 +[](https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/geekan/MetaGPT)
-Note: If you click this link you will open the main repo and not your local cloned repo, you can use this link and replace with your username and cloned repo name:
-https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/geekan/MetaGPT
+Note: Clicking the link above opens the main repository. To open your local cloned repository, replace the URL with your username and cloned repository's name: `https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/
+[](https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/geekan/MetaGPT)
-Note: If you click this link you will open the main repo and not your local cloned repo, you can use this link and replace with your username and cloned repo name:
-https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/geekan/MetaGPT
+Note: Clicking the link above opens the main repository. To open your local cloned repository, replace the URL with your username and cloned repository's name: `https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/@@ -32,7 +33,8 @@ # MetaGPT: The Multi-Agent Framework
Software Company Multi-Role Schematic (Gradually Implementing)
- +## News +- Dec 15: v0.5.0 is released! We introduce **incremental development**, facilitating agents to build up larger projects on top of their previous efforts or exisiting human codebase. We also launch a whole collection of important features, including multilingual support (experimental), multiple programming languages support (experimental), incremental development (experimental), CLI support, pip support, enhanced code review, documentation mechanism, and optimized messaging mechanism! ## Install @@ -50,9 +52,9 @@ # Step 2: Clone the repository to your local machine for latest version, and ins cd MetaGPT pip3 install -e. # or pip3 install metagpt # for stable version -# Step 3: run the startup.py +# Step 3: run metagpt cli # setup your OPENAI_API_KEY in key.yaml copy from config.yaml -python3 startup.py "Write a cli snake game" +metagpt "Write a cli snake game" # Step 4 [Optional]: If you want to save the artifacts like diagrams such as quadrant chart, system designs, sequence flow in the workspace, you can execute the step before Step 3. By default, the framework is compatible, and the entire process can be run completely without executing this step. # If executing, ensure that NPM is installed on your system. Then install mermaid-js. (If you don't have npm in your computer, please go to the Node.js official website to install Node.js https://nodejs.org/ and then you will have npm tool in your computer.) @@ -60,7 +62,7 @@ # If executing, ensure that NPM is installed on your system. Then install mermai sudo npm install -g @mermaid-js/mermaid-cli ``` -detail installation please refer to [cli_install](https://docs.deepwisdom.ai/guide/get_started/installation.html#install-stable-version) +detail installation please refer to [cli_install](https://docs.deepwisdom.ai/main/en/guide/get_started/installation.html#install-stable-version) ### Docker installation > Note: In the Windows, you need to replace "/opt/metagpt" with a directory that Docker has permission to create, such as "D:\Users\x\metagpt" @@ -78,10 +80,10 @@ # Step 2: Run metagpt demo with container -v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \ -v /opt/metagpt/workspace:/app/metagpt/workspace \ metagpt/metagpt:latest \ - python startup.py "Write a cli snake game" + metagpt "Write a cli snake game" ``` -detail installation please refer to [docker_install](https://docs.deepwisdom.ai/guide/get_started/installation.html#install-with-docker) +detail installation please refer to [docker_install](https://docs.deepwisdom.ai/main/en/guide/get_started/installation.html#install-with-docker) ### QuickStart & Demo Video - Try it on [MetaGPT Huggingface Space](https://huggingface.co/spaces/deepwisdom/MetaGPT) @@ -92,19 +94,19 @@ ### QuickStart & Demo Video ## Tutorial -- 🗒 [Online Document](https://docs.deepwisdom.ai/) -- 💻 [Usage](https://docs.deepwisdom.ai/guide/get_started/quickstart.html) -- 🔎 [What can MetaGPT do?](https://docs.deepwisdom.ai/guide/get_started/introduction.html) +- 🗒 [Online Document](https://docs.deepwisdom.ai/main/en/) +- 💻 [Usage](https://docs.deepwisdom.ai/main/en/guide/get_started/quickstart.html) +- 🔎 [What can MetaGPT do?](https://docs.deepwisdom.ai/main/en/guide/get_started/introduction.html) - 🛠 How to build your own agents? - - [MetaGPT Usage & Development Guide | Agent 101](https://docs.deepwisdom.ai/guide/tutorials/agent_101.html) - - [MetaGPT Usage & Development Guide | MultiAgent 101](https://docs.deepwisdom.ai/guide/tutorials/multi_agent_101.html) + - [MetaGPT Usage & Development Guide | Agent 101](https://docs.deepwisdom.ai/main/en/guide/tutorials/agent_101.html) + - [MetaGPT Usage & Development Guide | MultiAgent 101](https://docs.deepwisdom.ai/main/en/guide/tutorials/multi_agent_101.html) - 🧑💻 Contribution - [Develop Roadmap](docs/ROADMAP.md) - 🔖 Use Cases - - [Debate](https://docs.deepwisdom.ai/guide/use_cases/multi_agent/debate.html) - - [Researcher](https://docs.deepwisdom.ai/guide/use_cases/agent/researcher.html) - - [Recepit Assistant](https://docs.deepwisdom.ai/guide/use_cases/agent/receipt_assistant.html) -- ❓ [FAQs](https://docs.deepwisdom.ai/guide/faq.html) + - [Debate](https://docs.deepwisdom.ai/main/en/guide/use_cases/multi_agent/debate.html) + - [Researcher](https://docs.deepwisdom.ai/main/en/guide/use_cases/agent/researcher.html) + - [Recepit Assistant](https://docs.deepwisdom.ai/main/en/guide/use_cases/agent/receipt_assistant.html) +- ❓ [FAQs](https://docs.deepwisdom.ai/main/en/guide/faq.html) ## Support @@ -117,7 +119,7 @@ ### Contact Information If you have any questions or feedback about this project, please feel free to contact us. We highly appreciate your suggestions! -- **Email:** alexanderwu@fuzhi.ai +- **Email:** alexanderwu@deepwisdom.ai - **GitHub Issues:** For more technical inquiries, you can also create a new issue in our [GitHub repository](https://github.com/geekan/metagpt/issues). We will respond to all questions within 2-3 business days. diff --git a/config/config.yaml b/config/config.yaml index 2846467ed..1f5b85c21 100644 --- a/config/config.yaml +++ b/config/config.yaml @@ -1,15 +1,18 @@ # DO NOT MODIFY THIS FILE, create a new key.yaml, define OPENAI_API_KEY. # The configuration of key.yaml has a higher priority and will not enter git +#### Project Path Setting +# WORKSPACE_PATH: "Path for placing output files" + #### if OpenAI ## The official OPENAI_BASE_URL is https://api.openai.com/v1 ## If the official OPENAI_BASE_URL is not available, we recommend using the [openai-forward](https://github.com/beidongjiedeguang/openai-forward). ## Or, you can configure OPENAI_PROXY to access official OPENAI_BASE_URL. OPENAI_BASE_URL: "https://api.openai.com/v1" #OPENAI_PROXY: "http://127.0.0.1:8118" -#OPENAI_API_KEY: "YOUR_API_KEY" # set the value to sk-xxx if you host the openai interface for open llm model -OPENAI_API_MODEL: "gpt-4" -MAX_TOKENS: 1500 +#OPENAI_API_KEY: "YOUR_API_KEY" # set the value to sk-xxx if you host the openai interface for open llm model +OPENAI_API_MODEL: "gpt-4-1106-preview" +MAX_TOKENS: 4096 RPM: 10 #### if Spark @@ -20,7 +23,7 @@ RPM: 10 #SPARK_URL : "ws://spark-api.xf-yun.com/v2.1/chat" #### if Anthropic -#Anthropic_API_KEY: "YOUR_API_KEY" +#ANTHROPIC_API_KEY: "YOUR_API_KEY" #### if AZURE, check https://github.com/openai/openai-cookbook/blob/main/examples/azure/chat.ipynb #OPENAI_API_TYPE: "azure" @@ -32,6 +35,15 @@ RPM: 10 #### if zhipuai from `https://open.bigmodel.cn`. You can set here or export API_KEY="YOUR_API_KEY" # ZHIPUAI_API_KEY: "YOUR_API_KEY" +#### if use self-host open llm model with openai-compatible interface +#OPEN_LLM_API_BASE: "http://127.0.0.1:8000/v1" +#OPEN_LLM_API_MODEL: "llama2-13b" +# +##### if use Fireworks api +#FIREWORKS_API_KEY: "YOUR_API_KEY" +#FIREWORKS_API_BASE: "https://api.fireworks.ai/inference/v1" +#FIREWORKS_API_MODEL: "YOUR_LLM_MODEL" # example, accounts/fireworks/models/llama-v2-13b-chat + #### for Search ## Supported values: serpapi/google/serper/ddg @@ -66,8 +78,8 @@ RPM: 10 #### for Stable Diffusion ## Use SD service, based on https://github.com/AUTOMATIC1111/stable-diffusion-webui -SD_URL: "YOUR_SD_URL" -SD_T2I_API: "/sdapi/v1/txt2img" +#SD_URL: "YOUR_SD_URL" +#SD_T2I_API: "/sdapi/v1/txt2img" #### for Execution #LONG_TERM_MEMORY: false @@ -82,8 +94,8 @@ SD_T2I_API: "/sdapi/v1/txt2img" # CALC_USAGE: false ### for Research -MODEL_FOR_RESEARCHER_SUMMARY: gpt-3.5-turbo -MODEL_FOR_RESEARCHER_REPORT: gpt-3.5-turbo-16k +# MODEL_FOR_RESEARCHER_SUMMARY: gpt-3.5-turbo +# MODEL_FOR_RESEARCHER_REPORT: gpt-3.5-turbo-16k ### choose the engine for mermaid conversion, # default is nodejs, you can change it to playwright,pyppeteer or ink @@ -92,4 +104,9 @@ MODEL_FOR_RESEARCHER_REPORT: gpt-3.5-turbo-16k ### browser path for pyppeteer engine, support Chrome, Chromium,MS Edge #PYPPETEER_EXECUTABLE_PATH: "/usr/bin/google-chrome-stable" -PROMPT_FORMAT: json #json or markdown \ No newline at end of file +### for repair non-openai LLM's output when parse json-text if PROMPT_FORMAT=json +### due to non-openai LLM's output will not always follow the instruction, so here activate a post-process +### repair operation on the content extracted from LLM's raw output. Warning, it improves the result but not fix all cases. +# REPAIR_LLM_OUTPUT: false + +# PROMPT_FORMAT: json #json or markdown \ No newline at end of file diff --git a/docs/.pylintrc b/docs/.pylintrc new file mode 100644 index 000000000..9e8488bc7 --- /dev/null +++ b/docs/.pylintrc @@ -0,0 +1,639 @@ +[MAIN] + +# Analyse import fallback blocks. This can be used to support both Python 2 and +# 3 compatible code, which means that the block might have code that exists +# only in one or another interpreter, leading to false positives when analysed. +analyse-fallback-blocks=no + +# Clear in-memory caches upon conclusion of linting. Useful if running pylint +# in a server-like mode. +clear-cache-post-run=no + +# Load and enable all available extensions. Use --list-extensions to see a list +# all available extensions. +#enable-all-extensions= + +# In error mode, messages with a category besides ERROR or FATAL are +# suppressed, and no reports are done by default. Error mode is compatible with +# disabling specific errors. +#errors-only= + +# Always return a 0 (non-error) status code, even if lint errors are found. +# This is primarily useful in continuous integration scripts. +#exit-zero= + +# A comma-separated list of package or module names from where C extensions may +# be loaded. Extensions are loading into the active Python interpreter and may +# run arbitrary code. +extension-pkg-allow-list= + +# A comma-separated list of package or module names from where C extensions may +# be loaded. Extensions are loading into the active Python interpreter and may +# run arbitrary code. (This is an alternative name to extension-pkg-allow-list +# for backward compatibility.) +extension-pkg-whitelist=pydantic + +# Return non-zero exit code if any of these messages/categories are detected, +# even if score is above --fail-under value. Syntax same as enable. Messages +# specified are enabled, while categories only check already-enabled messages. +fail-on= + +# Specify a score threshold under which the program will exit with error. +fail-under=10 + +# Interpret the stdin as a python script, whose filename needs to be passed as +# the module_or_package argument. +#from-stdin= + +# Files or directories to be skipped. They should be base names, not paths. +ignore=CVS + +# Add files or directories matching the regular expressions patterns to the +# ignore-list. The regex matches against paths and can be in Posix or Windows +# format. Because '\\' represents the directory delimiter on Windows systems, +# it can't be used as an escape character. +ignore-paths= + +# Files or directories matching the regular expression patterns are skipped. +# The regex matches against base names, not paths. The default value ignores +# Emacs file locks +#ignore-patterns=^\.# +ignore-patterns=(.)*_test\.py,test_(.)*\.py + + +# List of module names for which member attributes should not be checked +# (useful for modules/projects where namespaces are manipulated during runtime +# and thus existing member attributes cannot be deduced by static analysis). It +# supports qualified module names, as well as Unix pattern matching. +ignored-modules= + +# Python code to execute, usually for sys.path manipulation such as +# pygtk.require(). +#init-hook= + +# Use multiple processes to speed up Pylint. Specifying 0 will auto-detect the +# number of processors available to use, and will cap the count on Windows to +# avoid hangs. +jobs=1 + +# Control the amount of potential inferred values when inferring a single +# object. This can help the performance when dealing with large functions or +# complex, nested conditions. +limit-inference-results=120 + +# List of plugins (as comma separated values of python module names) to load, +# usually to register additional checkers. +load-plugins= + +# Pickle collected data for later comparisons. +persistent=yes + +# Minimum Python version to use for version dependent checks. Will default to +# the version used to run pylint. +py-version=3.9 + +# Discover python modules and packages in the file system subtree. +recursive=no + +# Add paths to the list of the source roots. Supports globbing patterns. The +# source root is an absolute path or a path relative to the current working +# directory used to determine a package namespace for modules located under the +# source root. +source-roots= + +# When enabled, pylint would attempt to guess common misconfiguration and emit +# user-friendly hints instead of false-positive error messages. +suggestion-mode=yes + +# Allow loading of arbitrary C extensions. Extensions are imported into the +# active Python interpreter and may run arbitrary code. +unsafe-load-any-extension=no + +# In verbose mode, extra non-checker-related info will be displayed. +#verbose= + + +[BASIC] + +# Naming style matching correct argument names. +argument-naming-style=snake_case + +# Regular expression matching correct argument names. Overrides argument- +# naming-style. If left empty, argument names will be checked with the set +# naming style. +#argument-rgx= + +# Naming style matching correct attribute names. +attr-naming-style=snake_case + +# Regular expression matching correct attribute names. Overrides attr-naming- +# style. If left empty, attribute names will be checked with the set naming +# style. +#attr-rgx= + +# Bad variable names which should always be refused, separated by a comma. +bad-names=foo, + bar, + baz, + toto, + tutu, + tata + +# Bad variable names regexes, separated by a comma. If names match any regex, +# they will always be refused +bad-names-rgxs= + +# Naming style matching correct class attribute names. +class-attribute-naming-style=any + +# Regular expression matching correct class attribute names. Overrides class- +# attribute-naming-style. If left empty, class attribute names will be checked +# with the set naming style. +#class-attribute-rgx= + +# Naming style matching correct class constant names. +class-const-naming-style=UPPER_CASE + +# Regular expression matching correct class constant names. Overrides class- +# const-naming-style. If left empty, class constant names will be checked with +# the set naming style. +#class-const-rgx= + +# Naming style matching correct class names. +class-naming-style=PascalCase + +# Regular expression matching correct class names. Overrides class-naming- +# style. If left empty, class names will be checked with the set naming style. +#class-rgx= + +# Naming style matching correct constant names. +const-naming-style=UPPER_CASE + +# Regular expression matching correct constant names. Overrides const-naming- +# style. If left empty, constant names will be checked with the set naming +# style. +#const-rgx= + +# Minimum line length for functions/classes that require docstrings, shorter +# ones are exempt. +docstring-min-length=-1 + +# Naming style matching correct function names. +function-naming-style=snake_case + +# Regular expression matching correct function names. Overrides function- +# naming-style. If left empty, function names will be checked with the set +# naming style. +#function-rgx= + +# Good variable names which should always be accepted, separated by a comma. +good-names=i, + j, + k, + v, + e, + d, + m, + df, + ex, + Run, + _ + +# Good variable names regexes, separated by a comma. If names match any regex, +# they will always be accepted +good-names-rgxs= + +# Include a hint for the correct naming format with invalid-name. +include-naming-hint=no + +# Naming style matching correct inline iteration names. +inlinevar-naming-style=any + +# Regular expression matching correct inline iteration names. Overrides +# inlinevar-naming-style. If left empty, inline iteration names will be checked +# with the set naming style. +#inlinevar-rgx= + +# Naming style matching correct method names. +method-naming-style=snake_case + +# Regular expression matching correct method names. Overrides method-naming- +# style. If left empty, method names will be checked with the set naming style. +#method-rgx= + +# Naming style matching correct module names. +module-naming-style=snake_case + +# Regular expression matching correct module names. Overrides module-naming- +# style. If left empty, module names will be checked with the set naming style. +#module-rgx= + +# Colon-delimited sets of names that determine each other's naming style when +# the name regexes allow several styles. +name-group= + +# Regular expression which should only match function or class names that do +# not require a docstring. +no-docstring-rgx=^_ + +# List of decorators that produce properties, such as abc.abstractproperty. Add +# to this list to register other decorators that produce valid properties. +# These decorators are taken in consideration only for invalid-name. +property-classes=abc.abstractproperty + +# Regular expression matching correct type alias names. If left empty, type +# alias names will be checked with the set naming style. +#typealias-rgx= + +# Regular expression matching correct type variable names. If left empty, type +# variable names will be checked with the set naming style. +#typevar-rgx= + +# Naming style matching correct variable names. +variable-naming-style=snake_case + +# Regular expression matching correct variable names. Overrides variable- +# naming-style. If left empty, variable names will be checked with the set +# naming style. +#variable-rgx= + + +[CLASSES] + +# Warn about protected attribute access inside special methods +check-protected-access-in-special-methods=no + +# List of method names used to declare (i.e. assign) instance attributes. +defining-attr-methods=__init__, + __new__, + setUp, + __post_init__ + +# List of member names, which should be excluded from the protected access +# warning. +exclude-protected=_asdict,_fields,_replace,_source,_make,os._exit + +# List of valid names for the first argument in a class method. +valid-classmethod-first-arg=cls + +# List of valid names for the first argument in a metaclass class method. +valid-metaclass-classmethod-first-arg=mcs + + +[DESIGN] + +# List of regular expressions of class ancestor names to ignore when counting +# public methods (see R0903) +exclude-too-few-public-methods= + +# List of qualified class names to ignore when counting class parents (see +# R0901) +ignored-parents= + +# Maximum number of arguments for function / method. +max-args=5 + +# Maximum number of attributes for a class (see R0902). +max-attributes=7 + +# Maximum number of boolean expressions in an if statement (see R0916). +max-bool-expr=5 + +# Maximum number of branch for function / method body. +max-branches=12 + +# Maximum number of locals for function / method body. +max-locals=15 + +# Maximum number of parents for a class (see R0901). +max-parents=7 + +# Maximum number of public methods for a class (see R0904). +max-public-methods=20 + +# Maximum number of return / yield for function / method body. +max-returns=6 + +# Maximum number of statements in function / method body. +max-statements=50 + +# Minimum number of public methods for a class (see R0903). +min-public-methods=2 + + +[EXCEPTIONS] + +# Exceptions that will emit a warning when caught. +overgeneral-exceptions=builtins.BaseException,builtins.Exception + + +[FORMAT] + +# Expected format of line ending, e.g. empty (any line ending), LF or CRLF. +expected-line-ending-format= + +# Regexp for a line that is allowed to be longer than the limit. +ignore-long-lines=^\s*(# )??$ + +# Number of spaces of indent required inside a hanging or continued line. +indent-after-paren=4 + +# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1 +# tab). +indent-string=' ' + +# Maximum number of characters on a single line. +max-line-length=120 + +# Maximum number of lines in a module. +max-module-lines=1000 + +# Allow the body of a class to be on the same line as the declaration if body +# contains single statement. +single-line-class-stmt=no + +# Allow the body of an if to be on the same line as the test if there is no +# else. +single-line-if-stmt=no + + +[IMPORTS] + +# List of modules that can be imported at any level, not just the top level +# one. +allow-any-import-level= + +# Allow explicit reexports by alias from a package __init__. +allow-reexport-from-package=no + +# Allow wildcard imports from modules that define __all__. +allow-wildcard-with-all=no + +# Deprecated modules which should not be used, separated by a comma. +deprecated-modules= + +# Output a graph (.gv or any supported image format) of external dependencies +# to the given file (report RP0402 must not be disabled). +ext-import-graph= + +# Output a graph (.gv or any supported image format) of all (i.e. internal and +# external) dependencies to the given file (report RP0402 must not be +# disabled). +import-graph= + +# Output a graph (.gv or any supported image format) of internal dependencies +# to the given file (report RP0402 must not be disabled). +int-import-graph= + +# Force import order to recognize a module as part of the standard +# compatibility libraries. +known-standard-library= + +# Force import order to recognize a module as part of a third party library. +known-third-party=enchant + +# Couples of modules and preferred modules, separated by a comma. +preferred-modules= + + +[LOGGING] + +# The type of string formatting that logging methods do. `old` means using % +# formatting, `new` is for `{}` formatting. +logging-format-style=old + +# Logging modules to check that the string format arguments are in logging +# function parameter format. +logging-modules=logging + + +[MESSAGES CONTROL] + +# Only show warnings with the listed confidence levels. Leave empty to show +# all. Valid levels: HIGH, CONTROL_FLOW, INFERENCE, INFERENCE_FAILURE, +# UNDEFINED. +confidence=HIGH, + CONTROL_FLOW, + INFERENCE, + INFERENCE_FAILURE, + UNDEFINED + +# Disable the message, report, category or checker with the given id(s). You +# can either give multiple identifiers separated by comma (,) or put this +# option multiple times (only on the command line, not in the configuration +# file where it should appear only once). You can also use "--disable=all" to +# disable everything first and then re-enable specific checks. For example, if +# you want to run only the similarities checker, you can use "--disable=all +# --enable=similarities". If you want to run only the classes checker, but have +# no Warning level messages displayed, use "--disable=all --enable=classes +# --disable=W". +disable=raw-checker-failed, + bad-inline-option, + locally-disabled, + file-ignored, + suppressed-message, + useless-suppression, + deprecated-pragma, + use-symbolic-message-instead, + expression-not-assigned, + pointless-statement + +# Enable the message, report, category or checker with the given id(s). You can +# either give multiple identifier separated by comma (,) or put this option +# multiple time (only on the command line, not in the configuration file where +# it should appear only once). See also the "--disable" option for examples. +enable=c-extension-no-member + + +[METHOD_ARGS] + +# List of qualified names (i.e., library.method) which require a timeout +# parameter e.g. 'requests.api.get,requests.api.post' +timeout-methods=requests.api.delete,requests.api.get,requests.api.head,requests.api.options,requests.api.patch,requests.api.post,requests.api.put,requests.api.request + + +[MISCELLANEOUS] + +# List of note tags to take in consideration, separated by a comma. +notes=FIXME, + XXX, + TODO + +# Regular expression of note tags to take in consideration. +notes-rgx= + + +[REFACTORING] + +# Maximum number of nested blocks for function / method body +max-nested-blocks=5 + +# Complete name of functions that never returns. When checking for +# inconsistent-return-statements if a never returning function is called then +# it will be considered as an explicit return statement and no message will be +# printed. +never-returning-functions=sys.exit,argparse.parse_error + + +[REPORTS] + +# Python expression which should return a score less than or equal to 10. You +# have access to the variables 'fatal', 'error', 'warning', 'refactor', +# 'convention', and 'info' which contain the number of messages in each +# category, as well as 'statement' which is the total number of statements +# analyzed. This score is used by the global evaluation report (RP0004). +evaluation=max(0, 0 if fatal else 10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10)) + +# Template used to display messages. This is a python new-style format string +# used to format the message information. See doc for all details. +msg-template= + +# Set the output format. Available formats are text, parseable, colorized, json +# and msvs (visual studio). You can also give a reporter class, e.g. +# mypackage.mymodule.MyReporterClass. +#output-format= + +# Tells whether to display a full report or only the messages. +reports=no + +# Activate the evaluation score. +score=yes + + +[SIMILARITIES] + +# Comments are removed from the similarity computation +ignore-comments=yes + +# Docstrings are removed from the similarity computation +ignore-docstrings=yes + +# Imports are removed from the similarity computation +ignore-imports=yes + +# Signatures are removed from the similarity computation +ignore-signatures=yes + +# Minimum lines number of a similarity. +min-similarity-lines=4 + + +[SPELLING] + +# Limits count of emitted suggestions for spelling mistakes. +max-spelling-suggestions=4 + +# Spelling dictionary name. No available dictionaries : You need to install +# both the python package and the system dependency for enchant to work.. +spelling-dict= + +# List of comma separated words that should be considered directives if they +# appear at the beginning of a comment and should not be checked. +spelling-ignore-comment-directives=fmt: on,fmt: off,noqa:,noqa,nosec,isort:skip,mypy: + +# List of comma separated words that should not be checked. +spelling-ignore-words= + +# A path to a file that contains the private dictionary; one word per line. +spelling-private-dict-file= + +# Tells whether to store unknown words to the private dictionary (see the +# --spelling-private-dict-file option) instead of raising a message. +spelling-store-unknown-words=no + + +[STRING] + +# This flag controls whether inconsistent-quotes generates a warning when the +# character used as a quote delimiter is used inconsistently within a module. +check-quote-consistency=no + +# This flag controls whether the implicit-str-concat should generate a warning +# on implicit string concatenation in sequences defined over several lines. +check-str-concat-over-line-jumps=no + + +[TYPECHECK] + +# List of decorators that produce context managers, such as +# contextlib.contextmanager. Add to this list to register other decorators that +# produce valid context managers. +contextmanager-decorators=contextlib.contextmanager + +# List of members which are set dynamically and missed by pylint inference +# system, and so shouldn't trigger E1101 when accessed. Python regular +# expressions are accepted. +generated-members= + +# Tells whether to warn about missing members when the owner of the attribute +# is inferred to be None. +ignore-none=yes + +# This flag controls whether pylint should warn about no-member and similar +# checks whenever an opaque object is returned when inferring. The inference +# can return multiple potential results while evaluating a Python object, but +# some branches might not be evaluated, which results in partial inference. In +# that case, it might be useful to still emit no-member and other checks for +# the rest of the inferred objects. +ignore-on-opaque-inference=yes + +# List of symbolic message names to ignore for Mixin members. +ignored-checks-for-mixins=no-member, + not-async-context-manager, + not-context-manager, + attribute-defined-outside-init + +# List of class names for which member attributes should not be checked (useful +# for classes with dynamically set attributes). This supports the use of +# qualified names. +ignored-classes=optparse.Values,thread._local,_thread._local,argparse.Namespace + +# Show a hint with possible names when a member name was not found. The aspect +# of finding the hint is based on edit distance. +missing-member-hint=yes + +# The minimum edit distance a name should have in order to be considered a +# similar match for a missing member name. +missing-member-hint-distance=1 + +# The total number of similar names that should be taken in consideration when +# showing a hint for a missing member. +missing-member-max-choices=1 + +# Regex pattern to define which classes are considered mixins. +mixin-class-rgx=.*[Mm]ixin + +# List of decorators that change the signature of a decorated function. +signature-mutators= + + +[VARIABLES] + +# List of additional names supposed to be defined in builtins. Remember that +# you should avoid defining new builtins when possible. +additional-builtins= + +# Tells whether unused global variables should be treated as a violation. +allow-global-unused-variables=yes + +# List of names allowed to shadow builtins +allowed-redefined-builtins= + +# List of strings which can identify a callback function by name. A callback +# name must start or end with one of those strings. +callbacks=cb_, + _cb + +# A regular expression matching the name of dummy variables (i.e. expected to +# not be used). +dummy-variables-rgx=_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|dummy|^ignored_|^unused_ + +# Argument names that match this expression will be ignored. +ignored-argument-names=_.*|^ignored_|^unused_ + +# Tells whether we should check for unused import in __init__ files. +init-import=no + +# List of qualified module names which can have objects that can redefine +# builtins. +redefining-builtins-modules=six.moves,past.builtins,future.builtins,builtins,io diff --git a/docs/FAQ-EN.md b/docs/FAQ-EN.md index fe2def1e1..d4a9f6097 100644 --- a/docs/FAQ-EN.md +++ b/docs/FAQ-EN.md @@ -98,7 +98,7 @@ 1. How to change the investment amount? - 1. You can view all commands by typing `python startup.py --help` + 1. You can view all commands by typing `metagpt --help` 1. Which version of Python is more stable? @@ -134,7 +134,7 @@ 1. Configuration instructions for SD Skills: The SD interface is currently deployed based on *https://github.com/AUTOMATIC1111/stable-diffusion-webui* **For environmental configurations and model downloads, please refer to the aforementioned GitHub repository. To initiate the SD service that supports API calls, run the command specified in cmd with the parameter nowebui, i.e., - 1. > python webui.py --enable-insecure-extension-access --port xxx --no-gradio-queue --nowebui + 1. > python3 webui.py --enable-insecure-extension-access --port xxx --no-gradio-queue --nowebui 1. Once it runs without errors, the interface will be accessible after approximately 1 minute when the model finishes loading. 1. Configure SD_URL and SD_T2I_API in the config.yaml/key.yaml files. 1. 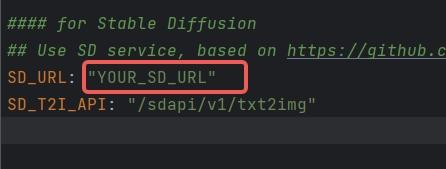 diff --git a/docs/README_CN.md b/docs/README_CN.md index 038925184..2855b5500 100644 --- a/docs/README_CN.md +++ b/docs/README_CN.md @@ -47,9 +47,9 @@ # 第 2 步:克隆最新仓库到您的本地机器,并进行安装。 cd MetaGPT pip3 install -e. # 或者 pip3 install metagpt # 安装稳定版本 -# 第 3 步:执行startup.py +# 第 3 步:执行metagpt # 拷贝config.yaml为key.yaml,并设置你自己的OPENAI_API_KEY -python3 startup.py "Write a cli snake game" +metagpt "Write a cli snake game" # 第 4 步【可选的】:如果你想在执行过程中保存像象限图、系统设计、序列流程等图表这些产物,可以在第3步前执行该步骤。默认的,框架做了兼容,在不执行该步的情况下,也可以完整跑完整个流程。 # 如果执行,确保您的系统上安装了 NPM。并使用npm安装mermaid-js @@ -75,10 +75,10 @@ # 步骤2: 使用容器运行metagpt演示 -v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \ -v /opt/metagpt/workspace:/app/metagpt/workspace \ metagpt/metagpt:latest \ - python startup.py "Write a cli snake game" + metagpt "Write a cli snake game" ``` -详细的安装请安装 [docker_install](https://docs.deepwisdom.ai/zhcn/guide/get_started/installation.html#%E4%BD%BF%E7%94%A8docker%E5%AE%89%E8%A3%85) +详细的安装请安装 [docker_install](https://docs.deepwisdom.ai/main/zh/guide/get_started/installation.html#%E4%BD%BF%E7%94%A8docker%E5%AE%89%E8%A3%85) ### 快速开始的演示视频 - 在 [MetaGPT Huggingface Space](https://huggingface.co/spaces/deepwisdom/MetaGPT) 上进行体验 @@ -88,19 +88,19 @@ ### 快速开始的演示视频 https://github.com/geekan/MetaGPT/assets/34952977/34345016-5d13-489d-b9f9-b82ace413419 ## 教程 -- 🗒 [在线文档](https://docs.deepwisdom.ai/zhcn/) -- 💻 [如何使用](https://docs.deepwisdom.ai/zhcn/guide/get_started/quickstart.html) -- 🔎 [MetaGPT的能力及应用场景](https://docs.deepwisdom.ai/zhcn/guide/get_started/introduction.html) +- 🗒 [在线文档](https://docs.deepwisdom.ai/main/zh/) +- 💻 [如何使用](https://docs.deepwisdom.ai/main/zh/guide/get_started/quickstart.html) +- 🔎 [MetaGPT的能力及应用场景](https://docs.deepwisdom.ai/main/zh/guide/get_started/introduction.html) - 🛠 如何构建你自己的智能体? - - [MetaGPT的使用和开发教程 | 智能体入门](https://docs.deepwisdom.ai/zhcn/guide/tutorials/agent_101.html) - - [MetaGPT的使用和开发教程 | 多智能体入门](https://docs.deepwisdom.ai/zhcn/guide/tutorials/multi_agent_101.html) + - [MetaGPT的使用和开发教程 | 智能体入门](https://docs.deepwisdom.ai/main/zh/guide/tutorials/agent_101.html) + - [MetaGPT的使用和开发教程 | 多智能体入门](https://docs.deepwisdom.ai/main/zh/guide/tutorials/multi_agent_101.html) - 🧑💻 贡献 - [开发路线图](ROADMAP.md) - 🔖 示例 - - [辩论](https://docs.deepwisdom.ai/zhcn/guide/use_cases/multi_agent/debate.html) - - [调研员](https://docs.deepwisdom.ai/zhcn/guide/use_cases/agent/researcher.html) - - [票据助手](https://docs.deepwisdom.ai/zhcn/guide/use_cases/agent/receipt_assistant.html) -- ❓ [常见问题解答](https://docs.deepwisdom.ai/zhcn/guide/faq.html) + - [辩论](https://docs.deepwisdom.ai/main/zh/guide/use_cases/multi_agent/debate.html) + - [调研员](https://docs.deepwisdom.ai/main/zh/guide/use_cases/agent/researcher.html) + - [票据助手](https://docs.deepwisdom.ai/main/zh/guide/use_cases/agent/receipt_assistant.html) +- ❓ [常见问题解答](https://docs.deepwisdom.ai/main/zh/guide/faq.html) ## 支持 @@ -114,7 +114,7 @@ ### 联系信息 如果您对这个项目有任何问题或反馈,欢迎联系我们。我们非常欢迎您的建议! -- **邮箱:** alexanderwu@fuzhi.ai +- **邮箱:** alexanderwu@deepwisdom.ai - **GitHub 问题:** 对于更技术性的问题,您也可以在我们的 [GitHub 仓库](https://github.com/geekan/metagpt/issues) 中创建一个新的问题。 我们会在2-3个工作日内回复所有问题。 diff --git a/docs/README_JA.md b/docs/README_JA.md index 14e7c3111..8b2bf1fae 100644 --- a/docs/README_JA.md +++ b/docs/README_JA.md @@ -41,7 +41,7 @@ ## MetaGPT の能力 ## 例(GPT-4 で完全生成) -例えば、`python startup.py "Toutiao のような RecSys をデザインする"`と入力すると、多くの出力が得られます +例えば、`metagpt "Toutiao のような RecSys をデザインする"`と入力すると、多くの出力が得られます  @@ -60,16 +60,16 @@ ### 伝統的なインストール ```bash # ステップ 1: Python 3.9+ がシステムにインストールされていることを確認してください。これを確認するには: -python --version +python3 --version # ステップ 2: リポジトリをローカルマシンにクローンし、インストールする。 git clone https://github.com/geekan/MetaGPT.git cd MetaGPT pip install -e. -# ステップ 3: startup.py を実行する +# ステップ 3: metagpt を実行する # config.yaml を key.yaml にコピーし、独自の OPENAI_API_KEY を設定します -python3 startup.py "Write a cli snake game" +metagpt "Write a cli snake game" # ステップ 4 [オプション]: 実行中に PRD ファイルなどのアーティファクトを保存する場合は、ステップ 3 の前にこのステップを実行できます。デフォルトでは、フレームワークには互換性があり、この手順を実行しなくてもプロセス全体を完了できます。 # NPM がシステムにインストールされていることを確認してください。次に mermaid-js をインストールします。(お使いのコンピューターに npm がない場合は、Node.js 公式サイトで Node.js https://nodejs.org/ をインストールしてください。) @@ -178,7 +178,7 @@ # ステップ 2: コンテナで metagpt デモを実行する -v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \ -v /opt/metagpt/workspace:/app/metagpt/workspace \ metagpt/metagpt:latest \ - python startup.py "Write a cli snake game" + metagpt "Write a cli snake game" # コンテナを起動し、その中でコマンドを実行することもできます docker run --name metagpt -d \ @@ -188,7 +188,7 @@ # コンテナを起動し、その中でコマンドを実行することもで metagpt/metagpt:latest docker exec -it metagpt /bin/bash -$ python startup.py "Write a cli snake game" +$ metagpt "Write a cli snake game" ``` コマンド `docker run ...` は以下のことを行います: @@ -196,7 +196,7 @@ # コンテナを起動し、その中でコマンドを実行することもで - 特権モードで実行し、ブラウザの実行権限を得る - ホスト設定ファイル `/opt/metagpt/config/key.yaml` をコンテナ `/app/metagpt/config/key.yaml` にマップします - ホストディレクトリ `/opt/metagpt/workspace` をコンテナディレクトリ `/app/metagpt/workspace` にマップするs -- デモコマンド `python startup.py "Write a cli snake game"` を実行する +- デモコマンド `metagpt "Write a cli snake game"` を実行する ### 自分でイメージをビルドする @@ -225,11 +225,11 @@ ## チュートリアル: スタートアップの開始 ```shell # スクリプトの実行 -python startup.py "Write a cli snake game" +metagpt "Write a cli snake game" # プロジェクトの実施にエンジニアを雇わないこと -python startup.py "Write a cli snake game" --implement False +metagpt "Write a cli snake game" --no-implement # エンジニアを雇い、コードレビューを行う -python startup.py "Write a cli snake game" --code_review True +metagpt "Write a cli snake game" --code_review ``` スクリプトを実行すると、`workspace/` ディレクトリに新しいプロジェクトが見つかります。 @@ -239,17 +239,17 @@ ### プラットフォームまたはツールの設定 要件を述べるときに、どのプラットフォームまたはツールを使用するかを指定できます。 ```shell -python startup.py "pygame をベースとした cli ヘビゲームを書く" +metagpt "pygame をベースとした cli ヘビゲームを書く" ``` ### 使用方法 ``` 会社名 - startup.py - 私たちは AI で構成されたソフトウェア・スタートアップです。私たちに投資することは、無限の可能性に満ちた未来に力を与えることです。 + metagpt - 私たちは AI で構成されたソフトウェア・スタートアップです。私たちに投資することは、無限の可能性に満ちた未来に力を与えることです。 シノプシス - startup.py IDEA.*)(```.*?)",
- r"(.*?```python.*?\s+)?(?P.*)",
- ):
+ for pattern in (r"(.*?```python.*?\s+)?(?P.*)(```.*?)", r"(.*?```python.*?\s+)?(?P.*)"):
match = re.search(pattern, text, re.DOTALL)
if not match:
continue
@@ -119,8 +134,32 @@ class OutputParser:
parsed_data[block] = content
return parsed_data
+ @staticmethod
+ def extract_content(text, tag="CONTENT"):
+ # Use regular expression to extract content between [CONTENT] and [/CONTENT]
+ extracted_content = re.search(rf"\[{tag}\](.*?)\[/{tag}\]", text, re.DOTALL)
+
+ if extracted_content:
+ return extracted_content.group(1).strip()
+ else:
+ return "No content found between [CONTENT] and [/CONTENT] tags."
