||
- Present data and findings in an intuitive manner, utilizing feature comparative tables, if applicable.
|
||||
- The report should have a minimum word count of 2,000 and be formatted with Markdown syntax following APA style guidelines.
|
||||
- Include all source URLs in APA format at the end of the report.
|
||||
'''
|
||||
"""
|
||||
|
||||
|
||||
class CollectLinks(Action):
|
||||
"""Action class to collect links from a search engine."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
name: str = "",
|
||||
|
|
@ -114,19 +114,24 @@ class CollectLinks(Action):
|
|||
keywords = OutputParser.extract_struct(keywords, list)
|
||||
keywords = parse_obj_as(list[str], keywords)
|
||||
except Exception as e:
|
||||
logger.exception(f"fail to get keywords related to the research topic \"{topic}\" for {e}")
|
||||
logger.exception(f"fail to get keywords related to the research topic '{topic}' for {e}")
|
||||
keywords = [topic]
|
||||
results = await asyncio.gather(*(self.search_engine.run(i, as_string=False) for i in keywords))
|
||||
|
||||
def gen_msg():
|
||||
while True:
|
||||
search_results = "\n".join(f"#### Keyword: {i}\n Search Result: {j}\n" for (i, j) in zip(keywords, results))
|
||||
prompt = SUMMARIZE_SEARCH_PROMPT.format(decomposition_nums=decomposition_nums, search_results=search_results)
|
||||
search_results = "\n".join(
|
||||
f"#### Keyword: {i}\n Search Result: {j}\n" for (i, j) in zip(keywords, results)
|
||||
)
|
||||
prompt = SUMMARIZE_SEARCH_PROMPT.format(
|
||||
decomposition_nums=decomposition_nums, search_results=search_results
|
||||
)
|
||||
yield prompt
|
||||
remove = max(results, key=len)
|
||||
remove.pop()
|
||||
if len(remove) == 0:
|
||||
break
|
||||
|
||||
prompt = reduce_message_length(gen_msg(), self.llm.model, system_text, CONFIG.max_tokens_rsp)
|
||||
logger.debug(prompt)
|
||||
queries = await self._aask(prompt, [system_text])
|
||||
|
|
@ -172,6 +177,7 @@ class CollectLinks(Action):
|
|||
|
||||
class WebBrowseAndSummarize(Action):
|
||||
"""Action class to explore the web and provide summaries of articles and webpages."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
*args,
|
||||
|
|
@ -214,7 +220,9 @@ class WebBrowseAndSummarize(Action):
|
|||
for u, content in zip([url, *urls], contents):
|
||||
content = content.inner_text
|
||||
chunk_summaries = []
|
||||
for prompt in generate_prompt_chunk(content, prompt_template, self.llm.model, system_text, CONFIG.max_tokens_rsp):
|
||||
for prompt in generate_prompt_chunk(
|
||||
content, prompt_template, self.llm.model, system_text, CONFIG.max_tokens_rsp
|
||||
):
|
||||
logger.debug(prompt)
|
||||
summary = await self._aask(prompt, [system_text])
|
||||
if summary == "Not relevant.":
|
||||
|
|
@ -238,6 +246,7 @@ class WebBrowseAndSummarize(Action):
|
|||
|
||||
class ConductResearch(Action):
|
||||
"""Action class to conduct research and generate a research report."""
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
if CONFIG.model_for_researcher_report:
|
||||
|
|
|
|||
|
|
@ -4,14 +4,28 @@
|
|||
@Time : 2023/5/11 17:46
|
||||
@Author : alexanderwu
|
||||
@File : run_code.py
|
||||
@Modified By: mashenquan, 2023/11/27.
|
||||
1. Mark the location of Console logs in the PROMPT_TEMPLATE with markdown code-block formatting to enhance
|
||||
the understanding for the LLM.
|
||||
2. Fix bug: Add the "install dependency" operation.
|
||||
3. Encapsulate the input of RunCode into RunCodeContext and encapsulate the output of RunCode into
|
||||
RunCodeResult to standardize and unify parameter passing between WriteCode, RunCode, and DebugError.
|
||||
4. According to section 2.2.3.5.7 of RFC 135, change the method of transferring file content
|
||||
(code files, unit test files, log files) from using the message to using the file name.
|
||||
5. Merged the `Config` class of send18:dev branch to take over the set/get operations of the Environment
|
||||
class.
|
||||
"""
|
||||
import os
|
||||
import subprocess
|
||||
import traceback
|
||||
from typing import Tuple
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.llm import LLM, BaseGPTAPI
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import RunCodeContext, RunCodeResult
|
||||
from metagpt.utils.exceptions import handle_exception
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
Role: You are a senior development and qa engineer, your role is summarize the code running result.
|
||||
|
|
@ -51,25 +65,29 @@ CONTEXT = """
|
|||
## Running Command
|
||||
{command}
|
||||
## Running Output
|
||||
standard output: {outs};
|
||||
standard errors: {errs};
|
||||
standard output:
|
||||
```text
|
||||
{outs}
|
||||
```
|
||||
standard errors:
|
||||
```text
|
||||
{errs}
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
class RunCode(Action):
|
||||
def __init__(self, name="RunCode", context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
name: str = "RunCode"
|
||||
context: RunCodeContext = Field(default_factory=RunCodeContext)
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
|
||||
@classmethod
|
||||
@handle_exception
|
||||
async def run_text(cls, code) -> Tuple[str, str]:
|
||||
try:
|
||||
# We will document_store the result in this dictionary
|
||||
namespace = {}
|
||||
exec(code, namespace)
|
||||
return namespace.get("result", ""), ""
|
||||
except Exception:
|
||||
# If there is an error in the code, return the error message
|
||||
return "", traceback.format_exc()
|
||||
# We will document_store the result in this dictionary
|
||||
namespace = {}
|
||||
exec(code, namespace)
|
||||
return namespace.get("result", ""), ""
|
||||
|
||||
@classmethod
|
||||
async def run_script(cls, working_directory, additional_python_paths=[], command=[]) -> Tuple[str, str]:
|
||||
|
|
@ -77,17 +95,19 @@ class RunCode(Action):
|
|||
additional_python_paths = [str(path) for path in additional_python_paths]
|
||||
|
||||
# Copy the current environment variables
|
||||
env = os.environ.copy()
|
||||
env = CONFIG.new_environ()
|
||||
|
||||
# Modify the PYTHONPATH environment variable
|
||||
additional_python_paths = [working_directory] + additional_python_paths
|
||||
additional_python_paths = ":".join(additional_python_paths)
|
||||
env["PYTHONPATH"] = additional_python_paths + ":" + env.get("PYTHONPATH", "")
|
||||
RunCode._install_dependencies(working_directory=working_directory, env=env)
|
||||
|
||||
# Start the subprocess
|
||||
process = subprocess.Popen(
|
||||
command, cwd=working_directory, stdout=subprocess.PIPE, stderr=subprocess.PIPE, env=env
|
||||
)
|
||||
logger.info(" ".join(command))
|
||||
|
||||
try:
|
||||
# Wait for the process to complete, with a timeout
|
||||
|
|
@ -98,31 +118,45 @@ class RunCode(Action):
|
|||
stdout, stderr = process.communicate()
|
||||
return stdout.decode("utf-8"), stderr.decode("utf-8")
|
||||
|
||||
async def run(
|
||||
self, code, mode="script", code_file_name="", test_code="", test_file_name="", command=[], **kwargs
|
||||
) -> str:
|
||||
logger.info(f"Running {' '.join(command)}")
|
||||
if mode == "script":
|
||||
outs, errs = await self.run_script(command=command, **kwargs)
|
||||
elif mode == "text":
|
||||
outs, errs = await self.run_text(code=code)
|
||||
async def run(self, *args, **kwargs) -> RunCodeResult:
|
||||
logger.info(f"Running {' '.join(self.context.command)}")
|
||||
if self.context.mode == "script":
|
||||
outs, errs = await self.run_script(
|
||||
command=self.context.command,
|
||||
working_directory=self.context.working_directory,
|
||||
additional_python_paths=self.context.additional_python_paths,
|
||||
)
|
||||
elif self.context.mode == "text":
|
||||
outs, errs = await self.run_text(code=self.context.code)
|
||||
|
||||
logger.info(f"{outs=}")
|
||||
logger.info(f"{errs=}")
|
||||
|
||||
context = CONTEXT.format(
|
||||
code=code,
|
||||
code_file_name=code_file_name,
|
||||
test_code=test_code,
|
||||
test_file_name=test_file_name,
|
||||
command=" ".join(command),
|
||||
code=self.context.code,
|
||||
code_file_name=self.context.code_filename,
|
||||
test_code=self.context.test_code,
|
||||
test_file_name=self.context.test_filename,
|
||||
command=" ".join(self.context.command),
|
||||
outs=outs[:500], # outs might be long but they are not important, truncate them to avoid token overflow
|
||||
errs=errs[:10000], # truncate errors to avoid token overflow
|
||||
)
|
||||
|
||||
prompt = PROMPT_TEMPLATE.format(context=context)
|
||||
rsp = await self._aask(prompt)
|
||||
return RunCodeResult(summary=rsp, stdout=outs, stderr=errs)
|
||||
|
||||
result = context + rsp
|
||||
@staticmethod
|
||||
@handle_exception(exception_type=subprocess.CalledProcessError)
|
||||
def _install_via_subprocess(cmd, check, cwd, env):
|
||||
return subprocess.run(cmd, check=check, cwd=cwd, env=env)
|
||||
|
||||
return result
|
||||
@staticmethod
|
||||
def _install_dependencies(working_directory, env):
|
||||
install_command = ["python", "-m", "pip", "install", "-r", "requirements.txt"]
|
||||
logger.info(" ".join(install_command))
|
||||
RunCode._install_via_subprocess(install_command, check=True, cwd=working_directory, env=env)
|
||||
|
||||
install_pytest_command = ["python", "-m", "pip", "install", "pytest"]
|
||||
logger.info(" ".join(install_pytest_command))
|
||||
RunCode._install_via_subprocess(install_pytest_command, check=True, cwd=working_directory, env=env)
|
||||
|
|
|
|||
|
|
@ -5,11 +5,16 @@
|
|||
@Author : alexanderwu
|
||||
@File : search_google.py
|
||||
"""
|
||||
from typing import Optional
|
||||
|
||||
import pydantic
|
||||
from pydantic import Field, root_validator
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.config import Config
|
||||
from metagpt.config import CONFIG, Config
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.schema import Message
|
||||
from metagpt.tools.search_engine import SearchEngine
|
||||
|
||||
|
|
@ -54,7 +59,6 @@ SEARCH_AND_SUMMARIZE_PROMPT = """
|
|||
|
||||
"""
|
||||
|
||||
|
||||
SEARCH_AND_SUMMARIZE_SALES_SYSTEM = """## Requirements
|
||||
1. Please summarize the latest dialogue based on the reference information (secondary) and dialogue history (primary). Do not include text that is irrelevant to the conversation.
|
||||
- The context is for reference only. If it is irrelevant to the user's search request history, please reduce its reference and usage.
|
||||
|
|
@ -101,17 +105,31 @@ You are a member of a professional butler team and will provide helpful suggesti
|
|||
|
||||
|
||||
class SearchAndSummarize(Action):
|
||||
def __init__(self, name="", context=None, llm=None, engine=None, search_func=None):
|
||||
self.config = Config()
|
||||
self.engine = engine or self.config.search_engine
|
||||
name: str = ""
|
||||
content: Optional[str] = None
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
config: None = Field(default_factory=Config)
|
||||
engine: Optional[str] = CONFIG.search_engine
|
||||
search_func: Optional[str] = None
|
||||
search_engine: SearchEngine = None
|
||||
|
||||
result = ""
|
||||
|
||||
@root_validator
|
||||
def validate_engine_and_run_func(cls, values):
|
||||
engine = values.get("engine")
|
||||
search_func = values.get("search_func")
|
||||
config = Config()
|
||||
|
||||
if engine is None:
|
||||
engine = config.search_engine
|
||||
try:
|
||||
self.search_engine = SearchEngine(self.engine, run_func=search_func)
|
||||
search_engine = SearchEngine(engine=engine, run_func=search_func)
|
||||
except pydantic.ValidationError:
|
||||
self.search_engine = None
|
||||
search_engine = None
|
||||
|
||||
self.result = ""
|
||||
super().__init__(name, context, llm)
|
||||
values["search_engine"] = search_engine
|
||||
return values
|
||||
|
||||
async def run(self, context: list[Message], system_text=SEARCH_AND_SUMMARIZE_SYSTEM) -> str:
|
||||
if self.search_engine is None:
|
||||
|
|
@ -130,8 +148,7 @@ class SearchAndSummarize(Action):
|
|||
system_prompt = [system_text]
|
||||
|
||||
prompt = SEARCH_AND_SUMMARIZE_PROMPT.format(
|
||||
# PREFIX = self.prefix,
|
||||
ROLE=self.profile,
|
||||
ROLE=self.prefix,
|
||||
CONTEXT=rsp,
|
||||
QUERY_HISTORY="\n".join([str(i) for i in context[:-1]]),
|
||||
QUERY=str(context[-1]),
|
||||
|
|
@ -140,4 +157,3 @@ class SearchAndSummarize(Action):
|
|||
logger.debug(prompt)
|
||||
logger.debug(result)
|
||||
return result
|
||||
|
||||
124
metagpt/actions/summarize_code.py
Normal file
124
metagpt/actions/summarize_code.py
Normal file
|
|
@ -0,0 +1,124 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Author : alexanderwu
|
||||
@File : summarize_code.py
|
||||
@Modified By: mashenquan, 2023/12/5. Archive the summarization content of issue discovery for use in WriteCode.
|
||||
"""
|
||||
from pathlib import Path
|
||||
|
||||
from pydantic import Field
|
||||
from tenacity import retry, stop_after_attempt, wait_random_exponential
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import SYSTEM_DESIGN_FILE_REPO, TASK_FILE_REPO
|
||||
from metagpt.llm import LLM, BaseGPTAPI
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import CodeSummarizeContext
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
NOTICE
|
||||
Role: You are a professional software engineer, and your main task is to review the code.
|
||||
Language: Please use the same language as the user requirement, but the title and code should be still in English. For example, if the user speaks Chinese, the specific text of your answer should also be in Chinese.
|
||||
ATTENTION: Use '##' to SPLIT SECTIONS, not '#'. Output format carefully referenced "Format example".
|
||||
|
||||
-----
|
||||
# System Design
|
||||
```text
|
||||
{system_design}
|
||||
```
|
||||
-----
|
||||
# Tasks
|
||||
```text
|
||||
{tasks}
|
||||
```
|
||||
-----
|
||||
{code_blocks}
|
||||
|
||||
## Code Review All: Please read all historical files and find possible bugs in the files, such as unimplemented functions, calling errors, unreferences, etc.
|
||||
|
||||
## Call flow: mermaid code, based on the implemented function, use mermaid to draw a complete call chain
|
||||
|
||||
## Summary: Summary based on the implementation of historical files
|
||||
|
||||
## TODOs: Python dict[str, str], write down the list of files that need to be modified and the reasons. We will modify them later.
|
||||
|
||||
"""
|
||||
|
||||
FORMAT_EXAMPLE = """
|
||||
|
||||
## Code Review All
|
||||
|
||||
### a.py
|
||||
- It fulfills less of xxx requirements...
|
||||
- Field yyy is not given...
|
||||
-...
|
||||
|
||||
### b.py
|
||||
...
|
||||
|
||||
### c.py
|
||||
...
|
||||
|
||||
## Call flow
|
||||
```mermaid
|
||||
flowchart TB
|
||||
c1-->a2
|
||||
subgraph one
|
||||
a1-->a2
|
||||
end
|
||||
subgraph two
|
||||
b1-->b2
|
||||
end
|
||||
subgraph three
|
||||
c1-->c2
|
||||
end
|
||||
```
|
||||
|
||||
## Summary
|
||||
- a.py:...
|
||||
- b.py:...
|
||||
- c.py:...
|
||||
- ...
|
||||
|
||||
## TODOs
|
||||
{
|
||||
"a.py": "implement requirement xxx...",
|
||||
}
|
||||
|
||||
"""
|
||||
|
||||
|
||||
class SummarizeCode(Action):
|
||||
name: str = "SummarizeCode"
|
||||
context: CodeSummarizeContext = Field(default_factory=CodeSummarizeContext)
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
|
||||
@retry(stop=stop_after_attempt(2), wait=wait_random_exponential(min=1, max=60))
|
||||
async def summarize_code(self, prompt):
|
||||
code_rsp = await self._aask(prompt)
|
||||
return code_rsp
|
||||
|
||||
async def run(self):
|
||||
design_pathname = Path(self.context.design_filename)
|
||||
design_doc = await FileRepository.get_file(filename=design_pathname.name, relative_path=SYSTEM_DESIGN_FILE_REPO)
|
||||
task_pathname = Path(self.context.task_filename)
|
||||
task_doc = await FileRepository.get_file(filename=task_pathname.name, relative_path=TASK_FILE_REPO)
|
||||
src_file_repo = CONFIG.git_repo.new_file_repository(relative_path=CONFIG.src_workspace)
|
||||
code_blocks = []
|
||||
for filename in self.context.codes_filenames:
|
||||
code_doc = await src_file_repo.get(filename)
|
||||
code_block = f"```python\n{code_doc.content}\n```\n-----"
|
||||
code_blocks.append(code_block)
|
||||
format_example = FORMAT_EXAMPLE
|
||||
prompt = PROMPT_TEMPLATE.format(
|
||||
system_design=design_doc.content,
|
||||
tasks=task_doc.content,
|
||||
code_blocks="\n".join(code_blocks),
|
||||
format_example=format_example,
|
||||
)
|
||||
logger.info("Summarize code..")
|
||||
rsp = await self.summarize_code(prompt)
|
||||
return rsp
|
||||
|
|
@ -4,79 +4,154 @@
|
|||
@Time : 2023/5/11 17:45
|
||||
@Author : alexanderwu
|
||||
@File : write_code.py
|
||||
@Modified By: mashenquan, 2023-11-1. In accordance with Chapter 2.1.3 of RFC 116, modify the data type of the `cause_by`
|
||||
value of the `Message` object.
|
||||
@Modified By: mashenquan, 2023-11-27.
|
||||
1. Mark the location of Design, Tasks, Legacy Code and Debug logs in the PROMPT_TEMPLATE with markdown
|
||||
code-block formatting to enhance the understanding for the LLM.
|
||||
2. Following the think-act principle, solidify the task parameters when creating the WriteCode object, rather
|
||||
than passing them in when calling the run function.
|
||||
3. Encapsulate the input of RunCode into RunCodeContext and encapsulate the output of RunCode into
|
||||
RunCodeResult to standardize and unify parameter passing between WriteCode, RunCode, and DebugError.
|
||||
"""
|
||||
from metagpt.actions import WriteDesign
|
||||
|
||||
import json
|
||||
|
||||
from pydantic import Field
|
||||
from tenacity import retry, stop_after_attempt, wait_random_exponential
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.const import WORKSPACE_ROOT
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import (
|
||||
BUGFIX_FILENAME,
|
||||
CODE_SUMMARIES_FILE_REPO,
|
||||
DOCS_FILE_REPO,
|
||||
TASK_FILE_REPO,
|
||||
TEST_OUTPUTS_FILE_REPO,
|
||||
)
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Message
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.schema import CodingContext, Document, RunCodeResult
|
||||
from metagpt.utils.common import CodeParser
|
||||
from tenacity import retry, stop_after_attempt, wait_fixed
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
NOTICE
|
||||
Role: You are a professional engineer; the main goal is to write PEP8 compliant, elegant, modular, easy to read and maintain Python 3.9 code (but you can also use other programming language)
|
||||
Role: You are a professional engineer; the main goal is to write google-style, elegant, modular, easy to read and maintain code
|
||||
Language: Please use the same language as the user requirement, but the title and code should be still in English. For example, if the user speaks Chinese, the specific text of your answer should also be in Chinese.
|
||||
ATTENTION: Use '##' to SPLIT SECTIONS, not '#'. Output format carefully referenced "Format example".
|
||||
|
||||
## Code: {filename} Write code with triple quoto, based on the following list and context.
|
||||
1. Do your best to implement THIS ONLY ONE FILE. ONLY USE EXISTING API. IF NO API, IMPLEMENT IT.
|
||||
2. Requirement: Based on the context, implement one following code file, note to return only in code form, your code will be part of the entire project, so please implement complete, reliable, reusable code snippets
|
||||
3. Attention1: If there is any setting, ALWAYS SET A DEFAULT VALUE, ALWAYS USE STRONG TYPE AND EXPLICIT VARIABLE.
|
||||
4. Attention2: YOU MUST FOLLOW "Data structures and interface definitions". DONT CHANGE ANY DESIGN.
|
||||
5. Think before writing: What should be implemented and provided in this document?
|
||||
6. CAREFULLY CHECK THAT YOU DONT MISS ANY NECESSARY CLASS/FUNCTION IN THIS FILE.
|
||||
7. Do not use public member functions that do not exist in your design.
|
||||
|
||||
-----
|
||||
# Context
|
||||
{context}
|
||||
-----
|
||||
## Format example
|
||||
-----
|
||||
## Design
|
||||
{design}
|
||||
|
||||
## Tasks
|
||||
{tasks}
|
||||
|
||||
## Legacy Code
|
||||
```Code
|
||||
{code}
|
||||
```
|
||||
|
||||
## Debug logs
|
||||
```text
|
||||
{logs}
|
||||
|
||||
{summary_log}
|
||||
```
|
||||
|
||||
## Bug Feedback logs
|
||||
```text
|
||||
{feedback}
|
||||
```
|
||||
|
||||
# Format example
|
||||
## Code: {filename}
|
||||
```python
|
||||
## {filename}
|
||||
...
|
||||
```
|
||||
-----
|
||||
|
||||
# Instruction: Based on the context, follow "Format example", write code.
|
||||
|
||||
## Code: {filename}. Write code with triple quoto, based on the following attentions and context.
|
||||
1. Only One file: do your best to implement THIS ONLY ONE FILE.
|
||||
2. COMPLETE CODE: Your code will be part of the entire project, so please implement complete, reliable, reusable code snippets.
|
||||
3. Set default value: If there is any setting, ALWAYS SET A DEFAULT VALUE, ALWAYS USE STRONG TYPE AND EXPLICIT VARIABLE. AVOID circular import.
|
||||
4. Follow design: YOU MUST FOLLOW "Data structures and interfaces". DONT CHANGE ANY DESIGN. Do not use public member functions that do not exist in your design.
