mirror of
https://github.com/FoundationAgents/MetaGPT.git
synced 2026-07-11 16:22:15 +02:00
commit
e7b5d3c0c9
422 changed files with 16834 additions and 4078 deletions
84
.github/workflows/fulltest.yaml
vendored
Normal file
84
.github/workflows/fulltest.yaml
vendored
Normal file
|
|
@ -0,0 +1,84 @@
|
|||
name: Full Tests
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
pull_request_target:
|
||||
push:
|
||||
branches:
|
||||
- 'main'
|
||||
- 'dev'
|
||||
- '*-release'
|
||||
- '*-debugger'
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
environment: unittest
|
||||
strategy:
|
||||
matrix:
|
||||
# python-version: ['3.9', '3.10', '3.11']
|
||||
python-version: ['3.9']
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.sha }}
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
cache: 'pip'
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
sh tests/scripts/run_install_deps.sh
|
||||
- name: Run reverse proxy script for ssh service
|
||||
if: contains(github.ref, '-debugger')
|
||||
continue-on-error: true
|
||||
env:
|
||||
FPR_SERVER_ADDR: ${{ secrets.FPR_SERVER_ADDR }}
|
||||
FPR_TOKEN: ${{ secrets.FPR_TOKEN }}
|
||||
FPR_SSH_REMOTE_PORT: ${{ secrets.FPR_SSH_REMOTE_PORT }}
|
||||
RSA_PUB: ${{ secrets.RSA_PUB }}
|
||||
SSH_PORT: ${{ vars.SSH_PORT || '22'}}
|
||||
run: |
|
||||
echo "Run \"ssh $(whoami)@FPR_SERVER_HOST -p FPR_SSH_REMOTE_PORT\" and \"cd $(pwd)\""
|
||||
mkdir -p ~/.ssh/
|
||||
echo $RSA_PUB >> ~/.ssh/authorized_keys
|
||||
chmod 600 ~/.ssh/authorized_keys
|
||||
wget https://github.com/fatedier/frp/releases/download/v0.32.1/frp_0.32.1_linux_amd64.tar.gz -O frp.tar.gz
|
||||
tar xvzf frp.tar.gz -C /opt
|
||||
mv /opt/frp* /opt/frp
|
||||
/opt/frp/frpc tcp --server_addr $FPR_SERVER_ADDR --token $FPR_TOKEN --local_port $SSH_PORT --remote_port $FPR_SSH_REMOTE_PORT
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
export ALLOW_OPENAI_API_CALL=0
|
||||
echo "${{ secrets.METAGPT_KEY_YAML }}" | base64 -d > config/key.yaml
|
||||
mkdir -p ~/.metagpt && echo "${{ secrets.METAGPT_CONFIG2_YAML }}" | base64 -d > ~/.metagpt/config2.yaml
|
||||
echo "${{ secrets.SPARK_YAML }}" | base64 -d > ~/.metagpt/spark.yaml
|
||||
pytest tests/ --doctest-modules --cov=./metagpt/ --cov-report=xml:cov.xml --cov-report=html:htmlcov --durations=20 | tee unittest.txt
|
||||
- name: Show coverage report
|
||||
run: |
|
||||
coverage report -m
|
||||
- name: Show failed tests and overall summary
|
||||
run: |
|
||||
grep -E "FAILED tests|ERROR tests|[0-9]+ passed," unittest.txt
|
||||
failed_count=$(grep -E "FAILED|ERROR" unittest.txt | wc -l)
|
||||
if [[ "$failed_count" -gt 0 ]]; then
|
||||
echo "$failed_count failed lines found! Task failed."
|
||||
exit 1
|
||||
fi
|
||||
- name: Upload pytest test results
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: pytest-results-${{ matrix.python-version }}
|
||||
path: |
|
||||
./unittest.txt
|
||||
./htmlcov/
|
||||
./tests/data/rsp_cache_new.json
|
||||
retention-days: 3
|
||||
if: ${{ always() }}
|
||||
- name: Upload coverage reports to Codecov
|
||||
uses: codecov/codecov-action@v3
|
||||
env:
|
||||
CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
|
||||
if: ${{ always() }}
|
||||
26
.github/workflows/unittest.yaml
vendored
26
.github/workflows/unittest.yaml
vendored
|
|
@ -1,16 +1,16 @@
|
|||
name: Unit Tests
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
pull_request_target:
|
||||
push:
|
||||
branches:
|
||||
- '*-debugger'
|
||||
- 'main'
|
||||
- 'dev'
|
||||
- '*-release'
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
environment: unittest
|
||||
strategy:
|
||||
matrix:
|
||||
# python-version: ['3.9', '3.10', '3.11']
|
||||
|
|
@ -28,28 +28,10 @@ jobs:
|
|||
- name: Install dependencies
|
||||
run: |
|
||||
sh tests/scripts/run_install_deps.sh
|
||||
- name: Run reverse proxy script for ssh service
|
||||
if: contains(github.ref, '-debugger')
|
||||
continue-on-error: true
|
||||
env:
|
||||
FPR_SERVER_ADDR: ${{ secrets.FPR_SERVER_ADDR }}
|
||||
FPR_TOKEN: ${{ secrets.FPR_TOKEN }}
|
||||
FPR_SSH_REMOTE_PORT: ${{ secrets.FPR_SSH_REMOTE_PORT }}
|
||||
RSA_PUB: ${{ secrets.RSA_PUB }}
|
||||
SSH_PORT: ${{ vars.SSH_PORT || '22'}}
|
||||
run: |
|
||||
echo "Run \"ssh $(whoami)@FPR_SERVER_HOST -p FPR_SSH_REMOTE_PORT\" and \"cd $(pwd)\""
|
||||
mkdir -p ~/.ssh/
|
||||
echo $RSA_PUB >> ~/.ssh/authorized_keys
|
||||
chmod 600 ~/.ssh/authorized_keys
|
||||
wget https://github.com/fatedier/frp/releases/download/v0.32.1/frp_0.32.1_linux_amd64.tar.gz -O frp.tar.gz
|
||||
tar xvzf frp.tar.gz -C /opt
|
||||
mv /opt/frp* /opt/frp
|
||||
/opt/frp/frpc tcp --server_addr $FPR_SERVER_ADDR --token $FPR_TOKEN --local_port $SSH_PORT --remote_port $FPR_SSH_REMOTE_PORT
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
export ALLOW_OPENAI_API_CALL=0
|
||||
echo "${{ secrets.METAGPT_KEY_YAML }}" | base64 -d > config/key.yaml
|
||||
mkdir -p ~/.metagpt && cp tests/config2.yaml ~/.metagpt/config2.yaml && cp tests/spark.yaml ~/.metagpt/spark.yaml
|
||||
pytest tests/ --doctest-modules --cov=./metagpt/ --cov-report=xml:cov.xml --cov-report=html:htmlcov --durations=20 | tee unittest.txt
|
||||
- name: Show coverage report
|
||||
run: |
|
||||
|
|
|
|||
4
.gitignore
vendored
4
.gitignore
vendored
|
|
@ -172,8 +172,10 @@ tests/metagpt/utils/file_repo_git
|
|||
*.png
|
||||
htmlcov
|
||||
htmlcov.*
|
||||
cov.xml
|
||||
*.dot
|
||||
*.pkl
|
||||
*.faiss
|
||||
*-structure.csv
|
||||
*-structure.json
|
||||
|
||||
metagpt/tools/schemas
|
||||
|
|
@ -8,7 +8,7 @@ RUN apt update &&\
|
|||
|
||||
# Install Mermaid CLI globally
|
||||
ENV CHROME_BIN="/usr/bin/chromium" \
|
||||
PUPPETEER_CONFIG="/app/metagpt/config/puppeteer-config.json"\
|
||||
puppeteer_config="/app/metagpt/config/puppeteer-config.json"\
|
||||
PUPPETEER_SKIP_CHROMIUM_DOWNLOAD="true"
|
||||
RUN npm install -g @mermaid-js/mermaid-cli &&\
|
||||
npm cache clean --force
|
||||
|
|
|
|||
43
README.md
43
README.md
|
|
@ -55,30 +55,21 @@ ## Install
|
|||
|
||||
### Pip installation
|
||||
|
||||
> Ensure that Python 3.9+ is installed on your system. You can check this by using: `python --version`.
|
||||
> You can use conda like this: `conda create -n metagpt python=3.9 && conda activate metagpt`
|
||||
|
||||
```bash
|
||||
# Step 1: Ensure that Python 3.9+ is installed on your system. You can check this by using:
|
||||
# You can use conda to initialize a new python env
|
||||
# conda create -n metagpt python=3.9
|
||||
# conda activate metagpt
|
||||
python3 --version
|
||||
pip install metagpt
|
||||
metagpt --init-config # create ~/.metagpt/config2.yaml, modify it to your own config
|
||||
metagpt "Create a 2048 game" # this will create a repo in ./workspace
|
||||
```
|
||||
|
||||
# Step 2: Clone the repository to your local machine for latest version, and install it.
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip3 install -e . # or pip3 install metagpt # for stable version
|
||||
or you can use it as library
|
||||
|
||||
# Step 3: setup your OPENAI_API_KEY, or make sure it existed in the env
|
||||
mkdir ~/.metagpt
|
||||
cp config/config.yaml ~/.metagpt/config.yaml
|
||||
vim ~/.metagpt/config.yaml
|
||||
|
||||
# Step 4: run metagpt cli
|
||||
metagpt "Create a 2048 game in python"
|
||||
|
||||
# Step 5 [Optional]: If you want to save the artifacts like diagrams such as quadrant chart, system designs, sequence flow in the workspace, you can execute the step before Step 3. By default, the framework is compatible, and the entire process can be run completely without executing this step.
|
||||
# If executing, ensure that NPM is installed on your system. Then install mermaid-js. (If you don't have npm in your computer, please go to the Node.js official website to install Node.js https://nodejs.org/ and then you will have npm tool in your computer.)
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
```python
|
||||
from metagpt.software_company import generate_repo, ProjectRepo
|
||||
repo: ProjectRepo = generate_repo("Create a 2048 game") # or ProjectRepo("<path>")
|
||||
print(repo) # it will print the repo structure with files
|
||||
```
|
||||
|
||||
detail installation please refer to [cli_install](https://docs.deepwisdom.ai/main/en/guide/get_started/installation.html#install-stable-version)
|
||||
|
|
@ -87,19 +78,19 @@ ### Docker installation
|
|||
> Note: In the Windows, you need to replace "/opt/metagpt" with a directory that Docker has permission to create, such as "D:\Users\x\metagpt"
|
||||
|
||||
```bash
|
||||
# Step 1: Download metagpt official image and prepare config.yaml
|
||||
# Step 1: Download metagpt official image and prepare config2.yaml
|
||||
docker pull metagpt/metagpt:latest
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # Change the config
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
|
||||
vim /opt/metagpt/config/config2.yaml # Change the config
|
||||
|
||||
# Step 2: Run metagpt demo with container
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
metagpt "Write a cli snake game"
|
||||
metagpt "Create a 2048 game"
|
||||
```
|
||||
|
||||
detail installation please refer to [docker_install](https://docs.deepwisdom.ai/main/en/guide/get_started/installation.html#install-with-docker)
|
||||
|
|
|
|||
|
|
@ -1,145 +0,0 @@
|
|||
# DO NOT MODIFY THIS FILE, create a new key.yaml, define OPENAI_API_KEY.
|
||||
# The configuration of key.yaml has a higher priority and will not enter git
|
||||
|
||||
#### Project Path Setting
|
||||
# WORKSPACE_PATH: "Path for placing output files"
|
||||
|
||||
#### if OpenAI
|
||||
## The official OPENAI_BASE_URL is https://api.openai.com/v1
|
||||
## If the official OPENAI_BASE_URL is not available, we recommend using the [openai-forward](https://github.com/beidongjiedeguang/openai-forward).
|
||||
## Or, you can configure OPENAI_PROXY to access official OPENAI_BASE_URL.
|
||||
OPENAI_BASE_URL: "https://api.openai.com/v1"
|
||||
#OPENAI_PROXY: "http://127.0.0.1:8118"
|
||||
#OPENAI_API_KEY: "YOUR_API_KEY" # set the value to sk-xxx if you host the openai interface for open llm model
|
||||
OPENAI_API_MODEL: "gpt-4-1106-preview"
|
||||
MAX_TOKENS: 4096
|
||||
RPM: 10
|
||||
TIMEOUT: 60 # Timeout for llm invocation
|
||||
#DEFAULT_PROVIDER: openai
|
||||
|
||||
#### if Spark
|
||||
#SPARK_APPID : "YOUR_APPID"
|
||||
#SPARK_API_SECRET : "YOUR_APISecret"
|
||||
#SPARK_API_KEY : "YOUR_APIKey"
|
||||
#DOMAIN : "generalv2"
|
||||
#SPARK_URL : "ws://spark-api.xf-yun.com/v2.1/chat"
|
||||
|
||||
#### if Anthropic
|
||||
#ANTHROPIC_API_KEY: "YOUR_API_KEY"
|
||||
|
||||
#### if AZURE, check https://github.com/openai/openai-cookbook/blob/main/examples/azure/chat.ipynb
|
||||
#OPENAI_API_TYPE: "azure"
|
||||
#OPENAI_BASE_URL: "YOUR_AZURE_ENDPOINT"
|
||||
#OPENAI_API_KEY: "YOUR_AZURE_API_KEY"
|
||||
#OPENAI_API_VERSION: "YOUR_AZURE_API_VERSION"
|
||||
#DEPLOYMENT_NAME: "YOUR_DEPLOYMENT_NAME"
|
||||
|
||||
#### if zhipuai from `https://open.bigmodel.cn`. You can set here or export API_KEY="YOUR_API_KEY"
|
||||
# ZHIPUAI_API_KEY: "YOUR_API_KEY"
|
||||
# ZHIPUAI_API_MODEL: "glm-4"
|
||||
|
||||
#### if Google Gemini from `https://ai.google.dev/` and API_KEY from `https://makersuite.google.com/app/apikey`.
|
||||
#### You can set here or export GOOGLE_API_KEY="YOUR_API_KEY"
|
||||
# GEMINI_API_KEY: "YOUR_API_KEY"
|
||||
|
||||
#### if use self-host open llm model with openai-compatible interface
|
||||
#OPEN_LLM_API_BASE: "http://127.0.0.1:8000/v1"
|
||||
#OPEN_LLM_API_MODEL: "llama2-13b"
|
||||
#
|
||||
##### if use Fireworks api
|
||||
#FIREWORKS_API_KEY: "YOUR_API_KEY"
|
||||
#FIREWORKS_API_BASE: "https://api.fireworks.ai/inference/v1"
|
||||
#FIREWORKS_API_MODEL: "YOUR_LLM_MODEL" # example, accounts/fireworks/models/llama-v2-13b-chat
|
||||
|
||||
#### if use self-host open llm model by ollama
|
||||
# OLLAMA_API_BASE: http://127.0.0.1:11434/api
|
||||
# OLLAMA_API_MODEL: llama2
|
||||
|
||||
#### for Search
|
||||
|
||||
## Supported values: serpapi/google/serper/ddg
|
||||
#SEARCH_ENGINE: serpapi
|
||||
|
||||
## Visit https://serpapi.com/ to get key.
|
||||
#SERPAPI_API_KEY: "YOUR_API_KEY"
|
||||
|
||||
## Visit https://console.cloud.google.com/apis/credentials to get key.
|
||||
#GOOGLE_API_KEY: "YOUR_API_KEY"
|
||||
## Visit https://programmablesearchengine.google.com/controlpanel/create to get id.
|
||||
#GOOGLE_CSE_ID: "YOUR_CSE_ID"
|
||||
|
||||
## Visit https://serper.dev/ to get key.
|
||||
#SERPER_API_KEY: "YOUR_API_KEY"
|
||||
|
||||
#### for web access
|
||||
|
||||
## Supported values: playwright/selenium
|
||||
#WEB_BROWSER_ENGINE: playwright
|
||||
|
||||
## Supported values: chromium/firefox/webkit, visit https://playwright.dev/python/docs/api/class-browsertype
|
||||
##PLAYWRIGHT_BROWSER_TYPE: chromium
|
||||
|
||||
## Supported values: chrome/firefox/edge/ie, visit https://www.selenium.dev/documentation/webdriver/browsers/
|
||||
# SELENIUM_BROWSER_TYPE: chrome
|
||||
|
||||
#### for TTS
|
||||
|
||||
#AZURE_TTS_SUBSCRIPTION_KEY: "YOUR_API_KEY"
|
||||
#AZURE_TTS_REGION: "eastus"
|
||||
|
||||
#### for Stable Diffusion
|
||||
## Use SD service, based on https://github.com/AUTOMATIC1111/stable-diffusion-webui
|
||||
#SD_URL: "YOUR_SD_URL"
|
||||
#SD_T2I_API: "/sdapi/v1/txt2img"
|
||||
|
||||
#### for Execution
|
||||
#LONG_TERM_MEMORY: false
|
||||
|
||||
#### for Mermaid CLI
|
||||
## If you installed mmdc (Mermaid CLI) only for metagpt then enable the following configuration.
|
||||
#PUPPETEER_CONFIG: "./config/puppeteer-config.json"
|
||||
#MMDC: "./node_modules/.bin/mmdc"
|
||||
|
||||
|
||||
### for calc_usage
|
||||
# CALC_USAGE: false
|
||||
|
||||
### for Research
|
||||
# MODEL_FOR_RESEARCHER_SUMMARY: gpt-3.5-turbo
|
||||
# MODEL_FOR_RESEARCHER_REPORT: gpt-3.5-turbo-16k
|
||||
|
||||
### choose the engine for mermaid conversion,
|
||||
# default is nodejs, you can change it to playwright,pyppeteer or ink
|
||||
# MERMAID_ENGINE: nodejs
|
||||
|
||||
### browser path for pyppeteer engine, support Chrome, Chromium,MS Edge
|
||||
#PYPPETEER_EXECUTABLE_PATH: "/usr/bin/google-chrome-stable"
|
||||
|
||||
### for repair non-openai LLM's output when parse json-text if PROMPT_FORMAT=json
|
||||
### due to non-openai LLM's output will not always follow the instruction, so here activate a post-process
|
||||
### repair operation on the content extracted from LLM's raw output. Warning, it improves the result but not fix all cases.
|
||||
# REPAIR_LLM_OUTPUT: false
|
||||
|
||||
# PROMPT_FORMAT: json #json or markdown
|
||||
|
||||
### Agent configurations
|
||||
# RAISE_NOT_CONFIG_ERROR: true # "true" if the LLM key is not configured, throw a NotConfiguredException, else "false".
|
||||
# WORKSPACE_PATH_WITH_UID: false # "true" if using `{workspace}/{uid}` as the workspace path; "false" use `{workspace}`.
|
||||
|
||||
### Meta Models
|
||||
#METAGPT_TEXT_TO_IMAGE_MODEL: MODEL_URL
|
||||
|
||||
### S3 config
|
||||
#S3_ACCESS_KEY: "YOUR_S3_ACCESS_KEY"
|
||||
#S3_SECRET_KEY: "YOUR_S3_SECRET_KEY"
|
||||
#S3_ENDPOINT_URL: "YOUR_S3_ENDPOINT_URL"
|
||||
#S3_SECURE: true # true/false
|
||||
#S3_BUCKET: "YOUR_S3_BUCKET"
|
||||
|
||||
### Redis config
|
||||
#REDIS_HOST: "YOUR_REDIS_HOST"
|
||||
#REDIS_PORT: "YOUR_REDIS_PORT"
|
||||
#REDIS_PASSWORD: "YOUR_REDIS_PASSWORD"
|
||||
#REDIS_DB: "YOUR_REDIS_DB_INDEX, str, 0-based"
|
||||
|
||||
# DISABLE_LLM_PROVIDER_CHECK: false
|
||||
3
config/config2.yaml
Normal file
3
config/config2.yaml
Normal file
|
|
@ -0,0 +1,3 @@
|
|||
llm:
|
||||
api_key: "YOUR_API_KEY"
|
||||
model: "gpt-4-turbo-preview" # or gpt-3.5-turbo-1106 / gpt-4-1106-preview
|
||||
45
config/config2.yaml.example
Normal file
45
config/config2.yaml.example
Normal file
|
|
@ -0,0 +1,45 @@
|
|||
llm:
|
||||
api_type: "openai"
|
||||
base_url: "YOUR_BASE_URL"
|
||||
api_key: "YOUR_API_KEY"
|
||||
model: "gpt-4-turbo-preview" # or gpt-3.5-turbo-1106 / gpt-4-1106-preview
|
||||
|
||||
proxy: "YOUR_PROXY"
|
||||
|
||||
search:
|
||||
api_type: "google"
|
||||
api_key: "YOUR_API_KEY"
|
||||
cse_id: "YOUR_CSE_ID"
|
||||
|
||||
browser:
|
||||
engine: "playwright" # playwright/selenium
|
||||
browser_type: "chromium" # playwright: chromium/firefox/webkit; selenium: chrome/firefox/edge/ie
|
||||
|
||||
mermaid:
|
||||
engine: "pyppeteer"
|
||||
path: "/Applications/Google Chrome.app"
|
||||
|
||||
redis:
|
||||
host: "YOUR_HOST"
|
||||
port: 32582
|
||||
password: "YOUR_PASSWORD"
|
||||
db: "0"
|
||||
|
||||
s3:
|
||||
access_key: "YOUR_ACCESS_KEY"
|
||||
secret_key: "YOUR_SECRET_KEY"
|
||||
endpoint: "YOUR_ENDPOINT"
|
||||
secure: false
|
||||
bucket: "test"
|
||||
|
||||
|
||||
azure_tts_subscription_key: "YOUR_SUBSCRIPTION_KEY"
|
||||
azure_tts_region: "eastus"
|
||||
|
||||
iflytek_api_id: "YOUR_APP_ID"
|
||||
iflytek_api_key: "YOUR_API_KEY"
|
||||
iflytek_api_secret: "YOUR_API_SECRET"
|
||||
|
||||
metagpt_tti_url: "YOUR_MODEL_URL"
|
||||
|
||||
repair_llm_output: true
|
||||
|
|
@ -14,16 +14,16 @@ paths:
|
|||
/tts/azsure:
|
||||
x-prerequisite:
|
||||
configurations:
|
||||
AZURE_TTS_SUBSCRIPTION_KEY:
|
||||
azure_tts_subscription_key:
|
||||
type: string
|
||||
description: "For more details, check out: [Azure Text-to_Speech](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts)"
|
||||
AZURE_TTS_REGION:
|
||||
azure_tts_region:
|
||||
type: string
|
||||
description: "For more details, check out: [Azure Text-to_Speech](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts)"
|
||||
required:
|
||||
allOf:
|
||||
- AZURE_TTS_SUBSCRIPTION_KEY
|
||||
- AZURE_TTS_REGION
|
||||
- azure_tts_subscription_key
|
||||
- azure_tts_region
|
||||
post:
|
||||
summary: "Convert Text to Base64-encoded .wav File Stream"
|
||||
description: "For more details, check out: [Azure Text-to_Speech](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts)"
|
||||
|
|
@ -94,9 +94,9 @@ paths:
|
|||
description: "WebAPI argument, see: `https://console.xfyun.cn/services/tts`"
|
||||
required:
|
||||
allOf:
|
||||
- IFLYTEK_APP_ID
|
||||
- IFLYTEK_API_KEY
|
||||
- IFLYTEK_API_SECRET
|
||||
- iflytek_app_id
|
||||
- iflytek_api_key
|
||||
- iflytek_api_secret
|
||||
post:
|
||||
summary: "Convert Text to Base64-encoded .mp3 File Stream"
|
||||
description: "For more details, check out: [iFlyTek](https://console.xfyun.cn/services/tts)"
|
||||
|
|
@ -242,12 +242,12 @@ paths:
|
|||
/txt2image/metagpt:
|
||||
x-prerequisite:
|
||||
configurations:
|
||||
METAGPT_TEXT_TO_IMAGE_MODEL_URL:
|
||||
metagpt_tti_url:
|
||||
type: string
|
||||
description: "Model url."
