| .github | ||
| examples | ||
| images | ||
| src/dp_fusion_lib | ||
| tests | ||
| .gitignore | ||
| CHANGELOG.md | ||
| CITATION.cff | ||
| CONTRIBUTING.md | ||
| environment.yml | ||
| LICENSE | ||
| LICENSE-COMMERCIAL.md | ||
| pyproject.toml | ||
| README.md | ||
![]()

![]()
![]()
![]()
![]()
![]()
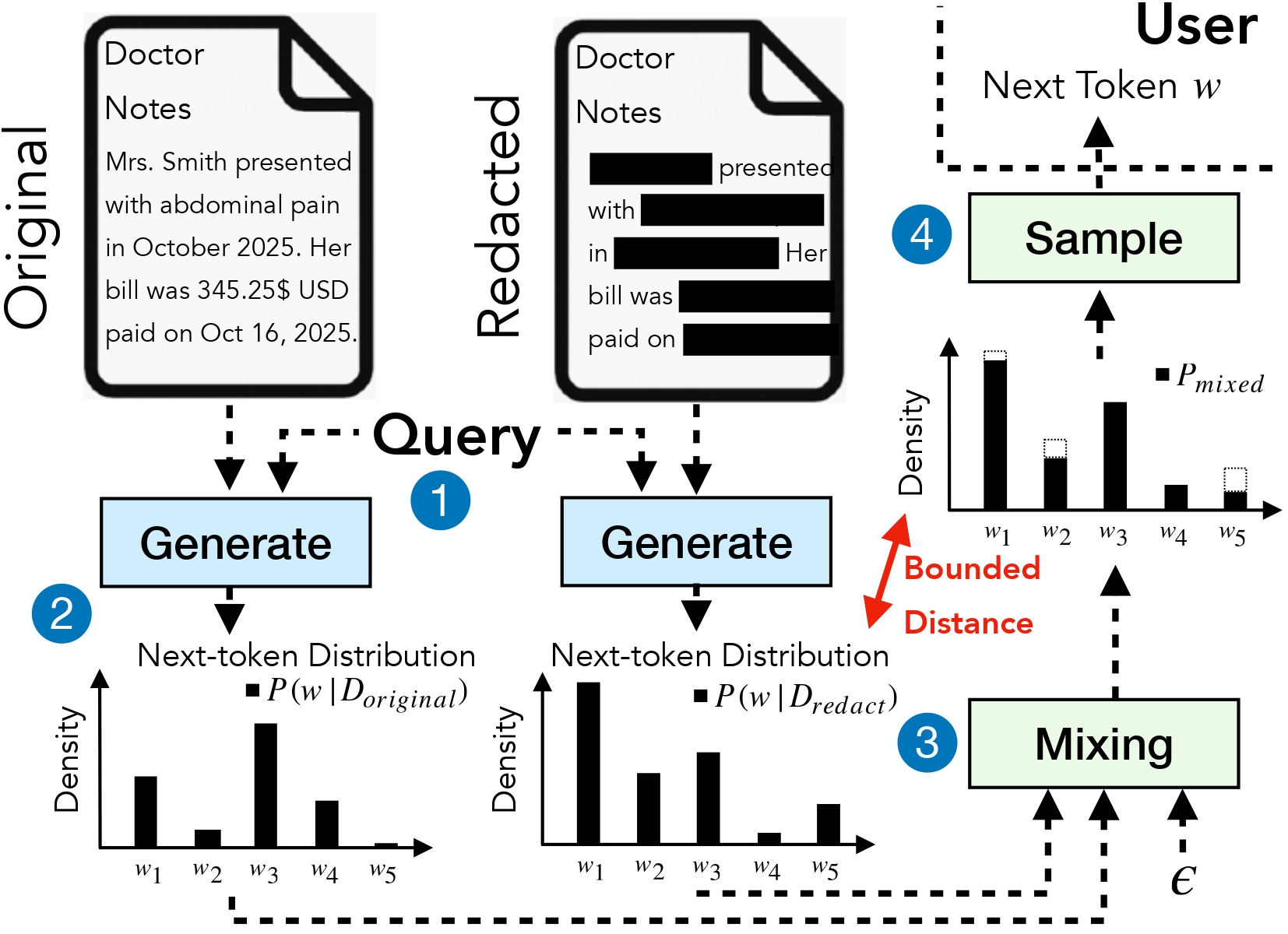
DP-Fusion-Lib enables Large Language Model inference with mathematically provable differential privacy guarantees. Based on our research paper "DP-Fusion: Token-Level Differentially Private Inference for Large Language Models", this library provides formal (ε, δ)-DP protection for sensitive text generation workflows.
