diff --git a/README.md b/README.md
index 38d1c39b..c366a3d9 100644
--- a/README.md
+++ b/README.md
@@ -3,7 +3,7 @@
-[](https://pypi.org/project/trustgraph/)  
+[](https://pypi.org/project/trustgraph/) [](LICENSE) 
[](https://discord.gg/sQMwkRz5GX) [](https://deepwiki.com/trustgraph-ai/trustgraph)
@@ -11,89 +11,44 @@
-# Write context once. Run agents anywhere.
+# The agent runtime platform
-Stop rebuilding context from scratch. TrustGraph treats context as a holon — a modular, independent whole that naturally snaps into a larger domain-wide intelligence layer. By deploying context as holonic context graphs, TrustGraph powers multi-tenant agent workflows, dramatically reduces token consumption, and aligns with semantic web standards (RDF, OWL, SKOS, SHACL). Version your context, share it across teams, and scale with full provenance.
+TrustGraph is an agent runtime platform built around context graphs — structured, queryable representations of your domain knowledge that ground every agent query in verified, explainable facts in private deployments with sovereign control. The platform is the full stack for agentic systems: context graphs, memory, retrieval, orchestration, and inference for precision-critical agent workloads.
-## What TrustGraph Does
-
-TrustGraph is a complete holonic context harness for all LLMs. It provides the full infrastructure layer underneath your agents: knowledge ingestion, structured storage, graph-grounded retrieval, agent orchestration, and a full LLM inferencing stack.
-
-TrustGraph relies on absolutely no 3rd party services aside from optional API integrations to cloud-hosted LLMs. Whether you are using Anthropic's or OpenAI's API, or self-hosting Qwen3.7 via vLLM, TrustGraph handles it all with pre-built API connectors and a full LLM inferencing stack to enrich the models with a sovereign, private holonic system that grounds your agents in reality.
-
-## The Problem: Why Agents Break
-
-When you build an AI agent today, you spend most of your time fighting context:
-
-- **RAG retrieves fragments, not meaning**. Chunks of text have no structure. Relationships between facts are invisible. Your agent guesses at the connections.
-
-- **Context is disposable**. What the agent learned in one session is gone in the next. There is no persistent, structured knowledge layer underneath.
-
-- **Answers aren't traceable**. You can't explain why the agent said what it said, which means you can't trust it in production.
-
-- **Knowledge can't be reused**. You rebuild the same context pipelines for every new project, every new agent, every new environment.
-
-These aren't retrieval problems. They are structural problems. Context needs to be organized, versioned, and composable — exactly the way software infrastructure is.
-
-## The Solution: A Holonic Context System
-The philosopher Arthur Koestler coined the word [holon](https://en.wikipedia.org/wiki/Holon_(philosophy)) to describe something that is simultaneously a whole in itself and a part of something larger. A fact is whole. It is also part of a domain. A domain is whole. It is also part of an organization's knowledge.
-
-AI agents break down because this holonic structure is never built. Context gets shoved into flat text windows, scattered across vector stores, or hardwired into one-off prompts. Facts lose their relationships.
-
-TrustGraph solves this by organizing your domain into holonic context graphs. Entities, relationships, and evidence are treated as first-class objects. Every agent query is grounded against these holons—marrying symbolic graph structures with vector embeddings. Every answer carries provenance. Every fact is traceable.
-
-## Context Cores: Knowledge as a First-Class Citizen
-
-A Context Core is the deployable unit of knowledge in TrustGraph. It packages everything an agent needs to reason reliably over a domain into a single, portable artifact.
-
-### What's inside a Context Core
-- **Ontology** — your domain schema and entity mappings
-- **Holon** — entities, relationships, and supporting evidence
-- **Embeddings** — vector indexes for fast semantic entry-point lookup
-- **Provenance** — where every fact came from, when, and how it was derived
-- **Retrieval policies** — traversal rules, freshness controls, authority ranking
-
-Context Cores decouple what agents know from how agents are deployed. Build once. Run in Docker locally, Kubernetes in production, or on any cloud. Pin a version. Roll back. Promote across environments. This is context engineering — and it works because knowledge is finally treated like the infrastructure it is.