|
||||
required:
|
||||
allOf:
|
||||
- METAGPT_TEXT_TO_IMAGE_MODEL_URL
|
||||
- metagpt_tti_url
|
||||
post:
|
||||
summary: "Text to Image"
|
||||
description: "Generate an image from the provided text using the MetaGPT Text-to-Image API."
|
||||
|
|
|
|||
|
|
@ -14,10 +14,10 @@ entities:
|
|||
id: text_to_speech.text_to_speech
|
||||
x-prerequisite:
|
||||
configurations:
|
||||
AZURE_TTS_SUBSCRIPTION_KEY:
|
||||
azure_tts_subscription_key:
|
||||
type: string
|
||||
description: "For more details, check out: [Azure Text-to_Speech](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts)"
|
||||
AZURE_TTS_REGION:
|
||||
azure_tts_region:
|
||||
type: string
|
||||
description: "For more details, check out: [Azure Text-to_Speech](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts)"
|
||||
IFLYTEK_APP_ID:
|
||||
|
|
@ -32,12 +32,12 @@ entities:
|
|||
required:
|
||||
oneOf:
|
||||
- allOf:
|
||||
- AZURE_TTS_SUBSCRIPTION_KEY
|
||||
- AZURE_TTS_REGION
|
||||
- azure_tts_subscription_key
|
||||
- azure_tts_region
|
||||
- allOf:
|
||||
- IFLYTEK_APP_ID
|
||||
- IFLYTEK_API_KEY
|
||||
- IFLYTEK_API_SECRET
|
||||
- iflytek_app_id
|
||||
- iflytek_api_key
|
||||
- iflytek_api_secret
|
||||
parameters:
|
||||
text:
|
||||
description: 'The text used for voice conversion.'
|
||||
|
|
@ -103,13 +103,13 @@ entities:
|
|||
OPENAI_API_KEY:
|
||||
type: string
|
||||
description: "OpenAI API key, For more details, checkout: `https://platform.openai.com/account/api-keys`"
|
||||
METAGPT_TEXT_TO_IMAGE_MODEL_URL:
|
||||
metagpt_tti_url:
|
||||
type: string
|
||||
description: "Model url."
|
||||
required:
|
||||
oneOf:
|
||||
- OPENAI_API_KEY
|
||||
- METAGPT_TEXT_TO_IMAGE_MODEL_URL
|
||||
- metagpt_tti_url
|
||||
parameters:
|
||||
text:
|
||||
description: 'The text used for image conversion.'
|
||||
|
|
|
|||
198
docs/FAQ-EN.md
198
docs/FAQ-EN.md
|
|
@ -1,183 +1,93 @@
|
|||
Our vision is to [extend human life](https://github.com/geekan/HowToLiveLonger) and [reduce working hours](https://github.com/geekan/MetaGPT/).
|
||||
|
||||
1. ### Convenient Link for Sharing this Document:
|
||||
### Convenient Link for Sharing this Document:
|
||||
|
||||
```
|
||||
- MetaGPT-Index/FAQ https://deepwisdom.feishu.cn/wiki/MsGnwQBjiif9c3koSJNcYaoSnu4
|
||||
- MetaGPT-Index/FAQ-EN https://github.com/geekan/MetaGPT/blob/main/docs/FAQ-EN.md
|
||||
- MetaGPT-Index/FAQ-CN https://deepwisdom.feishu.cn/wiki/MsGnwQBjiif9c3koSJNcYaoSnu4
|
||||
```
|
||||
|
||||
2. ### Link
|
||||
|
||||
<!---->
|
||||
### Link
|
||||
|
||||
1. Code:https://github.com/geekan/MetaGPT
|
||||
|
||||
1. Roadmap:https://github.com/geekan/MetaGPT/blob/main/docs/ROADMAP.md
|
||||
|
||||
1. EN
|
||||
|
||||
1. Demo Video: [MetaGPT: Multi-Agent AI Programming Framework](https://www.youtube.com/watch?v=8RNzxZBTW8M)
|
||||
2. Roadmap:https://github.com/geekan/MetaGPT/blob/main/docs/ROADMAP.md
|
||||
3. EN
|
||||
1. Demo Video: [MetaGPT: Multi-Agent AI Programming Framework](https://www.youtube.com/watch?v=8RNzxZBTW8M)
|
||||
2. Tutorial: [MetaGPT: Deploy POWERFUL Autonomous Ai Agents BETTER Than SUPERAGI!](https://www.youtube.com/watch?v=q16Gi9pTG_M&t=659s)
|
||||
3. Author's thoughts video(EN): [MetaGPT Matthew Berman](https://youtu.be/uT75J_KG_aY?si=EgbfQNAwD8F5Y1Ak)
|
||||
4. CN
|
||||
1. Demo Video: [MetaGPT:一行代码搭建你的虚拟公司_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1NP411C7GW/?spm_id_from=333.999.0.0&vd_source=735773c218b47da1b4bd1b98a33c5c77)
|
||||
1. Tutorial: [一个提示词写游戏 Flappy bird, 比AutoGPT强10倍的MetaGPT,最接近AGI的AI项目](https://youtu.be/Bp95b8yIH5c)
|
||||
2. Author's thoughts video(CN): [MetaGPT作者深度解析直播回放_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1Ru411V7XL/?spm_id_from=333.337.search-card.all.click)
|
||||
|
||||
1. CN
|
||||
|
||||
1. Demo Video: [MetaGPT:一行代码搭建你的虚拟公司_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1NP411C7GW/?spm_id_from=333.999.0.0&vd_source=735773c218b47da1b4bd1b98a33c5c77)
|
||||
1. Tutorial: [一个提示词写游戏 Flappy bird, 比AutoGPT强10倍的MetaGPT,最接近AGI的AI项目](https://youtu.be/Bp95b8yIH5c)
|
||||
2. Author's thoughts video(CN): [MetaGPT作者深度解析直播回放_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1Ru411V7XL/?spm_id_from=333.337.search-card.all.click)
|
||||
|
||||
<!---->
|
||||
|
||||
3. ### How to become a contributor?
|
||||
|
||||
<!---->
|
||||
### How to become a contributor?
|
||||
|
||||
1. Choose a task from the Roadmap (or you can propose one). By submitting a PR, you can become a contributor and join the dev team.
|
||||
1. Current contributors come from backgrounds including ByteDance AI Lab/DingDong/Didi/Xiaohongshu, Tencent/Baidu/MSRA/TikTok/BloomGPT Infra/Bilibili/CUHK/HKUST/CMU/UCB
|
||||
2. Current contributors come from backgrounds including ByteDance AI Lab/DingDong/Didi/Xiaohongshu, Tencent/Baidu/MSRA/TikTok/BloomGPT Infra/Bilibili/CUHK/HKUST/CMU/UCB
|
||||
|
||||
<!---->
|
||||
|
||||
4. ### Chief Evangelist (Monthly Rotation)
|
||||
### Chief Evangelist (Monthly Rotation)
|
||||
|
||||
MetaGPT Community - The position of Chief Evangelist rotates on a monthly basis. The primary responsibilities include:
|
||||
|
||||
1. Maintaining community FAQ documents, announcements, and Github resources/READMEs.
|
||||
1. Responding to, answering, and distributing community questions within an average of 30 minutes, including on platforms like Github Issues, Discord and WeChat.
|
||||
1. Upholding a community atmosphere that is enthusiastic, genuine, and friendly.
|
||||
1. Encouraging everyone to become contributors and participate in projects that are closely related to achieving AGI (Artificial General Intelligence).
|
||||
1. (Optional) Organizing small-scale events, such as hackathons.
|
||||
2. Responding to, answering, and distributing community questions within an average of 30 minutes, including on platforms like Github Issues, Discord and WeChat.
|
||||
3. Upholding a community atmosphere that is enthusiastic, genuine, and friendly.
|
||||
4. Encouraging everyone to become contributors and participate in projects that are closely related to achieving AGI (Artificial General Intelligence).
|
||||
5. (Optional) Organizing small-scale events, such as hackathons.
|
||||
|
||||
<!---->
|
||||
|
||||
5. ### FAQ
|
||||
|
||||
<!---->
|
||||
|
||||
1. Experience with the generated repo code:
|
||||
|
||||
1. https://github.com/geekan/MetaGPT/releases/tag/v0.1.0
|
||||
### FAQ
|
||||
|
||||
1. Code truncation/ Parsing failure:
|
||||
|
||||
1. Check if it's due to exceeding length. Consider using the gpt-3.5-turbo-16k or other long token versions.
|
||||
|
||||
1. Success rate:
|
||||
|
||||
1. There hasn't been a quantitative analysis yet, but the success rate of code generated by GPT-4 is significantly higher than that of gpt-3.5-turbo.
|
||||
|
||||
1. Support for incremental, differential updates (if you wish to continue a half-done task):
|
||||
|
||||
1. Several prerequisite tasks are listed on the ROADMAP.
|
||||
|
||||
1. Can existing code be loaded?
|
||||
|
||||
1. It's not on the ROADMAP yet, but there are plans in place. It just requires some time.
|
||||
|
||||
1. Support for multiple programming languages and natural languages?
|
||||
|
||||
1. It's listed on ROADMAP.
|
||||
|
||||
1. Want to join the contributor team? How to proceed?
|
||||
|
||||
1. Check if it's due to exceeding length. Consider using the gpt-4-turbo-preview or other long token versions.
|
||||
2. Success rate:
|
||||
1. There hasn't been a quantitative analysis yet, but the success rate of code generated by gpt-4-turbo-preview is significantly higher than that of gpt-3.5-turbo.
|
||||
3. Support for incremental, differential updates (if you wish to continue a half-done task):
|
||||
1. There is now an experimental version. Specify `--inc --project-path "<path>"` or `--inc --project-name "<name>"` on the command line and enter the corresponding requirements to try it.
|
||||
4. Can existing code be loaded?
|
||||
1. We are doing this, but it is very difficult, especially when the project is large, it is very difficult to achieve a high success rate.
|
||||
5. Support for multiple programming languages and natural languages?
|
||||
1. It is now supported, but it is still in experimental version
|
||||
6. Want to join the contributor team? How to proceed?
|
||||
1. Merging a PR will get you into the contributor's team. The main ongoing tasks are all listed on the ROADMAP.
|
||||
|
||||
1. PRD stuck / unable to access/ connection interrupted
|
||||
|
||||
1. The official OPENAI_BASE_URL address is `https://api.openai.com/v1`
|
||||
1. If the official OPENAI_BASE_URL address is inaccessible in your environment (this can be verified with curl), it's recommended to configure using the reverse proxy OPENAI_BASE_URL provided by libraries such as openai-forward. For instance, `OPENAI_BASE_URL: "``https://api.openai-forward.com/v1``"`
|
||||
1. If the official OPENAI_BASE_URL address is inaccessible in your environment (again, verifiable via curl), another option is to configure the OPENAI_PROXY parameter. This way, you can access the official OPENAI_BASE_URL via a local proxy. If you don't need to access via a proxy, please do not enable this configuration; if accessing through a proxy is required, modify it to the correct proxy address. Note that when OPENAI_PROXY is enabled, don't set OPENAI_BASE_URL.
|
||||
1. Note: OpenAI's default API design ends with a v1. An example of the correct configuration is: `OPENAI_BASE_URL: "``https://api.openai.com/v1``"`
|
||||
|
||||
1. Absolutely! How can I assist you today?
|
||||
|
||||
7. PRD stuck / unable to access/ connection interrupted
|
||||
1. The official openai base_url address is `https://api.openai.com/v1`
|
||||
2. If the official openai base_url address is inaccessible in your environment (this can be verified with curl), it's recommended to configure using base_url to other "reverse-proxy" provider such as openai-forward. For instance, `openai base_url: "``https://api.openai-forward.com/v1``"`
|
||||
3. If the official openai base_url address is inaccessible in your environment (again, verifiable via curl), another option is to configure the llm.proxy in the `config2.yaml`. This way, you can access the official openai base_url via a local proxy. If you don't need to access via a proxy, please do not enable this configuration; if accessing through a proxy is required, modify it to the correct proxy address.
|
||||
4. Note: OpenAI's default API design ends with a v1. An example of the correct configuration is: `base_url: "https://api.openai.com/v1"
|
||||
8. Get reply: "Absolutely! How can I assist you today?"
|
||||
1. Did you use Chi or a similar service? These services are prone to errors, and it seems that the error rate is higher when consuming 3.5k-4k tokens in GPT-4
|
||||
|
||||
1. What does Max token mean?
|
||||
|
||||
9. What does Max token mean?
|
||||
1. It's a configuration for OpenAI's maximum response length. If the response exceeds the max token, it will be truncated.
|
||||
|
||||
1. How to change the investment amount?
|
||||
|
||||
10. How to change the investment amount?
|
||||
1. You can view all commands by typing `metagpt --help`
|
||||
|
||||
1. Which version of Python is more stable?
|
||||
|
||||
11. Which version of Python is more stable?
|
||||
1. python3.9 / python3.10
|
||||
|
||||
1. Can't use GPT-4, getting the error "The model gpt-4 does not exist."
|
||||
|
||||
12. Can't use GPT-4, getting the error "The model gpt-4 does not exist."
|
||||
1. OpenAI's official requirement: You can use GPT-4 only after spending $1 on OpenAI.
|
||||
1. Tip: Run some data with gpt-3.5-turbo (consume the free quota and $1), and then you should be able to use gpt-4.
|
||||
|
||||
1. Can games whose code has never been seen before be written?
|
||||
|
||||
13. Can games whose code has never been seen before be written?
|
||||
1. Refer to the README. The recommendation system of Toutiao is one of the most complex systems in the world currently. Although it's not on GitHub, many discussions about it exist online. If it can visualize these, it suggests it can also summarize these discussions and convert them into code. The prompt would be something like "write a recommendation system similar to Toutiao". Note: this was approached in earlier versions of the software. The SOP of those versions was different; the current one adopts Elon Musk's five-step work method, emphasizing trimming down requirements as much as possible.
|
||||
|
||||
1. Under what circumstances would there typically be errors?
|
||||
|
||||
14. Under what circumstances would there typically be errors?
|
||||
1. More than 500 lines of code: some function implementations may be left blank.
|
||||
1. When using a database, it often gets the implementation wrong — since the SQL database initialization process is usually not in the code.
|
||||
1. With more lines of code, there's a higher chance of false impressions, leading to calls to non-existent APIs.
|
||||
|
||||
1. Instructions for using SD Skills/UI Role:
|
||||
|
||||
1. Currently, there is a test script located in /tests/metagpt/roles. The file ui_role provides the corresponding code implementation. For testing, you can refer to the test_ui in the same directory.
|
||||
|
||||
1. The UI role takes over from the product manager role, extending the output from the 【UI Design draft】 provided by the product manager role. The UI role has implemented the UIDesign Action. Within the run of UIDesign, it processes the respective context, and based on the set template, outputs the UI. The output from the UI role includes:
|
||||
|
||||
1. UI Design Description: Describes the content to be designed and the design objectives.
|
||||
1. Selected Elements: Describes the elements in the design that need to be illustrated.
|
||||
1. HTML Layout: Outputs the HTML code for the page.
|
||||
1. CSS Styles (styles.css): Outputs the CSS code for the page.
|
||||
|
||||
1. Currently, the SD skill is a tool invoked by UIDesign. It instantiates the SDEngine, with specific code found in metagpt/tools/sd_engine.
|
||||
|
||||
1. Configuration instructions for SD Skills: The SD interface is currently deployed based on *https://github.com/AUTOMATIC1111/stable-diffusion-webui* **For environmental configurations and model downloads, please refer to the aforementioned GitHub repository. To initiate the SD service that supports API calls, run the command specified in cmd with the parameter nowebui, i.e.,
|
||||
|
||||
1. > python3 webui.py --enable-insecure-extension-access --port xxx --no-gradio-queue --nowebui
|
||||
1. Once it runs without errors, the interface will be accessible after approximately 1 minute when the model finishes loading.
|
||||
1. Configure SD_URL and SD_T2I_API in the config.yaml/key.yaml files.
|
||||
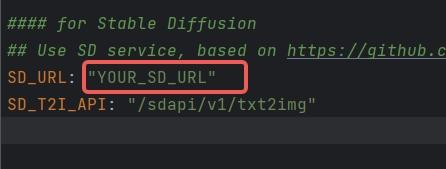
1. 
|
||||
1. SD_URL is the deployed server/machine IP, and Port is the specified port above, defaulting to 7860.
|
||||
1. > SD_URL: IP:Port
|
||||
|
||||
1. An error occurred during installation: "Another program is using this file...egg".
|
||||
|
||||
2. When using a database, it often gets the implementation wrong — since the SQL database initialization process is usually not in the code.
|
||||
3. With more lines of code, there's a higher chance of false impressions, leading to calls to non-existent APIs.
|
||||
15. An error occurred during installation: "Another program is using this file...egg".
|
||||
1. Delete the file and try again.
|
||||
1. Or manually execute`pip install -r requirements.txt`
|
||||
|
||||
1. The origin of the name MetaGPT?
|
||||
|
||||
2. Or manually execute`pip install -r requirements.txt`
|
||||
16. The origin of the name MetaGPT?
|
||||
1. The name was derived after iterating with GPT-4 over a dozen rounds. GPT-4 scored and suggested it.
|
||||
|
||||
1. Is there a more step-by-step installation tutorial?
|
||||
|
||||
1. Youtube(CN):[一个提示词写游戏 Flappy bird, 比AutoGPT强10倍的MetaGPT,最接近AGI的AI项目=一个软件公司产品经理+程序员](https://youtu.be/Bp95b8yIH5c)
|
||||
1. Youtube(EN)https://www.youtube.com/watch?v=q16Gi9pTG_M&t=659s
|
||||
2. video(EN): [MetaGPT Matthew Berman](https://youtu.be/uT75J_KG_aY?si=EgbfQNAwD8F5Y1Ak)
|
||||
|
||||
1. openai.error.RateLimitError: You exceeded your current quota, please check your plan and billing details
|
||||
|
||||
17. openai.error.RateLimitError: You exceeded your current quota, please check your plan and billing details
|
||||
1. If you haven't exhausted your free quota, set RPM to 3 or lower in the settings.
|
||||
1. If your free quota is used up, consider adding funds to your account.
|
||||
|
||||
1. What does "borg" mean in n_borg?
|
||||
|
||||
2. If your free quota is used up, consider adding funds to your account.
|
||||
18. What does "borg" mean in n_borg?
|
||||
1. [Wikipedia borg meaning ](https://en.wikipedia.org/wiki/Borg)
|
||||
1. The Borg civilization operates based on a hive or collective mentality, known as "the Collective." Every Borg individual is connected to the collective via a sophisticated subspace network, ensuring continuous oversight and guidance for every member. This collective consciousness allows them to not only "share the same thoughts" but also to adapt swiftly to new strategies. While individual members of the collective rarely communicate, the collective "voice" sometimes transmits aboard ships.
|
||||
|
||||
1. How to use the Claude API?
|
||||
|
||||
2. The Borg civilization operates based on a hive or collective mentality, known as "the Collective." Every Borg individual is connected to the collective via a sophisticated subspace network, ensuring continuous oversight and guidance for every member. This collective consciousness allows them to not only "share the same thoughts" but also to adapt swiftly to new strategies. While individual members of the collective rarely communicate, the collective "voice" sometimes transmits aboard ships.
|
||||
19. How to use the Claude API?
|
||||
1. The full implementation of the Claude API is not provided in the current code.
|
||||
1. You can use the Claude API through third-party API conversion projects like: https://github.com/jtsang4/claude-to-chatgpt
|
||||
|
||||
1. Is Llama2 supported?
|
||||
|
||||
20. Is Llama2 supported?
|
||||
1. On the day Llama2 was released, some of the community members began experiments and found that output can be generated based on MetaGPT's structure. However, Llama2's context is too short to generate a complete project. Before regularly using Llama2, it's necessary to expand the context window to at least 8k. If anyone has good recommendations for expansion models or methods, please leave a comment.