Differential privacy is the core foundation, but the library addresses the full spectrum of text and document privacy. Its PII detection and rewriting tools can be used with or without DP, offering practical privacy protection by default, and formal guarantees when DP is enabled.
Run the example collab notebook
Overview
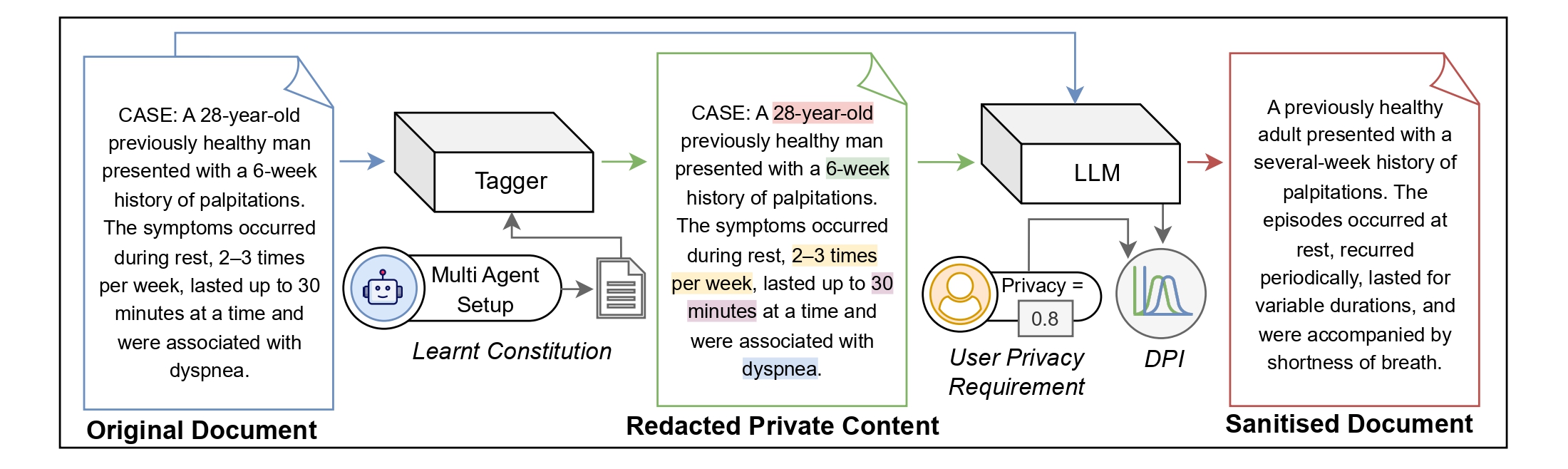
Traditional privacy approaches for LLMs rely on heuristic redaction or post-hoc filtering. DP-Fusion-Lib goes further by providing a complete privacy framework with three levels of protection:
| Level | Approach | Protection |
|---|---|---|
| 1 | Redaction | Automatic PII detection and replacement via Constitutional Tagger API |
| 2 | Paraphrasing | Context rewriting to obscure stylistic and contextual signatures |
| 3 | Differential Privacy | Formal (ε, δ)-DP guarantees via controlled distribution fusion |
The library achieves Level 3 protection by fusing token probability distributions from private and redacted contexts, bounding the Rényi divergence at each generation step to provide provable privacy guarantees.