-
-## Explainability: Trust Your Agents in Production
-LLMs are black boxes, and traditional RAG makes it worse. When an agent pulls flat text chunks from a vector store, you have no idea how it connected those fragments to form an answer. You cannot ship agents to production if you can't explain why they said what they said.
-
-### How TrustGraph makes agents explainable:
-
-- **Traceable Reasoning Paths**: Instead of guessing at connections between text chunks, TrustGraph traverses explicit relationship paths in the holonic context graph. You can inspect exactly which entities, relationships, and sub-graphs were pulled into the LLM's context window to generate a given response.
-- **Fact-Level Provenance**: Every node and edge in the graph carries strict provenance. When an agent makes a claim, you can trace it back to the exact source document, the time it was ingested, and the extraction method used to derive it.
-- **No Black-Box Guesses**: By grounding the LLM in a structured, symbolic graph, you eliminate the hallucinations that occur when models are forced to infer relationships from unstructured text. If a fact isn't in the graph, the agent doesn't use it.
-
-TrustGraph doesn't just give you answers - it gives you the receipt. Every fact is traceable, every connection is visible, and every output is verifiable.
-
-## Workspaces, Collections, and Flows
-
-TrustGraph has a [three-level system](https://docs.trustgraph.ai/overview/workspaces) for organizing and isolating knowledge.
-
-A `Workspace` is the outermost boundary — a fully isolated tenancy scope where all data, users, configuration, and pipelines live independently from every other workspace. Isolation is structural: enforced at the pub/sub queue, storage, and API gateway layers, not by trusting a field in a message body.
-
-Within a workspace, a `Collection` groups related holons, graph structures, embeddings, and documents together — think of it as a dedicated shelf in a library, scoped to a specific domain, project, or customer.
-
-A `Flow` is a running data processing pipeline that defines how raw data moves through ingestion, extraction, structuring, and storage — the assembly line that turns documents into queryable knowledge. Together, the three layers let you run multiple isolated tenants on a single deployment, separate knowledge by domain within each tenant, and process that knowledge through fully configurable pipelines — all without restarting the system or rebuilding your infrastructure.
-
-## The Full Stack
-TrustGraph is not a wrapper around a graph database. It is the complete backend for production agentic systems.
-
-- **Holonic context graph engine**: automated entity and relationship extraction, ontology-driven graph construction, graph-grounded retrieval for explainable outputs
-- **Multi-model database**: tabular/relational, key-value, document, graph, vectors, images, video, and audio — all managed in Cassandra and S3-compatible Garage
-- **Out-of-the-box RAG pipelines**: DocumentRAG, GraphRAG, and OntologyRAG ready to deploy
-- **Fully agentic orchestration**: single or multi-agent, ReAct, Plan-then-Execute, Supervisor patterns, and MCP integration
-- **3D Knowledge Explorer**: interactive graph visualization with BFS neighborhood extraction and edge pulse animation
-- **Automated data ingest**: quick ingest with semantic similarity or ontology-structured precision retrieval
-- **Run anywhere**: Docker/Podman locally, Kubernetes in the cloud
-
-All major LLMs — Anthropic, Cohere, Gemini, Mistral, OpenAI, and more via API.
-
-vLLM, Ollama, TGI, LM Studio, and Llamafiles for fully local inferencing.
-
-Verified cloud deployments for Alibaba Cloud, AWS, Azure, GCP, OVHcloud, and Scaleway.