|
||||
5. CAREFULLY CHECK THAT YOU DONT MISS ANY NECESSARY CLASS/FUNCTION IN THIS FILE.
|
||||
6. Before using a external variable/module, make sure you import it first.
|
||||
7. Write out EVERY CODE DETAIL, DON'T LEAVE TODO.
|
||||
|
||||
"""
|
||||
|
||||
|
||||
class WriteCode(Action):
|
||||
def __init__(self, name="WriteCode", context: list[Message] = None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
name: str = "WriteCode"
|
||||
context: Document = Field(default_factory=Document)
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
|
||||
def _is_invalid(self, filename):
|
||||
return any(i in filename for i in ["mp3", "wav"])
|
||||
|
||||
def _save(self, context, filename, code):
|
||||
# logger.info(filename)
|
||||
# logger.info(code_rsp)
|
||||
if self._is_invalid(filename):
|
||||
return
|
||||
|
||||
design = [i for i in context if i.cause_by == WriteDesign][0]
|
||||
|
||||
ws_name = CodeParser.parse_str(block="Python package name", text=design.content)
|
||||
ws_path = WORKSPACE_ROOT / ws_name
|
||||
if f"{ws_name}/" not in filename and all(i not in filename for i in ["requirements.txt", ".md"]):
|
||||
ws_path = ws_path / ws_name
|
||||
code_path = ws_path / filename
|
||||
code_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
code_path.write_text(code)
|
||||
logger.info(f"Saving Code to {code_path}")
|
||||
|
||||
@retry(stop=stop_after_attempt(2), wait=wait_fixed(1))
|
||||
async def write_code(self, prompt):
|
||||
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
|
||||
async def write_code(self, prompt) -> str:
|
||||
code_rsp = await self._aask(prompt)
|
||||
code = CodeParser.parse_code(block="", text=code_rsp)
|
||||
return code
|
||||
|
||||
async def run(self, context, filename):
|
||||
prompt = PROMPT_TEMPLATE.format(context=context, filename=filename)
|
||||
logger.info(f'Writing {filename}..')
|
||||
async def run(self, *args, **kwargs) -> CodingContext:
|
||||
bug_feedback = await FileRepository.get_file(filename=BUGFIX_FILENAME, relative_path=DOCS_FILE_REPO)
|
||||
coding_context = CodingContext.loads(self.context.content)
|
||||
test_doc = await FileRepository.get_file(
|
||||
filename="test_" + coding_context.filename + ".json", relative_path=TEST_OUTPUTS_FILE_REPO
|
||||
)
|
||||
summary_doc = None
|
||||
if coding_context.design_doc and coding_context.design_doc.filename:
|
||||
summary_doc = await FileRepository.get_file(
|
||||
filename=coding_context.design_doc.filename, relative_path=CODE_SUMMARIES_FILE_REPO
|
||||
)
|
||||
logs = ""
|
||||
if test_doc:
|
||||
test_detail = RunCodeResult.loads(test_doc.content)
|
||||
logs = test_detail.stderr
|
||||
|
||||
if bug_feedback:
|
||||
code_context = coding_context.code_doc.content
|
||||
else:
|
||||
code_context = await self.get_codes(coding_context.task_doc, exclude=self.context.filename)
|
||||
|
||||
prompt = PROMPT_TEMPLATE.format(
|
||||
design=coding_context.design_doc.content if coding_context.design_doc else "",
|
||||
tasks=coding_context.task_doc.content if coding_context.task_doc else "",
|
||||
code=code_context,
|
||||
logs=logs,
|
||||
feedback=bug_feedback.content if bug_feedback else "",
|
||||
filename=self.context.filename,
|
||||
summary_log=summary_doc.content if summary_doc else "",
|
||||
)
|
||||
logger.info(f"Writing {coding_context.filename}..")
|
||||
code = await self.write_code(prompt)
|
||||
# code_rsp = await self._aask_v1(prompt, "code_rsp", OUTPUT_MAPPING)
|
||||
# self._save(context, filename, code)
|
||||
return code
|
||||
|
||||
if not coding_context.code_doc:
|
||||
# avoid root_path pydantic ValidationError if use WriteCode alone
|
||||
root_path = CONFIG.src_workspace if CONFIG.src_workspace else ""
|
||||
coding_context.code_doc = Document(filename=coding_context.filename, root_path=root_path)
|
||||
coding_context.code_doc.content = code
|
||||
return coding_context
|
||||
|
||||
@staticmethod
|
||||
async def get_codes(task_doc, exclude) -> str:
|
||||
if not task_doc:
|
||||
return ""
|
||||
if not task_doc.content:
|
||||
task_doc.content = FileRepository.get_file(filename=task_doc.filename, relative_path=TASK_FILE_REPO)
|
||||
m = json.loads(task_doc.content)
|
||||
code_filenames = m.get("Task list", [])
|
||||
codes = []
|
||||
src_file_repo = CONFIG.git_repo.new_file_repository(relative_path=CONFIG.src_workspace)
|
||||
for filename in code_filenames:
|
||||
if filename == exclude:
|
||||
continue
|
||||
doc = await src_file_repo.get(filename=filename)
|
||||
if not doc:
|
||||
continue
|
||||
codes.append(f"----- {filename}\n" + doc.content)
|
||||
return "\n".join(codes)
|
||||
|
|
|
|||
591
metagpt/actions/write_code_an_draft.py
Normal file
591
metagpt/actions/write_code_an_draft.py
Normal file
|
|
@ -0,0 +1,591 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Author : alexanderwu
|
||||
@File : write_review.py
|
||||
"""
|
||||
import asyncio
|
||||
from typing import List
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
|
||||
REVIEW = ActionNode(
|
||||
key="Review",
|
||||
expected_type=List[str],
|
||||
instruction="Act as an experienced reviewer and critically assess the given output. Provide specific and"
|
||||
" constructive feedback, highlighting areas for improvement and suggesting changes.",
|
||||
example=[
|
||||
"The logic in the function `calculate_total` seems flawed. Shouldn't it consider the discount rate as well?",
|
||||
"The TODO function is not implemented yet? Should we implement it before commit?",
|
||||
],
|
||||
)
|
||||
|
||||
LGTM = ActionNode(
|
||||
key="LGTM",
|
||||
expected_type=str,
|
||||
instruction="LGTM/LBTM. If the code is fully implemented, "
|
||||
"give a LGTM (Looks Good To Me), otherwise provide a LBTM (Looks Bad To Me).",
|
||||
example="LBTM",
|
||||
)
|
||||
|
||||
ACTIONS = ActionNode(
|
||||
key="Actions",
|
||||
expected_type=str,
|
||||
instruction="Based on the code review outcome, suggest actionable steps. This can include code changes, "
|
||||
"refactoring suggestions, or any follow-up tasks.",
|
||||
example="""1. Refactor the `process_data` method to improve readability and efficiency.
|
||||
2. Cover edge cases in the `validate_user` function.
|
||||
3. Implement a the TODO in the `calculate_total` function.
|
||||
4. Fix the `handle_events` method to update the game state only if a move is successful.
|
||||
```python
|
||||
def handle_events(self):
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
return False
|
||||
if event.type == pygame.KEYDOWN:
|
||||
moved = False
|
||||
if event.key == pygame.K_UP:
|
||||
moved = self.game.move('UP')
|
||||
elif event.key == pygame.K_DOWN:
|
||||
moved = self.game.move('DOWN')
|
||||
elif event.key == pygame.K_LEFT:
|
||||
moved = self.game.move('LEFT')
|
||||
elif event.key == pygame.K_RIGHT:
|
||||
moved = self.game.move('RIGHT')
|
||||
if moved:
|
||||
# Update the game state only if a move was successful
|
||||
self.render()
|
||||
return True
|
||||
```
|
||||
""",
|
||||
)
|
||||
|
||||
WRITE_DRAFT = ActionNode(
|
||||
key="WriteDraft",
|
||||
expected_type=str,
|
||||
instruction="Could you write draft code for move function in order to implement it?",
|
||||
example="Draft: ...",
|
||||
)
|
||||
|
||||
|
||||
WRITE_MOVE_FUNCTION = ActionNode(
|
||||
key="WriteFunction",
|
||||
expected_type=str,
|
||||
instruction="write code for the function not implemented.",
|
||||
example="""
|
||||
```Code
|
||||
...
|
||||
```
|
||||
""",
|
||||
)
|
||||
|
||||
|
||||
REWRITE_CODE = ActionNode(
|
||||
key="RewriteCode",
|
||||
expected_type=str,
|
||||
instruction="""rewrite code based on the Review and Actions""",
|
||||
example="""
|
||||
```python
|
||||
## example.py
|
||||
def calculate_total(price, quantity):
|
||||
total = price * quantity
|
||||
```
|
||||
""",
|
||||
)
|
||||
|
||||
|
||||
CODE_REVIEW_CONTEXT = """
|
||||
# System
|
||||
Role: You are a professional software engineer, and your main task is to review and revise the code. You need to ensure that the code conforms to the google-style standards, is elegantly designed and modularized, easy to read and maintain.
|
||||
Language: Please use the same language as the user requirement, but the title and code should be still in English. For example, if the user speaks Chinese, the specific text of your answer should also be in Chinese.
|
||||
|
||||
# Context
|
||||
## System Design
|
||||
{"Implementation approach": "我们将使用HTML、CSS和JavaScript来实现这个单机的响应式2048游戏。为了确保游戏性能流畅和响应式设计,我们会选择使用Vue.js框架,因为它易于上手且适合构建交互式界面。我们还将使用localStorage来记录玩家的最高分。", "File list": ["index.html", "styles.css", "main.js", "game.js", "storage.js"], "Data structures and interfaces": "classDiagram\
|
||||
class Game {\
|
||||
-board Array\
|
||||
-score Number\
|
||||
-bestScore Number\
|
||||
+constructor()\
|
||||
+startGame()\
|
||||
+move(direction: String)\
|
||||
+getBoard() Array\
|
||||
+getScore() Number\
|
||||
+getBestScore() Number\
|
||||
+setBestScore(score: Number)\
|
||||
}\
|
||||
class Storage {\
|
||||
+getBestScore() Number\
|
||||
+setBestScore(score: Number)\
|
||||
}\
|
||||
class Main {\
|
||||
+init()\
|
||||
+bindEvents()\
|
||||
}\
|
||||
Game --> Storage : uses\
|
||||
Main --> Game : uses", "Program call flow": "sequenceDiagram\
|
||||
participant M as Main\
|
||||
participant G as Game\
|
||||
participant S as Storage\
|
||||
M->>G: init()\
|
||||
G->>S: getBestScore()\
|
||||
S-->>G: return bestScore\
|
||||
M->>G: bindEvents()\
|
||||
M->>G: startGame()\
|
||||
loop Game Loop\
|
||||
M->>G: move(direction)\
|
||||
G->>S: setBestScore(score)\
|
||||
S-->>G: return\
|
||||
end", "Anything UNCLEAR": "目前项目要求明确,没有不清楚的地方。"}
|
||||
|
||||
## Tasks
|
||||
{"Required Python packages": ["无需Python包"], "Required Other language third-party packages": ["vue.js"], "Logic Analysis": [["index.html", "作为游戏的入口文件和主要的HTML结构"], ["styles.css", "包含所有的CSS样式,确保游戏界面美观"], ["main.js", "包含Main类,负责初始化游戏和绑定事件"], ["game.js", "包含Game类,负责游戏逻辑,如开始游戏、移动方块等"], ["storage.js", "包含Storage类,用于获取和设置玩家的最高分"]], "Task list": ["index.html", "styles.css", "storage.js", "game.js", "main.js"], "Full API spec": "", "Shared Knowledge": "\'game.js\' 包含游戏逻辑相关的函数,被 \'main.js\' 调用。", "Anything UNCLEAR": "目前项目要求明确,没有不清楚的地方。"}
|
||||
|
||||
## Code Files
|
||||
----- index.html
|
||||
<!DOCTYPE html>
|
||||
<html lang="zh-CN">
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title>2048游戏</title>
|
||||
<link rel="stylesheet" href="styles.css">
|
||||
<script src="https://cdn.jsdelivr.net/npm/vue@2.6.14/dist/vue.js"></script>
|
||||
</head>
|
||||
<body>
|
||||
<div id="app">
|
||||
<h1>2048</h1>
|
||||
<div class="scores-container">
|
||||
<div class="score-container">
|
||||
<div class="score-header">分数</div>
|
||||
<div>{{ score }}</div>
|
||||
</div>
|
||||
<div class="best-container">
|
||||
<div class="best-header">最高分</div>
|
||||
<div>{{ bestScore }}</div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="game-container">
|
||||
<div v-for="(row, rowIndex) in board" :key="rowIndex" class="grid-row">
|
||||
<div v-for="(cell, cellIndex) in row" :key="cellIndex" class="grid-cell" :class="\'number-cell-\' + cell">
|
||||
{{ cell !== 0 ? cell : \'\' }}
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<button @click="startGame" aria-label="开始新游戏">新游戏</button>
|
||||
</div>
|
||||
|
||||
<script src="storage.js"></script>
|
||||
<script src="game.js"></script>
|
||||
<script src="main.js"></script>
|
||||
<script src="app.js"></script>
|
||||
</body>
|
||||
</html>
|
||||
|
||||
----- styles.css
|
||||
/* styles.css */
|
||||
body, html {
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
font-family: \'Arial\', sans-serif;
|
||||
}
|
||||
|
||||
#app {
|
||||
text-align: center;
|
||||
font-size: 18px;
|
||||
color: #776e65;
|
||||
}
|
||||
|
||||
h1 {
|
||||
color: #776e65;
|
||||
font-size: 72px;
|
||||
font-weight: bold;
|
||||
margin: 20px 0;
|
||||
}
|
||||
|
||||
.scores-container {
|
||||
display: flex;
|
||||
justify-content: center;
|
||||
margin-bottom: 20px;
|
||||
}
|
||||
|
||||
.score-container, .best-container {
|
||||
background: #bbada0;
|
||||
padding: 10px;
|
||||
border-radius: 5px;
|
||||
margin: 0 10px;
|
||||
min-width: 100px;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
.score-header, .best-header {
|
||||
color: #eee4da;
|
||||
font-size: 18px;
|
||||
margin-bottom: 5px;
|
||||
}
|
||||
|
||||
.game-container {
|
||||
max-width: 500px;
|
||||
margin: 0 auto 20px;
|
||||
background: #bbada0;
|
||||
padding: 15px;
|
||||
border-radius: 10px;
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.grid-row {
|
||||
display: flex;
|
||||
}
|
||||
|
||||
.grid-cell {
|
||||
background: #cdc1b4;
|
||||
width: 100px;
|
||||
height: 100px;
|
||||
margin: 5px;
|
||||
display: flex;
|
||||
justify-content: center;
|
||||
align-items: center;
|
||||
font-size: 35px;
|
||||
font-weight: bold;
|
||||
color: #776e65;
|
||||
border-radius: 3px;
|
||||
}
|
||||
|
||||
/* Dynamic classes for different number cells */
|
||||
.number-cell-2 {
|
||||
background: #eee4da;
|
||||
}
|
||||
|
||||
.number-cell-4 {
|
||||
background: #ede0c8;
|
||||
}
|
||||
|
||||
.number-cell-8 {
|
||||
background: #f2b179;
|
||||
color: #f9f6f2;
|
||||
}
|
||||
|
||||
.number-cell-16 {
|
||||
background: #f59563;
|
||||
color: #f9f6f2;
|
||||
}
|
||||
|
||||
.number-cell-32 {
|
||||
background: #f67c5f;
|
||||
color: #f9f6f2;
|
||||
}
|
||||
|
||||
.number-cell-64 {
|
||||
background: #f65e3b;
|
||||
color: #f9f6f2;
|
||||
}
|
||||
|
||||
.number-cell-128 {
|
||||
background: #edcf72;
|
||||
color: #f9f6f2;
|
||||
}
|
||||
|
||||
.number-cell-256 {
|
||||
background: #edcc61;
|
||||
color: #f9f6f2;
|
||||
}
|
||||
|
||||
.number-cell-512 {
|
||||
background: #edc850;
|
||||
color: #f9f6f2;
|
||||
}
|
||||
|
||||
.number-cell-1024 {
|
||||
background: #edc53f;
|
||||
color: #f9f6f2;
|
||||
}
|
||||
|
||||
.number-cell-2048 {
|
||||
background: #edc22e;
|
||||
color: #f9f6f2;
|
||||
}
|
||||
|
||||
/* Larger numbers need smaller font sizes */
|
||||
.number-cell-1024, .number-cell-2048 {
|
||||
font-size: 30px;
|
||||
}
|
||||
|
||||
button {
|
||||
background-color: #8f7a66;
|
||||
color: #f9f6f2;
|
||||
border: none;
|
||||
border-radius: 3px;
|
||||
padding: 10px 20px;
|
||||
font-size: 18px;
|
||||
cursor: pointer;
|
||||
outline: none;
|
||||
}
|
||||
|
||||
button:hover {
|
||||
background-color: #9f8b76;
|
||||
}
|
||||
|
||||
----- storage.js
|
||||
## storage.js
|
||||
class Storage {
|
||||
// 获取最高分
|
||||
getBestScore() {
|
||||
// 尝试从localStorage中获取最高分,如果不存在则默认为0
|
||||
const bestScore = localStorage.getItem(\'bestScore\');
|
||||
return bestScore ? Number(bestScore) : 0;
|
||||
}
|
||||
|
||||
// 设置最高分
|
||||
setBestScore(score) {
|
||||
// 将最高分设置到localStorage中
|
||||
localStorage.setItem(\'bestScore\', score.toString());
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
## Code to be Reviewed: game.js
|
||||
```Code
|
||||
## game.js
|
||||
class Game {
|
||||
constructor() {
|
||||
this.board = this.createEmptyBoard();
|
||||
this.score = 0;
|
||||
this.bestScore = 0;
|
||||
}
|
||||
|
||||
createEmptyBoard() {
|
||||
const board = [];
|
||||
for (let i = 0; i < 4; i++) {
|
||||
board[i] = [0, 0, 0, 0];
|
||||
}
|
||||
return board;
|
||||
}
|
||||
|
||||
startGame() {
|
||||
this.board = this.createEmptyBoard();
|
||||
this.score = 0;
|
||||
this.addRandomTile();
|
||||
this.addRandomTile();
|
||||
}
|
||||
|
||||
addRandomTile() {
|
||||
let emptyCells = [];
|
||||
for (let r = 0; r < 4; r++) {
|
||||
for (let c = 0; c < 4; c++) {
|
||||
if (this.board[r][c] === 0) {
|
||||
emptyCells.push({ r, c });
|
||||
}
|
||||
}
|
||||
}
|
||||
if (emptyCells.length > 0) {
|
||||
let randomCell = emptyCells[Math.floor(Math.random() * emptyCells.length)];
|
||||
this.board[randomCell.r][randomCell.c] = Math.random() < 0.9 ? 2 : 4;
|
||||
}
|
||||
}
|
||||
|
||||
move(direction) {
|
||||
// This function will handle the logic for moving tiles
|
||||
// in the specified direction and merging them
|
||||
// It will also update the score and add a new random tile if the move is successful
|
||||
// The actual implementation of this function is complex and would require
|
||||
// a significant amount of code to handle all the cases for moving and merging tiles
|
||||
// For the purposes of this example, we will not implement the full logic
|
||||
// Instead, we will just call addRandomTile to simulate a move
|
||||
this.addRandomTile();
|
||||
}
|
||||
|
||||
getBoard() {
|
||||
return this.board;
|
||||
}
|
||||
|
||||
getScore() {
|
||||
return this.score;
|
||||
}
|
||||
|
||||
getBestScore() {
|
||||
return this.bestScore;
|
||||
}
|
||||
|
||||
setBestScore(score) {
|
||||
this.bestScore = score;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
CODE_REVIEW_SMALLEST_CONTEXT = """
|
||||
## Code to be Reviewed: game.js
|
||||
```Code
|
||||
// game.js
|
||||
class Game {
|
||||
constructor() {
|
||||
this.board = this.createEmptyBoard();
|
||||
this.score = 0;
|
||||
this.bestScore = 0;
|
||||
}
|
||||
|
||||
createEmptyBoard() {
|
||||
const board = [];
|
||||
for (let i = 0; i < 4; i++) {
|
||||
board[i] = [0, 0, 0, 0];
|
||||
}
|
||||
return board;
|
||||
}
|
||||
|
||||
startGame() {
|
||||
this.board = this.createEmptyBoard();
|
||||
this.score = 0;
|
||||
this.addRandomTile();
|
||||
this.addRandomTile();
|
||||
}
|
||||
|
||||
addRandomTile() {
|
||||
let emptyCells = [];
|
||||
for (let r = 0; r < 4; r++) {
|
||||
for (let c = 0; c < 4; c++) {
|
||||
if (this.board[r][c] === 0) {
|
||||
emptyCells.push({ r, c });
|
||||
}
|
||||
}
|
||||
}
|
||||
if (emptyCells.length > 0) {
|
||||
let randomCell = emptyCells[Math.floor(Math.random() * emptyCells.length)];
|
||||
this.board[randomCell.r][randomCell.c] = Math.random() < 0.9 ? 2 : 4;
|
||||
}
|
||||
}
|
||||
|
||||
move(direction) {
|
||||
// This function will handle the logic for moving tiles
|
||||
// in the specified direction and merging them
|
||||
// It will also update the score and add a new random tile if the move is successful
|
||||
// The actual implementation of this function is complex and would require
|
||||
// a significant amount of code to handle all the cases for moving and merging tiles
|
||||
// For the purposes of this example, we will not implement the full logic
|
||||
// Instead, we will just call addRandomTile to simulate a move
|
||||
this.addRandomTile();
|
||||
}
|
||||
|
||||
getBoard() {
|
||||
return this.board;
|
||||
}
|
||||
|
||||
getScore() {
|
||||
return this.score;
|
||||
}
|
||||
|
||||
getBestScore() {
|
||||
return this.bestScore;
|
||||
}
|
||||
|
||||
setBestScore(score) {
|
||||
this.bestScore = score;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
CODE_REVIEW_SAMPLE = """
|
||||
## Code Review: game.js
|
||||
1. The code partially implements the requirements. The `Game` class is missing the full implementation of the `move` method, which is crucial for the game\'s functionality.
|
||||
2. The code logic is not completely correct. The `move` method is not implemented, which means the game cannot process player moves.
|
||||
3. The existing code follows the "Data structures and interfaces" in terms of class structure but lacks full method implementations.
|
||||
4. Not all functions are implemented. The `move` method is incomplete and does not handle the logic for moving and merging tiles.
|
||||
5. All necessary pre-dependencies seem to be imported since the code does not indicate the need for additional imports.
|
||||
6. The methods from other files (such as `Storage`) are not being used in the provided code snippet, but the class structure suggests that they will be used correctly.