+
+ @staticmethod
+ def is_supported_list_type(i):
+ origin = get_origin(i)
+ if origin is not List:
+ return False
+
+ args = get_args(i)
+ if args == (str,) or args == (Tuple[str, str],) or args == (List[str],):
+ return True
+
+ return False
+
@classmethod
def parse_data_with_mapping(cls, data, mapping):
+ if "[CONTENT]" in data:
+ data = cls.extract_content(text=data)
block_dict = cls.parse_blocks(data)
parsed_data = {}
for block, content in block_dict.items():
@@ -187,7 +226,7 @@ class OutputParser:
result = ast.literal_eval(structure_text)
# Ensure the result matches the specified data type
- if isinstance(result, list) or isinstance(result, dict):
+ if isinstance(result, (list, dict)):
return result
raise ValueError(f"The extracted structure is not a {data_type}.")
@@ -219,10 +258,15 @@ class CodeParser:
# 遍历所有的block
for block in blocks:
# 如果block不为空,则继续处理
- if block.strip() != "":
+ if block.strip() == "":
+ continue
+ if "\n" not in block:
+ block_title = block
+ block_content = ""
+ else:
# 将block的标题和内容分开,并分别去掉前后的空白字符
block_title, block_content = block.split("\n", 1)
- block_dict[block_title.strip()] = block_content.strip()
+ block_dict[block_title.strip()] = block_content.strip()
return block_dict
@@ -282,9 +326,6 @@ class NoMoneyException(Exception):
def print_members(module, indent=0):
"""
https://stackoverflow.com/questions/1796180/how-can-i-get-a-list-of-all-classes-within-current-module-in-python
- :param module:
- :param indent:
- :return:
"""
prefix = " " * indent
for name, obj in inspect.getmembers(module):
@@ -302,6 +343,173 @@ def print_members(module, indent=0):
def parse_recipient(text):
+ # FIXME: use ActionNode instead.
pattern = r"## Send To:\s*([A-Za-z]+)\s*?" # hard code for now
recipient = re.search(pattern, text)
- return recipient.group(1) if recipient else ""
+ if recipient:
+ return recipient.group(1)
+ pattern = r"Send To:\s*([A-Za-z]+)\s*?"
+ recipient = re.search(pattern, text)
+ if recipient:
+ return recipient.group(1)
+ return ""
+
+
+def get_class_name(cls) -> str:
+ """Return class name"""
+ return f"{cls.__module__}.{cls.__name__}"
+
+
+def any_to_str(val: str | typing.Callable) -> str:
+ """Return the class name or the class name of the object, or 'val' if it's a string type."""
+ if isinstance(val, str):
+ return val
+ if not callable(val):
+ return get_class_name(type(val))
+
+ return get_class_name(val)
+
+
+def any_to_str_set(val) -> set:
+ """Convert any type to string set."""
+ res = set()
+
+ # Check if the value is iterable, but not a string (since strings are technically iterable)
+ if isinstance(val, (dict, list, set, tuple)):
+ # Special handling for dictionaries to iterate over values
+ if isinstance(val, dict):
+ val = val.values()
+
+ for i in val:
+ res.add(any_to_str(i))
+ else:
+ res.add(any_to_str(val))
+
+ return res
+
+
+def is_subscribed(message: "Message", tags: set):
+ """Return whether it's consumer"""
+ if MESSAGE_ROUTE_TO_ALL in message.send_to:
+ return True
+
+ for i in tags:
+ if i in message.send_to:
+ return True
+ return False
+
+
+def general_after_log(i: "loguru.Logger", sec_format: str = "%0.3f") -> typing.Callable[["RetryCallState"], None]:
+ """
+ Generates a logging function to be used after a call is retried.
+
+ This generated function logs an error message with the outcome of the retried function call. It includes
+ the name of the function, the time taken for the call in seconds (formatted according to `sec_format`),
+ the number of attempts made, and the exception raised, if any.
+
+ :param i: A Logger instance from the loguru library used to log the error message.
+ :param sec_format: A string format specifier for how to format the number of seconds since the start of the call.
+ Defaults to three decimal places.
+ :return: A callable that accepts a RetryCallState object and returns None. This callable logs the details
+ of the retried call.
+ """
+
+ def log_it(retry_state: "RetryCallState") -> None:
+ # If the function name is not known, default to ""
+ if retry_state.fn is None:
+ fn_name = ""
+ else:
+ # Retrieve the callable's name using a utility function
+ fn_name = _utils.get_callback_name(retry_state.fn)
+
+ # Log an error message with the function name, time since start, attempt number, and the exception
+ i.error(
+ f"Finished call to '{fn_name}' after {sec_format % retry_state.seconds_since_start}(s), "
+ f"this was the {_utils.to_ordinal(retry_state.attempt_number)} time calling it. "
+ f"exp: {retry_state.outcome.exception()}"
+ )
+
+ return log_it
+
+
+def read_json_file(json_file: str, encoding=None) -> list[Any]:
+ if not Path(json_file).exists():
+ raise FileNotFoundError(f"json_file: {json_file} not exist, return []")
+
+ with open(json_file, "r", encoding=encoding) as fin:
+ try:
+ data = json.load(fin)
+ except Exception:
+ raise ValueError(f"read json file: {json_file} failed")
+ return data
+
+
+def write_json_file(json_file: str, data: list, encoding=None):
+ folder_path = Path(json_file).parent
+ if not folder_path.exists():
+ folder_path.mkdir(parents=True, exist_ok=True)
+
+ with open(json_file, "w", encoding=encoding) as fout:
+ json.dump(data, fout, ensure_ascii=False, indent=4, default=pydantic_encoder)
+
+
+def import_class(class_name: str, module_name: str) -> type:
+ module = importlib.import_module(module_name)
+ a_class = getattr(module, class_name)
+ return a_class
+
+
+def import_class_inst(class_name: str, module_name: str, *args, **kwargs) -> object:
+ a_class = import_class(class_name, module_name)
+ class_inst = a_class(*args, **kwargs)
+ return class_inst
+
+
+def format_trackback_info(limit: int = 2):
+ return traceback.format_exc(limit=limit)
+
+
+def serialize_decorator(func):
+ async def wrapper(self, *args, **kwargs):
+ try:
+ result = await func(self, *args, **kwargs)
+ return result
+ except KeyboardInterrupt:
+ logger.error(f"KeyboardInterrupt occurs, start to serialize the project, exp:\n{format_trackback_info()}")
+ except Exception:
+ logger.error(f"Exception occurs, start to serialize the project, exp:\n{format_trackback_info()}")
+ self.serialize() # Team.serialize
+
+ return wrapper
+
+
+def role_raise_decorator(func):
+ async def wrapper(self, *args, **kwargs):
+ try:
+ return await func(self, *args, **kwargs)
+ except KeyboardInterrupt as kbi:
+ logger.error(f"KeyboardInterrupt: {kbi} occurs, start to serialize the project")
+ if self.latest_observed_msg:
+ self._rc.memory.delete(self.latest_observed_msg)
+ # raise again to make it captured outside
+ raise Exception(format_trackback_info(limit=None))
+ except Exception:
+ if self.latest_observed_msg:
+ logger.warning(
+ "There is a exception in role's execution, in order to resume, "
+ "we delete the newest role communication message in the role's memory."
+ )
+ # remove role newest observed msg to make it observed again
+ self._rc.memory.delete(self.latest_observed_msg)
+ # raise again to make it captured outside
+ raise Exception(format_trackback_info(limit=None))
+
+ return wrapper
+
+
+@handle_exception
+async def aread(file_path: str) -> str:
+ """Read file asynchronously."""
+ async with aiofiles.open(str(file_path), mode="r") as reader:
+ content = await reader.read()
+ return content
diff --git a/metagpt/utils/custom_decoder.py b/metagpt/utils/custom_decoder.py
index 373d16356..eb01a1115 100644
--- a/metagpt/utils/custom_decoder.py
+++ b/metagpt/utils/custom_decoder.py
@@ -25,7 +25,7 @@ def py_make_scanner(context):
except IndexError:
raise StopIteration(idx) from None
- if nextchar == '"' or nextchar == "'":
+ if nextchar in ("'", '"'):
if idx + 2 < len(string) and string[idx + 1] == nextchar and string[idx + 2] == nextchar:
# Handle the case where the next two characters are the same as nextchar
return parse_string(string, idx + 3, strict, delimiter=nextchar * 3) # triple quote
diff --git a/metagpt/utils/dependency_file.py b/metagpt/utils/dependency_file.py
new file mode 100644
index 000000000..8a6575e9e
--- /dev/null
+++ b/metagpt/utils/dependency_file.py
@@ -0,0 +1,103 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/11/22
+@Author : mashenquan
+@File : dependency_file.py
+@Desc: Implementation of the dependency file described in Section 2.2.3.2 of RFC 135.
+"""
+from __future__ import annotations
+
+import json
+from pathlib import Path
+from typing import Set
+
+import aiofiles
+
+from metagpt.config import CONFIG
+from metagpt.utils.common import aread
+from metagpt.utils.exceptions import handle_exception
+
+
+class DependencyFile:
+ """A class representing a DependencyFile for managing dependencies.
+
+ :param workdir: The working directory path for the DependencyFile.
+ """
+
+ def __init__(self, workdir: Path | str):
+ """Initialize a DependencyFile instance.
+
+ :param workdir: The working directory path for the DependencyFile.
+ """
+ self._dependencies = {}
+ self._filename = Path(workdir) / ".dependencies.json"
+
+ async def load(self):
+ """Load dependencies from the file asynchronously."""
+ if not self._filename.exists():
+ return
+ self._dependencies = json.loads(await aread(self._filename))
+
+ @handle_exception
+ async def save(self):
+ """Save dependencies to the file asynchronously."""
+ data = json.dumps(self._dependencies)
+ async with aiofiles.open(str(self._filename), mode="w") as writer:
+ await writer.write(data)
+
+ async def update(self, filename: Path | str, dependencies: Set[Path | str], persist=True):
+ """Update dependencies for a file asynchronously.
+
+ :param filename: The filename or path.
+ :param dependencies: The set of dependencies.
+ :param persist: Whether to persist the changes immediately.
+ """
+ if persist:
+ await self.load()
+
+ root = self._filename.parent
+ try:
+ key = Path(filename).relative_to(root)
+ except ValueError:
+ key = filename
+
+ if dependencies:
+ relative_paths = []
+ for i in dependencies:
+ try:
+ relative_paths.append(str(Path(i).relative_to(root)))
+ except ValueError:
+ relative_paths.append(str(i))
+ self._dependencies[str(key)] = relative_paths
+ elif str(key) in self._dependencies:
+ del self._dependencies[str(key)]
+
+ if persist:
+ await self.save()
+
+ async def get(self, filename: Path | str, persist=True):
+ """Get dependencies for a file asynchronously.
+
+ :param filename: The filename or path.
+ :param persist: Whether to load dependencies from the file immediately.
+ :return: A set of dependencies.
+ """
+ if persist:
+ await self.load()
+
+ root = CONFIG.git_repo.workdir
+ try:
+ key = Path(filename).relative_to(root)
+ except ValueError:
+ key = filename
+ return set(self._dependencies.get(str(key), {}))
+
+ def delete_file(self):
+ """Delete the dependency file."""
+ self._filename.unlink(missing_ok=True)
+
+ @property
+ def exists(self):
+ """Check if the dependency file exists."""
+ return self._filename.exists()
diff --git a/metagpt/utils/exceptions.py b/metagpt/utils/exceptions.py
new file mode 100644
index 000000000..b4b5aa590
--- /dev/null
+++ b/metagpt/utils/exceptions.py
@@ -0,0 +1,59 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/12/19 14:46
+@Author : alexanderwu
+@File : exceptions.py
+"""
+
+
+import asyncio
+import functools
+import traceback
+from typing import Any, Callable, Tuple, Type, TypeVar, Union
+
+from metagpt.logs import logger
+
+ReturnType = TypeVar("ReturnType")
+
+
+def handle_exception(
+ _func: Callable[..., ReturnType] = None,
+ *,
+ exception_type: Union[Type[Exception], Tuple[Type[Exception], ...]] = Exception,
+ default_return: Any = None,
+) -> Callable[..., ReturnType]:
+ """handle exception, return default value"""
+
+ def decorator(func: Callable[..., ReturnType]) -> Callable[..., ReturnType]:
+ @functools.wraps(func)
+ async def async_wrapper(*args: Any, **kwargs: Any) -> ReturnType:
+ try:
+ return await func(*args, **kwargs)
+ except exception_type as e:
+ logger.opt(depth=1).error(
+ f"Calling {func.__name__} with args: {args}, kwargs: {kwargs} failed: {e}, "
+ f"stack: {traceback.format_exc()}"
+ )
+ return default_return
+
+ @functools.wraps(func)
+ def sync_wrapper(*args: Any, **kwargs: Any) -> ReturnType:
+ try:
+ return func(*args, **kwargs)
+ except exception_type as e:
+ logger.opt(depth=1).error(
+ f"Calling {func.__name__} with args: {args}, kwargs: {kwargs} failed: {e}, "
+ f"stack: {traceback.format_exc()}"
+ )
+ return default_return
+
+ if asyncio.iscoroutinefunction(func):
+ return async_wrapper
+ else:
+ return sync_wrapper
+
+ if _func is None:
+ return decorator
+ else:
+ return decorator(_func)
diff --git a/metagpt/utils/file.py b/metagpt/utils/file.py
index f3691549b..f62b44eb8 100644
--- a/metagpt/utils/file.py
+++ b/metagpt/utils/file.py
@@ -6,10 +6,12 @@
@File : file.py
@Describe : General file operations.
"""
-import aiofiles
from pathlib import Path
+import aiofiles
+
from metagpt.logs import logger
+from metagpt.utils.exceptions import handle_exception
class File:
@@ -18,6 +20,7 @@ class File:
CHUNK_SIZE = 64 * 1024
@classmethod
+ @handle_exception
async def write(cls, root_path: Path, filename: str, content: bytes) -> Path:
"""Write the file content to the local specified path.
@@ -32,18 +35,15 @@ class File:
Raises:
Exception: If an unexpected error occurs during the file writing process.
"""
- try:
- root_path.mkdir(parents=True, exist_ok=True)
- full_path = root_path / filename
- async with aiofiles.open(full_path, mode="wb") as writer:
- await writer.write(content)
- logger.debug(f"Successfully write file: {full_path}")
- return full_path
- except Exception as e:
- logger.error(f"Error writing file: {e}")
- raise e
+ root_path.mkdir(parents=True, exist_ok=True)
+ full_path = root_path / filename
+ async with aiofiles.open(full_path, mode="wb") as writer:
+ await writer.write(content)
+ logger.debug(f"Successfully write file: {full_path}")
+ return full_path
@classmethod
+ @handle_exception
async def read(cls, file_path: Path, chunk_size: int = None) -> bytes:
"""Partitioning read the file content from the local specified path.
@@ -57,19 +57,14 @@ class File:
Raises:
Exception: If an unexpected error occurs during the file reading process.
"""
- try:
- chunk_size = chunk_size or cls.CHUNK_SIZE
- async with aiofiles.open(file_path, mode="rb") as reader:
- chunks = list()
- while True:
- chunk = await reader.read(chunk_size)
- if not chunk:
- break
- chunks.append(chunk)
- content = b''.join(chunks)
- logger.debug(f"Successfully read file, the path of file: {file_path}")
- return content
- except Exception as e:
- logger.error(f"Error reading file: {e}")
- raise e
-
+ chunk_size = chunk_size or cls.CHUNK_SIZE
+ async with aiofiles.open(file_path, mode="rb") as reader:
+ chunks = list()
+ while True:
+ chunk = await reader.read(chunk_size)
+ if not chunk:
+ break
+ chunks.append(chunk)
+ content = b"".join(chunks)
+ logger.debug(f"Successfully read file, the path of file: {file_path}")
+ return content
diff --git a/metagpt/utils/file_repository.py b/metagpt/utils/file_repository.py
new file mode 100644
index 000000000..099556a6b
--- /dev/null
+++ b/metagpt/utils/file_repository.py
@@ -0,0 +1,287 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/11/20
+@Author : mashenquan
+@File : git_repository.py
+@Desc: File repository management. RFC 135 2.2.3.2, 2.2.3.4 and 2.2.3.13.
+"""
+from __future__ import annotations
+
+import json
+import os
+from datetime import datetime
+from pathlib import Path
+from typing import Dict, List, Set
+
+import aiofiles
+
+from metagpt.config import CONFIG
+from metagpt.logs import logger
+from metagpt.schema import Document
+from metagpt.utils.common import aread
+from metagpt.utils.json_to_markdown import json_to_markdown
+
+
+class FileRepository:
+ """A class representing a FileRepository associated with a Git repository.
+
+ :param git_repo: The associated GitRepository instance.
+ :param relative_path: The relative path within the Git repository.
+
+ Attributes:
+ _relative_path (Path): The relative path within the Git repository.
+ _git_repo (GitRepository): The associated GitRepository instance.
+ """
+
+ def __init__(self, git_repo, relative_path: Path = Path(".")):
+ """Initialize a FileRepository instance.
+
+ :param git_repo: The associated GitRepository instance.
+ :param relative_path: The relative path within the Git repository.
+ """
+ self._relative_path = relative_path
+ self._git_repo = git_repo
+
+ # Initializing
+ self.workdir.mkdir(parents=True, exist_ok=True)
+
+ async def save(self, filename: Path | str, content, dependencies: List[str] = None):
+ """Save content to a file and update its dependencies.
+
+ :param filename: The filename or path within the repository.
+ :param content: The content to be saved.
+ :param dependencies: List of dependency filenames or paths.
+ """
+ pathname = self.workdir / filename
+ pathname.parent.mkdir(parents=True, exist_ok=True)
+ async with aiofiles.open(str(pathname), mode="w") as writer:
+ await writer.write(content)
+ logger.info(f"save to: {str(pathname)}")
+
+ if dependencies is not None:
+ dependency_file = await self._git_repo.get_dependency()
+ await dependency_file.update(pathname, set(dependencies))
+ logger.info(f"update dependency: {str(pathname)}:{dependencies}")
+
+ async def get_dependency(self, filename: Path | str) -> Set[str]:
+ """Get the dependencies of a file.
+
+ :param filename: The filename or path within the repository.
+ :return: Set of dependency filenames or paths.
+ """
+ pathname = self.workdir / filename
+ dependency_file = await self._git_repo.get_dependency()
+ return await dependency_file.get(pathname)
+
+ async def get_changed_dependency(self, filename: Path | str) -> Set[str]:
+ """Get the dependencies of a file that have changed.
+
+ :param filename: The filename or path within the repository.
+ :return: List of changed dependency filenames or paths.
+ """
+ dependencies = await self.get_dependency(filename=filename)
+ changed_files = self.changed_files
+ changed_dependent_files = set()
+ for df in dependencies:
+ if df in changed_files.keys():
+ changed_dependent_files.add(df)
+ return changed_dependent_files
+
+ async def get(self, filename: Path | str) -> Document | None:
+ """Read the content of a file.
+
+ :param filename: The filename or path within the repository.
+ :return: The content of the file.
+ """
+ doc = Document(root_path=str(self.root_path), filename=str(filename))
+ path_name = self.workdir / filename
+ if not path_name.exists():
+ return None
+ doc.content = await aread(path_name)
+ return doc
+
+ async def get_all(self) -> List[Document]:
+ """Get the content of all files in the repository.
+
+ :return: List of Document instances representing files.
+ """
+ docs = []
+ for root, dirs, files in os.walk(str(self.workdir)):
+ for file in files:
+ file_path = Path(root) / file
+ relative_path = file_path.relative_to(self.workdir)
+ doc = await self.get(relative_path)
+ docs.append(doc)
+ return docs
+
+ @property
+ def workdir(self):
+ """Return the absolute path to the working directory of the FileRepository.
+
+ :return: The absolute path to the working directory.
+ """
+ return self._git_repo.workdir / self._relative_path
+
+ @property
+ def root_path(self):
+ """Return the relative path from git repository root"""
+ return self._relative_path
+
+ @property
+ def changed_files(self) -> Dict[str, str]:
+ """Return a dictionary of changed files and their change types.
+
+ :return: A dictionary where keys are file paths and values are change types.
+ """
+ files = self._git_repo.changed_files
+ relative_files = {}
+ for p, ct in files.items():
+ try:
+ rf = Path(p).relative_to(self._relative_path)
+ except ValueError:
+ continue
+ relative_files[str(rf)] = ct
+ return relative_files
+
+ @property
+ def all_files(self) -> List:
+ """Get a dictionary of all files in the repository.
+
+ The dictionary includes file paths relative to the current FileRepository.
+
+ :return: A dictionary where keys are file paths and values are file information.
+ :rtype: List
+ """
+ return self._git_repo.get_files(relative_path=self._relative_path)
+
+ def get_change_dir_files(self, dir: Path | str) -> List:
+ """Get the files in a directory that have changed.
+
+ :param dir: The directory path within the repository.
+ :return: List of changed filenames or paths within the directory.
+ """
+ changed_files = self.changed_files
+ children = []
+ for f in changed_files:
+ try:
+ Path(f).relative_to(Path(dir))
+ except ValueError:
+ continue
+ children.append(str(f))
+ return children
+
+ @staticmethod
+ def new_filename():
+ """Generate a new filename based on the current timestamp and a UUID suffix.
+
+ :return: A new filename string.
+ """
+ current_time = datetime.now().strftime("%Y%m%d%H%M%S")
+ return current_time
+ # guid_suffix = str(uuid.uuid4())[:8]
+ # return f"{current_time}x{guid_suffix}"
+
+ async def save_doc(self, doc: Document, with_suffix: str = None, dependencies: List[str] = None):
+ """Save a Document instance as a PDF file.
+
+ This method converts the content of the Document instance to Markdown,
+ saves it to a file with an optional specified suffix, and logs the saved file.
+
+ :param doc: The Document instance to be saved.
+ :type doc: Document
+ :param with_suffix: An optional suffix to append to the saved file's name.
+ :type with_suffix: str, optional
+ :param dependencies: A list of dependencies for the saved file.
+ :type dependencies: List[str], optional
+ """
+ m = json.loads(doc.content)
+ filename = Path(doc.filename).with_suffix(with_suffix) if with_suffix is not None else Path(doc.filename)
+ await self.save(filename=str(filename), content=json_to_markdown(m), dependencies=dependencies)
+ logger.debug(f"File Saved: {str(filename)}")
+
+ @staticmethod
+ async def get_file(filename: Path | str, relative_path: Path | str = ".") -> Document | None:
+ """Retrieve a specific file from the file repository.
+
+ :param filename: The name or path of the file to retrieve.
+ :type filename: Path or str
+ :param relative_path: The relative path within the file repository.
+ :type relative_path: Path or str, optional
+ :return: The document representing the file, or None if not found.
+ :rtype: Document or None
+ """
+ file_repo = CONFIG.git_repo.new_file_repository(relative_path=relative_path)
+ return await file_repo.get(filename=filename)
+
+ @staticmethod
+ async def get_all_files(relative_path: Path | str = ".") -> List[Document]:
+ """Retrieve all files from the file repository.
+
+ :param relative_path: The relative path within the file repository.
+ :type relative_path: Path or str, optional
+ :return: A list of documents representing all files in the repository.
+ :rtype: List[Document]
+ """
+ file_repo = CONFIG.git_repo.new_file_repository(relative_path=relative_path)
+ return await file_repo.get_all()
+
+ @staticmethod
+ async def save_file(filename: Path | str, content, dependencies: List[str] = None, relative_path: Path | str = "."):
+ """Save a file to the file repository.
+
+ :param filename: The name or path of the file to save.
+ :type filename: Path or str
+ :param content: The content of the file.
+ :param dependencies: A list of dependencies for the file.
+ :type dependencies: List[str], optional
+ :param relative_path: The relative path within the file repository.
+ :type relative_path: Path or str, optional
+ """
+ file_repo = CONFIG.git_repo.new_file_repository(relative_path=relative_path)
+ return await file_repo.save(filename=filename, content=content, dependencies=dependencies)
+
+ @staticmethod
+ async def save_as(
+ doc: Document, with_suffix: str = None, dependencies: List[str] = None, relative_path: Path | str = "."
+ ):
+ """Save a Document instance with optional modifications.
+
+ This static method creates a new FileRepository, saves the Document instance
+ with optional modifications (such as a suffix), and logs the saved file.
+
+ :param doc: The Document instance to be saved.
+ :type doc: Document
+ :param with_suffix: An optional suffix to append to the saved file's name.
+ :type with_suffix: str, optional
+ :param dependencies: A list of dependencies for the saved file.
+ :type dependencies: List[str], optional
+ :param relative_path: The relative path within the file repository.
+ :type relative_path: Path or str, optional
+ :return: A boolean indicating whether the save operation was successful.
+ :rtype: bool
+ """
+ file_repo = CONFIG.git_repo.new_file_repository(relative_path=relative_path)
+ return await file_repo.save_doc(doc=doc, with_suffix=with_suffix, dependencies=dependencies)
+
+ async def delete(self, filename: Path | str):
+ """Delete a file from the file repository.
+
+ This method deletes a file from the file repository based on the provided filename.
+
+ :param filename: The name or path of the file to be deleted.
+ :type filename: Path or str
+ """
+ pathname = self.workdir / filename
+ if not pathname.exists():
+ return
+ pathname.unlink(missing_ok=True)
+
+ dependency_file = await self._git_repo.get_dependency()
+ await dependency_file.update(filename=pathname, dependencies=None)
+ logger.info(f"remove dependency key: {str(pathname)}")
+
+ @staticmethod
+ async def delete_file(filename: Path | str, relative_path: Path | str = "."):
+ file_repo = CONFIG.git_repo.new_file_repository(relative_path=relative_path)
+ await file_repo.delete(filename=filename)
diff --git a/metagpt/utils/get_template.py b/metagpt/utils/get_template.py
index 86c1915f7..7e05e5d5e 100644
--- a/metagpt/utils/get_template.py
+++ b/metagpt/utils/get_template.py
@@ -8,10 +8,10 @@
from metagpt.config import CONFIG
-def get_template(templates, format=CONFIG.prompt_format):
- selected_templates = templates.get(format)
+def get_template(templates, schema=CONFIG.prompt_schema):
+ selected_templates = templates.get(schema)
if selected_templates is None:
- raise ValueError(f"Can't find {format} in passed in templates")
+ raise ValueError(f"Can't find {schema} in passed in templates")
# Extract the selected templates
prompt_template = selected_templates["PROMPT_TEMPLATE"]
diff --git a/metagpt/utils/git_repository.py b/metagpt/utils/git_repository.py
new file mode 100644
index 000000000..d2bdf5d85
--- /dev/null
+++ b/metagpt/utils/git_repository.py
@@ -0,0 +1,290 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/11/20
+@Author : mashenquan
+@File : git_repository.py
+@Desc: Git repository management. RFC 135 2.2.3.3.
+"""
+from __future__ import annotations
+
+import shutil
+from enum import Enum
+from pathlib import Path
+from typing import Dict, List
+
+from git.repo import Repo
+from git.repo.fun import is_git_dir
+from gitignore_parser import parse_gitignore
+
+from metagpt.const import DEFAULT_WORKSPACE_ROOT
+from metagpt.logs import logger
+from metagpt.utils.dependency_file import DependencyFile
+from metagpt.utils.file_repository import FileRepository
+
+
+class ChangeType(Enum):
+ ADDED = "A" # File was added
+ COPIED = "C" # File was copied
+ DELETED = "D" # File was deleted
+ RENAMED = "R" # File was renamed
+ MODIFIED = "M" # File was modified
+ TYPE_CHANGED = "T" # Type of the file was changed
+ UNTRACTED = "U" # File is untracked (not added to version control)
+
+
+class GitRepository:
+ """A class representing a Git repository.
+
+ :param local_path: The local path to the Git repository.
+ :param auto_init: If True, automatically initializes a new Git repository if the provided path is not a Git repository.
+
+ Attributes:
+ _repository (Repo): The GitPython `Repo` object representing the Git repository.
+ """
+
+ def __init__(self, local_path=None, auto_init=True):
+ """Initialize a GitRepository instance.
+
+ :param local_path: The local path to the Git repository.
+ :param auto_init: If True, automatically initializes a new Git repository if the provided path is not a Git repository.
+ """
+ self._repository = None
+ self._dependency = None
+ self._gitignore_rules = None
+ if local_path:
+ self.open(local_path=local_path, auto_init=auto_init)
+
+ def open(self, local_path: Path, auto_init=False):
+ """Open an existing Git repository or initialize a new one if auto_init is True.
+
+ :param local_path: The local path to the Git repository.
+ :param auto_init: If True, automatically initializes a new Git repository if the provided path is not a Git repository.
+ """
+ local_path = Path(local_path)
+ if self.is_git_dir(local_path):
+ self._repository = Repo(local_path)
+ self._gitignore_rules = parse_gitignore(full_path=str(local_path / ".gitignore"))
+ return
+ if not auto_init:
+ return
+ local_path.mkdir(parents=True, exist_ok=True)
+ return self._init(local_path)
+
+ def _init(self, local_path: Path):
+ """Initialize a new Git repository at the specified path.
+
+ :param local_path: The local path where the new Git repository will be initialized.
+ """
+ self._repository = Repo.init(path=Path(local_path))
+
+ gitignore_filename = Path(local_path) / ".gitignore"
+ ignores = ["__pycache__", "*.pyc"]
+ with open(str(gitignore_filename), mode="w") as writer:
+ writer.write("\n".join(ignores))
+ self._repository.index.add([".gitignore"])
+ self._repository.index.commit("Add .gitignore")
+ self._gitignore_rules = parse_gitignore(full_path=gitignore_filename)
+
+ def add_change(self, files: Dict):
+ """Add or remove files from the staging area based on the provided changes.
+
+ :param files: A dictionary where keys are file paths and values are instances of ChangeType.
+ """
+ if not self.is_valid or not files:
+ return
+
+ for k, v in files.items():
+ self._repository.index.remove(k) if v is ChangeType.DELETED else self._repository.index.add([k])
+
+ def commit(self, comments):
+ """Commit the staged changes with the given comments.
+
+ :param comments: Comments for the commit.
+ """
+ if self.is_valid:
+ self._repository.index.commit(comments)
+
+ def delete_repository(self):
+ """Delete the entire repository directory."""
+ if self.is_valid:
+ shutil.rmtree(self._repository.working_dir)
+
+ @property
+ def changed_files(self) -> Dict[str, str]:
+ """Return a dictionary of changed files and their change types.
+
+ :return: A dictionary where keys are file paths and values are change types.
+ """
+ files = {i: ChangeType.UNTRACTED for i in self._repository.untracked_files}
+ changed_files = {f.a_path: ChangeType(f.change_type) for f in self._repository.index.diff(None)}
+ files.update(changed_files)
+ return files
+
+ @staticmethod
+ def is_git_dir(local_path):
+ """Check if the specified directory is a Git repository.
+
+ :param local_path: The local path to check.
+ :return: True if the directory is a Git repository, False otherwise.
+ """
+ git_dir = Path(local_path) / ".git"
+ if git_dir.exists() and is_git_dir(git_dir):
+ return True
+ return False
+
+ @property
+ def is_valid(self):
+ """Check if the Git repository is valid (exists and is initialized).
+
+ :return: True if the repository is valid, False otherwise.
+ """
+ return bool(self._repository)
+
+ @property
+ def status(self) -> str:
+ """Return the Git repository's status as a string."""
+ if not self.is_valid:
+ return ""
+ return self._repository.git.status()
+
+ @property
+ def workdir(self) -> Path | None:
+ """Return the path to the working directory of the Git repository.
+
+ :return: The path to the working directory or None if the repository is not valid.
+ """
+ if not self.is_valid:
+ return None
+ return Path(self._repository.working_dir)
+
+ def archive(self, comments="Archive"):
+ """Archive the current state of the Git repository.
+
+ :param comments: Comments for the archive commit.
+ """
+ logger.info(f"Archive: {list(self.changed_files.keys())}")
+ self.add_change(self.changed_files)
+ self.commit(comments)
+
+ def new_file_repository(self, relative_path: Path | str = ".") -> FileRepository:
+ """Create a new instance of FileRepository associated with this Git repository.
+
+ :param relative_path: The relative path to the file repository within the Git repository.
+ :return: A new instance of FileRepository.
+ """
+ path = Path(relative_path)
+ try:
+ path = path.relative_to(self.workdir)
+ except ValueError:
+ path = relative_path
+ return FileRepository(git_repo=self, relative_path=Path(path))
+
+ async def get_dependency(self) -> DependencyFile:
+ """Get the dependency file associated with the Git repository.
+
+ :return: An instance of DependencyFile.
+ """
+ if not self._dependency:
+ self._dependency = DependencyFile(workdir=self.workdir)
+ return self._dependency
+
+ def rename_root(self, new_dir_name):
+ """Rename the root directory of the Git repository.
+
+ :param new_dir_name: The new name for the root directory.
+ """
+ if self.workdir.name == new_dir_name:
+ return
+ new_path = self.workdir.parent / new_dir_name
+ if new_path.exists():
+ logger.info(f"Delete directory {str(new_path)}")
+ shutil.rmtree(new_path)
+ try:
+ shutil.move(src=str(self.workdir), dst=str(new_path))
+ except Exception as e:
+ logger.warning(f"Move {str(self.workdir)} to {str(new_path)} error: {e}")
+ logger.info(f"Rename directory {str(self.workdir)} to {str(new_path)}")
+ self._repository = Repo(new_path)
+ self._gitignore_rules = parse_gitignore(full_path=str(new_path / ".gitignore"))
+
+ def get_files(self, relative_path: Path | str, root_relative_path: Path | str = None, filter_ignored=True) -> List:
+ """
+ Retrieve a list of files in the specified relative path.
+
+ The method returns a list of file paths relative to the current FileRepository.
+
+ :param relative_path: The relative path within the repository.
+ :type relative_path: Path or str
+ :param root_relative_path: The root relative path within the repository.
+ :type root_relative_path: Path or str
+ :param filter_ignored: Flag to indicate whether to filter files based on .gitignore rules.
+ :type filter_ignored: bool
+ :return: A list of file paths in the specified directory.
+ :rtype: List[str]
+ """
+ try:
+ relative_path = Path(relative_path).relative_to(self.workdir)
+ except ValueError:
+ relative_path = Path(relative_path)
+
+ if not root_relative_path:
+ root_relative_path = Path(self.workdir) / relative_path
+ files = []
+ try:
+ directory_path = Path(self.workdir) / relative_path
+ if not directory_path.exists():
+ return []
+ for file_path in directory_path.iterdir():
+ if file_path.is_file():
+ rpath = file_path.relative_to(root_relative_path)
+ files.append(str(rpath))
+ else:
+ subfolder_files = self.get_files(
+ relative_path=file_path, root_relative_path=root_relative_path, filter_ignored=False
+ )
+ files.extend(subfolder_files)
+ except Exception as e:
+ logger.error(f"Error: {e}")
+ if not filter_ignored:
+ return files
+ filtered_files = self.filter_gitignore(filenames=files, root_relative_path=root_relative_path)
+ return filtered_files
+
+ def filter_gitignore(self, filenames: List[str], root_relative_path: Path | str = None) -> List[str]:
+ """
+ Filter a list of filenames based on .gitignore rules.
+
+ :param filenames: A list of filenames to be filtered.
+ :type filenames: List[str]
+ :param root_relative_path: The root relative path within the repository.
+ :type root_relative_path: Path or str
+ :return: A list of filenames that pass the .gitignore filtering.
+ :rtype: List[str]
+ """
+ if root_relative_path is None:
+ root_relative_path = self.workdir
+ files = []
+ for filename in filenames:
+ pathname = root_relative_path / filename
+ if self._gitignore_rules(str(pathname)):
+ continue
+ files.append(filename)
+ return files
+
+
+if __name__ == "__main__":
+ path = DEFAULT_WORKSPACE_ROOT / "git"
+ path.mkdir(exist_ok=True, parents=True)
+
+ repo = GitRepository()
+ repo.open(path, auto_init=True)
+ repo.filter_gitignore(filenames=["snake_game/snake_game/__pycache__", "snake_game/snake_game/game.py"])
+
+ changes = repo.changed_files
+ print(changes)
+ repo.add_change(changes)
+ print(repo.status)
+ repo.commit("test")
+ print(repo.status)
+ repo.delete_repository()
diff --git a/metagpt/utils/highlight.py b/metagpt/utils/highlight.py
index e6cbb228c..2e1d6f615 100644
--- a/metagpt/utils/highlight.py
+++ b/metagpt/utils/highlight.py
@@ -1,22 +1,22 @@
# 添加代码语法高亮显示
from pygments import highlight as highlight_
+from pygments.formatters import HtmlFormatter, TerminalFormatter
from pygments.lexers import PythonLexer, SqlLexer
-from pygments.formatters import TerminalFormatter, HtmlFormatter
-def highlight(code: str, language: str = 'python', formatter: str = 'terminal'):
+def highlight(code: str, language: str = "python", formatter: str = "terminal"):
# 指定要高亮的语言
- if language.lower() == 'python':
+ if language.lower() == "python":
lexer = PythonLexer()
- elif language.lower() == 'sql':
+ elif language.lower() == "sql":
lexer = SqlLexer()
else:
raise ValueError(f"Unsupported language: {language}")
# 指定输出格式
- if formatter.lower() == 'terminal':
+ if formatter.lower() == "terminal":
formatter = TerminalFormatter()
- elif formatter.lower() == 'html':
+ elif formatter.lower() == "html":
formatter = HtmlFormatter()
else:
raise ValueError(f"Unsupported formatter: {formatter}")
diff --git a/metagpt/utils/mermaid.py b/metagpt/utils/mermaid.py
index 204c22c67..eb85a3f90 100644
--- a/metagpt/utils/mermaid.py
+++ b/metagpt/utils/mermaid.py
@@ -10,7 +10,7 @@ import os
from pathlib import Path
from metagpt.config import CONFIG
-from metagpt.const import PROJECT_ROOT
+from metagpt.const import METAGPT_ROOT
from metagpt.logs import logger
from metagpt.utils.common import check_cmd_exists
@@ -69,7 +69,7 @@ async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048,
if stdout:
logger.info(stdout.decode())
if stderr:
- logger.error(stderr.decode())
+ logger.warning(stderr.decode())
else:
if engine == "playwright":
from metagpt.utils.mmdc_playwright import mermaid_to_file
@@ -141,6 +141,6 @@ MMC2 = """sequenceDiagram
if __name__ == "__main__":
loop = asyncio.new_event_loop()
- result = loop.run_until_complete(mermaid_to_file(MMC1, PROJECT_ROOT / f"{CONFIG.mermaid_engine}/1"))
- result = loop.run_until_complete(mermaid_to_file(MMC2, PROJECT_ROOT / f"{CONFIG.mermaid_engine}/1"))
+ result = loop.run_until_complete(mermaid_to_file(MMC1, METAGPT_ROOT / f"{CONFIG.mermaid_engine}/1"))
+ result = loop.run_until_complete(mermaid_to_file(MMC2, METAGPT_ROOT / f"{CONFIG.mermaid_engine}/1"))
loop.close()
diff --git a/metagpt/utils/mmdc_ink.py b/metagpt/utils/mmdc_ink.py
index 3d91cde9d..d594adb30 100644
--- a/metagpt/utils/mmdc_ink.py
+++ b/metagpt/utils/mmdc_ink.py
@@ -6,9 +6,9 @@
@File : mermaid.py
"""
import base64
-import os
-from aiohttp import ClientSession,ClientError
+from aiohttp import ClientError, ClientSession
+
from metagpt.logs import logger
@@ -29,7 +29,7 @@ async def mermaid_to_file(mermaid_code, output_file_without_suffix):
async with session.get(url) as response:
if response.status == 200:
text = await response.content.read()
- with open(output_file, 'wb') as f:
+ with open(output_file, "wb") as f:
f.write(text)
logger.info(f"Generating {output_file}..")
else:
diff --git a/metagpt/utils/mmdc_playwright.py b/metagpt/utils/mmdc_playwright.py
index bdbfd82ff..5d455e1c5 100644
--- a/metagpt/utils/mmdc_playwright.py
+++ b/metagpt/utils/mmdc_playwright.py
@@ -8,10 +8,13 @@
import os
from urllib.parse import urljoin
+
from playwright.async_api import async_playwright
+
from metagpt.logs import logger
-async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048, height=2048)-> int:
+
+async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048, height=2048) -> int:
"""
Converts the given Mermaid code to various output formats and saves them to files.