+The platform:
+- [x] Multi-model and multimodal database system
+ - [x] Tabular/relational, key-value
+ - [x] Document, graph, and vectors
+ - [x] Images, video, and audio
+- [x] Context Graph engine
+ - [x] Automated entity and relationship extraction
+ - [x] Ontology-driven graph construction
+ - [x] Graph-grounded retrieval for explainable outputs
+- [x] Automated data ingest and loading
+ - [x] Quick ingest with semantic similarity retrieval
+ - [x] Ontology structuring for precision retrieval
+- [x] Out-of-the-box RAG pipelines
+ - [x] DocumentRAG
+ - [x] GraphRAG
+ - [x] OntologyRAG
+- [x] 3D GraphViz for exploring context
+- [x] Fully Agentic System
+ - [x] Single or Multi Agent
+ - [x] ReAct, Plan-then-Execute, and Supervisor patterns
+ - [x] MCP integration
+- [x] Run anywhere
+ - [x] Deploy locally with Docker
+ - [x] Deploy in cloud with Kubernetes
+- [x] Support for all major LLMs
+ - [x] API support for Anthropic, Cohere, Gemini, Mistral, OpenAI, and others
+ - [x] Model inferencing with vLLM, Ollama, TGI, LM Studio, and Llamafiles
+- [x] Developer friendly
+ - [x] REST API [Docs](https://docs.trustgraph.ai/reference/apis/rest.html)
+ - [x] Websocket API [Docs](https://docs.trustgraph.ai/reference/apis/websocket.html)
+ - [x] Python API [Docs](https://docs.trustgraph.ai/reference/apis/python)
+ - [x] CLI [Docs](https://docs.trustgraph.ai/reference/cli/)
## No API Keys Required
@@ -107,12 +62,12 @@ Everything else is included.
- [x] Managed Multi-model storage in [Cassandra](https://cassandra.apache.org/_/index.html)
- [x] Managed Vector embedding storage in [Qdrant](https://github.com/qdrant/qdrant)
- [x] Managed File and Object storage in [Garage](https://github.com/deuxfleurs-org/garage) (S3 compatible)
-- [x] Managed High-speed Pub/Sub messaging fabric with [Pulsar](https://github.com/apache/pulsar) or [RabbitMQ](https://www.rabbitmq.com/)
+- [x] Managed High-speed Pub/Sub messaging fabric with [Pulsar](https://github.com/apache/pulsar)
- [x] Complete LLM inferencing stack for open LLMs with [vLLM](https://github.com/vllm-project/vllm), [TGI](https://github.com/huggingface/text-generation-inference), [Ollama](https://github.com/ollama/ollama), [LM Studio](https://github.com/lmstudio-ai), and [Llamafiles](https://github.com/mozilla-ai/llamafile)
## Quickstart
-No need to clone the repo unless you are building from source. TrustGraph deploys as a set of Docker containers. Configure it on the command line in one step:
+There's no need to clone this repo, unless you want to build from source. TrustGraph is a fully containerized app that deploys as a set of Docker containers. To configure TrustGraph on the command line:
```
npx @trustgraph/config
@@ -123,39 +78,44 @@ The config process will generate an app config that can be run locally with Dock
- Deployment instructions as `INSTALLATION.md`
-
For a browser based configuration, try the [Configuration Terminal](https://config-ui.demo.trustgraph.ai/).
-## Watch What is a Holonic Context Graph?
+## Watch What is a Context Graph?
[](https://www.youtube.com/watch?v=gZjlt5WcWB4)
-## Watch Holonic Context Graphs in Action
+## Watch Context Graphs in Action
[](https://www.youtube.com/watch?v=sWc7mkhITIo)
## Getting Started with TrustGraph
- [**Getting Started Guides**](https://docs.trustgraph.ai/getting-started)
+- [**Using the Workbench**](#workbench)
- [**Developer APIs and CLI**](https://docs.trustgraph.ai/reference)
- [**Deployment Guides**](https://docs.trustgraph.ai/deployment)
-## TrustGraph UI
+## Workbench
-
+The **Workbench** provides tools for all major features of TrustGraph. The **Workbench** is on port `8888` by default.
-The UI provides tools for all major features of TrustGraph. The UI deploys on port `8888` by default.