|
||||
|
||||
## Actions
|
||||
1. Implement the `move` method to handle tile movements and merging. This is a complex task that requires careful consideration of the game\'s rules and logic. Here is a simplified version of how one might begin to implement the `move` method:
|
||||
```javascript
|
||||
move(direction) {
|
||||
// Simplified logic for moving tiles up
|
||||
if (direction === \'up\') {
|
||||
for (let col = 0; col < 4; col++) {
|
||||
let tiles = this.board.map(row => row[col]).filter(val => val !== 0);
|
||||
let merged = [];
|
||||
for (let i = 0; i < tiles.length; i++) {
|
||||
if (tiles[i] === tiles[i + 1]) {
|
||||
tiles[i] *= 2;
|
||||
this.score += tiles[i];
|
||||
tiles[i + 1] = 0;
|
||||
merged.push(i);
|
||||
}
|
||||
}
|
||||
tiles = tiles.filter(val => val !== 0);
|
||||
while (tiles.length < 4) {
|
||||
tiles.push(0);
|
||||
}
|
||||
for (let row = 0; row < 4; row++) {
|
||||
this.board[row][col] = tiles[row];
|
||||
}
|
||||
}
|
||||
}
|
||||
// Additional logic needed for \'down\', \'left\', \'right\'
|
||||
// ...
|
||||
this.addRandomTile();
|
||||
}
|
||||
```
|
||||
2. Integrate the `Storage` class methods to handle the best score. This means updating the `startGame` and `setBestScore` methods to use `Storage` for retrieving and setting the best score:
|
||||
```javascript
|
||||
startGame() {
|
||||
this.board = this.createEmptyBoard();
|
||||
this.score = 0;
|
||||
this.bestScore = new Storage().getBestScore(); // Retrieve the best score from storage
|
||||
this.addRandomTile();
|
||||
this.addRandomTile();
|
||||
}
|
||||
|
||||
setBestScore(score) {
|
||||
if (score > this.bestScore) {
|
||||
this.bestScore = score;
|
||||
new Storage().setBestScore(score); // Set the new best score in storage
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Code Review Result
|
||||
LBTM
|
||||
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
WRITE_CODE_NODE = ActionNode.from_children("WRITE_REVIEW_NODE", [REVIEW, LGTM, ACTIONS])
|
||||
WRITE_MOVE_NODE = ActionNode.from_children("WRITE_MOVE_NODE", [WRITE_DRAFT, WRITE_MOVE_FUNCTION])
|
||||
|
||||
|
||||
CR_FOR_MOVE_FUNCTION_BY_3 = """
|
||||
The move function implementation provided appears to be well-structured and follows a clear logic for moving and merging tiles in the specified direction. However, there are a few potential improvements that could be made to enhance the code:
|
||||
|
||||
1. Encapsulation: The logic for moving and merging tiles could be encapsulated into smaller, reusable functions to improve readability and maintainability.
|
||||
|
||||
2. Magic Numbers: There are some magic numbers (e.g., 4, 3) used in the loops that could be replaced with named constants for improved readability and easier maintenance.
|
||||
|
||||
3. Comments: Adding comments to explain the logic and purpose of each section of the code can improve understanding for future developers who may need to work on or maintain the code.
|
||||
|
||||
4. Error Handling: It's important to consider error handling for unexpected input or edge cases to ensure the function behaves as expected in all scenarios.
|
||||
|
||||
Overall, the code could benefit from refactoring to improve readability, maintainability, and extensibility. If you would like, I can provide a refactored version of the move function that addresses these considerations.
|
||||
"""
|
||||
|
||||
|
||||
class WriteCodeAN(Action):
|
||||
"""Write a code review for the context."""
|
||||
|
||||
async def run(self, context):
|
||||
self.llm.system_prompt = "You are an outstanding engineer and can implement any code"
|
||||
return await WRITE_MOVE_FUNCTION.fill(context=context, llm=self.llm, schema="json")
|
||||
# return await WRITE_CODE_NODE.fill(context=context, llm=self.llm, schema="markdown")
|
||||
|
||||
|
||||
async def main():
|
||||
await WriteCodeAN().run(CODE_REVIEW_SMALLEST_CONTEXT)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
|
|
@ -4,57 +4,116 @@
|
|||
@Time : 2023/5/11 17:45
|
||||
@Author : alexanderwu
|
||||
@File : write_code_review.py
|
||||
@Modified By: mashenquan, 2023/11/27. Following the think-act principle, solidify the task parameters when creating the
|
||||
WriteCode object, rather than passing them in when calling the run function.
|
||||
"""
|
||||
|
||||
from pydantic import Field
|
||||
from tenacity import retry, stop_after_attempt, wait_random_exponential
|
||||
|
||||
from metagpt.actions import WriteCode
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Message
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.schema import CodingContext
|
||||
from metagpt.utils.common import CodeParser
|
||||
from tenacity import retry, stop_after_attempt, wait_fixed
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
NOTICE
|
||||
Role: You are a professional software engineer, and your main task is to review the code. You need to ensure that the code conforms to the PEP8 standards, is elegantly designed and modularized, easy to read and maintain, and is written in Python 3.9 (or in another programming language).
|
||||
# System
|
||||
Role: You are a professional software engineer, and your main task is to review and revise the code. You need to ensure that the code conforms to the google-style standards, is elegantly designed and modularized, easy to read and maintain.
|
||||
Language: Please use the same language as the user requirement, but the title and code should be still in English. For example, if the user speaks Chinese, the specific text of your answer should also be in Chinese.
|
||||
ATTENTION: Use '##' to SPLIT SECTIONS, not '#'. Output format carefully referenced "Format example".
|
||||
|
||||
## Code Review: Based on the following context and code, and following the check list, Provide key, clear, concise, and specific code modification suggestions, up to 5.
|
||||
```
|
||||
1. Check 0: Is the code implemented as per the requirements?
|
||||
2. Check 1: Are there any issues with the code logic?
|
||||
3. Check 2: Does the existing code follow the "Data structures and interface definitions"?
|
||||
4. Check 3: Is there a function in the code that is omitted or not fully implemented that needs to be implemented?
|
||||
5. Check 4: Does the code have unnecessary or lack dependencies?
|
||||
```
|
||||
|
||||
## Rewrite Code: {filename} Base on "Code Review" and the source code, rewrite code with triple quotes. Do your utmost to optimize THIS SINGLE FILE.
|
||||
-----
|
||||
# Context
|
||||
{context}
|
||||
|
||||
## Code: {filename}
|
||||
```
|
||||
## Code to be Reviewed: {filename}
|
||||
```Code
|
||||
{code}
|
||||
```
|
||||
-----
|
||||
"""
|
||||
|
||||
EXAMPLE_AND_INSTRUCTION = """
|
||||
|
||||
## Format example
|
||||
-----
|
||||
{format_example}
|
||||
-----
|
||||
|
||||
|
||||
# Instruction: Based on the actual code situation, follow one of the "Format example".
|
||||
|
||||
## Code Review: Ordered List. Based on the "Code to be Reviewed", provide key, clear, concise, and specific answer. If any answer is no, explain how to fix it step by step.
|
||||
1. Is the code implemented as per the requirements? If not, how to achieve it? Analyse it step by step.
|
||||
2. Is the code logic completely correct? If there are errors, please indicate how to correct them.
|
||||
3. Does the existing code follow the "Data structures and interfaces"?
|
||||
4. Are all functions implemented? If there is no implementation, please indicate how to achieve it step by step.
|
||||
5. Have all necessary pre-dependencies been imported? If not, indicate which ones need to be imported
|
||||
6. Are methods from other files being reused correctly?
|
||||
|
||||
## Actions: Ordered List. Things that should be done after CR, such as implementing class A and function B
|
||||
|
||||
## Code Review Result: str. If the code doesn't have bugs, we don't need to rewrite it, so answer LGTM and stop. ONLY ANSWER LGTM/LBTM.
|
||||
LGTM/LBTM
|
||||
|
||||
"""
|
||||
|
||||
FORMAT_EXAMPLE = """
|
||||
|
||||
## Code Review
|
||||
1. The code ...
|
||||
# Format example 1
|
||||
## Code Review: {filename}
|
||||
1. No, we should fix the logic of class A due to ...
|
||||
2. ...
|
||||
3. ...
|
||||
4. ...
|
||||
4. No, function B is not implemented, ...
|
||||
5. ...
|
||||
6. ...
|
||||
|
||||
## Rewrite Code: {filename}
|
||||
```python
|
||||
## Actions
|
||||
1. Fix the `handle_events` method to update the game state only if a move is successful.
|
||||
```python
|
||||
def handle_events(self):
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
return False
|
||||
if event.type == pygame.KEYDOWN:
|
||||
moved = False
|
||||
if event.key == pygame.K_UP:
|
||||
moved = self.game.move('UP')
|
||||
elif event.key == pygame.K_DOWN:
|
||||
moved = self.game.move('DOWN')
|
||||
elif event.key == pygame.K_LEFT:
|
||||
moved = self.game.move('LEFT')
|
||||
elif event.key == pygame.K_RIGHT:
|
||||
moved = self.game.move('RIGHT')
|
||||
if moved:
|
||||
# Update the game state only if a move was successful
|
||||
self.render()
|
||||
return True
|
||||
```
|
||||
2. Implement function B
|
||||
|
||||
## Code Review Result
|
||||
LBTM
|
||||
|
||||
# Format example 2
|
||||
## Code Review: {filename}
|
||||
1. Yes.
|
||||
2. Yes.
|
||||
3. Yes.
|
||||
4. Yes.
|
||||
5. Yes.
|
||||
6. Yes.
|
||||
|
||||
## Actions
|
||||
pass
|
||||
|
||||
## Code Review Result
|
||||
LGTM
|
||||
"""
|
||||
|
||||
REWRITE_CODE_TEMPLATE = """
|
||||
# Instruction: rewrite code based on the Code Review and Actions
|
||||
## Rewrite Code: CodeBlock. If it still has some bugs, rewrite {filename} with triple quotes. Do your utmost to optimize THIS SINGLE FILE. Return all completed codes and prohibit the return of unfinished codes.
|
||||
```Code
|
||||
## {filename}
|
||||
...
|
||||
```
|
||||
|
|
@ -62,21 +121,59 @@ FORMAT_EXAMPLE = """
|
|||
|
||||
|
||||
class WriteCodeReview(Action):
|
||||
def __init__(self, name="WriteCodeReview", context: list[Message] = None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
name: str = "WriteCodeReview"
|
||||
context: CodingContext = Field(default_factory=CodingContext)
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
|
||||
@retry(stop=stop_after_attempt(2), wait=wait_fixed(1))
|
||||
async def write_code(self, prompt):
|
||||
code_rsp = await self._aask(prompt)
|
||||
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
|
||||
async def write_code_review_and_rewrite(self, context_prompt, cr_prompt, filename):
|
||||
cr_rsp = await self._aask(context_prompt + cr_prompt)
|
||||
result = CodeParser.parse_block("Code Review Result", cr_rsp)
|
||||
if "LGTM" in result:
|
||||
return result, None
|
||||
|
||||
# if LBTM, rewrite code
|
||||
rewrite_prompt = f"{context_prompt}\n{cr_rsp}\n{REWRITE_CODE_TEMPLATE.format(filename=filename)}"
|
||||
code_rsp = await self._aask(rewrite_prompt)
|
||||
code = CodeParser.parse_code(block="", text=code_rsp)
|
||||
return code
|
||||
return result, code
|
||||
|
||||
async def run(self, context, code, filename):
|
||||
format_example = FORMAT_EXAMPLE.format(filename=filename)
|
||||
prompt = PROMPT_TEMPLATE.format(context=context, code=code, filename=filename, format_example=format_example)
|
||||
logger.info(f'Code review {filename}..')
|
||||
code = await self.write_code(prompt)
|
||||
async def run(self, *args, **kwargs) -> CodingContext:
|
||||
iterative_code = self.context.code_doc.content
|
||||
k = CONFIG.code_review_k_times or 1
|
||||
for i in range(k):
|
||||
format_example = FORMAT_EXAMPLE.format(filename=self.context.code_doc.filename)
|
||||
task_content = self.context.task_doc.content if self.context.task_doc else ""
|
||||
code_context = await WriteCode.get_codes(self.context.task_doc, exclude=self.context.filename)
|
||||
context = "\n".join(
|
||||
[
|
||||
"## System Design\n" + str(self.context.design_doc) + "\n",
|
||||
"## Tasks\n" + task_content + "\n",
|
||||
"## Code Files\n" + code_context + "\n",
|
||||
]
|
||||
)
|
||||
context_prompt = PROMPT_TEMPLATE.format(
|
||||
context=context,
|
||||
code=iterative_code,
|
||||
filename=self.context.code_doc.filename,
|
||||
)
|
||||
cr_prompt = EXAMPLE_AND_INSTRUCTION.format(
|
||||
format_example=format_example,
|
||||
)
|
||||
logger.info(
|
||||
f"Code review and rewrite {self.context.code_doc.filename}: {i + 1}/{k} | {len(iterative_code)=}, "
|
||||
f"{len(self.context.code_doc.content)=}"
|
||||
)
|
||||
result, rewrited_code = await self.write_code_review_and_rewrite(
|
||||
context_prompt, cr_prompt, self.context.code_doc.filename
|
||||
)
|
||||
if "LBTM" in result:
|
||||
iterative_code = rewrited_code
|
||||
elif "LGTM" in result:
|
||||
self.context.code_doc.content = iterative_code
|
||||
return self.context
|
||||
# code_rsp = await self._aask_v1(prompt, "code_rsp", OUTPUT_MAPPING)
|
||||
# self._save(context, filename, code)
|
||||
return code
|
||||
|
||||
# 如果rewrited_code是None(原code perfect),那么直接返回code
|
||||
self.context.code_doc.content = iterative_code
|
||||
return self.context
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ Options:
|
|||
Default: 'google'
|
||||
|
||||
Example:
|
||||
python3 -m metagpt.actions.write_docstring startup.py --overwrite False --style=numpy
|
||||
python3 -m metagpt.actions.write_docstring ./metagpt/startup.py --overwrite False --style=numpy
|
||||
|
||||
This script uses the 'fire' library to create a command-line interface. It generates docstrings for the given Python code using
|
||||
the specified docstring style and adds them to the code.
|
||||
|
|
@ -28,7 +28,7 @@ from metagpt.actions.action import Action
|
|||
from metagpt.utils.common import OutputParser
|
||||
from metagpt.utils.pycst import merge_docstring
|
||||
|
||||
PYTHON_DOCSTRING_SYSTEM = '''### Requirements
|
||||
PYTHON_DOCSTRING_SYSTEM = """### Requirements
|
||||
1. Add docstrings to the given code following the {style} style.
|
||||
2. Replace the function body with an Ellipsis object(...) to reduce output.
|
||||
3. If the types are already annotated, there is no need to include them in the docstring.
|
||||
|
|
@ -48,7 +48,7 @@ class ExampleError(Exception):
|
|||
```python
|
||||
{example}
|
||||
```
|
||||
'''
|
||||
"""
|
||||
|
||||
# https://www.sphinx-doc.org/en/master/usage/extensions/napoleon.html
|
||||
|
||||
|
|
@ -162,7 +162,8 @@ class WriteDocstring(Action):
|
|||
self.desc = "Write docstring for code."
|
||||
|
||||
async def run(
|
||||
self, code: str,
|
||||
self,
|
||||
code: str,
|
||||
system_text: str = PYTHON_DOCSTRING_SYSTEM,
|
||||
style: Literal["google", "numpy", "sphinx"] = "google",
|
||||
) -> str:
|
||||
|
|
|
|||
|
|
@ -4,238 +4,199 @@
|
|||
@Time : 2023/5/11 17:45
|
||||
@Author : alexanderwu
|
||||
@File : write_prd.py
|
||||
@Modified By: mashenquan, 2023/11/27.
|
||||
1. According to Section 2.2.3.1 of RFC 135, replace file data in the message with the file name.
|
||||
2. According to the design in Section 2.2.3.5.2 of RFC 135, add incremental iteration functionality.
|
||||
3. Move the document storage operations related to WritePRD from the save operation of WriteDesign.
|
||||
@Modified By: mashenquan, 2023/12/5. Move the generation logic of the project name to WritePRD.
|
||||
"""
|
||||
from typing import List
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import json
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.actions import Action, ActionOutput
|
||||
from metagpt.actions.search_and_summarize import SearchAndSummarize
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
from metagpt.actions.fix_bug import FixBug
|
||||
from metagpt.actions.write_prd_an import (
|
||||
WP_IS_RELATIVE_NODE,
|
||||
WP_ISSUE_TYPE_NODE,
|
||||
WRITE_PRD_NODE,
|
||||
)
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import (
|
||||
BUGFIX_FILENAME,
|
||||
COMPETITIVE_ANALYSIS_FILE_REPO,
|
||||
DOCS_FILE_REPO,
|
||||
PRD_PDF_FILE_REPO,
|
||||
PRDS_FILE_REPO,
|
||||
REQUIREMENT_FILENAME,
|
||||
)
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.utils.get_template import get_template
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.schema import BugFixContext, Document, Documents, Message
|
||||
from metagpt.utils.common import CodeParser
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
from metagpt.utils.mermaid import mermaid_to_file
|
||||
|
||||
templates = {
|
||||
"json": {
|
||||
"PROMPT_TEMPLATE": """
|
||||
# Context
|
||||
## Original Requirements
|
||||
CONTEXT_TEMPLATE = """
|
||||
### Project Name
|
||||
{project_name}
|
||||
|
||||
### Original Requirements
|
||||
{requirements}
|
||||
|
||||
## Search Information
|
||||
{search_information}
|
||||
### Search Information
|
||||
-
|
||||
"""
|
||||
|
||||
## mermaid quadrantChart code syntax example. DONT USE QUOTO IN CODE DUE TO INVALID SYNTAX. Replace the <Campain X> with REAL COMPETITOR NAME
|
||||
```mermaid
|
||||
quadrantChart
|
||||
title Reach and engagement of campaigns
|
||||
x-axis Low Reach --> High Reach
|
||||
y-axis Low Engagement --> High Engagement
|
||||
quadrant-1 We should expand
|
||||
quadrant-2 Need to promote
|
||||
quadrant-3 Re-evaluate
|
||||
quadrant-4 May be improved
|
||||
"Campaign: A": [0.3, 0.6]
|
||||
"Campaign B": [0.45, 0.23]
|
||||
"Campaign C": [0.57, 0.69]
|
||||
"Campaign D": [0.78, 0.34]
|
||||
"Campaign E": [0.40, 0.34]
|
||||
"Campaign F": [0.35, 0.78]
|
||||
"Our Target Product": [0.5, 0.6]
|
||||
```
|
||||
NEW_REQ_TEMPLATE = """
|
||||
### Legacy Content
|
||||
{old_prd}
|
||||
|
||||
## Format example
|
||||
{format_example}
|
||||
-----
|
||||
Role: You are a professional product manager; the goal is to design a concise, usable, efficient product
|
||||
Requirements: According to the context, fill in the following missing information, each section name is a key in json ,If the requirements are unclear, ensure minimum viability and avoid excessive design
|
||||
|
||||
## Original Requirements: Provide as Plain text, place the polished complete original requirements here
|
||||
|
||||
## Product Goals: Provided as Python list[str], up to 3 clear, orthogonal product goals. If the requirement itself is simple, the goal should also be simple
|
||||
|
||||
## User Stories: Provided as Python list[str], up to 5 scenario-based user stories, If the requirement itself is simple, the user stories should also be less
|
||||
|
||||
## Competitive Analysis: Provided as Python list[str], up to 7 competitive product analyses, consider as similar competitors as possible
|
||||
|
||||
## Competitive Quadrant Chart: Use mermaid quadrantChart code syntax. up to 14 competitive products. Translation: Distribute these competitor scores evenly between 0 and 1, trying to conform to a normal distribution centered around 0.5 as much as possible.
|
||||
|
||||
## Requirement Analysis: Provide as Plain text. Be simple. LESS IS MORE. Make your requirements less dumb. Delete the parts unnessasery.
|
||||
|
||||
## Requirement Pool: Provided as Python list[list[str], the parameters are requirement description, priority(P0/P1/P2), respectively, comply with PEP standards; no more than 5 requirements and consider to make its difficulty lower
|
||||
|
||||
## UI Design draft: Provide as Plain text. Be simple. Describe the elements and functions, also provide a simple style description and layout description.
|
||||
## Anything UNCLEAR: Provide as Plain text. Make clear here.
|
||||
|
||||
output a properly formatted JSON, wrapped inside [CONTENT][/CONTENT] like format example,
|
||||
and only output the json inside this tag, nothing else
|
||||
""",
|
||||
"FORMAT_EXAMPLE": """
|
||||
[CONTENT]
|
||||
{
|
||||
"Original Requirements": "",
|
||||
"Search Information": "",
|
||||
"Requirements": "",
|
||||
"Product Goals": [],
|
||||
"User Stories": [],
|
||||
"Competitive Analysis": [],
|
||||
"Competitive Quadrant Chart": "quadrantChart
|
||||
title Reach and engagement of campaigns
|
||||
x-axis Low Reach --> High Reach
|
||||
y-axis Low Engagement --> High Engagement
|
||||
quadrant-1 We should expand
|
||||
quadrant-2 Need to promote
|
||||
quadrant-3 Re-evaluate
|
||||
quadrant-4 May be improved
|
||||
Campaign A: [0.3, 0.6]
|
||||
Campaign B: [0.45, 0.23]
|
||||
Campaign C: [0.57, 0.69]
|
||||
Campaign D: [0.78, 0.34]
|
||||
Campaign E: [0.40, 0.34]
|
||||
Campaign F: [0.35, 0.78]",
|
||||
"Requirement Analysis": "",
|
||||
"Requirement Pool": [["P0","P0 requirement"],["P1","P1 requirement"]],
|
||||
"UI Design draft": "",
|
||||
"Anything UNCLEAR": "",
|
||||
}
|
||||
[/CONTENT]
|
||||
""",
|
||||
},
|
||||
"markdown": {
|
||||
"PROMPT_TEMPLATE": """
|
||||
# Context
|
||||
## Original Requirements
|
||||
### New Requirements
|
||||
{requirements}
|
||||
|
||||
## Search Information
|
||||
{search_information}
|
||||
|
||||
## mermaid quadrantChart code syntax example. DONT USE QUOTO IN CODE DUE TO INVALID SYNTAX. Replace the <Campain X> with REAL COMPETITOR NAME
|
||||
```mermaid
|
||||
quadrantChart
|
||||
title Reach and engagement of campaigns
|
||||
x-axis Low Reach --> High Reach
|
||||
y-axis Low Engagement --> High Engagement
|
||||
quadrant-1 We should expand
|
||||
quadrant-2 Need to promote
|
||||
quadrant-3 Re-evaluate
|
||||
quadrant-4 May be improved
|
||||
"Campaign: A": [0.3, 0.6]
|
||||
"Campaign B": [0.45, 0.23]
|
||||
"Campaign C": [0.57, 0.69]
|
||||
"Campaign D": [0.78, 0.34]
|
||||
"Campaign E": [0.40, 0.34]
|
||||
"Campaign F": [0.35, 0.78]
|
||||
"Our Target Product": [0.5, 0.6]
|
||||
```
|
||||
|
||||
## Format example
|
||||
{format_example}
|
||||
-----
|
||||
Role: You are a professional product manager; the goal is to design a concise, usable, efficient product
|
||||
Requirements: According to the context, fill in the following missing information, note that each sections are returned in Python code triple quote form seperatedly. If the requirements are unclear, ensure minimum viability and avoid excessive design
|
||||
ATTENTION: Use '##' to SPLIT SECTIONS, not '#'. AND '## <SECTION_NAME>' SHOULD WRITE BEFORE the code and triple quote. Output carefully referenced "Format example" in format.