@@ -24,66 +27,72 @@ async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048,
Returns:
int: Returns 1 if the conversion and saving were successful, -1 otherwise.
"""
- suffixes=['png', 'svg', 'pdf']
+ suffixes = ["png", "svg", "pdf"]
__dirname = os.path.dirname(os.path.abspath(__file__))
async with async_playwright() as p:
browser = await p.chromium.launch()
device_scale_factor = 1.0
context = await browser.new_context(
- viewport={'width': width, 'height': height},
- device_scale_factor=device_scale_factor,
- )
+ viewport={"width": width, "height": height},
+ device_scale_factor=device_scale_factor,
+ )
page = await context.new_page()
async def console_message(msg):
logger.info(msg.text)
- page.on('console', console_message)
+
+ page.on("console", console_message)
try:
- await page.set_viewport_size({'width': width, 'height': height})
+ await page.set_viewport_size({"width": width, "height": height})
- mermaid_html_path = os.path.abspath(
- os.path.join(__dirname, 'index.html'))
- mermaid_html_url = urljoin('file:', mermaid_html_path)
+ mermaid_html_path = os.path.abspath(os.path.join(__dirname, "index.html"))
+ mermaid_html_url = urljoin("file:", mermaid_html_path)
await page.goto(mermaid_html_url)
await page.wait_for_load_state("networkidle")
await page.wait_for_selector("div#container", state="attached")
- mermaid_config = {}
+ # mermaid_config = {}
background_color = "#ffffff"
- my_css = ""
+ # my_css = ""
await page.evaluate(f'document.body.style.background = "{background_color}";')
- metadata = await page.evaluate('''async ([definition, mermaidConfig, myCSS, backgroundColor]) => {
- const { mermaid, zenuml } = globalThis;
- await mermaid.registerExternalDiagrams([zenuml]);
- mermaid.initialize({ startOnLoad: false, ...mermaidConfig });
- const { svg } = await mermaid.render('my-svg', definition, document.getElementById('container'));
- document.getElementById('container').innerHTML = svg;
- const svgElement = document.querySelector('svg');
- svgElement.style.backgroundColor = backgroundColor;
+ # metadata = await page.evaluate(
+ # """async ([definition, mermaidConfig, myCSS, backgroundColor]) => {
+ # const { mermaid, zenuml } = globalThis;
+ # await mermaid.registerExternalDiagrams([zenuml]);
+ # mermaid.initialize({ startOnLoad: false, ...mermaidConfig });
+ # const { svg } = await mermaid.render('my-svg', definition, document.getElementById('container'));
+ # document.getElementById('container').innerHTML = svg;
+ # const svgElement = document.querySelector('svg');
+ # svgElement.style.backgroundColor = backgroundColor;
+ #
+ # if (myCSS) {
+ # const style = document.createElementNS('http://www.w3.org/2000/svg', 'style');
+ # style.appendChild(document.createTextNode(myCSS));
+ # svgElement.appendChild(style);
+ # }
+ #
+ # }""",
+ # [mermaid_code, mermaid_config, my_css, background_color],
+ # )
- if (myCSS) {
- const style = document.createElementNS('http://www.w3.org/2000/svg', 'style');
- style.appendChild(document.createTextNode(myCSS));
- svgElement.appendChild(style);
- }
-
- }''', [mermaid_code, mermaid_config, my_css, background_color])
-
- if 'svg' in suffixes :
- svg_xml = await page.evaluate('''() => {
+ if "svg" in suffixes:
+ svg_xml = await page.evaluate(
+ """() => {
const svg = document.querySelector('svg');
const xmlSerializer = new XMLSerializer();
return xmlSerializer.serializeToString(svg);
- }''')
+ }"""
+ )
logger.info(f"Generating {output_file_without_suffix}.svg..")
- with open(f'{output_file_without_suffix}.svg', 'wb') as f:
- f.write(svg_xml.encode('utf-8'))
+ with open(f"{output_file_without_suffix}.svg", "wb") as f:
+ f.write(svg_xml.encode("utf-8"))
- if 'png' in suffixes:
- clip = await page.evaluate('''() => {
+ if "png" in suffixes:
+ clip = await page.evaluate(
+ """() => {
const svg = document.querySelector('svg');
const rect = svg.getBoundingClientRect();
return {
@@ -92,16 +101,17 @@ async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048,
width: Math.ceil(rect.width),
height: Math.ceil(rect.height)
};
- }''')
- await page.set_viewport_size({'width': clip['x'] + clip['width'], 'height': clip['y'] + clip['height']})
- screenshot = await page.screenshot(clip=clip, omit_background=True, scale='device')
+ }"""
+ )
+ await page.set_viewport_size({"width": clip["x"] + clip["width"], "height": clip["y"] + clip["height"]})
+ screenshot = await page.screenshot(clip=clip, omit_background=True, scale="device")
logger.info(f"Generating {output_file_without_suffix}.png..")
- with open(f'{output_file_without_suffix}.png', 'wb') as f:
+ with open(f"{output_file_without_suffix}.png", "wb") as f:
f.write(screenshot)
- if 'pdf' in suffixes:
+ if "pdf" in suffixes:
pdf_data = await page.pdf(scale=device_scale_factor)
logger.info(f"Generating {output_file_without_suffix}.pdf..")
- with open(f'{output_file_without_suffix}.pdf', 'wb') as f:
+ with open(f"{output_file_without_suffix}.pdf", "wb") as f:
f.write(pdf_data)
return 0
except Exception as e:
diff --git a/metagpt/utils/mmdc_pyppeteer.py b/metagpt/utils/mmdc_pyppeteer.py
index 7ec30fd12..7125cafc5 100644
--- a/metagpt/utils/mmdc_pyppeteer.py
+++ b/metagpt/utils/mmdc_pyppeteer.py
@@ -7,11 +7,14 @@
"""
import os
from urllib.parse import urljoin
-from pyppeteer import launch
-from metagpt.logs import logger
-from metagpt.config import CONFIG
-async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048, height=2048)-> int:
+from pyppeteer import launch
+
+from metagpt.config import CONFIG
+from metagpt.logs import logger
+
+
+async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048, height=2048) -> int:
"""
Converts the given Mermaid code to various output formats and saves them to files.
@@ -24,15 +27,15 @@ async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048,
Returns:
int: Returns 1 if the conversion and saving were successful, -1 otherwise.
"""
- suffixes = ['png', 'svg', 'pdf']
+ suffixes = ["png", "svg", "pdf"]
__dirname = os.path.dirname(os.path.abspath(__file__))
-
if CONFIG.pyppeteer_executable_path:
- browser = await launch(headless=True,
- executablePath=CONFIG.pyppeteer_executable_path,
- args=['--disable-extensions',"--no-sandbox"]
- )
+ browser = await launch(
+ headless=True,
+ executablePath=CONFIG.pyppeteer_executable_path,
+ args=["--disable-extensions", "--no-sandbox"],
+ )
else:
logger.error("Please set the environment variable:PYPPETEER_EXECUTABLE_PATH.")
return -1
@@ -41,50 +44,56 @@ async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048,
async def console_message(msg):
logger.info(msg.text)
- page.on('console', console_message)
+
+ page.on("console", console_message)
try:
- await page.setViewport(viewport={'width': width, 'height': height, 'deviceScaleFactor': device_scale_factor})
+ await page.setViewport(viewport={"width": width, "height": height, "deviceScaleFactor": device_scale_factor})
- mermaid_html_path = os.path.abspath(
- os.path.join(__dirname, 'index.html'))
- mermaid_html_url = urljoin('file:', mermaid_html_path)
+ mermaid_html_path = os.path.abspath(os.path.join(__dirname, "index.html"))
+ mermaid_html_url = urljoin("file:", mermaid_html_path)
await page.goto(mermaid_html_url)
await page.querySelector("div#container")
- mermaid_config = {}
+ # mermaid_config = {}
background_color = "#ffffff"
- my_css = ""
+ # my_css = ""
await page.evaluate(f'document.body.style.background = "{background_color}";')
- metadata = await page.evaluate('''async ([definition, mermaidConfig, myCSS, backgroundColor]) => {
- const { mermaid, zenuml } = globalThis;
- await mermaid.registerExternalDiagrams([zenuml]);
- mermaid.initialize({ startOnLoad: false, ...mermaidConfig });
- const { svg } = await mermaid.render('my-svg', definition, document.getElementById('container'));
- document.getElementById('container').innerHTML = svg;
- const svgElement = document.querySelector('svg');
- svgElement.style.backgroundColor = backgroundColor;
+ # metadata = await page.evaluate(
+ # """async ([definition, mermaidConfig, myCSS, backgroundColor]) => {
+ # const { mermaid, zenuml } = globalThis;
+ # await mermaid.registerExternalDiagrams([zenuml]);
+ # mermaid.initialize({ startOnLoad: false, ...mermaidConfig });
+ # const { svg } = await mermaid.render('my-svg', definition, document.getElementById('container'));
+ # document.getElementById('container').innerHTML = svg;
+ # const svgElement = document.querySelector('svg');
+ # svgElement.style.backgroundColor = backgroundColor;
+ #
+ # if (myCSS) {
+ # const style = document.createElementNS('http://www.w3.org/2000/svg', 'style');
+ # style.appendChild(document.createTextNode(myCSS));
+ # svgElement.appendChild(style);
+ # }
+ # }""",
+ # [mermaid_code, mermaid_config, my_css, background_color],
+ # )
- if (myCSS) {
- const style = document.createElementNS('http://www.w3.org/2000/svg', 'style');
- style.appendChild(document.createTextNode(myCSS));
- svgElement.appendChild(style);
- }
- }''', [mermaid_code, mermaid_config, my_css, background_color])
-
- if 'svg' in suffixes :
- svg_xml = await page.evaluate('''() => {
+ if "svg" in suffixes:
+ svg_xml = await page.evaluate(
+ """() => {
const svg = document.querySelector('svg');
const xmlSerializer = new XMLSerializer();
return xmlSerializer.serializeToString(svg);
- }''')
+ }"""
+ )
logger.info(f"Generating {output_file_without_suffix}.svg..")
- with open(f'{output_file_without_suffix}.svg', 'wb') as f:
- f.write(svg_xml.encode('utf-8'))
+ with open(f"{output_file_without_suffix}.svg", "wb") as f:
+ f.write(svg_xml.encode("utf-8"))
- if 'png' in suffixes:
- clip = await page.evaluate('''() => {
+ if "png" in suffixes:
+ clip = await page.evaluate(
+ """() => {
const svg = document.querySelector('svg');
const rect = svg.getBoundingClientRect();
return {
@@ -93,16 +102,23 @@ async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048,
width: Math.ceil(rect.width),
height: Math.ceil(rect.height)
};
- }''')
- await page.setViewport({'width': clip['x'] + clip['width'], 'height': clip['y'] + clip['height'], 'deviceScaleFactor': device_scale_factor})
- screenshot = await page.screenshot(clip=clip, omit_background=True, scale='device')
+ }"""
+ )
+ await page.setViewport(
+ {
+ "width": clip["x"] + clip["width"],
+ "height": clip["y"] + clip["height"],
+ "deviceScaleFactor": device_scale_factor,
+ }
+ )
+ screenshot = await page.screenshot(clip=clip, omit_background=True, scale="device")
logger.info(f"Generating {output_file_without_suffix}.png..")
- with open(f'{output_file_without_suffix}.png', 'wb') as f:
+ with open(f"{output_file_without_suffix}.png", "wb") as f:
f.write(screenshot)
- if 'pdf' in suffixes:
+ if "pdf" in suffixes:
pdf_data = await page.pdf(scale=device_scale_factor)
logger.info(f"Generating {output_file_without_suffix}.pdf..")
- with open(f'{output_file_without_suffix}.pdf', 'wb') as f:
+ with open(f"{output_file_without_suffix}.pdf", "wb") as f:
f.write(pdf_data)
return 0
except Exception as e:
@@ -110,4 +126,3 @@ async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048,
return -1
finally:
await browser.close()
-
diff --git a/metagpt/utils/parse_html.py b/metagpt/utils/parse_html.py
index 62de26541..f2395026f 100644
--- a/metagpt/utils/parse_html.py
+++ b/metagpt/utils/parse_html.py
@@ -16,7 +16,7 @@ class WebPage(BaseModel):
class Config:
underscore_attrs_are_private = True
- _soup : Optional[BeautifulSoup] = None
+ _soup: Optional[BeautifulSoup] = None
_title: Optional[str] = None
@property
@@ -24,7 +24,7 @@ class WebPage(BaseModel):
if self._soup is None:
self._soup = BeautifulSoup(self.html, "html.parser")
return self._soup
-
+
@property
def title(self):
if self._title is None:
diff --git a/metagpt/utils/pycst.py b/metagpt/utils/pycst.py
index afd85a547..1edfed81c 100644
--- a/metagpt/utils/pycst.py
+++ b/metagpt/utils/pycst.py
@@ -37,12 +37,12 @@ def get_docstring_statement(body: DocstringNode) -> cst.SimpleStatementLine:
if not isinstance(expr, cst.Expr):
return None
-
+
val = expr.value
if not isinstance(val, (cst.SimpleString, cst.ConcatenatedString)):
return None
-
- evaluated_value = val.evaluated_value
+
+ evaluated_value = val.evaluated_value
if isinstance(evaluated_value, bytes):
return None
@@ -56,6 +56,7 @@ class DocstringCollector(cst.CSTVisitor):
stack: A list to keep track of the current path in the CST.
docstrings: A dictionary mapping paths in the CST to their corresponding docstrings.
"""
+
def __init__(self):
self.stack: list[str] = []
self.docstrings: dict[tuple[str, ...], cst.SimpleStatementLine] = {}
@@ -96,6 +97,7 @@ class DocstringTransformer(cst.CSTTransformer):
stack: A list to keep track of the current path in the CST.
docstrings: A dictionary mapping paths in the CST to their corresponding docstrings.
"""
+
def __init__(
self,
docstrings: dict[tuple[str, ...], cst.SimpleStatementLine],
@@ -125,7 +127,9 @@ class DocstringTransformer(cst.CSTTransformer):
key = tuple(self.stack)
self.stack.pop()
- if hasattr(updated_node, "decorators") and any((i.decorator.value == "overload") for i in updated_node.decorators):
+ if hasattr(updated_node, "decorators") and any(
+ (i.decorator.value == "overload") for i in updated_node.decorators
+ ):
return updated_node
statement = self.docstrings.get(key)
diff --git a/metagpt/utils/read_document.py b/metagpt/utils/read_document.py
index c837baf25..d2fafbc17 100644
--- a/metagpt/utils/read_document.py
+++ b/metagpt/utils/read_document.py
@@ -8,6 +8,7 @@
import docx
+
def read_docx(file_path: str) -> list:
"""Open a docx file"""
doc = docx.Document(file_path)
diff --git a/metagpt/utils/repair_llm_raw_output.py b/metagpt/utils/repair_llm_raw_output.py
new file mode 100644
index 000000000..67ad4e963
--- /dev/null
+++ b/metagpt/utils/repair_llm_raw_output.py
@@ -0,0 +1,310 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+# @Desc : repair llm raw output with particular conditions
+
+import copy
+from enum import Enum
+from typing import Callable, Union
+
+import regex as re
+from tenacity import RetryCallState, retry, stop_after_attempt, wait_fixed
+
+from metagpt.config import CONFIG
+from metagpt.logs import logger
+from metagpt.utils.custom_decoder import CustomDecoder
+
+
+class RepairType(Enum):
+ CS = "case sensitivity"
+ RKPM = "required key pair missing" # condition like `[key] xx` which lacks `[/key]`
+ SCM = "special character missing" # Usually the req_key appear in pairs like `[key] xx [/key]`
+ JSON = "json format"
+
+
+def repair_case_sensitivity(output: str, req_key: str) -> str:
+ """
+ usually, req_key is the key name of expected json or markdown content, it won't appear in the value part.
+ fix target string `"Shared Knowledge": ""` but `"Shared knowledge": ""` actually
+ """
+ if req_key in output:
+ return output
+
+ output_lower = output.lower()
+ req_key_lower = req_key.lower()
+ if req_key_lower in output_lower:
+ # find the sub-part index, and replace it with raw req_key
+ lidx = output_lower.find(req_key_lower)
+ source = output[lidx : lidx + len(req_key_lower)]
+ output = output.replace(source, req_key)
+ logger.info(f"repair_case_sensitivity: {req_key}")
+
+ return output
+
+
+def repair_special_character_missing(output: str, req_key: str = "[/CONTENT]") -> str:
+ """
+ fix
+ 1. target string `[CONTENT] xx [CONTENT] xxx [CONTENT]` lacks `/` in the last `[CONTENT]`
+ 2. target string `xx [CONTENT] xxx [CONTENT] xxxx` lacks `/` in the last `[CONTENT]`
+ """
+ sc_arr = ["/"]
+
+ if req_key in output:
+ return output
+
+ for sc in sc_arr:
+ req_key_pure = req_key.replace(sc, "")
+ appear_cnt = output.count(req_key_pure)
+ if req_key_pure in output and appear_cnt > 1:
+ # req_key with special_character usually in the tail side
+ ridx = output.rfind(req_key_pure)
+ output = f"{output[:ridx]}{req_key}{output[ridx + len(req_key_pure):]}"
+ logger.info(f"repair_special_character_missing: {sc} in {req_key_pure} as position {ridx}")
+
+ return output
+
+
+def repair_required_key_pair_missing(output: str, req_key: str = "[/CONTENT]") -> str:
+ """
+ implement the req_key pair in the begin or end of the content
+ req_key format
+ 1. `[req_key]`, and its pair `[/req_key]`
+ 2. `[/req_key]`, and its pair `[req_key]`
+ """
+ sc = "/" # special char
+ if req_key.startswith("[") and req_key.endswith("]"):
+ if sc in req_key:
+ left_key = req_key.replace(sc, "") # `[/req_key]` -> `[req_key]`
+ right_key = req_key
+ else:
+ left_key = req_key
+ right_key = f"{req_key[0]}{sc}{req_key[1:]}" # `[req_key]` -> `[/req_key]`
+
+ if left_key not in output:
+ output = left_key + "\n" + output
+ if right_key not in output:
+
+ def judge_potential_json(routput: str, left_key: str) -> Union[str, None]:
+ ridx = routput.rfind(left_key)
+ if ridx < 0:
+ return None
+ sub_output = routput[ridx:]
+ idx1 = sub_output.rfind("}")
+ idx2 = sub_output.rindex("]")
+ idx = idx1 if idx1 >= idx2 else idx2
+ sub_output = sub_output[: idx + 1]
+ return sub_output
+
+ if output.strip().endswith("}") or (output.strip().endswith("]") and not output.strip().endswith(left_key)):
+ # # avoid [req_key]xx[req_key] case to append [/req_key]
+ output = output + "\n" + right_key
+ elif judge_potential_json(output, left_key) and (not output.strip().endswith(left_key)):
+ sub_content = judge_potential_json(output, left_key)
+ output = sub_content + "\n" + right_key
+
+ return output
+
+
+def repair_json_format(output: str) -> str:
+ """
+ fix extra `[` or `}` in the end
+ """
+ output = output.strip()
+
+ if output.startswith("[{"):
+ output = output[1:]
+ logger.info(f"repair_json_format: {'[{'}")
+ elif output.endswith("}]"):
+ output = output[:-1]
+ logger.info(f"repair_json_format: {'}]'}")
+ elif output.startswith("{") and output.endswith("]"):
+ output = output[:-1] + "}"
+
+ return output
+
+
+def _repair_llm_raw_output(output: str, req_key: str, repair_type: RepairType = None) -> str:
+ repair_types = [repair_type] if repair_type else [item for item in RepairType if item not in [RepairType.JSON]]
+ for repair_type in repair_types:
+ if repair_type == RepairType.CS:
+ output = repair_case_sensitivity(output, req_key)
+ elif repair_type == RepairType.RKPM:
+ output = repair_required_key_pair_missing(output, req_key)
+ elif repair_type == RepairType.SCM:
+ output = repair_special_character_missing(output, req_key)
+ elif repair_type == RepairType.JSON:
+ output = repair_json_format(output)
+ return output
+
+
+def repair_llm_raw_output(output: str, req_keys: list[str], repair_type: RepairType = None) -> str:
+ """
+ in open-source llm model, it usually can't follow the instruction well, the output may be incomplete,
+ so here we try to repair it and use all repair methods by default.
+ typical case
+ 1. case sensitivity
+ target: "Original Requirements"
+ output: "Original requirements"
+ 2. special character missing
+ target: [/CONTENT]
+ output: [CONTENT]
+ 3. json format
+ target: { xxx }
+ output: { xxx }]
+ """
+ if not CONFIG.repair_llm_output:
+ return output
+
+ # do the repairation usually for non-openai models
+ for req_key in req_keys:
+ output = _repair_llm_raw_output(output=output, req_key=req_key, repair_type=repair_type)
+ return output
+
+
+def repair_invalid_json(output: str, error: str) -> str:
+ """
+ repair the situation like there are extra chars like
+ error examples
+ example 1. json.decoder.JSONDecodeError: Expecting ',' delimiter: line 154 column 1 (char 2765)
+ example 2. xxx.JSONDecodeError: Expecting property name enclosed in double quotes: line 14 column 1 (char 266)
+ """
+ pattern = r"line ([0-9]+)"
+
+ matches = re.findall(pattern, error, re.DOTALL)
+ if len(matches) > 0:
+ line_no = int(matches[0]) - 1
+
+ # due to CustomDecoder can handle `"": ''` or `'': ""`, so convert `"""` -> `"`, `'''` -> `'`
+ output = output.replace('"""', '"').replace("'''", '"')
+ arr = output.split("\n")
+ line = arr[line_no].strip()
+ # different general problems
+ if line.endswith("],"):
+ # problem, redundant char `]`
+ new_line = line.replace("]", "")
+ elif line.endswith("},") and not output.endswith("},"):
+ # problem, redundant char `}`
+ new_line = line.replace("}", "")
+ elif line.endswith("},") and output.endswith("},"):
+ new_line = line[:-1]
+ elif '",' not in line and "," not in line:
+ new_line = f'{line}",'
+ elif "," not in line:
+ # problem, miss char `,` at the end.
+ new_line = f"{line},"
+ elif "," in line and len(line) == 1:
+ new_line = f'"{line}'
+ elif '",' in line:
+ new_line = line[:-2] + "',"
+
+ arr[line_no] = new_line
+ output = "\n".join(arr)
+ logger.info(f"repair_invalid_json, raw error: {error}")
+
+ return output
+
+
+def run_after_exp_and_passon_next_retry(logger: "loguru.Logger") -> Callable[["RetryCallState"], None]:
+ def run_and_passon(retry_state: RetryCallState) -> None:
+ """
+ RetryCallState example
+ {
+ "start_time":143.098322024,
+ "retry_object":")>",
+ "fn":"",
+ "args":"(\"tag:[/CONTENT]\",)", # function input args
+ "kwargs":{}, # function input kwargs
+ "attempt_number":1, # retry number
+ "outcome":"", # type(outcome.result()) = "str", type(outcome.exception()) = "class"
+ "outcome_timestamp":143.098416904,
+ "idle_for":0,
+ "next_action":"None"
+ }
+ """
+ if retry_state.outcome.failed:
+ if retry_state.args:
+ # # can't be used as args=retry_state.args
+ func_param_output = retry_state.args[0]
+ elif retry_state.kwargs:
+ func_param_output = retry_state.kwargs.get("output", "")
+ exp_str = str(retry_state.outcome.exception())
+ logger.warning(
+ f"parse json from content inside [CONTENT][/CONTENT] failed at retry "
+ f"{retry_state.attempt_number}, try to fix it, exp: {exp_str}"
+ )
+
+ repaired_output = repair_invalid_json(func_param_output, exp_str)
+ retry_state.kwargs["output"] = repaired_output
+
+ return run_and_passon
+
+
+@retry(
+ stop=stop_after_attempt(3 if CONFIG.repair_llm_output else 0),
+ wait=wait_fixed(1),
+ after=run_after_exp_and_passon_next_retry(logger),
+)
+def retry_parse_json_text(output: str) -> Union[list, dict]:
+ """
+ repair the json-text situation like there are extra chars like [']', '}']
+
+ Warning
+ if CONFIG.repair_llm_output is False, retry _aask_v1 {x=3} times, and the retry_parse_json_text's retry not work
+ if CONFIG.repair_llm_output is True, the _aask_v1 and the retry_parse_json_text will loop for {x=3*3} times.
+ it's a two-layer retry cycle
+ """
+ # logger.debug(f"output to json decode:\n{output}")
+
+ # if CONFIG.repair_llm_output is True, it will try to fix output until the retry break
+ parsed_data = CustomDecoder(strict=False).decode(output)
+
+ return parsed_data
+
+
+def extract_content_from_output(content: str, right_key: str = "[/CONTENT]"):
+ """extract xxx from [CONTENT](xxx)[/CONTENT] using regex pattern"""
+
+ def re_extract_content(cont: str, pattern: str) -> str:
+ matches = re.findall(pattern, cont, re.DOTALL)
+ for match in matches:
+ if match:
+ cont = match
+ break
+ return cont.strip()
+
+ # TODO construct the extract pattern with the `right_key`
+ raw_content = copy.deepcopy(content)
+ pattern = r"\[CONTENT\]([\s\S]*)\[/CONTENT\]"
+ new_content = re_extract_content(raw_content, pattern)
+
+ if not new_content.startswith("{"):
+ # TODO find a more general pattern
+ # # for `[CONTENT]xxx[CONTENT]xxxx[/CONTENT] situation
+ logger.warning(f"extract_content try another pattern: {pattern}")
+ if right_key not in new_content:
+ raw_content = copy.deepcopy(new_content + "\n" + right_key)
+ # # pattern = r"\[CONTENT\](\s*\{.*?\}\s*)\[/CONTENT\]"
+ new_content = re_extract_content(raw_content, pattern)
+ else:
+ if right_key in new_content:
+ idx = new_content.find(right_key)
+ new_content = new_content[:idx]
+ new_content = new_content.strip()
+
+ return new_content
+
+
+def extract_state_value_from_output(content: str) -> str:
+ """
+ For openai models, they will always return state number. But for open llm models, the instruction result maybe a
+ long text contain target number, so here add a extraction to improve success rate.
+
+ Args:
+ content (str): llm's output from `Role._think`
+ """
+ content = content.strip() # deal the output cases like " 0", "0\n" and so on.
+ pattern = r"([0-9])" # TODO find the number using a more proper method not just extract from content using pattern
+ matches = re.findall(pattern, content, re.DOTALL)
+ matches = list(set(matches))
+ state = matches[0] if len(matches) > 0 else "-1"
+ return state
diff --git a/metagpt/utils/serialize.py b/metagpt/utils/serialize.py
index 124176fcb..3939b1306 100644
--- a/metagpt/utils/serialize.py
+++ b/metagpt/utils/serialize.py
@@ -4,13 +4,11 @@
import copy
import pickle
-from typing import Dict, List
-from metagpt.actions.action_output import ActionOutput
-from metagpt.schema import Message
+from metagpt.utils.common import import_class
-def actionoutout_schema_to_mapping(schema: Dict) -> Dict:
+def actionoutout_schema_to_mapping(schema: dict) -> dict:
"""
directly traverse the `properties` in the first level.
schema structure likes
@@ -35,14 +33,31 @@ def actionoutout_schema_to_mapping(schema: Dict) -> Dict:
if property["type"] == "string":
mapping[field] = (str, ...)
elif property["type"] == "array" and property["items"]["type"] == "string":
- mapping[field] = (List[str], ...)
+ mapping[field] = (list[str], ...)
elif property["type"] == "array" and property["items"]["type"] == "array":
- # here only consider the `List[List[str]]` situation
- mapping[field] = (List[List[str]], ...)
+ # here only consider the `list[list[str]]` situation
+ mapping[field] = (list[list[str]], ...)
return mapping
-def serialize_message(message: Message):
+def actionoutput_mapping_to_str(mapping: dict) -> dict:
+ new_mapping = {}
+ for key, value in mapping.items():
+ new_mapping[key] = str(value)
+ return new_mapping
+
+
+def actionoutput_str_to_mapping(mapping: dict) -> dict:
+ new_mapping = {}
+ for key, value in mapping.items():
+ if value == "(, Ellipsis)":
+ new_mapping[key] = (str, ...)
+ else:
+ new_mapping[key] = eval(value) # `"'(list[str], Ellipsis)"` to `(list[str], ...)`
+ return new_mapping
+
+
+def serialize_message(message: "Message"):
message_cp = copy.deepcopy(message) # avoid `instruct_content` value update by reference
ic = message_cp.instruct_content
if ic:
@@ -56,11 +71,12 @@ def serialize_message(message: Message):
return msg_ser
-def deserialize_message(message_ser: str) -> Message:
+def deserialize_message(message_ser: str) -> "Message":
message = pickle.loads(message_ser)
if message.instruct_content:
ic = message.instruct_content
- ic_obj = ActionOutput.create_model_class(class_name=ic["class"], mapping=ic["mapping"])
+ actionnode_class = import_class("ActionNode", "metagpt.actions.action_node") # avoid circular import
+ ic_obj = actionnode_class.create_model_class(class_name=ic["class"], mapping=ic["mapping"])
ic_new = ic_obj(**ic["value"])
message.instruct_content = ic_new
diff --git a/metagpt/utils/singleton.py b/metagpt/utils/singleton.py
index 474b537db..a9e0862c0 100644
--- a/metagpt/utils/singleton.py
+++ b/metagpt/utils/singleton.py
@@ -20,4 +20,3 @@ class Singleton(abc.ABCMeta, type):
if cls not in cls._instances:
cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)
return cls._instances[cls]
-
\ No newline at end of file
diff --git a/metagpt/utils/special_tokens.py b/metagpt/utils/special_tokens.py
index 2adb93c77..5e780ce05 100644
--- a/metagpt/utils/special_tokens.py
+++ b/metagpt/utils/special_tokens.py
@@ -1,4 +1,4 @@
# token to separate different code messages in a WriteCode Message content
-MSG_SEP = "#*000*#"
+MSG_SEP = "#*000*#"
# token to seperate file name and the actual code text in a code message
FILENAME_CODE_SEP = "#*001*#"
diff --git a/metagpt/utils/text.py b/metagpt/utils/text.py
index be3c52edd..dd9678438 100644
--- a/metagpt/utils/text.py
+++ b/metagpt/utils/text.py
@@ -3,7 +3,12 @@ from typing import Generator, Sequence
from metagpt.utils.token_counter import TOKEN_MAX, count_string_tokens
-def reduce_message_length(msgs: Generator[str, None, None], model_name: str, system_text: str, reserved: int = 0,) -> str:
+def reduce_message_length(
+ msgs: Generator[str, None, None],
+ model_name: str,
+ system_text: str,
+ reserved: int = 0,
+) -> str:
"""Reduce the length of concatenated message segments to fit within the maximum token size.
Args:
@@ -49,9 +54,9 @@ def generate_prompt_chunk(
current_token = 0
current_lines = []
- reserved = reserved + count_string_tokens(prompt_template+system_text, model_name)
+ reserved = reserved + count_string_tokens(prompt_template + system_text, model_name)
# 100 is a magic number to ensure the maximum context length is not exceeded
- max_token = TOKEN_MAX.get(model_name, 2048) - reserved - 100
+ max_token = TOKEN_MAX.get(model_name, 2048) - reserved - 100
while paragraphs:
paragraph = paragraphs.pop(0)
@@ -103,7 +108,7 @@ def decode_unicode_escape(text: str) -> str:
return text.encode("utf-8").decode("unicode_escape", "ignore")
-def _split_by_count(lst: Sequence , count: int):
+def _split_by_count(lst: Sequence, count: int):
avg = len(lst) // count
remainder = len(lst) % count
start = 0
diff --git a/metagpt/utils/token_counter.py b/metagpt/utils/token_counter.py
index 21de43501..af49845be 100644
--- a/metagpt/utils/token_counter.py
+++ b/metagpt/utils/token_counter.py
@@ -18,11 +18,13 @@ TOKEN_COSTS = {
"gpt-3.5-turbo-16k-0613": {"prompt": 0.003, "completion": 0.004},
"gpt-35-turbo": {"prompt": 0.0015, "completion": 0.002},
"gpt-35-turbo-16k": {"prompt": 0.003, "completion": 0.004},
+ "gpt-3.5-turbo-1106": {"prompt": 0.001, "completion": 0.002},
"gpt-4-0314": {"prompt": 0.03, "completion": 0.06},
"gpt-4": {"prompt": 0.03, "completion": 0.06},
"gpt-4-32k": {"prompt": 0.06, "completion": 0.12},
"gpt-4-32k-0314": {"prompt": 0.06, "completion": 0.12},
"gpt-4-0613": {"prompt": 0.06, "completion": 0.12},
+ "gpt-4-1106-preview": {"prompt": 0.01, "completion": 0.03},
"text-embedding-ada-002": {"prompt": 0.0004, "completion": 0.0},
"chatglm_turbo": {"prompt": 0.0, "completion": 0.00069}, # 32k version, prompt + completion tokens=0.005¥/k-tokens
}
@@ -36,11 +38,13 @@ TOKEN_MAX = {
"gpt-3.5-turbo-16k-0613": 16384,
"gpt-35-turbo": 4096,
"gpt-35-turbo-16k": 16384,
+ "gpt-3.5-turbo-1106": 16384,
"gpt-4-0314": 8192,
"gpt-4": 8192,
"gpt-4-32k": 32768,
"gpt-4-32k-0314": 32768,
"gpt-4-0613": 8192,
+ "gpt-4-1106-preview": 128000,
"text-embedding-ada-002": 8192,
"chatglm_turbo": 32768,
}
@@ -58,20 +62,23 @@ def count_message_tokens(messages, model="gpt-3.5-turbo-0613"):
"gpt-3.5-turbo-16k-0613",
"gpt-35-turbo",
"gpt-35-turbo-16k",
+ "gpt-3.5-turbo-16k",
+ "gpt-3.5-turbo-1106",
"gpt-4-0314",
"gpt-4-32k-0314",
"gpt-4-0613",
"gpt-4-32k-0613",
+ "gpt-4-1106-preview",
}:
- tokens_per_message = 3
+ tokens_per_message = 3 # # every reply is primed with <|start|>assistant<|message|>
tokens_per_name = 1
elif model == "gpt-3.5-turbo-0301":
tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n
tokens_per_name = -1 # if there's a name, the role is omitted
- elif "gpt-3.5-turbo" in model:
+ elif "gpt-3.5-turbo" == model:
print("Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0613.")
return count_message_tokens(messages, model="gpt-3.5-turbo-0613")
- elif "gpt-4" in model:
+ elif "gpt-4" == model:
print("Warning: gpt-4 may update over time. Returning num tokens assuming gpt-4-0613.")
return count_message_tokens(messages, model="gpt-4-0613")
else:
diff --git a/requirements-ocr.txt b/requirements-ocr.txt
deleted file mode 100644
index cf6103afc..000000000
--- a/requirements-ocr.txt
+++ /dev/null
@@ -1,4 +0,0 @@
-paddlepaddle==2.4.2
-paddleocr>=2.0.1
-tabulate==0.9.0
--r requirements.txt
diff --git a/requirements.txt b/requirements.txt
index fd7a31607..0e8e3650b 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -7,6 +7,7 @@ channels==4.0.0
#faiss==1.5.3
faiss_cpu==1.7.4
fire==0.4.0
+typer
# godot==0.1.1
# google_api_python_client==2.93.0
lancedb==0.1.16
@@ -44,4 +45,7 @@ ta==0.10.2
semantic-kernel==0.4.0.dev0
wrapt==1.15.0
websocket-client==0.58.0
+aiofiles==23.2.1
+gitpython==3.1.40
zhipuai==1.0.7
+gitignore-parser==0.1.9
diff --git a/ruff.toml b/ruff.toml
index 7835865e0..21de5ee14 100644
--- a/ruff.toml
+++ b/ruff.toml
@@ -31,7 +31,7 @@ exclude = [
]
# Same as Black.
-line-length = 119
+line-length = 120
# Allow unused variables when underscore-prefixed.
dummy-variable-rgx = "^(_+|(_+[a-zA-Z0-9_]*[a-zA-Z0-9]+?))$"
diff --git a/setup.py b/setup.py
index 239156ae3..8ef2a6946 100644
--- a/setup.py
+++ b/setup.py
@@ -30,15 +30,15 @@ with open(path.join(here, "requirements.txt"), encoding="utf-8") as f:
setup(
name="metagpt",
- version="0.3.0",
- description="The Multi-Role Meta Programming Framework",
+ version="0.5.2",
+ description="The Multi-Agent Framework",
long_description=long_description,
long_description_content_type="text/markdown",
url="https://github.com/geekan/MetaGPT",
author="Alexander Wu",
- author_email="alexanderwu@fuzhi.ai",
- license="Apache 2.0",
- keywords="metagpt multi-role multi-agent programming gpt llm",
+ author_email="alexanderwu@deepwisdom.ai",
+ license="MIT",
+ keywords="metagpt multi-agent multi-role programming gpt llm metaprogramming",
packages=find_packages(exclude=["contrib", "docs", "examples", "tests*"]),
python_requires=">=3.9",
install_requires=requirements,
@@ -48,8 +48,14 @@ setup(
"search-google": ["google-api-python-client==2.94.0"],
"search-ddg": ["duckduckgo-search==3.8.5"],
"pyppeteer": ["pyppeteer>=1.0.2"],
+ "ocr": ["paddlepaddle==2.4.2", "paddleocr>=2.0.1", "tabulate==0.9.0"],
},
cmdclass={
"install_mermaid": InstallMermaidCLI,
},
+ entry_points={
+ "console_scripts": [
+ "metagpt=metagpt.startup:app",
+ ],
+ },
)
diff --git a/startup.py b/startup.py
deleted file mode 100644
index e9fbf94d3..000000000
--- a/startup.py
+++ /dev/null
@@ -1,72 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8 -*-
-import asyncio
-
-import fire
-
-from metagpt.roles import (
- Architect,
- Engineer,
- ProductManager,
- ProjectManager,
- QaEngineer,
-)
-from metagpt.team import Team
-
-
-async def startup(
- idea: str,
- investment: float = 3.0,
- n_round: int = 5,
- code_review: bool = False,
- run_tests: bool = False,
- implement: bool = True,
-):
- """Run a startup. Be a boss."""
- company = Team()
- company.hire(
- [
- ProductManager(),
- Architect(),
- ProjectManager(),
- ]
- )
-
- # if implement or code_review
- if implement or code_review:
- # developing features: implement the idea
- company.hire([Engineer(n_borg=5, use_code_review=code_review)])
-
- if run_tests:
- # developing features: run tests on the spot and identify bugs
- # (bug fixing capability comes soon!)
- company.hire([QaEngineer()])
-
- company.invest(investment)
- company.start_project(idea)
- await company.run(n_round=n_round)
-
-
-def main(
- idea: str,
- investment: float = 3.0,
- n_round: int = 5,
- code_review: bool = True,
- run_tests: bool = False,
- implement: bool = True,
-):
- """
- We are a software startup comprised of AI. By investing in us,
- you are empowering a future filled with limitless possibilities.
- :param idea: Your innovative idea, such as "Creating a snake game."