-
-- **Agent Console** — Query your agents directly with streaming responses and live explainability event tracking, so you can watch reasoning unfold in real time
-- **GraphRAG View** — Interactive graph RAG queries with a visual explainability DAG and inline provenance display, making it easy to see exactly where answers came from
-- **Context Explorer** — An interactive 3D context graph explorer with dynamic graph loading, BFS neighborhood extraction, edge pulse animation, and multiple navigation views
-- **Document Ingestion** — A complete upload and submission workflow with page and chunk inspection and document structure browsing
-- **Ontology Workbench** — A full ontology editor with class and property trees, OWL/XML and Turtle import/export with round-trip fidelity, circular dependency detection, and safe-delete confirmation dialogs
-- **Schema Workbench** — Interactive schema management with list, create, edit, and delete operations including field and index management
-- **Prompt Editor** — A dedicated prompt editing workflow
+- **Vector Search**: Search the installed knowledge bases
+- **Agentic, GraphRAG and LLM Chat**: Chat interface for agents, GraphRAG queries, or direct to LLMs
+- **Relationships**: Analyze deep relationships in the installed knowledge bases
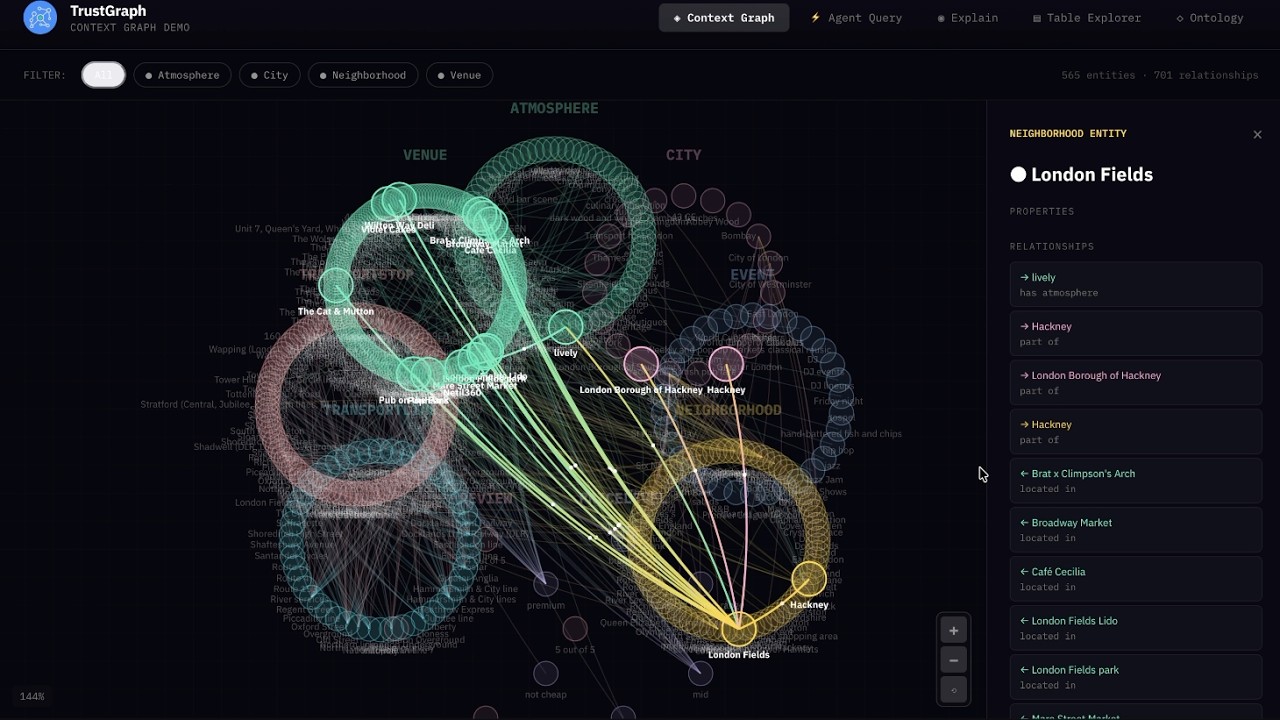
+- **Graph Visualizer**: 3D GraphViz of the installed knowledge bases
+- **Library**: Staging area for installing knowledge bases
+- **Flow Classes**: Workflow preset configurations
+- **Flows**: Create custom workflows and adjust LLM parameters during runtime
+- **Knowledge Cores**: Manage resuable knowledge bases
+- **Prompts**: Manage and adjust prompts during runtime
+- **Schemas**: Define custom schemas for structured data knowledge bases
+- **Ontologies**: Define custom ontologies for unstructured data knowledge bases
+- **Agent Tools**: Define tools with collections, knowledge cores, MCP connections, and tool groups
+- **MCP Tools**: Connect to MCP servers
## TypeScript Library for UIs
@@ -165,6 +125,134 @@ There are 3 libraries for quick UI integration of TrustGraph services.