|
||||
|
||||
## Original Requirements: Provide as Plain text, place the polished complete original requirements here
|
||||
|
||||
## Product Goals: Provided as Python list[str], up to 3 clear, orthogonal product goals. If the requirement itself is simple, the goal should also be simple
|
||||
|
||||
## User Stories: Provided as Python list[str], up to 5 scenario-based user stories, If the requirement itself is simple, the user stories should also be less
|
||||
|
||||
## Competitive Analysis: Provided as Python list[str], up to 7 competitive product analyses, consider as similar competitors as possible
|
||||
|
||||
## Competitive Quadrant Chart: Use mermaid quadrantChart code syntax. up to 14 competitive products. Translation: Distribute these competitor scores evenly between 0 and 1, trying to conform to a normal distribution centered around 0.5 as much as possible.
|
||||
|
||||
## Requirement Analysis: Provide as Plain text. Be simple. LESS IS MORE. Make your requirements less dumb. Delete the parts unnessasery.
|
||||
|
||||
## Requirement Pool: Provided as Python list[list[str], the parameters are requirement description, priority(P0/P1/P2), respectively, comply with PEP standards; no more than 5 requirements and consider to make its difficulty lower
|
||||
|
||||
## UI Design draft: Provide as Plain text. Be simple. Describe the elements and functions, also provide a simple style description and layout description.
|
||||
## Anything UNCLEAR: Provide as Plain text. Make clear here.
|
||||
""",
|
||||
"FORMAT_EXAMPLE": """
|
||||
---
|
||||
## Original Requirements
|
||||
The boss ...
|
||||
|
||||
## Product Goals
|
||||
```python
|
||||
[
|
||||
"Create a ...",
|
||||
]
|
||||
```
|
||||
|
||||
## User Stories
|
||||
```python
|
||||
[
|
||||
"As a user, ...",
|
||||
]
|
||||
```
|
||||
|
||||
## Competitive Analysis
|
||||
```python
|
||||
[
|
||||
"Python Snake Game: ...",
|
||||
]
|
||||
```
|
||||
|
||||
## Competitive Quadrant Chart
|
||||
```mermaid
|
||||
quadrantChart
|
||||
title Reach and engagement of campaigns
|
||||
...
|
||||
"Our Target Product": [0.6, 0.7]
|
||||
```
|
||||
|
||||
## Requirement Analysis
|
||||
The product should be a ...
|
||||
|
||||
## Requirement Pool
|
||||
```python
|
||||
[
|
||||
["End game ...", "P0"]
|
||||
]
|
||||
```
|
||||
|
||||
## UI Design draft
|
||||
Give a basic function description, and a draft
|
||||
|
||||
## Anything UNCLEAR
|
||||
There are no unclear points.
|
||||
---
|
||||
""",
|
||||
},
|
||||
}
|
||||
|
||||
OUTPUT_MAPPING = {
|
||||
"Original Requirements": (str, ...),
|
||||
"Product Goals": (List[str], ...),
|
||||
"User Stories": (List[str], ...),
|
||||
"Competitive Analysis": (List[str], ...),
|
||||
"Competitive Quadrant Chart": (str, ...),
|
||||
"Requirement Analysis": (str, ...),
|
||||
"Requirement Pool": (List[List[str]], ...),
|
||||
"UI Design draft": (str, ...),
|
||||
"Anything UNCLEAR": (str, ...),
|
||||
}
|
||||
"""
|
||||
|
||||
|
||||
class WritePRD(Action):
|
||||
def __init__(self, name="", context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
name: str = ""
|
||||
content: Optional[str] = None
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
|
||||
async def run(self, requirements, format=CONFIG.prompt_format, *args, **kwargs) -> ActionOutput:
|
||||
sas = SearchAndSummarize()
|
||||
# rsp = await sas.run(context=requirements, system_text=SEARCH_AND_SUMMARIZE_SYSTEM_EN_US)
|
||||
rsp = ""
|
||||
info = f"### Search Results\n{sas.result}\n\n### Search Summary\n{rsp}"
|
||||
if sas.result:
|
||||
logger.info(sas.result)
|
||||
logger.info(rsp)
|
||||
async def run(self, with_messages, schema=CONFIG.prompt_schema, *args, **kwargs) -> ActionOutput | Message:
|
||||
# Determine which requirement documents need to be rewritten: Use LLM to assess whether new requirements are
|
||||
# related to the PRD. If they are related, rewrite the PRD.
|
||||
docs_file_repo = CONFIG.git_repo.new_file_repository(relative_path=DOCS_FILE_REPO)
|
||||
requirement_doc = await docs_file_repo.get(filename=REQUIREMENT_FILENAME)
|
||||
if requirement_doc and await self._is_bugfix(requirement_doc.content):
|
||||
await docs_file_repo.save(filename=BUGFIX_FILENAME, content=requirement_doc.content)
|
||||
await docs_file_repo.save(filename=REQUIREMENT_FILENAME, content="")
|
||||
bug_fix = BugFixContext(filename=BUGFIX_FILENAME)
|
||||
return Message(
|
||||
content=bug_fix.json(),
|
||||
instruct_content=bug_fix,
|
||||
role="",
|
||||
cause_by=FixBug,
|
||||
sent_from=self,
|
||||
send_to="Alex", # the name of Engineer
|
||||
)
|
||||
else:
|
||||
await docs_file_repo.delete(filename=BUGFIX_FILENAME)
|
||||
|
||||
prompt_template, format_example = get_template(templates, format)
|
||||
prompt = prompt_template.format(
|
||||
requirements=requirements, search_information=info, format_example=format_example
|
||||
prds_file_repo = CONFIG.git_repo.new_file_repository(PRDS_FILE_REPO)
|
||||
prd_docs = await prds_file_repo.get_all()
|
||||
change_files = Documents()
|
||||
for prd_doc in prd_docs:
|
||||
prd_doc = await self._update_prd(
|
||||
requirement_doc=requirement_doc, prd_doc=prd_doc, prds_file_repo=prds_file_repo, *args, **kwargs
|
||||
)
|
||||
if not prd_doc:
|
||||
continue
|
||||
change_files.docs[prd_doc.filename] = prd_doc
|
||||
logger.info(f"rewrite prd: {prd_doc.filename}")
|
||||
# If there is no existing PRD, generate one using 'docs/requirement.txt'.
|
||||
if not change_files.docs:
|
||||
prd_doc = await self._update_prd(
|
||||
requirement_doc=requirement_doc, prd_doc=None, prds_file_repo=prds_file_repo, *args, **kwargs
|
||||
)
|
||||
if prd_doc:
|
||||
change_files.docs[prd_doc.filename] = prd_doc
|
||||
logger.debug(f"new prd: {prd_doc.filename}")
|
||||
# Once all files under 'docs/prds/' have been compared with the newly added requirements, trigger the
|
||||
# 'publish' message to transition the workflow to the next stage. This design allows room for global
|
||||
# optimization in subsequent steps.
|
||||
return ActionOutput(content=change_files.json(), instruct_content=change_files)
|
||||
|
||||
async def _run_new_requirement(self, requirements, schema=CONFIG.prompt_schema) -> ActionOutput:
|
||||
# sas = SearchAndSummarize()
|
||||
# # rsp = await sas.run(context=requirements, system_text=SEARCH_AND_SUMMARIZE_SYSTEM_EN_US)
|
||||
# rsp = ""
|
||||
# info = f"### Search Results\n{sas.result}\n\n### Search Summary\n{rsp}"
|
||||
# if sas.result:
|
||||
# logger.info(sas.result)
|
||||
# logger.info(rsp)
|
||||
project_name = CONFIG.project_name if CONFIG.project_name else ""
|
||||
context = CONTEXT_TEMPLATE.format(requirements=requirements, project_name=project_name)
|
||||
node = await WRITE_PRD_NODE.fill(context=context, llm=self.llm, schema=schema)
|
||||
await self._rename_workspace(node)
|
||||
return node
|
||||
|
||||
async def _is_relative(self, new_requirement_doc, old_prd_doc) -> bool:
|
||||
context = NEW_REQ_TEMPLATE.format(old_prd=old_prd_doc.content, requirements=new_requirement_doc.content)
|
||||
node = await WP_IS_RELATIVE_NODE.fill(context, self.llm)
|
||||
return node.get("is_relative") == "YES"
|
||||
|
||||
async def _merge(self, new_requirement_doc, prd_doc, schema=CONFIG.prompt_schema) -> Document:
|
||||
if not CONFIG.project_name:
|
||||
CONFIG.project_name = Path(CONFIG.project_path).name
|
||||
prompt = NEW_REQ_TEMPLATE.format(requirements=new_requirement_doc.content, old_prd=prd_doc.content)
|
||||
node = await WRITE_PRD_NODE.fill(context=prompt, llm=self.llm, schema=schema)
|
||||
prd_doc.content = node.instruct_content.json(ensure_ascii=False)
|
||||
await self._rename_workspace(node)
|
||||
return prd_doc
|
||||
|
||||
async def _update_prd(self, requirement_doc, prd_doc, prds_file_repo, *args, **kwargs) -> Document | None:
|
||||
if not prd_doc:
|
||||
prd = await self._run_new_requirement(
|
||||
requirements=[requirement_doc.content if requirement_doc else ""], *args, **kwargs
|
||||
)
|
||||
new_prd_doc = Document(
|
||||
root_path=PRDS_FILE_REPO,
|
||||
filename=FileRepository.new_filename() + ".json",
|
||||
content=prd.instruct_content.json(ensure_ascii=False),
|
||||
)
|
||||
elif await self._is_relative(requirement_doc, prd_doc):
|
||||
new_prd_doc = await self._merge(requirement_doc, prd_doc)
|
||||
else:
|
||||
return None
|
||||
await prds_file_repo.save(filename=new_prd_doc.filename, content=new_prd_doc.content)
|
||||
await self._save_competitive_analysis(new_prd_doc)
|
||||
await self._save_pdf(new_prd_doc)
|
||||
return new_prd_doc
|
||||
|
||||
@staticmethod
|
||||
async def _save_competitive_analysis(prd_doc):
|
||||
m = json.loads(prd_doc.content)
|
||||
quadrant_chart = m.get("Competitive Quadrant Chart")
|
||||
if not quadrant_chart:
|
||||
return
|
||||
pathname = (
|
||||
CONFIG.git_repo.workdir / Path(COMPETITIVE_ANALYSIS_FILE_REPO) / Path(prd_doc.filename).with_suffix("")
|
||||
)
|
||||
logger.debug(prompt)
|
||||
# prd = await self._aask_v1(prompt, "prd", OUTPUT_MAPPING)
|
||||
prd = await self._aask_v1(prompt, "prd", OUTPUT_MAPPING, format=format)
|
||||
return prd
|
||||
if not pathname.parent.exists():
|
||||
pathname.parent.mkdir(parents=True, exist_ok=True)
|
||||
await mermaid_to_file(quadrant_chart, pathname)
|
||||
|
||||
@staticmethod
|
||||
async def _save_pdf(prd_doc):
|
||||
await FileRepository.save_as(doc=prd_doc, with_suffix=".md", relative_path=PRD_PDF_FILE_REPO)
|
||||
|
||||
@staticmethod
|
||||
async def _rename_workspace(prd):
|
||||
if CONFIG.project_path: # Updating on the old version has already been specified if it's valid. According to
|
||||
# Section 2.2.3.10 of RFC 135
|
||||
if not CONFIG.project_name:
|
||||
CONFIG.project_name = Path(CONFIG.project_path).name
|
||||
return
|
||||
|
||||
if not CONFIG.project_name:
|
||||
if isinstance(prd, (ActionOutput, ActionNode)):
|
||||
ws_name = prd.instruct_content.dict()["Project Name"]
|
||||
else:
|
||||
ws_name = CodeParser.parse_str(block="Project Name", text=prd)
|
||||
CONFIG.project_name = ws_name
|
||||
CONFIG.git_repo.rename_root(CONFIG.project_name)
|
||||
|
||||
async def _is_bugfix(self, context) -> bool:
|
||||
src_workspace_path = CONFIG.git_repo.workdir / CONFIG.git_repo.workdir.name
|
||||
code_files = CONFIG.git_repo.get_files(relative_path=src_workspace_path)
|
||||
if not code_files:
|
||||
return False
|
||||
node = await WP_ISSUE_TYPE_NODE.fill(context, self.llm)
|
||||
return node.get("issue_type") == "BUG"
|
||||
|
|
|
|||
166
metagpt/actions/write_prd_an.py
Normal file
166
metagpt/actions/write_prd_an.py
Normal file
|
|
@ -0,0 +1,166 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/12/14 11:40
|
||||
@Author : alexanderwu
|
||||
@File : write_prd_an.py
|
||||
"""
|
||||
from typing import List
|
||||
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
from metagpt.logs import logger
|
||||
|
||||
LANGUAGE = ActionNode(
|
||||
key="Language",
|
||||
expected_type=str,
|
||||
instruction="Provide the language used in the project, typically matching the user's requirement language.",
|
||||
example="en_us",
|
||||
)
|
||||
|
||||
PROGRAMMING_LANGUAGE = ActionNode(
|
||||
key="Programming Language",
|
||||
expected_type=str,
|
||||
instruction="Python/JavaScript or other mainstream programming language.",
|
||||
example="Python",
|
||||
)
|
||||
|
||||
ORIGINAL_REQUIREMENTS = ActionNode(
|
||||
key="Original Requirements",
|
||||
expected_type=str,
|
||||
instruction="Place the original user's requirements here.",
|
||||
example="Create a 2048 game",
|
||||
)
|
||||
|
||||
PROJECT_NAME = ActionNode(
|
||||
key="Project Name",
|
||||
expected_type=str,
|
||||
instruction="Name the project using snake case style, like 'game_2048' or 'simple_crm'.",
|
||||
example="game_2048",
|
||||
)
|
||||
|
||||
PRODUCT_GOALS = ActionNode(
|
||||
key="Product Goals",
|
||||
expected_type=List[str],
|
||||
instruction="Provide up to three clear, orthogonal product goals.",
|
||||
example=["Create an engaging user experience", "Improve accessibility, be responsive", "More beautiful UI"],
|
||||
)
|
||||
|
||||
USER_STORIES = ActionNode(
|
||||
key="User Stories",
|
||||
expected_type=List[str],
|
||||
instruction="Provide up to 3 to 5 scenario-based user stories.",
|
||||
example=[
|
||||
"As a player, I want to be able to choose difficulty levels",
|
||||
"As a player, I want to see my score after each game",
|
||||
"As a player, I want to get restart button when I lose",
|
||||
"As a player, I want to see beautiful UI that make me feel good",
|
||||
"As a player, I want to play game via mobile phone",
|
||||
],
|
||||
)
|
||||
|
||||
COMPETITIVE_ANALYSIS = ActionNode(
|
||||
key="Competitive Analysis",
|
||||
expected_type=List[str],
|
||||
instruction="Provide 5 to 7 competitive products.",
|
||||
example=[
|
||||
"2048 Game A: Simple interface, lacks responsive features",
|
||||
"play2048.co: Beautiful and responsive UI with my best score shown",
|
||||
"2048game.com: Responsive UI with my best score shown, but many ads",
|
||||
],
|
||||
)
|
||||
|
||||
COMPETITIVE_QUADRANT_CHART = ActionNode(
|
||||
key="Competitive Quadrant Chart",
|
||||
expected_type=str,
|
||||
instruction="Use mermaid quadrantChart syntax. Distribute scores evenly between 0 and 1",
|
||||
example="""quadrantChart
|
||||
title "Reach and engagement of campaigns"
|
||||
x-axis "Low Reach" --> "High Reach"
|
||||
y-axis "Low Engagement" --> "High Engagement"
|
||||
quadrant-1 "We should expand"
|
||||
quadrant-2 "Need to promote"
|
||||
quadrant-3 "Re-evaluate"
|
||||
quadrant-4 "May be improved"
|
||||
"Campaign A": [0.3, 0.6]
|
||||
"Campaign B": [0.45, 0.23]
|
||||
"Campaign C": [0.57, 0.69]
|
||||
"Campaign D": [0.78, 0.34]
|
||||
"Campaign E": [0.40, 0.34]
|
||||
"Campaign F": [0.35, 0.78]
|
||||
"Our Target Product": [0.5, 0.6]""",
|
||||
)
|
||||
|
||||
REQUIREMENT_ANALYSIS = ActionNode(
|
||||
key="Requirement Analysis",
|
||||
expected_type=str,
|
||||
instruction="Provide a detailed analysis of the requirements.",
|
||||
example="",
|
||||
)
|
||||
|
||||
REQUIREMENT_POOL = ActionNode(
|
||||
key="Requirement Pool",
|
||||
expected_type=List[List[str]],
|
||||
instruction="List down the top-5 requirements with their priority (P0, P1, P2).",
|
||||
example=[["P0", "The main code ..."], ["P0", "The game algorithm ..."]],
|
||||
)
|
||||
|
||||
UI_DESIGN_DRAFT = ActionNode(
|
||||
key="UI Design draft",
|
||||
expected_type=str,
|
||||
instruction="Provide a simple description of UI elements, functions, style, and layout.",
|
||||
example="Basic function description with a simple style and layout.",
|
||||
)
|
||||
|
||||
ANYTHING_UNCLEAR = ActionNode(
|
||||
key="Anything UNCLEAR",
|
||||
expected_type=str,
|
||||
instruction="Mention any aspects of the project that are unclear and try to clarify them.",
|
||||
example="",
|
||||
)
|
||||
|
||||
ISSUE_TYPE = ActionNode(
|
||||
key="issue_type",
|
||||
expected_type=str,
|
||||
instruction="Answer BUG/REQUIREMENT. If it is a bugfix, answer BUG, otherwise answer Requirement",
|
||||
example="BUG",
|
||||
)
|
||||
|
||||
IS_RELATIVE = ActionNode(
|
||||
key="is_relative",
|
||||
expected_type=str,
|
||||
instruction="Answer YES/NO. If the requirement is related to the old PRD, answer YES, otherwise NO",
|
||||
example="YES",
|
||||
)
|
||||
|
||||
REASON = ActionNode(
|
||||
key="reason", expected_type=str, instruction="Explain the reasoning process from question to answer", example="..."
|
||||
)
|
||||
|
||||
|
||||
NODES = [
|
||||
LANGUAGE,
|
||||
PROGRAMMING_LANGUAGE,
|
||||
ORIGINAL_REQUIREMENTS,
|
||||
PROJECT_NAME,
|
||||
PRODUCT_GOALS,
|
||||
USER_STORIES,
|
||||
COMPETITIVE_ANALYSIS,
|
||||
COMPETITIVE_QUADRANT_CHART,
|
||||
REQUIREMENT_ANALYSIS,
|
||||
REQUIREMENT_POOL,
|
||||
UI_DESIGN_DRAFT,
|
||||
ANYTHING_UNCLEAR,
|
||||
]
|
||||
|
||||
WRITE_PRD_NODE = ActionNode.from_children("WritePRD", NODES)
|
||||
WP_ISSUE_TYPE_NODE = ActionNode.from_children("WP_ISSUE_TYPE", [ISSUE_TYPE, REASON])
|
||||
WP_IS_RELATIVE_NODE = ActionNode.from_children("WP_IS_RELATIVE", [IS_RELATIVE, REASON])
|
||||
|
||||
|
||||
def main():
|
||||
prompt = WRITE_PRD_NODE.compile(context="")
|
||||
logger.info(prompt)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
|
@ -5,24 +5,31 @@
|
|||
@Author : alexanderwu
|
||||
@File : write_prd_review.py
|
||||
"""
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
|
||||
|
||||
class WritePRDReview(Action):
|
||||
def __init__(self, name, context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
self.prd = None
|
||||
self.desc = "Based on the PRD, conduct a PRD Review, providing clear and detailed feedback"
|
||||
self.prd_review_prompt_template = """
|
||||
Given the following Product Requirement Document (PRD):
|
||||
{prd}
|
||||
name: str = ""
|
||||
context: Optional[str] = None
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
prd: Optional[str] = None
|
||||
desc: str = "Based on the PRD, conduct a PRD Review, providing clear and detailed feedback"
|
||||
prd_review_prompt_template: str = """
|
||||
Given the following Product Requirement Document (PRD):
|
||||
{prd}
|
||||
|
||||
As a project manager, please review it and provide your feedback and suggestions.
|
||||
"""
|
||||
As a project manager, please review it and provide your feedback and suggestions.
|
||||
"""
|
||||
|
||||
async def run(self, prd):
|
||||
self.prd = prd
|
||||
prompt = self.prd_review_prompt_template.format(prd=self.prd)
|
||||
review = await self._aask(prompt)
|
||||
return review
|
||||
|
||||
37
metagpt/actions/write_review.py
Normal file
37
metagpt/actions/write_review.py
Normal file
|
|
@ -0,0 +1,37 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Author : alexanderwu
|
||||
@File : write_review.py
|
||||
"""
|
||||
from typing import List
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
|
||||
REVIEW = ActionNode(
|
||||
key="Review",
|
||||
expected_type=List[str],
|
||||
instruction="Act as an experienced Reviewer and review the given output. Ask a series of critical questions, "
|
||||
"concisely and clearly, to help the writer improve their work.",
|
||||
example=[
|
||||
"This is a good PRD, but I think it can be improved by adding more details.",
|
||||
],
|
||||
)
|
||||
|
||||
LGTM = ActionNode(
|
||||
key="LGTM",
|
||||
expected_type=str,
|
||||
instruction="LGTM/LBTM. If the output is good enough, give a LGTM (Looks Good To Me) to the writer, "
|
||||
"else LBTM (Looks Bad To Me).",
|
||||
example="LGTM",
|
||||
)
|
||||
|
||||
WRITE_REVIEW_NODE = ActionNode.from_children("WRITE_REVIEW_NODE", [REVIEW, LGTM])
|
||||
|
||||
|
||||
class WriteReview(Action):
|
||||
"""Write a review for the given context."""
