mirror of
https://github.com/katanemo/plano.git
synced 2026-06-17 15:25:17 +02:00
| .. | ||
| config.yaml | ||
| docker-compose.yaml | ||
| jaeger_tracing_llm_routing.png | ||
| llm_routing_demo.png | ||
| README.md | ||
| run_demo.sh | ||
{kind=link}
{kind=link}
LLM Routing
This demo shows how you can use Plano gateway to manage keys and route to upstream LLM.
Starting the demo
- Please make sure the pre-requisites are installed correctly
- Start Plano
sh run_demo.sh - Navigate to http://localhost:3001/
Following screen shows an example of interaction with Plano gateway showing dynamic routing. You can select between different LLMs using "override model" option in the chat UI.
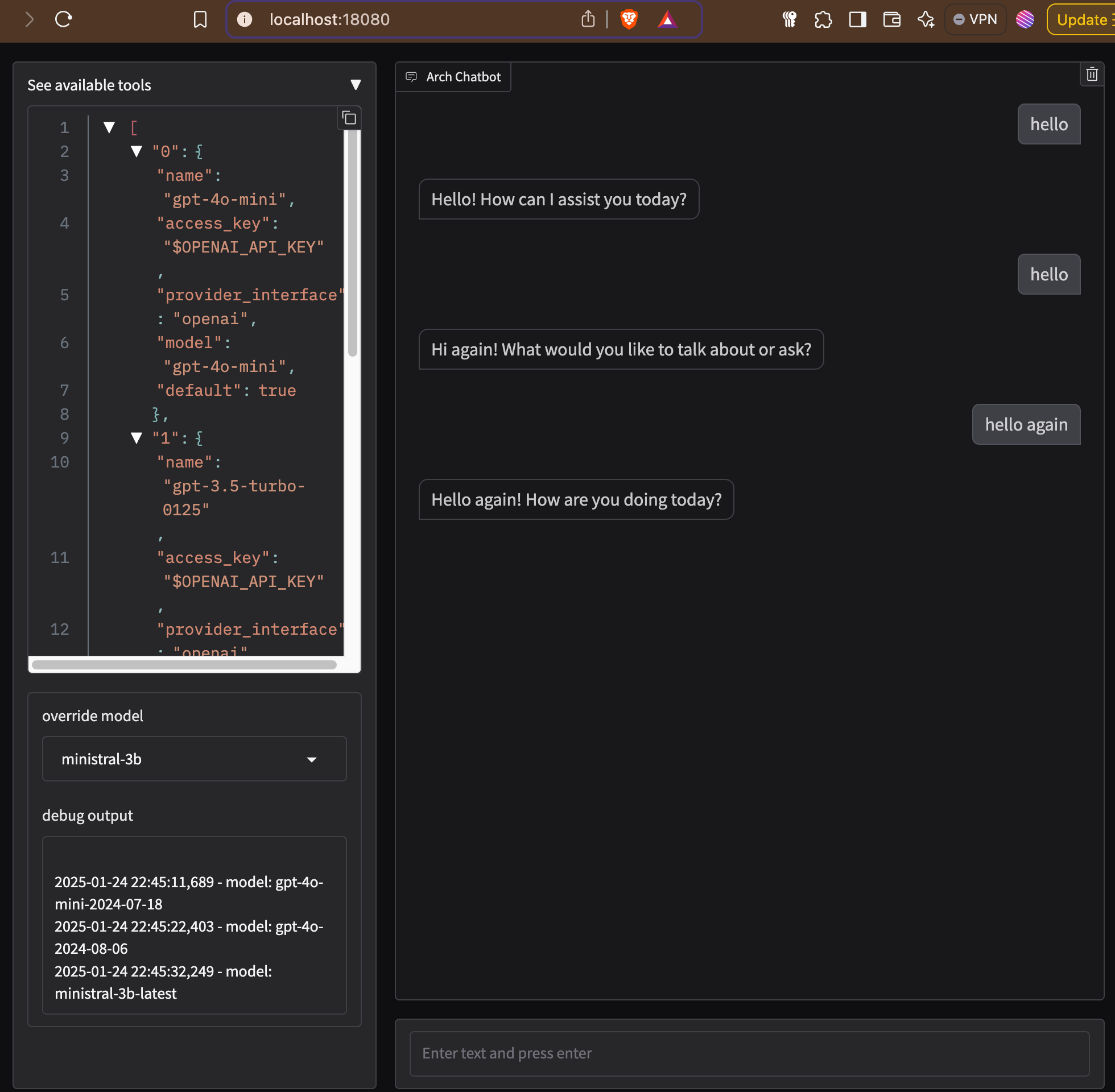
You can also pass in a header to override model when sending prompt. Following example shows how you can use x-arch-llm-provider-hint header to override model selection,
$ curl --header 'Content-Type: application/json' \
--header 'x-arch-llm-provider-hint: mistral/ministral-3b' \
--data '{"messages": [{"role": "user","content": "hello"}], "model": "gpt-4o"}' \
http://localhost:12000/v1/chat/completions 2> /dev/null | jq .
{
"id": "xxx",
"object": "chat.completion",
"created": 1737760394,
"model": "ministral-3b-latest",
"choices": [
{
"index": 0,
"messages": {
"role": "assistant",
"tool_calls": null,
"content": "Hello! How can I assist you today? Let's chat about anything you'd like."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 4,
"total_tokens": 25,
"completion_tokens": 21
}
}
Observability
For tracing you can head over to http://localhost:16686/ to view recent traces.
Following is a screenshot of tracing UI showing call received by Plano gateway and making upstream call to LLM,