|
||||
|
||||
1. `mermaid-cli getElementsByTagName SyntaxError: Unexpected token '.'`
|
||||
|
||||
21. `mermaid-cli getElementsByTagName SyntaxError: Unexpected token '.'`
|
||||
1. Upgrade node to version 14.x or above:
|
||||
|
||||
1. `npm install -g n`
|
||||
1. `n stable` to install the stable version of node(v18.x)
|
||||
2. `n stable` to install the stable version of node(v18.x)
|
||||
|
|
|
|||
|
|
@ -35,50 +35,45 @@ # MetaGPT: 多智能体框架
|
|||
## 安装
|
||||
### Pip安装
|
||||
|
||||
> 确保您的系统已安装 Python 3.9 或更高版本。您可以使用以下命令来检查:`python --version`。
|
||||
> 您可以这样使用 conda:`conda create -n metagpt python=3.9 && conda activate metagpt`
|
||||
|
||||
```bash
|
||||
# 第 1 步:确保您的系统上安装了 Python 3.9+。您可以使用以下命令进行检查:
|
||||
# 可以使用conda来初始化新的python环境
|
||||
# conda create -n metagpt python=3.9
|
||||
# conda activate metagpt
|
||||
python3 --version
|
||||
|
||||
# 第 2 步:克隆最新仓库到您的本地机器,并进行安装。
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip3 install -e. # 或者 pip3 install metagpt # 安装稳定版本
|
||||
|
||||
# 第 3 步:执行metagpt
|
||||
# 拷贝config.yaml为key.yaml,并设置你自己的OPENAI_API_KEY
|
||||
metagpt "Write a cli snake game"
|
||||
|
||||
# 第 4 步【可选的】:如果你想在执行过程中保存像象限图、系统设计、序列流程等图表这些产物,可以在第3步前执行该步骤。默认的,框架做了兼容,在不执行该步的情况下,也可以完整跑完整个流程。
|
||||
# 如果执行,确保您的系统上安装了 NPM。并使用npm安装mermaid-js
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
pip install metagpt
|
||||
metagpt --init-config # 创建 ~/.metagpt/config2.yaml,根据您的需求修改它
|
||||
metagpt "创建一个 2048 游戏" # 这将在 ./workspace 创建一个仓库
|
||||
```
|
||||
|
||||
详细的安装请安装 [cli_install](https://docs.deepwisdom.ai/guide/get_started/installation.html#install-stable-version)
|
||||
或者您可以将其作为库使用
|
||||
|
||||
```python
|
||||
from metagpt.software_company import generate_repo, ProjectRepo
|
||||
repo: ProjectRepo = generate_repo("创建一个 2048 游戏") # 或 ProjectRepo("<路径>")
|
||||
print(repo) # 它将打印出仓库结构及其文件
|
||||
```
|
||||
|
||||
详细的安装请参考 [cli_install](https://docs.deepwisdom.ai/guide/get_started/installation.html#install-stable-version)
|
||||
|
||||
### Docker安装
|
||||
> 注意:在Windows中,你需要将 "/opt/metagpt" 替换为Docker具有创建权限的目录,比如"D:\Users\x\metagpt"
|
||||
|
||||
```bash
|
||||
# 步骤1: 下载metagpt官方镜像并准备好config.yaml
|
||||
# 步骤1: 下载metagpt官方镜像并准备好config2.yaml
|
||||
docker pull metagpt/metagpt:latest
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # 修改配置文件
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
|
||||
vim /opt/metagpt/config/config2.yaml # 修改配置文件
|
||||
|
||||
# 步骤2: 使用容器运行metagpt演示
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
metagpt "Write a cli snake game"
|
||||
```
|
||||
|
||||
详细的安装请安装 [docker_install](https://docs.deepwisdom.ai/main/zh/guide/get_started/installation.html#%E4%BD%BF%E7%94%A8docker%E5%AE%89%E8%A3%85)
|
||||
详细的安装请参考 [docker_install](https://docs.deepwisdom.ai/main/zh/guide/get_started/installation.html#%E4%BD%BF%E7%94%A8docker%E5%AE%89%E8%A3%85)
|
||||
|
||||
### 快速开始的演示视频
|
||||
- 在 [MetaGPT Huggingface Space](https://huggingface.co/spaces/deepwisdom/MetaGPT) 上进行体验
|
||||
|
|
|
|||
|
|
@ -57,24 +57,21 @@ ### インストールビデオガイド
|
|||
- [Matthew Berman: How To Install MetaGPT - Build A Startup With One Prompt!!](https://youtu.be/uT75J_KG_aY)
|
||||
|
||||
### 伝統的なインストール
|
||||
> Python 3.9 以上がシステムにインストールされていることを確認してください。これは `python --version` を使ってチェックできます。
|
||||
> 以下のようにcondaを使うことができます:`conda create -n metagpt python=3.9 && conda activate metagpt`
|
||||
|
||||
```bash
|
||||
# ステップ 1: Python 3.9+ がシステムにインストールされていることを確認してください。これを確認するには:
|
||||
python3 --version
|
||||
pip install metagpt
|
||||
metagpt --init-config # ~/.metagpt/config2.yaml を作成し、自分の設定に合わせて変更してください
|
||||
metagpt "2048ゲームを作成する" # これにより ./workspace にリポジトリが作成されます
|
||||
```
|
||||
|
||||
# ステップ 2: リポジトリをローカルマシンにクローンし、インストールする。
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip install -e.
|
||||
または、ライブラリとして使用することもできます
|
||||
|
||||
# ステップ 3: metagpt を実行する
|
||||
# config.yaml を key.yaml にコピーし、独自の OPENAI_API_KEY を設定します
|
||||
metagpt "Write a cli snake game"
|
||||
|
||||
# ステップ 4 [オプション]: 実行中に PRD ファイルなどのアーティファクトを保存する場合は、ステップ 3 の前にこのステップを実行できます。デフォルトでは、フレームワークには互換性があり、この手順を実行しなくてもプロセス全体を完了できます。
|
||||
# NPM がシステムにインストールされていることを確認してください。次に mermaid-js をインストールします。(お使いのコンピューターに npm がない場合は、Node.js 公式サイトで Node.js https://nodejs.org/ をインストールしてください。)
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
```python
|
||||
from metagpt.software_company import generate_repo, ProjectRepo
|
||||
repo: ProjectRepo = generate_repo("2048ゲームを作成する") # または ProjectRepo("<パス>")
|
||||
print(repo) # リポジトリの構造とファイルを出力します
|
||||
```
|
||||
|
||||
**注:**
|
||||
|
|
@ -91,8 +88,8 @@ # NPM がシステムにインストールされていることを確認して
|
|||
- config.yml に mmdc のコンフィグを記述するのを忘れないこと
|
||||
|
||||
```yml
|
||||
PUPPETEER_CONFIG: "./config/puppeteer-config.json"
|
||||
MMDC: "./node_modules/.bin/mmdc"
|
||||
puppeteer_config: "./config/puppeteer-config.json"
|
||||
path: "./node_modules/.bin/mmdc"
|
||||
```
|
||||
|
||||
- もし `pip install -e.` がエラー `[Errno 13] Permission denied: '/usr/local/lib/python3.11/dist-packages/test-easy-install-13129.write-test'` で失敗したら、代わりに `pip install -e. --user` を実行してみてください
|
||||
|
|
@ -114,12 +111,13 @@ # NPM がシステムにインストールされていることを確認して
|
|||
playwright install --with-deps chromium
|
||||
```
|
||||
|
||||
- **modify `config.yaml`**
|
||||
- **modify `config2.yaml`**
|
||||
|
||||
config.yaml から MERMAID_ENGINE のコメントを外し、`playwright` に変更する
|
||||
config2.yaml から mermaid.engine のコメントを外し、`playwright` に変更する
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: playwright
|
||||
mermaid:
|
||||
engine: playwright
|
||||
```
|
||||
|
||||
- pyppeteer
|
||||
|
|
@ -143,21 +141,23 @@ # NPM がシステムにインストールされていることを確認して
|
|||
pyppeteer-install
|
||||
```
|
||||
|
||||
- **`config.yaml` を修正**
|
||||
- **`config2.yaml` を修正**
|
||||
|
||||
config.yaml から MERMAID_ENGINE のコメントを外し、`pyppeteer` に変更する
|
||||
config2.yaml から mermaid.engine のコメントを外し、`pyppeteer` に変更する
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: pyppeteer
|
||||
mermaid:
|
||||
engine: pyppeteer
|
||||
```
|
||||
|
||||
- mermaid.ink
|
||||
- **`config.yaml` を修正**
|
||||
- **`config2.yaml` を修正**
|
||||
|
||||
config.yaml から MERMAID_ENGINE のコメントを外し、`ink` に変更する
|
||||
config2.yaml から mermaid.engine のコメントを外し、`ink` に変更する
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: ink
|
||||
mermaid:
|
||||
engine: ink
|
||||
```
|
||||
|
||||
注: この方法は pdf エクスポートに対応していません。
|
||||
|
|
@ -166,16 +166,16 @@ ### Docker によるインストール
|
|||
> Windowsでは、"/opt/metagpt"をDockerが作成する権限を持つディレクトリに置き換える必要があります。例えば、"D:\Users\x\metagpt"などです。
|
||||
|
||||
```bash
|
||||
# ステップ 1: metagpt 公式イメージをダウンロードし、config.yaml を準備する
|
||||
# ステップ 1: metagpt 公式イメージをダウンロードし、config2.yaml を準備する
|
||||
docker pull metagpt/metagpt:latest
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # 設定を変更する
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
|
||||
vim /opt/metagpt/config/config2.yaml # 設定を変更する
|
||||
|
||||
# ステップ 2: コンテナで metagpt デモを実行する
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
metagpt "Write a cli snake game"
|
||||
|
|
@ -183,7 +183,7 @@ # ステップ 2: コンテナで metagpt デモを実行する
|
|||
# コンテナを起動し、その中でコマンドを実行することもできます
|
||||
docker run --name metagpt -d \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest
|
||||
|
||||
|
|
@ -194,7 +194,7 @@ # コンテナを起動し、その中でコマンドを実行することもで
|
|||
コマンド `docker run ...` は以下のことを行います:
|
||||
|
||||
- 特権モードで実行し、ブラウザの実行権限を得る
|
||||
- ホスト設定ファイル `/opt/metagpt/config/key.yaml` をコンテナ `/app/metagpt/config/key.yaml` にマップします
|
||||
- ホスト設定ファイル `/opt/metagpt/config/config2.yaml` をコンテナ `/app/metagpt/config/config2.yaml` にマップします
|
||||
- ホストディレクトリ `/opt/metagpt/workspace` をコンテナディレクトリ `/app/metagpt/workspace` にマップするs
|
||||
- デモコマンド `metagpt "Write a cli snake game"` を実行する
|
||||
|
||||
|
|
@ -208,19 +208,14 @@ # また、自分で metagpt イメージを構築することもできます。
|
|||
|
||||
## 設定
|
||||
|
||||
- `OPENAI_API_KEY` を `config/key.yaml / config/config.yaml / env` のいずれかで設定します。
|
||||
- 優先順位は: `config/key.yaml > config/config.yaml > env` の順です。
|
||||
- `api_key` を `~/.metagpt/config2.yaml / config/config2.yaml` のいずれかで設定します。
|
||||
- 優先順位は: `~/.metagpt/config2.yaml > config/config2.yaml > env` の順です。
|
||||
|
||||
```bash
|
||||
# 設定ファイルをコピーし、必要な修正を加える。
|
||||
cp config/config.yaml config/key.yaml
|
||||
cp config/config2.yaml ~/.metagpt/config2.yaml
|
||||
```
|
||||
|
||||
| 変数名 | config/key.yaml | env |
|
||||
| --------------------------------------- | ----------------------------------------- | ----------------------------------------------- |
|
||||
| OPENAI_API_KEY # 自分のキーに置き換える | OPENAI_API_KEY: "sk-..." | export OPENAI_API_KEY="sk-..." |
|
||||
| OPENAI_BASE_URL # オプション | OPENAI_BASE_URL: "https://<YOUR_SITE>/v1" | export OPENAI_BASE_URL="https://<YOUR_SITE>/v1" |
|
||||
|
||||
## チュートリアル: スタートアップの開始
|
||||
|
||||
```shell
|
||||
|
|
|
|||
|
|
@ -9,17 +9,29 @@ ### Support System and version
|
|||
|
||||
### Detail Installation
|
||||
```bash
|
||||
# Step 1: Ensure that NPM is installed on your system. Then install mermaid-js. (If you don't have npm in your computer, please go to the Node.js official website to install Node.js https://nodejs.org/ and then you will have npm tool in your computer.)
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
|
||||
# Step 2: Ensure that Python 3.9+ is installed on your system. You can check this by using:
|
||||
# Step 1: Ensure that Python 3.9+ is installed on your system. You can check this by using:
|
||||
# You can use conda to initialize a new python env
|
||||
# conda create -n metagpt python=3.9
|
||||
# conda activate metagpt
|
||||
python3 --version
|
||||
|
||||
# Step 3: Clone the repository to your local machine, and install it.
|
||||
# Step 2: Clone the repository to your local machine for latest version, and install it.
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip install -e.
|
||||
pip3 install -e . # or pip3 install metagpt # for stable version
|
||||
|
||||
# Step 3: setup your LLM key in the config2.yaml file
|
||||
mkdir ~/.metagpt
|
||||
cp config/config2.yaml ~/.metagpt/config2.yaml
|
||||
vim ~/.metagpt/config2.yaml
|
||||
|
||||
# Step 4: run metagpt cli
|
||||
metagpt "Create a 2048 game in python"
|
||||
|
||||
# Step 5 [Optional]: If you want to save the artifacts like diagrams such as quadrant chart, system designs, sequence flow in the workspace, you can execute the step before Step 3. By default, the framework is compatible, and the entire process can be run completely without executing this step.
|
||||
# If executing, ensure that NPM is installed on your system. Then install mermaid-js. (If you don't have npm in your computer, please go to the Node.js official website to install Node.js https://nodejs.org/ and then you will have npm tool in your computer.)
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
```
|
||||
|
||||
**Note:**
|
||||
|
|
@ -33,11 +45,12 @@ # Step 3: Clone the repository to your local machine, and install it.
|
|||
npm install @mermaid-js/mermaid-cli
|
||||
```
|
||||
|
||||
- don't forget to the configuration for mmdc in config.yml
|
||||
- don't forget to the configuration for mmdc path in config.yml
|
||||
|
||||
```yml
|
||||
PUPPETEER_CONFIG: "./config/puppeteer-config.json"
|
||||
MMDC: "./node_modules/.bin/mmdc"
|
||||
```yaml
|
||||
mermaid:
|
||||
puppeteer_config: "./config/puppeteer-config.json"
|
||||
path: "./node_modules/.bin/mmdc"
|
||||
```
|
||||
|
||||
- if `pip install -e.` fails with error `[Errno 13] Permission denied: '/usr/local/lib/python3.11/dist-packages/test-easy-install-13129.write-test'`, try instead running `pip install -e. --user`
|
||||
|
|
@ -59,12 +72,13 @@ # Step 3: Clone the repository to your local machine, and install it.
|
|||
playwright install --with-deps chromium
|
||||
```
|
||||
|
||||
- **modify `config.yaml`**
|
||||
- **modify `config2.yaml`**
|
||||
|
||||
uncomment MERMAID_ENGINE from config.yaml and change it to `playwright`
|
||||
change mermaid.engine to `playwright`
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: playwright
|
||||
mermaid:
|
||||
engine: playwright
|
||||
```
|
||||
|
||||
- pyppeteer
|
||||
|
|
@ -88,22 +102,24 @@ # Step 3: Clone the repository to your local machine, and install it.
|
|||
pyppeteer-install
|
||||
```
|
||||
|
||||
- **modify `config.yaml`**
|
||||
- **modify `config2.yaml`**
|
||||
|
||||
uncomment MERMAID_ENGINE from config.yaml and change it to `pyppeteer`
|
||||
change mermaid.engine to `pyppeteer`
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: pyppeteer
|
||||
mermaid:
|
||||
engine: pyppeteer
|
||||
```
|
||||
|
||||
- mermaid.ink
|
||||
- **modify `config.yaml`**
|
||||
|
||||
uncomment MERMAID_ENGINE from config.yaml and change it to `ink`
|
||||
- **modify `config2.yaml`**
|
||||
|
||||
change mermaid.engine to `ink`
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: ink
|
||||
mermaid:
|
||||
engine: ink
|
||||
```
|
||||
|
||||
Note: this method does not support pdf export.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -10,17 +10,29 @@ ### 支持的系统和版本
|
|||
### 详细安装
|
||||
|
||||
```bash
|
||||
# 第 1 步:确保您的系统上安装了 NPM。并使用npm安装mermaid-js
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
|
||||
# 第 2 步:确保您的系统上安装了 Python 3.9+。您可以使用以下命令进行检查:
|
||||
# 步骤 1: 确保您的系统安装了 Python 3.9 或更高版本。您可以使用以下命令来检查:
|
||||
# 您可以使用 conda 来初始化一个新的 Python 环境
|
||||
# conda create -n metagpt python=3.9
|
||||
# conda activate metagpt
|
||||
python3 --version
|
||||
|
||||
# 第 3 步:克隆仓库到您的本地机器,并进行安装。
|
||||
# 步骤 2: 克隆仓库到您的本地机器以获取最新版本,并安装它。
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip install -e.
|
||||
pip3 install -e . # 或 pip3 install metagpt # 用于稳定版本
|
||||
|
||||
# 步骤 3: 在 config2.yaml 文件中设置您的 LLM 密钥
|
||||
mkdir ~/.metagpt
|
||||
cp config/config2.yaml ~/.metagpt/config2.yaml
|
||||
vim ~/.metagpt/config2.yaml
|
||||
|
||||
# 步骤 4: 运行 metagpt 命令行界面
|
||||
metagpt "用 python 创建一个 2048 游戏"
|
||||
|
||||
# 步骤 5 [可选]: 如果您想保存诸如象限图、系统设计、序列流等图表作为工作空间的工件,您可以在执行步骤 3 之前执行此步骤。默认情况下,该框架是兼容的,整个过程可以完全不执行此步骤而运行。
|
||||
# 如果执行此步骤,请确保您的系统上安装了 NPM。然后安装 mermaid-js。(如果您的计算机中没有 npm,请访问 Node.js 官方网站 https://nodejs.org/ 安装 Node.js,然后您将在计算机中拥有 npm 工具。)
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
```
|
||||
|
||||
**注意:**
|
||||
|
|
@ -33,11 +45,12 @@ # 第 3 步:克隆仓库到您的本地机器,并进行安装。
|
|||
npm install @mermaid-js/mermaid-cli
|
||||
```
|
||||
|
||||
- 不要忘记在config.yml中为mmdc配置配置,
|
||||
- 不要忘记在config.yml中为mmdc配置
|
||||
|
||||
```yml
|
||||
PUPPETEER_CONFIG: "./config/puppeteer-config.json"
|
||||
MMDC: "./node_modules/.bin/mmdc"
|
||||
mermaid:
|
||||
puppeteer_config: "./config/puppeteer-config.json"
|
||||
path: "./node_modules/.bin/mmdc"
|
||||
```
|
||||
|
||||
- 如果`pip install -e.`失败并显示错误`[Errno 13] Permission denied: '/usr/local/lib/python3.11/dist-packages/test-easy-install-13129.write-test'`,请尝试使用`pip install -e. --user`运行。
|
||||
|
|
|
|||
|
|
@ -3,16 +3,16 @@ ## Docker Installation
|
|||
### Use default MetaGPT image
|
||||
|
||||
```bash
|
||||
# Step 1: Download metagpt official image and prepare config.yaml
|
||||
# Step 1: Download metagpt official image and prepare config2.yaml
|
||||
docker pull metagpt/metagpt:latest
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # Change the config
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
|
||||
vim /opt/metagpt/config/config2.yaml # Change the config
|
||||
|
||||
# Step 2: Run metagpt demo with container
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
metagpt "Write a cli snake game"
|
||||
|
|
@ -20,7 +20,7 @@ # Step 2: Run metagpt demo with container
|
|||
# You can also start a container and execute commands in it
|
||||
docker run --name metagpt -d \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest
|
||||
|
||||
|
|
@ -31,7 +31,7 @@ # You can also start a container and execute commands in it
|
|||
The command `docker run ...` do the following things:
|
||||
|
||||
- Run in privileged mode to have permission to run the browser
|
||||
- Map host configure file `/opt/metagpt/config/key.yaml` to container `/app/metagpt/config/key.yaml`
|
||||
- Map host configure file `/opt/metagpt/config/config2.yaml` to container `/app/metagpt/config/config2.yaml`
|
||||
- Map host directory `/opt/metagpt/workspace` to container `/app/metagpt/workspace`
|
||||
- Execute the demo command `metagpt "Write a cli snake game"`
|
||||
|
||||
|
|
|
|||
|
|
@ -3,16 +3,16 @@ ## Docker安装
|
|||
### 使用MetaGPT镜像
|
||||
|
||||
```bash
|
||||
# 步骤1: 下载metagpt官方镜像并准备好config.yaml
|
||||
# 步骤1: 下载metagpt官方镜像并准备好config2.yaml
|
||||
docker pull metagpt/metagpt:latest
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # 修改配置文件
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
|
||||
vim /opt/metagpt/config/config2.yaml # 修改配置文件
|
||||
|
||||
# 步骤2: 使用容器运行metagpt演示
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
metagpt "Write a cli snake game"
|
||||
|
|
@ -20,7 +20,7 @@ # 步骤2: 使用容器运行metagpt演示
|
|||
# 您也可以启动一个容器并在其中执行命令
|
||||
docker run --name metagpt -d \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest
|
||||
|
||||
|
|
@ -31,7 +31,7 @@ # 您也可以启动一个容器并在其中执行命令
|
|||
`docker run ...`做了以下事情:
|
||||
|
||||
- 以特权模式运行,有权限运行浏览器
|
||||
- 将主机文件 `/opt/metagpt/config/key.yaml` 映射到容器文件 `/app/metagpt/config/key.yaml`
|
||||
- 将主机文件 `/opt/metagpt/config/config2.yaml` 映射到容器文件 `/app/metagpt/config/config2.yaml`
|
||||
- 将主机目录 `/opt/metagpt/workspace` 映射到容器目录 `/app/metagpt/workspace`
|
||||
- 执行示例命令 `metagpt "Write a cli snake game"`
|
||||
|
||||
|
|
|
|||
|
|
@ -2,19 +2,14 @@ ## MetaGPT Usage
|
|||
|
||||
### Configuration
|
||||
|
||||
- Configure your `OPENAI_API_KEY` in any of `config/key.yaml / config/config.yaml / env`
|
||||
- Priority order: `config/key.yaml > config/config.yaml > env`
|
||||
- Configure your `api_key` in any of `~/.metagpt/config2.yaml / config/config2.yaml`
|
||||
- Priority order: `~/.metagpt/config2.yaml > config/config2.yaml`
|
||||
|
||||
```bash
|
||||
# Copy the configuration file and make the necessary modifications.
|
||||
cp config/config.yaml config/key.yaml
|
||||
cp config/config2.yaml ~/.metagpt/config2.yaml
|
||||
```
|
||||
|
||||
| Variable Name | config/key.yaml | env |
|
||||
| ------------------------------------------ | ----------------------------------------- | ----------------------------------------------- |
|
||||
| OPENAI_API_KEY # Replace with your own key | OPENAI_API_KEY: "sk-..." | export OPENAI_API_KEY="sk-..." |
|
||||
| OPENAI_BASE_URL # Optional | OPENAI_BASE_URL: "https://<YOUR_SITE>/v1" | export OPENAI_BASE_URL="https://<YOUR_SITE>/v1" |
|
||||
|
||||
### Initiating a startup
|
||||
|
||||
```shell
|
||||
|
|
@ -39,29 +34,28 @@ ### Preference of Platform or Tool
|
|||
### Usage
|
||||
|
||||
```
|
||||
NAME
|
||||
metagpt - We are a software startup comprised of AI. By investing in us, you are empowering a future filled with limitless possibilities.
|
||||
|
||||
SYNOPSIS
|
||||
metagpt IDEA <flags>
|
||||
|
||||
DESCRIPTION
|
||||
We are a software startup comprised of AI. By investing in us, you are empowering a future filled with limitless possibilities.
|
||||
|
||||
POSITIONAL ARGUMENTS
|
||||
IDEA
|
||||
Type: str
|
||||
Your innovative idea, such as "Creating a snake game."