|
||||
|
||||
async def run(self, context):
|
||||
return await WRITE_REVIEW_NODE.fill(context=context, llm=self.llm, schema="json")
|
||||
|
|
@ -3,10 +3,22 @@
|
|||
"""
|
||||
@Time : 2023/5/11 22:12
|
||||
@Author : alexanderwu
|
||||
@File : environment.py
|
||||
@File : write_test.py
|
||||
@Modified By: mashenquan, 2023-11-27. Following the think-act principle, solidify the task parameters when creating the
|
||||
WriteTest object, rather than passing them in when calling the run function.
|
||||
"""
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import TEST_CODES_FILE_REPO
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.schema import Document, TestingContext
|
||||
from metagpt.utils.common import CodeParser
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
|
|
@ -15,7 +27,7 @@ NOTICE
|
|||
2. Requirement: Based on the context, develop a comprehensive test suite that adequately covers all relevant aspects of the code file under review. Your test suite will be part of the overall project QA, so please develop complete, robust, and reusable test cases.
|
||||
3. Attention1: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD WRITE BEFORE the test case or script.
|
||||
4. Attention2: If there are any settings in your tests, ALWAYS SET A DEFAULT VALUE, ALWAYS USE STRONG TYPE AND EXPLICIT VARIABLE.
|
||||
5. Attention3: YOU MUST FOLLOW "Data structures and interface definitions". DO NOT CHANGE ANY DESIGN. Make sure your tests respect the existing design and ensure its validity.
|
||||
5. Attention3: YOU MUST FOLLOW "Data structures and interfaces". DO NOT CHANGE ANY DESIGN. Make sure your tests respect the existing design and ensure its validity.
|
||||
6. Think before writing: What should be tested and validated in this document? What edge cases could exist? What might fail?
|
||||
7. CAREFULLY CHECK THAT YOU DON'T MISS ANY NECESSARY TEST CASES/SCRIPTS IN THIS FILE.
|
||||
Attention: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD WRITE BEFORE the test case or script and triple quotes.
|
||||
|
|
@ -26,13 +38,14 @@ Attention: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD W
|
|||
```
|
||||
Note that the code to test is at {source_file_path}, we will put your test code at {workspace}/tests/{test_file_name}, and run your test code from {workspace},
|
||||
you should correctly import the necessary classes based on these file locations!
|
||||
## {test_file_name}: Write test code with triple quoto. Do your best to implement THIS ONLY ONE FILE.
|
||||
## {test_file_name}: Write test code with triple quote. Do your best to implement THIS ONLY ONE FILE.
|
||||
"""
|
||||
|
||||
|
||||
class WriteTest(Action):
|
||||
def __init__(self, name="WriteTest", context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
name: str = "WriteTest"
|
||||
context: Optional[str] = None
|
||||
llm: BaseGPTAPI = Field(default_factory=LLM)
|
||||
|
||||
async def write_code(self, prompt):
|
||||
code_rsp = await self._aask(prompt)
|
||||
|
|
@ -47,12 +60,16 @@ class WriteTest(Action):
|
|||
code = code_rsp
|
||||
return code
|
||||
|
||||
async def run(self, code_to_test, test_file_name, source_file_path, workspace):
|
||||
async def run(self, *args, **kwargs) -> TestingContext:
|
||||
if not self.context.test_doc:
|
||||
self.context.test_doc = Document(
|
||||
filename="test_" + self.context.code_doc.filename, root_path=TEST_CODES_FILE_REPO
|
||||
)
|
||||
prompt = PROMPT_TEMPLATE.format(
|
||||
code_to_test=code_to_test,
|
||||
test_file_name=test_file_name,
|
||||
source_file_path=source_file_path,
|
||||
workspace=workspace,
|
||||
code_to_test=self.context.code_doc.content,
|
||||
test_file_name=self.context.test_doc.filename,
|
||||
source_file_path=self.context.code_doc.root_relative_path,
|
||||
workspace=CONFIG.git_repo.workdir,
|
||||
)
|
||||
code = await self.write_code(prompt)
|
||||
return code
|
||||
self.context.test_doc.content = await self.write_code(prompt)
|
||||
return self.context
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@
|
|||
from typing import Dict
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.prompts.tutorial_assistant import DIRECTORY_PROMPT, CONTENT_PROMPT
|
||||
from metagpt.prompts.tutorial_assistant import CONTENT_PROMPT, DIRECTORY_PROMPT
|
||||
from metagpt.utils.common import OutputParser
|
||||
|
||||
|
||||
|
|
@ -65,4 +65,3 @@ class WriteContent(Action):
|
|||
"""
|
||||
prompt = CONTENT_PROMPT.format(topic=topic, language=self.language, directory=self.directory)
|
||||
return await self._aask(prompt=prompt)
|
||||
|
||||
|
|
|
|||
|
|
@ -2,12 +2,19 @@
|
|||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
Provide configuration, singleton
|
||||
@Modified By: mashenquan, 2023/11/27.
|
||||
1. According to Section 2.2.3.11 of RFC 135, add git repository support.
|
||||
2. Add the parameter `src_workspace` for the old version project path.
|
||||
"""
|
||||
import os
|
||||
from copy import deepcopy
|
||||
from enum import Enum
|
||||
from pathlib import Path
|
||||
from typing import Any
|
||||
|
||||
import yaml
|
||||
|
||||
from metagpt.const import PROJECT_ROOT
|
||||
from metagpt.const import DEFAULT_WORKSPACE_ROOT, METAGPT_ROOT, OPTIONS
|
||||
from metagpt.logs import logger
|
||||
from metagpt.tools import SearchEngineType, WebBrowserEngineType
|
||||
from metagpt.utils.singleton import Singleton
|
||||
|
|
@ -25,6 +32,15 @@ class NotConfiguredException(Exception):
|
|||
super().__init__(self.message)
|
||||
|
||||
|
||||
class LLMProviderEnum(Enum):
|
||||
OPENAI = "openai"
|
||||
ANTHROPIC = "anthropic"
|
||||
SPARK = "spark"
|
||||
ZHIPUAI = "zhipuai"
|
||||
FIREWORKS = "fireworks"
|
||||
OPEN_LLM = "open_llm"
|
||||
|
||||
|
||||
class Config(metaclass=Singleton):
|
||||
"""
|
||||
Regular usage method:
|
||||
|
|
@ -34,29 +50,60 @@ class Config(metaclass=Singleton):
|
|||
"""
|
||||
|
||||
_instance = None
|
||||
key_yaml_file = PROJECT_ROOT / "config/key.yaml"
|
||||
default_yaml_file = PROJECT_ROOT / "config/config.yaml"
|
||||
home_yaml_file = Path.home() / ".metagpt/config.yaml"
|
||||
key_yaml_file = METAGPT_ROOT / "config/key.yaml"
|
||||
default_yaml_file = METAGPT_ROOT / "config/config.yaml"
|
||||
|
||||
def __init__(self, yaml_file=default_yaml_file):
|
||||
self._configs = {}
|
||||
self._init_with_config_files_and_env(self._configs, yaml_file)
|
||||
logger.info("Config loading done.")
|
||||
global_options = OPTIONS.get()
|
||||
# cli paras
|
||||
self.project_path = ""
|
||||
self.project_name = ""
|
||||
self.inc = False
|
||||
self.reqa_file = ""
|
||||
self.max_auto_summarize_code = 0
|
||||
|
||||
self._init_with_config_files_and_env(yaml_file)
|
||||
self._update()
|
||||
global_options.update(OPTIONS.get())
|
||||
logger.debug("Config loading done.")
|
||||
|
||||
def get_default_llm_provider_enum(self) -> LLMProviderEnum:
|
||||
for k, v in [
|
||||
(self.openai_api_key, LLMProviderEnum.OPENAI),
|
||||
(self.anthropic_api_key, LLMProviderEnum.ANTHROPIC),
|
||||
(self.zhipuai_api_key, LLMProviderEnum.ZHIPUAI),
|
||||
(self.fireworks_api_key, LLMProviderEnum.FIREWORKS),
|
||||
(self.open_llm_api_base, LLMProviderEnum.OPEN_LLM), # reuse logic. but not a key
|
||||
]:
|
||||
if self._is_valid_llm_key(k):
|
||||
if self.openai_api_model:
|
||||
logger.info(f"OpenAI API Model: {self.openai_api_model}")
|
||||
return v
|
||||
raise NotConfiguredException("You should config a LLM configuration first")
|
||||
|
||||
@staticmethod
|
||||
def _is_valid_llm_key(k: str) -> bool:
|
||||
return k and k != "YOUR_API_KEY"
|
||||
|
||||
def _update(self):
|
||||
# logger.info("Config loading done.")
|
||||
self.global_proxy = self._get("GLOBAL_PROXY")
|
||||
|
||||
self.openai_api_key = self._get("OPENAI_API_KEY")
|
||||
self.anthropic_api_key = self._get("Anthropic_API_KEY")
|
||||
self.anthropic_api_key = self._get("ANTHROPIC_API_KEY")
|
||||
self.zhipuai_api_key = self._get("ZHIPUAI_API_KEY")
|
||||
if (
|
||||
(not self.openai_api_key or "YOUR_API_KEY" == self.openai_api_key)
|
||||
and (not self.anthropic_api_key or "YOUR_API_KEY" == self.anthropic_api_key)
|
||||
and (not self.zhipuai_api_key or "YOUR_API_KEY" == self.zhipuai_api_key)
|
||||
):
|
||||
raise NotConfiguredException("Set OPENAI_API_KEY or Anthropic_API_KEY or ZHIPUAI_API_KEY first")
|
||||
self.open_llm_api_base = self._get("OPEN_LLM_API_BASE")
|
||||
self.open_llm_api_model = self._get("OPEN_LLM_API_MODEL")
|
||||
self.fireworks_api_key = self._get("FIREWORKS_API_KEY")
|
||||
_ = self.get_default_llm_provider_enum()
|
||||
|
||||
self.openai_base_url = self._get("OPENAI_BASE_URL")
|
||||
self.openai_proxy = self._get("OPENAI_PROXY") or self.global_proxy
|
||||
self.openai_api_type = self._get("OPENAI_API_TYPE")
|
||||
self.openai_api_version = self._get("OPENAI_API_VERSION")
|
||||
self.openai_api_rpm = self._get("RPM", 3)
|
||||
self.openai_api_model = self._get("OPENAI_API_MODEL", "gpt-4")
|
||||
self.openai_api_model = self._get("OPENAI_API_MODEL", "gpt-4-1106-preview")
|
||||
self.max_tokens_rsp = self._get("MAX_TOKENS", 2048)
|
||||
self.deployment_name = self._get("DEPLOYMENT_NAME", "gpt-4")
|
||||
|
||||
|
|
@ -66,7 +113,10 @@ class Config(metaclass=Singleton):
|
|||
self.domain = self._get("DOMAIN")
|
||||
self.spark_url = self._get("SPARK_URL")
|
||||
|
||||
self.claude_api_key = self._get("Anthropic_API_KEY")
|
||||
self.fireworks_api_base = self._get("FIREWORKS_API_BASE")
|
||||
self.fireworks_api_model = self._get("FIREWORKS_API_MODEL")
|
||||
|
||||
self.claude_api_key = self._get("ANTHROPIC_API_KEY")
|
||||
self.serpapi_api_key = self._get("SERPAPI_API_KEY")
|
||||
self.serper_api_key = self._get("SERPER_API_KEY")
|
||||
self.google_api_key = self._get("GOOGLE_API_KEY")
|
||||
|
|
@ -81,6 +131,7 @@ class Config(metaclass=Singleton):
|
|||
logger.warning("LONG_TERM_MEMORY is True")
|
||||
self.max_budget = self._get("MAX_BUDGET", 10.0)
|
||||
self.total_cost = 0.0
|
||||
self.code_review_k_times = 2
|
||||
|
||||
self.puppeteer_config = self._get("PUPPETEER_CONFIG", "")
|
||||
self.mmdc = self._get("MMDC", "mmdc")
|
||||
|
|
@ -90,13 +141,33 @@ class Config(metaclass=Singleton):
|
|||
self.mermaid_engine = self._get("MERMAID_ENGINE", "nodejs")
|
||||
self.pyppeteer_executable_path = self._get("PYPPETEER_EXECUTABLE_PATH", "")
|
||||
|
||||
self.prompt_format = self._get("PROMPT_FORMAT", "markdown")
|
||||
self.repair_llm_output = self._get("REPAIR_LLM_OUTPUT", False)
|
||||
self.prompt_schema = self._get("PROMPT_FORMAT", "json")
|
||||
self.workspace_path = Path(self._get("WORKSPACE_PATH", DEFAULT_WORKSPACE_ROOT))
|
||||
self._ensure_workspace_exists()
|
||||
|
||||
def _init_with_config_files_and_env(self, configs: dict, yaml_file):
|
||||
def update_via_cli(self, project_path, project_name, inc, reqa_file, max_auto_summarize_code):
|
||||
"""update config via cli"""
|
||||
|
||||
# Use in the PrepareDocuments action according to Section 2.2.3.5.1 of RFC 135.
|
||||
if project_path:
|
||||
inc = True
|
||||
project_name = project_name or Path(project_path).name
|
||||
self.project_path = project_path
|
||||
self.project_name = project_name
|
||||
self.inc = inc
|
||||
self.reqa_file = reqa_file
|
||||
self.max_auto_summarize_code = max_auto_summarize_code
|
||||
|
||||
def _ensure_workspace_exists(self):
|
||||
self.workspace_path.mkdir(parents=True, exist_ok=True)
|
||||
logger.debug(f"WORKSPACE_PATH set to {self.workspace_path}")
|
||||
|
||||
def _init_with_config_files_and_env(self, yaml_file):
|
||||
"""Load from config/key.yaml, config/config.yaml, and env in decreasing order of priority"""
|
||||
configs.update(os.environ)
|
||||
configs = dict(os.environ)
|
||||
|
||||
for _yaml_file in [yaml_file, self.key_yaml_file]:
|
||||
for _yaml_file in [yaml_file, self.key_yaml_file, self.home_yaml_file]:
|
||||
if not _yaml_file.exists():
|
||||
continue
|
||||
|
||||
|
|
@ -105,11 +176,13 @@ class Config(metaclass=Singleton):
|
|||
yaml_data = yaml.safe_load(file)
|
||||
if not yaml_data:
|
||||
continue
|
||||
os.environ.update({k: v for k, v in yaml_data.items() if isinstance(v, str)})
|
||||
configs.update(yaml_data)
|
||||
OPTIONS.set(configs)
|
||||
|
||||
def _get(self, *args, **kwargs):
|
||||
return self._configs.get(*args, **kwargs)
|
||||
@staticmethod
|
||||
def _get(*args, **kwargs):
|
||||
i = OPTIONS.get()
|
||||
return i.get(*args, **kwargs)
|
||||
|
||||
def get(self, key, *args, **kwargs):
|
||||
"""Search for a value in config/key.yaml, config/config.yaml, and env; raise an error if not found"""
|
||||
|
|
@ -118,5 +191,33 @@ class Config(metaclass=Singleton):
|
|||
raise ValueError(f"Key '{key}' not found in environment variables or in the YAML file")
|
||||
return value
|
||||
|
||||
def __setattr__(self, name: str, value: Any) -> None:
|
||||
OPTIONS.get()[name] = value
|
||||
|
||||
def __getattr__(self, name: str) -> Any:
|
||||
i = OPTIONS.get()
|
||||
return i.get(name)
|
||||
|
||||
def set_context(self, options: dict):
|
||||
"""Update current config"""
|
||||
if not options:
|
||||
return
|
||||
opts = deepcopy(OPTIONS.get())
|
||||
opts.update(options)
|
||||
OPTIONS.set(opts)
|
||||
self._update()
|
||||
|
||||
@property
|
||||
def options(self):
|
||||
"""Return all key-values"""
|
||||
return OPTIONS.get()
|
||||
|
||||
def new_environ(self):
|
||||
"""Return a new os.environ object"""
|
||||
env = os.environ.copy()
|
||||
i = self.options
|
||||
env.update({k: v for k, v in i.items() if isinstance(v, str)})
|
||||
return env
|
||||
|
||||
|
||||
CONFIG = Config()
|
||||
|
|
|
|||
116
metagpt/const.py
116
metagpt/const.py
|
|
@ -4,45 +4,101 @@
|
|||
@Time : 2023/5/1 11:59
|
||||
@Author : alexanderwu
|
||||
@File : const.py
|
||||
@Modified By: mashenquan, 2023-11-1. According to Section 2.2.1 and 2.2.2 of RFC 116, added key definitions for
|
||||
common properties in the Message.
|
||||
@Modified By: mashenquan, 2023-11-27. Defines file repository paths according to Section 2.2.3.4 of RFC 135.
|
||||
@Modified By: mashenquan, 2023/12/5. Add directories for code summarization..
|
||||
"""
|
||||
import contextvars
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
from loguru import logger
|
||||
|
||||
def get_project_root():
|
||||
"""Search upwards to find the project root directory."""
|
||||
current_path = Path.cwd()
|
||||
while True:
|
||||
if (
|
||||
(current_path / ".git").exists()
|
||||
or (current_path / ".project_root").exists()
|
||||
or (current_path / ".gitignore").exists()
|
||||
):
|
||||
# use metagpt with git clone will land here
|
||||
logger.info(f"PROJECT_ROOT set to {str(current_path)}")
|
||||
return current_path
|
||||
parent_path = current_path.parent
|
||||
if parent_path == current_path:
|
||||
# use metagpt with pip install will land here
|
||||
cwd = Path.cwd()
|
||||
logger.info(f"PROJECT_ROOT set to current working directory: {str(cwd)}")
|
||||
return cwd
|
||||
current_path = parent_path
|
||||
import metagpt
|
||||
|
||||
OPTIONS = contextvars.ContextVar("OPTIONS", default={})
|
||||
|
||||
|
||||
PROJECT_ROOT = get_project_root()
|
||||
DATA_PATH = PROJECT_ROOT / "data"
|
||||
WORKSPACE_ROOT = PROJECT_ROOT / "workspace"
|
||||
PROMPT_PATH = PROJECT_ROOT / "metagpt/prompts"
|
||||
UT_PATH = PROJECT_ROOT / "data/ut"
|
||||
SWAGGER_PATH = UT_PATH / "files/api/"
|
||||
UT_PY_PATH = UT_PATH / "files/ut/"
|
||||
API_QUESTIONS_PATH = UT_PATH / "files/question/"
|
||||
YAPI_URL = "http://yapi.deepwisdomai.com/"
|
||||
TMP = PROJECT_ROOT / "tmp"
|
||||
def get_metagpt_package_root():
|
||||
"""Get the root directory of the installed package."""
|
||||
package_root = Path(metagpt.__file__).parent.parent
|
||||
for i in (".git", ".project_root", ".gitignore"):
|
||||
if (package_root / i).exists():
|
||||
break
|
||||
else:
|
||||
package_root = Path.cwd()
|
||||
|
||||
logger.info(f"Package root set to {str(package_root)}")
|
||||
return package_root
|
||||
|
||||
|
||||
def get_metagpt_root():
|
||||
"""Get the project root directory."""
|
||||
# Check if a project root is specified in the environment variable
|
||||
project_root_env = os.getenv("METAGPT_PROJECT_ROOT")
|
||||
if project_root_env:
|
||||
project_root = Path(project_root_env)
|
||||
logger.info(f"PROJECT_ROOT set from environment variable to {str(project_root)}")
|
||||
else:
|
||||
# Fallback to package root if no environment variable is set
|
||||
project_root = get_metagpt_package_root()
|
||||
return project_root
|
||||
|
||||
|
||||
# METAGPT PROJECT ROOT AND VARS
|
||||
|
||||
METAGPT_ROOT = get_metagpt_root()
|
||||
DEFAULT_WORKSPACE_ROOT = METAGPT_ROOT / "workspace"
|
||||
|
||||
DATA_PATH = METAGPT_ROOT / "data"
|
||||
RESEARCH_PATH = DATA_PATH / "research"
|
||||
TUTORIAL_PATH = DATA_PATH / "tutorial_docx"
|
||||
INVOICE_OCR_TABLE_PATH = DATA_PATH / "invoice_table"
|
||||
|
||||
SKILL_DIRECTORY = PROJECT_ROOT / "metagpt/skills"
|
||||
UT_PATH = DATA_PATH / "ut"
|
||||
SWAGGER_PATH = UT_PATH / "files/api/"
|
||||
UT_PY_PATH = UT_PATH / "files/ut/"
|
||||
API_QUESTIONS_PATH = UT_PATH / "files/question/"
|
||||
|
||||
SERDESER_PATH = DEFAULT_WORKSPACE_ROOT / "storage" # TODO to store `storage` under the individual generated project
|
||||
|
||||
TMP = METAGPT_ROOT / "tmp"
|
||||
|
||||
SOURCE_ROOT = METAGPT_ROOT / "metagpt"
|
||||
PROMPT_PATH = SOURCE_ROOT / "prompts"
|
||||
SKILL_DIRECTORY = SOURCE_ROOT / "skills"
|
||||
|
||||
|
||||
# REAL CONSTS
|
||||
|
||||
MEM_TTL = 24 * 30 * 3600
|
||||
|
||||
|
||||
MESSAGE_ROUTE_FROM = "sent_from"
|
||||
MESSAGE_ROUTE_TO = "send_to"
|
||||
MESSAGE_ROUTE_CAUSE_BY = "cause_by"
|
||||
MESSAGE_META_ROLE = "role"
|
||||
MESSAGE_ROUTE_TO_ALL = "<all>"
|
||||
MESSAGE_ROUTE_TO_NONE = "<none>"
|
||||
|
||||
REQUIREMENT_FILENAME = "requirement.txt"
|
||||
BUGFIX_FILENAME = "bugfix.txt"
|
||||
PACKAGE_REQUIREMENTS_FILENAME = "requirements.txt"
|
||||
|
||||
DOCS_FILE_REPO = "docs"
|
||||
PRDS_FILE_REPO = "docs/prds"
|
||||
SYSTEM_DESIGN_FILE_REPO = "docs/system_design"
|
||||
TASK_FILE_REPO = "docs/tasks"
|
||||
COMPETITIVE_ANALYSIS_FILE_REPO = "resources/competitive_analysis"
|
||||
DATA_API_DESIGN_FILE_REPO = "resources/data_api_design"
|
||||
SEQ_FLOW_FILE_REPO = "resources/seq_flow"
|
||||
SYSTEM_DESIGN_PDF_FILE_REPO = "resources/system_design"
|
||||
PRD_PDF_FILE_REPO = "resources/prd"
|
||||
TASK_PDF_FILE_REPO = "resources/api_spec_and_tasks"
|
||||
TEST_CODES_FILE_REPO = "tests"
|
||||
TEST_OUTPUTS_FILE_REPO = "test_outputs"
|
||||
CODE_SUMMARIES_FILE_REPO = "docs/code_summaries"
|
||||
CODE_SUMMARIES_PDF_FILE_REPO = "resources/code_summaries"
|
||||
|
||||
YAPI_URL = "http://yapi.deepwisdomai.com/"
|
||||
|
|
|
|||
256
metagpt/document.py
Normal file
256
metagpt/document.py
Normal file
|
|
@ -0,0 +1,256 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/6/8 14:03
|
||||
@Author : alexanderwu
|
||||
@File : document.py
|
||||
@Desc : Classes and Operations Related to Files in the File System.