Technical Approach
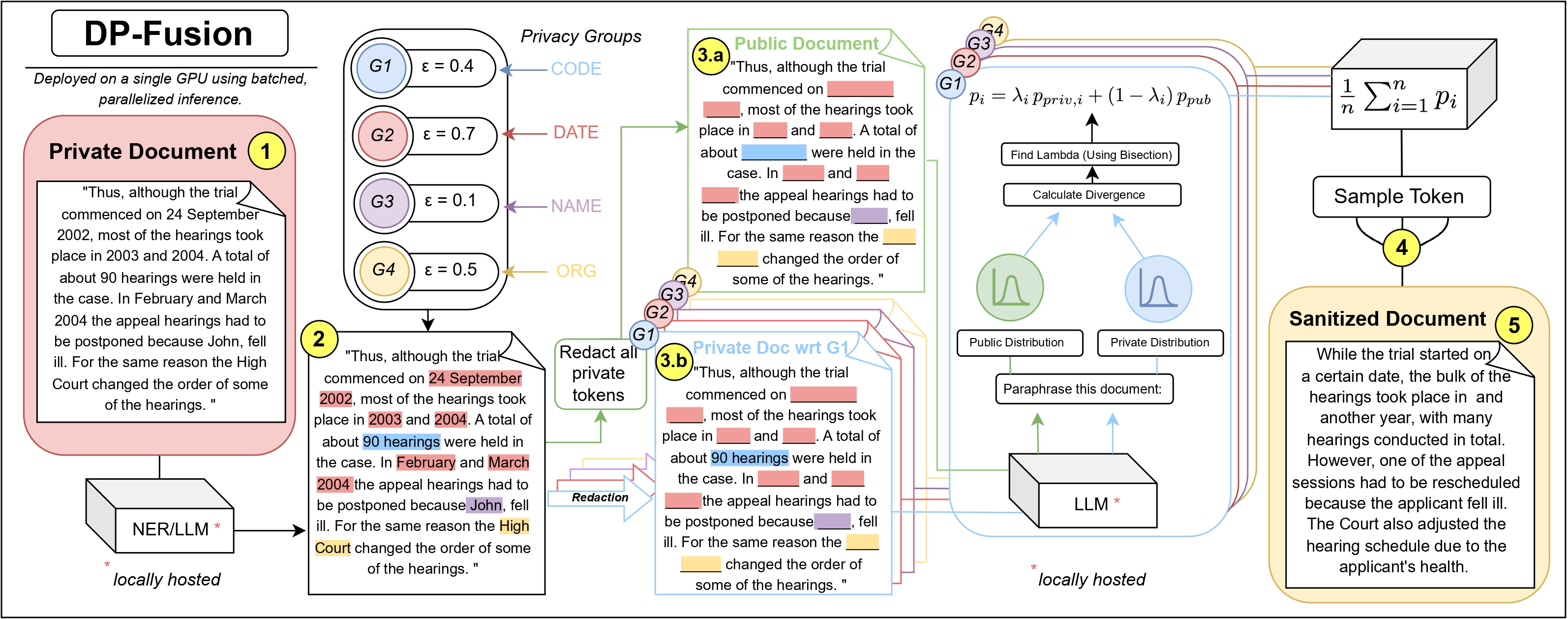
DP-Fusion operates by maintaining two parallel contexts during generation:
- Private Context: The original document containing sensitive information
- Public Context: A redacted version with sensitive phrases replaced by placeholders
At each token generation step, the algorithm:
- Computes next-token probability distributions for both contexts
- Performs binary search to find the optimal mixing parameter λ
- Ensures the fused distribution satisfies the Rényi divergence bound
- Samples from the privacy-preserving mixed distribution
This approach guarantees that the output distribution is statistically similar regardless of the specific private information present, providing formal differential privacy.
Installation
pip install dp-fusion-lib
Hardware Requirements: This library requires PyTorch. For production deployments, NVIDIA GPU acceleration is recommended. The Qwen/Qwen2.5-7B-Instruct model provides an effective balance between generation quality and privacy utility.
# For CUDA 12.1 environments
pip install torch --index-url https://download.pytorch.org/whl/cu121
pip install dp-fusion-lib
Quick Start
For a complete working example, see the basic usage script or run the interactive Jupyter notebook.
Step 1: Initialize Components
The Tagger API provides automated sensitive phrase detection using Constitutional AI. API keys are available at console.documentprivacy.com.
from dp_fusion_lib import DPFusion, Tagger, compute_epsilon_single_group
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load model
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B-Instruct",
torch_dtype=torch.float16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
# Initialize Tagger
tagger = Tagger(api_key="your_api_key")
tagger.set_model("gpt-oss-120b") # Strong extraction model
tagger.set_constitution("LEGAL") # Options: LEGAL, HEALTH, FINANCE
Step 2: Build Context
The library applies differential privacy only to segments marked as private, allowing precise control over which content receives protection.
dpf = DPFusion(model=model, tokenizer=tokenizer, max_tokens=100, tagger=tagger)
# Sample document with sensitive information
document = """The applicant was born in 1973 and currently resides in
Les Salles-sur-Verdon, France. In the early 1990s, a new criminal
phenomenon emerged in Denmark known as 'tax asset stripping cases'."""