|
||||
|
||||
FLAGS
|
||||
--investment=INVESTMENT
|
||||
Type: float
|
||||
Default: 3.0
|
||||
As an investor, you have the opportunity to contribute a certain dollar amount to this AI company.
|
||||
--n_round=N_ROUND
|
||||
Type: int
|
||||
Default: 5
|
||||
|
||||
NOTES
|
||||
You can also use flags syntax for POSITIONAL ARGUMENTS
|
||||
Usage: metagpt [OPTIONS] [IDEA]
|
||||
|
||||
Start a new project.
|
||||
|
||||
╭─ Arguments ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
|
||||
│ idea [IDEA] Your innovative idea, such as 'Create a 2048 game.' [default: None] │
|
||||
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
|
||||
╭─ Options ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
|
||||
│ --investment FLOAT Dollar amount to invest in the AI company. [default: 3.0] │
|
||||
│ --n-round INTEGER Number of rounds for the simulation. [default: 5] │
|
||||
│ --code-review --no-code-review Whether to use code review. [default: code-review] │
|
||||
│ --run-tests --no-run-tests Whether to enable QA for adding & running tests. [default: no-run-tests] │
|
||||
│ --implement --no-implement Enable or disable code implementation. [default: implement] │
|
||||
│ --project-name TEXT Unique project name, such as 'game_2048'. │
|
||||
│ --inc --no-inc Incremental mode. Use it to coop with existing repo. [default: no-inc] │
|
||||
│ --project-path TEXT Specify the directory path of the old version project to fulfill the incremental requirements. │
|
||||
│ --reqa-file TEXT Specify the source file name for rewriting the quality assurance code. │
|
||||
│ --max-auto-summarize-code INTEGER The maximum number of times the 'SummarizeCode' action is automatically invoked, with -1 indicating unlimited. This parameter is used for debugging the │
|
||||
│ workflow. │
|
||||
│ [default: 0] │
|
||||
│ --recover-path TEXT recover the project from existing serialized storage [default: None] │
|
||||
│ --init-config --no-init-config Initialize the configuration file for MetaGPT. [default: no-init-config] │
|
||||
│ --help Show this message and exit. │
|
||||
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
|
||||
```
|
||||
|
|
@ -2,19 +2,14 @@ ## MetaGPT 使用
|
|||
|
||||
### 配置
|
||||
|
||||
- 在 `config/key.yaml / config/config.yaml / env` 中配置您的 `OPENAI_API_KEY`
|
||||
- 优先级顺序:`config/key.yaml > config/config.yaml > env`
|
||||
- 在 `~/.metagpt/config2.yaml / config/config2.yaml` 中配置您的 `api_key`
|
||||
- 优先级顺序:`~/.metagpt/config2.yaml > config/config2.yaml`
|
||||
|
||||
```bash
|
||||
# 复制配置文件并进行必要的修改
|
||||
cp config/config.yaml config/key.yaml
|
||||
cp config/config2.yaml ~/.metagpt/config2.yaml
|
||||
```
|
||||
|
||||
| 变量名 | config/key.yaml | env |
|
||||
| ----------------------------------- | ----------------------------------------- | ----------------------------------------------- |
|
||||
| OPENAI_API_KEY # 用您自己的密钥替换 | OPENAI_API_KEY: "sk-..." | export OPENAI_API_KEY="sk-..." |
|
||||
| OPENAI_BASE_URL # 可选 | OPENAI_BASE_URL: "https://<YOUR_SITE>/v1" | export OPENAI_BASE_URL="https://<YOUR_SITE>/v1" |
|
||||
|
||||
### 示例:启动一个创业公司
|
||||
|
||||
```shell
|
||||
|
|
@ -35,29 +30,28 @@ ### 平台或工具的倾向性
|
|||
### 使用
|
||||
|
||||
```
|
||||
名称
|
||||
metagpt - 我们是一家AI软件创业公司。通过投资我们,您将赋能一个充满无限可能的未来。
|
||||
|
||||
概要
|
||||
metagpt IDEA <flags>
|
||||
|
||||
描述
|
||||
我们是一家AI软件创业公司。通过投资我们,您将赋能一个充满无限可能的未来。
|
||||
|
||||
位置参数
|
||||
IDEA
|
||||
类型: str
|
||||
您的创新想法,例如"写一个命令行贪吃蛇。"
|
||||
|
||||
标志
|
||||
--investment=INVESTMENT
|
||||
类型: float
|
||||
默认值: 3.0
|
||||
作为投资者,您有机会向这家AI公司投入一定的美元金额。
|
||||
--n_round=N_ROUND
|
||||
类型: int
|
||||
默认值: 5
|
||||
|
||||
备注
|
||||
您也可以用`标志`的语法,来处理`位置参数`
|
||||
Usage: metagpt [OPTIONS] [IDEA]
|
||||
|
||||
Start a new project.
|
||||
|
||||
╭─ Arguments ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
|
||||
│ idea [IDEA] Your innovative idea, such as 'Create a 2048 game.' [default: None] │
|
||||
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
|
||||
╭─ Options ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
|
||||
│ --investment FLOAT Dollar amount to invest in the AI company. [default: 3.0] │
|
||||
│ --n-round INTEGER Number of rounds for the simulation. [default: 5] │
|
||||
│ --code-review --no-code-review Whether to use code review. [default: code-review] │
|
||||
│ --run-tests --no-run-tests Whether to enable QA for adding & running tests. [default: no-run-tests] │
|
||||
│ --implement --no-implement Enable or disable code implementation. [default: implement] │
|
||||
│ --project-name TEXT Unique project name, such as 'game_2048'. │
|
||||
│ --inc --no-inc Incremental mode. Use it to coop with existing repo. [default: no-inc] │
|
||||
│ --project-path TEXT Specify the directory path of the old version project to fulfill the incremental requirements. │
|
||||
│ --reqa-file TEXT Specify the source file name for rewriting the quality assurance code. │
|
||||
│ --max-auto-summarize-code INTEGER The maximum number of times the 'SummarizeCode' action is automatically invoked, with -1 indicating unlimited. This parameter is used for debugging the │
|
||||
│ workflow. │
|
||||
│ [default: 0] │
|
||||
│ --recover-path TEXT recover the project from existing serialized storage [default: None] │
|
||||
│ --init-config --no-init-config Initialize the configuration file for MetaGPT. [default: no-init-config] │
|
||||
│ --help Show this message and exit. │
|
||||
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
|
||||
```
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ Author: garylin2099
|
|||
import re
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.config2 import config
|
||||
from metagpt.const import METAGPT_ROOT
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles import Role
|
||||
|
|
@ -48,8 +48,8 @@ class CreateAgent(Action):
|
|||
pattern = r"```python(.*)```"
|
||||
match = re.search(pattern, rsp, re.DOTALL)
|
||||
code_text = match.group(1) if match else ""
|
||||
CONFIG.workspace_path.mkdir(parents=True, exist_ok=True)
|
||||
new_file = CONFIG.workspace_path / "agent_created_agent.py"
|
||||
config.workspace.path.mkdir(parents=True, exist_ok=True)
|
||||
new_file = config.workspace.path / "agent_created_agent.py"
|
||||
new_file.write_text(code_text)
|
||||
return code_text
|
||||
|
||||
|
|
@ -61,7 +61,7 @@ class AgentCreator(Role):
|
|||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self._init_actions([CreateAgent])
|
||||
self.set_actions([CreateAgent])
|
||||
|
||||
async def _act(self) -> Message:
|
||||
logger.info(f"{self._setting}: to do {self.rc.todo}({self.rc.todo.name})")
|
||||
|
|
|
|||
|
|
@ -57,7 +57,7 @@ class SimpleCoder(Role):
|
|||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self._init_actions([SimpleWriteCode])
|
||||
self.set_actions([SimpleWriteCode])
|
||||
|
||||
async def _act(self) -> Message:
|
||||
logger.info(f"{self._setting}: to do {self.rc.todo}({self.rc.todo.name})")
|
||||
|
|
@ -76,7 +76,7 @@ class RunnableCoder(Role):
|
|||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self._init_actions([SimpleWriteCode, SimpleRunCode])
|
||||
self.set_actions([SimpleWriteCode, SimpleRunCode])
|
||||
self._set_react_mode(react_mode=RoleReactMode.BY_ORDER.value)
|
||||
|
||||
async def _act(self) -> Message:
|
||||
|
|
|
|||
|
|
@ -46,7 +46,7 @@ class SimpleCoder(Role):
|
|||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self._watch([UserRequirement])
|
||||
self._init_actions([SimpleWriteCode])
|
||||
self.set_actions([SimpleWriteCode])
|
||||
|
||||
|
||||
class SimpleWriteTest(Action):
|
||||
|
|
@ -75,7 +75,7 @@ class SimpleTester(Role):
|
|||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self._init_actions([SimpleWriteTest])
|
||||
self.set_actions([SimpleWriteTest])
|
||||
# self._watch([SimpleWriteCode])
|
||||
self._watch([SimpleWriteCode, SimpleWriteReview]) # feel free to try this too
|
||||
|
||||
|
|
@ -114,7 +114,7 @@ class SimpleReviewer(Role):
|
|||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self._init_actions([SimpleWriteReview])
|
||||
self.set_actions([SimpleWriteReview])
|
||||
self._watch([SimpleWriteTest])
|
||||
|
||||
|
||||
|
|
|
|||
22
examples/crawl_webpage.py
Normal file
22
examples/crawl_webpage.py
Normal file
|
|
@ -0,0 +1,22 @@
|
|||
# -*- encoding: utf-8 -*-
|
||||
"""
|
||||
@Date : 2024/01/24 15:11:27
|
||||
@Author : orange-crow
|
||||
@File : crawl_webpage.py
|
||||
"""
|
||||
|
||||
from metagpt.roles.ci.code_interpreter import CodeInterpreter
|
||||
|
||||
|
||||
async def main():
|
||||
prompt = """Get data from `paperlist` table in https://papercopilot.com/statistics/iclr-statistics/iclr-2024-statistics/,
|
||||
and save it to a csv file. paper title must include `multiagent` or `large language model`. *notice: print key variables*"""
|
||||
ci = CodeInterpreter(goal=prompt, use_tools=True)
|
||||
|
||||
await ci.run(prompt)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import asyncio
|
||||
|
||||
asyncio.run(main())
|
||||
77
examples/dalle_gpt4v_agent.py
Normal file
77
examples/dalle_gpt4v_agent.py
Normal file
|
|
@ -0,0 +1,77 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : use gpt4v to improve prompt and draw image with dall-e-3
|
||||
|
||||
"""set `model: "gpt-4-vision-preview"` in `config2.yaml` first"""
|
||||
|
||||
import asyncio
|
||||
|
||||
from PIL import Image
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles.role import Role
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.common import encode_image
|
||||
|
||||
|
||||
class GenAndImproveImageAction(Action):
|
||||
save_image: bool = True
|
||||
|
||||
async def generate_image(self, prompt: str) -> Image:
|
||||
imgs = await self.llm.gen_image(model="dall-e-3", prompt=prompt)
|
||||
return imgs[0]
|
||||
|
||||
async def refine_prompt(self, old_prompt: str, image: Image) -> str:
|
||||
msg = (
|
||||
f"You are a creative painter, with the given generated image and old prompt: {old_prompt}, "
|
||||
f"please refine the prompt and generate new one. Just output the new prompt."
|
||||
)
|
||||
b64_img = encode_image(image)
|
||||
new_prompt = await self.llm.aask(msg=msg, images=[b64_img])
|
||||
return new_prompt
|
||||
|
||||
async def evaluate_images(self, old_prompt: str, images: list[Image]) -> str:
|
||||
msg = (
|
||||
"With the prompt and two generated image, to judge if the second one is better than the first one. "
|
||||
"If so, just output True else output False"
|
||||
)
|
||||
b64_imgs = [encode_image(img) for img in images]
|
||||
res = await self.llm.aask(msg=msg, images=b64_imgs)
|
||||
return res
|
||||
|
||||
async def run(self, messages: list[Message]) -> str:
|
||||
prompt = messages[-1].content
|
||||
|
||||
old_img: Image = await self.generate_image(prompt)
|
||||
new_prompt = await self.refine_prompt(old_prompt=prompt, image=old_img)
|
||||
logger.info(f"original prompt: {prompt}")
|
||||
logger.info(f"refined prompt: {new_prompt}")
|
||||
new_img: Image = await self.generate_image(new_prompt)
|
||||
if self.save_image:
|
||||
old_img.save("./img_by-dall-e_old.png")
|
||||
new_img.save("./img_by-dall-e_new.png")
|
||||
res = await self.evaluate_images(old_prompt=prompt, images=[old_img, new_img])
|
||||
opinion = f"The second generated image is better than the first one: {res}"
|
||||
logger.info(f"evaluate opinion: {opinion}")
|
||||
return opinion
|
||||
|
||||
|
||||
class Painter(Role):
|
||||
name: str = "MaLiang"
|
||||
profile: str = "Painter"
|
||||
goal: str = "to generate fine painting"
|
||||
|
||||
def __init__(self, **data):
|
||||
super().__init__(**data)
|
||||
|
||||
self.set_actions([GenAndImproveImageAction])
|
||||
|
||||
|
||||
async def main():
|
||||
role = Painter()
|
||||
await role.run(with_message="a girl with flowers")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
|
|
@ -49,7 +49,7 @@ class Debator(Role):
|
|||
|
||||
def __init__(self, **data: Any):
|
||||
super().__init__(**data)
|
||||
self._init_actions([SpeakAloud])
|
||||
self.set_actions([SpeakAloud])
|
||||
self._watch([UserRequirement, SpeakAloud])
|
||||
|
||||
async def _observe(self) -> int:
|
||||
|
|
|
|||
|
|
@ -13,7 +13,9 @@ from metagpt.roles import Role
|
|||
from metagpt.team import Team
|
||||
|
||||
action1 = Action(name="AlexSay", instruction="Express your opinion with emotion and don't repeat it")
|
||||
action1.llm.model = "gpt-4-1106-preview"
|
||||
action2 = Action(name="BobSay", instruction="Express your opinion with emotion and don't repeat it")
|
||||
action2.llm.model = "gpt-3.5-turbo-1106"
|
||||
alex = Role(name="Alex", profile="Democratic candidate", goal="Win the election", actions=[action1], watch=[action2])
|
||||
bob = Role(name="Bob", profile="Republican candidate", goal="Win the election", actions=[action2], watch=[action1])
|
||||
env = Environment(desc="US election live broadcast")
|
||||
|
|
|
|||
Binary file not shown.
Binary file not shown.
26
examples/imitate_webpage.py
Normal file
26
examples/imitate_webpage.py
Normal file
|
|
@ -0,0 +1,26 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/01/15
|
||||
@Author : mannaandpoem
|
||||
@File : imitate_webpage.py
|
||||
"""
|
||||
from metagpt.roles.ci.code_interpreter import CodeInterpreter
|
||||
|
||||
|
||||
async def main():
|
||||
web_url = "https://pytorch.org/"
|
||||
prompt = f"""This is a URL of webpage: '{web_url}' .
|
||||
Firstly, utilize Selenium and WebDriver for rendering.
|
||||
Secondly, convert image to a webpage including HTML, CSS and JS in one go.
|
||||
Finally, save webpage in a text file.
|
||||
Note: All required dependencies and environments have been fully installed and configured."""
|
||||
ci = CodeInterpreter(goal=prompt, use_tools=True)
|
||||
|
||||
await ci.run(prompt)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import asyncio
|
||||
|
||||
asyncio.run(main())
|
||||
|
|
@ -6,9 +6,11 @@
|
|||
@File : llm_hello_world.py
|
||||
"""
|
||||
import asyncio
|
||||
from pathlib import Path
|
||||
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.utils.common import encode_image
|
||||
|
||||
|
||||
async def main():
|
||||
|
|
@ -27,6 +29,12 @@ async def main():
|
|||
if hasattr(llm, "completion"):
|
||||
logger.info(llm.completion(hello_msg))
|
||||
|
||||
# check if the configured llm supports llm-vision capacity. If not, it will throw a error
|
||||
invoice_path = Path(__file__).parent.joinpath("..", "tests", "data", "invoices", "invoice-2.png")
|
||||
img_base64 = encode_image(invoice_path)
|
||||
res = await llm.aask(msg="if this is a invoice, just return True else return False", images=[img_base64])
|
||||
assert "true" in res.lower()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
|
|
|
|||
21
examples/sd_tool_usage.py
Normal file
21
examples/sd_tool_usage.py
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
# -*- coding: utf-8 -*-
|
||||
# @Date : 1/11/2024 7:06 PM
|
||||
# @Author : stellahong (stellahong@fuzhi.ai)
|
||||
# @Desc :
|
||||
import asyncio
|
||||
|
||||
from metagpt.roles.ci.code_interpreter import CodeInterpreter
|
||||
|
||||
|
||||
async def main(requirement: str = ""):
|
||||
code_interpreter = CodeInterpreter(use_tools=True, goal=requirement)
|
||||
await code_interpreter.run(requirement)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
sd_url = "http://your.sd.service.ip:port"
|
||||
requirement = (
|
||||
f"I want to generate an image of a beautiful girl using the stable diffusion text2image tool, sd_url={sd_url}"
|
||||
)
|
||||
|
||||
asyncio.run(main(requirement))
|
||||
|
|
@ -8,7 +8,7 @@ import asyncio
|
|||
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.config2 import config
|
||||
from metagpt.const import DATA_PATH, EXAMPLE_PATH
|
||||
from metagpt.document_store import FaissStore
|
||||
from metagpt.logs import logger
|
||||
|
|
@ -16,7 +16,8 @@ from metagpt.roles import Sales
|
|||
|
||||
|
||||
def get_store():
|
||||
embedding = OpenAIEmbeddings(openai_api_key=CONFIG.openai_api_key, openai_api_base=CONFIG.openai_base_url)
|
||||
llm = config.get_openai_llm()
|
||||
embedding = OpenAIEmbeddings(openai_api_key=llm.api_key, openai_api_base=llm.base_url)
|
||||
return FaissStore(DATA_PATH / "example.json", embedding=embedding)
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -5,17 +5,20 @@
|
|||
import asyncio
|
||||
|
||||
from metagpt.roles import Searcher
|
||||
from metagpt.tools import SearchEngineType
|
||||
from metagpt.tools.search_engine import SearchEngine, SearchEngineType
|
||||
|
||||
|
||||
async def main():
|
||||
question = "What are the most interesting human facts?"
|
||||
kwargs = {"api_key": "", "cse_id": "", "proxy": None}
|
||||
# Serper API
|
||||
# await Searcher(engine=SearchEngineType.SERPER_GOOGLE).run(question)
|
||||
# await Searcher(search_engine=SearchEngine(engine=SearchEngineType.SERPER_GOOGLE, **kwargs)).run(question)
|
||||
# SerpAPI
|
||||
await Searcher(engine=SearchEngineType.SERPAPI_GOOGLE).run(question)
|
||||
# await Searcher(search_engine=SearchEngine(engine=SearchEngineType.SERPAPI_GOOGLE, **kwargs)).run(question)
|
||||
# Google API
|
||||
# await Searcher(engine=SearchEngineType.DIRECT_GOOGLE).run(question)
|
||||
# await Searcher(search_engine=SearchEngine(engine=SearchEngineType.DIRECT_GOOGLE, **kwargs)).run(question)
|
||||
# DDG API
|
||||
await Searcher(search_engine=SearchEngine(engine=SearchEngineType.DUCK_DUCK_GO, **kwargs)).run(question)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
|
|
|||
49
examples/write_novel.py
Normal file
49
examples/write_novel.py
Normal file
|
|
@ -0,0 +1,49 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/2/1 12:01
|
||||
@Author : alexanderwu
|
||||
@File : write_novel.py
|
||||
"""
|
||||
import asyncio
|
||||
from typing import List
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
from metagpt.llm import LLM
|
||||
|
||||
|
||||
class Novel(BaseModel):
|
||||
name: str = Field(default="The Lord of the Rings", description="The name of the novel.")
|
||||
user_group: str = Field(default="...", description="The user group of the novel.")
|
||||
outlines: List[str] = Field(
|
||||
default=["Chapter 1: ...", "Chapter 2: ...", "Chapter 3: ..."],
|
||||
description="The outlines of the novel. No more than 10 chapters.",
|
||||
)
|
||||
background: str = Field(default="...", description="The background of the novel.")
|
||||
character_names: List[str] = Field(default=["Frodo", "Gandalf", "Sauron"], description="The characters.")
|
||||
conflict: str = Field(default="...", description="The conflict of the characters.")
|
||||
plot: str = Field(default="...", description="The plot of the novel.")
|
||||
ending: str = Field(default="...", description="The ending of the novel.")
|
||||
|
||||
|
||||
class Chapter(BaseModel):
|
||||
name: str = Field(default="Chapter 1", description="The name of the chapter.")
|
||||
content: str = Field(default="...", description="The content of the chapter. No more than 1000 words.")
|
||||
|
||||
|
||||
async def generate_novel():
|
||||
instruction = (
|
||||
"Write a novel named 'Harry Potter in The Lord of the Rings'. "
|
||||
"Fill the empty nodes with your own ideas. Be creative! Use your own words!"
|
||||
"I will tip you $100,000 if you write a good novel."
