Agentic Workflow
Arch helps you easily personalize your applications by calling application-specific (API) functions via user prompts. This involves any predefined functions or APIs you want to expose to users to perform tasks, gather information, or manipulate data. This capability is generally referred to as function calling, where you have the flexibility to support “agentic” apps tailored to specific use cases - from updating insurance claims to creating ad campaigns - via prompts.
Arch analyzes prompts, extracts critical information from prompts, engages in lightweight conversation with the user to gather any missing parameters and makes API calls so that you can focus on writing business logic. Arch does this via its purpose-built Arch-Function - the fastest (200ms p90 - 10x faser than GPT-4o) and cheapest (100x than GPT-40) function-calling LLM that matches performance with frontier models.
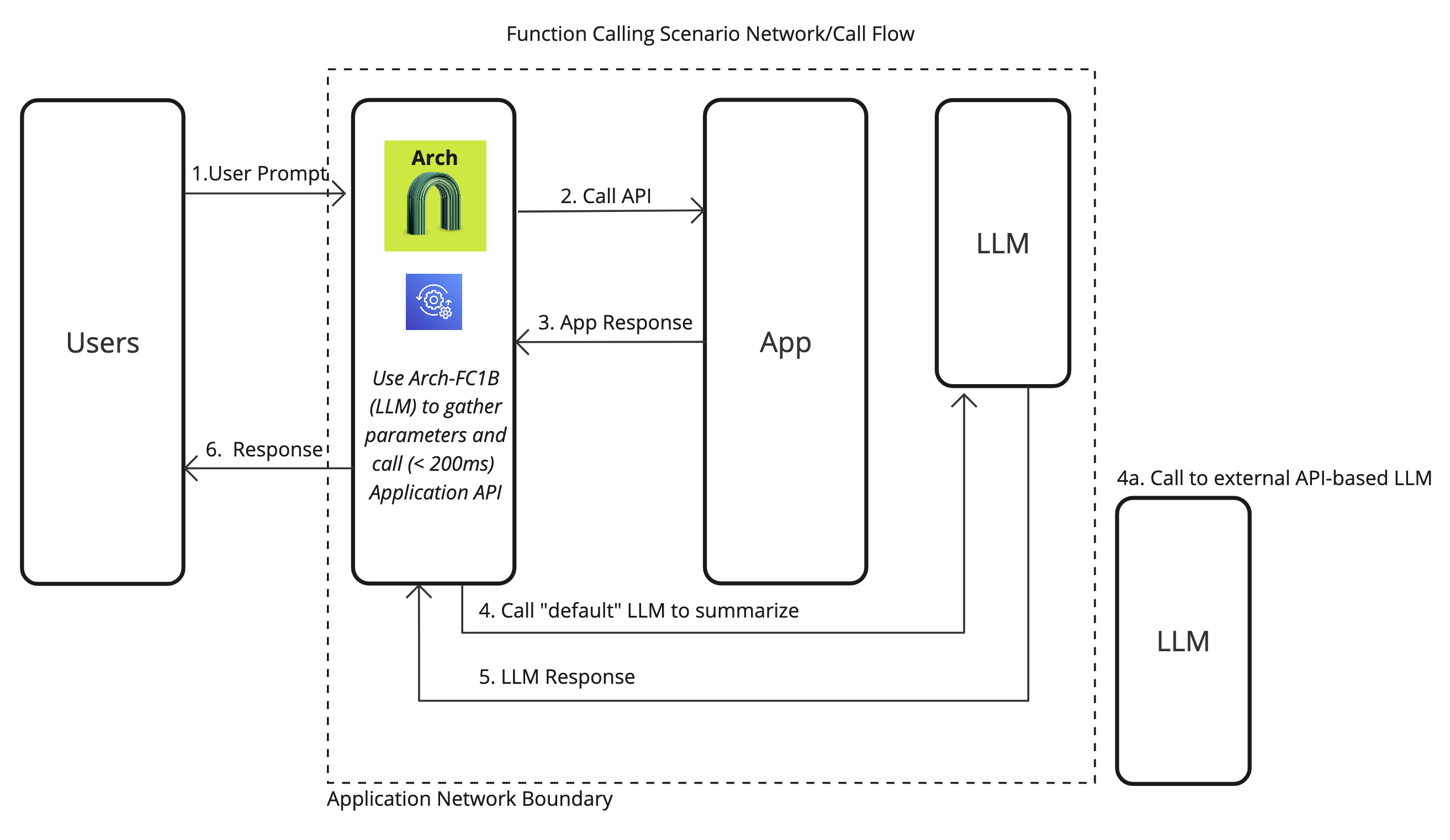
Single Function Call
In the most common scenario, users will request a single action via prompts, and Arch efficiently processes the request by extracting relevant parameters, validating the input, and calling the designated function or API. Here is how you would go about enabling this scenario with Arch:
Step 1: Define Prompt Targets
1version: v0.1
2
3listen:
4 address: 0.0.0.0 # or 127.0.0.1
5 port: 10000
6 # Defines how Arch should parse the content from application/json or text/pain Content-type in the http request
7 message_format: huggingface
8
9# Centralized way to manage LLMs, manage keys, retry logic, failover and limits in a central way
10llm_providers:
11 - name: OpenAI
12 provider: openai
13 access_key: OPENAI_API_KEY
14 model: gpt-4o
15 default: true
16 stream: true
17
18# default system prompt used by all prompt targets
19system_prompt: You are a network assistant that just offers facts; not advice on manufacturers or purchasing decisions.