- :param investment: As an investor, you have the opportunity to contribute
- a certain dollar amount to this AI company.
- :param n_round:
- :param code_review: Whether to use code review.
- :return:
- """
- asyncio.run(startup(idea, investment, n_round, code_review, run_tests, implement))
-
-
-if __name__ == "__main__":
- fire.Fire(main)
diff --git a/tests/conftest.py b/tests/conftest.py
index feecc7715..b22e43e79 100644
--- a/tests/conftest.py
+++ b/tests/conftest.py
@@ -6,14 +6,18 @@
@File : conftest.py
"""
+import asyncio
+import logging
+import re
from unittest.mock import Mock
import pytest
+from metagpt.config import CONFIG
+from metagpt.const import DEFAULT_WORKSPACE_ROOT
from metagpt.logs import logger
from metagpt.provider.openai_api import OpenAIGPTAPI as GPTAPI
-import asyncio
-import re
+from metagpt.utils.git_repository import GitRepository
class Context:
@@ -68,3 +72,27 @@ def proxy():
server = asyncio.get_event_loop().run_until_complete(asyncio.start_server(handle_client, "127.0.0.1", 0))
return "http://{}:{}".format(*server.sockets[0].getsockname())
+
+
+# see https://github.com/Delgan/loguru/issues/59#issuecomment-466591978
+@pytest.fixture
+def loguru_caplog(caplog):
+ class PropogateHandler(logging.Handler):
+ def emit(self, record):
+ logging.getLogger(record.name).handle(record)
+
+ logger.add(PropogateHandler(), format="{message}")
+ yield caplog
+
+
+# init & dispose git repo
+@pytest.fixture(scope="session", autouse=True)
+def setup_and_teardown_git_repo(request):
+ CONFIG.git_repo = GitRepository(local_path=DEFAULT_WORKSPACE_ROOT / "unittest")
+
+ # Destroy git repo at the end of the test session.
+ def fin():
+ CONFIG.git_repo.delete_repository()
+
+ # Register the function for destroying the environment.
+ request.addfinalizer(fin)
diff --git a/tests/metagpt/actions/mock.py b/tests/metagpt/actions/mock.py
index a800690e8..f6602a82b 100644
--- a/tests/metagpt/actions/mock.py
+++ b/tests/metagpt/actions/mock.py
@@ -90,7 +90,7 @@ Python's in-built data structures like lists and dictionaries will be used exten
For testing, we can use the PyTest framework. This is a mature full-featured Python testing tool that helps you write better programs.
-## Python package name:
+## Project Name:
```python
"adventure_game"
```
@@ -100,7 +100,7 @@ For testing, we can use the PyTest framework. This is a mature full-featured Pyt
file_list = ["main.py", "room.py", "player.py", "game.py", "object.py", "puzzle.py", "test_game.py"]
```
-## Data structures and interface definitions:
+## Data structures and interfaces:
```mermaid
classDiagram
class Room{
@@ -209,7 +209,7 @@ Shared knowledge for this project includes understanding the basic principles of
"""
```
-## Anything UNCLEAR: Provide as Plain text. Make clear here. For example, don't forget a main entry. don't forget to init 3rd party libs.
+## Anything UNCLEAR: Provide as Plain text. Try to clarify it. For example, don't forget a main entry. don't forget to init 3rd party libs.
```python
"""
The original requirements did not specify whether the game should have a save/load feature, multiplayer support, or any specific graphical user interface. More information on these aspects could help in further refining the product design and requirements.
@@ -311,12 +311,10 @@ TASKS = [
"添加数据API:接受用户输入的文档库,对文档库进行索引\n- 使用MeiliSearch连接并添加文档库",
"搜索API:接收用户输入的关键词,返回相关的搜索结果\n- 使用MeiliSearch连接并使用接口获得对应数据",
"多条件筛选API:接收用户选择的筛选条件,返回符合条件的搜索结果。\n- 使用MeiliSearch进行筛选并返回符合条件的搜索结果",
- "智能推荐API:根据用户的搜索历史记录和搜索行为,推荐相关的搜索结果。"
+ "智能推荐API:根据用户的搜索历史记录和搜索行为,推荐相关的搜索结果。",
]
-TASKS_2 = [
- "完成main.py的功能"
-]
+TASKS_2 = ["完成main.py的功能"]
SEARCH_CODE_SAMPLE = """
import requests
@@ -460,7 +458,7 @@ if __name__ == '__main__':
print('No results found.')
'''
-MEILI_CODE = '''import meilisearch
+MEILI_CODE = """import meilisearch
from typing import List
@@ -496,9 +494,9 @@ if __name__ == '__main__':
# 添加文档库到搜索引擎
search_engine.add_documents(books_data_source, documents)
-'''
+"""
-MEILI_ERROR = '''/usr/local/bin/python3.9 /Users/alexanderwu/git/metagpt/examples/search/meilisearch_index.py
+MEILI_ERROR = """/usr/local/bin/python3.9 /Users/alexanderwu/git/metagpt/examples/search/meilisearch_index.py
Traceback (most recent call last):
File "/Users/alexanderwu/git/metagpt/examples/search/meilisearch_index.py", line 44, in
search_engine.add_documents(books_data_source, documents)
@@ -506,7 +504,7 @@ Traceback (most recent call last):
index = self.client.get_or_create_index(index_name)
AttributeError: 'Client' object has no attribute 'get_or_create_index'
-Process finished with exit code 1'''
+Process finished with exit code 1"""
MEILI_CODE_REFINED = """
"""
diff --git a/tests/metagpt/actions/test_action_output.py b/tests/metagpt/actions/test_action_output.py
index a556789db..f1765cb03 100644
--- a/tests/metagpt/actions/test_action_output.py
+++ b/tests/metagpt/actions/test_action_output.py
@@ -7,20 +7,23 @@
"""
from typing import List, Tuple
-from metagpt.actions import ActionOutput
+from metagpt.actions.action_node import ActionNode
-t_dict = {"Required Python third-party packages": "\"\"\"\nflask==1.1.2\npygame==2.0.1\n\"\"\"\n",
- "Required Other language third-party packages": "\"\"\"\nNo third-party packages required for other languages.\n\"\"\"\n",
- "Full API spec": "\"\"\"\nopenapi: 3.0.0\ninfo:\n title: Web Snake Game API\n version: 1.0.0\npaths:\n /game:\n get:\n summary: Get the current game state\n responses:\n '200':\n description: A JSON object of the game state\n post:\n summary: Send a command to the game\n requestBody:\n required: true\n content:\n application/json:\n schema:\n type: object\n properties:\n command:\n type: string\n responses:\n '200':\n description: A JSON object of the updated game state\n\"\"\"\n",
- "Logic Analysis": [
- ["app.py", "Main entry point for the Flask application. Handles HTTP requests and responses."],
- ["game.py", "Contains the Game and Snake classes. Handles the game logic."],
- ["static/js/script.js", "Handles user interactions and updates the game UI."],
- ["static/css/styles.css", "Defines the styles for the game UI."],
- ["templates/index.html", "The main page of the web application. Displays the game UI."]],
- "Task list": ["game.py", "app.py", "static/css/styles.css", "static/js/script.js", "templates/index.html"],
- "Shared Knowledge": "\"\"\"\n'game.py' contains the Game and Snake classes which are responsible for the game logic. The Game class uses an instance of the Snake class.\n\n'app.py' is the main entry point for the Flask application. It creates an instance of the Game class and handles HTTP requests and responses.\n\n'static/js/script.js' is responsible for handling user interactions and updating the game UI based on the game state returned by 'app.py'.\n\n'static/css/styles.css' defines the styles for the game UI.\n\n'templates/index.html' is the main page of the web application. It displays the game UI and loads 'static/js/script.js' and 'static/css/styles.css'.\n\"\"\"\n",
- "Anything UNCLEAR": "We need clarification on how the high score should be stored. Should it persist across sessions (stored in a database or a file) or should it reset every time the game is restarted? Also, should the game speed increase as the snake grows, or should it remain constant throughout the game?"}
+t_dict = {
+ "Required Python third-party packages": '"""\nflask==1.1.2\npygame==2.0.1\n"""\n',
+ "Required Other language third-party packages": '"""\nNo third-party packages required for other languages.\n"""\n',
+ "Full API spec": '"""\nopenapi: 3.0.0\ninfo:\n title: Web Snake Game API\n version: 1.0.0\npaths:\n /game:\n get:\n summary: Get the current game state\n responses:\n \'200\':\n description: A JSON object of the game state\n post:\n summary: Send a command to the game\n requestBody:\n required: true\n content:\n application/json:\n schema:\n type: object\n properties:\n command:\n type: string\n responses:\n \'200\':\n description: A JSON object of the updated game state\n"""\n',
+ "Logic Analysis": [
+ ["app.py", "Main entry point for the Flask application. Handles HTTP requests and responses."],
+ ["game.py", "Contains the Game and Snake classes. Handles the game logic."],
+ ["static/js/script.js", "Handles user interactions and updates the game UI."],
+ ["static/css/styles.css", "Defines the styles for the game UI."],
+ ["templates/index.html", "The main page of the web application. Displays the game UI."],
+ ],
+ "Task list": ["game.py", "app.py", "static/css/styles.css", "static/js/script.js", "templates/index.html"],
+ "Shared Knowledge": "\"\"\"\n'game.py' contains the Game and Snake classes which are responsible for the game logic. The Game class uses an instance of the Snake class.\n\n'app.py' is the main entry point for the Flask application. It creates an instance of the Game class and handles HTTP requests and responses.\n\n'static/js/script.js' is responsible for handling user interactions and updating the game UI based on the game state returned by 'app.py'.\n\n'static/css/styles.css' defines the styles for the game UI.\n\n'templates/index.html' is the main page of the web application. It displays the game UI and loads 'static/js/script.js' and 'static/css/styles.css'.\n\"\"\"\n",
+ "Anything UNCLEAR": "We need clarification on how the high score should be stored. Should it persist across sessions (stored in a database or a file) or should it reset every time the game is restarted? Also, should the game speed increase as the snake grows, or should it remain constant throughout the game?",
+}
WRITE_TASKS_OUTPUT_MAPPING = {
"Required Python third-party packages": (str, ...),
@@ -34,17 +37,17 @@ WRITE_TASKS_OUTPUT_MAPPING = {
def test_create_model_class():
- test_class = ActionOutput.create_model_class("test_class", WRITE_TASKS_OUTPUT_MAPPING)
+ test_class = ActionNode.create_model_class("test_class", WRITE_TASKS_OUTPUT_MAPPING)
assert test_class.__name__ == "test_class"
def test_create_model_class_with_mapping():
- t = ActionOutput.create_model_class("test_class_1", WRITE_TASKS_OUTPUT_MAPPING)
+ t = ActionNode.create_model_class("test_class_1", WRITE_TASKS_OUTPUT_MAPPING)
t1 = t(**t_dict)
value = t1.dict()["Task list"]
assert value == ["game.py", "app.py", "static/css/styles.css", "static/js/script.js", "templates/index.html"]
-if __name__ == '__main__':
+if __name__ == "__main__":
test_create_model_class()
test_create_model_class_with_mapping()
diff --git a/tests/metagpt/actions/test_azure_tts.py b/tests/metagpt/actions/test_azure_tts.py
index b5a333af2..9995e9691 100644
--- a/tests/metagpt/actions/test_azure_tts.py
+++ b/tests/metagpt/actions/test_azure_tts.py
@@ -5,17 +5,12 @@
@Author : alexanderwu
@File : test_azure_tts.py
"""
-from metagpt.actions.azure_tts import AzureTTS
+from metagpt.tools.azure_tts import AzureTTS
def test_azure_tts():
- azure_tts = AzureTTS("azure_tts")
- azure_tts.synthesize_speech(
- "zh-CN",
- "zh-CN-YunxiNeural",
- "Boy",
- "你好,我是卡卡",
- "output.wav")
+ azure_tts = AzureTTS()
+ azure_tts.synthesize_speech("zh-CN", "zh-CN-YunxiNeural", "Boy", "你好,我是卡卡", "output.wav")
# 运行需要先配置 SUBSCRIPTION_KEY
# TODO: 这里如果要检验,还要额外加上对应的asr,才能确保前后生成是接近一致的,但现在还没有
diff --git a/tests/metagpt/actions/test_clone_function.py b/tests/metagpt/actions/test_clone_function.py
index 6d4432dcd..44248eb80 100644
--- a/tests/metagpt/actions/test_clone_function.py
+++ b/tests/metagpt/actions/test_clone_function.py
@@ -2,7 +2,6 @@ import pytest
from metagpt.actions.clone_function import CloneFunction, run_function_code
-
source_code = """
import pandas as pd
import ta
@@ -31,14 +30,18 @@ def get_expected_res():
import ta
# 读取股票数据
- stock_data = pd.read_csv('./tests/data/baba_stock.csv')
+ stock_data = pd.read_csv("./tests/data/baba_stock.csv")
stock_data.head()
# 计算简单移动平均线
- stock_data['SMA'] = ta.trend.sma_indicator(stock_data['Close'], window=6)
- stock_data[['Date', 'Close', 'SMA']].head()
+ stock_data["SMA"] = ta.trend.sma_indicator(stock_data["Close"], window=6)
+ stock_data[["Date", "Close", "SMA"]].head()
# 计算布林带
- stock_data['bb_upper'], stock_data['bb_middle'], stock_data['bb_lower'] = ta.volatility.bollinger_hband_indicator(stock_data['Close'], window=20), ta.volatility.bollinger_mavg(stock_data['Close'], window=20), ta.volatility.bollinger_lband_indicator(stock_data['Close'], window=20)
- stock_data[['Date', 'Close', 'bb_upper', 'bb_middle', 'bb_lower']].head()
+ stock_data["bb_upper"], stock_data["bb_middle"], stock_data["bb_lower"] = (
+ ta.volatility.bollinger_hband_indicator(stock_data["Close"], window=20),
+ ta.volatility.bollinger_mavg(stock_data["Close"], window=20),
+ ta.volatility.bollinger_lband_indicator(stock_data["Close"], window=20),
+ )
+ stock_data[["Date", "Close", "bb_upper", "bb_middle", "bb_lower"]].head()
return stock_data
@@ -46,9 +49,9 @@ def get_expected_res():
async def test_clone_function():
clone = CloneFunction()
code = await clone.run(template_code, source_code)
- assert 'def ' in code
- stock_path = './tests/data/baba_stock.csv'
- df, msg = run_function_code(code, 'stock_indicator', stock_path)
+ assert "def " in code
+ stock_path = "./tests/data/baba_stock.csv"
+ df, msg = run_function_code(code, "stock_indicator", stock_path)
assert not msg
expected_df = get_expected_res()
assert df.equals(expected_df)
diff --git a/tests/metagpt/actions/test_debug_error.py b/tests/metagpt/actions/test_debug_error.py
index 555c84e4e..8289fe41b 100644
--- a/tests/metagpt/actions/test_debug_error.py
+++ b/tests/metagpt/actions/test_debug_error.py
@@ -4,17 +4,19 @@
@Time : 2023/5/11 17:46
@Author : alexanderwu
@File : test_debug_error.py
+@Modifiled By: mashenquan, 2023-12-6. According to RFC 135
"""
+import uuid
+
import pytest
from metagpt.actions.debug_error import DebugError
+from metagpt.config import CONFIG
+from metagpt.const import TEST_CODES_FILE_REPO, TEST_OUTPUTS_FILE_REPO
+from metagpt.schema import RunCodeContext, RunCodeResult
+from metagpt.utils.file_repository import FileRepository
-EXAMPLE_MSG_CONTENT = '''
----
-## Development Code File Name
-player.py
-## Development Code
-```python
+CODE_CONTENT = '''
from typing import List
from deck import Deck
from card import Card
@@ -58,12 +60,9 @@ class Player:
if self.score > 21 and any(card.rank == 'A' for card in self.hand):
self.score -= 10
return self.score
+'''
-```
-## Test File Name
-test_player.py
-## Test Code
-```python
+TEST_CONTENT = """
import unittest
from blackjack_game.player import Player
from blackjack_game.deck import Deck
@@ -114,42 +113,41 @@ class TestPlayer(unittest.TestCase):
if __name__ == '__main__':
unittest.main()
-```
-## Running Command
-python tests/test_player.py
-## Running Output
-standard output: ;
-standard errors: ..F..
-======================================================================
-FAIL: test_player_calculate_score_with_multiple_aces (__main__.TestPlayer)
-----------------------------------------------------------------------
-Traceback (most recent call last):
- File "tests/test_player.py", line 46, in test_player_calculate_score_with_multiple_aces
- self.assertEqual(player.score, 12)
-AssertionError: 22 != 12
+"""
-----------------------------------------------------------------------
-Ran 5 tests in 0.007s
-
-FAILED (failures=1)
-;
-## instruction:
-The error is in the development code, specifically in the calculate_score method of the Player class. The method is not correctly handling the case where there are multiple Aces in the player's hand. The current implementation only subtracts 10 from the score once if the score is over 21 and there's an Ace in the hand. However, in the case of multiple Aces, it should subtract 10 for each Ace until the score is 21 or less.
-## File To Rewrite:
-player.py
-## Status:
-FAIL
-## Send To:
-Engineer
----
-'''
@pytest.mark.asyncio
async def test_debug_error():
+ CONFIG.src_workspace = CONFIG.git_repo.workdir / uuid.uuid4().hex
+ ctx = RunCodeContext(
+ code_filename="player.py",
+ test_filename="test_player.py",
+ command=["python", "tests/test_player.py"],
+ output_filename="output.log",
+ )
- debug_error = DebugError("debug_error")
+ await FileRepository.save_file(filename=ctx.code_filename, content=CODE_CONTENT, relative_path=CONFIG.src_workspace)
+ await FileRepository.save_file(filename=ctx.test_filename, content=TEST_CONTENT, relative_path=TEST_CODES_FILE_REPO)
+ output_data = RunCodeResult(
+ stdout=";",
+ stderr="",
+ summary="======================================================================\n"
+ "FAIL: test_player_calculate_score_with_multiple_aces (__main__.TestPlayer)\n"
+ "----------------------------------------------------------------------\n"
+ "Traceback (most recent call last):\n"
+ ' File "tests/test_player.py", line 46, in test_player_calculate_score_'
+ "with_multiple_aces\n"
+ " self.assertEqual(player.score, 12)\nAssertionError: 22 != 12\n\n"
+ "----------------------------------------------------------------------\n"
+ "Ran 5 tests in 0.007s\n\nFAILED (failures=1)\n;\n",
+ )
+ await FileRepository.save_file(
+ filename=ctx.output_filename, content=output_data.json(), relative_path=TEST_OUTPUTS_FILE_REPO
+ )
+ debug_error = DebugError(context=ctx)
- file_name, rewritten_code = await debug_error.run(context=EXAMPLE_MSG_CONTENT)
+ rsp = await debug_error.run()
- assert "class Player" in rewritten_code # rewrite the same class
- assert "while self.score > 21" in rewritten_code # a key logic to rewrite to (original one is "if self.score > 12")
+ assert "class Player" in rsp # rewrite the same class
+ # a key logic to rewrite to (original one is "if self.score > 12")
+ assert "while self.score > 21" in rsp
diff --git a/tests/metagpt/actions/test_design_api.py b/tests/metagpt/actions/test_design_api.py
index 0add8fb74..e90707d1a 100644
--- a/tests/metagpt/actions/test_design_api.py
+++ b/tests/metagpt/actions/test_design_api.py
@@ -4,33 +4,27 @@
@Time : 2023/5/11 19:26
@Author : alexanderwu
@File : test_design_api.py
+@Modifiled By: mashenquan, 2023-12-6. According to RFC 135
"""
import pytest
from metagpt.actions.design_api import WriteDesign
+from metagpt.const import PRDS_FILE_REPO
from metagpt.logs import logger
from metagpt.schema import Message
+from metagpt.utils.file_repository import FileRepository
from tests.metagpt.actions.mock import PRD_SAMPLE
@pytest.mark.asyncio
async def test_design_api():
- prd = "我们需要一个音乐播放器,它应该有播放、暂停、上一曲、下一曲等功能。"
+ inputs = ["我们需要一个音乐播放器,它应该有播放、暂停、上一曲、下一曲等功能。", PRD_SAMPLE]
+ for prd in inputs:
+ await FileRepository.save_file("new_prd.txt", content=prd, relative_path=PRDS_FILE_REPO)
- design_api = WriteDesign("design_api")
+ design_api = WriteDesign("design_api")
- result = await design_api.run([Message(content=prd, instruct_content=None)])
- logger.info(result)
+ result = await design_api.run([Message(content=prd, instruct_content=None)])
+ logger.info(result)
- assert result
-
-
-@pytest.mark.asyncio
-async def test_design_api_calculator():
- prd = PRD_SAMPLE
-
- design_api = WriteDesign("design_api")
- result = await design_api.run([Message(content=prd, instruct_content=None)])
- logger.info(result)
-
- assert result
+ assert result
diff --git a/tests/metagpt/actions/test_detail_mining.py b/tests/metagpt/actions/test_detail_mining.py
index c9d5331f9..a178ec840 100644
--- a/tests/metagpt/actions/test_detail_mining.py
+++ b/tests/metagpt/actions/test_detail_mining.py
@@ -3,21 +3,27 @@
"""
@Time : 2023/9/13 00:26
@Author : fisherdeng
-@File : test_detail_mining.py
+@File : test_generate_questions.py
"""
import pytest
-from metagpt.actions.detail_mining import DetailMining
+from metagpt.actions.generate_questions import GenerateQuestions
from metagpt.logs import logger
-@pytest.mark.asyncio
-async def test_detail_mining():
- topic = "如何做一个生日蛋糕"
- record = "我认为应该先准备好材料,然后再开始做蛋糕。"
- detail_mining = DetailMining("detail_mining")
- rsp = await detail_mining.run(topic=topic, record=record)
- logger.info(f"{rsp.content=}")
-
- assert '##OUTPUT' in rsp.content
- assert '蛋糕' in rsp.content
+context = """
+## topic
+如何做一个生日蛋糕
+## record
+我认为应该先准备好材料,然后再开始做蛋糕。
+"""
+
+
+@pytest.mark.asyncio
+async def test_generate_questions():
+ detail_mining = GenerateQuestions()
+ rsp = await detail_mining.run(context)
+ logger.info(f"{rsp.content=}")
+
+ assert "Questions" in rsp.content
+ assert "1." in rsp.content
diff --git a/tests/metagpt/actions/test_invoice_ocr.py b/tests/metagpt/actions/test_invoice_ocr.py
index a15166f7c..7f16aa9a4 100644
--- a/tests/metagpt/actions/test_invoice_ocr.py
+++ b/tests/metagpt/actions/test_invoice_ocr.py
@@ -8,12 +8,11 @@
"""
import os
-from typing import List
-
-import pytest
from pathlib import Path
-from metagpt.actions.invoice_ocr import InvoiceOCR, GenerateTable, ReplyQuestion
+import pytest
+
+from metagpt.actions.invoice_ocr import GenerateTable, InvoiceOCR, ReplyQuestion
@pytest.mark.asyncio
@@ -22,7 +21,7 @@ from metagpt.actions.invoice_ocr import InvoiceOCR, GenerateTable, ReplyQuestion
[
"../../data/invoices/invoice-3.jpg",
"../../data/invoices/invoice-4.zip",
- ]
+ ],
)
async def test_invoice_ocr(invoice_path: str):
invoice_path = os.path.abspath(os.path.join(os.getcwd(), invoice_path))
@@ -35,18 +34,8 @@ async def test_invoice_ocr(invoice_path: str):
@pytest.mark.parametrize(
("invoice_path", "expected_result"),
[
- (
- "../../data/invoices/invoice-1.pdf",
- [
- {
- "收款人": "小明",
- "城市": "深圳市",
- "总费用/元": "412.00",
- "开票日期": "2023年02月03日"
- }
- ]
- ),
- ]
+ ("../../data/invoices/invoice-1.pdf", [{"收款人": "小明", "城市": "深圳市", "总费用/元": "412.00", "开票日期": "2023年02月03日"}]),
+ ],
)
async def test_generate_table(invoice_path: str, expected_result: list[dict]):
invoice_path = os.path.abspath(os.path.join(os.getcwd(), invoice_path))
@@ -59,9 +48,7 @@ async def test_generate_table(invoice_path: str, expected_result: list[dict]):
@pytest.mark.asyncio
@pytest.mark.parametrize(
("invoice_path", "query", "expected_result"),
- [
- ("../../data/invoices/invoice-1.pdf", "Invoicing date", "2023年02月03日")
- ]
+ [("../../data/invoices/invoice-1.pdf", "Invoicing date", "2023年02月03日")],
)
async def test_reply_question(invoice_path: str, query: dict, expected_result: str):
invoice_path = os.path.abspath(os.path.join(os.getcwd(), invoice_path))
@@ -69,4 +56,3 @@ async def test_reply_question(invoice_path: str, query: dict, expected_result: s
ocr_result = await InvoiceOCR().run(file_path=Path(invoice_path), filename=filename)
result = await ReplyQuestion().run(query=query, ocr_result=ocr_result)
assert expected_result in result
-
diff --git a/tests/metagpt/actions/test_prepare_documents.py b/tests/metagpt/actions/test_prepare_documents.py
new file mode 100644
index 000000000..31c8bcb80
--- /dev/null
+++ b/tests/metagpt/actions/test_prepare_documents.py
@@ -0,0 +1,30 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/12/6
+@Author : mashenquan
+@File : test_prepare_documents.py
+@Desc: Unit test for prepare_documents.py
+"""
+import pytest
+
+from metagpt.actions.prepare_documents import PrepareDocuments
+from metagpt.config import CONFIG
+from metagpt.const import DOCS_FILE_REPO, REQUIREMENT_FILENAME
+from metagpt.schema import Message
+from metagpt.utils.file_repository import FileRepository
+
+
+@pytest.mark.asyncio
+async def test_prepare_documents():
+ msg = Message(content="New user requirements balabala...")
+
+ if CONFIG.git_repo:
+ CONFIG.git_repo.delete_repository()
+ CONFIG.git_repo = None
+
+ await PrepareDocuments().run(with_messages=[msg])
+ assert CONFIG.git_repo
+ doc = await FileRepository.get_file(filename=REQUIREMENT_FILENAME, relative_path=DOCS_FILE_REPO)
+ assert doc
+ assert doc.content == msg.content
diff --git a/tests/metagpt/actions/test_prepare_interview.py b/tests/metagpt/actions/test_prepare_interview.py
new file mode 100644
index 000000000..7c32882e0
--- /dev/null
+++ b/tests/metagpt/actions/test_prepare_interview.py
@@ -0,0 +1,21 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/9/13 00:26
+@Author : fisherdeng
+@File : test_detail_mining.py
+"""
+import pytest
+
+from metagpt.actions.prepare_interview import PrepareInterview
+from metagpt.logs import logger
+
+
+@pytest.mark.asyncio
+async def test_prepare_interview():
+ action = PrepareInterview()
+ rsp = await action.run("I just graduated and hope to find a job as a Python engineer")
+ logger.info(f"{rsp.content=}")
+
+ assert "Questions" in rsp.content
+ assert "1." in rsp.content
diff --git a/tests/metagpt/actions/test_run_code.py b/tests/metagpt/actions/test_run_code.py
index 1e451cb14..888418974 100644
--- a/tests/metagpt/actions/test_run_code.py
+++ b/tests/metagpt/actions/test_run_code.py
@@ -4,10 +4,12 @@
@Time : 2023/5/11 17:46
@Author : alexanderwu
@File : test_run_code.py
+@Modifiled By: mashenquan, 2023-12-6. According to RFC 135
"""
import pytest
from metagpt.actions.run_code import RunCode
+from metagpt.schema import RunCodeContext
@pytest.mark.asyncio
@@ -35,37 +37,29 @@ async def test_run_script():
@pytest.mark.asyncio
async def test_run():
- action = RunCode()
- result = await action.run(mode="text", code="print('Hello, World')")
- assert "PASS" in result
-
- result = await action.run(
- mode="script",
- code="echo 'Hello World'",
- code_file_name="",
- test_code="",
- test_file_name="",
- command=["echo", "Hello World"],
- working_directory=".",
- additional_python_paths=[],
- )
- assert "PASS" in result
-
-
-@pytest.mark.asyncio
-async def test_run_failure():
- action = RunCode()
- result = await action.run(mode="text", code="result = 1 / 0")
- assert "FAIL" in result
-
- result = await action.run(
- mode="script",
- code='python -c "print(1/0)"',
- code_file_name="",
- test_code="",
- test_file_name="",
- command=["python", "-c", "print(1/0)"],
- working_directory=".",
- additional_python_paths=[],
- )
- assert "FAIL" in result
+ inputs = [
+ (RunCodeContext(mode="text", code_filename="a.txt", code="print('Hello, World')"), "PASS"),
+ (
+ RunCodeContext(
+ mode="script",
+ code_filename="a.sh",
+ code="echo 'Hello World'",
+ command=["echo", "Hello World"],
+ working_directory=".",
+ ),
+ "PASS",
+ ),
+ (
+ RunCodeContext(
+ mode="script",
+ code_filename="a.py",
+ code='python -c "print(1/0)"',
+ command=["python", "-c", "print(1/0)"],
+ working_directory=".",
+ ),
+ "FAIL",
+ ),
+ ]
+ for ctx, result in inputs:
+ rsp = await RunCode(context=ctx).run()
+ assert result in rsp.summary
diff --git a/tests/metagpt/actions/test_summarize_code.py b/tests/metagpt/actions/test_summarize_code.py
new file mode 100644
index 000000000..7ecb67afd
--- /dev/null
+++ b/tests/metagpt/actions/test_summarize_code.py
@@ -0,0 +1,195 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/5/11 17:46
+@Author : mashenquan
+@File : test_summarize_code.py
+@Modifiled By: mashenquan, 2023-12-6. Unit test for summarize_code.py
+"""
+import pytest
+
+from metagpt.actions.summarize_code import SummarizeCode
+from metagpt.config import CONFIG
+from metagpt.const import SYSTEM_DESIGN_FILE_REPO, TASK_FILE_REPO
+from metagpt.logs import logger
+from metagpt.schema import CodeSummarizeContext
+from metagpt.utils.file_repository import FileRepository
+
+DESIGN_CONTENT = """
+{"Implementation approach": "To develop this snake game, we will use the Python language and choose the Pygame library. Pygame is an open-source Python module collection specifically designed for writing video games. It provides functionalities such as displaying images and playing sounds, making it suitable for creating intuitive and responsive user interfaces. We will ensure efficient game logic to prevent any delays during gameplay. The scoring system will be simple, with the snake gaining points for each food it eats. We will use Pygame's event handling system to implement pause and resume functionality, as well as high-score tracking. The difficulty will increase by speeding up the snake's movement. In the initial version, we will focus on single-player mode and consider adding multiplayer mode and customizable skins in future updates. Based on the new requirement, we will also add a moving obstacle that appears randomly. If the snake eats this obstacle, the game will end. If the snake does not eat the obstacle, it will disappear after 5 seconds. For this, we need to add mechanisms for obstacle generation, movement, and disappearance in the game logic.", "Project_name": "snake_game", "File list": ["main.py", "game.py", "snake.py", "food.py", "obstacle.py", "scoreboard.py", "constants.py", "assets/styles.css", "assets/index.html"], "Data structures and interfaces": "```mermaid\n classDiagram\n class Game{\n +int score\n +int speed\n +bool game_over\n +bool paused\n +Snake snake\n +Food food\n +Obstacle obstacle\n +Scoreboard scoreboard\n +start_game() void\n +pause_game() void\n +resume_game() void\n +end_game() void\n +increase_difficulty() void\n +update() void\n +render() void\n Game()\n }\n class Snake{\n +list body_parts\n +str direction\n +bool grow\n +move() void\n +grow() void\n +check_collision() bool\n Snake()\n }\n class Food{\n +tuple position\n +spawn() void\n Food()\n }\n class Obstacle{\n +tuple position\n +int lifetime\n +bool active\n +spawn() void\n +move() void\n +check_collision() bool\n +disappear() void\n Obstacle()\n }\n class Scoreboard{\n +int high_score\n +update_score(int) void\n +reset_score() void\n +load_high_score() void\n +save_high_score() void\n Scoreboard()\n }\n class Constants{\n }\n Game \"1\" -- \"1\" Snake: has\n Game \"1\" -- \"1\" Food: has\n Game \"1\" -- \"1\" Obstacle: has\n Game \"1\" -- \"1\" Scoreboard: has\n ```", "Program call flow": "```sequenceDiagram\n participant M as Main\n participant G as Game\n participant S as Snake\n participant F as Food\n participant O as Obstacle\n participant SB as Scoreboard\n M->>G: start_game()\n loop game loop\n G->>S: move()\n G->>S: check_collision()\n G->>F: spawn()\n G->>O: spawn()\n G->>O: move()\n G->>O: check_collision()\n G->>O: disappear()\n G->>SB: update_score(score)\n G->>G: update()\n G->>G: render()\n alt if paused\n M->>G: pause_game()\n M->>G: resume_game()\n end\n alt if game_over\n G->>M: end_game()\n end\n end\n```", "Anything UNCLEAR": "There is no need for further clarification as the requirements are already clear."}
+"""
+
+TASK_CONTENT = """
+{"Required Python third-party packages": ["pygame==2.0.1"], "Required Other language third-party packages": ["No third-party packages required for other languages."], "Full API spec": "\n openapi: 3.0.0\n info:\n title: Snake Game API\n version: \"1.0.0\"\n paths:\n /start:\n get:\n summary: Start the game\n responses:\n '200':\n description: Game started successfully\n /pause:\n get:\n summary: Pause the game\n responses:\n '200':\n description: Game paused successfully\n /resume:\n get:\n summary: Resume the game\n responses:\n '200':\n description: Game resumed successfully\n /end:\n get:\n summary: End the game\n responses:\n '200':\n description: Game ended successfully\n /score:\n get:\n summary: Get the current score\n responses:\n '200':\n description: Current score retrieved successfully\n /highscore:\n get:\n summary: Get the high score\n responses:\n '200':\n description: High score retrieved successfully\n components: {}\n ", "Logic Analysis": [["constants.py", "Contains all the constant values like screen size, colors, game speeds, etc. This should be implemented first as it provides the base values for other components."], ["snake.py", "Contains the Snake class with methods for movement, growth, and collision detection. It is dependent on constants.py for configuration values."], ["food.py", "Contains the Food class responsible for spawning food items on the screen. It is dependent on constants.py for configuration values."], ["obstacle.py", "Contains the Obstacle class with methods for spawning, moving, and disappearing of obstacles, as well as collision detection with the snake. It is dependent on constants.py for configuration values."], ["scoreboard.py", "Contains the Scoreboard class for updating, resetting, loading, and saving high scores. It may use constants.py for configuration values and depends on the game's scoring logic."], ["game.py", "Contains the main Game class which includes the game loop and methods for starting, pausing, resuming, and ending the game. It is dependent on snake.py, food.py, obstacle.py, and scoreboard.py."], ["main.py", "The entry point of the game that initializes the game and starts the game loop. It is dependent on game.py."]], "Task list": ["constants.py", "snake.py", "food.py", "obstacle.py", "scoreboard.py", "game.py", "main.py"], "Shared Knowledge": "\n 'constants.py' should contain all the necessary configurations for the game, such as screen dimensions, color definitions, and speed settings. These constants will be used across multiple files, ensuring consistency and ease of updates. Ensure that the Pygame library is initialized correctly in 'main.py' before starting the game loop. Also, make sure that the game's state is managed properly when pausing and resuming the game.\n ", "Anything UNCLEAR": "The interaction between the 'obstacle.py' and the game loop needs to be clearly defined to ensure obstacles appear and disappear correctly. The lifetime of the obstacle and its random movement should be implemented in a way that does not interfere with the game's performance."}
+"""
+
+FOOD_PY = """
+## food.py
+import random
+
+class Food:
+ def __init__(self):
+ self.position = (0, 0)
+
+ def generate(self):
+ x = random.randint(0, 9)
+ y = random.randint(0, 9)
+ self.position = (x, y)
+
+ def get_position(self):
+ return self.position
+
+"""
+
+GAME_PY = """
+## game.py
+import pygame
+from snake import Snake
+from food import Food
+
+class Game:
+ def __init__(self):
+ self.score = 0
+ self.level = 1
+ self.snake = Snake()
+ self.food = Food()
+
+ def start_game(self):
+ pygame.init()
+ self.initialize_game()
+ self.game_loop()
+
+ def initialize_game(self):
+ self.score = 0
+ self.level = 1
+ self.snake.reset()
+ self.food.generate()
+
+ def game_loop(self):
+ game_over = False
+
+ while not game_over:
+ self.update()
+ self.draw()
+ self.handle_events()
+ self.check_collision()
+ self.increase_score()
+ self.increase_level()
+
+ if self.snake.is_collision():
+ game_over = True
+ self.game_over()
+
+ def update(self):
+ self.snake.move()
+
+ def draw(self):
+ self.snake.draw()
+ self.food.draw()
+
+ def handle_events(self):
+ for event in pygame.event.get():
+ if event.type == pygame.QUIT:
+ pygame.quit()
+ quit()
+ elif event.type == pygame.KEYDOWN:
+ if event.key == pygame.K_UP:
+ self.snake.change_direction("UP")
+ elif event.key == pygame.K_DOWN:
+ self.snake.change_direction("DOWN")
+ elif event.key == pygame.K_LEFT:
+ self.snake.change_direction("LEFT")
+ elif event.key == pygame.K_RIGHT:
+ self.snake.change_direction("RIGHT")
+
+ def check_collision(self):
+ if self.snake.get_head() == self.food.get_position():
+ self.snake.grow()
+ self.food.generate()
+
+ def increase_score(self):
+ self.score += 1
+
+ def increase_level(self):
+ if self.score % 10 == 0:
+ self.level += 1
+
+ def game_over(self):
+ print("Game Over")
+ self.initialize_game()
+
+"""
+
+MAIN_PY = """
+## main.py
+import pygame
+from game import Game
+
+def main():
+ pygame.init()
+ game = Game()
+ game.start_game()
+
+if __name__ == "__main__":
+ main()
+
+"""
+
+SNAKE_PY = """
+## snake.py
+import pygame
+
+class Snake:
+ def __init__(self):
+ self.body = [(0, 0)]
+ self.direction = (1, 0)
+
+ def move(self):
+ head = self.body[0]
+ dx, dy = self.direction
+ new_head = (head[0] + dx, head[1] + dy)
+ self.body.insert(0, new_head)
+ self.body.pop()
+
+ def change_direction(self, direction):
+ if direction == "UP":
+ self.direction = (0, -1)
+ elif direction == "DOWN":
+ self.direction = (0, 1)
+ elif direction == "LEFT":
+ self.direction = (-1, 0)
+ elif direction == "RIGHT":
+ self.direction = (1, 0)
+
+ def grow(self):
+ tail = self.body[-1]
+ dx, dy = self.direction
+ new_tail = (tail[0] - dx, tail[1] - dy)
+ self.body.append(new_tail)
+
+ def get_head(self):
+ return self.body[0]
+
+ def get_body(self):
+ return self.body[1:]
+
+"""
+
+
+@pytest.mark.asyncio
+async def test_summarize_code():
+ CONFIG.src_workspace = CONFIG.git_repo.workdir / "src"
+ await FileRepository.save_file(filename="1.json", relative_path=SYSTEM_DESIGN_FILE_REPO, content=DESIGN_CONTENT)
+ await FileRepository.save_file(filename="1.json", relative_path=TASK_FILE_REPO, content=TASK_CONTENT)
+ await FileRepository.save_file(filename="food.py", relative_path=CONFIG.src_workspace, content=FOOD_PY)
+ await FileRepository.save_file(filename="game.py", relative_path=CONFIG.src_workspace, content=GAME_PY)
+ await FileRepository.save_file(filename="main.py", relative_path=CONFIG.src_workspace, content=MAIN_PY)
+ await FileRepository.save_file(filename="snake.py", relative_path=CONFIG.src_workspace, content=SNAKE_PY)
+
+ src_file_repo = CONFIG.git_repo.new_file_repository(relative_path=CONFIG.src_workspace)
+ all_files = src_file_repo.all_files
+ ctx = CodeSummarizeContext(design_filename="1.json", task_filename="1.json", codes_filenames=all_files)
+ action = SummarizeCode(context=ctx)
+ rsp = await action.run()
+ assert rsp
+ logger.info(rsp)
diff --git a/tests/metagpt/actions/test_ui_design.py b/tests/metagpt/actions/test_ui_design.py
index d284b20f2..83590ec7d 100644
--- a/tests/metagpt/actions/test_ui_design.py
+++ b/tests/metagpt/actions/test_ui_design.py
@@ -1,10 +1,10 @@
# -*- coding: utf-8 -*-
# @Date : 2023/7/22 02:40
-# @Author : stellahong (stellahong@fuzhi.ai)
+# @Author : stellahong (stellahong@deepwisdom.ai)
#
from tests.metagpt.roles.ui_role import UIDesign
-llm_resp= '''
+llm_resp = """
# UI Design Description
```The user interface for the snake game will be designed in a way that is simple, clean, and intuitive. The main elements of the game such as the game grid, snake, food, score, and game over message will be clearly defined and easy to understand. The game grid will be centered on the screen with the score displayed at the top. The game controls will be intuitive and easy to use. The design will be modern and minimalist with a pleasing color scheme.```
@@ -98,12 +98,13 @@ body {
left: 50%;
transform: translate(-50%, -50%);
font-size: 3em;
- '''
+ """
+
def test_ui_design_parse_css():
ui_design_work = UIDesign(name="UI design action")
- css = '''
+ css = """
body {
display: flex;
flex-direction: column;
@@ -160,14 +161,14 @@ def test_ui_design_parse_css():
left: 50%;
transform: translate(-50%, -50%);
font-size: 3em;
- '''
- assert ui_design_work.parse_css_code(context=llm_resp)==css
+ """
+ assert ui_design_work.parse_css_code(context=llm_resp) == css
def test_ui_design_parse_html():
ui_design_work = UIDesign(name="UI design action")
- html = '''
+ html = """
@@ -184,8 +185,5 @@ def test_ui_design_parse_html():
Game Over
- '''
- assert ui_design_work.parse_css_code(context=llm_resp)==html
-
-
-
+ """
+ assert ui_design_work.parse_css_code(context=llm_resp) == html
diff --git a/tests/metagpt/actions/test_write_code.py b/tests/metagpt/actions/test_write_code.py
index 7bb18ddf2..54229089c 100644
--- a/tests/metagpt/actions/test_write_code.py
+++ b/tests/metagpt/actions/test_write_code.py
@@ -4,31 +4,36 @@
@Time : 2023/5/11 17:45
@Author : alexanderwu
@File : test_write_code.py
+@Modifiled By: mashenquan, 2023-12-6. According to RFC 135
"""
import pytest
from metagpt.actions.write_code import WriteCode
from metagpt.llm import LLM
from metagpt.logs import logger
+from metagpt.schema import CodingContext, Document
from tests.metagpt.actions.mock import TASKS_2, WRITE_CODE_PROMPT_SAMPLE
@pytest.mark.asyncio
async def test_write_code():
- api_design = "设计一个名为'add'的函数,该函数接受两个整数作为输入,并返回它们的和。"
- write_code = WriteCode("write_code")
+ context = CodingContext(
+ filename="task_filename.py", design_doc=Document(content="设计一个名为'add'的函数,该函数接受两个整数作为输入,并返回它们的和。")
+ )
+ doc = Document(content=context.json())
+ write_code = WriteCode(context=doc)
- code = await write_code.run(api_design)
- logger.info(code)
+ code = await write_code.run()
+ logger.info(code.json())
# 我们不能精确地预测生成的代码,但我们可以检查某些关键字
- assert 'def add' in code
- assert 'return' in code
+ assert "def add" in code.code_doc.content
+ assert "return" in code.code_doc.content
@pytest.mark.asyncio
async def test_write_code_directly():
- prompt = WRITE_CODE_PROMPT_SAMPLE + '\n' + TASKS_2[0]
+ prompt = WRITE_CODE_PROMPT_SAMPLE + "\n" + TASKS_2[0]
llm = LLM()
rsp = await llm.aask(prompt)
logger.info(rsp)
diff --git a/tests/metagpt/actions/test_write_code_review.py b/tests/metagpt/actions/test_write_code_review.py
index 21bc563ec..e16eb7348 100644
--- a/tests/metagpt/actions/test_write_code_review.py
+++ b/tests/metagpt/actions/test_write_code_review.py
@@ -8,6 +8,8 @@
import pytest
from metagpt.actions.write_code_review import WriteCodeReview
+from metagpt.document import Document
+from metagpt.schema import CodingContext
@pytest.mark.asyncio
@@ -16,13 +18,15 @@ async def test_write_code_review(capfd):
def add(a, b):
return a +
"""
- # write_code_review = WriteCodeReview("write_code_review")
+ context = CodingContext(
+ filename="math.py", design_doc=Document(content="编写一个从a加b的函数,返回a+b"), code_doc=Document(content=code)
+ )
- code = await WriteCodeReview().run(context="编写一个从a加b的函数,返回a+b", code=code, filename="math.py")
+ context = await WriteCodeReview(context=context).run()
# 我们不能精确地预测生成的代码评审,但我们可以检查返回的是否为字符串
- assert isinstance(code, str)
- assert len(code) > 0
+ assert isinstance(context.code_doc.content, str)
+ assert len(context.code_doc.content) > 0
captured = capfd.readouterr()
print(f"输出内容: {captured.out}")
diff --git a/tests/metagpt/actions/test_write_docstring.py b/tests/metagpt/actions/test_write_docstring.py
index 82d96e1a6..a8a80b36d 100644
--- a/tests/metagpt/actions/test_write_docstring.py
+++ b/tests/metagpt/actions/test_write_docstring.py
@@ -2,7 +2,7 @@ import pytest
from metagpt.actions.write_docstring import WriteDocstring
-code = '''
+code = """
def add_numbers(a: int, b: int):
return a + b
@@ -14,7 +14,7 @@ class Person:
def greet(self):
return f"Hello, my name is {self.name} and I am {self.age} years old."