|
||||
)
|
||||
novel_node = await ActionNode.from_pydantic(Novel).fill(context=instruction, llm=LLM())
|
||||
chap_node = await ActionNode.from_pydantic(Chapter).fill(
|
||||
context=f"### instruction\n{instruction}\n### novel\n{novel_node.content}", llm=LLM()
|
||||
)
|
||||
print(chap_node.content)
|
||||
|
||||
|
||||
asyncio.run(generate_novel())
|
||||
|
|
@ -22,6 +22,9 @@ from metagpt.actions.write_code_review import WriteCodeReview
|
|||
from metagpt.actions.write_prd import WritePRD
|
||||
from metagpt.actions.write_prd_review import WritePRDReview
|
||||
from metagpt.actions.write_test import WriteTest
|
||||
from metagpt.actions.ci.execute_nb_code import ExecuteNbCode
|
||||
from metagpt.actions.ci.write_analysis_code import WriteCodeWithoutTools, WriteCodeWithTools
|
||||
from metagpt.actions.ci.write_plan import WritePlan
|
||||
|
||||
|
||||
class ActionType(Enum):
|
||||
|
|
@ -42,6 +45,10 @@ class ActionType(Enum):
|
|||
COLLECT_LINKS = CollectLinks
|
||||
WEB_BROWSE_AND_SUMMARIZE = WebBrowseAndSummarize
|
||||
CONDUCT_RESEARCH = ConductResearch
|
||||
EXECUTE_NB_CODE = ExecuteNbCode
|
||||
WRITE_CODE_WITHOUT_TOOLS = WriteCodeWithoutTools
|
||||
WRITE_CODE_WITH_TOOLS = WriteCodeWithTools
|
||||
WRITE_PLAN = WritePlan
|
||||
|
||||
|
||||
__all__ = [
|
||||
|
|
|
|||
|
|
@ -10,41 +10,67 @@ from __future__ import annotations
|
|||
|
||||
from typing import Optional, Union
|
||||
|
||||
from pydantic import ConfigDict, Field, model_validator
|
||||
from pydantic import BaseModel, ConfigDict, Field, model_validator
|
||||
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.provider.base_llm import BaseLLM
|
||||
from metagpt.context_mixin import ContextMixin
|
||||
from metagpt.schema import (
|
||||
CodePlanAndChangeContext,
|
||||
CodeSummarizeContext,
|
||||
CodingContext,
|
||||
RunCodeContext,
|
||||
SerializationMixin,
|
||||
TestingContext,
|
||||
)
|
||||
from metagpt.utils.project_repo import ProjectRepo
|
||||
|
||||
|
||||
class Action(SerializationMixin, is_polymorphic_base=True):
|
||||
model_config = ConfigDict(arbitrary_types_allowed=True, exclude=["llm"])
|
||||
class Action(SerializationMixin, ContextMixin, BaseModel):
|
||||
model_config = ConfigDict(arbitrary_types_allowed=True)
|
||||
|
||||
name: str = ""
|
||||
llm: BaseLLM = Field(default_factory=LLM, exclude=True)
|
||||
context: Union[dict, CodingContext, CodeSummarizeContext, TestingContext, RunCodeContext, str, None] = ""
|
||||
i_context: Union[
|
||||
dict, CodingContext, CodeSummarizeContext, TestingContext, RunCodeContext, CodePlanAndChangeContext, str, None
|
||||
] = ""
|
||||
prefix: str = "" # aask*时会加上prefix,作为system_message
|
||||
desc: str = "" # for skill manager
|
||||
node: ActionNode = Field(default=None, exclude=True)
|
||||
|
||||
@property
|
||||
def repo(self) -> ProjectRepo:
|
||||
if not self.context.repo:
|
||||
self.context.repo = ProjectRepo(self.context.git_repo)
|
||||
return self.context.repo
|
||||
|
||||
@property
|
||||
def prompt_schema(self):
|
||||
return self.config.prompt_schema
|
||||
|
||||
@property
|
||||
def project_name(self):
|
||||
return self.config.project_name
|
||||
|
||||
@project_name.setter
|
||||
def project_name(self, value):
|
||||
self.config.project_name = value
|
||||
|
||||
@property
|
||||
def project_path(self):
|
||||
return self.config.project_path
|
||||
|
||||
@model_validator(mode="before")
|
||||
@classmethod
|
||||
def set_name_if_empty(cls, values):
|
||||
if "name" not in values or not values["name"]:
|
||||
values["name"] = cls.__name__
|
||||
return values
|
||||
|
||||
@model_validator(mode="before")
|
||||
@classmethod
|
||||
def _init_with_instruction(cls, values):
|
||||
if "instruction" in values:
|
||||
name = values["name"]
|
||||
i = values["instruction"]
|
||||
i = values.pop("instruction")
|
||||
values["node"] = ActionNode(key=name, expected_type=str, instruction=i, example="", schema="raw")
|
||||
return values
|
||||
|
||||
|
|
|
|||
49
metagpt/actions/action_graph.py
Normal file
49
metagpt/actions/action_graph.py
Normal file
|
|
@ -0,0 +1,49 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/30 13:52
|
||||
@Author : alexanderwu
|
||||
@File : action_graph.py
|
||||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
# from metagpt.actions.action_node import ActionNode
|
||||
|
||||
|
||||
class ActionGraph:
|
||||
"""ActionGraph: a directed graph to represent the dependency between actions."""
|
||||
|
||||
def __init__(self):
|
||||
self.nodes = {}
|
||||
self.edges = {}
|
||||
self.execution_order = []
|
||||
|
||||
def add_node(self, node):
|
||||
"""Add a node to the graph"""
|
||||
self.nodes[node.key] = node
|
||||
|
||||
def add_edge(self, from_node: "ActionNode", to_node: "ActionNode"):
|
||||
"""Add an edge to the graph"""
|
||||
if from_node.key not in self.edges:
|
||||
self.edges[from_node.key] = []
|
||||
self.edges[from_node.key].append(to_node.key)
|
||||
from_node.add_next(to_node)
|
||||
to_node.add_prev(from_node)
|
||||
|
||||
def topological_sort(self):
|
||||
"""Topological sort the graph"""
|
||||
visited = set()
|
||||
stack = []
|
||||
|
||||
def visit(k):
|
||||
if k not in visited:
|
||||
visited.add(k)
|
||||
if k in self.edges:
|
||||
for next_node in self.edges[k]:
|
||||
visit(next_node)
|
||||
stack.insert(0, k)
|
||||
|
||||
for key in self.nodes:
|
||||
visit(key)
|
||||
|
||||
self.execution_order = stack
|
||||
|
|
@ -9,23 +9,37 @@ NOTE: You should use typing.List instead of list to do type annotation. Because
|
|||
we can use typing to extract the type of the node, but we cannot use built-in list to extract.
|
||||
"""
|
||||
import json
|
||||
from typing import Any, Dict, List, Optional, Tuple, Type
|
||||
import typing
|
||||
from enum import Enum
|
||||
from typing import Any, Dict, List, Optional, Tuple, Type, Union
|
||||
|
||||
from pydantic import BaseModel, create_model, model_validator
|
||||
from pydantic import BaseModel, Field, create_model, model_validator
|
||||
from tenacity import retry, stop_after_attempt, wait_random_exponential
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.actions.action_outcls_registry import register_action_outcls
|
||||
from metagpt.llm import BaseLLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.provider.postprocess.llm_output_postprocess import llm_output_postprocess
|
||||
from metagpt.utils.common import OutputParser, general_after_log
|
||||
from metagpt.utils.human_interaction import HumanInteraction
|
||||
|
||||
|
||||
class ReviewMode(Enum):
|
||||
HUMAN = "human"
|
||||
AUTO = "auto"
|
||||
|
||||
|
||||
class ReviseMode(Enum):
|
||||
HUMAN = "human" # human revise
|
||||
HUMAN_REVIEW = "human_review" # human-review and auto-revise
|
||||
AUTO = "auto" # auto-review and auto-revise
|
||||
|
||||
|
||||
TAG = "CONTENT"
|
||||
|
||||
LANGUAGE_CONSTRAINT = "Language: Please use the same language as Human INPUT."
|
||||
FORMAT_CONSTRAINT = f"Format: output wrapped inside [{TAG}][/{TAG}] like format example, nothing else."
|
||||
|
||||
|
||||
SIMPLE_TEMPLATE = """
|
||||
## context
|
||||
{context}
|
||||
|
|
@ -45,6 +59,58 @@ SIMPLE_TEMPLATE = """
|
|||
Follow instructions of nodes, generate output and make sure it follows the format example.
|
||||
"""
|
||||
|
||||
REVIEW_TEMPLATE = """
|
||||
## context
|
||||
Compare the key's value of nodes_output and the corresponding requirements one by one. If a key's value that does not match the requirement is found, provide the comment content on how to modify it. No output is required for matching keys.
|
||||
|
||||
### nodes_output
|
||||
{nodes_output}
|
||||
|
||||
-----
|
||||
|
||||
## format example
|
||||
[{tag}]
|
||||
{{
|
||||
"key1": "comment1",
|
||||
"key2": "comment2",
|
||||
"keyn": "commentn"
|
||||
}}
|
||||
[/{tag}]
|
||||
|
||||
## nodes: "<node>: <type> # <instruction>"
|
||||
- key1: <class \'str\'> # the first key name of mismatch key
|
||||
- key2: <class \'str\'> # the second key name of mismatch key
|
||||
- keyn: <class \'str\'> # the last key name of mismatch key
|
||||
|
||||
## constraint
|
||||
{constraint}
|
||||
|
||||
## action
|
||||
Follow format example's {prompt_schema} format, generate output and make sure it follows the format example.
|
||||
"""
|
||||
|
||||
REVISE_TEMPLATE = """
|
||||
## context
|
||||
change the nodes_output key's value to meet its comment and no need to add extra comment.
|
||||
|
||||
### nodes_output
|
||||
{nodes_output}
|
||||
|
||||
-----
|
||||
|
||||
## format example
|
||||
{example}
|
||||
|
||||
## nodes: "<node>: <type> # <instruction>"
|
||||
{instruction}
|
||||
|
||||
## constraint
|
||||
{constraint}
|
||||
|
||||
## action
|
||||
Follow format example's {prompt_schema} format, generate output and make sure it follows the format example.
|
||||
"""
|
||||
|
||||
|
||||
def dict_to_markdown(d, prefix="- ", kv_sep="\n", postfix="\n"):
|
||||
markdown_str = ""
|
||||
|
|
@ -65,6 +131,8 @@ class ActionNode:
|
|||
|
||||
# Action Input
|
||||
key: str # Product Requirement / File list / Code
|
||||
func: typing.Callable # 与节点相关联的函数或LLM调用
|
||||
params: Dict[str, Type] # 输入参数的字典,键为参数名,值为参数类型
|
||||
expected_type: Type # such as str / int / float etc.
|
||||
# context: str # everything in the history.
|
||||
instruction: str # the instructions should be followed.
|
||||
|
|
@ -74,6 +142,10 @@ class ActionNode:
|
|||
content: str
|
||||
instruct_content: BaseModel
|
||||
|
||||
# For ActionGraph
|
||||
prevs: List["ActionNode"] # previous nodes
|
||||
nexts: List["ActionNode"] # next nodes
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
key: str,
|
||||
|
|
@ -91,6 +163,8 @@ class ActionNode:
|
|||
self.content = content
|
||||
self.children = children if children is not None else {}
|
||||
self.schema = schema
|
||||
self.prevs = []
|
||||
self.nexts = []
|
||||
|
||||
def __str__(self):
|
||||
return (
|
||||
|
|
@ -101,10 +175,21 @@ class ActionNode:
|
|||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
def add_prev(self, node: "ActionNode"):
|
||||
"""增加前置ActionNode"""
|
||||
self.prevs.append(node)
|
||||
|
||||
def add_next(self, node: "ActionNode"):
|
||||
"""增加后置ActionNode"""
|
||||
self.nexts.append(node)
|
||||
|
||||
def add_child(self, node: "ActionNode"):
|
||||
"""增加子ActionNode"""
|
||||
self.children[node.key] = node
|
||||
|
||||
def get_child(self, key: str) -> Union["ActionNode", None]:
|
||||
return self.children.get(key, None)
|
||||
|
||||
def add_children(self, nodes: List["ActionNode"]):
|
||||
"""批量增加子ActionNode"""
|
||||
for node in nodes:
|
||||
|
|
@ -117,24 +202,38 @@ class ActionNode:
|
|||
obj.add_children(nodes)
|
||||
return obj
|
||||
|
||||
def get_children_mapping(self, exclude=None) -> Dict[str, Tuple[Type, Any]]:
|
||||
"""获得子ActionNode的字典,以key索引"""
|
||||
def _get_children_mapping(self, exclude=None) -> Dict[str, Any]:
|
||||
"""获得子ActionNode的字典,以key索引,支持多级结构。"""
|
||||
exclude = exclude or []
|
||||
return {k: (v.expected_type, ...) for k, v in self.children.items() if k not in exclude}
|
||||
|
||||
def get_self_mapping(self) -> Dict[str, Tuple[Type, Any]]:
|
||||
def _get_mapping(node: "ActionNode") -> Dict[str, Any]:
|
||||
mapping = {}
|
||||
for key, child in node.children.items():
|
||||
if key in exclude:
|
||||
continue
|
||||
# 对于嵌套的子节点,递归调用 _get_mapping
|
||||
if child.children:
|
||||
mapping[key] = _get_mapping(child)
|
||||
else:
|
||||
mapping[key] = (child.expected_type, Field(default=child.example, description=child.instruction))
|
||||
return mapping
|
||||
|
||||
return _get_mapping(self)
|
||||
|
||||
def _get_self_mapping(self) -> Dict[str, Tuple[Type, Any]]:
|
||||
"""get self key: type mapping"""
|
||||
return {self.key: (self.expected_type, ...)}
|
||||
|
||||
def get_mapping(self, mode="children", exclude=None) -> Dict[str, Tuple[Type, Any]]:
|
||||
"""get key: type mapping under mode"""
|
||||
if mode == "children" or (mode == "auto" and self.children):
|
||||
return self.get_children_mapping(exclude=exclude)
|
||||
return {} if exclude and self.key in exclude else self.get_self_mapping()
|
||||
return self._get_children_mapping(exclude=exclude)
|
||||
return {} if exclude and self.key in exclude else self._get_self_mapping()
|
||||
|
||||
@classmethod
|
||||
@register_action_outcls
|
||||
def create_model_class(cls, class_name: str, mapping: Dict[str, Tuple[Type, Any]]):
|
||||
"""基于pydantic v1的模型动态生成,用来检验结果类型正确性"""
|
||||
"""基于pydantic v2的模型动态生成,用来检验结果类型正确性"""
|
||||
|
||||
def check_fields(cls, values):
|
||||
required_fields = set(mapping.keys())
|
||||
|
|
@ -149,42 +248,85 @@ class ActionNode:
|
|||
|
||||
validators = {"check_missing_fields_validator": model_validator(mode="before")(check_fields)}
|
||||
|
||||
new_class = create_model(class_name, __validators__=validators, **mapping)
|
||||
new_fields = {}
|
||||
for field_name, field_value in mapping.items():
|
||||
if isinstance(field_value, dict):
|
||||
# 对于嵌套结构,递归创建模型类
|
||||
nested_class_name = f"{class_name}_{field_name}"
|
||||
nested_class = cls.create_model_class(nested_class_name, field_value)
|
||||
new_fields[field_name] = (nested_class, ...)
|
||||
else:
|
||||
new_fields[field_name] = field_value
|
||||
|
||||
new_class = create_model(class_name, __validators__=validators, **new_fields)
|
||||
return new_class
|
||||
|
||||
def create_children_class(self, exclude=None):
|
||||
def create_class(self, mode: str = "auto", class_name: str = None, exclude=None):
|
||||
class_name = class_name if class_name else f"{self.key}_AN"
|
||||
mapping = self.get_mapping(mode=mode, exclude=exclude)
|
||||
return self.create_model_class(class_name, mapping)
|
||||
|
||||
def _create_children_class(self, exclude=None):
|
||||
"""使用object内有的字段直接生成model_class"""
|
||||
class_name = f"{self.key}_AN"
|
||||
mapping = self.get_children_mapping(exclude=exclude)
|
||||
mapping = self._get_children_mapping(exclude=exclude)
|
||||
return self.create_model_class(class_name, mapping)
|
||||
|
||||
def to_dict(self, format_func=None, mode="auto", exclude=None) -> Dict:
|
||||
"""将当前节点与子节点都按照node: format的格式组织成字典"""
|
||||
nodes = self._to_dict(format_func=format_func, mode=mode, exclude=exclude)
|
||||
if not isinstance(nodes, dict):
|
||||
nodes = {self.key: nodes}
|
||||
return nodes
|
||||
|
||||
# 如果没有提供格式化函数,使用默认的格式化方式
|
||||
def _to_dict(self, format_func=None, mode="auto", exclude=None) -> Dict:
|
||||
"""将当前节点与子节点都按照node: format的格式组织成字典"""
|
||||
|
||||
# 如果没有提供格式化函数,则使用默认的格式化函数
|
||||
if format_func is None:
|
||||
format_func = lambda node: f"{node.instruction}"
|
||||
format_func = lambda node: node.instruction
|
||||
|
||||
# 使用提供的格式化函数来格式化当前节点的值
|
||||
formatted_value = format_func(self)
|
||||
|
||||
# 创建当前节点的键值对
|
||||
if mode == "children" or (mode == "auto" and self.children):
|
||||
node_dict = {}
|
||||
if (mode == "children" or mode == "auto") and self.children:
|
||||
node_value = {}
|
||||
else:
|
||||
node_dict = {self.key: formatted_value}
|
||||
node_value = formatted_value
|
||||
|
||||
if mode == "root":
|
||||
return node_dict
|
||||
return {self.key: node_value}
|
||||
|
||||
# 遍历子节点并递归调用 to_dict 方法
|
||||
# 递归处理子节点
|
||||
exclude = exclude or []
|
||||
for _, child_node in self.children.items():
|
||||
if child_node.key in exclude:
|
||||
for child_key, child_node in self.children.items():
|
||||
if child_key in exclude:
|
||||
continue
|
||||
node_dict.update(child_node.to_dict(format_func))
|
||||
# 递归调用 to_dict 方法并更新节点字典
|
||||
child_dict = child_node._to_dict(format_func, mode, exclude)
|
||||
node_value[child_key] = child_dict
|
||||
|
||||
return node_dict
|
||||
return node_value
|
||||
|
||||
def update_instruct_content(self, incre_data: dict[str, Any]):
|
||||
assert self.instruct_content
|
||||
origin_sc_dict = self.instruct_content.model_dump()
|
||||
origin_sc_dict.update(incre_data)
|
||||
output_class = self.create_class()
|
||||
self.instruct_content = output_class(**origin_sc_dict)
|
||||
|
||||
def keys(self, mode: str = "auto") -> list:
|
||||
if mode == "children" or (mode == "auto" and self.children):
|
||||
keys = []
|
||||
else:
|
||||
keys = [self.key]
|
||||
if mode == "root":
|
||||
return keys
|
||||
|
||||
for _, child_node in self.children.items():
|
||||
keys.append(child_node.key)
|
||||
return keys
|
||||
|
||||
def compile_to(self, i: Dict, schema, kv_sep) -> str:
|
||||
if schema == "json":
|
||||
|
|
@ -234,6 +376,17 @@ class ActionNode:
|
|||
if schema == "raw":
|
||||
return context + "\n\n## Actions\n" + LANGUAGE_CONSTRAINT + "\n" + self.instruction
|
||||
|
||||
### 直接使用 pydantic BaseModel 生成 instruction 与 example,仅限 JSON
|
||||
# child_class = self._create_children_class()
|
||||
# node_schema = child_class.model_json_schema()
|
||||
# defaults = {
|
||||
# k: str(v)
|
||||
# for k, v in child_class.model_fields.items()
|
||||
# if k not in exclude
|
||||
# }
|
||||
# instruction = node_schema
|
||||
# example = json.dumps(defaults, indent=4)
|
||||
|
||||
# FIXME: json instruction会带来格式问题,如:"Project name": "web_2048 # 项目名称使用下划线",
|
||||
# compile example暂时不支持markdown
|
||||
instruction = self.compile_instruction(schema="markdown", mode=mode, exclude=exclude)
|
||||
|
|
@ -260,12 +413,13 @@ class ActionNode:
|
|||
prompt: str,
|
||||
output_class_name: str,
|
||||
output_data_mapping: dict,
|
||||
images: Optional[Union[str, list[str]]] = None,
|
||||
system_msgs: Optional[list[str]] = None,
|
||||
schema="markdown", # compatible to original format
|
||||
timeout=CONFIG.timeout,
|
||||
timeout=3,
|
||||
) -> (str, BaseModel):
|
||||
"""Use ActionOutput to wrap the output of aask"""
|
||||
content = await self.llm.aask(prompt, system_msgs, timeout=timeout)
|
||||
content = await self.llm.aask(prompt, system_msgs, images=images, timeout=timeout)
|
||||
logger.debug(f"llm raw output:\n{content}")
|
||||
output_class = self.create_model_class(output_class_name, output_data_mapping)
|
||||
|
||||
|
|
@ -294,13 +448,15 @@ class ActionNode:
|
|||
def set_context(self, context):
|
||||
self.set_recursive("context", context)
|
||||
|
||||
async def simple_fill(self, schema, mode, timeout=CONFIG.timeout, exclude=None):
|
||||
async def simple_fill(self, schema, mode, images: Optional[Union[str, list[str]]] = None, timeout=3, exclude=None):
|
||||
prompt = self.compile(context=self.context, schema=schema, mode=mode, exclude=exclude)
|
||||
|
||||
if schema != "raw":
|
||||
mapping = self.get_mapping(mode, exclude=exclude)
|
||||
class_name = f"{self.key}_AN"
|
||||
content, scontent = await self._aask_v1(prompt, class_name, mapping, schema=schema, timeout=timeout)
|
||||
content, scontent = await self._aask_v1(
|
||||
prompt, class_name, mapping, images=images, schema=schema, timeout=timeout
|
||||
)
|
||||
self.content = content
|
||||
self.instruct_content = scontent
|
||||
else:
|
||||
|
|
@ -309,7 +465,17 @@ class ActionNode:
|
|||
|
||||
return self
|
||||
|
||||
async def fill(self, context, llm, schema="json", mode="auto", strgy="simple", timeout=CONFIG.timeout, exclude=[]):
|
||||
async def fill(
|
||||
self,
|
||||
context,
|
||||
llm,
|
||||
schema="json",
|
||||
mode="auto",
|
||||
strgy="simple",
|
||||
images: Optional[Union[str, list[str]]] = None,
|
||||
timeout=3,
|
||||
exclude=[],
|
||||
):
|
||||
"""Fill the node(s) with mode.
|
||||
|
||||
:param context: Everything we should know when filling node.
|
||||
|
|
@ -325,6 +491,7 @@ class ActionNode:
|
|||
:param strgy: simple/complex
|
||||
- simple: run only once
|
||||
- complex: run each node
|
||||
:param images: the list of image url or base64 for gpt4-v
|
||||
:param timeout: Timeout for llm invocation.
|
||||
:param exclude: The keys of ActionNode to exclude.