20
21prompt_targets:
22 - name: reboot_devices
23 description: Reboot specific devices or device groups
24
25 path: /agent/device_reboot
26 parameters:
27 - name: device_ids
28 type: list
29 description: A list of device identifiers (IDs) to reboot.
30 required: false
31 - name: device_group
32 type: str
33 description: The name of the device group to reboot
34 required: false
35
36# Arch creates a round-robin load balancing between different endpoints, managed via the cluster subsystem.
37endpoints:
38 app_server:
39 # value could be ip address or a hostname with port
40 # this could also be a list of endpoints for load balancing
41 # for example endpoint: [ ip1:port, ip2:port ]
42 endpoint: 127.0.0.1:80
43 # max time to wait for a connection to be established
44 connect_timeout: 0.005s
Step 2: Process Request Parameters
Once the prompt targets are configured as above, handling those parameters is
1from flask import Flask, request, jsonify
2
3app = Flask(__name__)
4
5
6@app.route("/agent/device_summary", methods=["POST"])
7def get_device_summary():
8 """
9 Endpoint to retrieve device statistics based on device IDs and an optional time range.
10 """
11 data = request.get_json()
12
13 # Validate 'device_ids' parameter
14 device_ids = data.get("device_ids")
15 if not device_ids or not isinstance(device_ids, list):
16 return jsonify(
17 {"error": "'device_ids' parameter is required and must be a list"}
18 ), 400
19
20 # Validate 'time_range' parameter (optional, defaults to 7)
21 time_range = data.get("time_range", 7)
22 if not isinstance(time_range, int):
23 return jsonify({"error": "'time_range' must be an integer"}), 400
24
25 # Simulate retrieving statistics for the given device IDs and time range
26 # In a real application, you would query your database or external service here
27 statistics = []
28 for device_id in device_ids:
29 # Placeholder for actual data retrieval
30 stats = {
31 "device_id": device_id,
32 "time_range": f"Last {time_range} days",
33 "data": f"Statistics data for device {device_id} over the last {time_range} days.",
34 }
35 statistics.append(stats)
36
37 response = {"statistics": statistics}
38
39 return jsonify(response), 200
40
41
42if __name__ == "__main__":
43 app.run(debug=True)
Parallel & Multiple Function Calling
In more complex use cases, users may request multiple actions or need multiple APIs/functions to be called simultaneously or sequentially. With Arch, you can handle these scenarios efficiently using parallel or multiple function calling. This allows your application to engage in a broader range of interactions, such as updating different datasets, triggering events across systems, or collecting results from multiple services in one prompt.
Arch-FC1B is built to manage these parallel tasks efficiently, ensuring low latency and high throughput, even when multiple functions are invoked. It provides two mechanisms to handle these cases:
Step 1: Define Prompt Targets
When enabling multiple function calling, define the prompt targets in a way that supports multiple functions or API calls based on the user’s prompt. These targets can be triggered in parallel or sequentially, depending on the user’s intent.
Example of Multiple Prompt Targets in YAML:
1version: v0.1
2
3listen:
4 address: 0.0.0.0 # or 127.0.0.1
5 port: 10000
6 # Defines how Arch should parse the content from application/json or text/pain Content-type in the http request
7 message_format: huggingface
8
9# Centralized way to manage LLMs, manage keys, retry logic, failover and limits in a central way
10llm_providers:
11 - name: OpenAI
12 provider: openai
13 access_key: OPENAI_API_KEY
14 model: gpt-4o
15 default: true
16 stream: true
17
18# default system prompt used by all prompt targets
19system_prompt: You are a network assistant that just offers facts; not advice on manufacturers or purchasing decisions.
20
21prompt_targets:
22 - name: reboot_devices
23 description: Reboot specific devices or device groups
24
25 path: /agent/device_reboot
26 parameters:
27 - name: device_ids
28 type: list
29 description: A list of device identifiers (IDs) to reboot.
30 required: false
31 - name: device_group
32 type: str
33 description: The name of the device group to reboot
34 required: false
35
36# Arch creates a round-robin load balancing between different endpoints, managed via the cluster subsystem.
37endpoints:
38 app_server:
39 # value could be ip address or a hostname with port
40 # this could also be a list of endpoints for load balancing
41 # for example endpoint: [ ip1:port, ip2:port ]
42 endpoint: 127.0.0.1:80
43 # max time to wait for a connection to be established
44 connect_timeout: 0.005s