-'''
+"""
@pytest.mark.asyncio
@@ -25,7 +25,7 @@ class Person:
("numpy", "Parameters"),
("sphinx", ":param name:"),
],
- ids=["google", "numpy", "sphinx"]
+ ids=["google", "numpy", "sphinx"],
)
async def test_write_docstring(style: str, part: str):
ret = await WriteDocstring().run(code, style=style)
diff --git a/tests/metagpt/actions/test_write_prd.py b/tests/metagpt/actions/test_write_prd.py
index 38e4e5221..08be3cf75 100644
--- a/tests/metagpt/actions/test_write_prd.py
+++ b/tests/metagpt/actions/test_write_prd.py
@@ -4,23 +4,29 @@
@Time : 2023/5/11 17:45
@Author : alexanderwu
@File : test_write_prd.py
+@Modified By: mashenquan, 2023-11-1. According to Chapter 2.2.1 and 2.2.2 of RFC 116, replace `handle` with `run`.
"""
import pytest
-from metagpt.actions import BossRequirement
+from metagpt.actions import UserRequirement
+from metagpt.config import CONFIG
+from metagpt.const import DOCS_FILE_REPO, PRDS_FILE_REPO, REQUIREMENT_FILENAME
from metagpt.logs import logger
from metagpt.roles.product_manager import ProductManager
from metagpt.schema import Message
+from metagpt.utils.file_repository import FileRepository
@pytest.mark.asyncio
async def test_write_prd():
product_manager = ProductManager()
requirements = "开发一个基于大语言模型与私有知识库的搜索引擎,希望可以基于大语言模型进行搜索总结"
- prd = await product_manager.handle(Message(content=requirements, cause_by=BossRequirement))
+ await FileRepository.save_file(filename=REQUIREMENT_FILENAME, content=requirements, relative_path=DOCS_FILE_REPO)
+ prd = await product_manager.run(Message(content=requirements, cause_by=UserRequirement))
logger.info(requirements)
logger.info(prd)
# Assert the prd is not None or empty
assert prd is not None
- assert prd != ""
+ assert prd.content != ""
+ assert CONFIG.git_repo.new_file_repository(relative_path=PRDS_FILE_REPO).changed_files
diff --git a/tests/metagpt/actions/test_write_review.py b/tests/metagpt/actions/test_write_review.py
new file mode 100644
index 000000000..2d188b720
--- /dev/null
+++ b/tests/metagpt/actions/test_write_review.py
@@ -0,0 +1,53 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/12/20 15:01
+@Author : alexanderwu
+@File : test_write_review.py
+"""
+import pytest
+
+from metagpt.actions.write_review import WriteReview
+
+CONTEXT = """
+{
+ "Language": "zh_cn",
+ "Programming Language": "Python",
+ "Original Requirements": "写一个简单的2048",
+ "Project Name": "game_2048",
+ "Product Goals": [
+ "创建一个引人入胜的用户体验",
+ "确保高性能",
+ "提供可定制的功能"
+ ],
+ "User Stories": [
+ "作为用户,我希望能够选择不同的难度级别",
+ "作为玩家,我希望在每局游戏结束后能看到我的得分"
+ ],
+ "Competitive Analysis": [
+ "Python Snake Game: 界面简单,缺乏高级功能"
+ ],
+ "Competitive Quadrant Chart": "quadrantChart\n title \"Reach and engagement of campaigns\"\n x-axis \"Low Reach\" --> \"High Reach\"\n y-axis \"Low Engagement\" --> \"High Engagement\"\n quadrant-1 \"我们应该扩展\"\n quadrant-2 \"需要推广\"\n quadrant-3 \"重新评估\"\n quadrant-4 \"可能需要改进\"\n \"Campaign A\": [0.3, 0.6]\n \"Campaign B\": [0.45, 0.23]\n \"Campaign C\": [0.57, 0.69]\n \"Campaign D\": [0.78, 0.34]\n \"Campaign E\": [0.40, 0.34]\n \"Campaign F\": [0.35, 0.78]\n \"Our Target Product\": [0.5, 0.6]",
+ "Requirement Analysis": "产品应该用户友好。",
+ "Requirement Pool": [
+ [
+ "P0",
+ "主要代码..."
+ ],
+ [
+ "P0",
+ "游戏算法..."
+ ]
+ ],
+ "UI Design draft": "基本功能描述,简单的风格和布局。",
+ "Anything UNCLEAR": "..."
+}
+"""
+
+
+@pytest.mark.asyncio
+async def test_write_review():
+ write_review = WriteReview()
+ review = await write_review.run(CONTEXT)
+ assert review.instruct_content
+ assert review.get("LGTM") in ["LGTM", "LBTM"]
diff --git a/tests/metagpt/actions/test_write_test.py b/tests/metagpt/actions/test_write_test.py
index e5acdff44..a3190fb0e 100644
--- a/tests/metagpt/actions/test_write_test.py
+++ b/tests/metagpt/actions/test_write_test.py
@@ -9,6 +9,7 @@ import pytest
from metagpt.actions.write_test import WriteTest
from metagpt.logs import logger
+from metagpt.schema import Document, TestingContext
@pytest.mark.asyncio
@@ -24,22 +25,17 @@ async def test_write_test():
def generate(self, max_y: int, max_x: int):
self.position = (random.randint(1, max_y - 1), random.randint(1, max_x - 1))
"""
+ context = TestingContext(filename="food.py", code_doc=Document(filename="food.py", content=code))
+ write_test = WriteTest(context=context)
- write_test = WriteTest()
-
- test_code = await write_test.run(
- code_to_test=code,
- test_file_name="test_food.py",
- source_file_path="/some/dummy/path/cli_snake_game/cli_snake_game/food.py",
- workspace="/some/dummy/path/cli_snake_game",
- )
- logger.info(test_code)
+ context = await write_test.run()
+ logger.info(context.json())
# We cannot exactly predict the generated test cases, but we can check if it is a string and if it is not empty
- assert isinstance(test_code, str)
- assert "from cli_snake_game.food import Food" in test_code
- assert "class TestFood(unittest.TestCase)" in test_code
- assert "def test_generate" in test_code
+ assert isinstance(context.test_doc.content, str)
+ assert "from food import Food" in context.test_doc.content
+ assert "class TestFood(unittest.TestCase)" in context.test_doc.content
+ assert "def test_generate" in context.test_doc.content
@pytest.mark.asyncio
diff --git a/tests/metagpt/actions/test_write_tutorial.py b/tests/metagpt/actions/test_write_tutorial.py
index 683fee082..27a323b44 100644
--- a/tests/metagpt/actions/test_write_tutorial.py
+++ b/tests/metagpt/actions/test_write_tutorial.py
@@ -9,14 +9,11 @@ from typing import Dict
import pytest
-from metagpt.actions.write_tutorial import WriteDirectory, WriteContent
+from metagpt.actions.write_tutorial import WriteContent, WriteDirectory
@pytest.mark.asyncio
-@pytest.mark.parametrize(
- ("language", "topic"),
- [("English", "Write a tutorial about Python")]
-)
+@pytest.mark.parametrize(("language", "topic"), [("English", "Write a tutorial about Python")])
async def test_write_directory(language: str, topic: str):
ret = await WriteDirectory(language=language).run(topic=topic)
assert isinstance(ret, dict)
@@ -30,7 +27,7 @@ async def test_write_directory(language: str, topic: str):
@pytest.mark.asyncio
@pytest.mark.parametrize(
("language", "topic", "directory"),
- [("English", "Write a tutorial about Python", {"Introduction": ["What is Python?", "Why learn Python?"]})]
+ [("English", "Write a tutorial about Python", {"Introduction": ["What is Python?", "Why learn Python?"]})],
)
async def test_write_content(language: str, topic: str, directory: Dict):
ret = await WriteContent(language=language, directory=directory).run(topic=topic)
diff --git a/tests/metagpt/document_store/test_chromadb_store.py b/tests/metagpt/document_store/test_chromadb_store.py
index f8c11e1ca..fd115dcdd 100644
--- a/tests/metagpt/document_store/test_chromadb_store.py
+++ b/tests/metagpt/document_store/test_chromadb_store.py
@@ -12,12 +12,12 @@ from metagpt.document_store.chromadb_store import ChromaStore
def test_chroma_store():
"""FIXME:chroma使用感觉很诡异,一用Python就挂,测试用例里也是"""
# 创建 ChromaStore 实例,使用 'sample_collection' 集合
- document_store = ChromaStore('sample_collection_1')
+ document_store = ChromaStore("sample_collection_1")
# 使用 write 方法添加多个文档
- document_store.write(["This is document1", "This is document2"],
- [{"source": "google-docs"}, {"source": "notion"}],
- ["doc1", "doc2"])
+ document_store.write(
+ ["This is document1", "This is document2"], [{"source": "google-docs"}, {"source": "notion"}], ["doc1", "doc2"]
+ )
# 使用 add 方法添加一个文档
document_store.add("This is document3", {"source": "notion"}, "doc3")
diff --git a/tests/metagpt/document_store/test_document.py b/tests/metagpt/document_store/test_document.py
index 5ae357fb1..13c0921a3 100644
--- a/tests/metagpt/document_store/test_document.py
+++ b/tests/metagpt/document_store/test_document.py
@@ -7,22 +7,22 @@
"""
import pytest
-from metagpt.const import DATA_PATH
-from metagpt.document_store.document import Document
+from metagpt.const import METAGPT_ROOT
+from metagpt.document import IndexableDocument
CASES = [
- ("st/faq.xlsx", "Question", "Answer", 1),
- ("cases/faq.csv", "Question", "Answer", 1),
+ ("requirements.txt", None, None, 0),
+ # ("cases/faq.csv", "Question", "Answer", 1),
# ("cases/faq.json", "Question", "Answer", 1),
- ("docx/faq.docx", None, None, 1),
- ("cases/faq.pdf", None, None, 0), # 这是因为pdf默认没有分割段落
- ("cases/faq.txt", None, None, 0), # 这是因为txt按照256分割段落
+ # ("docx/faq.docx", None, None, 1),
+ # ("cases/faq.pdf", None, None, 0), # 这是因为pdf默认没有分割段落
+ # ("cases/faq.txt", None, None, 0), # 这是因为txt按照256分割段落
]
@pytest.mark.parametrize("relative_path, content_col, meta_col, threshold", CASES)
def test_document(relative_path, content_col, meta_col, threshold):
- doc = Document(DATA_PATH / relative_path, content_col, meta_col)
+ doc = IndexableDocument.from_path(METAGPT_ROOT / relative_path, content_col, meta_col)
rsp = doc.get_docs_and_metadatas()
assert len(rsp[0]) > threshold
assert len(rsp[1]) > threshold
diff --git a/tests/metagpt/document_store/test_faiss_store.py b/tests/metagpt/document_store/test_faiss_store.py
index d22d234f5..f14bee817 100644
--- a/tests/metagpt/document_store/test_faiss_store.py
+++ b/tests/metagpt/document_store/test_faiss_store.py
@@ -39,11 +39,11 @@ user: 没有了
@pytest.mark.asyncio
async def test_faiss_store_search():
- store = FaissStore(DATA_PATH / 'qcs/qcs_4w.json')
- store.add(['油皮洗面奶'])
+ store = FaissStore(DATA_PATH / "qcs/qcs_4w.json")
+ store.add(["油皮洗面奶"])
role = Sales(store=store)
- queries = ['油皮洗面奶', '介绍下欧莱雅的']
+ queries = ["油皮洗面奶", "介绍下欧莱雅的"]
for query in queries:
rsp = await role.run(query)
assert rsp
@@ -60,7 +60,10 @@ def customer_service():
async def test_faiss_store_customer_service():
allq = [
# ["我的餐怎么两小时都没到", "退货吧"],
- ["你好收不到取餐码,麻烦帮我开箱", "14750187158", ]
+ [
+ "你好收不到取餐码,麻烦帮我开箱",
+ "14750187158",
+ ]
]
role = customer_service()
for queries in allq:
@@ -71,4 +74,4 @@ async def test_faiss_store_customer_service():
def test_faiss_store_no_file():
with pytest.raises(FileNotFoundError):
- FaissStore(DATA_PATH / 'wtf.json')
+ FaissStore(DATA_PATH / "wtf.json")
diff --git a/tests/metagpt/document_store/test_lancedb_store.py b/tests/metagpt/document_store/test_lancedb_store.py
index 9c2f9fb42..5c0e40f57 100644
--- a/tests/metagpt/document_store/test_lancedb_store.py
+++ b/tests/metagpt/document_store/test_lancedb_store.py
@@ -5,27 +5,33 @@
@Author : unkn-wn (Leon Yee)
@File : test_lancedb_store.py
"""
-from metagpt.document_store.lancedb_store import LanceStore
-import pytest
import random
+import pytest
+
+from metagpt.document_store.lancedb_store import LanceStore
+
+
@pytest
def test_lance_store():
-
# This simply establishes the connection to the database, so we can drop the table if it exists
- store = LanceStore('test')
+ store = LanceStore("test")
- store.drop('test')
+ store.drop("test")
- store.write(data=[[random.random() for _ in range(100)] for _ in range(2)],
- metadatas=[{"source": "google-docs"}, {"source": "notion"}],
- ids=["doc1", "doc2"])
+ store.write(
+ data=[[random.random() for _ in range(100)] for _ in range(2)],
+ metadatas=[{"source": "google-docs"}, {"source": "notion"}],
+ ids=["doc1", "doc2"],
+ )
store.add(data=[random.random() for _ in range(100)], metadata={"source": "notion"}, _id="doc3")
result = store.search([random.random() for _ in range(100)], n_results=3)
- assert(len(result) == 3)
+ assert len(result) == 3
store.delete("doc2")
- result = store.search([random.random() for _ in range(100)], n_results=3, where="source = 'notion'", metric='cosine')
- assert(len(result) == 1)
\ No newline at end of file
+ result = store.search(
+ [random.random() for _ in range(100)], n_results=3, where="source = 'notion'", metric="cosine"
+ )
+ assert len(result) == 1
diff --git a/tests/metagpt/document_store/test_milvus_store.py b/tests/metagpt/document_store/test_milvus_store.py
index 1cf65776d..34497b9c6 100644
--- a/tests/metagpt/document_store/test_milvus_store.py
+++ b/tests/metagpt/document_store/test_milvus_store.py
@@ -12,7 +12,7 @@ import numpy as np
from metagpt.document_store.milvus_store import MilvusConnection, MilvusStore
from metagpt.logs import logger
-book_columns = {'idx': int, 'name': str, 'desc': str, 'emb': np.ndarray, 'price': float}
+book_columns = {"idx": int, "name": str, "desc": str, "emb": np.ndarray, "price": float}
book_data = [
[i for i in range(10)],
[f"book-{i}" for i in range(10)],
@@ -25,12 +25,12 @@ book_data = [
def test_milvus_store():
milvus_connection = MilvusConnection(alias="default", host="192.168.50.161", port="30530")
milvus_store = MilvusStore(milvus_connection)
- milvus_store.drop('Book')
- milvus_store.create_collection('Book', book_columns)
+ milvus_store.drop("Book")
+ milvus_store.create_collection("Book", book_columns)
milvus_store.add(book_data)
- milvus_store.build_index('emb')
+ milvus_store.build_index("emb")
milvus_store.load_collection()
- results = milvus_store.search([[1.0, 1.0]], field='emb')
+ results = milvus_store.search([[1.0, 1.0]], field="emb")
logger.info(results)
assert results
diff --git a/tests/metagpt/document_store/test_qdrant_store.py b/tests/metagpt/document_store/test_qdrant_store.py
index a63a4329d..cdd619d37 100644
--- a/tests/metagpt/document_store/test_qdrant_store.py
+++ b/tests/metagpt/document_store/test_qdrant_store.py
@@ -24,9 +24,7 @@ random.seed(seed_value)
vectors = [[random.random() for _ in range(2)] for _ in range(10)]
points = [
- PointStruct(
- id=idx, vector=vector, payload={"color": "red", "rand_number": idx % 10}
- )
+ PointStruct(id=idx, vector=vector, payload={"color": "red", "rand_number": idx % 10})
for idx, vector in enumerate(vectors)
]
@@ -57,9 +55,7 @@ def test_milvus_store():
results = qdrant_store.search(
"Book",
query=[1.0, 1.0],
- query_filter=Filter(
- must=[FieldCondition(key="rand_number", range=Range(gte=8))]
- ),
+ query_filter=Filter(must=[FieldCondition(key="rand_number", range=Range(gte=8))]),
)
assert results[0]["id"] == 8
assert results[0]["score"] == 0.9100373450784073
@@ -68,9 +64,7 @@ def test_milvus_store():
results = qdrant_store.search(
"Book",
query=[1.0, 1.0],
- query_filter=Filter(
- must=[FieldCondition(key="rand_number", range=Range(gte=8))]
- ),
+ query_filter=Filter(must=[FieldCondition(key="rand_number", range=Range(gte=8))]),
return_vector=True,
)
assert results[0]["vector"] == [0.35037919878959656, 0.9366079568862915]
diff --git a/tests/metagpt/management/test_skill_manager.py b/tests/metagpt/management/test_skill_manager.py
index b0be858a1..462bc23a6 100644
--- a/tests/metagpt/management/test_skill_manager.py
+++ b/tests/metagpt/management/test_skill_manager.py
@@ -30,7 +30,7 @@ def test_skill_manager():
rsp = manager.retrieve_skill("写测试用例")
logger.info(rsp)
- assert rsp[0] == 'WriteTest'
+ assert rsp[0] == "WriteTest"
rsp = manager.retrieve_skill_scored("写PRD")
logger.info(rsp)
diff --git a/tests/metagpt/memory/test_longterm_memory.py b/tests/metagpt/memory/test_longterm_memory.py
index dc5540520..b6ae0ac79 100644
--- a/tests/metagpt/memory/test_longterm_memory.py
+++ b/tests/metagpt/memory/test_longterm_memory.py
@@ -1,12 +1,14 @@
#!/usr/bin/env python
# -*- coding: utf-8 -*-
-# @Desc : unittest of `metagpt/memory/longterm_memory.py`
+"""
+@Desc : unittest of `metagpt/memory/longterm_memory.py`
+"""
+from metagpt.actions import UserRequirement
from metagpt.config import CONFIG
-from metagpt.schema import Message
-from metagpt.actions import BossRequirement
-from metagpt.roles.role import RoleContext
from metagpt.memory import LongTermMemory
+from metagpt.roles.role import RoleContext
+from metagpt.schema import Message
def test_ltm_search():
@@ -14,25 +16,25 @@ def test_ltm_search():
openai_api_key = CONFIG.openai_api_key
assert len(openai_api_key) > 20
- role_id = 'UTUserLtm(Product Manager)'
- rc = RoleContext(watch=[BossRequirement])
+ role_id = "UTUserLtm(Product Manager)"
+ rc = RoleContext(watch=[UserRequirement])
ltm = LongTermMemory()
ltm.recover_memory(role_id, rc)
- idea = 'Write a cli snake game'
- message = Message(role='BOSS', content=idea, cause_by=BossRequirement)
+ idea = "Write a cli snake game"
+ message = Message(role="User", content=idea, cause_by=UserRequirement)
news = ltm.find_news([message])
assert len(news) == 1
ltm.add(message)
- sim_idea = 'Write a game of cli snake'
- sim_message = Message(role='BOSS', content=sim_idea, cause_by=BossRequirement)
+ sim_idea = "Write a game of cli snake"
+ sim_message = Message(role="User", content=sim_idea, cause_by=UserRequirement)
news = ltm.find_news([sim_message])
assert len(news) == 0
ltm.add(sim_message)
- new_idea = 'Write a 2048 web game'
- new_message = Message(role='BOSS', content=new_idea, cause_by=BossRequirement)
+ new_idea = "Write a 2048 web game"
+ new_message = Message(role="User", content=new_idea, cause_by=UserRequirement)
news = ltm.find_news([new_message])
assert len(news) == 1
ltm.add(new_message)
@@ -47,8 +49,8 @@ def test_ltm_search():
news = ltm_new.find_news([sim_message])
assert len(news) == 0
- new_idea = 'Write a Battle City'
- new_message = Message(role='BOSS', content=new_idea, cause_by=BossRequirement)
+ new_idea = "Write a Battle City"
+ new_message = Message(role="User", content=new_idea, cause_by=UserRequirement)
news = ltm_new.find_news([new_message])
assert len(news) == 1
diff --git a/tests/metagpt/memory/test_memory_storage.py b/tests/metagpt/memory/test_memory_storage.py
index 6bb3e8f1d..7b74eb512 100644
--- a/tests/metagpt/memory/test_memory_storage.py
+++ b/tests/metagpt/memory/test_memory_storage.py
@@ -1,20 +1,22 @@
#!/usr/bin/env python
# -*- coding: utf-8 -*-
-# @Desc : the unittests of metagpt/memory/memory_storage.py
+"""
+@Desc : the unittests of metagpt/memory/memory_storage.py
+"""
+
from typing import List
+from metagpt.actions import UserRequirement, WritePRD
+from metagpt.actions.action_node import ActionNode
from metagpt.memory.memory_storage import MemoryStorage
from metagpt.schema import Message
-from metagpt.actions import BossRequirement
-from metagpt.actions import WritePRD
-from metagpt.actions.action_output import ActionOutput
def test_idea_message():
- idea = 'Write a cli snake game'
- role_id = 'UTUser1(Product Manager)'
- message = Message(role='BOSS', content=idea, cause_by=BossRequirement)
+ idea = "Write a cli snake game"
+ role_id = "UTUser1(Product Manager)"
+ message = Message(role="User", content=idea, cause_by=UserRequirement)
memory_storage: MemoryStorage = MemoryStorage()
messages = memory_storage.recover_memory(role_id)
@@ -23,13 +25,13 @@ def test_idea_message():
memory_storage.add(message)
assert memory_storage.is_initialized is True
- sim_idea = 'Write a game of cli snake'
- sim_message = Message(role='BOSS', content=sim_idea, cause_by=BossRequirement)
+ sim_idea = "Write a game of cli snake"
+ sim_message = Message(role="User", content=sim_idea, cause_by=UserRequirement)
new_messages = memory_storage.search(sim_message)
- assert len(new_messages) == 0 # similar, return []
+ assert len(new_messages) == 0 # similar, return []
- new_idea = 'Write a 2048 web game'
- new_message = Message(role='BOSS', content=new_idea, cause_by=BossRequirement)
+ new_idea = "Write a 2048 web game"
+ new_message = Message(role="User", content=new_idea, cause_by=UserRequirement)
new_messages = memory_storage.search(new_message)
assert new_messages[0].content == message.content
@@ -38,22 +40,15 @@ def test_idea_message():
def test_actionout_message():
- out_mapping = {
- 'field1': (str, ...),
- 'field2': (List[str], ...)
- }
- out_data = {
- 'field1': 'field1 value',
- 'field2': ['field2 value1', 'field2 value2']
- }
- ic_obj = ActionOutput.create_model_class('prd', out_mapping)
+ out_mapping = {"field1": (str, ...), "field2": (List[str], ...)}
+ out_data = {"field1": "field1 value", "field2": ["field2 value1", "field2 value2"]}
+ ic_obj = ActionNode.create_model_class("prd", out_mapping)
- role_id = 'UTUser2(Architect)'
- content = 'The boss has requested the creation of a command-line interface (CLI) snake game'
- message = Message(content=content,
- instruct_content=ic_obj(**out_data),
- role='user',
- cause_by=WritePRD) # WritePRD as test action
+ role_id = "UTUser2(Architect)"
+ content = "The user has requested the creation of a command-line interface (CLI) snake game"
+ message = Message(
+ content=content, instruct_content=ic_obj(**out_data), role="user", cause_by=WritePRD
+ ) # WritePRD as test action
memory_storage: MemoryStorage = MemoryStorage()
messages = memory_storage.recover_memory(role_id)
@@ -62,19 +57,13 @@ def test_actionout_message():
memory_storage.add(message)
assert memory_storage.is_initialized is True
- sim_conent = 'The request is command-line interface (CLI) snake game'
- sim_message = Message(content=sim_conent,
- instruct_content=ic_obj(**out_data),
- role='user',
- cause_by=WritePRD)
+ sim_conent = "The request is command-line interface (CLI) snake game"
+ sim_message = Message(content=sim_conent, instruct_content=ic_obj(**out_data), role="user", cause_by=WritePRD)
new_messages = memory_storage.search(sim_message)
- assert len(new_messages) == 0 # similar, return []
+ assert len(new_messages) == 0 # similar, return []
- new_conent = 'Incorporate basic features of a snake game such as scoring and increasing difficulty'
- new_message = Message(content=new_conent,
- instruct_content=ic_obj(**out_data),
- role='user',
- cause_by=WritePRD)
+ new_conent = "Incorporate basic features of a snake game such as scoring and increasing difficulty"
+ new_message = Message(content=new_conent, instruct_content=ic_obj(**out_data), role="user", cause_by=WritePRD)
new_messages = memory_storage.search(new_message)
assert new_messages[0].content == message.content
diff --git a/tests/metagpt/planner/test_action_planner.py b/tests/metagpt/planner/test_action_planner.py
index 5ab9a493f..1bc451db8 100644
--- a/tests/metagpt/planner/test_action_planner.py
+++ b/tests/metagpt/planner/test_action_planner.py
@@ -4,12 +4,14 @@
@Time : 2023/9/16 20:03
@Author : femto Zheng
@File : test_basic_planner.py
+@Modified By: mashenquan, 2023-11-1. In accordance with Chapter 2.2.1 and 2.2.2 of RFC 116, utilize the new message
+ distribution feature for message handling.
"""
import pytest
from semantic_kernel.core_skills import FileIOSkill, MathSkill, TextSkill, TimeSkill
from semantic_kernel.planning.action_planner.action_planner import ActionPlanner
-from metagpt.actions import BossRequirement
+from metagpt.actions import UserRequirement
from metagpt.roles.sk_agent import SkAgent
from metagpt.schema import Message
@@ -23,7 +25,8 @@ async def test_action_planner():
role.import_skill(TimeSkill(), "time")
role.import_skill(TextSkill(), "text")
task = "What is the sum of 110 and 990?"
- role.recv(Message(content=task, cause_by=BossRequirement))
+ role.put_message(Message(content=task, cause_by=UserRequirement))
+ await role._observe()
await role._think() # it will choose mathskill.Add
assert "1100" == (await role._act()).content
diff --git a/tests/metagpt/planner/test_basic_planner.py b/tests/metagpt/planner/test_basic_planner.py
index 03a82ec5e..f406143ee 100644
--- a/tests/metagpt/planner/test_basic_planner.py
+++ b/tests/metagpt/planner/test_basic_planner.py
@@ -4,11 +4,13 @@
@Time : 2023/9/16 20:03
@Author : femto Zheng
@File : test_basic_planner.py
+@Modified By: mashenquan, 2023-11-1. In accordance with Chapter 2.2.1 and 2.2.2 of RFC 116, utilize the new message
+ distribution feature for message handling.
"""
import pytest
from semantic_kernel.core_skills import TextSkill
-from metagpt.actions import BossRequirement
+from metagpt.actions import UserRequirement
from metagpt.const import SKILL_DIRECTORY
from metagpt.roles.sk_agent import SkAgent
from metagpt.schema import Message
@@ -26,7 +28,8 @@ async def test_basic_planner():
role.import_semantic_skill_from_directory(SKILL_DIRECTORY, "WriterSkill")
role.import_skill(TextSkill(), "TextSkill")
# using BasicPlanner
- role.recv(Message(content=task, cause_by=BossRequirement))
+ role.put_message(Message(content=task, cause_by=UserRequirement))
+ await role._observe()
await role._think()
# assuming sk_agent will think he needs WriterSkill.Brainstorm and WriterSkill.Translate
assert "WriterSkill.Brainstorm" in role.plan.generated_plan.result
diff --git a/tests/metagpt/provider/test_base_gpt_api.py b/tests/metagpt/provider/test_base_gpt_api.py
index 882338a01..6cfe3b02d 100644
--- a/tests/metagpt/provider/test_base_gpt_api.py
+++ b/tests/metagpt/provider/test_base_gpt_api.py
@@ -10,6 +10,6 @@ from metagpt.schema import Message
def test_message():
- message = Message(role='user', content='wtf')
- assert 'role' in message.to_dict()
- assert 'user' in str(message)
+ message = Message(role="user", content="wtf")
+ assert "role" in message.to_dict()
+ assert "user" in str(message)
diff --git a/tests/metagpt/provider/test_spark_api.py b/tests/metagpt/provider/test_spark_api.py
index bfa2bf76f..3b3dd67f4 100644
--- a/tests/metagpt/provider/test_spark_api.py
+++ b/tests/metagpt/provider/test_spark_api.py
@@ -6,6 +6,6 @@ def test_message():
llm = SparkAPI()
logger.info(llm.ask('只回答"收到了"这三个字。'))
- result = llm.ask('写一篇五百字的日记')
+ result = llm.ask("写一篇五百字的日记")
logger.info(result)
assert len(result) > 100
diff --git a/tests/metagpt/roles/mock.py b/tests/metagpt/roles/mock.py
index 52fc4a3c1..75f6b3b43 100644
--- a/tests/metagpt/roles/mock.py
+++ b/tests/metagpt/roles/mock.py
@@ -5,10 +5,10 @@
@Author : alexanderwu
@File : mock.py
"""
-from metagpt.actions import BossRequirement, WriteDesign, WritePRD, WriteTasks
+from metagpt.actions import UserRequirement, WriteDesign, WritePRD, WriteTasks
from metagpt.schema import Message
-BOSS_REQUIREMENT = """开发一个基于大语言模型与私有知识库的搜索引擎,希望可以基于大语言模型进行搜索总结"""
+USER_REQUIREMENT = """开发一个基于大语言模型与私有知识库的搜索引擎,希望可以基于大语言模型进行搜索总结"""
DETAIL_REQUIREMENT = """需求:开发一个基于LLM(大语言模型)与私有知识库的搜索引擎,希望有几点能力
1. 用户可以在私有知识库进行搜索,再根据大语言模型进行总结,输出的结果包括了总结
@@ -71,7 +71,7 @@ PRD = '''## 原始需求
```
'''
-SYSTEM_DESIGN = '''## Python package name
+SYSTEM_DESIGN = """## Project name
```python
"smart_search_engine"
```
@@ -94,7 +94,7 @@ SYSTEM_DESIGN = '''## Python package name
]
```
-## Data structures and interface definitions
+## Data structures and interfaces
```mermaid
classDiagram
class Main {
@@ -149,10 +149,10 @@ sequenceDiagram
S-->>SE: return summary
SE-->>M: return summary
```
-'''
+"""
-TASKS = '''## Logic Analysis
+TASKS = """## Logic Analysis
在这个项目中,所有的模块都依赖于“SearchEngine”类,这是主入口,其他的模块(Index、Ranking和Summary)都通过它交互。另外,"Index"类又依赖于"KnowledgeBase"类,因为它需要从知识库中获取数据。
@@ -181,7 +181,7 @@ task_list = [
]
```
这个任务列表首先定义了最基础的模块,然后是依赖这些模块的模块,最后是辅助模块。可以根据团队的能力和资源,同时开发多个任务,只要满足依赖关系。例如,在开发"search.py"之前,可以同时开发"knowledge_base.py"、"index.py"、"ranking.py"和"summary.py"。
-'''
+"""
TASKS_TOMATO_CLOCK = '''## Required Python third-party packages: Provided in requirements.txt format
@@ -224,35 +224,35 @@ task_list = [
TASK = """smart_search_engine/knowledge_base.py"""
STRS_FOR_PARSING = [
-"""
+ """
## 1
```python
a
```
""",
-"""
+ """
##2
```python
"a"
```
""",
-"""
+ """
## 3
```python
a = "a"
```
""",
-"""
+ """
## 4
```python
a = 'a'
```
-"""
+""",
]
class MockMessages:
- req = Message(role="Boss", content=BOSS_REQUIREMENT, cause_by=BossRequirement)
+ req = Message(role="User", content=USER_REQUIREMENT, cause_by=UserRequirement)
prd = Message(role="Product Manager", content=PRD, cause_by=WritePRD)
system_design = Message(role="Architect", content=SYSTEM_DESIGN, cause_by=WriteDesign)
tasks = Message(role="Project Manager", content=TASKS, cause_by=WriteTasks)
diff --git a/tests/metagpt/roles/test_architect.py b/tests/metagpt/roles/test_architect.py
index d44e0d923..111438b0b 100644
--- a/tests/metagpt/roles/test_architect.py
+++ b/tests/metagpt/roles/test_architect.py
@@ -4,6 +4,8 @@
@Time : 2023/5/20 14:37
@Author : alexanderwu
@File : test_architect.py
+@Modified By: mashenquan, 2023-11-1. In accordance with Chapter 2.2.1 and 2.2.2 of RFC 116, utilize the new message
+ distribution feature for message handling.