|
||||
:return: self
|
||||
|
|
@ -335,15 +502,219 @@ class ActionNode:
|
|||
schema = self.schema
|
||||
|
||||
if strgy == "simple":
|
||||
return await self.simple_fill(schema=schema, mode=mode, timeout=timeout, exclude=exclude)
|
||||
return await self.simple_fill(schema=schema, mode=mode, images=images, timeout=timeout, exclude=exclude)
|
||||
elif strgy == "complex":
|
||||
# 这里隐式假设了拥有children
|
||||
tmp = {}
|
||||
for _, i in self.children.items():
|
||||
if exclude and i.key in exclude:
|
||||
continue
|
||||
child = await i.simple_fill(schema=schema, mode=mode, timeout=timeout, exclude=exclude)
|
||||
tmp.update(child.instruct_content.dict())
|
||||
cls = self.create_children_class()
|
||||
child = await i.simple_fill(schema=schema, mode=mode, images=images, timeout=timeout, exclude=exclude)
|
||||
tmp.update(child.instruct_content.model_dump())
|
||||
cls = self._create_children_class()
|
||||
self.instruct_content = cls(**tmp)
|
||||
return self
|
||||
|
||||
async def human_review(self) -> dict[str, str]:
|
||||
review_comments = HumanInteraction().interact_with_instruct_content(
|
||||
instruct_content=self.instruct_content, interact_type="review"
|
||||
)
|
||||
|
||||
return review_comments
|
||||
|
||||
def _makeup_nodes_output_with_req(self) -> dict[str, str]:
|
||||
instruct_content_dict = self.instruct_content.model_dump()
|
||||
nodes_output = {}
|
||||
for key, value in instruct_content_dict.items():
|
||||
child = self.get_child(key)
|
||||
nodes_output[key] = {"value": value, "requirement": child.instruction if child else self.instruction}
|
||||
return nodes_output
|
||||
|
||||
async def auto_review(self, template: str = REVIEW_TEMPLATE) -> dict[str, str]:
|
||||
"""use key's output value and its instruction to review the modification comment"""
|
||||
nodes_output = self._makeup_nodes_output_with_req()
|
||||
"""nodes_output format:
|
||||
{
|
||||
"key": {"value": "output value", "requirement": "key instruction"}
|
||||
}
|
||||
"""
|
||||
if not nodes_output:
|
||||
return dict()
|
||||
|
||||
prompt = template.format(
|
||||
nodes_output=json.dumps(nodes_output, ensure_ascii=False),
|
||||
tag=TAG,
|
||||
constraint=FORMAT_CONSTRAINT,
|
||||
prompt_schema="json",
|
||||
)
|
||||
|
||||
content = await self.llm.aask(prompt)
|
||||
# Extract the dict of mismatch key and its comment. Due to the mismatch keys are unknown, here use the keys
|
||||
# of ActionNode to judge if exist in `content` and then follow the `data_mapping` method to create model class.
|
||||
keys = self.keys()
|
||||
include_keys = []
|
||||
for key in keys:
|
||||
if f'"{key}":' in content:
|
||||
include_keys.append(key)
|
||||
if not include_keys:
|
||||
return dict()
|
||||
|
||||
exclude_keys = list(set(keys).difference(include_keys))
|
||||
output_class_name = f"{self.key}_AN_REVIEW"
|
||||
output_class = self.create_class(class_name=output_class_name, exclude=exclude_keys)
|
||||
parsed_data = llm_output_postprocess(
|
||||
output=content, schema=output_class.model_json_schema(), req_key=f"[/{TAG}]"
|
||||
)
|
||||
instruct_content = output_class(**parsed_data)
|
||||
return instruct_content.model_dump()
|
||||
|
||||
async def simple_review(self, review_mode: ReviewMode = ReviewMode.AUTO):
|
||||
# generate review comments
|
||||
if review_mode == ReviewMode.HUMAN:
|
||||
review_comments = await self.human_review()
|
||||
else:
|
||||
review_comments = await self.auto_review()
|
||||
|
||||
if not review_comments:
|
||||
logger.warning("There are no review comments")
|
||||
return review_comments
|
||||
|
||||
async def review(self, strgy: str = "simple", review_mode: ReviewMode = ReviewMode.AUTO):
|
||||
"""only give the review comment of each exist and mismatch key
|
||||
|
||||
:param strgy: simple/complex
|
||||
- simple: run only once
|
||||
- complex: run each node
|
||||
"""
|
||||
if not hasattr(self, "llm"):
|
||||
raise RuntimeError("use `review` after `fill`")
|
||||
assert review_mode in ReviewMode
|
||||
assert self.instruct_content, 'review only support with `schema != "raw"`'
|
||||
|
||||
if strgy == "simple":
|
||||
review_comments = await self.simple_review(review_mode)
|
||||
elif strgy == "complex":
|
||||
# review each child node one-by-one
|
||||
review_comments = {}
|
||||
for _, child in self.children.items():
|
||||
child_review_comment = await child.simple_review(review_mode)
|
||||
review_comments.update(child_review_comment)
|
||||
|
||||
return review_comments
|
||||
|
||||
async def human_revise(self) -> dict[str, str]:
|
||||
review_contents = HumanInteraction().interact_with_instruct_content(
|
||||
instruct_content=self.instruct_content, mapping=self.get_mapping(mode="auto"), interact_type="revise"
|
||||
)
|
||||
# re-fill the ActionNode
|
||||
self.update_instruct_content(review_contents)
|
||||
return review_contents
|
||||
|
||||
def _makeup_nodes_output_with_comment(self, review_comments: dict[str, str]) -> dict[str, str]:
|
||||
instruct_content_dict = self.instruct_content.model_dump()
|
||||
nodes_output = {}
|
||||
for key, value in instruct_content_dict.items():
|
||||
if key in review_comments:
|
||||
nodes_output[key] = {"value": value, "comment": review_comments[key]}
|
||||
return nodes_output
|
||||
|
||||
async def auto_revise(
|
||||
self, revise_mode: ReviseMode = ReviseMode.AUTO, template: str = REVISE_TEMPLATE
|
||||
) -> dict[str, str]:
|
||||
"""revise the value of incorrect keys"""
|
||||
# generate review comments
|
||||
if revise_mode == ReviseMode.AUTO:
|
||||
review_comments: dict = await self.auto_review()
|
||||
elif revise_mode == ReviseMode.HUMAN_REVIEW:
|
||||
review_comments: dict = await self.human_review()
|
||||
|
||||
include_keys = list(review_comments.keys())
|
||||
|
||||
# generate revise content, two-steps
|
||||
# step1, find the needed revise keys from review comments to makeup prompt template
|
||||
nodes_output = self._makeup_nodes_output_with_comment(review_comments)
|
||||
keys = self.keys()
|
||||
exclude_keys = list(set(keys).difference(include_keys))
|
||||
example = self.compile_example(schema="json", mode="auto", tag=TAG, exclude=exclude_keys)
|
||||
instruction = self.compile_instruction(schema="markdown", mode="auto", exclude=exclude_keys)
|
||||
|
||||
prompt = template.format(
|
||||
nodes_output=json.dumps(nodes_output, ensure_ascii=False),
|
||||
example=example,
|
||||
instruction=instruction,
|
||||
constraint=FORMAT_CONSTRAINT,
|
||||
prompt_schema="json",
|
||||
)
|
||||
|
||||
# step2, use `_aask_v1` to get revise structure result
|
||||
output_mapping = self.get_mapping(mode="auto", exclude=exclude_keys)
|
||||
output_class_name = f"{self.key}_AN_REVISE"
|
||||
content, scontent = await self._aask_v1(
|
||||
prompt=prompt, output_class_name=output_class_name, output_data_mapping=output_mapping, schema="json"
|
||||
)
|
||||
|
||||
# re-fill the ActionNode
|
||||
sc_dict = scontent.model_dump()
|
||||
self.update_instruct_content(sc_dict)
|
||||
return sc_dict
|
||||
|
||||
async def simple_revise(self, revise_mode: ReviseMode = ReviseMode.AUTO) -> dict[str, str]:
|
||||
if revise_mode == ReviseMode.HUMAN:
|
||||
revise_contents = await self.human_revise()
|
||||
else:
|
||||
revise_contents = await self.auto_revise(revise_mode)
|
||||
|
||||
return revise_contents
|
||||
|
||||
async def revise(self, strgy: str = "simple", revise_mode: ReviseMode = ReviseMode.AUTO) -> dict[str, str]:
|
||||
"""revise the content of ActionNode and update the instruct_content
|
||||
|
||||
:param strgy: simple/complex
|
||||
- simple: run only once
|
||||
- complex: run each node
|
||||
"""
|
||||
if not hasattr(self, "llm"):
|
||||
raise RuntimeError("use `revise` after `fill`")
|
||||
assert revise_mode in ReviseMode
|
||||
assert self.instruct_content, 'revise only support with `schema != "raw"`'
|
||||
|
||||
if strgy == "simple":
|
||||
revise_contents = await self.simple_revise(revise_mode)
|
||||
elif strgy == "complex":
|
||||
# revise each child node one-by-one
|
||||
revise_contents = {}
|
||||
for _, child in self.children.items():
|
||||
child_revise_content = await child.simple_revise(revise_mode)
|
||||
revise_contents.update(child_revise_content)
|
||||
self.update_instruct_content(revise_contents)
|
||||
|
||||
return revise_contents
|
||||
|
||||
@classmethod
|
||||
def from_pydantic(cls, model: Type[BaseModel], key: str = None):
|
||||
"""
|
||||
Creates an ActionNode tree from a Pydantic model.
|
||||
|
||||
Args:
|
||||
model (Type[BaseModel]): The Pydantic model to convert.
|
||||
|
||||
Returns:
|
||||
ActionNode: The root node of the created ActionNode tree.
|
||||
"""
|
||||
key = key or model.__name__
|
||||
root_node = cls(key=key, expected_type=Type[model], instruction="", example="")
|
||||
|
||||
for field_name, field_info in model.model_fields.items():
|
||||
field_type = field_info.annotation
|
||||
description = field_info.description
|
||||
default = field_info.default
|
||||
|
||||
# Recursively handle nested models if needed
|
||||
if not isinstance(field_type, typing._GenericAlias) and issubclass(field_type, BaseModel):
|
||||
child_node = cls.from_pydantic(field_type, key=field_name)
|
||||
else:
|
||||
child_node = cls(key=field_name, expected_type=field_type, instruction=description, example=default)
|
||||
|
||||
root_node.add_child(child_node)
|
||||
|
||||
return root_node
|
||||
|
|
|
|||
42
metagpt/actions/action_outcls_registry.py
Normal file
42
metagpt/actions/action_outcls_registry.py
Normal file
|
|
@ -0,0 +1,42 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : registry to store Dynamic Model from ActionNode.create_model_class to keep it as same Class
|
||||
# with same class name and mapping
|
||||
|
||||
from functools import wraps
|
||||
|
||||
action_outcls_registry = dict()
|
||||
|
||||
|
||||
def register_action_outcls(func):
|
||||
"""
|
||||
Due to `create_model` return different Class even they have same class name and mapping.
|
||||
In order to do a comparison, use outcls_id to identify same Class with same class name and field definition
|
||||
"""
|
||||
|
||||
@wraps(func)
|
||||
def decorater(*args, **kwargs):
|
||||
"""
|
||||
arr example
|
||||
[<class 'metagpt.actions.action_node.ActionNode'>, 'test', {'field': (str, Ellipsis)}]
|
||||
"""
|
||||
arr = list(args) + list(kwargs.values())
|
||||
"""
|
||||
outcls_id example
|
||||
"<class 'metagpt.actions.action_node.ActionNode'>_test_{'field': (str, Ellipsis)}"
|
||||
"""
|
||||
for idx, item in enumerate(arr):
|
||||
if isinstance(item, dict):
|
||||
arr[idx] = dict(sorted(item.items()))
|
||||
outcls_id = "_".join([str(i) for i in arr])
|
||||
# eliminate typing influence
|
||||
outcls_id = outcls_id.replace("typing.List", "list").replace("typing.Dict", "dict")
|
||||
|
||||
if outcls_id in action_outcls_registry:
|
||||
return action_outcls_registry[outcls_id]
|
||||
|
||||
out_cls = func(*args, **kwargs)
|
||||
action_outcls_registry[outcls_id] = out_cls
|
||||
return out_cls
|
||||
|
||||
return decorater
|
||||
62
metagpt/actions/ci/ask_review.py
Normal file
62
metagpt/actions/ci/ask_review.py
Normal file
|
|
@ -0,0 +1,62 @@
|
|||
from __future__ import annotations
|
||||
|
||||
from typing import Tuple
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Message, Plan
|
||||
|
||||
|
||||
class ReviewConst:
|
||||
TASK_REVIEW_TRIGGER = "task"
|
||||
CODE_REVIEW_TRIGGER = "code"
|
||||
CONTINUE_WORDS = ["confirm", "continue", "c", "yes", "y"]
|
||||
CHANGE_WORDS = ["change"]
|
||||
EXIT_WORDS = ["exit"]
|
||||
TASK_REVIEW_INSTRUCTION = (
|
||||
f"If you want to change, add, delete a task or merge tasks in the plan, say '{CHANGE_WORDS[0]} task task_id or current task, ... (things to change)' "
|
||||
f"If you confirm the output from the current task and wish to continue, type: {CONTINUE_WORDS[0]}"
|
||||
)
|
||||
CODE_REVIEW_INSTRUCTION = (
|
||||
f"If you want the codes to be rewritten, say '{CHANGE_WORDS[0]} ... (your change advice)' "
|
||||
f"If you want to leave it as is, type: {CONTINUE_WORDS[0]} or {CONTINUE_WORDS[1]}"
|
||||
)
|
||||
EXIT_INSTRUCTION = f"If you want to terminate the process, type: {EXIT_WORDS[0]}"
|
||||
|
||||
|
||||
class AskReview(Action):
|
||||
async def run(
|
||||
self, context: list[Message] = [], plan: Plan = None, trigger: str = ReviewConst.TASK_REVIEW_TRIGGER
|
||||
) -> Tuple[str, bool]:
|
||||
if plan:
|
||||
logger.info("Current overall plan:")
|
||||
logger.info(
|
||||
"\n".join(
|
||||
[f"{task.task_id}: {task.instruction}, is_finished: {task.is_finished}" for task in plan.tasks]
|
||||
)
|
||||
)
|
||||
|
||||
logger.info("Most recent context:")
|
||||
latest_action = context[-1].cause_by if context and context[-1].cause_by else ""
|
||||
review_instruction = (
|
||||
ReviewConst.TASK_REVIEW_INSTRUCTION
|
||||
if trigger == ReviewConst.TASK_REVIEW_TRIGGER
|
||||
else ReviewConst.CODE_REVIEW_INSTRUCTION
|
||||
)
|
||||
prompt = (
|
||||
f"This is a <{trigger}> review. Please review output from {latest_action}\n"
|
||||
f"{review_instruction}\n"
|
||||
f"{ReviewConst.EXIT_INSTRUCTION}\n"
|
||||
"Please type your review below:\n"
|
||||
)
|
||||
|
||||
rsp = input(prompt)
|
||||
|
||||
if rsp.lower() in ReviewConst.EXIT_WORDS:
|
||||
exit()
|
||||
|
||||
# Confirmation can be one of "confirm", "continue", "c", "yes", "y" exactly, or sentences containing "confirm".
|
||||
# One could say "confirm this task, but change the next task to ..."
|
||||
confirmed = rsp.lower() in ReviewConst.CONTINUE_WORDS or ReviewConst.CONTINUE_WORDS[0] in rsp.lower()
|
||||
|
||||
return rsp, confirmed
|
||||
109
metagpt/actions/ci/debug_code.py
Normal file
109
metagpt/actions/ci/debug_code.py
Normal file
|
|
@ -0,0 +1,109 @@
|
|||
from __future__ import annotations
|
||||
|
||||
from metagpt.actions.ci.write_analysis_code import BaseWriteAnalysisCode
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.common import create_func_call_config
|
||||
|
||||
DEBUG_REFLECTION_EXAMPLE = '''
|
||||
Example 1:
|
||||
[previous impl]:
|
||||
```python
|
||||
def add(a: int, b: int) -> int:
|
||||
"""
|
||||
Given integers a and b, return the total value of a and b.
|
||||
"""
|
||||
return a - b
|
||||
```
|
||||
|
||||
[runtime Error]:
|
||||
Tested passed:
|
||||
|
||||
Tests failed:
|
||||
assert add(1, 2) == 3 # output: -1
|
||||
assert add(1, 2) == 4 # output: -1
|
||||
|
||||
[reflection on previous impl]:
|
||||
The implementation failed the test cases where the input integers are 1 and 2. The issue arises because the code does not add the two integers together, but instead subtracts the second integer from the first. To fix this issue, we should change the operator from `-` to `+` in the return statement. This will ensure that the function returns the correct output for the given input.
|
||||
|
||||
[improved impl]:
|
||||
```python
|
||||
def add(a: int, b: int) -> int:
|
||||
"""
|
||||
Given integers a and b, return the total value of a and b.
|
||||
"""
|
||||
return a + b
|
||||
```
|
||||
'''
|
||||
|
||||
REFLECTION_PROMPT = """
|
||||
Here is an example for you.
|
||||
{debug_example}
|
||||
[context]
|
||||
{context}
|
||||
|
||||
[previous impl]
|
||||
{code}
|
||||
[runtime Error]
|
||||
{runtime_result}
|
||||
|
||||
Analysis the error step by step, provide me improve method and code. Remember to follow [context] requirement. Don't forget write code for steps behind the error step.
|
||||
[reflection on previous impl]:
|
||||
xxx
|
||||
"""
|
||||
|
||||
CODE_REFLECTION = {
|
||||
"name": "execute_reflection_code",
|
||||
"description": "Execute reflection code.",
|
||||
"parameters": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"reflection": {
|
||||
"type": "string",
|
||||
"description": "Reflection on previous impl.",
|
||||
},
|
||||
"improved_impl": {
|
||||
"type": "string",
|
||||
"description": "Refined code after reflection.",
|
||||
},
|
||||
},
|
||||
"required": ["reflection", "improved_impl"],
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
class DebugCode(BaseWriteAnalysisCode):
|
||||
async def run(
|
||||
self,
|
||||
context: list[Message] = None,
|
||||
code: str = "",
|
||||
runtime_result: str = "",
|
||||
) -> str:
|
||||
"""
|
||||
Execute the debugging process based on the provided context, code, and runtime_result.
|
||||
|
||||
Args:
|
||||
context (list[Message]): A list of Message objects representing the context.
|
||||
code (str): The code to be debugged.
|
||||
runtime_result (str): The result of the code execution.
|
||||
|
||||
Returns:
|
||||
str: The improved implementation based on the debugging process.
|
||||
"""
|
||||
|
||||
info = []
|
||||
reflection_prompt = REFLECTION_PROMPT.format(
|
||||
debug_example=DEBUG_REFLECTION_EXAMPLE,
|
||||
context=context,
|
||||
code=code,
|
||||
runtime_result=runtime_result,
|
||||
)
|
||||
system_prompt = "You are an AI Python assistant. You will be given your previous implementation code of a task, runtime error results, and a hint to change the implementation appropriately. Write your full implementation "
|
||||
info.append(Message(role="system", content=system_prompt))
|
||||
info.append(Message(role="user", content=reflection_prompt))
|
||||
|
||||
tool_config = create_func_call_config(CODE_REFLECTION)
|
||||
reflection = await self.llm.aask_code(messages=info, **tool_config)
|
||||
logger.info(f"reflection is {reflection}")
|
||||
|
||||
return {"code": reflection["improved_impl"]}
|
||||
249
metagpt/actions/ci/execute_nb_code.py
Normal file
249
metagpt/actions/ci/execute_nb_code.py
Normal file
|
|
@ -0,0 +1,249 @@
|
|||
# -*- encoding: utf-8 -*-
|
||||
"""
|
||||
@Date : 2023/11/17 14:22:15
|
||||
@Author : orange-crow
|
||||
@File : execute_nb_code.py
|
||||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
import asyncio
|
||||
import base64
|
||||
import re
|
||||
import traceback
|
||||
from typing import Literal, Tuple
|
||||
|
||||
import nbformat
|
||||
from nbclient import NotebookClient
|
||||
from nbclient.exceptions import CellTimeoutError, DeadKernelError
|
||||
from nbformat import NotebookNode
|
||||
from nbformat.v4 import new_code_cell, new_markdown_cell, new_output
|
||||
from rich.box import MINIMAL
|
||||
from rich.console import Console, Group
|
||||
from rich.live import Live
|
||||
from rich.markdown import Markdown
|
||||
from rich.panel import Panel
|
||||
from rich.syntax import Syntax
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.logs import logger
|
||||
|
||||
|
||||
class ExecuteNbCode(Action):
|
||||
"""execute notebook code block, return result to llm, and display it."""
|
||||
|
||||
nb: NotebookNode
|
||||
nb_client: NotebookClient
|
||||
console: Console
|
||||
interaction: str
|
||||
timeout: int = 600
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
nb=nbformat.v4.new_notebook(),
|
||||
timeout=600,
|
||||
):
|
||||
super().__init__(
|
||||
nb=nb,
|
||||
nb_client=NotebookClient(nb, timeout=timeout),
|
||||
timeout=timeout,
|
||||
console=Console(),
|
||||
interaction=("ipython" if self.is_ipython() else "terminal"),
|
||||
)
|
||||
|
||||
async def build(self):
|
||||
if self.nb_client.kc is None or not await self.nb_client.kc.is_alive():
|
||||
self.nb_client.create_kernel_manager()
|
||||
self.nb_client.start_new_kernel()
|
||||
self.nb_client.start_new_kernel_client()
|
||||
|
||||
async def terminate(self):
|
||||
"""kill NotebookClient"""
|
||||
await self.nb_client._async_cleanup_kernel()
|
||||
|
||||
async def reset(self):
|
||||
"""reset NotebookClient"""
|
||||
await self.terminate()
|
||||
|
||||
# sleep 1s to wait for the kernel to be cleaned up completely
|
||||
await asyncio.sleep(1)
|
||||
await self.build()
|
||||
self.nb_client = NotebookClient(self.nb, timeout=self.timeout)
|
||||
|
||||
def add_code_cell(self, code: str):
|
||||
self.nb.cells.append(new_code_cell(source=code))
|
||||
|
||||
def add_markdown_cell(self, markdown: str):
|
||||
self.nb.cells.append(new_markdown_cell(source=markdown))
|
||||
|
||||
def _display(self, code: str, language: Literal["python", "markdown"] = "python"):
|
||||
if language == "python":
|
||||
code = Syntax(code, "python", theme="paraiso-dark", line_numbers=True)
|
||||
self.console.print(code)
|
||||
elif language == "markdown":
|
||||
display_markdown(code)
|
||||
else:
|
||||
raise ValueError(f"Only support for python, markdown, but got {language}")
|
||||
|
||||
def add_output_to_cell(self, cell: NotebookNode, output: str):
|
||||
"""add outputs of code execution to notebook cell."""
|
||||
if "outputs" not in cell:
|
||||
cell["outputs"] = []
|
||||
else:
|
||||
cell["outputs"].append(new_output(output_type="stream", name="stdout", text=str(output)))
|
||||
|
||||
def parse_outputs(self, outputs: list[str]) -> str:
|
||||
"""Parses the outputs received from notebook execution."""
|
||||
assert isinstance(outputs, list)
|
||||
parsed_output = ""
|
||||
|
||||
for i, output in enumerate(outputs):
|
||||
if output["output_type"] == "stream" and not any(
|
||||
tag in output["text"]
|
||||
for tag in ["| INFO | metagpt", "| ERROR | metagpt", "| WARNING | metagpt"]
|
||||
):
|
||||
parsed_output += output["text"]
|
||||
elif output["output_type"] == "display_data":
|
||||
if "image/png" in output["data"]:
|
||||
self.show_bytes_figure(output["data"]["image/png"], self.interaction)
|
||||
else:
|
||||
logger.info(
|
||||
f"{i}th output['data'] from nbclient outputs dont have image/png, continue next output ..."