- [@trustgraph/react-state](https://www.npmjs.com/package/@trustgraph/react-state)
- [@trustgraph/react-provider](https://www.npmjs.com/package/@trustgraph/react-provider)
+## Context Cores
+
+Context Cores are how TrustGraph treats context like code. A Context Core is a **portable, versioned bundle of context** that you can ship between projects and environments, pin in production, and reuse across agents. It packages the “stuff agents need to know” (structured knowledge + embeddings + evidence + policies) into a single artifact, so you can treat context like code: build it, test it, version it, promote it, and roll it back. TrustGraph is built to support this kind of end-to-end context engineering and orchestration workflow.
+
+### What’s inside a Context Core
+A Context Core typically includes:
+- Ontology (your domain schema) and mappings
+- Context Graph (entities, relationships, supporting evidence)
+- Embeddings / vector indexes for fast semantic entry-point lookup
+- Source manifests + provenance (where facts came from, when, and how they were derived)
+- Retrieval policies (traversal rules, freshness, authority ranking)
+
+## Tech Stack
+TrustGraph provides component flexibility to optimize agent workflows.
+
+
+LLM APIs
+
+
+- Anthropic
+- AWS Bedrock
+- AzureAI
+- AzureOpenAI
+- Cohere
+- Google AI Studio
+- Google VertexAI
+- Mistral
+- OpenAI
+
+
+
+LLM Orchestration
+
+
+- LM Studio
+- Llamafiles
+- Ollama
+- TGI
+- vLLM
+
+
+
+Multi-model storage
+
+
+- Apache Cassandra
+
+
+
+VectorDB
+
+
+- Qdrant
+
+
+
+File and Object Storage
+
+
+- Garage
+
+
+
+Observability
+
+
+- Prometheus
+- Grafana
+- Loki
+
+
+
+Data Streaming
+
+
+- Apache Pulsar
+- RabbitMQ
+- Apache Kafka
+
+
+
+Clouds
+
+
+- AWS
+- Azure
+- Google Cloud
+- OVHcloud
+- Scaleway
+
+
+
+## Observability & Telemetry
+
+Once the platform is running, access the Grafana dashboard at:
+
+```
+http://localhost:3000
+```
+
+Default credentials are:
+
+```
+user: admin
+password: admin
+```
+
+The default Grafana dashboard tracks the following:
+
+
+Telemetry
+
+
+- LLM Latency
+- Error Rate
+- Service Request Rates
+- Queue Backlogs
+- Chunking Histogram
+- Error Source by Service
+- Rate Limit Events
+- CPU usage by Service
+- Memory usage by Service
+- Models Deployed
+- Token Throughput (Tokens/second)
+- Cost Throughput (Cost/second)
+
+
+
## Contributing
[Developer's Guide](https://docs.trustgraph.ai/guides/building/introduction.html)
@@ -173,7 +261,7 @@ There are 3 libraries for quick UI integration of TrustGraph services.