# Build context with privacy annotations
dpf.add_message("system", "You are a helpful assistant that paraphrases text.", is_private=False)
dpf.add_message("user", document, is_private=True) # Mark sensitive content as private
dpf.add_message("system", "Now paraphrase this text for privacy", is_private=False)
dpf.add_message("assistant", "Sure, here is the paraphrase of the above text that ensures privacy:", is_private=False)
Step 3: Run Tagger to Build Private and Public Contexts
The tagger automatically identifies sensitive phrases and creates two parallel contexts:
# Run tagger to extract PII and build redacted context
dpf.run_tagger()
# Extracted phrases: ['1973', 'Les Salles-sur-Verdon', 'early 1990s', 'tax asset stripping cases']
# View the two contexts that DP-Fusion uses:
print(dpf.private_context) # Original text with real values
print(dpf.public_context) # Redacted text with ____ placeholders
Private context (what the model sees with full information):
The applicant was born in 1973 and currently resides in Les Salles-sur-Verdon, France.
In the early 1990s, a new criminal phenomenon emerged in Denmark...
Public context (redacted version):
The applicant was born in ____ and currently resides in _________.
In the _______, a new criminal phenomenon emerged in Denmark...
Step 4: Generate with Differential Privacy
# Generate with differential privacy
output = dpf.generate(
alpha=2.0, # Rényi order
beta=0.01, # Per-token privacy budget
max_new_tokens=100
)
print(output['text'])
Step 5: Compute Privacy Guarantee
The library provides two epsilon values for comprehensive privacy accounting:
alpha = 2.0
beta = 0.01
delta = 1e-5
eps_result = compute_epsilon_single_group(
divergences=output['divergences']['PRIVATE'],
alpha=alpha,
delta=delta,
beta=beta
)
print(f"(ε, δ)-DP Guarantee (α={alpha}, δ={delta}, T={eps_result['T']} tokens):")
print(f" Empirical ε = {eps_result['empirical']:.4f} (from actual divergences)")
print(f" Theoretical ε = {eps_result['theoretical']:.4f} (worst-case, β={beta} per step)")
| Epsilon Type | Description | Use Case |
|---|---|---|
| Empirical ε | Computed from actual per-step divergences observed during generation | Tighter bound reflecting real privacy cost |
| Theoretical ε | Worst-case bound assuming maximum divergence (α·β) at every step | Conservative upper bound for compliance reporting |
Privacy Parameters
| Parameter | Symbol | Description | Trade-off |
|---|---|---|---|
| Beta | β | Maximum Rényi divergence per token | Lower β → Stronger privacy, reduced utility |
| Alpha | α | Rényi divergence order (must be > 1) | Higher α → Tighter bounds, different privacy regime |
| Delta | δ | Probability of privacy failure | Lower δ → Stronger guarantee, higher ε |
| Epsilon | ε | Total privacy budget (computed) | Lower ε → Stronger privacy guarantee |
Recommendation: For most applications, start with alpha=2.0 and beta=0.01. Adjust based on your privacy-utility requirements.
Data Privacy
While dp-fusion-lib executes entirely on your infrastructure, the Tagger API requires an external call for sensitive phrase detection. For anyone with strict data residency or compliance requirements please contact me, I will help-out.
Contact rushil.thareja@mbzuai.ac.ae.
Citation
If you use this library in academic work, please cite:
@misc{thareja2025dpfusion,
title={DP-Fusion: Token-Level Differentially Private Inference for Large Language Models},
author={Rushil Thareja and Preslav Nakov and Praneeth Vepakomma and Nils Lukas},
year={2025},
eprint={2507.04531},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.04531}
}
License
DP-Fusion-Lib is available under a dual license:
| Use Case | License | Cost |
|---|---|---|
| Academic research | Non-Commercial License | Free |
| Educational use | Non-Commercial License | Free |
| Commercial products | Commercial License | Contact for pricing |
Support
- Documentation: GitHub Repository
- Issues: GitHub Issues
- Any querries? just email me: rushil.thareja@mbzuai.ac.ae