"""
import pytest
@@ -15,7 +17,7 @@ from tests.metagpt.roles.mock import MockMessages
@pytest.mark.asyncio
async def test_architect():
role = Architect()
- role.recv(MockMessages.req)
- rsp = await role.handle(MockMessages.prd)
+ role.put_message(MockMessages.req)
+ rsp = await role.run(MockMessages.prd)
logger.info(rsp)
assert len(rsp.content) > 0
diff --git a/tests/metagpt/roles/test_engineer.py b/tests/metagpt/roles/test_engineer.py
index c0c48d0b1..3dc599770 100644
--- a/tests/metagpt/roles/test_engineer.py
+++ b/tests/metagpt/roles/test_engineer.py
@@ -4,6 +4,8 @@
@Time : 2023/5/12 10:14
@Author : alexanderwu
@File : test_engineer.py
+@Modified By: mashenquan, 2023-11-1. In accordance with Chapter 2.2.1 and 2.2.2 of RFC 116, utilize the new message
+ distribution feature for message handling.
"""
import pytest
@@ -22,10 +24,10 @@ from tests.metagpt.roles.mock import (
async def test_engineer():
engineer = Engineer()
- engineer.recv(MockMessages.req)
- engineer.recv(MockMessages.prd)
- engineer.recv(MockMessages.system_design)
- rsp = await engineer.handle(MockMessages.tasks)
+ engineer.put_message(MockMessages.req)
+ engineer.put_message(MockMessages.prd)
+ engineer.put_message(MockMessages.system_design)
+ rsp = await engineer.run(MockMessages.tasks)
logger.info(rsp)
assert "all done." == rsp.content
@@ -35,13 +37,13 @@ def test_parse_str():
for idx, i in enumerate(STRS_FOR_PARSING):
text = CodeParser.parse_str(f"{idx+1}", i)
# logger.info(text)
- assert text == 'a'
+ assert text == "a"
def test_parse_blocks():
tasks = CodeParser.parse_blocks(TASKS)
logger.info(tasks.keys())
- assert 'Task list' in tasks.keys()
+ assert "Task list" in tasks.keys()
target_list = [
diff --git a/tests/metagpt/roles/test_invoice_ocr_assistant.py b/tests/metagpt/roles/test_invoice_ocr_assistant.py
index 75097e73c..c9aad93a7 100644
--- a/tests/metagpt/roles/test_invoice_ocr_assistant.py
+++ b/tests/metagpt/roles/test_invoice_ocr_assistant.py
@@ -9,8 +9,8 @@
from pathlib import Path
-import pytest
import pandas as pd
+import pytest
from metagpt.roles.invoice_ocr_assistant import InvoiceOCRAssistant
from metagpt.schema import Message
@@ -24,82 +24,39 @@ from metagpt.schema import Message
"Invoicing date",
Path("../../data/invoices/invoice-1.pdf"),
Path("../../../data/invoice_table/invoice-1.xlsx"),
- [
- {
- "收款人": "小明",
- "城市": "深圳市",
- "总费用/元": 412.00,
- "开票日期": "2023年02月03日"
- }
- ]
+ [{"收款人": "小明", "城市": "深圳市", "总费用/元": 412.00, "开票日期": "2023年02月03日"}],
),
(
"Invoicing date",
Path("../../data/invoices/invoice-2.png"),
Path("../../../data/invoice_table/invoice-2.xlsx"),
- [
- {
- "收款人": "铁头",
- "城市": "广州市",
- "总费用/元": 898.00,
- "开票日期": "2023年03月17日"
- }
- ]
+ [{"收款人": "铁头", "城市": "广州市", "总费用/元": 898.00, "开票日期": "2023年03月17日"}],
),
(
"Invoicing date",
Path("../../data/invoices/invoice-3.jpg"),
Path("../../../data/invoice_table/invoice-3.xlsx"),
- [
- {
- "收款人": "夏天",
- "城市": "福州市",
- "总费用/元": 2462.00,
- "开票日期": "2023年08月26日"
- }
- ]
+ [{"收款人": "夏天", "城市": "福州市", "总费用/元": 2462.00, "开票日期": "2023年08月26日"}],
),
(
"Invoicing date",
Path("../../data/invoices/invoice-4.zip"),
Path("../../../data/invoice_table/invoice-4.xlsx"),
[
- {
- "收款人": "小明",
- "城市": "深圳市",
- "总费用/元": 412.00,
- "开票日期": "2023年02月03日"
- },
- {
- "收款人": "铁头",
- "城市": "广州市",
- "总费用/元": 898.00,
- "开票日期": "2023年03月17日"
- },
- {
- "收款人": "夏天",
- "城市": "福州市",
- "总费用/元": 2462.00,
- "开票日期": "2023年08月26日"
- }
- ]
+ {"收款人": "小明", "城市": "深圳市", "总费用/元": 412.00, "开票日期": "2023年02月03日"},
+ {"收款人": "铁头", "城市": "广州市", "总费用/元": 898.00, "开票日期": "2023年03月17日"},
+ {"收款人": "夏天", "城市": "福州市", "总费用/元": 2462.00, "开票日期": "2023年08月26日"},
+ ],
),
- ]
+ ],
)
async def test_invoice_ocr_assistant(
- query: str,
- invoice_path: Path,
- invoice_table_path: Path,
- expected_result: list[dict]
+ query: str, invoice_path: Path, invoice_table_path: Path, expected_result: list[dict]
):
invoice_path = Path.cwd() / invoice_path
role = InvoiceOCRAssistant()
- await role.run(Message(
- content=query,
- instruct_content={"file_path": invoice_path}
- ))
+ await role.run(Message(content=query, instruct_content={"file_path": invoice_path}))
invoice_table_path = Path.cwd() / invoice_table_path
df = pd.read_excel(invoice_table_path)
- dict_result = df.to_dict(orient='records')
+ dict_result = df.to_dict(orient="records")
assert dict_result == expected_result
-
diff --git a/tests/metagpt/roles/test_researcher.py b/tests/metagpt/roles/test_researcher.py
index 01b5dae3b..dd130662d 100644
--- a/tests/metagpt/roles/test_researcher.py
+++ b/tests/metagpt/roles/test_researcher.py
@@ -11,10 +11,12 @@ async def mock_llm_ask(self, prompt: str, system_msgs):
if "Please provide up to 2 necessary keywords" in prompt:
return '["dataiku", "datarobot"]'
elif "Provide up to 4 queries related to your research topic" in prompt:
- return '["Dataiku machine learning platform", "DataRobot AI platform comparison", ' \
+ return (
+ '["Dataiku machine learning platform", "DataRobot AI platform comparison", '
'"Dataiku vs DataRobot features", "Dataiku and DataRobot use cases"]'
+ )
elif "sort the remaining search results" in prompt:
- return '[1,2]'
+ return "[1,2]"
elif "Not relevant." in prompt:
return "Not relevant" if random() > 0.5 else prompt[-100:]
elif "provide a detailed research report" in prompt:
diff --git a/tests/metagpt/roles/test_role.py b/tests/metagpt/roles/test_role.py
new file mode 100644
index 000000000..72cd84a9a
--- /dev/null
+++ b/tests/metagpt/roles/test_role.py
@@ -0,0 +1,11 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+# @Desc : unittest of Role
+
+from metagpt.roles.role import Role
+
+
+def test_role_desc():
+ role = Role(profile="Sales", desc="Best Seller")
+ assert role.profile == "Sales"
+ assert role._setting.desc == "Best Seller"
diff --git a/tests/metagpt/roles/test_tutorial_assistant.py b/tests/metagpt/roles/test_tutorial_assistant.py
index 945620cfc..105f976c3 100644
--- a/tests/metagpt/roles/test_tutorial_assistant.py
+++ b/tests/metagpt/roles/test_tutorial_assistant.py
@@ -12,10 +12,7 @@ from metagpt.roles.tutorial_assistant import TutorialAssistant
@pytest.mark.asyncio
-@pytest.mark.parametrize(
- ("language", "topic"),
- [("Chinese", "Write a tutorial about Python")]
-)
+@pytest.mark.parametrize(("language", "topic"), [("Chinese", "Write a tutorial about Python")])
async def test_tutorial_assistant(language: str, topic: str):
topic = "Write a tutorial about MySQL"
role = TutorialAssistant(language=language)
@@ -24,4 +21,4 @@ async def test_tutorial_assistant(language: str, topic: str):
title = filename.split("/")[-1].split(".")[0]
async with aiofiles.open(filename, mode="r") as reader:
content = await reader.read()
- assert content.startswith(f"# {title}")
\ No newline at end of file
+ assert content.startswith(f"# {title}")
diff --git a/tests/metagpt/roles/test_ui.py b/tests/metagpt/roles/test_ui.py
index d58d31bd9..2038a1aee 100644
--- a/tests/metagpt/roles/test_ui.py
+++ b/tests/metagpt/roles/test_ui.py
@@ -1,10 +1,9 @@
# -*- coding: utf-8 -*-
# @Date : 2023/7/22 02:40
-# @Author : stellahong (stellahong@fuzhi.ai)
+# @Author : stellahong (stellahong@deepwisdom.ai)
#
-from metagpt.team import Team
from metagpt.roles import ProductManager
-
+from metagpt.team import Team
from tests.metagpt.roles.ui_role import UI
@@ -18,5 +17,5 @@ async def test_ui_role(idea: str, investment: float = 3.0, n_round: int = 5):
company = Team()
company.hire([ProductManager(), UI()])
company.invest(investment)
- company.start_project(idea)
+ company.run_project(idea)
await company.run(n_round=n_round)
diff --git a/tests/metagpt/roles/ui_role.py b/tests/metagpt/roles/ui_role.py
index a45a89cde..0932efa1f 100644
--- a/tests/metagpt/roles/ui_role.py
+++ b/tests/metagpt/roles/ui_role.py
@@ -1,6 +1,6 @@
# -*- coding: utf-8 -*-
# @Date : 2023/7/15 16:40
-# @Author : stellahong (stellahong@fuzhi.ai)
+# @Author : stellahong (stellahong@deepwisdom.ai)
# @Desc :
import os
import re
@@ -8,51 +8,48 @@ from functools import wraps
from importlib import import_module
from metagpt.actions import Action, ActionOutput, WritePRD
-from metagpt.const import WORKSPACE_ROOT
+
+# from metagpt.const import WORKSPACE_ROOT
+from metagpt.actions.action_node import ActionNode
+from metagpt.config import CONFIG
from metagpt.logs import logger
from metagpt.roles import Role
from metagpt.schema import Message
from metagpt.tools.sd_engine import SDEngine
PROMPT_TEMPLATE = """
-# Context
{context}
-## Format example
-{format_example}
------
-Role: You are a UserInterface Designer; the goal is to finish a UI design according to PRD, give a design description, and select specified elements and UI style.
-Requirements: Based on the context, fill in the following missing information, provide detailed HTML and CSS code
-Attention: Use '##' to split sections, not '#', and '## ' SHOULD WRITE BEFORE the code and triple quote.
-
-## UI Design Description:Provide as Plain text, place the design objective here
-## Selected Elements:Provide as Plain text, up to 5 specified elements, clear and simple
-## HTML Layout:Provide as Plain text, use standard HTML code
-## CSS Styles (styles.css):Provide as Plain text,use standard css code
-## Anything UNCLEAR:Provide as Plain text. Make clear here.
-
+## Role
+You are a UserInterface Designer; the goal is to finish a UI design according to PRD, give a design description, and select specified elements and UI style.
"""
-FORMAT_EXAMPLE = """
+UI_DESIGN_DESC = ActionNode(
+ key="UI Design Desc",
+ expected_type=str,
+ instruction="place the design objective here",
+ example="Snake games are classic and addictive games with simple yet engaging elements. Here are the main elements"
+ " commonly found in snake games",
+)
-## UI Design Description
-```Snake games are classic and addictive games with simple yet engaging elements. Here are the main elements commonly found in snake games ```
+SELECTED_ELEMENTS = ActionNode(
+ key="Selected Elements",
+ expected_type=list[str],
+ instruction="up to 5 specified elements, clear and simple",
+ example=[
+ "Game Grid: The game grid is a rectangular...",
+ "Snake: The player controls a snake that moves across the grid...",
+ "Food: Food items (often represented as small objects or differently colored blocks)",
+ "Score: The player's score increases each time the snake eats a piece of food. The longer the snake becomes, the higher the score.",
+ "Game Over: The game ends when the snake collides with itself or an obstacle. At this point, the player's final score is displayed, and they are given the option to restart the game.",
+ ],
+)
-## Selected Elements
-
-Game Grid: The game grid is a rectangular...
-
-Snake: The player controls a snake that moves across the grid...
-
-Food: Food items (often represented as small objects or differently colored blocks)
-
-Score: The player's score increases each time the snake eats a piece of food. The longer the snake becomes, the higher the score.
-
-Game Over: The game ends when the snake collides with itself or an obstacle. At this point, the player's final score is displayed, and they are given the option to restart the game.
-
-
-## HTML Layout
-
+HTML_LAYOUT = ActionNode(
+ key="HTML Layout",
+ expected_type=str,
+ instruction="use standard HTML code",
+ example="""
@@ -69,9 +66,14 @@ Game Over: The game ends when the snake collides with itself or an obstacle. At
+""",
+)
-## CSS Styles (styles.css)
-body {
+CSS_STYLES = ActionNode(
+ key="CSS Styles",
+ expected_type=str,
+ instruction="use standard css code",
+ example="""body {
display: flex;
justify-content: center;
align-items: center;
@@ -119,19 +121,25 @@ body {
color: #ff0000;
display: none;
}
+""",
+)
-## Anything UNCLEAR
-There are no unclear points.
+ANYTHING_UNCLEAR = ActionNode(
+ key="Anything UNCLEAR",
+ expected_type=str,
+ instruction="Mention any aspects of the project that are unclear and try to clarify them.",
+ example="...",
+)
-"""
+NODES = [
+ UI_DESIGN_DESC,
+ SELECTED_ELEMENTS,
+ HTML_LAYOUT,
+ CSS_STYLES,
+ ANYTHING_UNCLEAR,
+]
-OUTPUT_MAPPING = {
- "UI Design Description": (str, ...),
- "Selected Elements": (str, ...),
- "HTML Layout": (str, ...),
- "CSS Styles (styles.css)": (str, ...),
- "Anything UNCLEAR": (str, ...),
-}
+UI_DESIGN_NODE = ActionNode.from_children("UI_DESIGN", NODES)
def load_engine(func):
@@ -214,17 +222,15 @@ class UIDesign(Action):
logger.info("Finish icon design using StableDiffusion API")
async def _save(self, css_content, html_content):
- save_dir = WORKSPACE_ROOT / "resources" / "codes"
+ save_dir = CONFIG.workspace_path / "resources" / "codes"
if not os.path.exists(save_dir):
os.makedirs(save_dir, exist_ok=True)
# Save CSS and HTML content to files
css_file_path = save_dir / "ui_design.css"
html_file_path = save_dir / "ui_design.html"
- with open(css_file_path, "w") as css_file:
- css_file.write(css_content)
- with open(html_file_path, "w") as html_file:
- html_file.write(html_content)
+ css_file_path.write_text(css_content)
+ html_file_path.write_text(html_content)
async def run(self, requirements: list[Message], *args, **kwargs) -> ActionOutput:
"""Run the UI Design action."""
@@ -232,9 +238,9 @@ class UIDesign(Action):
context = requirements[-1].content
ui_design_draft = self.parse_requirement(context=context)
# todo: parse requirements str
- prompt = PROMPT_TEMPLATE.format(context=ui_design_draft, format_example=FORMAT_EXAMPLE)
+ prompt = PROMPT_TEMPLATE.format(context=ui_design_draft)
logger.info(prompt)
- ui_describe = await self._aask_v1(prompt, "ui_design", OUTPUT_MAPPING)
+ ui_describe = await UI_DESIGN_NODE.fill(prompt)
logger.info(ui_describe.content)
logger.info(ui_describe.instruct_content)
css = self.parse_css_code(context=ui_describe.content)
diff --git a/tests/metagpt/serialize_deserialize/__init__.py b/tests/metagpt/serialize_deserialize/__init__.py
new file mode 100644
index 000000000..78f454fb5
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/__init__.py
@@ -0,0 +1,4 @@
+# -*- coding: utf-8 -*-
+# @Date : 11/22/2023 11:48 AM
+# @Author : stellahong (stellahong@fuzhi.ai)
+# @Desc :
diff --git a/tests/metagpt/serialize_deserialize/test_action.py b/tests/metagpt/serialize_deserialize/test_action.py
new file mode 100644
index 000000000..14d558c13
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_action.py
@@ -0,0 +1,27 @@
+# -*- coding: utf-8 -*-
+# @Date : 11/22/2023 11:48 AM
+# @Author : stellahong (stellahong@fuzhi.ai)
+# @Desc :
+import pytest
+
+from metagpt.actions import Action
+from metagpt.llm import LLM
+
+
+def test_action_serialize():
+ action = Action()
+ ser_action_dict = action.dict()
+ assert "name" in ser_action_dict
+ # assert "llm" not in ser_action_dict # not export
+
+
+@pytest.mark.asyncio
+async def test_action_deserialize():
+ action = Action()
+ serialized_data = action.dict()
+
+ new_action = Action(**serialized_data)
+
+ assert new_action.name == ""
+ assert new_action.llm == LLM()
+ assert len(await new_action._aask("who are you")) > 0
diff --git a/tests/metagpt/serialize_deserialize/test_architect_deserialize.py b/tests/metagpt/serialize_deserialize/test_architect_deserialize.py
new file mode 100644
index 000000000..b92eba8a1
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_architect_deserialize.py
@@ -0,0 +1,28 @@
+# -*- coding: utf-8 -*-
+# @Date : 11/26/2023 2:04 PM
+# @Author : stellahong (stellahong@fuzhi.ai)
+# @Desc :
+import pytest
+
+from metagpt.actions.action import Action
+from metagpt.roles.architect import Architect
+
+
+def test_architect_serialize():
+ role = Architect()
+ ser_role_dict = role.dict(by_alias=True)
+ assert "name" in ser_role_dict
+ assert "_states" in ser_role_dict
+ assert "_actions" in ser_role_dict
+
+
+@pytest.mark.asyncio
+async def test_architect_deserialize():
+ role = Architect()
+ ser_role_dict = role.dict(by_alias=True)
+ new_role = Architect(**ser_role_dict)
+ # new_role = Architect.deserialize(ser_role_dict)
+ assert new_role.name == "Bob"
+ assert len(new_role._actions) == 1
+ assert isinstance(new_role._actions[0], Action)
+ await new_role._actions[0].run(with_messages="write a cli snake game")
diff --git a/tests/metagpt/serialize_deserialize/test_environment.py b/tests/metagpt/serialize_deserialize/test_environment.py
new file mode 100644
index 000000000..096c1dd68
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_environment.py
@@ -0,0 +1,88 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+# @Desc :
+
+import shutil
+
+from metagpt.actions.action_node import ActionNode
+from metagpt.actions.add_requirement import UserRequirement
+from metagpt.actions.project_management import WriteTasks
+from metagpt.environment import Environment
+from metagpt.roles.project_manager import ProjectManager
+from metagpt.schema import Message
+from metagpt.utils.common import any_to_str
+from tests.metagpt.serialize_deserialize.test_serdeser_base import (
+ ActionOK,
+ RoleC,
+ serdeser_path,
+)
+
+
+def test_env_serialize():
+ env = Environment()
+ ser_env_dict = env.dict()
+ assert "roles" in ser_env_dict
+
+
+def test_env_deserialize():
+ env = Environment()
+ env.publish_message(message=Message(content="test env serialize"))
+ ser_env_dict = env.dict()
+ new_env = Environment(**ser_env_dict)
+ assert len(new_env.roles) == 0
+ assert len(new_env.history) == 25
+
+
+def test_environment_serdeser():
+ out_mapping = {"field1": (list[str], ...)}
+ out_data = {"field1": ["field1 value1", "field1 value2"]}
+ ic_obj = ActionNode.create_model_class("prd", out_mapping)
+
+ message = Message(
+ content="prd", instruct_content=ic_obj(**out_data), role="product manager", cause_by=any_to_str(UserRequirement)
+ )
+
+ environment = Environment()
+ role_c = RoleC()
+ environment.add_role(role_c)
+ environment.publish_message(message)
+
+ ser_data = environment.dict()
+ assert ser_data["roles"]["Role C"]["name"] == "RoleC"
+
+ new_env: Environment = Environment(**ser_data)
+ assert len(new_env.roles) == 1
+
+ assert list(new_env.roles.values())[0]._states == list(environment.roles.values())[0]._states
+ assert list(new_env.roles.values())[0]._actions == list(environment.roles.values())[0]._actions
+ assert isinstance(list(environment.roles.values())[0]._actions[0], ActionOK)
+ assert type(list(new_env.roles.values())[0]._actions[0]) == ActionOK
+
+
+def test_environment_serdeser_v2():
+ environment = Environment()
+ pm = ProjectManager()
+ environment.add_role(pm)
+
+ ser_data = environment.dict()
+
+ new_env: Environment = Environment(**ser_data)
+ role = new_env.get_role(pm.profile)
+ assert isinstance(role, ProjectManager)
+ assert isinstance(role._actions[0], WriteTasks)
+ assert isinstance(list(new_env.roles.values())[0]._actions[0], WriteTasks)
+
+
+def test_environment_serdeser_save():
+ environment = Environment()
+ role_c = RoleC()
+
+ shutil.rmtree(serdeser_path.joinpath("team"), ignore_errors=True)
+
+ stg_path = serdeser_path.joinpath("team", "environment")
+ environment.add_role(role_c)
+ environment.serialize(stg_path)
+
+ new_env: Environment = Environment.deserialize(stg_path)
+ assert len(new_env.roles) == 1
+ assert type(list(new_env.roles.values())[0]._actions[0]) == ActionOK
diff --git a/tests/metagpt/serialize_deserialize/test_memory.py b/tests/metagpt/serialize_deserialize/test_memory.py
new file mode 100644
index 000000000..5a40f5c3b
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_memory.py
@@ -0,0 +1,63 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+# @Desc : unittest of memory
+
+from pydantic import BaseModel
+
+from metagpt.actions.action_node import ActionNode
+from metagpt.actions.add_requirement import UserRequirement
+from metagpt.actions.design_api import WriteDesign
+from metagpt.memory.memory import Memory
+from metagpt.schema import Message
+from metagpt.utils.common import any_to_str
+from tests.metagpt.serialize_deserialize.test_serdeser_base import serdeser_path
+
+
+def test_memory_serdeser():
+ msg1 = Message(role="Boss", content="write a snake game", cause_by=UserRequirement)
+
+ out_mapping = {"field2": (list[str], ...)}
+ out_data = {"field2": ["field2 value1", "field2 value2"]}
+ ic_obj = ActionNode.create_model_class("system_design", out_mapping)
+ msg2 = Message(
+ role="Architect", instruct_content=ic_obj(**out_data), content="system design content", cause_by=WriteDesign
+ )
+
+ memory = Memory()
+ memory.add_batch([msg1, msg2])
+ ser_data = memory.dict()
+
+ new_memory = Memory(**ser_data)
+ assert new_memory.count() == 2
+ new_msg2 = new_memory.get(2)[0]
+ assert isinstance(new_msg2, BaseModel)
+ assert isinstance(new_memory.storage[-1], BaseModel)
+ assert new_memory.storage[-1].cause_by == any_to_str(WriteDesign)
+ assert new_msg2.role == "Boss"
+
+
+def test_memory_serdeser_save():
+ msg1 = Message(role="User", content="write a 2048 game", cause_by=UserRequirement)
+
+ out_mapping = {"field1": (list[str], ...)}
+ out_data = {"field1": ["field1 value1", "field1 value2"]}
+ ic_obj = ActionNode.create_model_class("system_design", out_mapping)
+ msg2 = Message(
+ role="Architect", instruct_content=ic_obj(**out_data), content="system design content", cause_by=WriteDesign
+ )
+
+ memory = Memory()
+ memory.add_batch([msg1, msg2])
+
+ stg_path = serdeser_path.joinpath("team", "environment")
+ memory.serialize(stg_path)
+ assert stg_path.joinpath("memory.json").exists()
+
+ new_memory = Memory.deserialize(stg_path)
+ assert new_memory.count() == 2
+ new_msg2 = new_memory.get(1)[0]
+ assert new_msg2.instruct_content.field1 == ["field1 value1", "field1 value2"]
+ assert new_msg2.cause_by == any_to_str(WriteDesign)
+ assert len(new_memory.index) == 2
+
+ stg_path.joinpath("memory.json").unlink()
diff --git a/tests/metagpt/serialize_deserialize/test_product_manager.py b/tests/metagpt/serialize_deserialize/test_product_manager.py
new file mode 100644
index 000000000..b65e329d1
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_product_manager.py
@@ -0,0 +1,21 @@
+# -*- coding: utf-8 -*-
+# @Date : 11/26/2023 2:07 PM
+# @Author : stellahong (stellahong@fuzhi.ai)
+# @Desc :
+import pytest
+
+from metagpt.actions.action import Action
+from metagpt.roles.product_manager import ProductManager
+from metagpt.schema import Message
+
+
+@pytest.mark.asyncio
+async def test_product_manager_deserialize():
+ role = ProductManager()
+ ser_role_dict = role.dict(by_alias=True)
+ new_role = ProductManager(**ser_role_dict)
+
+ assert new_role.name == "Alice"
+ assert len(new_role._actions) == 2
+ assert isinstance(new_role._actions[0], Action)
+ await new_role._actions[0].run([Message(content="write a cli snake game")])
diff --git a/tests/metagpt/serialize_deserialize/test_project_manager.py b/tests/metagpt/serialize_deserialize/test_project_manager.py
new file mode 100644
index 000000000..e52e3f247
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_project_manager.py
@@ -0,0 +1,30 @@
+# -*- coding: utf-8 -*-
+# @Date : 11/26/2023 2:06 PM
+# @Author : stellahong (stellahong@fuzhi.ai)
+# @Desc :
+import pytest
+
+from metagpt.actions.action import Action
+from metagpt.actions.project_management import WriteTasks
+from metagpt.roles.project_manager import ProjectManager
+
+
+def test_project_manager_serialize():
+ role = ProjectManager()
+ ser_role_dict = role.dict(by_alias=True)
+ assert "name" in ser_role_dict
+ assert "_states" in ser_role_dict
+ assert "_actions" in ser_role_dict
+
+
+@pytest.mark.asyncio
+async def test_project_manager_deserialize():
+ role = ProjectManager()
+ ser_role_dict = role.dict(by_alias=True)
+
+ new_role = ProjectManager(**ser_role_dict)
+ assert new_role.name == "Eve"
+ assert len(new_role._actions) == 1
+ assert isinstance(new_role._actions[0], Action)
+ assert isinstance(new_role._actions[0], WriteTasks)
+ # await new_role._actions[0].run(context="write a cli snake game")
diff --git a/tests/metagpt/serialize_deserialize/test_role.py b/tests/metagpt/serialize_deserialize/test_role.py
new file mode 100644
index 000000000..72da8a6fc
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_role.py
@@ -0,0 +1,96 @@
+# -*- coding: utf-8 -*-
+# @Date : 11/23/2023 4:49 PM
+# @Author : stellahong (stellahong@fuzhi.ai)
+# @Desc :
+
+import shutil
+
+import pytest
+
+from metagpt.actions import WriteCode
+from metagpt.actions.add_requirement import UserRequirement
+from metagpt.const import SERDESER_PATH
+from metagpt.logs import logger
+from metagpt.roles.engineer import Engineer
+from metagpt.roles.product_manager import ProductManager
+from metagpt.roles.role import Role
+from metagpt.schema import Message
+from metagpt.utils.common import format_trackback_info
+from tests.metagpt.serialize_deserialize.test_serdeser_base import (
+ RoleA,
+ RoleB,
+ RoleC,
+ serdeser_path,
+)
+
+
+def test_roles():
+ role_a = RoleA()
+ assert len(role_a._rc.watch) == 1
+ role_b = RoleB()
+ assert len(role_a._rc.watch) == 1
+ assert len(role_b._rc.watch) == 1
+
+
+def test_role_serialize():
+ role = Role()
+ ser_role_dict = role.dict(by_alias=True)
+ assert "name" in ser_role_dict
+ assert "_states" in ser_role_dict
+ assert "_actions" in ser_role_dict
+
+
+def test_engineer_serialize():
+ role = Engineer()
+ ser_role_dict = role.dict(by_alias=True)
+ assert "name" in ser_role_dict
+ assert "_states" in ser_role_dict
+ assert "_actions" in ser_role_dict
+
+
+@pytest.mark.asyncio
+async def test_engineer_deserialize():
+ role = Engineer(use_code_review=True)
+ ser_role_dict = role.dict(by_alias=True)
+
+ new_role = Engineer(**ser_role_dict)
+ assert new_role.name == "Alex"
+ assert new_role.use_code_review is True
+ assert len(new_role._actions) == 1
+ assert isinstance(new_role._actions[0], WriteCode)
+ # await new_role._actions[0].run(context="write a cli snake game", filename="test_code")
+
+
+def test_role_serdeser_save():
+ stg_path_prefix = serdeser_path.joinpath("team", "environment", "roles")
+ shutil.rmtree(serdeser_path.joinpath("team"), ignore_errors=True)
+
+ pm = ProductManager()
+ role_tag = f"{pm.__class__.__name__}_{pm.name}"
+ stg_path = stg_path_prefix.joinpath(role_tag)
+ pm.serialize(stg_path)
+
+ new_pm = Role.deserialize(stg_path)
+ assert new_pm.name == pm.name
+ assert len(new_pm.get_memories(1)) == 0
+
+
+@pytest.mark.asyncio
+async def test_role_serdeser_interrupt():
+ role_c = RoleC()
+ shutil.rmtree(SERDESER_PATH.joinpath("team"), ignore_errors=True)
+
+ stg_path = SERDESER_PATH.joinpath("team", "environment", "roles", f"{role_c.__class__.__name__}_{role_c.name}")
+ try:
+ await role_c.run(with_message=Message(content="demo", cause_by=UserRequirement))
+ except Exception:
+ logger.error(f"Exception in `role_a.run`, detail: {format_trackback_info()}")
+ role_c.serialize(stg_path)
+
+ assert role_c._rc.memory.count() == 1
+
+ new_role_a: Role = Role.deserialize(stg_path)
+ assert new_role_a._rc.state == 1
+
+ with pytest.raises(Exception):
+ await role_c.run(with_message=Message(content="demo", cause_by=UserRequirement))
diff --git a/tests/metagpt/serialize_deserialize/test_schema.py b/tests/metagpt/serialize_deserialize/test_schema.py
new file mode 100644
index 000000000..0358265a9
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_schema.py
@@ -0,0 +1,38 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+# @Desc : unittest of schema ser&deser
+
+from metagpt.actions.action_node import ActionNode
+from metagpt.actions.write_code import WriteCode
+from metagpt.schema import Message
+from metagpt.utils.common import any_to_str
+from tests.metagpt.serialize_deserialize.test_serdeser_base import MockMessage
+
+
+def test_message_serdeser():
+ out_mapping = {"field3": (str, ...), "field4": (list[str], ...)}
+ out_data = {"field3": "field3 value3", "field4": ["field4 value1", "field4 value2"]}
+ ic_obj = ActionNode.create_model_class("code", out_mapping)
+
+ message = Message(content="code", instruct_content=ic_obj(**out_data), role="engineer", cause_by=WriteCode)
+ ser_data = message.dict()
+ assert ser_data["cause_by"] == "metagpt.actions.write_code.WriteCode"
+ assert ser_data["instruct_content"]["class"] == "code"
+
+ new_message = Message(**ser_data)
+ assert new_message.cause_by == any_to_str(WriteCode)
+ assert new_message.cause_by in [any_to_str(WriteCode)]
+ assert new_message.instruct_content == ic_obj(**out_data)
+
+
+def test_message_without_postprocess():
+ """to explain `instruct_content` should be postprocessed"""
+ out_mapping = {"field1": (list[str], ...)}
+ out_data = {"field1": ["field1 value1", "field1 value2"]}
+ ic_obj = ActionNode.create_model_class("code", out_mapping)
+ message = MockMessage(content="code", instruct_content=ic_obj(**out_data))
+ ser_data = message.dict()
+ assert ser_data["instruct_content"] == {"field1": ["field1 value1", "field1 value2"]}
+
+ new_message = MockMessage(**ser_data)
+ assert new_message.instruct_content != ic_obj(**out_data)
diff --git a/tests/metagpt/serialize_deserialize/test_serdeser_base.py b/tests/metagpt/serialize_deserialize/test_serdeser_base.py
new file mode 100644
index 000000000..a66813489
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_serdeser_base.py
@@ -0,0 +1,87 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+# @Desc : base test actions / roles used in unittest
+
+import asyncio
+from pathlib import Path
+
+from pydantic import BaseModel, Field
+
+from metagpt.actions import Action, ActionOutput
+from metagpt.actions.action_node import ActionNode
+from metagpt.actions.add_requirement import UserRequirement
+from metagpt.roles.role import Role, RoleReactMode
+
+serdeser_path = Path(__file__).absolute().parent.joinpath("..", "..", "data", "serdeser_storage")
+
+
+class MockMessage(BaseModel):
+ """to test normal dict without postprocess"""
+
+ content: str = ""
+ instruct_content: BaseModel = Field(default=None)
+
+
+class ActionPass(Action):
+ name: str = Field(default="ActionPass")
+
+ async def run(self, messages: list["Message"]) -> ActionOutput:
+ await asyncio.sleep(5) # sleep to make other roles can watch the executed Message
+ output_mapping = {"result": (str, ...)}
+ pass_class = ActionNode.create_model_class("pass", output_mapping)
+ pass_output = ActionOutput("ActionPass run passed", pass_class(**{"result": "pass result"}))
+
+ return pass_output
+
+
+class ActionOK(Action):
+ name: str = Field(default="ActionOK")
+
+ async def run(self, messages: list["Message"]) -> str:
+ await asyncio.sleep(5)
+ return "ok"
+
+
+class ActionRaise(Action):
+ name: str = Field(default="ActionRaise")
+
+ async def run(self, messages: list["Message"]) -> str:
+ raise RuntimeError("parse error in ActionRaise")
+
+
+class RoleA(Role):
+ name: str = Field(default="RoleA")
+ profile: str = Field(default="Role A")
+ goal: str = "RoleA's goal"
+ constraints: str = "RoleA's constraints"
+
+ def __init__(self, **kwargs):
+ super(RoleA, self).__init__(**kwargs)
+ self._init_actions([ActionPass])
+ self._watch([UserRequirement])
+
+
+class RoleB(Role):
+ name: str = Field(default="RoleB")
+ profile: str = Field(default="Role B")
+ goal: str = "RoleB's goal"
+ constraints: str = "RoleB's constraints"
+
+ def __init__(self, **kwargs):
+ super(RoleB, self).__init__(**kwargs)
+ self._init_actions([ActionOK, ActionRaise])
+ self._watch([ActionPass])
+ self._rc.react_mode = RoleReactMode.BY_ORDER
+
+
+class RoleC(Role):
+ name: str = Field(default="RoleC")
+ profile: str = Field(default="Role C")
+ goal: str = "RoleC's goal"
+ constraints: str = "RoleC's constraints"
+
+ def __init__(self, **kwargs):
+ super(RoleC, self).__init__(**kwargs)
+ self._init_actions([ActionOK, ActionRaise])
+ self._watch([UserRequirement])
+ self._rc.react_mode = RoleReactMode.BY_ORDER
diff --git a/tests/metagpt/serialize_deserialize/test_team.py b/tests/metagpt/serialize_deserialize/test_team.py
new file mode 100644
index 000000000..dc41fa4ed
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_team.py
@@ -0,0 +1,135 @@
+# -*- coding: utf-8 -*-
+# @Date : 11/27/2023 10:07 AM
+# @Author : stellahong (stellahong@fuzhi.ai)
+# @Desc :
+
+import shutil
+
+import pytest
+
+from metagpt.const import SERDESER_PATH
+from metagpt.logs import logger
+from metagpt.roles import Architect, ProductManager, ProjectManager
+from metagpt.team import Team
+from tests.metagpt.serialize_deserialize.test_serdeser_base import (
+ ActionOK,
+ RoleA,
+ RoleB,
+ RoleC,
+ serdeser_path,
+)
+
+
+def test_team_deserialize():
+ company = Team()
+
+ pm = ProductManager()
+ arch = Architect()
+ company.hire(
+ [
+ pm,
+ arch,
+ ProjectManager(),
+ ]
+ )
+ assert len(company.env.get_roles()) == 3
+ ser_company = company.dict()
+ new_company = Team(**ser_company)
+
+ assert len(new_company.env.get_roles()) == 3
+ assert new_company.env.get_role(pm.profile) is not None
+
+ new_pm = new_company.env.get_role(pm.profile)
+ assert type(new_pm) == ProductManager
+ assert new_company.env.get_role(pm.profile) is not None
+ assert new_company.env.get_role(arch.profile) is not None
+
+
+def test_team_serdeser_save():
+ company = Team()
+ company.hire([RoleC()])
+
+ stg_path = serdeser_path.joinpath("team")
+ shutil.rmtree(stg_path, ignore_errors=True)
+
+ company.serialize(stg_path=stg_path)
+
+ new_company = Team.deserialize(stg_path)
+
+ assert len(new_company.env.roles) == 1
+
+
+@pytest.mark.asyncio
+async def test_team_recover():
+ idea = "write a snake game"
+ stg_path = SERDESER_PATH.joinpath("team")
+ shutil.rmtree(stg_path, ignore_errors=True)
+
+ company = Team()
+ role_c = RoleC()
+ company.hire([role_c])
+ company.run_project(idea)
+ await company.run(n_round=4)
+
+ ser_data = company.dict()
+ new_company = Team(**ser_data)
+
+ new_role_c = new_company.env.get_role(role_c.profile)
+ # assert new_role_c._rc.memory == role_c._rc.memory # TODO
+ assert new_role_c._rc.env != role_c._rc.env # TODO
+ assert type(list(new_company.env.roles.values())[0]._actions[0]) == ActionOK
+
+ new_company.run_project(idea)
+ await new_company.run(n_round=4)
+
+
+@pytest.mark.asyncio
+async def test_team_recover_save():
+ idea = "write a 2048 web game"
+ stg_path = SERDESER_PATH.joinpath("team")
+ shutil.rmtree(stg_path, ignore_errors=True)
+
+ company = Team()
+ role_c = RoleC()
+ company.hire([role_c])
+ company.run_project(idea)
+ await company.run(n_round=4)
+
+ new_company = Team.deserialize(stg_path)
+ new_role_c = new_company.env.get_role(role_c.profile)
+ # assert new_role_c._rc.memory == role_c._rc.memory
+ assert new_role_c._rc.env != role_c._rc.env
+ assert new_role_c.recovered != role_c.recovered # here cause previous ut is `!=`
+ assert new_role_c._rc.todo != role_c._rc.todo # serialize exclude `_rc.todo`
+ assert new_role_c._rc.news != role_c._rc.news # serialize exclude `_rc.news`
+
+ new_company.run_project(idea)
+ await new_company.run(n_round=4)
+
+
+@pytest.mark.asyncio
+async def test_team_recover_multi_roles_save():
+ idea = "write a snake game"
+ stg_path = SERDESER_PATH.joinpath("team")
+ shutil.rmtree(stg_path, ignore_errors=True)
+
+ role_a = RoleA()
+ role_b = RoleB()
+
+ assert role_a.subscription == {"tests.metagpt.serialize_deserialize.test_serdeser_base.RoleA", "RoleA"}
+ assert role_b.subscription == {"tests.metagpt.serialize_deserialize.test_serdeser_base.RoleB", "RoleB"}
+ assert role_b._rc.watch == {"tests.metagpt.serialize_deserialize.test_serdeser_base.ActionPass"}
+
+ company = Team()
+ company.hire([role_a, role_b])
+ company.run_project(idea)
+ await company.run(n_round=4)
+
+ logger.info("Team recovered")
+
+ new_company = Team.deserialize(stg_path)
+ new_company.run_project(idea)
+
+ assert new_company.env.get_role(role_b.profile)._rc.state == 1
+
+ await new_company.run(n_round=4)
diff --git a/tests/metagpt/serialize_deserialize/test_write_code.py b/tests/metagpt/serialize_deserialize/test_write_code.py
new file mode 100644
index 000000000..65b8f456a
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_write_code.py
@@ -0,0 +1,32 @@
+# -*- coding: utf-8 -*-
+# @Date : 11/23/2023 10:56 AM
+# @Author : stellahong (stellahong@fuzhi.ai)
+# @Desc :
+
+import pytest
+
+from metagpt.actions import WriteCode
+from metagpt.llm import LLM
+from metagpt.schema import CodingContext, Document
+
+
+def test_write_design_serialize():
+ action = WriteCode()
+ ser_action_dict = action.dict()
+ assert ser_action_dict["name"] == "WriteCode"
+ # assert "llm" in ser_action_dict # not export
+
+
+@pytest.mark.asyncio
+async def test_write_code_deserialize():
+ context = CodingContext(
+ filename="test_code.py", design_doc=Document(content="write add function to calculate two numbers")
+ )
+ doc = Document(content=context.json())
+ action = WriteCode(context=doc)
+ serialized_data = action.dict()
+ new_action = WriteCode(**serialized_data)
+
+ assert new_action.name == "WriteCode"
+ assert new_action.llm == LLM()
+ await action.run()
diff --git a/tests/metagpt/serialize_deserialize/test_write_code_review.py b/tests/metagpt/serialize_deserialize/test_write_code_review.py
new file mode 100644
index 000000000..01026590c
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_write_code_review.py
@@ -0,0 +1,32 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+# @Desc : unittest of WriteCodeReview SerDeser
+
+import pytest
+
+from metagpt.actions import WriteCodeReview
+from metagpt.llm import LLM
+from metagpt.schema import CodingContext, Document
+
+
+@pytest.mark.asyncio
+async def test_write_code_review_deserialize():
+ code_content = """
+def div(a: int, b: int = 0):
+ return a / b
+"""
+ context = CodingContext(
+ filename="test_op.py",
+ design_doc=Document(content="divide two numbers"),
+ code_doc=Document(content=code_content),
+ )
+
+ action = WriteCodeReview(context=context)
+ serialized_data = action.dict()
+ assert serialized_data["name"] == "WriteCodeReview"
+
+ new_action = WriteCodeReview(**serialized_data)
+
+ assert new_action.name == "WriteCodeReview"
+ assert new_action.llm == LLM()
+ await new_action.run()
diff --git a/tests/metagpt/serialize_deserialize/test_write_design.py b/tests/metagpt/serialize_deserialize/test_write_design.py
new file mode 100644
index 000000000..4e768ddd7
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_write_design.py
@@ -0,0 +1,42 @@
+# -*- coding: utf-8 -*-
+# @Date : 11/22/2023 8:19 PM
+# @Author : stellahong (stellahong@fuzhi.ai)
+# @Desc :
+import pytest
+
+from metagpt.actions import WriteDesign, WriteTasks
+from metagpt.llm import LLM
+
+
+def test_write_design_serialize():
+ action = WriteDesign()
+ ser_action_dict = action.dict()
+ assert "name" in ser_action_dict
+ # assert "llm" in ser_action_dict # not export
+
+
+def test_write_task_serialize():
+ action = WriteTasks()
+ ser_action_dict = action.dict()
+ assert "name" in ser_action_dict
+ # assert "llm" in ser_action_dict # not export
+
+
+@pytest.mark.asyncio
+async def test_write_design_deserialize():
+ action = WriteDesign()
+ serialized_data = action.dict()
+ new_action = WriteDesign(**serialized_data)
+ assert new_action.name == ""
+ assert new_action.llm == LLM()
+ await new_action.run(with_messages="write a cli snake game")
+
+
+@pytest.mark.asyncio
+async def test_write_task_deserialize():
+ action = WriteTasks()
+ serialized_data = action.dict()
+ new_action = WriteTasks(**serialized_data)
+ assert new_action.name == "CreateTasks"
+ assert new_action.llm == LLM()
+ await new_action.run(with_messages="write a cli snake game")
diff --git a/tests/metagpt/serialize_deserialize/test_write_prd.py b/tests/metagpt/serialize_deserialize/test_write_prd.py
new file mode 100644
index 000000000..d6d14f99a
--- /dev/null
+++ b/tests/metagpt/serialize_deserialize/test_write_prd.py
@@ -0,0 +1,28 @@
+# -*- coding: utf-8 -*-
+# @Date : 11/22/2023 1:47 PM
+# @Author : stellahong (stellahong@fuzhi.ai)
+# @Desc :
+
+import pytest
+
+from metagpt.actions import WritePRD
+from metagpt.llm import LLM
+from metagpt.schema import Message
+
+
+def test_action_serialize():
+ action = WritePRD()
+ ser_action_dict = action.dict()
+ assert "name" in ser_action_dict
+ # assert "llm" in ser_action_dict # not export
+
+
+@pytest.mark.asyncio
+async def test_action_deserialize():
+ action = WritePRD()
+ serialized_data = action.dict()
+ new_action = WritePRD(**serialized_data)
+ assert new_action.name == ""
+ assert new_action.llm == LLM()
+ action_output = await new_action.run(with_messages=Message(content="write a cli snake game"))
+ assert len(action_output.content) > 0
diff --git a/tests/metagpt/test_environment.py b/tests/metagpt/test_environment.py
index a0f1f6257..56e2b4fc3 100644
--- a/tests/metagpt/test_environment.py
+++ b/tests/metagpt/test_environment.py
@@ -6,15 +6,19 @@
@File : test_environment.py
"""
+from pathlib import Path
+
import pytest
-from metagpt.actions import BossRequirement
+from metagpt.actions import UserRequirement
from metagpt.environment import Environment
from metagpt.logs import logger
from metagpt.manager import Manager
from metagpt.roles import Architect, ProductManager, Role
from metagpt.schema import Message
+serdeser_path = Path(__file__).absolute().parent.joinpath("../data/serdeser_storage")
+
@pytest.fixture
def env():
@@ -22,34 +26,33 @@ def env():
def test_add_role(env: Environment):
- role = ProductManager("Alice", "product manager", "create a new product", "limited resources")
+ role = ProductManager(
+ name="Alice", profile="product manager", goal="create a new product", constraints="limited resources"
+ )
env.add_role(role)
assert env.get_role(role.profile) == role
def test_get_roles(env: Environment):
- role1 = Role("Alice", "product manager", "create a new product", "limited resources")
- role2 = Role("Bob", "engineer", "develop the new product", "short deadline")
+ role1 = Role(name="Alice", profile="product manager", goal="create a new product", constraints="limited resources")
+ role2 = Role(name="Bob", profile="engineer", goal="develop the new product", constraints="short deadline")
env.add_role(role1)
env.add_role(role2)
roles = env.get_roles()
assert roles == {role1.profile: role1, role2.profile: role2}
-def test_set_manager(env: Environment):
- manager = Manager()
- env.set_manager(manager)
- assert env.manager == manager
-
-
@pytest.mark.asyncio
async def test_publish_and_process_message(env: Environment):
- product_manager = ProductManager("Alice", "Product Manager", "做AI Native产品", "资源有限")
- architect = Architect("Bob", "Architect", "设计一个可用、高效、较低成本的系统,包括数据结构与接口", "资源有限,需要节省成本")
+ product_manager = ProductManager(name="Alice", profile="Product Manager", goal="做AI Native产品", constraints="资源有限")
+ architect = Architect(
+ name="Bob", profile="Architect", goal="设计一个可用、高效、较低成本的系统,包括数据结构与接口", constraints="资源有限,需要节省成本"
+ )
env.add_roles([product_manager, architect])
+
env.set_manager(Manager())
- env.publish_message(Message(role="BOSS", content="需要一个基于LLM做总结的搜索引擎", cause_by=BossRequirement))
+ env.publish_message(Message(role="User", content="需要一个基于LLM做总结的搜索引擎", cause_by=UserRequirement))
await env.run(k=2)
logger.info(f"{env.history=}")
diff --git a/tests/metagpt/test_gpt.py b/tests/metagpt/test_gpt.py
index 89dd726a8..431858d4c 100644
--- a/tests/metagpt/test_gpt.py
+++ b/tests/metagpt/test_gpt.py
@@ -14,7 +14,8 @@ from metagpt.logs import logger
@pytest.mark.usefixtures("llm_api")
class TestGPT:
def test_llm_api_ask(self, llm_api):
- answer = llm_api.ask('hello chatgpt')
+ answer = llm_api.ask("hello chatgpt")
+ logger.info(answer)
assert len(answer) > 0
# def test_gptapi_ask_batch(self, llm_api):
@@ -22,22 +23,29 @@ class TestGPT:
# assert len(answer) > 0
def test_llm_api_ask_code(self, llm_api):
- answer = llm_api.ask_code(['请扮演一个Google Python专家工程师,如果理解,回复明白', '写一个hello world'])
+ answer = llm_api.ask_code(["请扮演一个Google Python专家工程师,如果理解,回复明白", "写一个hello world"])
+ logger.info(answer)
assert len(answer) > 0
@pytest.mark.asyncio
async def test_llm_api_aask(self, llm_api):
- answer = await llm_api.aask('hello chatgpt')
+ answer = await llm_api.aask("hello chatgpt")
+ logger.info(answer)
assert len(answer) > 0
@pytest.mark.asyncio
async def test_llm_api_aask_code(self, llm_api):
- answer = await llm_api.aask_code(['请扮演一个Google Python专家工程师,如果理解,回复明白', '写一个hello world'])
+ answer = await llm_api.aask_code(["请扮演一个Google Python专家工程师,如果理解,回复明白", "写一个hello world"])
+ logger.info(answer)
assert len(answer) > 0
@pytest.mark.asyncio
async def test_llm_api_costs(self, llm_api):
- await llm_api.aask('hello chatgpt')
+ await llm_api.aask("hello chatgpt")
costs = llm_api.get_costs()
logger.info(costs)
assert costs.total_cost > 0
+
+
+# if __name__ == "__main__":
+# pytest.main([__file__, "-s"])
diff --git a/tests/metagpt/test_llm.py b/tests/metagpt/test_llm.py
index 11503af1d..408fd3162 100644
--- a/tests/metagpt/test_llm.py
+++ b/tests/metagpt/test_llm.py
@@ -18,17 +18,21 @@ def llm():
@pytest.mark.asyncio
async def test_llm_aask(llm):
- assert len(await llm.aask('hello world')) > 0
+ assert len(await llm.aask("hello world")) > 0
@pytest.mark.asyncio
async def test_llm_aask_batch(llm):
- assert len(await llm.aask_batch(['hi', 'write python hello world.'])) > 0
+ assert len(await llm.aask_batch(["hi", "write python hello world."])) > 0
@pytest.mark.asyncio
async def test_llm_acompletion(llm):
- hello_msg = [{'role': 'user', 'content': 'hello'}]
+ hello_msg = [{"role": "user", "content": "hello"}]
assert len(await llm.acompletion(hello_msg)) > 0
assert len(await llm.acompletion_batch([hello_msg])) > 0
assert len(await llm.acompletion_batch_text([hello_msg])) > 0
+
+
+# if __name__ == "__main__":
+# pytest.main([__file__, "-s"])
diff --git a/tests/metagpt/test_message.py b/tests/metagpt/test_message.py
index e26f38381..04d85d9e4 100644
--- a/tests/metagpt/test_message.py
+++ b/tests/metagpt/test_message.py
@@ -4,6 +4,7 @@
@Time : 2023/5/16 10:57
@Author : alexanderwu
@File : test_message.py
+@Modified By: mashenquan, 2023-11-1. Modify coding style.