**TrustGraph** is licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0).
- Copyright 2024-2026 TrustGraph
+ Copyright 2024-2025 TrustGraph
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
diff --git a/containers/Containerfile.hf b/containers/Containerfile.hf
index 9cc6c2c8..93768b54 100644
--- a/containers/Containerfile.hf
+++ b/containers/Containerfile.hf
@@ -23,7 +23,7 @@ RUN pip3 install --no-cache-dir \
langchain==1.2.16 langchain-core==1.3.2 langchain-huggingface==1.2.2 \
langchain-community==0.4.1 \
sentence-transformers==5.4.1 transformers==5.7.0 \
- huggingface-hub==1.13.0 click \
+ huggingface-hub==1.13.0 \
pulsar-client==3.11.0
# Most commonly used embeddings model, just build it into the container
diff --git a/containers/Containerfile.unstructured b/containers/Containerfile.unstructured
index 2b9a18f7..6de8a800 100644
--- a/containers/Containerfile.unstructured
+++ b/containers/Containerfile.unstructured
@@ -7,7 +7,7 @@ FROM docker.io/fedora:42 AS base
ENV PIP_BREAK_SYSTEM_PACKAGES=1
-RUN dnf install -y python3.13 libxcb mesa-libGL poppler-utils && \
+RUN dnf install -y python3.13 libxcb mesa-libGL && \
alternatives --install /usr/bin/python python /usr/bin/python3.13 1 && \
python -m ensurepip --upgrade && \
pip3 install --no-cache-dir --upgrade 'pip>=26.0' 'setuptools>=78.1.1' && \
diff --git a/dev-tools/library_client.py b/dev-tools/library_client.py
index 30e0c344..ae9d6857 100644
--- a/dev-tools/library_client.py
+++ b/dev-tools/library_client.py
@@ -25,7 +25,7 @@ BUCKET_URL = "https://storage.googleapis.com/trustgraph-library"
INDEX_URL = f"{BUCKET_URL}/index.json"
default_url = os.getenv("TRUSTGRAPH_URL", "http://localhost:8088/")
-default_workspace = os.getenv("TRUSTGRAPH_WORKSPACE", "default")
+default_user = "trustgraph"
default_token = os.getenv("TRUSTGRAPH_TOKEN", None)
@@ -113,7 +113,7 @@ def convert_metadata(metadata_json):
return triples
-def load_document(api, doc_entry):
+def load_document(api, user, doc_entry):
"""Fetch metadata and content for a document, then load into TrustGraph."""
doc_id = doc_entry["id"]
title = doc_entry["title"]
@@ -133,6 +133,7 @@ def load_document(api, doc_entry):
api.add_document(
id=doc["id"],
metadata=metadata,
+ user=user,
kind=doc["kind"],
title=doc["title"],
comments=doc["comments"],
@@ -143,12 +144,12 @@ def load_document(api, doc_entry):
print(f" done.")
-def load_documents(api, docs):
+def load_documents(api, user, docs):
"""Load a list of documents."""
print(f"Loading {len(docs)} document(s)...\n")
for doc in docs:
try:
- load_document(api, doc)
+ load_document(api, user, doc)
except Exception as e:
print(f" FAILED: {e}", file=sys.stderr)
print()
@@ -165,8 +166,8 @@ def main():
help=f"TrustGraph API URL (default: {default_url})",
)
parser.add_argument(
- "-w", "--workspace", default=default_workspace,
- help=f"Workspace (default: {default_workspace})",
+ "-U", "--user", default=default_user,
+ help=f"User ID (default: {default_user})",
)
parser.add_argument(
"-t", "--token", default=default_token,
@@ -211,22 +212,22 @@ def main():
return
# Load commands need the API
- api = Api(args.url, token=args.token, workspace=args.workspace).library()
+ api = Api(args.url, token=args.token).library()
if args.command == "load-all":
- load_documents(api, index)
+ load_documents(api, args.user, index)
elif args.command == "load-doc":
matches = [d for d in index if str(d.get("id")) == args.id]
if not matches:
print(f"No document with ID '{args.id}' found.", file=sys.stderr)
sys.exit(1)
- load_documents(api, matches)
+ load_documents(api, args.user, matches)
elif args.command == "load-match":
results = search_index(index, args.query)
if results:
- load_documents(api, results)
+ load_documents(api, args.user, results)
else:
print("No matches found.", file=sys.stderr)
sys.exit(1)
diff --git a/docs/api.html b/docs/api.html
index a98b3675..2a03a38b 100644
--- a/docs/api.html
+++ b/docs/api.html
@@ -12,417 +12,417 @@
margin: 0;
}
-
-