|
||||
"""
|
||||
from enum import Enum
|
||||
from pathlib import Path
|
||||
from typing import Optional, Union
|
||||
|
||||
import pandas as pd
|
||||
from langchain.document_loaders import (
|
||||
TextLoader,
|
||||
UnstructuredPDFLoader,
|
||||
UnstructuredWordDocumentLoader,
|
||||
)
|
||||
from langchain.text_splitter import CharacterTextSplitter
|
||||
from pydantic import BaseModel, Field
|
||||
from tqdm import tqdm
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.logs import logger
|
||||
from metagpt.repo_parser import RepoParser
|
||||
|
||||
|
||||
def validate_cols(content_col: str, df: pd.DataFrame):
|
||||
if content_col not in df.columns:
|
||||
raise ValueError("Content column not found in DataFrame.")
|
||||
|
||||
|
||||
def read_data(data_path: Path):
|
||||
suffix = data_path.suffix
|
||||
if ".xlsx" == suffix:
|
||||
data = pd.read_excel(data_path)
|
||||
elif ".csv" == suffix:
|
||||
data = pd.read_csv(data_path)
|
||||
elif ".json" == suffix:
|
||||
data = pd.read_json(data_path)
|
||||
elif suffix in (".docx", ".doc"):
|
||||
data = UnstructuredWordDocumentLoader(str(data_path), mode="elements").load()
|
||||
elif ".txt" == suffix:
|
||||
data = TextLoader(str(data_path)).load()
|
||||
text_splitter = CharacterTextSplitter(separator="\n", chunk_size=256, chunk_overlap=0)
|
||||
texts = text_splitter.split_documents(data)
|
||||
data = texts
|
||||
elif ".pdf" == suffix:
|
||||
data = UnstructuredPDFLoader(str(data_path), mode="elements").load()
|
||||
else:
|
||||
raise NotImplementedError("File format not supported.")
|
||||
return data
|
||||
|
||||
|
||||
class DocumentStatus(Enum):
|
||||
"""Indicates document status, a mechanism similar to RFC/PEP"""
|
||||
|
||||
DRAFT = "draft"
|
||||
UNDERREVIEW = "underreview"
|
||||
APPROVED = "approved"
|
||||
DONE = "done"
|
||||
|
||||
|
||||
class Document(BaseModel):
|
||||
"""
|
||||
Document: Handles operations related to document files.
|
||||
"""
|
||||
|
||||
path: Path = Field(default=None)
|
||||
name: str = Field(default="")
|
||||
content: str = Field(default="")
|
||||
|
||||
# metadata? in content perhaps.
|
||||
author: str = Field(default="")
|
||||
status: DocumentStatus = Field(default=DocumentStatus.DRAFT)
|
||||
reviews: list = Field(default_factory=list)
|
||||
|
||||
@classmethod
|
||||
def from_path(cls, path: Path):
|
||||
"""
|
||||
Create a Document instance from a file path.
|
||||
"""
|
||||
if not path.exists():
|
||||
raise FileNotFoundError(f"File {path} not found.")
|
||||
content = path.read_text()
|
||||
return cls(content=content, path=path)
|
||||
|
||||
@classmethod
|
||||
def from_text(cls, text: str, path: Optional[Path] = None):
|
||||
"""
|
||||
Create a Document from a text string.
|
||||
"""
|
||||
return cls(content=text, path=path)
|
||||
|
||||
def to_path(self, path: Optional[Path] = None):
|
||||
"""
|
||||
Save content to the specified file path.
|
||||
"""
|
||||
if path is not None:
|
||||
self.path = path
|
||||
|
||||
if self.path is None:
|
||||
raise ValueError("File path is not set.")
|
||||
|
||||
self.path.parent.mkdir(parents=True, exist_ok=True)
|
||||
self.path.write_text(self.content, encoding="utf-8")
|
||||
|
||||
def persist(self):
|
||||
"""
|
||||
Persist document to disk.
|
||||
"""
|
||||
return self.to_path()
|
||||
|
||||
|
||||
class IndexableDocument(Document):
|
||||
"""
|
||||
Advanced document handling: For vector databases or search engines.
|
||||
"""
|
||||
|
||||
data: Union[pd.DataFrame, list]
|
||||
content_col: Optional[str] = Field(default="")
|
||||
meta_col: Optional[str] = Field(default="")
|
||||
|
||||
class Config:
|
||||
arbitrary_types_allowed = True
|
||||
|
||||
@classmethod
|
||||
def from_path(cls, data_path: Path, content_col="content", meta_col="metadata"):
|
||||
if not data_path.exists():
|
||||
raise FileNotFoundError(f"File {data_path} not found.")
|
||||
data = read_data(data_path)
|
||||
content = data_path.read_text()
|
||||
if isinstance(data, pd.DataFrame):
|
||||
validate_cols(content_col, data)
|
||||
return cls(data=data, content=content, content_col=content_col, meta_col=meta_col)
|
||||
|
||||
def _get_docs_and_metadatas_by_df(self) -> (list, list):
|
||||
df = self.data
|
||||
docs = []
|
||||
metadatas = []
|
||||
for i in tqdm(range(len(df))):
|
||||
docs.append(df[self.content_col].iloc[i])
|
||||
if self.meta_col:
|
||||
metadatas.append({self.meta_col: df[self.meta_col].iloc[i]})
|
||||
else:
|
||||
metadatas.append({})
|
||||
return docs, metadatas
|
||||
|
||||
def _get_docs_and_metadatas_by_langchain(self) -> (list, list):
|
||||
data = self.data
|
||||
docs = [i.page_content for i in data]
|
||||
metadatas = [i.metadata for i in data]
|
||||
return docs, metadatas
|
||||
|
||||
def get_docs_and_metadatas(self) -> (list, list):
|
||||
if isinstance(self.data, pd.DataFrame):
|
||||
return self._get_docs_and_metadatas_by_df()
|
||||
elif isinstance(self.data, list):
|
||||
return self._get_docs_and_metadatas_by_langchain()
|
||||
else:
|
||||
raise NotImplementedError("Data type not supported for metadata extraction.")
|
||||
|
||||
|
||||
class RepoMetadata(BaseModel):
|
||||
name: str = Field(default="")
|
||||
n_docs: int = Field(default=0)
|
||||
n_chars: int = Field(default=0)
|
||||
symbols: list = Field(default_factory=list)
|
||||
|
||||
|
||||
class Repo(BaseModel):
|
||||
# Name of this repo.
|
||||
name: str = Field(default="")
|
||||
# metadata: RepoMetadata = Field(default=RepoMetadata)
|
||||
docs: dict[Path, Document] = Field(default_factory=dict)
|
||||
codes: dict[Path, Document] = Field(default_factory=dict)
|
||||
assets: dict[Path, Document] = Field(default_factory=dict)
|
||||
path: Path = Field(default=None)
|
||||
|
||||
def _path(self, filename):
|
||||
return self.path / filename
|
||||
|
||||
@classmethod
|
||||
def from_path(cls, path: Path):
|
||||
"""Load documents, code, and assets from a repository path."""
|
||||
path.mkdir(parents=True, exist_ok=True)
|
||||
repo = Repo(path=path, name=path.name)
|
||||
for file_path in path.rglob("*"):
|
||||
# FIXME: These judgments are difficult to support multiple programming languages and need to be more general
|
||||
if file_path.is_file() and file_path.suffix in [".json", ".txt", ".md", ".py", ".js", ".css", ".html"]:
|
||||
repo._set(file_path.read_text(), file_path)
|
||||
return repo
|
||||
|
||||
def to_path(self):
|
||||
"""Persist all documents, code, and assets to the given repository path."""
|
||||
for doc in self.docs.values():
|
||||
doc.to_path()
|
||||
for code in self.codes.values():
|
||||
code.to_path()
|
||||
for asset in self.assets.values():
|
||||
asset.to_path()
|
||||
|
||||
def _set(self, content: str, path: Path):
|
||||
"""Add a document to the appropriate category based on its file extension."""
|
||||
suffix = path.suffix
|
||||
doc = Document(content=content, path=path, name=str(path.relative_to(self.path)))
|
||||
|
||||
# FIXME: These judgments are difficult to support multiple programming languages and need to be more general
|
||||
if suffix.lower() == ".md":
|
||||
self.docs[path] = doc
|
||||
elif suffix.lower() in [".py", ".js", ".css", ".html"]:
|
||||
self.codes[path] = doc
|
||||
else:
|
||||
self.assets[path] = doc
|
||||
return doc
|
||||
|
||||
def set(self, content: str, filename: str):
|
||||
"""Set a document and persist it to disk."""
|
||||
path = self._path(filename)
|
||||
doc = self._set(content, path)
|
||||
doc.to_path()
|
||||
|
||||
def get(self, filename: str) -> Optional[Document]:
|
||||
"""Get a document by its filename."""
|
||||
path = self._path(filename)
|
||||
return self.docs.get(path) or self.codes.get(path) or self.assets.get(path)
|
||||
|
||||
def get_text_documents(self) -> list[Document]:
|
||||
return list(self.docs.values()) + list(self.codes.values())
|
||||
|
||||
def eda(self) -> RepoMetadata:
|
||||
n_docs = sum(len(i) for i in [self.docs, self.codes, self.assets])
|
||||
n_chars = sum(sum(len(j.content) for j in i.values()) for i in [self.docs, self.codes, self.assets])
|
||||
symbols = RepoParser(base_directory=self.path).generate_symbols()
|
||||
return RepoMetadata(name=self.name, n_docs=n_docs, n_chars=n_chars, symbols=symbols)
|
||||
|
||||
|
||||
def set_existing_repo(path=CONFIG.workspace_path / "t1"):
|
||||
repo1 = Repo.from_path(path)
|
||||
repo1.set("wtf content", "doc/wtf_file.md")
|
||||
repo1.set("wtf code", "code/wtf_file.py")
|
||||
logger.info(repo1) # check doc
|
||||
|
||||
|
||||
def load_existing_repo(path=CONFIG.workspace_path / "web_tetris"):
|
||||
repo = Repo.from_path(path)
|
||||
logger.info(repo)
|
||||
logger.info(repo.eda())
|
||||
|
||||
|
||||
def main():
|
||||
load_existing_repo()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
|
@ -28,20 +28,20 @@ class BaseStore(ABC):
|
|||
|
||||
|
||||
class LocalStore(BaseStore, ABC):
|
||||
def __init__(self, raw_data: Path, cache_dir: Path = None):
|
||||
if not raw_data:
|
||||
def __init__(self, raw_data_path: Path, cache_dir: Path = None):
|
||||
if not raw_data_path:
|
||||
raise FileNotFoundError
|
||||
self.config = Config()
|
||||
self.raw_data = raw_data
|
||||
self.raw_data_path = raw_data_path
|
||||
if not cache_dir:
|
||||
cache_dir = raw_data.parent
|
||||
cache_dir = raw_data_path.parent
|
||||
self.cache_dir = cache_dir
|
||||
self.store = self._load()
|
||||
if not self.store:
|
||||
self.store = self.write()
|
||||
|
||||
def _get_index_and_store_fname(self):
|
||||
fname = self.raw_data.name.split('.')[0]
|
||||
fname = self.raw_data_path.name.split(".")[0]
|
||||
index_file = self.cache_dir / f"{fname}.index"
|
||||
store_file = self.cache_dir / f"{fname}.pkl"
|
||||
return index_file, store_file
|
||||
|
|
@ -53,4 +53,3 @@ class LocalStore(BaseStore, ABC):
|
|||
@abstractmethod
|
||||
def _write(self, docs, metadatas):
|
||||
raise NotImplementedError
|
||||
|
||||
|
|
@ -10,6 +10,7 @@ import chromadb
|
|||
|
||||
class ChromaStore:
|
||||
"""If inherited from BaseStore, or importing other modules from metagpt, a Python exception occurs, which is strange."""
|
||||
|
||||
def __init__(self, name):
|
||||
client = chromadb.Client()
|
||||
collection = client.create_collection(name)
|
||||
|
|
@ -22,7 +23,7 @@ class ChromaStore:
|
|||
query_texts=[query],
|
||||
n_results=n_results,
|
||||
where=metadata_filter, # optional filter
|
||||
where_document=document_filter # optional filter
|
||||
where_document=document_filter, # optional filter
|
||||
)
|
||||
return results
|
||||
|
||||
|
|
|
|||
|
|
@ -4,6 +4,7 @@
|
|||
@Time : 2023/6/8 14:03
|
||||
@Author : alexanderwu
|
||||
@File : document.py
|
||||
@Desc : Classes and Operations Related to Vector Files in the Vector Database. Still under design.
|
||||
"""
|
||||
from pathlib import Path
|
||||
|
||||
|
|
@ -24,20 +25,20 @@ def validate_cols(content_col: str, df: pd.DataFrame):
|
|||
|
||||
def read_data(data_path: Path):
|
||||
suffix = data_path.suffix
|
||||
if '.xlsx' == suffix:
|
||||
if ".xlsx" == suffix:
|
||||
data = pd.read_excel(data_path)
|
||||
elif '.csv' == suffix:
|
||||
elif ".csv" == suffix:
|
||||
data = pd.read_csv(data_path)
|
||||
elif '.json' == suffix:
|
||||
elif ".json" == suffix:
|
||||
data = pd.read_json(data_path)
|
||||
elif suffix in ('.docx', '.doc'):
|
||||
data = UnstructuredWordDocumentLoader(str(data_path), mode='elements').load()
|
||||
elif '.txt' == suffix:
|
||||
elif suffix in (".docx", ".doc"):
|
||||
data = UnstructuredWordDocumentLoader(str(data_path), mode="elements").load()
|
||||
elif ".txt" == suffix:
|
||||
data = TextLoader(str(data_path)).load()
|
||||
text_splitter = CharacterTextSplitter(separator='\n', chunk_size=256, chunk_overlap=0)
|
||||
text_splitter = CharacterTextSplitter(separator="\n", chunk_size=256, chunk_overlap=0)
|
||||
texts = text_splitter.split_documents(data)
|
||||
data = texts
|
||||
elif '.pdf' == suffix:
|
||||
elif ".pdf" == suffix:
|
||||
data = UnstructuredPDFLoader(str(data_path), mode="elements").load()
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
|
@ -45,8 +46,7 @@ def read_data(data_path: Path):
|
|||
|
||||
|
||||
class Document:
|
||||
|
||||
def __init__(self, data_path, content_col='content', meta_col='metadata'):
|
||||
def __init__(self, data_path, content_col="content", meta_col="metadata"):
|
||||
self.data = read_data(data_path)
|
||||
if isinstance(self.data, pd.DataFrame):
|
||||
validate_cols(content_col, self.data)
|
||||
|
|
@ -79,4 +79,3 @@ class Document:
|
|||
return self._get_docs_and_metadatas_by_langchain()
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
|
|
@ -5,6 +5,7 @@
|
|||
@Author : alexanderwu
|
||||
@File : faiss_store.py
|
||||
"""
|
||||
import asyncio
|
||||
import pickle
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
|
@ -14,16 +15,16 @@ from langchain.embeddings import OpenAIEmbeddings
|
|||
from langchain.vectorstores import FAISS
|
||||
|
||||
from metagpt.const import DATA_PATH
|
||||
from metagpt.document import IndexableDocument
|
||||
from metagpt.document_store.base_store import LocalStore
|
||||
from metagpt.document_store.document import Document
|
||||
from metagpt.logs import logger
|
||||
|
||||
|
||||
class FaissStore(LocalStore):
|
||||
def __init__(self, raw_data: Path, cache_dir=None, meta_col='source', content_col='output'):
|
||||
def __init__(self, raw_data_path: Path, cache_dir=None, meta_col="source", content_col="output"):
|
||||
self.meta_col = meta_col
|
||||
self.content_col = content_col
|
||||
super().__init__(raw_data, cache_dir)
|
||||
super().__init__(raw_data_path, cache_dir)
|
||||
|
||||
def _load(self) -> Optional["FaissStore"]:
|
||||
index_file, store_file = self._get_index_and_store_fname()
|
||||
|
|
@ -50,7 +51,7 @@ class FaissStore(LocalStore):
|
|||
pickle.dump(store, f)
|
||||
store.index = index
|
||||
|
||||
def search(self, query, expand_cols=False, sep='\n', *args, k=5, **kwargs):
|
||||
def search(self, query, expand_cols=False, sep="\n", *args, k=5, **kwargs):
|
||||
rsp = self.store.similarity_search(query, k=k, **kwargs)
|
||||
logger.debug(rsp)
|
||||
if expand_cols:
|
||||
|
|
@ -58,11 +59,14 @@ class FaissStore(LocalStore):
|
|||
else:
|
||||
return str(sep.join([f"{x.page_content}" for x in rsp]))
|
||||
|
||||
async def asearch(self, *args, **kwargs):
|
||||
return await asyncio.to_thread(self.search, *args, **kwargs)
|
||||
|
||||
def write(self):
|
||||
"""Initialize the index and library based on the Document (JSON / XLSX, etc.) file provided by the user."""
|
||||
if not self.raw_data.exists():
|
||||
if not self.raw_data_path.exists():
|
||||
raise FileNotFoundError
|
||||
doc = Document(self.raw_data, self.content_col, self.meta_col)
|
||||
doc = IndexableDocument.from_path(self.raw_data_path, self.content_col, self.meta_col)
|
||||
docs, metadatas = doc.get_docs_and_metadatas()
|
||||
|
||||
self.store = self._write(docs, metadatas)
|
||||
|
|
@ -78,8 +82,8 @@ class FaissStore(LocalStore):
|
|||
raise NotImplementedError
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
faiss_store = FaissStore(DATA_PATH / 'qcs/qcs_4w.json')
|
||||
logger.info(faiss_store.search('Oily Skin Facial Cleanser'))
|
||||
faiss_store.add([f'Oily Skin Facial Cleanser-{i}' for i in range(3)])
|
||||
logger.info(faiss_store.search('Oily Skin Facial Cleanser'))
|
||||
if __name__ == "__main__":
|
||||
faiss_store = FaissStore(DATA_PATH / "qcs/qcs_4w.json")
|
||||
logger.info(faiss_store.search("Oily Skin Facial Cleanser"))
|
||||
faiss_store.add([f"Oily Skin Facial Cleanser-{i}" for i in range(3)])
|
||||
logger.info(faiss_store.search("Oily Skin Facial Cleanser"))
|
||||
|
|
|
|||
|
|
@ -12,12 +12,7 @@ from pymilvus import Collection, CollectionSchema, DataType, FieldSchema, connec
|
|||
|
||||
from metagpt.document_store.base_store import BaseStore
|
||||
|
||||
type_mapping = {
|
||||
int: DataType.INT64,
|
||||
str: DataType.VARCHAR,
|
||||
float: DataType.DOUBLE,
|
||||
np.ndarray: DataType.FLOAT_VECTOR
|
||||
}
|
||||
type_mapping = {int: DataType.INT64, str: DataType.VARCHAR, float: DataType.DOUBLE, np.ndarray: DataType.FLOAT_VECTOR}
|
||||
|
||||
|
||||
def columns_to_milvus_schema(columns: dict, primary_col_name: str = "", desc: str = ""):
|
||||
|
|
@ -52,17 +47,11 @@ class MilvusStore(BaseStore):
|
|||
self.collection = None
|
||||
|
||||
def _create_collection(self, name, schema):
|
||||
collection = Collection(
|
||||
name=name,
|
||||
schema=schema,
|
||||
using='default',
|
||||
shards_num=2,
|
||||
consistency_level="Strong"
|
||||
)
|
||||
collection = Collection(name=name, schema=schema, using="default", shards_num=2, consistency_level="Strong")
|
||||
return collection
|
||||
|
||||
def create_collection(self, name, columns):
|
||||
schema = columns_to_milvus_schema(columns, 'idx')
|
||||
schema = columns_to_milvus_schema(columns, "idx")
|
||||
self.collection = self._create_collection(name, schema)
|
||||
return self.collection
|
||||
|
||||
|
|
@ -72,7 +61,7 @@ class MilvusStore(BaseStore):
|
|||
def load_collection(self):
|
||||
self.collection.load()
|
||||
|
||||
def build_index(self, field='emb'):
|
||||
def build_index(self, field="emb"):
|
||||
self.collection.create_index(field, {"index_type": "FLAT", "metric_type": "L2", "params": {}})
|
||||
|
||||
def search(self, query: list[list[float]], *args, **kwargs):
|
||||
|
|
@ -85,11 +74,11 @@ class MilvusStore(BaseStore):
|
|||
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
|
||||
results = self.collection.search(
|
||||
data=query,
|
||||
anns_field=kwargs.get('field', 'emb'),
|
||||
anns_field=kwargs.get("field", "emb"),
|
||||
param=search_params,
|
||||
limit=10,
|
||||
expr=None,
|
||||
consistency_level="Strong"
|
||||
consistency_level="Strong",
|
||||
)
|
||||
# FIXME: results contain id, but to get the actual value from the id, we still need to call the query interface
|
||||
return results
|
||||
|
|
|
|||
|
|
@ -10,13 +10,14 @@ from metagpt.document_store.base_store import BaseStore
|
|||
@dataclass
|
||||
class QdrantConnection:
|
||||
"""
|
||||
Args:
|
||||
url: qdrant url
|
||||
host: qdrant host
|
||||
port: qdrant port
|
||||
memory: qdrant service use memory mode
|
||||
api_key: qdrant cloud api_key
|
||||
"""
|
||||
Args:
|
||||
url: qdrant url
|
||||
host: qdrant host
|
||||
port: qdrant port
|
||||
memory: qdrant service use memory mode
|
||||
api_key: qdrant cloud api_key
|
||||
"""
|
||||
|
||||
url: str = None
|
||||
host: str = None
|
||||
port: int = None
|
||||
|
|
@ -31,9 +32,7 @@ class QdrantStore(BaseStore):
|
|||
elif connect.url:
|
||||
self.client = QdrantClient(url=connect.url, api_key=connect.api_key)
|
||||
elif connect.host and connect.port:
|
||||
self.client = QdrantClient(
|
||||
host=connect.host, port=connect.port, api_key=connect.api_key
|
||||
)
|
||||
self.client = QdrantClient(host=connect.host, port=connect.port, api_key=connect.api_key)
|
||||
else:
|
||||
raise Exception("please check QdrantConnection.")