|
||||
)
|
||||
elif output["output_type"] == "execute_result":
|
||||
parsed_output += output["data"]["text/plain"]
|
||||
return parsed_output
|
||||
|
||||
def show_bytes_figure(self, image_base64: str, interaction_type: Literal["ipython", None]):
|
||||
image_bytes = base64.b64decode(image_base64)
|
||||
if interaction_type == "ipython":
|
||||
from IPython.display import Image, display
|
||||
|
||||
display(Image(data=image_bytes))
|
||||
else:
|
||||
import io
|
||||
|
||||
from PIL import Image
|
||||
|
||||
image = Image.open(io.BytesIO(image_bytes))
|
||||
image.show()
|
||||
|
||||
def is_ipython(self) -> bool:
|
||||
try:
|
||||
# 如果在Jupyter Notebook中运行,__file__ 变量不存在
|
||||
from IPython import get_ipython
|
||||
|
||||
if get_ipython() is not None and "IPKernelApp" in get_ipython().config:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
except NameError:
|
||||
return False
|
||||
|
||||
async def run_cell(self, cell: NotebookNode, cell_index: int) -> Tuple[bool, str]:
|
||||
"""set timeout for run code.
|
||||
returns the success or failure of the cell execution, and an optional error message.
|
||||
"""
|
||||
try:
|
||||
await self.nb_client.async_execute_cell(cell, cell_index)
|
||||
return True, ""
|
||||
except CellTimeoutError:
|
||||
assert self.nb_client.km is not None
|
||||
await self.nb_client.km.interrupt_kernel()
|
||||
await asyncio.sleep(1)
|
||||
error_msg = "Cell execution timed out: Execution exceeded the time limit and was stopped; consider optimizing your code for better performance."
|
||||
return False, error_msg
|
||||
except DeadKernelError:
|
||||
await self.reset()
|
||||
return False, "DeadKernelError"
|
||||
except Exception:
|
||||
return False, f"{traceback.format_exc()}"
|
||||
|
||||
async def run(self, code: str, language: Literal["python", "markdown"] = "python") -> Tuple[str, bool]:
|
||||
"""
|
||||
return the output of code execution, and a success indicator (bool) of code execution.
|
||||
"""
|
||||
self._display(code, language)
|
||||
|
||||
if language == "python":
|
||||
# add code to the notebook
|
||||
self.add_code_cell(code=code)
|
||||
|
||||
# build code executor
|
||||
await self.build()
|
||||
|
||||
# run code
|
||||
cell_index = len(self.nb.cells) - 1
|
||||
success, error_message = await self.run_cell(self.nb.cells[-1], cell_index)
|
||||
|
||||
if not success:
|
||||
return truncate(remove_escape_and_color_codes(error_message), is_success=success)
|
||||
|
||||
# code success
|
||||
outputs = self.parse_outputs(self.nb.cells[-1].outputs)
|
||||
outputs, success = truncate(remove_escape_and_color_codes(outputs), is_success=success)
|
||||
|
||||
if "!pip" in outputs:
|
||||
success = False
|
||||
|
||||
return outputs, success
|
||||
|
||||
elif language == "markdown":
|
||||
# add markdown content to markdown cell in a notebook.
|
||||
self.add_markdown_cell(code)
|
||||
# return True, beacuse there is no execution failure for markdown cell.
|
||||
return code, True
|
||||
else:
|
||||
raise ValueError(f"Only support for language: python, markdown, but got {language}, ")
|
||||
|
||||
|
||||
def truncate(result: str, keep_len: int = 2000, is_success: bool = True):
|
||||
"""对于超出keep_len个字符的result: 执行失败的代码, 展示result后keep_len个字符; 执行成功的代码, 展示result前keep_len个字符。"""
|
||||
if is_success:
|
||||
desc = f"Executed code successfully. Truncated to show only first {keep_len} characters\n"
|
||||
else:
|
||||
desc = f"Executed code failed, please reflect the cause of bug and then debug. Truncated to show only last {keep_len} characters\n"
|
||||
|
||||
if result.strip().startswith("<coroutine object"):
|
||||
result = "Executed code failed, you need use key word 'await' to run a async code."
|
||||
return result, False
|
||||
|
||||
if len(result) > keep_len:
|
||||
result = result[-keep_len:] if not is_success else result[:keep_len]
|
||||
return desc + result, is_success
|
||||
|
||||
return result, is_success
|
||||
|
||||
|
||||
def remove_escape_and_color_codes(input_str: str):
|
||||
# 使用正则表达式去除转义字符和颜色代码
|
||||
pattern = re.compile(r"\x1b\[[0-9;]*[mK]")
|
||||
result = pattern.sub("", input_str)
|
||||
return result
|
||||
|
||||
|
||||
def display_markdown(content: str):
|
||||
# 使用正则表达式逐个匹配代码块
|
||||
matches = re.finditer(r"```(.+?)```", content, re.DOTALL)
|
||||
start_index = 0
|
||||
content_panels = []
|
||||
# 逐个打印匹配到的文本和代码
|
||||
for match in matches:
|
||||
text_content = content[start_index : match.start()].strip()
|
||||
code_content = match.group(0).strip()[3:-3] # Remove triple backticks
|
||||
|
||||
if text_content:
|
||||
content_panels.append(Panel(Markdown(text_content), box=MINIMAL))
|
||||
|
||||
if code_content:
|
||||
content_panels.append(Panel(Markdown(f"```{code_content}"), box=MINIMAL))
|
||||
start_index = match.end()
|
||||
|
||||
# 打印剩余文本(如果有)
|
||||
remaining_text = content[start_index:].strip()
|
||||
if remaining_text:
|
||||
content_panels.append(Panel(Markdown(remaining_text), box=MINIMAL))
|
||||
|
||||
# 在Live模式中显示所有Panel
|
||||
with Live(auto_refresh=False, console=Console(), vertical_overflow="visible") as live:
|
||||
live.update(Group(*content_panels))
|
||||
live.refresh()
|
||||
70
metagpt/actions/ci/ml_action.py
Normal file
70
metagpt/actions/ci/ml_action.py
Normal file
|
|
@ -0,0 +1,70 @@
|
|||
from __future__ import annotations
|
||||
|
||||
from typing import Tuple
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.actions.ci.write_analysis_code import WriteCodeWithTools
|
||||
from metagpt.prompts.ci.ml_action import (
|
||||
ML_GENERATE_CODE_PROMPT,
|
||||
ML_TOOL_USAGE_PROMPT,
|
||||
PRINT_DATA_COLUMNS,
|
||||
UPDATE_DATA_COLUMNS,
|
||||
)
|
||||
from metagpt.prompts.ci.write_analysis_code import CODE_GENERATOR_WITH_TOOLS
|
||||
from metagpt.schema import Message, Plan
|
||||
from metagpt.utils.common import create_func_call_config, remove_comments
|
||||
|
||||
|
||||
class WriteCodeWithToolsML(WriteCodeWithTools):
|
||||
async def run(
|
||||
self,
|
||||
context: list[Message],
|
||||
plan: Plan = None,
|
||||
column_info: str = "",
|
||||
**kwargs,
|
||||
) -> Tuple[list[Message], str]:
|
||||
# prepare tool schemas and tool-type-specific instruction
|
||||
tool_schemas, tool_type_usage_prompt = await self._prepare_tools(plan=plan)
|
||||
|
||||
# ML-specific variables to be used in prompt
|
||||
finished_tasks = plan.get_finished_tasks()
|
||||
code_context = [remove_comments(task.code) for task in finished_tasks]
|
||||
code_context = "\n\n".join(code_context)
|
||||
|
||||
# prepare prompt depending on tool availability & LLM call
|
||||
if tool_schemas:
|
||||
prompt = ML_TOOL_USAGE_PROMPT.format(
|
||||
user_requirement=plan.goal,
|
||||
history_code=code_context,
|
||||
current_task=plan.current_task.instruction,
|
||||
column_info=column_info,
|
||||
tool_type_usage_prompt=tool_type_usage_prompt,
|
||||
tool_schemas=tool_schemas,
|
||||
)
|
||||
|
||||
else:
|
||||
prompt = ML_GENERATE_CODE_PROMPT.format(
|
||||
user_requirement=plan.goal,
|
||||
history_code=code_context,
|
||||
current_task=plan.current_task.instruction,
|
||||
column_info=column_info,
|
||||
tool_type_usage_prompt=tool_type_usage_prompt,
|
||||
)
|
||||
tool_config = create_func_call_config(CODE_GENERATOR_WITH_TOOLS)
|
||||
rsp = await self.llm.aask_code(prompt, **tool_config)
|
||||
|
||||
# Extra output to be used for potential debugging
|
||||
context = [Message(content=prompt, role="user")]
|
||||
|
||||
return context, rsp
|
||||
|
||||
|
||||
class UpdateDataColumns(Action):
|
||||
async def run(self, plan: Plan = None) -> dict:
|
||||
finished_tasks = plan.get_finished_tasks()
|
||||
code_context = [remove_comments(task.code) for task in finished_tasks]
|
||||
code_context = "\n\n".join(code_context)
|
||||
prompt = UPDATE_DATA_COLUMNS.format(history_code=code_context)
|
||||
tool_config = create_func_call_config(PRINT_DATA_COLUMNS)
|
||||
rsp = await self.llm.aask_code(prompt, **tool_config)
|
||||
return rsp
|
||||
155
metagpt/actions/ci/write_analysis_code.py
Normal file
155
metagpt/actions/ci/write_analysis_code.py
Normal file
|
|
@ -0,0 +1,155 @@
|
|||
# -*- encoding: utf-8 -*-
|
||||
"""
|
||||
@Date : 2023/11/20 13:19:39
|
||||
@Author : orange-crow
|
||||
@File : write_analysis_code.py
|
||||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Tuple
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.logs import logger
|
||||
from metagpt.prompts.ci.write_analysis_code import (
|
||||
CODE_GENERATOR_WITH_TOOLS,
|
||||
SELECT_FUNCTION_TOOLS,
|
||||
TOOL_RECOMMENDATION_PROMPT,
|
||||
TOOL_USAGE_PROMPT,
|
||||
)
|
||||
from metagpt.schema import Message, Plan, SystemMessage
|
||||
from metagpt.tools import TOOL_REGISTRY
|
||||
from metagpt.tools.tool_registry import validate_tool_names
|
||||
from metagpt.utils.common import create_func_call_config
|
||||
|
||||
|
||||
class BaseWriteAnalysisCode(Action):
|
||||
DEFAULT_SYSTEM_MSG: str = """You are Code Interpreter, a world-class programmer that can complete any goal by executing code. Strictly follow the plan and generate code step by step. Each step of the code will be executed on the user's machine, and the user will provide the code execution results to you.**Notice: The code for the next step depends on the code for the previous step. Must reuse variables in the lastest other code directly, dont creat it again, it is very import for you. Use !pip install in a standalone block to install missing packages.Usually the libraries you need are already installed.Dont check if packages already imported.**""" # prompt reference: https://github.com/KillianLucas/open-interpreter/blob/v0.1.4/interpreter/system_message.txt
|
||||
# REUSE_CODE_INSTRUCTION = """ATTENTION: DONT include codes from previous tasks in your current code block, include new codes only, DONT repeat codes!"""
|
||||
|
||||
def insert_system_message(self, context: list[Message], system_msg: str = None):
|
||||
system_msg = system_msg or self.DEFAULT_SYSTEM_MSG
|
||||
context.insert(0, SystemMessage(content=system_msg)) if context[0].role != "system" else None
|
||||
return context
|
||||
|
||||
async def run(self, context: list[Message], plan: Plan = None) -> dict:
|
||||
"""Run of a code writing action, used in data analysis or modeling
|
||||
|
||||
Args:
|
||||
context (list[Message]): Action output history, source action denoted by Message.cause_by
|
||||
plan (Plan, optional): Overall plan. Defaults to None.
|
||||
|
||||
Returns:
|
||||
dict: code result in the format of {"code": "print('hello world')", "language": "python"}
|
||||
"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class WriteCodeWithoutTools(BaseWriteAnalysisCode):
|
||||
"""Ask LLM to generate codes purely by itself without local user-defined tools"""
|
||||
|
||||
async def run(self, context: list[Message], plan: Plan = None, system_msg: str = None, **kwargs) -> dict:
|
||||
messages = self.insert_system_message(context, system_msg)
|
||||
rsp = await self.llm.aask_code(messages, **kwargs)
|
||||
return rsp
|
||||
|
||||
|
||||
class WriteCodeWithTools(BaseWriteAnalysisCode):
|
||||
"""Write code with help of local available tools. Choose tools first, then generate code to use the tools"""
|
||||
|
||||
# selected tools to choose from, listed by their names. An empty list means selection from all tools.
|
||||
selected_tools: list[str] = []
|
||||
|
||||
def _get_tools_by_type(self, tool_type: str) -> dict:
|
||||
"""
|
||||
Retreive tools by tool type from registry, but filtered by pre-selected tool list
|
||||
|
||||
Args:
|
||||
tool_type (str): Tool type to retrieve from the registry
|
||||
|
||||
Returns:
|
||||
dict: A dict of tool name to Tool object, representing available tools under the type
|
||||
"""
|
||||
candidate_tools = TOOL_REGISTRY.get_tools_by_type(tool_type)
|
||||
if self.selected_tools:
|
||||
candidate_tool_names = set(self.selected_tools) & candidate_tools.keys()
|
||||
candidate_tools = {tool_name: candidate_tools[tool_name] for tool_name in candidate_tool_names}
|
||||
return candidate_tools
|
||||
|
||||
async def _recommend_tool(
|
||||
self,
|
||||
task: str,
|
||||
available_tools: dict,
|
||||
) -> dict:
|
||||
"""
|
||||
Recommend tools for the specified task.
|
||||
|
||||
Args:
|
||||
task (str): the task to recommend tools for
|
||||
available_tools (dict): the available tools description
|
||||
|
||||
Returns:
|
||||
dict: schemas of recommended tools for the specified task
|
||||
"""
|
||||
prompt = TOOL_RECOMMENDATION_PROMPT.format(
|
||||
current_task=task,
|
||||
available_tools=available_tools,
|
||||
)
|
||||
tool_config = create_func_call_config(SELECT_FUNCTION_TOOLS)
|
||||
rsp = await self.llm.aask_code(prompt, **tool_config)
|
||||
recommend_tools = rsp["recommend_tools"]
|
||||
logger.info(f"Recommended tools: \n{recommend_tools}")
|
||||
|
||||
# Parses and validates the recommended tools, for LLM might hallucinate and recommend non-existing tools
|
||||
valid_tools = validate_tool_names(recommend_tools, return_tool_object=True)
|
||||
|
||||
tool_schemas = {tool.name: tool.schemas for tool in valid_tools}
|
||||
|
||||
return tool_schemas
|
||||
|
||||
async def _prepare_tools(self, plan: Plan) -> Tuple[dict, str]:
|
||||
"""Prepare tool schemas and usage instructions according to current task
|
||||
|
||||
Args:
|
||||
plan (Plan): The overall plan containing task information.
|
||||
|
||||
Returns:
|
||||
Tuple[dict, str]: A tool schemas ({tool_name: tool_schema_dict}) and a usage prompt for the type of tools selected
|
||||
"""
|
||||
# find tool type from task type through exact match, can extend to retrieval in the future
|
||||
tool_type = plan.current_task.task_type
|
||||
|
||||
# prepare tool-type-specific instruction
|
||||
tool_type_usage_prompt = (
|
||||
TOOL_REGISTRY.get_tool_type(tool_type).usage_prompt if TOOL_REGISTRY.has_tool_type(tool_type) else ""
|
||||
)
|
||||
|
||||
# prepare schemas of available tools
|
||||
tool_schemas = {}
|
||||
available_tools = self._get_tools_by_type(tool_type)
|
||||
if available_tools:
|
||||
available_tools = {tool_name: tool.schemas["description"] for tool_name, tool in available_tools.items()}
|
||||
tool_schemas = await self._recommend_tool(plan.current_task.instruction, available_tools)
|
||||
|
||||
return tool_schemas, tool_type_usage_prompt
|
||||
|
||||
async def run(
|
||||
self,
|
||||
context: list[Message],
|
||||
plan: Plan,
|
||||
**kwargs,
|
||||
) -> str:
|
||||
# prepare tool schemas and tool-type-specific instruction
|
||||
tool_schemas, tool_type_usage_prompt = await self._prepare_tools(plan=plan)
|
||||
|
||||
# form a complete tool usage instruction and include it as a message in context
|
||||
tools_instruction = TOOL_USAGE_PROMPT.format(
|
||||
tool_schemas=tool_schemas, tool_type_usage_prompt=tool_type_usage_prompt
|
||||
)
|
||||
context.append(Message(content=tools_instruction, role="user"))
|
||||
|
||||
# prepare prompt & LLM call
|
||||
prompt = self.insert_system_message(context)
|
||||
tool_config = create_func_call_config(CODE_GENERATOR_WITH_TOOLS)
|
||||
rsp = await self.llm.aask_code(prompt, **tool_config)
|
||||
|
||||
return rsp
|
||||
116
metagpt/actions/ci/write_plan.py
Normal file
116
metagpt/actions/ci/write_plan.py
Normal file
|
|
@ -0,0 +1,116 @@
|
|||
# -*- encoding: utf-8 -*-
|
||||
"""
|
||||
@Date : 2023/11/20 11:24:03
|
||||
@Author : orange-crow
|
||||
@File : plan.py
|
||||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
import json
|
||||
from copy import deepcopy
|
||||
from typing import Tuple
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.logs import logger
|
||||
from metagpt.prompts.ci.write_analysis_code import (
|
||||
ASSIGN_TASK_TYPE_CONFIG,
|
||||
ASSIGN_TASK_TYPE_PROMPT,
|
||||
)
|
||||
from metagpt.schema import Message, Plan, Task
|
||||
from metagpt.tools import TOOL_REGISTRY
|
||||
from metagpt.utils.common import CodeParser, create_func_call_config
|
||||
|
||||
|
||||
class WritePlan(Action):
|
||||
PROMPT_TEMPLATE: str = """
|
||||
# Context:
|
||||
__context__
|
||||
# Task:
|
||||
Based on the context, write a plan or modify an existing plan of what you should do to achieve the goal. A plan consists of one to __max_tasks__ tasks.
|
||||
If you are modifying an existing plan, carefully follow the instruction, don't make unnecessary changes. Give the whole plan unless instructed to modify only one task of the plan.
|
||||
If you encounter errors on the current task, revise and output the current single task only.
|
||||
Output a list of jsons following the format:
|
||||
```json
|
||||
[
|
||||
{
|
||||
"task_id": str = "unique identifier for a task in plan, can be an ordinal",
|
||||
"dependent_task_ids": list[str] = "ids of tasks prerequisite to this task",
|
||||
"instruction": "what you should do in this task, one short phrase or sentence",
|
||||
},
|
||||
...
|
||||
]
|
||||
```
|
||||
"""
|
||||
|
||||
async def assign_task_type(self, tasks: list[dict]) -> str:
|
||||
"""Assign task type to each task in tasks
|
||||
|
||||
Args:
|
||||
tasks (list[dict]): tasks to be assigned task type
|
||||
|
||||
Returns:
|
||||
str: tasks with task type assigned in a json string
|
||||
"""
|
||||
task_info = "\n".join([f"Task {task['task_id']}: {task['instruction']}" for task in tasks])
|
||||
task_type_desc = "\n".join(
|
||||
[f"- **{tool_type.name}**: {tool_type.desc}" for tool_type in TOOL_REGISTRY.get_tool_types().values()]
|
||||
) # task type are binded with tool type now, should be improved in the future
|
||||
prompt = ASSIGN_TASK_TYPE_PROMPT.format(
|
||||
task_info=task_info, task_type_desc=task_type_desc
|
||||
) # task types are set to be the same as tool types, for now
|
||||
tool_config = create_func_call_config(ASSIGN_TASK_TYPE_CONFIG)
|
||||
rsp = await self.llm.aask_code(prompt, **tool_config)
|
||||
task_type_list = rsp["task_type"]
|
||||
logger.info(f"assigned task types: {task_type_list}")
|
||||
for task, task_type in zip(tasks, task_type_list):
|
||||
task["task_type"] = task_type
|
||||
return json.dumps(tasks)
|
||||
|
||||
async def run(self, context: list[Message], max_tasks: int = 5, use_tools: bool = False) -> str:
|
||||
prompt = (
|
||||
self.PROMPT_TEMPLATE.replace("__context__", "\n".join([str(ct) for ct in context]))
|
||||
# .replace("__current_plan__", current_plan)
|
||||
.replace("__max_tasks__", str(max_tasks))
|
||||
)
|
||||
rsp = await self._aask(prompt)
|
||||
rsp = CodeParser.parse_code(block=None, text=rsp)
|
||||
if use_tools:
|
||||
rsp = await self.assign_task_type(json.loads(rsp))
|
||||
return rsp
|
||||
|
||||
|
||||
def rsp_to_tasks(rsp: str) -> list[Task]:
|
||||
rsp = json.loads(rsp)
|
||||
tasks = [Task(**task_config) for task_config in rsp]
|
||||
return tasks
|
||||
|
||||
|
||||
def update_plan_from_rsp(rsp: str, current_plan: Plan):
|
||||
tasks = rsp_to_tasks(rsp)
|
||||
if len(tasks) == 1 or tasks[0].dependent_task_ids:
|
||||
if tasks[0].dependent_task_ids and len(tasks) > 1:
|
||||
# tasks[0].dependent_task_ids means the generated tasks are not a complete plan
|
||||
# for they depend on tasks in the current plan, in this case, we only support updating one task each time
|
||||
logger.warning(
|
||||
"Current plan will take only the first generated task if the generated tasks are not a complete plan"
|
||||
)
|
||||
# handle a single task
|
||||
if current_plan.has_task_id(tasks[0].task_id):
|
||||
# replace an existing task
|
||||
current_plan.replace_task(tasks[0])
|
||||
else:
|
||||
# append one task
|
||||
current_plan.append_task(tasks[0])
|
||||
|
||||
else:
|
||||
# add tasks in general
|
||||
current_plan.add_tasks(tasks)
|
||||
|
||||
|
||||
def precheck_update_plan_from_rsp(rsp: str, current_plan: Plan) -> Tuple[bool, str]:
|
||||
temp_plan = deepcopy(current_plan)
|
||||
try:
|
||||
update_plan_from_rsp(rsp, temp_plan)
|
||||
return True, ""
|
||||
except Exception as e:
|
||||
return False, e
|
||||
|
|
@ -13,12 +13,9 @@ import re
|
|||
from pydantic import Field
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import TEST_CODES_FILE_REPO, TEST_OUTPUTS_FILE_REPO
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import RunCodeContext, RunCodeResult
|
||||
from metagpt.utils.common import CodeParser
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
NOTICE
|
||||
|
|
@ -49,13 +46,10 @@ Now you should start rewriting the code:
|
|||
|
||||
|
||||
class DebugError(Action):
|
||||
name: str = "DebugError"
|
||||
context: RunCodeContext = Field(default_factory=RunCodeContext)
|
||||
i_context: RunCodeContext = Field(default_factory=RunCodeContext)
|
||||
|
||||
async def run(self, *args, **kwargs) -> str:
|
||||
output_doc = await FileRepository.get_file(
|
||||
filename=self.context.output_filename, relative_path=TEST_OUTPUTS_FILE_REPO
|
||||
)
|
||||
output_doc = await self.repo.test_outputs.get(filename=self.i_context.output_filename)
|
||||
if not output_doc:
|
||||
return ""
|
||||
output_detail = RunCodeResult.loads(output_doc.content)
|
||||
|
|
@ -64,15 +58,13 @@ class DebugError(Action):
|
|||
if matches:
|
||||
return ""
|
||||
|
||||
logger.info(f"Debug and rewrite {self.context.test_filename}")
|
||||
code_doc = await FileRepository.get_file(
|
||||
filename=self.context.code_filename, relative_path=CONFIG.src_workspace
|
||||
logger.info(f"Debug and rewrite {self.i_context.test_filename}")
|
||||
code_doc = await self.repo.with_src_path(self.context.src_workspace).srcs.get(
|
||||
filename=self.i_context.code_filename
|
||||
)
|
||||
if not code_doc:
|
||||
return ""
|
||||
test_doc = await FileRepository.get_file(
|
||||
filename=self.context.test_filename, relative_path=TEST_CODES_FILE_REPO
|
||||
)
|
||||
test_doc = await self.repo.tests.get(filename=self.i_context.test_filename)
|
||||
if not test_doc:
|
||||
return ""
|
||||
prompt = PROMPT_TEMPLATE.format(code=code_doc.content, test_code=test_doc.content, logs=output_detail.stderr)
|
||||
|
|
|
|||
|
|
@ -22,17 +22,9 @@ from metagpt.actions.design_api_an import (
|
|||
REFINED_DESIGN_NODE,
|
||||
REFINED_PROGRAM_CALL_FLOW,
|
||||
)
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import (
|
||||
DATA_API_DESIGN_FILE_REPO,
|
||||
PRDS_FILE_REPO,
|
||||
SEQ_FLOW_FILE_REPO,
|
||||
SYSTEM_DESIGN_FILE_REPO,
|
||||
SYSTEM_DESIGN_PDF_FILE_REPO,
|
||||
)
|
||||
from metagpt.const import DATA_API_DESIGN_FILE_REPO, SEQ_FLOW_FILE_REPO
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Document, Documents, Message
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
from metagpt.utils.mermaid import mermaid_to_file
|
||||
|
||||
NEW_REQ_TEMPLATE = """
|
||||
|
|
@ -46,36 +38,30 @@ NEW_REQ_TEMPLATE = """
|
|||
|
||||
class WriteDesign(Action):
|
||||
name: str = ""
|
||||
context: Optional[str] = None
|
||||
i_context: Optional[str] = None
|
||||
desc: str = (
|
||||
"Based on the PRD, think about the system design, and design the corresponding APIs, "
|
||||
"data structures, library tables, processes, and paths. Please provide your design, feedback "
|
||||
"clearly and in detail."