"""
import pytest
@@ -11,26 +12,30 @@ from metagpt.schema import AIMessage, Message, RawMessage, SystemMessage, UserMe
def test_message():
- msg = Message(role='User', content='WTF')
- assert msg.to_dict()['role'] == 'User'
- assert 'User' in str(msg)
+ msg = Message(role="User", content="WTF")
+ assert msg.to_dict()["role"] == "User"
+ assert "User" in str(msg)
def test_all_messages():
- test_content = 'test_message'
+ test_content = "test_message"
msgs = [
UserMessage(test_content),
SystemMessage(test_content),
AIMessage(test_content),
- Message(test_content, role='QA')
+ Message(test_content, role="QA"),
]
for msg in msgs:
assert msg.content == test_content
def test_raw_message():
- msg = RawMessage(role='user', content='raw')
- assert msg['role'] == 'user'
- assert msg['content'] == 'raw'
+ msg = RawMessage(role="user", content="raw")
+ assert msg["role"] == "user"
+ assert msg["content"] == "raw"
with pytest.raises(KeyError):
- assert msg['1'] == 1, "KeyError: '1'"
+ assert msg["1"] == 1, "KeyError: '1'"
+
+
+if __name__ == "__main__":
+ pytest.main([__file__, "-s"])
diff --git a/tests/metagpt/test_prompt.py b/tests/metagpt/test_prompt.py
new file mode 100644
index 000000000..f7b1cc68e
--- /dev/null
+++ b/tests/metagpt/test_prompt.py
@@ -0,0 +1,342 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/5/11 14:45
+@Author : alexanderwu
+@File : test_llm.py
+"""
+
+import pytest
+
+from metagpt.llm import LLM
+
+CODE_REVIEW_SMALLEST_CONTEXT = """
+## game.js
+```Code
+// game.js
+class Game {
+ constructor() {
+ this.board = this.createEmptyBoard();
+ this.score = 0;
+ this.bestScore = 0;
+ }
+
+ createEmptyBoard() {
+ const board = [];
+ for (let i = 0; i < 4; i++) {
+ board[i] = [0, 0, 0, 0];
+ }
+ return board;
+ }
+
+ startGame() {
+ this.board = this.createEmptyBoard();
+ this.score = 0;
+ this.addRandomTile();
+ this.addRandomTile();
+ }
+
+ addRandomTile() {
+ let emptyCells = [];
+ for (let r = 0; r < 4; r++) {
+ for (let c = 0; c < 4; c++) {
+ if (this.board[r][c] === 0) {
+ emptyCells.push({ r, c });
+ }
+ }
+ }
+ if (emptyCells.length > 0) {
+ let randomCell = emptyCells[Math.floor(Math.random() * emptyCells.length)];
+ this.board[randomCell.r][randomCell.c] = Math.random() < 0.9 ? 2 : 4;
+ }
+ }
+
+ move(direction) {
+ // This function will handle the logic for moving tiles
+ // in the specified direction and merging them
+ // It will also update the score and add a new random tile if the move is successful
+ // The actual implementation of this function is complex and would require
+ // a significant amount of code to handle all the cases for moving and merging tiles
+ // For the purposes of this example, we will not implement the full logic
+ // Instead, we will just call addRandomTile to simulate a move
+ this.addRandomTile();
+ }
+
+ getBoard() {
+ return this.board;
+ }
+
+ getScore() {
+ return this.score;
+ }
+
+ getBestScore() {
+ return this.bestScore;
+ }
+
+ setBestScore(score) {
+ this.bestScore = score;
+ }
+}
+
+```
+"""
+
+MOVE_DRAFT = """
+## move function draft
+
+```javascript
+move(direction) {
+ let moved = false;
+ switch (direction) {
+ case 'up':
+ for (let c = 0; c < 4; c++) {
+ for (let r = 1; r < 4; r++) {
+ if (this.board[r][c] !== 0) {
+ let row = r;
+ while (row > 0 && this.board[row - 1][c] === 0) {
+ this.board[row - 1][c] = this.board[row][c];
+ this.board[row][c] = 0;
+ row--;
+ moved = true;
+ }
+ if (row > 0 && this.board[row - 1][c] === this.board[row][c]) {
+ this.board[row - 1][c] *= 2;
+ this.board[row][c] = 0;
+ this.score += this.board[row - 1][c];
+ moved = true;
+ }
+ }
+ }
+ }
+ break;
+ case 'down':
+ // Implement logic for moving tiles down
+ // Similar to the 'up' case but iterating in reverse order
+ // and checking for merging in the opposite direction
+ break;
+ case 'left':
+ // Implement logic for moving tiles left
+ // Similar to the 'up' case but iterating over columns first
+ // and checking for merging in the opposite direction
+ break;
+ case 'right':
+ // Implement logic for moving tiles right
+ // Similar to the 'up' case but iterating over columns in reverse order
+ // and checking for merging in the opposite direction
+ break;
+ }
+
+ if (moved) {
+ this.addRandomTile();
+ }
+}
+```
+"""
+
+FUNCTION_TO_MERMAID_CLASS = """
+## context
+```
+class UIDesign(Action):
+ #Class representing the UI Design action.
+ def __init__(self, name, context=None, llm=None):
+ super().__init__(name, context, llm) # 需要调用LLM进一步丰富UI设计的prompt
+ @parse
+ def parse_requirement(self, context: str):
+ #Parse UI Design draft from the context using regex.
+ pattern = r"## UI Design draft.*?\n(.*?)## Anything UNCLEAR"
+ return context, pattern
+ @parse
+ def parse_ui_elements(self, context: str):
+ #Parse Selected Elements from the context using regex.
+ pattern = r"## Selected Elements.*?\n(.*?)## HTML Layout"
+ return context, pattern
+ @parse
+ def parse_css_code(self, context: str):
+ pattern = r"```css.*?\n(.*?)## Anything UNCLEAR"
+ return context, pattern
+ @parse
+ def parse_html_code(self, context: str):
+ pattern = r"```html.*?\n(.*?)```"
+ return context, pattern
+ async def draw_icons(self, context, *args, **kwargs):
+ #Draw icons using SDEngine.
+ engine = SDEngine()
+ icon_prompts = self.parse_ui_elements(context)
+ icons = icon_prompts.split("\n")
+ icons = [s for s in icons if len(s.strip()) > 0]
+ prompts_batch = []
+ for icon_prompt in icons:
+ # fixme: 添加icon lora
+ prompt = engine.construct_payload(icon_prompt + ".")
+ prompts_batch.append(prompt)
+ await engine.run_t2i(prompts_batch)
+ logger.info("Finish icon design using StableDiffusion API")
+ async def _save(self, css_content, html_content):
+ save_dir = CONFIG.workspace_path / "resources" / "codes"
+ if not os.path.exists(save_dir):
+ os.makedirs(save_dir, exist_ok=True)
+ # Save CSS and HTML content to files
+ css_file_path = save_dir / "ui_design.css"
+ html_file_path = save_dir / "ui_design.html"
+ with open(css_file_path, "w") as css_file:
+ css_file.write(css_content)
+ with open(html_file_path, "w") as html_file:
+ html_file.write(html_content)
+ async def run(self, requirements: list[Message], *args, **kwargs) -> ActionOutput:
+ #Run the UI Design action.
+ # fixme: update prompt (根据需求细化prompt)
+ context = requirements[-1].content
+ ui_design_draft = self.parse_requirement(context=context)
+ # todo: parse requirements str
+ prompt = PROMPT_TEMPLATE.format(context=ui_design_draft, format_example=FORMAT_EXAMPLE)
+ logger.info(prompt)
+ ui_describe = await self._aask_v1(prompt, "ui_design", OUTPUT_MAPPING)
+ logger.info(ui_describe.content)
+ logger.info(ui_describe.instruct_content)
+ css = self.parse_css_code(context=ui_describe.content)
+ html = self.parse_html_code(context=ui_describe.content)
+ await self._save(css_content=css, html_content=html)
+ await self.draw_icons(ui_describe.content)
+ return ui_describe
+```
+-----
+## format example
+[CONTENT]
+{
+ "ClassView": "classDiagram\n class A {\n -int x\n +int y\n -int speed\n -int direction\n +__init__(x: int, y: int, speed: int, direction: int)\n +change_direction(new_direction: int) None\n +move() None\n }\n "
+}
+[/CONTENT]
+## nodes: ": # "
+- ClassView: # Generate the mermaid class diagram corresponding to source code in "context."
+## constraint
+- Language: Please use the same language as the user input.
+- Format: output wrapped inside [CONTENT][/CONTENT] as format example, nothing else.
+## action
+Fill in the above nodes(ClassView) based on the format example.
+"""
+
+MOVE_FUNCTION = """
+## move function implementation
+
+```javascript
+move(direction) {
+ let moved = false;
+ switch (direction) {
+ case 'up':
+ for (let c = 0; c < 4; c++) {
+ for (let r = 1; r < 4; r++) {
+ if (this.board[r][c] !== 0) {
+ let row = r;
+ while (row > 0 && this.board[row - 1][c] === 0) {
+ this.board[row - 1][c] = this.board[row][c];
+ this.board[row][c] = 0;
+ row--;
+ moved = true;
+ }
+ if (row > 0 && this.board[row - 1][c] === this.board[row][c]) {
+ this.board[row - 1][c] *= 2;
+ this.board[row][c] = 0;
+ this.score += this.board[row - 1][c];
+ moved = true;
+ }
+ }
+ }
+ }
+ break;
+ case 'down':
+ for (let c = 0; c < 4; c++) {
+ for (let r = 2; r >= 0; r--) {
+ if (this.board[r][c] !== 0) {
+ let row = r;
+ while (row < 3 && this.board[row + 1][c] === 0) {
+ this.board[row + 1][c] = this.board[row][c];
+ this.board[row][c] = 0;
+ row++;
+ moved = true;
+ }
+ if (row < 3 && this.board[row + 1][c] === this.board[row][c]) {
+ this.board[row + 1][c] *= 2;
+ this.board[row][c] = 0;
+ this.score += this.board[row + 1][c];
+ moved = true;
+ }
+ }
+ }
+ }
+ break;
+ case 'left':
+ for (let r = 0; r < 4; r++) {
+ for (let c = 1; c < 4; c++) {
+ if (this.board[r][c] !== 0) {
+ let col = c;
+ while (col > 0 && this.board[r][col - 1] === 0) {
+ this.board[r][col - 1] = this.board[r][col];
+ this.board[r][col] = 0;
+ col--;
+ moved = true;
+ }
+ if (col > 0 && this.board[r][col - 1] === this.board[r][col]) {
+ this.board[r][col - 1] *= 2;
+ this.board[r][col] = 0;
+ this.score += this.board[r][col - 1];
+ moved = true;
+ }
+ }
+ }
+ }
+ break;
+ case 'right':
+ for (let r = 0; r < 4; r++) {
+ for (let c = 2; c >= 0; c--) {
+ if (this.board[r][c] !== 0) {
+ let col = c;
+ while (col < 3 && this.board[r][col + 1] === 0) {
+ this.board[r][col + 1] = this.board[r][col];
+ this.board[r][col] = 0;
+ col++;
+ moved = true;
+ }
+ if (col < 3 && this.board[r][col + 1] === this.board[r][col]) {
+ this.board[r][col + 1] *= 2;
+ this.board[r][col] = 0;
+ this.score += this.board[r][col + 1];
+ moved = true;
+ }
+ }
+ }
+ }
+ break;
+ }
+
+ if (moved) {
+ this.addRandomTile();
+ }
+}
+```
+"""
+
+
+@pytest.fixture()
+def llm():
+ return LLM()
+
+
+@pytest.mark.asyncio
+async def test_llm_code_review(llm):
+ choices = [
+ "Please review the move function code above. Should it be refactor?",
+ "Please implement the move function",
+ "Please write a draft for the move function in order to implement it",
+ ]
+ # prompt = CODE_REVIEW_SMALLEST_CONTEXT+ "\n\n" + MOVE_DRAFT + "\n\n" + choices[1]
+ # rsp = await llm.aask(prompt)
+
+ prompt = CODE_REVIEW_SMALLEST_CONTEXT + "\n\n" + MOVE_FUNCTION + "\n\n" + choices[0]
+ prompt = FUNCTION_TO_MERMAID_CLASS
+
+ _ = await llm.aask(prompt)
+
+
+# if __name__ == "__main__":
+# pytest.main([__file__, "-s"])
diff --git a/tests/metagpt/test_role.py b/tests/metagpt/test_role.py
index 11fd804ec..dbe45130d 100644
--- a/tests/metagpt/test_role.py
+++ b/tests/metagpt/test_role.py
@@ -4,11 +4,98 @@
@Time : 2023/5/11 14:44
@Author : alexanderwu
@File : test_role.py
+@Modified By: mashenquan, 2023-11-1. In line with Chapter 2.2.1 and 2.2.2 of RFC 116, introduce unit tests for
+ the utilization of the new message distribution feature in message handling.
+@Modified By: mashenquan, 2023-11-4. According to the routing feature plan in Chapter 2.2.3.2 of RFC 113, the routing
+ functionality is to be consolidated into the `Environment` class.
"""
+import uuid
+
+import pytest
+from pydantic import BaseModel
+
+from metagpt.actions import Action, ActionOutput, UserRequirement
+from metagpt.environment import Environment
from metagpt.roles import Role
+from metagpt.schema import Message
+from metagpt.utils.common import any_to_str
-def test_role_desc():
- i = Role(profile='Sales', desc='Best Seller')
- assert i.profile == 'Sales'
- assert i._setting.desc == 'Best Seller'
+class MockAction(Action):
+ async def run(self, messages, *args, **kwargs):
+ assert messages
+ return ActionOutput(content=messages[-1].content, instruct_content=messages[-1])
+
+
+class MockRole(Role):
+ def __init__(self, name="", profile="", goal="", constraints="", desc=""):
+ super().__init__(name=name, profile=profile, goal=goal, constraints=constraints, desc=desc)
+ self._init_actions([MockAction()])
+
+
+@pytest.mark.asyncio
+async def test_react():
+ class Input(BaseModel):
+ name: str
+ profile: str
+ goal: str
+ constraints: str
+ desc: str
+ subscription: str
+
+ inputs = [
+ {
+ "name": "A",
+ "profile": "Tester",
+ "goal": "Test",
+ "constraints": "constraints",
+ "desc": "desc",
+ "subscription": "start",
+ }
+ ]
+
+ for i in inputs:
+ seed = Input(**i)
+ role = MockRole(
+ name=seed.name, profile=seed.profile, goal=seed.goal, constraints=seed.constraints, desc=seed.desc
+ )
+ role.subscribe({seed.subscription})
+ assert role._rc.watch == {any_to_str(UserRequirement)}
+ assert role.name == seed.name
+ assert role.profile == seed.profile
+ assert role._setting.goal == seed.goal
+ assert role._setting.constraints == seed.constraints
+ assert role._setting.desc == seed.desc
+ assert role.is_idle
+ env = Environment()
+ env.add_role(role)
+ assert env.get_subscription(role) == {seed.subscription}
+ env.publish_message(Message(content="test", msg_to=seed.subscription))
+ assert not role.is_idle
+ while not env.is_idle:
+ await env.run()
+ assert role.is_idle
+ env.publish_message(Message(content="test", cause_by=seed.subscription))
+ assert not role.is_idle
+ while not env.is_idle:
+ await env.run()
+ assert role.is_idle
+ tag = uuid.uuid4().hex
+ role.subscribe({tag})
+ assert env.get_subscription(role) == {tag}
+
+
+@pytest.mark.asyncio
+async def test_msg_to():
+ m = Message(content="a", send_to=["a", MockRole, Message])
+ assert m.send_to == {"a", any_to_str(MockRole), any_to_str(Message)}
+
+ m = Message(content="a", cause_by=MockAction, send_to={"a", MockRole, Message})
+ assert m.send_to == {"a", any_to_str(MockRole), any_to_str(Message)}
+
+ m = Message(content="a", send_to=("a", MockRole, Message))
+ assert m.send_to == {"a", any_to_str(MockRole), any_to_str(Message)}
+
+
+if __name__ == "__main__":
+ pytest.main([__file__, "-s"])
diff --git a/tests/metagpt/test_schema.py b/tests/metagpt/test_schema.py
index 12666e0d3..1742757e8 100644
--- a/tests/metagpt/test_schema.py
+++ b/tests/metagpt/test_schema.py
@@ -4,18 +4,97 @@
@Time : 2023/5/20 10:40
@Author : alexanderwu
@File : test_schema.py
+@Modified By: mashenquan, 2023-11-1. In line with Chapter 2.2.1 and 2.2.2 of RFC 116, introduce unit tests for
+ the utilization of the new feature of `Message` class.
"""
+
+import json
+
+import pytest
+
+from metagpt.actions import Action
+from metagpt.actions.action_node import ActionNode
+from metagpt.actions.write_code import WriteCode
from metagpt.schema import AIMessage, Message, SystemMessage, UserMessage
+from metagpt.utils.common import any_to_str
+@pytest.mark.asyncio
def test_messages():
- test_content = 'test_message'
+ test_content = "test_message"
msgs = [
- UserMessage(test_content),
- SystemMessage(test_content),
- AIMessage(test_content),
- Message(test_content, role='QA')
+ UserMessage(content=test_content),
+ SystemMessage(content=test_content),
+ AIMessage(content=test_content),
+ Message(content=test_content, role="QA"),
]
text = str(msgs)
- roles = ['user', 'system', 'assistant', 'QA']
+ roles = ["user", "system", "assistant", "QA"]
assert all([i in text for i in roles])
+
+
+@pytest.mark.asyncio
+def test_message():
+ m = Message(content="a", role="v1")
+ v = m.dump()
+ d = json.loads(v)
+ assert d
+ assert d.get("content") == "a"
+ assert d.get("role") == "v1"
+ m.role = "v2"
+ v = m.dump()
+ assert v
+ m = Message.load(v)
+ assert m.content == "a"
+ assert m.role == "v2"
+
+ m = Message(content="a", role="b", cause_by="c", x="d", send_to="c")
+ assert m.content == "a"
+ assert m.role == "b"
+ assert m.send_to == {"c"}
+ assert m.cause_by == "c"
+
+ m.cause_by = "Message"
+ assert m.cause_by == "Message"
+ m.cause_by = Action
+ assert m.cause_by == any_to_str(Action)
+ m.cause_by = Action()
+ assert m.cause_by == any_to_str(Action)
+ m.content = "b"
+ assert m.content == "b"
+
+
+@pytest.mark.asyncio
+def test_routes():
+ m = Message(content="a", role="b", cause_by="c", x="d", send_to="c")
+ m.send_to = "b"
+ assert m.send_to == {"b"}
+ m.send_to = {"e", Action}
+ assert m.send_to == {"e", any_to_str(Action)}
+
+
+def test_message_serdeser():
+ out_mapping = {"field3": (str, ...), "field4": (list[str], ...)}
+ out_data = {"field3": "field3 value3", "field4": ["field4 value1", "field4 value2"]}
+ ic_obj = ActionNode.create_model_class("code", out_mapping)
+
+ message = Message(content="code", instruct_content=ic_obj(**out_data), role="engineer", cause_by=WriteCode)
+ message_dict = message.dict()
+ assert message_dict["cause_by"] == "metagpt.actions.write_code.WriteCode"
+ assert message_dict["instruct_content"] == {
+ "class": "code",
+ "mapping": {"field3": "(, Ellipsis)", "field4": "(list[str], Ellipsis)"},
+ "value": {"field3": "field3 value3", "field4": ["field4 value1", "field4 value2"]},
+ }
+
+ new_message = Message(**message_dict)
+ assert new_message.content == message.content
+ assert new_message.instruct_content == message.instruct_content
+ assert new_message.cause_by == message.cause_by
+ assert new_message.instruct_content.field3 == out_data["field3"]
+
+ message = Message(content="code")
+ message_dict = message.dict()
+ new_message = Message(**message_dict)
+ assert new_message.instruct_content is None
+ assert new_message.cause_by == "metagpt.actions.add_requirement.UserRequirement"
diff --git a/tests/metagpt/test_software_company.py b/tests/metagpt/test_software_company.py
deleted file mode 100644
index 4fc651f52..000000000
--- a/tests/metagpt/test_software_company.py
+++ /dev/null
@@ -1,19 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8 -*-
-"""
-@Time : 2023/5/15 11:40
-@Author : alexanderwu
-@File : test_software_company.py
-"""
-import pytest
-
-from metagpt.logs import logger
-from metagpt.team import Team
-
-
-@pytest.mark.asyncio
-async def test_team():
- company = Team()
- company.start_project("做一个基础搜索引擎,可以支持知识库")
- history = await company.run(n_round=5)
- logger.info(history)
diff --git a/tests/metagpt/test_startup.py b/tests/metagpt/test_startup.py
new file mode 100644
index 000000000..c34fd2c31
--- /dev/null
+++ b/tests/metagpt/test_startup.py
@@ -0,0 +1,28 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/5/15 11:40
+@Author : alexanderwu
+@File : test_startup.py
+"""
+import pytest
+from typer.testing import CliRunner
+
+from metagpt.logs import logger
+from metagpt.team import Team
+
+runner = CliRunner()
+
+
+@pytest.mark.asyncio
+async def test_team():
+ # FIXME: we're now using "metagpt" cli, so the entrance should be replaced instead.
+ company = Team()
+ company.run_project("做一个基础搜索引擎,可以支持知识库")
+ history = await company.run(n_round=5)
+ logger.info(history)
+
+
+# def test_startup():
+# args = ["Make a 2048 game"]
+# result = runner.invoke(app, args)
diff --git a/tests/metagpt/test_subscription.py b/tests/metagpt/test_subscription.py
new file mode 100644
index 000000000..2e898424d
--- /dev/null
+++ b/tests/metagpt/test_subscription.py
@@ -0,0 +1,102 @@
+import asyncio
+
+import pytest
+
+from metagpt.roles import Role
+from metagpt.schema import Message
+from metagpt.subscription import SubscriptionRunner
+
+
+@pytest.mark.asyncio
+async def test_subscription_run():
+ callback_done = 0
+
+ async def trigger():
+ while True:
+ yield Message("the latest news about OpenAI")
+ await asyncio.sleep(3600 * 24)
+
+ class MockRole(Role):
+ async def run(self, message=None):
+ return Message("")
+
+ async def callback(message):
+ nonlocal callback_done
+ callback_done += 1
+
+ runner = SubscriptionRunner()
+
+ roles = []
+ for _ in range(2):
+ role = MockRole()
+ roles.append(role)
+ await runner.subscribe(role, trigger(), callback)
+
+ task = asyncio.get_running_loop().create_task(runner.run())
+
+ for _ in range(10):
+ if callback_done == 2:
+ break
+ await asyncio.sleep(0)
+ else:
+ raise TimeoutError("callback not call")
+
+ role = roles[0]
+ assert role in runner.tasks
+ await runner.unsubscribe(roles[0])
+
+ for _ in range(10):
+ if role not in runner.tasks:
+ break
+ await asyncio.sleep(0)
+ else:
+ raise TimeoutError("callback not call")
+
+ task.cancel()
+ for i in runner.tasks.values():
+ i.cancel()
+
+
+@pytest.mark.asyncio
+async def test_subscription_run_error(loguru_caplog):
+ async def trigger1():
+ while True:
+ yield Message("the latest news about OpenAI")
+ await asyncio.sleep(3600 * 24)
+
+ async def trigger2():
+ yield Message("the latest news about OpenAI")
+
+ class MockRole1(Role):
+ async def run(self, message=None):
+ raise RuntimeError
+
+ class MockRole2(Role):
+ async def run(self, message=None):
+ return Message("")
+
+ async def callback(msg: Message):
+ print(msg)
+
+ runner = SubscriptionRunner()
+ await runner.subscribe(MockRole1(), trigger1(), callback)
+ with pytest.raises(RuntimeError):
+ await runner.run()
+
+ await runner.subscribe(MockRole2(), trigger2(), callback)
+ task = asyncio.get_running_loop().create_task(runner.run(False))
+
+ for _ in range(10):
+ if not runner.tasks:
+ break
+ await asyncio.sleep(0)
+ else:
+ raise TimeoutError("wait runner tasks empty timeout")
+
+ task.cancel()
+ for i in runner.tasks.values():
+ i.cancel()
+ assert len(loguru_caplog.records) >= 2
+ logs = "".join(loguru_caplog.messages)
+ assert "run error" in logs
+ assert "has completed" in logs
diff --git a/tests/metagpt/test_team.py b/tests/metagpt/test_team.py
new file mode 100644
index 000000000..930306b5e
--- /dev/null
+++ b/tests/metagpt/test_team.py
@@ -0,0 +1,13 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+# @Desc : unittest of team
+
+from metagpt.roles.project_manager import ProjectManager
+from metagpt.team import Team
+
+
+def test_team():
+ company = Team()
+ company.hire([ProjectManager()])
+
+ assert len(company.environment.roles) == 1
diff --git a/tests/metagpt/tools/test_code_interpreter.py b/tests/metagpt/tools/test_code_interpreter.py
index 0eec3f80b..03d4ce8df 100644
--- a/tests/metagpt/tools/test_code_interpreter.py
+++ b/tests/metagpt/tools/test_code_interpreter.py
@@ -1,23 +1,22 @@
-import pytest
-import pandas as pd
from pathlib import Path
-from tests.data import sales_desc, store_desc
-from metagpt.tools.code_interpreter import OpenCodeInterpreter, OpenInterpreterDecorator
+import pandas as pd
+import pytest
+
from metagpt.actions import Action
from metagpt.logs import logger
+from metagpt.tools.code_interpreter import OpenCodeInterpreter, OpenInterpreterDecorator
-
-logger.add('./tests/data/test_ci.log')
+logger.add("./tests/data/test_ci.log")
stock = "./tests/data/baba_stock.csv"
# TODO: 需要一种表格数据格式,能够支持schame管理的,标注字段类型和字段含义。
class CreateStockIndicators(Action):
@OpenInterpreterDecorator(save_code=True, code_file_path="./tests/data/stock_indicators.py")
- async def run(self, stock_path: str, indicators=['Simple Moving Average', 'BollingerBands']) -> pd.DataFrame:
+ async def run(self, stock_path: str, indicators=["Simple Moving Average", "BollingerBands"]) -> pd.DataFrame:
"""对stock_path中的股票数据, 使用pandas和ta计算indicators中的技术指标, 返回带有技术指标的股票数据,不需要去除空值, 不需要安装任何包;
- 指标生成对应的三列: SMA, BB_upper, BB_lower
+ 指标生成对应的三列: SMA, BB_upper, BB_lower
"""
...