|
||||
|
||||
|
|
@ -58,15 +57,11 @@ class QdrantStore(BaseStore):
|
|||
try:
|
||||
self.client.get_collection(collection_name)
|
||||
if force_recreate:
|
||||
res = self.client.recreate_collection(
|
||||
collection_name, vectors_config=vectors_config, **kwargs
|
||||
)
|
||||
res = self.client.recreate_collection(collection_name, vectors_config=vectors_config, **kwargs)
|
||||
return res
|
||||
return True
|
||||
except: # noqa: E722
|
||||
return self.client.recreate_collection(
|
||||
collection_name, vectors_config=vectors_config, **kwargs
|
||||
)
|
||||
return self.client.recreate_collection(collection_name, vectors_config=vectors_config, **kwargs)
|
||||
|
||||
def has_collection(self, collection_name: str):
|
||||
try:
|
||||
|
|
|
|||
|
|
@ -4,60 +4,132 @@
|
|||
@Time : 2023/5/11 22:12
|
||||
@Author : alexanderwu
|
||||
@File : environment.py
|
||||
@Modified By: mashenquan, 2023-11-1. According to Chapter 2.2.2 of RFC 116:
|
||||
1. Remove the functionality of `Environment` class as a public message buffer.
|
||||
2. Standardize the message forwarding behavior of the `Environment` class.
|
||||
3. Add the `is_idle` property.
|
||||
@Modified By: mashenquan, 2023-11-4. According to the routing feature plan in Chapter 2.2.3.2 of RFC 113, the routing
|
||||
functionality is to be consolidated into the `Environment` class.
|
||||
"""
|
||||
import asyncio
|
||||
from typing import Iterable
|
||||
from pathlib import Path
|
||||
from typing import Iterable, Set
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from metagpt.memory import Memory
|
||||
from metagpt.roles import Role
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles.role import Role, role_subclass_registry
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.common import is_subscribed, read_json_file, write_json_file
|
||||
|
||||
|
||||
class Environment(BaseModel):
|
||||
"""环境,承载一批角色,角色可以向环境发布消息,可以被其他角色观察到
|
||||
Environment, hosting a batch of roles, roles can publish messages to the environment, and can be observed by other roles
|
||||
|
||||
Environment, hosting a batch of roles, roles can publish messages to the environment, and can be observed by other roles
|
||||
"""
|
||||
|
||||
roles: dict[str, Role] = Field(default_factory=dict)
|
||||
memory: Memory = Field(default_factory=Memory)
|
||||
history: str = Field(default='')
|
||||
members: dict[Role, Set] = Field(default_factory=dict)
|
||||
history: str = "" # For debug
|
||||
|
||||
class Config:
|
||||
arbitrary_types_allowed = True
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
roles = []
|
||||
for role_key, role in kwargs.get("roles", {}).items():
|
||||
current_role = kwargs["roles"][role_key]
|
||||
if isinstance(current_role, dict):
|
||||
item_class_name = current_role.get("builtin_class_name", None)
|
||||
for name, subclass in role_subclass_registry.items():
|
||||
registery_class_name = subclass.__fields__["builtin_class_name"].default
|
||||
if item_class_name == registery_class_name:
|
||||
current_role = subclass(**current_role)
|
||||
break
|
||||
kwargs["roles"][role_key] = current_role
|
||||
roles.append(current_role)
|
||||
super().__init__(**kwargs)
|
||||
|
||||
self.add_roles(roles) # add_roles again to init the Role.set_env
|
||||
|
||||
def serialize(self, stg_path: Path):
|
||||
roles_path = stg_path.joinpath("roles.json")
|
||||
roles_info = []
|
||||
for role_key, role in self.roles.items():
|
||||
roles_info.append(
|
||||
{
|
||||
"role_class": role.__class__.__name__,
|
||||
"module_name": role.__module__,
|
||||
"role_name": role.name,
|
||||
"role_sub_tags": list(self.members.get(role)),
|
||||
}
|
||||
)
|
||||
role.serialize(stg_path=stg_path.joinpath(f"roles/{role.__class__.__name__}_{role.name}"))
|
||||
write_json_file(roles_path, roles_info)
|
||||
|
||||
history_path = stg_path.joinpath("history.json")
|
||||
write_json_file(history_path, {"content": self.history})
|
||||
|
||||
@classmethod
|
||||
def deserialize(cls, stg_path: Path) -> "Environment":
|
||||
"""stg_path: ./storage/team/environment/"""
|
||||
roles_path = stg_path.joinpath("roles.json")
|
||||
roles_info = read_json_file(roles_path)
|
||||
roles = []
|
||||
for role_info in roles_info:
|
||||
# role stored in ./environment/roles/{role_class}_{role_name}
|
||||
role_path = stg_path.joinpath(f"roles/{role_info.get('role_class')}_{role_info.get('role_name')}")
|
||||
role = Role.deserialize(role_path)
|
||||
roles.append(role)
|
||||
|
||||
history = read_json_file(stg_path.joinpath("history.json"))
|
||||
history = history.get("content")
|
||||
|
||||
environment = Environment(**{"history": history})
|
||||
environment.add_roles(roles)
|
||||
|
||||
return environment
|
||||
|
||||
def add_role(self, role: Role):
|
||||
"""增加一个在当前环境的角色
|
||||
Add a role in the current environment
|
||||
Add a role in the current environment
|
||||
"""
|
||||
role.set_env(self)
|
||||
self.roles[role.profile] = role
|
||||
|
||||
def add_roles(self, roles: Iterable[Role]):
|
||||
"""增加一批在当前环境的角色
|
||||
Add a batch of characters in the current environment
|
||||
Add a batch of characters in the current environment
|
||||
"""
|
||||
for role in roles:
|
||||
self.add_role(role)
|
||||
|
||||
def publish_message(self, message: Message):
|
||||
"""向当前环境发布信息
|
||||
Post information to the current environment
|
||||
def publish_message(self, message: Message) -> bool:
|
||||
"""
|
||||
# self.message_queue.put(message)
|
||||
self.memory.add(message)
|
||||
self.history += f"\n{message}"
|
||||
Distribute the message to the recipients.
|
||||
In accordance with the Message routing structure design in Chapter 2.2.1 of RFC 116, as already planned
|
||||
in RFC 113 for the entire system, the routing information in the Message is only responsible for
|
||||
specifying the message recipient, without concern for where the message recipient is located. How to
|
||||
route the message to the message recipient is a problem addressed by the transport framework designed
|
||||
in RFC 113.
|
||||
"""
|
||||
logger.debug(f"publish_message: {message.dump()}")
|
||||
found = False
|
||||
# According to the routing feature plan in Chapter 2.2.3.2 of RFC 113
|
||||
for role, subscription in self.members.items():
|
||||
if is_subscribed(message, subscription):
|
||||
role.put_message(message)
|
||||
found = True
|
||||
if not found:
|
||||
logger.warning(f"Message no recipients: {message.dump()}")
|
||||
self.history += f"\n{message}" # For debug
|
||||
|
||||
return True
|
||||
|
||||
async def run(self, k=1):
|
||||
"""处理一次所有信息的运行
|
||||
Process all Role runs at once
|
||||
"""
|
||||
# while not self.message_queue.empty():
|
||||
# message = self.message_queue.get()
|
||||
# rsp = await self.manager.handle(message, self)
|
||||
# self.message_queue.put(rsp)
|
||||
for _ in range(k):
|
||||
futures = []
|
||||
for role in self.roles.values():
|
||||
|
|
@ -65,15 +137,32 @@ class Environment(BaseModel):
|
|||
futures.append(future)
|
||||
|
||||
await asyncio.gather(*futures)
|
||||
logger.debug(f"is idle: {self.is_idle}")
|
||||
|
||||
def get_roles(self) -> dict[str, Role]:
|
||||
"""获得环境内的所有角色
|
||||
Process all Role runs at once
|
||||
Process all Role runs at once
|
||||
"""
|
||||
return self.roles
|
||||
|
||||
def get_role(self, name: str) -> Role:
|
||||
"""获得环境内的指定角色
|
||||
get all the environment roles
|
||||
get all the environment roles
|
||||
"""
|
||||
return self.roles.get(name, None)
|
||||
|
||||
@property
|
||||
def is_idle(self):
|
||||
"""If true, all actions have been executed."""
|
||||
for r in self.roles.values():
|
||||
if not r.is_idle:
|
||||
return False
|
||||
return True
|
||||
|
||||
def get_subscription(self, obj):
|
||||
"""Get the labels for messages to be consumed by the object."""
|
||||
return self.members.get(obj, {})
|
||||
|
||||
def set_subscription(self, obj, tags):
|
||||
"""Set the labels for message to be consumed by the object"""
|
||||
self.members[obj] = tags
|
||||
|
|
|
|||
|
|
@ -1,28 +0,0 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/5/28 14:54
|
||||
@Author : alexanderwu
|
||||
@File : inspect_module.py
|
||||
"""
|
||||
|
||||
import inspect
|
||||
|
||||
import metagpt # replace with your module
|
||||
|
||||
|
||||
def print_classes_and_functions(module):
|
||||
"""FIXME: NOT WORK.. """
|
||||
for name, obj in inspect.getmembers(module):
|
||||
if inspect.isclass(obj):
|
||||
print(f'Class: {name}')
|
||||
elif inspect.isfunction(obj):
|
||||
print(f'Function: {name}')
|
||||
else:
|
||||
print(name)
|
||||
|
||||
print(dir(module))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
print_classes_and_functions(metagpt)
|
||||
|
|
@ -6,27 +6,14 @@
|
|||
@File : llm.py
|
||||
"""
|
||||
|
||||
from metagpt.logs import logger
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.provider.anthropic_api import Claude2 as Claude
|
||||
from metagpt.provider.openai_api import OpenAIGPTAPI
|
||||
from metagpt.provider.zhipuai_api import ZhiPuAIGPTAPI
|
||||
from metagpt.provider.spark_api import SparkAPI
|
||||
from metagpt.config import CONFIG, LLMProviderEnum
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.provider.human_provider import HumanProvider
|
||||
from metagpt.provider.llm_provider_registry import LLM_REGISTRY
|
||||
|
||||
_ = HumanProvider() # Avoid pre-commit error
|
||||
|
||||
|
||||
def LLM() -> "BaseGPTAPI":
|
||||
""" initialize different LLM instance according to the key field existence"""
|
||||
# TODO a little trick, can use registry to initialize LLM instance further
|
||||
if CONFIG.openai_api_key:
|
||||
llm = OpenAIGPTAPI()
|
||||
elif CONFIG.claude_api_key:
|
||||
llm = Claude()
|
||||
elif CONFIG.spark_api_key:
|
||||
llm = SparkAPI()
|
||||
elif CONFIG.zhipuai_api_key:
|
||||
llm = ZhiPuAIGPTAPI()
|
||||
else:
|
||||
raise RuntimeError("You should config a LLM configuration first")
|
||||
|
||||
return llm
|
||||
def LLM(provider: LLMProviderEnum = CONFIG.get_default_llm_provider_enum()) -> BaseGPTAPI:
|
||||
"""get the default llm provider"""
|
||||
return LLM_REGISTRY.get_provider(provider)
|
||||
|
|
|
|||
|
|
@ -7,18 +7,22 @@
|
|||
"""
|
||||
|
||||
import sys
|
||||
from datetime import datetime
|
||||
|
||||
from loguru import logger as _logger
|
||||
|
||||
from metagpt.const import PROJECT_ROOT
|
||||
from metagpt.const import METAGPT_ROOT
|
||||
|
||||
|
||||
def define_log_level(print_level="INFO", logfile_level="DEBUG"):
|
||||
"""调整日志级别到level之上
|
||||
Adjust the log level to above level
|
||||
"""
|
||||
"""Adjust the log level to above level"""
|
||||
current_date = datetime.now()
|
||||
formatted_date = current_date.strftime("%Y%m%d")
|
||||
|
||||
_logger.remove()
|
||||
_logger.add(sys.stderr, level=print_level)
|
||||
_logger.add(PROJECT_ROOT / 'logs/log.txt', level=logfile_level)
|
||||
_logger.add(METAGPT_ROOT / f"logs/{formatted_date}.txt", level=logfile_level)
|
||||
return _logger
|
||||
|
||||
|
||||
logger = define_log_level()
|
||||
|
|
|
|||
|
|
@ -19,8 +19,8 @@ class SkillManager:
|
|||
|
||||
def __init__(self):
|
||||
self._llm = LLM()
|
||||
self._store = ChromaStore('skill_manager')
|
||||
self._skills: dict[str: Skill] = {}
|
||||
self._store = ChromaStore("skill_manager")
|
||||
self._skills: dict[str:Skill] = {}
|
||||
|
||||
def add_skill(self, skill: Skill):
|
||||
"""
|
||||
|
|
@ -54,7 +54,7 @@ class SkillManager:
|
|||
:param desc: Skill description
|
||||
:return: Multiple skills
|
||||
"""
|
||||
return self._store.search(desc, n_results=n_results)['ids'][0]
|
||||
return self._store.search(desc, n_results=n_results)["ids"][0]
|
||||
|
||||
def retrieve_skill_scored(self, desc: str, n_results: int = 2) -> dict:
|
||||
"""
|
||||
|
|
@ -75,6 +75,6 @@ class SkillManager:
|
|||
logger.info(text)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
manager = SkillManager()
|
||||
manager.generate_skill_desc(Action())
|
||||
|
|
|
|||
|
|
@ -1,66 +0,0 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/5/11 14:42
|
||||
@Author : alexanderwu
|
||||
@File : manager.py
|
||||
"""
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Message
|
||||
|
||||
|
||||
class Manager:
|
||||
def __init__(self, llm: LLM = LLM()):
|
||||
self.llm = llm # Large Language Model
|
||||
self.role_directions = {
|
||||
"BOSS": "Product Manager",
|
||||
"Product Manager": "Architect",
|
||||
"Architect": "Engineer",
|
||||
"Engineer": "QA Engineer",
|
||||
"QA Engineer": "Product Manager"
|
||||
}
|
||||
self.prompt_template = """
|
||||
Given the following message:
|
||||
{message}
|
||||
|
||||
And the current status of roles:
|
||||
{roles}
|
||||
|
||||
Which role should handle this message?
|
||||
"""
|
||||
|
||||
async def handle(self, message: Message, environment):
|
||||
"""
|
||||
管理员处理信息,现在简单的将信息递交给下一个人
|
||||
The administrator processes the information, now simply passes the information on to the next person
|
||||
:param message:
|
||||
:param environment:
|
||||
:return:
|
||||
"""
|
||||
# Get all roles from the environment
|
||||
roles = environment.get_roles()
|
||||
# logger.debug(f"{roles=}, {message=}")
|
||||
|
||||
# Build a context for the LLM to understand the situation
|
||||
# context = {
|
||||
# "message": str(message),
|
||||
# "roles": {role.name: role.get_info() for role in roles},
|
||||
# }
|
||||
# Ask the LLM to decide which role should handle the message
|
||||
# chosen_role_name = self.llm.ask(self.prompt_template.format(context))
|
||||
|
||||
# FIXME: 现在通过简单的字典决定流向,但之后还是应该有思考过程
|
||||
#The direction of flow is now determined by a simple dictionary, but there should still be a thought process afterwards
|
||||
next_role_profile = self.role_directions[message.role]
|
||||
# logger.debug(f"{next_role_profile}")
|
||||
for _, role in roles.items():
|
||||
if next_role_profile == role.profile:
|
||||
next_role = role
|
||||
break
|
||||
else:
|
||||
logger.error(f"No available role can handle message: {message}.")
|
||||
return
|
||||
|
||||
# Find the chosen role and handle the message
|
||||
return await next_role.handle(message)
|
||||
|
|
@ -7,10 +7,11 @@
|
|||
"""
|
||||
|
||||
from metagpt.memory.memory import Memory
|
||||
from metagpt.memory.longterm_memory import LongTermMemory
|
||||
|
||||
# from metagpt.memory.longterm_memory import LongTermMemory
|
||||
|
||||
|
||||
__all__ = [
|
||||
"Memory",
|
||||
"LongTermMemory",
|
||||
# "LongTermMemory",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -1,6 +1,12 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : the implement of Long-term memory
|
||||
"""
|
||||
@Desc : the implement of Long-term memory
|
||||
"""
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.logs import logger
|
||||
from metagpt.memory import Memory
|
||||
|
|
@ -15,11 +21,12 @@ class LongTermMemory(Memory):
|
|||
- update memory when it changed
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.memory_storage: MemoryStorage = MemoryStorage()
|
||||
super(LongTermMemory, self).__init__()
|
||||
self.rc = None # RoleContext
|
||||
self.msg_from_recover = False
|
||||
memory_storage: MemoryStorage = Field(default_factory=MemoryStorage)
|
||||
rc: Optional["RoleContext"] = None
|
||||
msg_from_recover: bool = False
|
||||
|
||||
class Config:
|
||||
arbitrary_types_allowed = True
|
||||
|
||||
def recover_memory(self, role_id: str, rc: "RoleContext"):
|
||||
messages = self.memory_storage.recover_memory(role_id)
|
||||
|
|
@ -28,14 +35,14 @@ class LongTermMemory(Memory):
|
|||
logger.warning(f"It may the first time to run Agent {role_id}, the long-term memory is empty")
|
||||
else:
|
||||
logger.warning(
|
||||
f"Agent {role_id} has existed memory storage with {len(messages)} messages " f"and has recovered them."
|
||||
f"Agent {role_id} has existing memory storage with {len(messages)} messages " f"and has recovered them."
|
||||
)
|
||||
self.msg_from_recover = True
|
||||
self.add_batch(messages)
|
||||
self.msg_from_recover = False
|
||||
|
||||
def add(self, message: Message):
|
||||
super(LongTermMemory, self).add(message)
|
||||
super().add(message)
|
||||
for action in self.rc.watch:
|
||||
if message.cause_by == action and not self.msg_from_recover:
|
||||
# currently, only add role's watching messages to its memory_storage
|
||||
|
|
@ -48,7 +55,7 @@ class LongTermMemory(Memory):
|
|||
1. find the short-term memory(stm) news
|
||||
2. furthermore, filter out similar messages based on ltm(long-term memory), get the final news
|
||||
"""
|
||||
stm_news = super(LongTermMemory, self).find_news(observed, k=k) # shot-term memory news
|
||||
stm_news = super().find_news(observed, k=k) # shot-term memory news
|
||||
if not self.memory_storage.is_initialized:
|
||||
# memory_storage hasn't initialized, use default `find_news` to get stm_news
|
||||
return stm_news
|
||||
|
|
@ -62,10 +69,9 @@ class LongTermMemory(Memory):
|
|||
return ltm_news[-k:]
|
||||
|
||||
def delete(self, message: Message):
|
||||
super(LongTermMemory, self).delete(message)
|
||||
super().delete(message)
|
||||
# TODO delete message in memory_storage
|
||||
|
||||
def clear(self):
|
||||
super(LongTermMemory, self).clear()
|
||||
super().clear()
|
||||
self.memory_storage.clean()
|
||||
|
||||
|
|
@ -4,21 +4,53 @@
|
|||
@Time : 2023/5/20 12:15
|
||||
@Author : alexanderwu
|
||||
@File : memory.py
|
||||
@Modified By: mashenquan, 2023-11-1. According to RFC 116: Updated the type of index key.
|
||||
"""
|
||||
from collections import defaultdict
|
||||
from typing import Iterable, Type
|
||||
from pathlib import Path
|
||||
from typing import Iterable, Set
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.common import (
|
||||
any_to_str,
|
||||
any_to_str_set,
|
||||
read_json_file,
|
||||
write_json_file,
|
||||
)
|
||||
|
||||
|
||||
class Memory:
|
||||
class Memory(BaseModel):
|
||||
"""The most basic memory: super-memory"""
|
||||
|
||||
def __init__(self):
|
||||
"""Initialize an empty storage list and an empty index dictionary"""
|
||||
self.storage: list[Message] = []
|
||||
self.index: dict[Type[Action], list[Message]] = defaultdict(list)
|
||||
storage: list[Message] = []
|
||||
index: dict[str, list[Message]] = Field(default_factory=defaultdict(list))
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
index = kwargs.get("index", {})
|
||||
new_index = defaultdict(list)
|
||||
for action_str, value in index.items():
|
||||
new_index[action_str] = [Message(**item_dict) for item_dict in value]
|
||||
kwargs["index"] = new_index
|
||||
super(Memory, self).__init__(**kwargs)
|
||||
self.index = new_index
|
||||
|
||||
def serialize(self, stg_path: Path):
|
||||
"""stg_path = ./storage/team/environment/ or ./storage/team/environment/roles/{role_class}_{role_name}/"""
|
||||
memory_path = stg_path.joinpath("memory.json")
|
||||
storage = self.dict()
|
||||
write_json_file(memory_path, storage)
|
||||
|
||||
@classmethod
|
||||
def deserialize(cls, stg_path: Path) -> "Memory":
|
||||
"""stg_path = ./storage/team/environment/ or ./storage/team/environment/roles/{role_class}_{role_name}/"""
|
||||
memory_path = stg_path.joinpath("memory.json")
|
||||
|
||||
memory_dict = read_json_file(memory_path)
|
||||
memory = Memory(**memory_dict)
|
||||
|
||||
return memory
|
||||
|
||||
def add(self, message: Message):
|
||||
"""Add a new message to storage, while updating the index"""
|
||||
|
|
@ -40,6 +72,16 @@ class Memory:
|
|||
"""Return all messages containing a specified content"""
|
||||
return [message for message in self.storage if content in message.content]
|
||||
|
||||
def delete_newest(self) -> "Message":
|
||||
"""delete the newest message from the storage"""
|
||||
if len(self.storage) > 0:
|
||||
newest_msg = self.storage.pop()
|
||||
if newest_msg.cause_by and newest_msg in self.index[newest_msg.cause_by]:
|
||||
self.index[newest_msg.cause_by].remove(newest_msg)
|
||||
else:
|
||||
newest_msg = None
|
||||
return newest_msg
|
||||
|
||||
def delete(self, message: Message):
|
||||
"""Delete the specified message from storage, while updating the index"""
|
||||
self.storage.remove(message)
|
||||
|
|
@ -73,16 +115,17 @@ class Memory:
|
|||
news.append(i)
|
||||
return news
|
||||
|
||||
def get_by_action(self, action: Type[Action]) -> list[Message]:
|
||||
def get_by_action(self, action) -> list[Message]:
|
||||
"""Return all messages triggered by a specified Action"""
|
||||
return self.index[action]
|
||||
index = any_to_str(action)
|
||||
return self.index[index]
|
||||
|
||||
def get_by_actions(self, actions: Iterable[Type[Action]]) -> list[Message]:
|
||||
def get_by_actions(self, actions: Set) -> list[Message]:
|
||||
"""Return all messages triggered by specified Actions"""
|
||||
rsp = []
|
||||
for action in actions:
|
||||
indices = any_to_str_set(actions)
|
||||
for action in indices:
|
||||
if action not in self.index:
|
||||
continue
|
||||
rsp += self.index[action]
|
||||
return rsp
|
||||
|
||||
|
|
@ -2,16 +2,16 @@
|
|||
# -*- coding: utf-8 -*-
|
||||
# @Desc : the implement of memory storage
|
||||
|
||||
from typing import List
|
||||
from pathlib import Path
|
||||
from typing import List
|
||||
|
||||
from langchain.vectorstores.faiss import FAISS
|
||||
|
||||
from metagpt.const import DATA_PATH, MEM_TTL
|
||||
from metagpt.document_store.faiss_store import FaissStore
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.serialize import serialize_message, deserialize_message
|
||||
from metagpt.document_store.faiss_store import FaissStore
|
||||
from metagpt.utils.serialize import deserialize_message, serialize_message
|
||||
|
||||
|
||||
class MemoryStorage(FaissStore):
|
||||
|
|
@ -34,7 +34,7 @@ class MemoryStorage(FaissStore):
|
|||
|
||||
def recover_memory(self, role_id: str) -> List[Message]:
|
||||
self.role_id = role_id
|
||||
self.role_mem_path = Path(DATA_PATH / f'role_mem/{self.role_id}/')
|
||||
self.role_mem_path = Path(DATA_PATH / f"role_mem/{self.role_id}/")
|
||||
self.role_mem_path.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
self.store = self._load()
|
||||
|
|
@ -51,18 +51,18 @@ class MemoryStorage(FaissStore):
|
|||
|
||||
def _get_index_and_store_fname(self):
|
||||
if not self.role_mem_path:
|
||||
logger.error(f'You should call {self.__class__.__name__}.recover_memory fist when using LongTermMemory')
|
||||
logger.error(f"You should call {self.__class__.__name__}.recover_memory fist when using LongTermMemory")
|
||||
return None, None
|
||||
index_fpath = Path(self.role_mem_path / f'{self.role_id}.index')
|
||||
storage_fpath = Path(self.role_mem_path / f'{self.role_id}.pkl')
|
||||
index_fpath = Path(self.role_mem_path / f"{self.role_id}.index")
|
||||
storage_fpath = Path(self.role_mem_path / f"{self.role_id}.pkl")
|
||||
return index_fpath, storage_fpath
|
||||
|
||||
def persist(self):
|
||||
super(MemoryStorage, self).persist()
|
||||
logger.debug(f'Agent {self.role_id} persist memory into local')
|
||||
super().persist()
|
||||
logger.debug(f"Agent {self.role_id} persist memory into local")
|
||||
|
||||
def add(self, message: Message) -> bool:
|
||||
""" add message into memory storage"""
|
||||
"""add message into memory storage"""
|
||||
docs = [message.content]
|
||||
metadatas = [{"message_ser": serialize_message(message)}]
|
||||
if not self.store:
|
||||
|
|
@ -79,10 +79,7 @@ class MemoryStorage(FaissStore):
|
|||
if not self.store:
|
||||
return []
|
||||
|
||||
resp = self.store.similarity_search_with_score(
|
||||
query=message.content,
|
||||
k=k
|
||||
)
|
||||
resp = self.store.similarity_search_with_score(query=message.content, k=k)
|
||||
# filter the result which score is smaller than the threshold
|
||||
filtered_resp = []
|
||||
for item, score in resp:
|
||||
|
|
@ -104,4 +101,3 @@ class MemoryStorage(FaissStore):
|
|||
|
||||
self.store = None
|
||||
self._initialized = False
|
||||
|
||||
|
|
@ -10,7 +10,7 @@
|
|||
from typing import Optional
|
||||
from abc import ABC
|
||||
from metagpt.llm import LLM # Large language model, similar to GPT
|
||||
n
|
||||
|
||||
class Action(ABC):
|
||||
def __init__(self, name='', context=None, llm: LLM = LLM()):
|
||||
self.name = name
|
||||
|
|
|
|||
|
|
@ -10,7 +10,9 @@
|
|||
|
||||
COMMON_PROMPT = "Now I will provide you with the OCR text recognition results for the invoice."
|
||||
|
||||
EXTRACT_OCR_MAIN_INFO_PROMPT = COMMON_PROMPT + """
|
||||
EXTRACT_OCR_MAIN_INFO_PROMPT = (
|
||||
COMMON_PROMPT
|
||||
+ """
|
||||
Please extract the payee, city, total cost, and invoicing date of the invoice.
|
||||
|
||||
The OCR data of the invoice are as follows:
|
||||
|
|
@ -22,8 +24,11 @@ Mandatory restrictions are returned according to the following requirements:
|
|||
2. The returned JSON dictionary must be returned in {language}
|
||||
3. Mandatory requirement to output in JSON format: {{"收款人":"x","城市":"x","总费用/元":"","开票日期":""}}.
|
||||
"""
|
||||
)
|
||||
|
||||
REPLY_OCR_QUESTION_PROMPT = COMMON_PROMPT + """
|
||||
REPLY_OCR_QUESTION_PROMPT = (
|
||||
COMMON_PROMPT
|
||||
+ """
|
||||
Please answer the question: {query}
|
||||
|
||||
The OCR data of the invoice are as follows:
|
||||
|
|
@ -34,6 +39,6 @@ Mandatory restrictions are returned according to the following requirements:
|
|||
2. Enforce restrictions on not returning OCR data sent to you.
|
||||
3. Return with markdown syntax layout.
|
||||
"""
|
||||
)
|
||||
|
||||
INVOICE_OCR_SUCCESS = "Successfully completed OCR text recognition invoice."
|
||||
|
||||
|
|
|
|||
|
|
@ -54,10 +54,12 @@ Conversation history:
|
|||
{salesperson_name}:
|
||||
"""
|
||||
|
||||
conversation_stages = {'1' : "Introduction: Start the conversation by introducing yourself and your company. Be polite and respectful while keeping the tone of the conversation professional. Your greeting should be welcoming. Always clarify in your greeting the reason why you are contacting the prospect.",
|
||||
'2': "Qualification: Qualify the prospect by confirming if they are the right person to talk to regarding your product/service. Ensure that they have the authority to make purchasing decisions.",
|
||||
'3': "Value proposition: Briefly explain how your product/service can benefit the prospect. Focus on the unique selling points and value proposition of your product/service that sets it apart from competitors.",
|
||||
'4': "Needs analysis: Ask open-ended questions to uncover the prospect's needs and pain points. Listen carefully to their responses and take notes.",
|
||||
'5': "Solution presentation: Based on the prospect's needs, present your product/service as the solution that can address their pain points.",
|
||||
'6': "Objection handling: Address any objections that the prospect may have regarding your product/service. Be prepared to provide evidence or testimonials to support your claims.",
|
||||
'7': "Close: Ask for the sale by proposing a next step. This could be a demo, a trial or a meeting with decision-makers. Ensure to summarize what has been discussed and reiterate the benefits."}
|
||||
conversation_stages = {
|
||||
"1": "Introduction: Start the conversation by introducing yourself and your company. Be polite and respectful while keeping the tone of the conversation professional. Your greeting should be welcoming. Always clarify in your greeting the reason why you are contacting the prospect.",
|
||||
"2": "Qualification: Qualify the prospect by confirming if they are the right person to talk to regarding your product/service. Ensure that they have the authority to make purchasing decisions.",
|
||||
"3": "Value proposition: Briefly explain how your product/service can benefit the prospect. Focus on the unique selling points and value proposition of your product/service that sets it apart from competitors.",
|
||||
"4": "Needs analysis: Ask open-ended questions to uncover the prospect's needs and pain points. Listen carefully to their responses and take notes.",
|
||||
"5": "Solution presentation: Based on the prospect's needs, present your product/service as the solution that can address their pain points.",
|
||||
"6": "Objection handling: Address any objections that the prospect may have regarding your product/service. Be prepared to provide evidence or testimonials to support your claims.",
|
||||
"7": "Close: Ask for the sale by proposing a next step. This could be a demo, a trial or a meeting with decision-makers. Ensure to summarize what has been discussed and reiterate the benefits.",
|
||||
}
|
||||
|
|
|
|||
|
|
@ -12,7 +12,9 @@ You are now a seasoned technical professional in the field of the internet.
|
|||
We need you to write a technical tutorial with the topic "{topic}".
|
||||
"""
|
||||
|
||||
DIRECTORY_PROMPT = COMMON_PROMPT + """
|
||||
DIRECTORY_PROMPT = (
|
||||
COMMON_PROMPT
|
||||
+ """
|
||||
Please provide the specific table of contents for this tutorial, strictly following the following requirements:
|
||||
1. The output must be strictly in the specified language, {language}.
|
||||
2. Answer strictly in the dictionary format like {{"title": "xxx", "directory": [{{"dir 1": ["sub dir 1", "sub dir 2"]}}, {{"dir 2": ["sub dir 3", "sub dir 4"]}}]}}.
|
||||
|
|
@ -20,8 +22,11 @@ Please provide the specific table of contents for this tutorial, strictly follow
|
|||
4. Do not have extra spaces or line breaks.
|
||||
5. Each directory title has practical significance.
|
||||
"""
|
||||
)
|
||||
|
||||
CONTENT_PROMPT = COMMON_PROMPT + """
|
||||
CONTENT_PROMPT = (
|
||||
COMMON_PROMPT
|
||||
+ """
|
||||
Now I will give you the module directory titles for the topic.
|
||||
Please output the detailed principle content of this title in detail.
|
||||
If there are code examples, please provide them according to standard code specifications.
|
||||
|
|
@ -36,4 +41,5 @@ Strictly limit output according to the following requirements:
|
|||
3. The output must be strictly in the specified language, {language}.
|
||||
4. Do not have redundant output, including concluding remarks.
|
||||
5. Strict requirement not to output the topic "{topic}".
|
||||
"""
|
||||
"""
|
||||
)
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ from metagpt.config import CONFIG
|
|||
|
||||
class Claude2:
|
||||
def ask(self, prompt):
|
||||
client = Anthropic(api_key=CONFIG.claude_api_key)
|
||||
client = Anthropic(api_key=CONFIG.anthropic_api_key)
|
||||
|
||||
res = client.completions.create(
|
||||
model="claude-2",
|
||||
|
|
@ -24,7 +24,7 @@ class Claude2:
|
|||
return res.completion
|
||||
|
||||
async def aask(self, prompt):
|
||||
client = Anthropic(api_key=CONFIG.claude_api_key)
|
||||
client = Anthropic(api_key=CONFIG.anthropic_api_key)
|
||||
|
||||
res = client.completions.create(
|
||||
model="claude-2",
|
||||
|
|
@ -32,4 +32,3 @@ class Claude2:
|
|||
max_tokens_to_sample=1000,
|
||||
)
|
||||
return res.completion
|
||||
|
||||
|
|
@ -12,6 +12,7 @@ from dataclasses import dataclass
|
|||
@dataclass
|
||||
class BaseChatbot(ABC):
|
||||
"""Abstract GPT class"""
|
||||
|
||||
mode: str = "API"
|
||||
use_system_prompt: bool = True
|
||||
|
||||
|
|
@ -26,4 +27,3 @@ class BaseChatbot(ABC):
|
|||
@abstractmethod
|
||||
def ask_code(self, msgs: list) -> str:
|
||||
"""Ask GPT multiple questions and get a piece of code"""
|
||||
|
||||
|
|
@ -38,15 +38,19 @@ class BaseGPTAPI(BaseChatbot):
|
|||
rsp = self.completion(message)
|
||||
return self.get_choice_text(rsp)
|
||||
|
||||
async def aask(self, msg: str, system_msgs: Optional[list[str]] = None) -> str:
|
||||
async def aask(self, msg: str, system_msgs: Optional[list[str]] = None, stream=True) -> str:
|
||||
if system_msgs:
|
||||
message = self._system_msgs(system_msgs) + [self._user_msg(msg)] if self.use_system_prompt \
|
||||
message = (
|
||||
self._system_msgs(system_msgs) + [self._user_msg(msg)]
|
||||
if self.use_system_prompt
|
||||
else [self._user_msg(msg)]
|
||||
)
|
||||
else:
|
||||
message = [self._default_system_msg(), self._user_msg(msg)] if self.use_system_prompt \
|
||||
else [self._user_msg(msg)]
|
||||
rsp = await self.acompletion_text(message, stream=True)
|
||||
message = (
|
||||
[self._default_system_msg(), self._user_msg(msg)] if self.use_system_prompt else [self._user_msg(msg)]
|
||||
)
|
||||
logger.debug(message)
|
||||
rsp = await self.acompletion_text(message, stream=stream)
|
||||
# logger.debug(rsp)
|
||||
return rsp
|
||||
|
||||
|
|
|
|||
25
metagpt/provider/fireworks_api.py
Normal file
25
metagpt/provider/fireworks_api.py
Normal file
|
|
@ -0,0 +1,25 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : fireworks.ai's api
|
||||
|
||||
import openai
|
||||
|
||||
from metagpt.config import CONFIG, LLMProviderEnum
|
||||
from metagpt.provider.llm_provider_registry import register_provider
|
||||
from metagpt.provider.openai_api import CostManager, OpenAIGPTAPI, RateLimiter
|
||||
|
||||
|
||||
@register_provider(LLMProviderEnum.FIREWORKS)
|
||||
class FireWorksGPTAPI(OpenAIGPTAPI):
|
||||
def __init__(self):
|
||||
self.__init_fireworks(CONFIG)
|
||||
self.llm = openai
|
||||
self.model = CONFIG.fireworks_api_model
|
||||
self.auto_max_tokens = False
|
||||
self._cost_manager = CostManager()
|
||||
RateLimiter.__init__(self, rpm=self.rpm)
|
||||
|
||||
def __init_fireworks(self, config: "Config"):
|
||||
openai.api_key = config.fireworks_api_key
|
||||
openai.api_base = config.fireworks_api_base
|
||||
self.rpm = int(config.get("RPM", 10))
|
||||
|
|
@ -1,11 +1,13 @@
|
|||
'''
|
||||
"""
|
||||
Filename: MetaGPT/metagpt/provider/human_provider.py
|
||||
Created Date: Wednesday, November 8th 2023, 11:55:46 pm
|
||||
Author: garylin2099
|
||||
'''
|
||||
"""
|
||||
from typing import Optional
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
|
||||
from metagpt.logs import logger
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
|
||||
|
||||
class HumanProvider(BaseGPTAPI):
|
||||
"""Humans provide themselves as a 'model', which actually takes in human input as its response.
|
||||
|
|
|
|||
34
metagpt/provider/llm_provider_registry.py
Normal file
34
metagpt/provider/llm_provider_registry.py
Normal file
|
|
@ -0,0 +1,34 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/12/19 17:26
|
||||
@Author : alexanderwu
|
||||
@File : llm_provider_registry.py
|
||||
"""
|
||||
from metagpt.config import LLMProviderEnum
|
||||
|
||||
|
||||
class LLMProviderRegistry:
|
||||
def __init__(self):
|
||||
self.providers = {}
|
||||
|
||||
def register(self, key, provider_cls):
|
||||
self.providers[key] = provider_cls
|
||||
|
||||
def get_provider(self, enum: LLMProviderEnum):
|
||||
"""get provider instance according to the enum"""
|
||||
return self.providers[enum]()
|
||||
|
||||
|
||||
# Registry instance
|
||||
LLM_REGISTRY = LLMProviderRegistry()
|
||||
|
||||
|
||||
def register_provider(key):
|
||||
"""register provider to registry"""
|
||||
|
||||
def decorator(cls):
|
||||
LLM_REGISTRY.register(key, cls)
|
||||
return cls
|
||||
|
||||
return decorator
|
||||
48
metagpt/provider/open_llm_api.py
Normal file
48
metagpt/provider/open_llm_api.py
Normal file
|
|
@ -0,0 +1,48 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : self-host open llm model with openai-compatible interface
|
||||
|
||||
import openai
|
||||
|
||||
from metagpt.config import CONFIG, LLMProviderEnum
|
||||
from metagpt.logs import logger
|
||||
from metagpt.provider.llm_provider_registry import register_provider
|
||||
from metagpt.provider.openai_api import CostManager, OpenAIGPTAPI, RateLimiter
|
||||
|
||||
|
||||
class OpenLLMCostManager(CostManager):
|
||||
"""open llm model is self-host, it's free and without cost"""
|
||||
|
||||
def update_cost(self, prompt_tokens, completion_tokens, model):
|
||||
"""
|
||||
Update the total cost, prompt tokens, and completion tokens.
|
||||
|
||||
Args:
|
||||
prompt_tokens (int): The number of tokens used in the prompt.
|
||||
completion_tokens (int): The number of tokens used in the completion.
|
||||
model (str): The model used for the API call.
|
||||
"""
|
||||
self.total_prompt_tokens += prompt_tokens
|
||||
self.total_completion_tokens += completion_tokens
|
||||
|
||||
logger.info(
|
||||
f"Max budget: ${CONFIG.max_budget:.3f} | "
|
||||
f"prompt_tokens: {prompt_tokens}, completion_tokens: {completion_tokens}"
|
||||
)
|
||||
CONFIG.total_cost = self.total_cost
|
||||
|
||||
|
||||
@register_provider(LLMProviderEnum.OPEN_LLM)
|
||||
class OpenLLMGPTAPI(OpenAIGPTAPI):
|
||||
def __init__(self):
|
||||
self.__init_openllm(CONFIG)
|
||||
self.llm = openai
|
||||
self.model = CONFIG.open_llm_api_model
|
||||
self.auto_max_tokens = False
|
||||
self._cost_manager = OpenLLMCostManager()
|
||||
RateLimiter.__init__(self, rpm=self.rpm)
|
||||
|
||||
def __init_openllm(self, config: "Config"):
|
||||
openai.api_key = "sk-xx" # self-host api doesn't need api-key, use the default value
|
||||
openai.api_base = config.open_llm_api_base
|
||||
self.rpm = int(config.get("RPM", 10))
|
||||
|
|
@ -25,13 +25,15 @@ from tenacity import (
|
|||
retry,
|
||||
retry_if_exception_type,
|
||||
stop_after_attempt,
|
||||
wait_fixed,
|
||||
wait_random_exponential,
|
||||
)
|
||||
|
||||
from metagpt.config import CONFIG, Config
|
||||
|
||||
from metagpt.config import CONFIG, Config, LLMProviderEnum
|
||||
from metagpt.logs import logger
|
||||
from metagpt.provider.base_gpt_api import BaseGPTAPI
|
||||
from metagpt.provider.constant import GENERAL_FUNCTION_SCHEMA, GENERAL_TOOL_CHOICE
|
||||
from metagpt.provider.llm_provider_registry import register_provider
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.singleton import Singleton
|
||||
from metagpt.utils.token_counter import (
|
||||
|
|
@ -147,6 +149,7 @@ See FAQ 5.8
|
|||
raise retry_state.outcome.exception()
|
||||
|
||||
|
||||
@register_provider(LLMProviderEnum.OPENAI)
|
||||
class OpenAIGPTAPI(BaseGPTAPI, RateLimiter):
|
||||
"""
|
||||
Check https://platform.openai.com/examples for examples
|
||||
|
|
@ -259,8 +262,8 @@ class OpenAIGPTAPI(BaseGPTAPI, RateLimiter):
|
|||
return await self._achat_completion(messages)
|
||||
|
||||
@retry(
|
||||
stop=stop_after_attempt(3),
|
||||
wait=wait_fixed(1),
|
||||
wait=wait_random_exponential(min=1, max=60),
|
||||
stop=stop_after_attempt(6),
|
||||
after=after_log(logger, logger.level("WARNING").name),
|
||||
retry=retry_if_exception_type(APIConnectionError),
|
||||
retry_error_callback=log_and_reraise,
|
||||
|
|
@ -366,16 +369,17 @@ class OpenAIGPTAPI(BaseGPTAPI, RateLimiter):
|
|||
|
||||
def _calc_usage(self, messages: list[dict], rsp: str) -> CompletionUsage:
|
||||
usage = CompletionUsage(prompt_tokens=0, completion_tokens=0, total_tokens=0)
|
||||
if CONFIG.calc_usage:
|
||||
try:
|
||||
usage.prompt_tokens = count_message_tokens(messages, self.model)
|
||||
usage.completion_tokens = count_string_tokens(rsp, self.model)
|
||||
return usage
|
||||
except Exception as e:
|
||||
logger.error(f"usage calculation failed!: {e}")
|
||||
else:
|
||||
if not CONFIG.calc_usage:
|
||||
return usage
|
||||
|
||||
try:
|
||||
usage.prompt_tokens = count_message_tokens(messages, self.model)
|
||||
usage.completion_tokens = count_string_tokens(rsp, self.model)
|
||||
except Exception as e:
|
||||
logger.error(f"usage calculation failed!: {e}")
|
||||
|
||||
return usage
|
||||
|
||||
async def acompletion_batch(self, batch: list[list[dict]]) -> list[ChatCompletion]:
|
||||
"""Return full JSON"""
|
||||
split_batches = self.split_batches(batch)
|
||||
|
|
@ -403,7 +407,7 @@ class OpenAIGPTAPI(BaseGPTAPI, RateLimiter):
|
|||
return results
|
||||
|
||||
def _update_costs(self, usage: CompletionUsage):
|
||||
if CONFIG.calc_usage:
|
||||
if CONFIG.calc_usage and usage:
|
||||
try:
|
||||
self._cost_manager.update_cost(usage.prompt_tokens, usage.completion_tokens, self.model)
|
||||
except Exception as e:
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show more
Loading…
Add table
Add a link
Reference in a new issue