@@ -25,18 +24,20 @@ class CreateStockIndicators(Action):
@pytest.mark.asyncio
async def test_actions():
# 计算指标
- indicators = ['Simple Moving Average', 'BollingerBands']
+ indicators = ["Simple Moving Average", "BollingerBands"]
stocker = CreateStockIndicators()
df, msg = await stocker.run(stock, indicators=indicators)
assert isinstance(df, pd.DataFrame)
- assert 'Close' in df.columns
- assert 'Date' in df.columns
+ assert "Close" in df.columns
+ assert "Date" in df.columns
# 将df保存为文件,将文件路径传入到下一个action
- df_path = './tests/data/stock_indicators.csv'
+ df_path = "./tests/data/stock_indicators.csv"
df.to_csv(df_path)
assert Path(df_path).is_file()
# 可视化指标结果
- figure_path = './tests/data/figure_ci.png'
+ figure_path = "./tests/data/figure_ci.png"
ci_ploter = OpenCodeInterpreter()
- ci_ploter.chat(f"使用seaborn对{df_path}中与股票布林带有关的数据列的Date, Close, SMA, BB_upper(布林带上界), BB_lower(布林带下界)进行可视化, 可视化图片保存在{figure_path}中。不需要任何指标计算,把Date列转换为日期类型。要求图片优美,BB_upper, BB_lower之间使用合适的颜色填充。")
+ ci_ploter.chat(
+ f"使用seaborn对{df_path}中与股票布林带有关的数据列的Date, Close, SMA, BB_upper(布林带上界), BB_lower(布林带下界)进行可视化, 可视化图片保存在{figure_path}中。不需要任何指标计算,把Date列转换为日期类型。要求图片优美,BB_upper, BB_lower之间使用合适的颜色填充。"
+ )
assert Path(figure_path).is_file()
diff --git a/tests/metagpt/tools/test_prompt_generator.py b/tests/metagpt/tools/test_prompt_generator.py
index d2e870c6d..ddbd2c43b 100644
--- a/tests/metagpt/tools/test_prompt_generator.py
+++ b/tests/metagpt/tools/test_prompt_generator.py
@@ -20,8 +20,9 @@ from metagpt.tools.prompt_writer import (
@pytest.mark.usefixtures("llm_api")
def test_gpt_prompt_generator(llm_api):
generator = GPTPromptGenerator()
- example = "商品名称:WonderLab 新肌果味代餐奶昔 小胖瓶 胶原蛋白升级版 饱腹代餐粉6瓶 75g/瓶(6瓶/盒) 店铺名称:金力宁食品专营店 " \
- "品牌:WonderLab 保质期:1年 产地:中国 净含量:450g"
+ example = (
+ "商品名称:WonderLab 新肌果味代餐奶昔 小胖瓶 胶原蛋白升级版 饱腹代餐粉6瓶 75g/瓶(6瓶/盒) 店铺名称:金力宁食品专营店 " "品牌:WonderLab 保质期:1年 产地:中国 净含量:450g"
+ )
results = llm_api.ask_batch(generator.gen(example))
logger.info(results)
@@ -46,7 +47,7 @@ def test_enron_template(llm_api):
results = template.gen(subj)
assert len(results) > 0
- assert any("Write an email with the subject \"Meeting Agenda\"." in r for r in results)
+ assert any('Write an email with the subject "Meeting Agenda".' in r for r in results)
def test_beagec_template():
@@ -54,5 +55,6 @@ def test_beagec_template():
results = template.gen()
assert len(results) > 0
- assert any("Edit and revise this document to improve its grammar, vocabulary, spelling, and style."
- in r for r in results)
+ assert any(
+ "Edit and revise this document to improve its grammar, vocabulary, spelling, and style." in r for r in results
+ )
diff --git a/tests/metagpt/tools/test_sd_tool.py b/tests/metagpt/tools/test_sd_tool.py
index 77e53c7dc..e457101a9 100644
--- a/tests/metagpt/tools/test_sd_tool.py
+++ b/tests/metagpt/tools/test_sd_tool.py
@@ -1,10 +1,11 @@
# -*- coding: utf-8 -*-
# @Date : 2023/7/22 02:40
-# @Author : stellahong (stellahong@fuzhi.ai)
+# @Author : stellahong (stellahong@deepwisdom.ai)
#
import os
-from metagpt.tools.sd_engine import SDEngine, WORKSPACE_ROOT
+from metagpt.config import CONFIG
+from metagpt.tools.sd_engine import SDEngine
def test_sd_engine_init():
@@ -21,5 +22,5 @@ def test_sd_engine_generate_prompt():
async def test_sd_engine_run_t2i():
sd_engine = SDEngine()
await sd_engine.run_t2i(prompts=["test"])
- img_path = WORKSPACE_ROOT / "resources" / "SD_Output" / "output_0.png"
- assert os.path.exists(img_path) == True
+ img_path = CONFIG.workspace_path / "resources" / "SD_Output" / "output_0.png"
+ assert os.path.exists(img_path)
diff --git a/tests/metagpt/tools/test_search_engine.py b/tests/metagpt/tools/test_search_engine.py
index a7fe063a6..25bce124a 100644
--- a/tests/metagpt/tools/test_search_engine.py
+++ b/tests/metagpt/tools/test_search_engine.py
@@ -16,7 +16,9 @@ from metagpt.tools.search_engine import SearchEngine
class MockSearchEnine:
async def run(self, query: str, max_results: int = 8, as_string: bool = True) -> str | list[dict[str, str]]:
- rets = [{"url": "https://metagpt.com/mock/{i}", "title": query, "snippet": query * i} for i in range(max_results)]
+ rets = [
+ {"url": "https://metagpt.com/mock/{i}", "title": query, "snippet": query * i} for i in range(max_results)
+ ]
return "\n".join(rets) if as_string else rets
@@ -34,10 +36,14 @@ class MockSearchEnine:
(SearchEngineType.DUCK_DUCK_GO, None, 6, False),
(SearchEngineType.CUSTOM_ENGINE, MockSearchEnine().run, 8, False),
(SearchEngineType.CUSTOM_ENGINE, MockSearchEnine().run, 6, False),
-
],
)
-async def test_search_engine(search_engine_typpe, run_func, max_results, as_string, ):
+async def test_search_engine(
+ search_engine_typpe,
+ run_func,
+ max_results,
+ as_string,
+):
search_engine = SearchEngine(search_engine_typpe, run_func)
rsp = await search_engine.run("metagpt", max_results=max_results, as_string=as_string)
logger.info(rsp)
diff --git a/tests/metagpt/tools/test_search_engine_meilisearch.py b/tests/metagpt/tools/test_search_engine_meilisearch.py
index 8d2bb6494..d5f7d162b 100644
--- a/tests/metagpt/tools/test_search_engine_meilisearch.py
+++ b/tests/metagpt/tools/test_search_engine_meilisearch.py
@@ -13,7 +13,7 @@ import pytest
from metagpt.logs import logger
from metagpt.tools.search_engine_meilisearch import DataSource, MeilisearchEngine
-MASTER_KEY = '116Qavl2qpCYNEJNv5-e0RC9kncev1nr1gt7ybEGVLk'
+MASTER_KEY = "116Qavl2qpCYNEJNv5-e0RC9kncev1nr1gt7ybEGVLk"
@pytest.fixture()
@@ -29,7 +29,7 @@ def test_meilisearch(search_engine_server):
search_engine = MeilisearchEngine(url="http://localhost:7700", token=MASTER_KEY)
# 假设有一个名为"books"的数据源,包含要添加的文档库
- books_data_source = DataSource(name='books', url='https://example.com/books')
+ books_data_source = DataSource(name="books", url="https://example.com/books")
# 假设有一个名为"documents"的文档库,包含要添加的文档
documents = [
@@ -43,4 +43,4 @@ def test_meilisearch(search_engine_server):
# 添加文档库到搜索引擎
search_engine.add_documents(books_data_source, documents)
- logger.info(search_engine.search('Book 1'))
+ logger.info(search_engine.search("Book 1"))
diff --git a/tests/metagpt/tools/test_summarize.py b/tests/metagpt/tools/test_summarize.py
index cf616c144..6a372defb 100644
--- a/tests/metagpt/tools/test_summarize.py
+++ b/tests/metagpt/tools/test_summarize.py
@@ -20,7 +20,6 @@ CASES = [
1. 请根据上下文,对用户搜索请求进行总结性回答,不要包括与请求无关的文本
2. 以 [正文](引用链接) markdown形式在正文中**自然标注**~5个文本(如商品词或类似文本段),以便跳转
3. 回复优雅、清晰,**绝不重复文本**,行文流畅,长度居中""",
-
"""# 上下文
[{'title': '去厦门 有哪些推荐的美食? - 知乎', 'href': 'https://www.zhihu.com/question/286901854', 'body': '知乎,中文互联网高质量的问答社区和创作者聚集的原创内容平台,于 2011 年 1 月正式上线,以「让人们更好的分享知识、经验和见解,找到自己的解答」为品牌使命。知乎凭借认真、专业、友善的社区氛围、独特的产品机制以及结构化和易获得的优质内容,聚集了中文互联网科技、商业、影视 ...'}, {'title': '厦门到底有哪些真正值得吃的美食? - 知乎', 'href': 'https://www.zhihu.com/question/38012322', 'body': '有几个特色菜在别处不太能吃到,值得一试~常点的有西多士、沙茶肉串、咕老肉(个人认为还是良山排档的更炉火纯青~),因为爱吃芋泥,每次还会点一个芋泥鸭~人均50元左右. 潮福城. 厦门这两年经营港式茶点的店越来越多,但是最经典的还是潮福城的茶点 ...'}, {'title': '超全厦门美食攻略,好吃不贵不踩雷 - 知乎 - 知乎专栏', 'href': 'https://zhuanlan.zhihu.com/p/347055615', 'body': '厦门老字号店铺,味道卫生都有保障,喜欢吃芒果的,不要错过芒果牛奶绵绵冰. 285蚝味馆 70/人. 上过《舌尖上的中国》味道不用多说,想吃地道的海鲜烧烤就来这里. 堂宴.老厦门私房菜 80/人. 非常多的明星打卡过,上过《十二道锋味》,吃厦门传统菜的好去处 ...'}, {'title': '福建名小吃||寻味厦门,十大特色名小吃,你都吃过哪几样? - 知乎', 'href': 'https://zhuanlan.zhihu.com/p/375781836', 'body': '第一期,分享厦门的特色美食。 厦门是一个风景旅游城市,许多人来到厦门,除了游览厦门独特的风景之外,最难忘的应该是厦门的特色小吃。厦门小吃多种多样,有到厦门必吃的沙茶面、米线糊、蚵仔煎、土笋冻等非常之多。那么,厦门的名小吃有哪些呢?'}, {'title': '大家如果去厦门旅游的话,好吃的有很多,但... 来自庄时利和 - 微博', 'href': 'https://weibo.com/1728715190/MEAwzscRT', 'body': '大家如果去厦门旅游的话,好吃的有很多,但如果只选一样的话,我个人会选择莲花煎蟹。 靠海吃海,吃蟹对于闽南人来说是很平常的一件事。 厦门传统的做法多是清蒸或水煮,上世纪八十年代有一同安人在厦门的莲花公园旁,摆摊做起了煎蟹的生意。'}, {'title': '厦门美食,厦门美食攻略,厦门旅游美食攻略 - 马蜂窝', 'href': 'https://www.mafengwo.cn/cy/10132/gonglve.html', 'body': '醉壹号海鲜大排档 (厦门美食地标店) No.3. 哆啦Eanny 的最新点评:. 环境 挺复古的闽南风情,花砖地板,一楼有海鲜自己点菜,二楼室内位置,三楼露天位置,环境挺不错的。. 苦螺汤,看起来挺清的,螺肉吃起来很脆。. 姜... 5.0 分. 482 条用户点评.'}, {'title': '厦门超强中山路小吃合集,29家本地人推荐的正宗美食 - 马蜂窝', 'href': 'https://www.mafengwo.cn/gonglve/ziyouxing/176485.html', 'body': '莲欢海蛎煎. 提到厦门就想到海蛎煎,而这家位于中山路局口街的莲欢海蛎煎是实打实的好吃!. ·局口街老巷之中,全室外环境,吃的就是这种感觉。. ·取名"莲欢",是希望妻子每天开心。. 新鲜的食材,实在的用料,这样的用心也定能讨食客欢心。. ·海蛎又 ...'}, {'title': '厦门市 10 大餐厅- Tripadvisor', 'href': 'https://cn.tripadvisor.com/Restaurants-g297407-Xiamen_Fujian.html', 'body': '厦门市餐厅:在Tripadvisor查看中国厦门市餐厅的点评,并以价格、地点及更多选项进行搜索。 ... "牛排太好吃了啊啊啊" ... "厦门地区最老品牌最有口碑的潮州菜餐厅" ...'}, {'title': '#福建10条美食街简直不要太好吃#每到一... 来自新浪厦门 - 微博', 'href': 'https://weibo.com/1740522895/MF1lY7W4n', 'body': '福建的这10条美食街,你一定不能错过!福州师大学生街、福州达明路美食街、厦门八市、漳州古城老街、宁德老南门电影院美食集市、龙岩中山路美食街、三明龙岗夜市、莆田金鼎夜市、莆田玉湖夜市、南平嘉禾美食街。世间万事皆难,唯有美食可以治愈一切。'}, {'title': '厦门这50家餐厅最值得吃 - 腾讯新闻', 'href': 'https://new.qq.com/rain/a/20200114A09HJT00', 'body': '没有什么事是一顿辣解决不了的! 创意辣、川湘辣、温柔辣、异域辣,芙蓉涧的菜能把辣椒玩出花来! ... 早在2005年,这家老牌的东南亚餐厅就开在厦门莲花了,在许多老厦门的心中,都觉得这里有全厦门最好吃的咖喱呢。 ...'}, {'title': '好听的美食?又好听又好吃的食物有什么? - 哔哩哔哩', 'href': 'https://www.bilibili.com/read/cv23430069/', 'body': '专栏 / 好听的美食?又好听又好吃的食物有什么? 又好听又好吃的食物有什么? 2023-05-02 18:01 --阅读 · --喜欢 · --评论'}]
@@ -31,7 +30,7 @@ CASES = [
你是专业管家团队的一员,会给出有帮助的建议
1. 请根据上下文,对用户搜索请求进行总结性回答,不要包括与请求无关的文本
2. 以 [正文](引用链接) markdown形式在正文中**自然标注**3-5个文本(如商品词或类似文本段),以便跳转
-3. 回复优雅、清晰,**绝不重复文本**,行文流畅,长度居中"""
+3. 回复优雅、清晰,**绝不重复文本**,行文流畅,长度居中""",
]
diff --git a/tests/metagpt/tools/test_translate.py b/tests/metagpt/tools/test_translate.py
index 47a9034a5..024bda3ca 100644
--- a/tests/metagpt/tools/test_translate.py
+++ b/tests/metagpt/tools/test_translate.py
@@ -16,7 +16,7 @@ from metagpt.tools.translator import Translator
def test_translate(llm_api):
poetries = [
("Let life be beautiful like summer flowers", "花"),
- ("The ancient Chinese poetries are all songs.", "中国")
+ ("The ancient Chinese poetries are all songs.", "中国"),
]
for i, j in poetries:
prompt = Translator.translate_prompt(i)
diff --git a/tests/metagpt/tools/test_ut_generator.py b/tests/metagpt/tools/test_ut_generator.py
index 6f29999d4..2ae94885f 100644
--- a/tests/metagpt/tools/test_ut_generator.py
+++ b/tests/metagpt/tools/test_ut_generator.py
@@ -16,8 +16,12 @@ class TestUTWriter:
tags = ["测试"] # "智能合同导入", "律师审查", "ai合同审查", "草拟合同&律师在线审查", "合同审批", "履约管理", "签约公司"]
# 这里在文件中手动加入了两个测试标签的API
- utg = UTGenerator(swagger_file=swagger_file, ut_py_path=UT_PY_PATH, questions_path=API_QUESTIONS_PATH,
- template_prefix=YFT_PROMPT_PREFIX)
+ utg = UTGenerator(
+ swagger_file=swagger_file,
+ ut_py_path=UT_PY_PATH,
+ questions_path=API_QUESTIONS_PATH,
+ template_prefix=YFT_PROMPT_PREFIX,
+ )
ret = utg.generate_ut(include_tags=tags)
# 后续加入对文件生成内容与数量的检验
assert ret
diff --git a/tests/metagpt/tools/test_web_browser_engine.py b/tests/metagpt/tools/test_web_browser_engine.py
index b08d0ca10..28dd0e15c 100644
--- a/tests/metagpt/tools/test_web_browser_engine.py
+++ b/tests/metagpt/tools/test_web_browser_engine.py
@@ -7,8 +7,8 @@ from metagpt.tools import WebBrowserEngineType, web_browser_engine
@pytest.mark.parametrize(
"browser_type, url, urls",
[
- (WebBrowserEngineType.PLAYWRIGHT, "https://fuzhi.ai", ("https://fuzhi.ai",)),
- (WebBrowserEngineType.SELENIUM, "https://fuzhi.ai", ("https://fuzhi.ai",)),
+ (WebBrowserEngineType.PLAYWRIGHT, "https://deepwisdom.ai", ("https://deepwisdom.ai",)),
+ (WebBrowserEngineType.SELENIUM, "https://deepwisdom.ai", ("https://deepwisdom.ai",)),
],
ids=["playwright", "selenium"],
)
diff --git a/tests/metagpt/tools/test_web_browser_engine_playwright.py b/tests/metagpt/tools/test_web_browser_engine_playwright.py
index 69e1339e7..e9ea80b10 100644
--- a/tests/metagpt/tools/test_web_browser_engine_playwright.py
+++ b/tests/metagpt/tools/test_web_browser_engine_playwright.py
@@ -8,9 +8,9 @@ from metagpt.tools import web_browser_engine_playwright
@pytest.mark.parametrize(
"browser_type, use_proxy, kwagrs, url, urls",
[
- ("chromium", {"proxy": True}, {}, "https://fuzhi.ai", ("https://fuzhi.ai",)),
- ("firefox", {}, {"ignore_https_errors": True}, "https://fuzhi.ai", ("https://fuzhi.ai",)),
- ("webkit", {}, {"ignore_https_errors": True}, "https://fuzhi.ai", ("https://fuzhi.ai",)),
+ ("chromium", {"proxy": True}, {}, "https://deepwisdom.ai", ("https://deepwisdom.ai",)),
+ ("firefox", {}, {"ignore_https_errors": True}, "https://deepwisdom.ai", ("https://deepwisdom.ai",)),
+ ("webkit", {}, {"ignore_https_errors": True}, "https://deepwisdom.ai", ("https://deepwisdom.ai",)),
],
ids=["chromium-normal", "firefox-normal", "webkit-normal"],
)
diff --git a/tests/metagpt/tools/test_web_browser_engine_selenium.py b/tests/metagpt/tools/test_web_browser_engine_selenium.py
index ce322f7bd..ac6eafee7 100644
--- a/tests/metagpt/tools/test_web_browser_engine_selenium.py
+++ b/tests/metagpt/tools/test_web_browser_engine_selenium.py
@@ -8,9 +8,9 @@ from metagpt.tools import web_browser_engine_selenium
@pytest.mark.parametrize(
"browser_type, use_proxy, url, urls",
[
- ("chrome", True, "https://fuzhi.ai", ("https://fuzhi.ai",)),
- ("firefox", False, "https://fuzhi.ai", ("https://fuzhi.ai",)),
- ("edge", False, "https://fuzhi.ai", ("https://fuzhi.ai",)),
+ ("chrome", True, "https://deepwisdom.ai", ("https://deepwisdom.ai",)),
+ ("firefox", False, "https://deepwisdom.ai", ("https://deepwisdom.ai",)),
+ ("edge", False, "https://deepwisdom.ai", ("https://deepwisdom.ai",)),
],
ids=["chrome-normal", "firefox-normal", "edge-normal"],
)
diff --git a/tests/metagpt/utils/test_ahttp_client.py b/tests/metagpt/utils/test_ahttp_client.py
new file mode 100644
index 000000000..a595d645f
--- /dev/null
+++ b/tests/metagpt/utils/test_ahttp_client.py
@@ -0,0 +1,29 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+# @Desc : unittest of ahttp_client
+
+import pytest
+
+from metagpt.utils.ahttp_client import apost, apost_stream
+
+
+@pytest.mark.asyncio
+async def test_apost():
+ result = await apost(url="https://www.baidu.com/")
+ assert "百度一下" in result
+
+ result = await apost(
+ url="http://aider.meizu.com/app/weather/listWeather", data={"cityIds": "101240101"}, as_json=True
+ )
+ assert result["code"] == "200"
+
+
+@pytest.mark.asyncio
+async def test_apost_stream():
+ result = apost_stream(url="https://www.baidu.com/")
+ async for line in result:
+ assert len(line) >= 0
+
+ result = apost_stream(url="http://aider.meizu.com/app/weather/listWeather", data={"cityIds": "101240101"})
+ async for line in result:
+ assert len(line) >= 0
diff --git a/tests/metagpt/utils/test_code_parser.py b/tests/metagpt/utils/test_code_parser.py
index 707b558e1..6b7349cd9 100644
--- a/tests/metagpt/utils/test_code_parser.py
+++ b/tests/metagpt/utils/test_code_parser.py
@@ -131,10 +131,10 @@ class TestCodeParser:
def test_parse_file_list(self, parser, text):
result = parser.parse_file_list("Task list", text)
print(result)
- assert result == ['task1', 'task2']
+ assert result == ["task1", "task2"]
-if __name__ == '__main__':
+if __name__ == "__main__":
t = TestCodeParser()
t.test_parse_file_list(CodeParser(), t_text)
# TestCodeParser.test_parse_file_list()
diff --git a/tests/metagpt/utils/test_common.py b/tests/metagpt/utils/test_common.py
index ec4443175..4bd38db63 100644
--- a/tests/metagpt/utils/test_common.py
+++ b/tests/metagpt/utils/test_common.py
@@ -4,27 +4,79 @@
@Time : 2023/4/29 16:19
@Author : alexanderwu
@File : test_common.py
+@Modified by: mashenquan, 2023/11/21. Add unit tests.
"""
import os
+from typing import Any, Set
import pytest
+from pydantic import BaseModel
-from metagpt.const import get_project_root
+from metagpt.actions import RunCode
+from metagpt.const import get_metagpt_root
+from metagpt.roles.tutorial_assistant import TutorialAssistant
+from metagpt.schema import Message
+from metagpt.utils.common import any_to_str, any_to_str_set
class TestGetProjectRoot:
def change_etc_dir(self):
# current_directory = Path.cwd()
- abs_root = '/etc'
+ abs_root = "/etc"
os.chdir(abs_root)
def test_get_project_root(self):
- project_root = get_project_root()
- assert project_root.name == 'metagpt'
+ project_root = get_metagpt_root()
+ assert project_root.name == "metagpt"
def test_get_root_exception(self):
with pytest.raises(Exception) as exc_info:
self.change_etc_dir()
- get_project_root()
+ get_metagpt_root()
assert str(exc_info.value) == "Project root not found."
+
+ def test_any_to_str(self):
+ class Input(BaseModel):
+ x: Any
+ want: str
+
+ inputs = [
+ Input(x=TutorialAssistant, want="metagpt.roles.tutorial_assistant.TutorialAssistant"),
+ Input(x=TutorialAssistant(), want="metagpt.roles.tutorial_assistant.TutorialAssistant"),
+ Input(x=RunCode, want="metagpt.actions.run_code.RunCode"),
+ Input(x=RunCode(), want="metagpt.actions.run_code.RunCode"),
+ Input(x=Message, want="metagpt.schema.Message"),
+ Input(x=Message(""), want="metagpt.schema.Message"),
+ Input(x="A", want="A"),
+ ]
+ for i in inputs:
+ v = any_to_str(i.x)
+ assert v == i.want
+
+ def test_any_to_str_set(self):
+ class Input(BaseModel):
+ x: Any
+ want: Set
+
+ inputs = [
+ Input(
+ x=[TutorialAssistant, RunCode(), "a"],
+ want={"metagpt.roles.tutorial_assistant.TutorialAssistant", "metagpt.actions.run_code.RunCode", "a"},
+ ),
+ Input(
+ x={TutorialAssistant, RunCode(), "a"},
+ want={"metagpt.roles.tutorial_assistant.TutorialAssistant", "metagpt.actions.run_code.RunCode", "a"},
+ ),
+ Input(
+ x=(TutorialAssistant, RunCode(), "a"),
+ want={"metagpt.roles.tutorial_assistant.TutorialAssistant", "metagpt.actions.run_code.RunCode", "a"},
+ ),
+ ]
+ for i in inputs:
+ v = any_to_str_set(i.x)
+ assert v == i.want
+
+
+if __name__ == "__main__":
+ pytest.main([__file__, "-s"])
diff --git a/tests/metagpt/utils/test_config.py b/tests/metagpt/utils/test_config.py
index 558a4e5a4..b68a535f9 100644
--- a/tests/metagpt/utils/test_config.py
+++ b/tests/metagpt/utils/test_config.py
@@ -20,12 +20,12 @@ def test_config_class_is_singleton():
def test_config_class_get_key_exception():
with pytest.raises(Exception) as exc_info:
config = Config()
- config.get('wtf')
+ config.get("wtf")
assert str(exc_info.value) == "Key 'wtf' not found in environment variables or in the YAML file"
def test_config_yaml_file_not_exists():
- config = Config('wtf.yaml')
+ config = Config("wtf.yaml")
with pytest.raises(Exception) as exc_info:
- config.get('OPENAI_BASE_URL')
+ config.get("OPENAI_BASE_URL")
assert str(exc_info.value) == "Key 'OPENAI_BASE_URL' not found in environment variables or in the YAML file"
diff --git a/tests/metagpt/utils/test_custom_aio_session.py b/tests/metagpt/utils/test_custom_aio_session.py
index 3a8a7bf7e..e2876e4b8 100644
--- a/tests/metagpt/utils/test_custom_aio_session.py
+++ b/tests/metagpt/utils/test_custom_aio_session.py
@@ -10,12 +10,12 @@ from metagpt.provider.openai_api import OpenAIGPTAPI
async def try_hello(api):
- batch = [[{'role': 'user', 'content': 'hello'}]]
+ batch = [[{"role": "user", "content": "hello"}]]
results = await api.acompletion_batch_text(batch)
return results
async def aask_batch(api: OpenAIGPTAPI):
- results = await api.aask_batch(['hi', 'write python hello world.'])
+ results = await api.aask_batch(["hi", "write python hello world."])
logger.info(results)
return results
diff --git a/tests/metagpt/utils/test_custom_decoder.py b/tests/metagpt/utils/test_custom_decoder.py
index c7b14ad59..4af7a6cdc 100644
--- a/tests/metagpt/utils/test_custom_decoder.py
+++ b/tests/metagpt/utils/test_custom_decoder.py
@@ -6,6 +6,7 @@
@File : test_custom_decoder.py
"""
+import pytest
from metagpt.utils.custom_decoder import CustomDecoder
@@ -37,6 +38,46 @@ def test_parse_single_quote():
parsed_data = decoder.decode(input_data)
assert 'a"\n b' in parsed_data
+ input_data = """{
+ 'a': "
+ b
+"
+}
+"""
+ with pytest.raises(Exception):
+ parsed_data = decoder.decode(input_data)
+
+ input_data = """{
+ 'a': '
+ b
+'
+}
+"""
+ with pytest.raises(Exception):
+ parsed_data = decoder.decode(input_data)
+
+
+def test_parse_double_quote():
+ decoder = CustomDecoder(strict=False)
+
+ input_data = """{
+ "a": "
+ b
+"
+}
+"""
+ parsed_data = decoder.decode(input_data)
+ assert parsed_data["a"] == "\n b\n"
+
+ input_data = """{
+ "a": '
+ b
+'
+}
+"""
+ parsed_data = decoder.decode(input_data)
+ assert parsed_data["a"] == "\n b\n"
+
def test_parse_triple_double_quote():
# Create a custom JSON decoder
@@ -54,6 +95,10 @@ def test_parse_triple_double_quote():
parsed_data = decoder.decode(input_data)
assert parsed_data["a"] == "b"
+ input_data = "{\"\"\"a\"\"\": '''b'''}"
+ parsed_data = decoder.decode(input_data)
+ assert parsed_data["a"] == "b"
+
def test_parse_triple_single_quote():
# Create a custom JSON decoder
diff --git a/tests/metagpt/utils/test_dependency_file.py b/tests/metagpt/utils/test_dependency_file.py
new file mode 100644
index 000000000..ae4d40ea5
--- /dev/null
+++ b/tests/metagpt/utils/test_dependency_file.py
@@ -0,0 +1,64 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/11/22
+@Author : mashenquan
+@File : test_dependency_file.py
+@Desc: Unit tests for dependency_file.py
+"""
+from __future__ import annotations
+
+from pathlib import Path
+from typing import Optional, Set, Union
+
+import pytest
+from pydantic import BaseModel
+
+from metagpt.utils.dependency_file import DependencyFile
+
+
+@pytest.mark.asyncio
+async def test_dependency_file():
+ class Input(BaseModel):
+ x: Union[Path, str]
+ deps: Optional[Set[Union[Path, str]]]
+ key: Optional[Union[Path, str]]
+ want: Set[str]
+
+ inputs = [
+ Input(x="a/b.txt", deps={"c/e.txt", Path(__file__).parent / "d.txt"}, want={"c/e.txt", "d.txt"}),
+ Input(
+ x=Path(__file__).parent / "x/b.txt",
+ deps={"s/e.txt", Path(__file__).parent / "d.txt"},
+ key="x/b.txt",
+ want={"s/e.txt", "d.txt"},
+ ),
+ Input(x="f.txt", deps=None, want=set()),
+ Input(x="a/b.txt", deps=None, want=set()),
+ ]
+
+ file = DependencyFile(workdir=Path(__file__).parent)
+
+ for i in inputs:
+ await file.update(filename=i.x, dependencies=i.deps)
+ assert await file.get(filename=i.key or i.x) == i.want
+
+ file2 = DependencyFile(workdir=Path(__file__).parent)
+ file2.delete_file()
+ assert not file.exists
+ await file2.update(filename="a/b.txt", dependencies={"c/e.txt", Path(__file__).parent / "d.txt"}, persist=False)
+ assert not file.exists
+ await file2.save()
+ assert file2.exists
+
+ file1 = DependencyFile(workdir=Path(__file__).parent)
+ assert file1.exists
+ assert await file1.get("a/b.txt") == set()
+ await file1.load()
+ assert await file1.get("a/b.txt") == {"c/e.txt", "d.txt"}
+ file1.delete_file()
+ assert not file.exists
+
+
+if __name__ == "__main__":
+ pytest.main([__file__, "-s"])
diff --git a/tests/metagpt/utils/test_file.py b/tests/metagpt/utils/test_file.py
index b30e6be93..83e317213 100644
--- a/tests/metagpt/utils/test_file.py
+++ b/tests/metagpt/utils/test_file.py
@@ -15,12 +15,11 @@ from metagpt.utils.file import File
@pytest.mark.asyncio
@pytest.mark.parametrize(
("root_path", "filename", "content"),
- [(Path("/code/MetaGPT/data/tutorial_docx/2023-09-07_17-05-20"), "test.md", "Hello World!")]
+ [(Path("/code/MetaGPT/data/tutorial_docx/2023-09-07_17-05-20"), "test.md", "Hello World!")],
)
async def test_write_and_read_file(root_path: Path, filename: str, content: bytes):
- full_file_name = await File.write(root_path=root_path, filename=filename, content=content.encode('utf-8'))
+ full_file_name = await File.write(root_path=root_path, filename=filename, content=content.encode("utf-8"))
assert isinstance(full_file_name, Path)
assert root_path / filename == full_file_name
file_data = await File.read(full_file_name)
assert file_data.decode("utf-8") == content
-
diff --git a/tests/metagpt/utils/test_file_repository.py b/tests/metagpt/utils/test_file_repository.py
new file mode 100644
index 000000000..92e5204c5
--- /dev/null
+++ b/tests/metagpt/utils/test_file_repository.py
@@ -0,0 +1,55 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/11/20
+@Author : mashenquan
+@File : test_file_repository.py
+@Desc: Unit tests for file_repository.py
+"""
+import shutil
+from pathlib import Path
+
+import pytest
+
+from metagpt.utils.git_repository import ChangeType, GitRepository
+from tests.metagpt.utils.test_git_repository import mock_file
+
+
+@pytest.mark.asyncio
+async def test_file_repo():
+ local_path = Path(__file__).parent / "file_repo_git"
+ if local_path.exists():
+ shutil.rmtree(local_path)
+
+ git_repo = GitRepository(local_path=local_path, auto_init=True)
+ assert not git_repo.changed_files
+
+ await mock_file(local_path / "g.txt", "")
+
+ file_repo_path = "file_repo1"
+ full_path = local_path / file_repo_path
+ assert not full_path.exists()
+ file_repo = git_repo.new_file_repository(file_repo_path)
+ assert file_repo.workdir == full_path
+ assert file_repo.workdir.exists()
+ await file_repo.save("a.txt", "AAA")
+ await file_repo.save("b.txt", "BBB", ["a.txt"])
+ doc = await file_repo.get("a.txt")
+ assert "AAA" == doc.content
+ doc = await file_repo.get("b.txt")
+ assert "BBB" == doc.content
+ assert {"a.txt"} == await file_repo.get_dependency("b.txt")
+ assert {"a.txt": ChangeType.UNTRACTED, "b.txt": ChangeType.UNTRACTED} == file_repo.changed_files
+ assert {"a.txt"} == await file_repo.get_changed_dependency("b.txt")
+ await file_repo.save("d/e.txt", "EEE")
+ assert ["d/e.txt"] == file_repo.get_change_dir_files("d")
+ assert set(file_repo.all_files) == {"a.txt", "b.txt", "d/e.txt"}
+ await file_repo.delete("d/e.txt")
+ await file_repo.delete("d/e.txt") # delete twice
+ assert set(file_repo.all_files) == {"a.txt", "b.txt"}
+
+ git_repo.delete_repository()
+
+
+if __name__ == "__main__":
+ pytest.main([__file__, "-s"])
diff --git a/tests/metagpt/utils/test_git_repository.py b/tests/metagpt/utils/test_git_repository.py
new file mode 100644
index 000000000..d800e9594
--- /dev/null
+++ b/tests/metagpt/utils/test_git_repository.py
@@ -0,0 +1,103 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/11/20
+@Author : mashenquan
+@File : test_git_repository.py
+@Desc: Unit tests for git_repository.py
+"""
+
+import shutil
+from pathlib import Path
+
+import aiofiles
+import pytest
+
+from metagpt.utils.git_repository import GitRepository
+
+
+async def mock_file(filename, content=""):
+ async with aiofiles.open(str(filename), mode="w") as file:
+ await file.write(content)
+
+
+async def mock_repo(local_path) -> (GitRepository, Path):
+ if local_path.exists():
+ shutil.rmtree(local_path)
+ assert not local_path.exists()
+ repo = GitRepository(local_path=local_path, auto_init=True)
+ assert local_path.exists()
+ assert local_path == repo.workdir
+ assert not repo.changed_files
+
+ await mock_file(local_path / "a.txt")
+ await mock_file(local_path / "b.txt")
+ subdir = local_path / "subdir"
+ subdir.mkdir(parents=True, exist_ok=True)
+ await mock_file(subdir / "c.txt")
+ return repo, subdir
+
+
+@pytest.mark.asyncio
+async def test_git():
+ local_path = Path(__file__).parent / "git"
+ repo, subdir = await mock_repo(local_path)
+
+ assert len(repo.changed_files) == 3
+ repo.add_change(repo.changed_files)
+ repo.commit("commit1")
+ assert not repo.changed_files
+
+ await mock_file(local_path / "a.txt", "tests")
+ await mock_file(subdir / "d.txt")
+ rmfile = local_path / "b.txt"
+ rmfile.unlink()
+ assert repo.status
+
+ assert len(repo.changed_files) == 3
+ repo.add_change(repo.changed_files)
+ repo.commit("commit2")
+ assert not repo.changed_files
+
+ assert repo.status
+
+ repo.delete_repository()
+ assert not local_path.exists()
+
+
+@pytest.mark.asyncio
+async def test_git1():
+ local_path = Path(__file__).parent / "git1"
+ await mock_repo(local_path)
+
+ repo1 = GitRepository(local_path=local_path, auto_init=False)
+ assert repo1.changed_files
+
+ file_repo = repo1.new_file_repository("__pycache__")
+ await file_repo.save("a.pyc", content="")
+ all_files = repo1.get_files(relative_path=".", filter_ignored=False)
+ assert "__pycache__/a.pyc" in all_files
+ all_files = repo1.get_files(relative_path=".", filter_ignored=True)
+ assert "__pycache__/a.pyc" not in all_files
+
+ repo1.delete_repository()
+ assert not local_path.exists()
+
+
+@pytest.mark.asyncio
+async def test_dependency_file():
+ local_path = Path(__file__).parent / "git2"
+ repo, subdir = await mock_repo(local_path)
+
+ dependancy_file = await repo.get_dependency()
+ assert not dependancy_file.exists
+
+ await dependancy_file.update(filename="a/b.txt", dependencies={"c/d.txt", "e/f.txt"})
+ assert dependancy_file.exists
+
+ repo.delete_repository()
+ assert not dependancy_file.exists
+
+
+if __name__ == "__main__":
+ pytest.main([__file__, "-s"])
diff --git a/tests/metagpt/utils/test_output_parser.py b/tests/metagpt/utils/test_output_parser.py
index 4e362f9f7..c9f5813d9 100644
--- a/tests/metagpt/utils/test_output_parser.py
+++ b/tests/metagpt/utils/test_output_parser.py
@@ -14,17 +14,17 @@ from metagpt.utils.common import OutputParser
def test_parse_blocks():
test_text = "##block1\nThis is block 1.\n##block2\nThis is block 2."
- expected_result = {'block1': 'This is block 1.', 'block2': 'This is block 2.'}
+ expected_result = {"block1": "This is block 1.", "block2": "This is block 2."}
assert OutputParser.parse_blocks(test_text) == expected_result
def test_parse_code():
test_text = "```python\nprint('Hello, world!')```"
expected_result = "print('Hello, world!')"
- assert OutputParser.parse_code(test_text, 'python') == expected_result
+ assert OutputParser.parse_code(test_text, "python") == expected_result
with pytest.raises(Exception):
- OutputParser.parse_code(test_text, 'java')
+ OutputParser.parse_code(test_text, "java")
def test_parse_python_code():
@@ -45,13 +45,13 @@ def test_parse_python_code():
def test_parse_str():
test_text = "name = 'Alice'"
- expected_result = 'Alice'
+ expected_result = "Alice"
assert OutputParser.parse_str(test_text) == expected_result
def test_parse_file_list():
test_text = "files=['file1', 'file2', 'file3']"
- expected_result = ['file1', 'file2', 'file3']
+ expected_result = ["file1", "file2", "file3"]
assert OutputParser.parse_file_list(test_text) == expected_result
with pytest.raises(Exception):
@@ -60,7 +60,7 @@ def test_parse_file_list():
def test_parse_data():
test_data = "##block1\n```python\nprint('Hello, world!')\n```\n##block2\nfiles=['file1', 'file2', 'file3']"
- expected_result = {'block1': "print('Hello, world!')", 'block2': ['file1', 'file2', 'file3']}
+ expected_result = {"block1": "print('Hello, world!')", "block2": ["file1", "file2", "file3"]}
assert OutputParser.parse_data(test_data) == expected_result
@@ -103,9 +103,11 @@ def test_parse_data():
None,
Exception,
),
- ]
+ ],
)
-def test_extract_struct(text: str, data_type: Union[type(list), type(dict)], parsed_data: Union[list, dict], expected_exception):
+def test_extract_struct(
+ text: str, data_type: Union[type(list), type(dict)], parsed_data: Union[list, dict], expected_exception
+):
def case():
resp = OutputParser.extract_struct(text, data_type)
assert resp == parsed_data
@@ -117,7 +119,7 @@ def test_extract_struct(text: str, data_type: Union[type(list), type(dict)], par
case()
-if __name__ == '__main__':
+if __name__ == "__main__":
t_text = '''
## Required Python third-party packages
```python
@@ -216,9 +218,9 @@ We need clarification on how the high score should be stored. Should it persist
"Requirement Pool": (List[Tuple[str, str]], ...),
"Anything UNCLEAR": (str, ...),
}
- t_text1 = '''## Original Requirements:
+ t_text1 = """## Original Requirements:
-The boss wants to create a web-based version of the game "Fly Bird".
+The user wants to create a web-based version of the game "Fly Bird".
## Product Goals:
@@ -284,7 +286,7 @@ The product should be a web-based version of the game "Fly Bird" that is engagin
## Anything UNCLEAR:
There are no unclear points.
- '''
+ """
d = OutputParser.parse_data_with_mapping(t_text1, OUTPUT_MAPPING)
import json
diff --git a/tests/metagpt/utils/test_parse_html.py b/tests/metagpt/utils/test_parse_html.py
index 42be416a6..dd15bd80b 100644
--- a/tests/metagpt/utils/test_parse_html.py
+++ b/tests/metagpt/utils/test_parse_html.py
@@ -52,9 +52,11 @@ PAGE = """