|
||||
)
|
||||
|
||||
async def run(self, with_messages: Message, schema: str = CONFIG.prompt_schema):
|
||||
# Use `git status` to identify which PRD documents have been modified in the `docs/prds` directory.
|
||||
prds_file_repo = CONFIG.git_repo.new_file_repository(PRDS_FILE_REPO)
|
||||
changed_prds = prds_file_repo.changed_files
|
||||
async def run(self, with_messages: Message, schema: str = None):
|
||||
# Use `git status` to identify which PRD documents have been modified in the `docs/prd` directory.
|
||||
changed_prds = self.repo.docs.prd.changed_files
|
||||
# Use `git status` to identify which design documents in the `docs/system_designs` directory have undergone
|
||||
# changes.
|
||||
system_design_file_repo = CONFIG.git_repo.new_file_repository(SYSTEM_DESIGN_FILE_REPO)
|
||||
changed_system_designs = system_design_file_repo.changed_files
|
||||
changed_system_designs = self.repo.docs.system_design.changed_files
|
||||
|
||||
# For those PRDs and design documents that have undergone changes, regenerate the design content.
|
||||
changed_files = Documents()
|
||||
for filename in changed_prds.keys():
|
||||
doc = await self._update_system_design(
|
||||
filename=filename, prds_file_repo=prds_file_repo, system_design_file_repo=system_design_file_repo
|
||||
)
|
||||
doc = await self._update_system_design(filename=filename)
|
||||
changed_files.docs[filename] = doc
|
||||
|
||||
for filename in changed_system_designs.keys():
|
||||
if filename in changed_files.docs:
|
||||
continue
|
||||
doc = await self._update_system_design(
|
||||
filename=filename, prds_file_repo=prds_file_repo, system_design_file_repo=system_design_file_repo
|
||||
)
|
||||
doc = await self._update_system_design(filename=filename)
|
||||
changed_files.docs[filename] = doc
|
||||
if not changed_files.docs:
|
||||
logger.info("Nothing has changed.")
|
||||
|
|
@ -83,61 +69,52 @@ class WriteDesign(Action):
|
|||
# leaving room for global optimization in subsequent steps.
|
||||
return ActionOutput(content=changed_files.model_dump_json(), instruct_content=changed_files)
|
||||
|
||||
async def _new_system_design(self, context, schema=CONFIG.prompt_schema):
|
||||
node = await DESIGN_API_NODE.fill(context=context, llm=self.llm, schema=schema)
|
||||
async def _new_system_design(self, context):
|
||||
node = await DESIGN_API_NODE.fill(context=context, llm=self.llm)
|
||||
return node
|
||||
|
||||
async def _merge(self, prd_doc, system_design_doc, schema=CONFIG.prompt_schema):
|
||||
async def _merge(self, prd_doc, system_design_doc):
|
||||
context = NEW_REQ_TEMPLATE.format(old_design=system_design_doc.content, context=prd_doc.content)
|
||||
node = await REFINED_DESIGN_NODE.fill(context=context, llm=self.llm, schema=schema)
|
||||
node = await REFINED_DESIGN_NODE.fill(context=context, llm=self.llm)
|
||||
system_design_doc.content = node.instruct_content.model_dump_json()
|
||||
return system_design_doc
|
||||
|
||||
async def _update_system_design(self, filename, prds_file_repo, system_design_file_repo) -> Document:
|
||||
prd = await prds_file_repo.get(filename)
|
||||
old_system_design_doc = await system_design_file_repo.get(filename)
|
||||
async def _update_system_design(self, filename) -> Document:
|
||||
prd = await self.repo.docs.prd.get(filename)
|
||||
old_system_design_doc = await self.repo.docs.system_design.get(filename)
|
||||
if not old_system_design_doc:
|
||||
system_design = await self._new_system_design(context=prd.content)
|
||||
doc = Document(
|
||||
root_path=SYSTEM_DESIGN_FILE_REPO,
|
||||
doc = await self.repo.docs.system_design.save(
|
||||
filename=filename,
|
||||
content=system_design.instruct_content.model_dump_json(),
|
||||
dependencies={prd.root_relative_path},
|
||||
)
|
||||
else:
|
||||
doc = await self._merge(prd_doc=prd, system_design_doc=old_system_design_doc)
|
||||
await system_design_file_repo.save(
|
||||
filename=filename, content=doc.content, dependencies={prd.root_relative_path}
|
||||
)
|
||||
await self.repo.docs.system_design.save_doc(doc=doc, dependencies={prd.root_relative_path})
|
||||
await self._save_data_api_design(doc)
|
||||
await self._save_seq_flow(doc)
|
||||
await self._save_pdf(doc)
|
||||
await self.repo.resources.system_design.save_pdf(doc=doc)
|
||||
return doc
|
||||
|
||||
@staticmethod
|
||||
async def _save_data_api_design(design_doc):
|
||||
async def _save_data_api_design(self, design_doc):
|
||||
m = json.loads(design_doc.content)
|
||||
data_api_design = m.get(DATA_STRUCTURES_AND_INTERFACES.key) or m.get(REFINED_DATA_STRUCTURES_AND_INTERFACES.key)
|
||||
if not data_api_design:
|
||||
return
|
||||
pathname = CONFIG.git_repo.workdir / DATA_API_DESIGN_FILE_REPO / Path(design_doc.filename).with_suffix("")
|
||||
await WriteDesign._save_mermaid_file(data_api_design, pathname)
|
||||
pathname = self.repo.workdir / DATA_API_DESIGN_FILE_REPO / Path(design_doc.filename).with_suffix("")
|
||||
await self._save_mermaid_file(data_api_design, pathname)
|
||||
logger.info(f"Save class view to {str(pathname)}")
|
||||
|
||||
@staticmethod
|
||||
async def _save_seq_flow(design_doc):
|
||||
async def _save_seq_flow(self, design_doc):
|
||||
m = json.loads(design_doc.content)
|
||||
seq_flow = m.get(PROGRAM_CALL_FLOW.key) or m.get(REFINED_PROGRAM_CALL_FLOW.key)
|
||||
if not seq_flow:
|
||||
return
|
||||
pathname = CONFIG.git_repo.workdir / Path(SEQ_FLOW_FILE_REPO) / Path(design_doc.filename).with_suffix("")
|
||||
await WriteDesign._save_mermaid_file(seq_flow, pathname)
|
||||
pathname = self.repo.workdir / Path(SEQ_FLOW_FILE_REPO) / Path(design_doc.filename).with_suffix("")
|
||||
await self._save_mermaid_file(seq_flow, pathname)
|
||||
logger.info(f"Saving sequence flow to {str(pathname)}")
|
||||
|
||||
@staticmethod
|
||||
async def _save_pdf(design_doc):
|
||||
await FileRepository.save_as(doc=design_doc, with_suffix=".md", relative_path=SYSTEM_DESIGN_PDF_FILE_REPO)
|
||||
|
||||
@staticmethod
|
||||
async def _save_mermaid_file(data: str, pathname: Path):
|
||||
async def _save_mermaid_file(self, data: str, pathname: Path):
|
||||
pathname.parent.mkdir(parents=True, exist_ok=True)
|
||||
await mermaid_to_file(data, pathname)
|
||||
await mermaid_to_file(self.config.mermaid.engine, data, pathname)
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ from metagpt.actions.action import Action
|
|||
|
||||
class DesignReview(Action):
|
||||
name: str = "DesignReview"
|
||||
context: Optional[str] = None
|
||||
i_context: Optional[str] = None
|
||||
|
||||
async def run(self, prd, api_design):
|
||||
prompt = (
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ from metagpt.schema import Message
|
|||
|
||||
class ExecuteTask(Action):
|
||||
name: str = "ExecuteTask"
|
||||
context: list[Message] = []
|
||||
i_context: list[Message] = []
|
||||
|
||||
async def run(self, *args, **kwargs):
|
||||
pass
|
||||
|
|
|
|||
|
|
@ -1,8 +1,6 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/9/12 17:45
|
||||
@Author : fisherdeng
|
||||
@File : generate_questions.py
|
||||
"""
|
||||
from metagpt.actions import Action
|
||||
|
|
@ -23,5 +21,5 @@ class GenerateQuestions(Action):
|
|||
|
||||
name: str = "GenerateQuestions"
|
||||
|
||||
async def run(self, context):
|
||||
async def run(self, context) -> ActionNode:
|
||||
return await QUESTIONS.fill(context=context, llm=self.llm)
|
||||
|
|
|
|||
|
|
@ -16,17 +16,14 @@ from typing import Optional
|
|||
|
||||
import pandas as pd
|
||||
from paddleocr import PaddleOCR
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.const import INVOICE_OCR_TABLE_PATH
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.logs import logger
|
||||
from metagpt.prompts.invoice_ocr import (
|
||||
EXTRACT_OCR_MAIN_INFO_PROMPT,
|
||||
REPLY_OCR_QUESTION_PROMPT,
|
||||
)
|
||||
from metagpt.provider.base_llm import BaseLLM
|
||||
from metagpt.utils.common import OutputParser
|
||||
from metagpt.utils.file import File
|
||||
|
||||
|
|
@ -41,7 +38,7 @@ class InvoiceOCR(Action):
|
|||
"""
|
||||
|
||||
name: str = "InvoiceOCR"
|
||||
context: Optional[str] = None
|
||||
i_context: Optional[str] = None
|
||||
|
||||
@staticmethod
|
||||
async def _check_file_type(file_path: Path) -> str:
|
||||
|
|
@ -132,8 +129,7 @@ class GenerateTable(Action):
|
|||
"""
|
||||
|
||||
name: str = "GenerateTable"
|
||||
context: Optional[str] = None
|
||||
llm: BaseLLM = Field(default_factory=LLM)
|
||||
i_context: Optional[str] = None
|
||||
language: str = "ch"
|
||||
|
||||
async def run(self, ocr_results: list, filename: str, *args, **kwargs) -> dict[str, str]:
|
||||
|
|
@ -176,9 +172,6 @@ class ReplyQuestion(Action):
|
|||
|
||||
"""
|
||||
|
||||
name: str = "ReplyQuestion"
|
||||
context: Optional[str] = None
|
||||
llm: BaseLLM = Field(default_factory=LLM)
|
||||
language: str = "ch"
|
||||
|
||||
async def run(self, query: str, ocr_result: list, *args, **kwargs) -> str:
|
||||
|
|
|
|||
|
|
@ -12,39 +12,41 @@ from pathlib import Path
|
|||
from typing import Optional
|
||||
|
||||
from metagpt.actions import Action, ActionOutput
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import DOCS_FILE_REPO, REQUIREMENT_FILENAME
|
||||
from metagpt.schema import Document
|
||||
from metagpt.const import REQUIREMENT_FILENAME
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
from metagpt.utils.git_repository import GitRepository
|
||||
from metagpt.utils.project_repo import ProjectRepo
|
||||
|
||||
|
||||
class PrepareDocuments(Action):
|
||||
"""PrepareDocuments Action: initialize project folder and add new requirements to docs/requirements.txt."""
|
||||
|
||||
name: str = "PrepareDocuments"
|
||||
context: Optional[str] = None
|
||||
i_context: Optional[str] = None
|
||||
|
||||
@property
|
||||
def config(self):
|
||||
return self.context.config
|
||||
|
||||
def _init_repo(self):
|
||||
"""Initialize the Git environment."""
|
||||
if not CONFIG.project_path:
|
||||
name = CONFIG.project_name or FileRepository.new_filename()
|
||||
path = Path(CONFIG.workspace_path) / name
|
||||
if not self.config.project_path:
|
||||
name = self.config.project_name or FileRepository.new_filename()
|
||||
path = Path(self.config.workspace.path) / name
|
||||
else:
|
||||
path = Path(CONFIG.project_path)
|
||||
if path.exists() and not CONFIG.inc:
|
||||
path = Path(self.config.project_path)
|
||||
if path.exists() and not self.config.inc:
|
||||
shutil.rmtree(path)
|
||||
CONFIG.project_path = path
|
||||
CONFIG.git_repo = GitRepository(local_path=path, auto_init=True)
|
||||
self.config.project_path = path
|
||||
self.context.git_repo = GitRepository(local_path=path, auto_init=True)
|
||||
self.context.repo = ProjectRepo(self.context.git_repo)
|
||||
|
||||
async def run(self, with_messages, **kwargs):
|
||||
"""Create and initialize the workspace folder, initialize the Git environment."""
|
||||
self._init_repo()
|
||||
|
||||
# Write the newly added requirements from the main parameter idea to `docs/requirement.txt`.
|
||||
doc = Document(root_path=DOCS_FILE_REPO, filename=REQUIREMENT_FILENAME, content=with_messages[0].content)
|
||||
await FileRepository.save_file(filename=REQUIREMENT_FILENAME, content=doc.content, relative_path=DOCS_FILE_REPO)
|
||||
|
||||
doc = await self.repo.docs.save(filename=REQUIREMENT_FILENAME, content=with_messages[0].content)
|
||||
# Send a Message notification to the WritePRD action, instructing it to process requirements using
|
||||
# `docs/requirement.txt` and `docs/prds/`.
|
||||
# `docs/requirement.txt` and `docs/prd/`.
|
||||
return ActionOutput(content=doc.content, instruct_content=doc)
|
||||
|
|
|
|||
|
|
@ -13,23 +13,16 @@
|
|||
import json
|
||||
from typing import Optional
|
||||
|
||||
from metagpt.actions import ActionOutput
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.actions.action_output import ActionOutput
|
||||
from metagpt.actions.project_management_an import PM_NODE, REFINED_PM_NODE
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import (
|
||||
PACKAGE_REQUIREMENTS_FILENAME,
|
||||
SYSTEM_DESIGN_FILE_REPO,
|
||||
TASK_FILE_REPO,
|
||||
TASK_PDF_FILE_REPO,
|
||||
)
|
||||
from metagpt.const import PACKAGE_REQUIREMENTS_FILENAME
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Document, Documents
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
|
||||
NEW_REQ_TEMPLATE = """
|
||||
### Legacy Content
|
||||
{old_tasks}
|
||||
{old_task}
|
||||
|
||||
### New Requirements
|
||||
{context}
|
||||
|
|
@ -38,30 +31,23 @@ NEW_REQ_TEMPLATE = """
|
|||
|
||||
class WriteTasks(Action):
|
||||
name: str = "CreateTasks"
|
||||
context: Optional[str] = None
|
||||
i_context: Optional[str] = None
|
||||
|
||||
async def run(self, with_messages, schema=CONFIG.prompt_schema):
|
||||
system_design_file_repo = CONFIG.git_repo.new_file_repository(SYSTEM_DESIGN_FILE_REPO)
|
||||
changed_system_designs = system_design_file_repo.changed_files
|
||||
|
||||
tasks_file_repo = CONFIG.git_repo.new_file_repository(TASK_FILE_REPO)
|
||||
changed_tasks = tasks_file_repo.changed_files
|
||||
async def run(self, with_messages):
|
||||
changed_system_designs = self.repo.docs.system_design.changed_files
|
||||
changed_tasks = self.repo.docs.task.changed_files
|
||||
change_files = Documents()
|
||||
# Rewrite the system designs that have undergone changes based on the git head diff under
|
||||
# `docs/system_designs/`.
|
||||
for filename in changed_system_designs:
|
||||
task_doc = await self._update_tasks(
|
||||
filename=filename, system_design_file_repo=system_design_file_repo, tasks_file_repo=tasks_file_repo
|
||||
)
|
||||
task_doc = await self._update_tasks(filename=filename)
|
||||
change_files.docs[filename] = task_doc
|
||||
|
||||
# Rewrite the task files that have undergone changes based on the git head diff under `docs/tasks/`.
|
||||
for filename in changed_tasks:
|
||||
if filename in change_files.docs:
|
||||
continue
|
||||
task_doc = await self._update_tasks(
|
||||
filename=filename, system_design_file_repo=system_design_file_repo, tasks_file_repo=tasks_file_repo
|
||||
)
|
||||
task_doc = await self._update_tasks(filename=filename)
|
||||
change_files.docs[filename] = task_doc
|
||||
|
||||
if not change_files.docs:
|
||||
|
|
@ -70,39 +56,36 @@ class WriteTasks(Action):
|
|||
# global optimization in subsequent steps.
|
||||
return ActionOutput(content=change_files.model_dump_json(), instruct_content=change_files)
|
||||
|
||||
async def _update_tasks(self, filename, system_design_file_repo, tasks_file_repo):
|
||||
system_design_doc = await system_design_file_repo.get(filename)
|
||||
task_doc = await tasks_file_repo.get(filename)
|
||||
async def _update_tasks(self, filename):
|
||||
system_design_doc = await self.repo.docs.system_design.get(filename)
|
||||
task_doc = await self.repo.docs.task.get(filename)
|
||||
if task_doc:
|
||||
task_doc = await self._merge(system_design_doc=system_design_doc, task_doc=task_doc)
|
||||
await self.repo.docs.task.save_doc(doc=task_doc, dependencies={system_design_doc.root_relative_path})
|
||||
else:
|
||||
rsp = await self._run_new_tasks(context=system_design_doc.content)
|
||||
task_doc = Document(
|
||||
root_path=TASK_FILE_REPO, filename=filename, content=rsp.instruct_content.model_dump_json()
|
||||
task_doc = await self.repo.docs.task.save(
|
||||
filename=filename,
|
||||
content=rsp.instruct_content.model_dump_json(),
|
||||
dependencies={system_design_doc.root_relative_path},
|
||||
)
|
||||
await tasks_file_repo.save(
|
||||
filename=filename, content=task_doc.content, dependencies={system_design_doc.root_relative_path}
|
||||
)
|
||||
await self._update_requirements(task_doc)
|
||||
await self._save_pdf(task_doc=task_doc)
|
||||
return task_doc
|
||||
|
||||
async def _run_new_tasks(self, context, schema=CONFIG.prompt_schema):
|
||||
node = await PM_NODE.fill(context, self.llm, schema)
|
||||
async def _run_new_tasks(self, context):
|
||||
node = await PM_NODE.fill(context, self.llm, schema=self.prompt_schema)
|
||||
return node
|
||||
|
||||
async def _merge(self, system_design_doc, task_doc, schema=CONFIG.prompt_schema) -> Document:
|
||||
context = NEW_REQ_TEMPLATE.format(context=system_design_doc.content, old_tasks=task_doc.content)
|
||||
node = await REFINED_PM_NODE.fill(context, self.llm, schema)
|
||||
async def _merge(self, system_design_doc, task_doc) -> Document:
|
||||
context = NEW_REQ_TEMPLATE.format(context=system_design_doc.content, old_task=task_doc.content)
|
||||
node = await REFINED_PM_NODE.fill(context, self.llm, schema=self.prompt_schema)
|
||||
task_doc.content = node.instruct_content.model_dump_json()
|
||||
return task_doc
|
||||
|
||||
@staticmethod
|
||||
async def _update_requirements(doc):
|
||||
async def _update_requirements(self, doc):
|
||||
m = json.loads(doc.content)
|
||||
packages = set(m.get("Required Python packages", set()))
|
||||
file_repo = CONFIG.git_repo.new_file_repository()
|
||||
requirement_doc = await file_repo.get(filename=PACKAGE_REQUIREMENTS_FILENAME)
|
||||
requirement_doc = await self.repo.get(filename=PACKAGE_REQUIREMENTS_FILENAME)
|
||||
if not requirement_doc:
|
||||
requirement_doc = Document(filename=PACKAGE_REQUIREMENTS_FILENAME, root_path=".", content="")
|
||||
lines = requirement_doc.content.splitlines()
|
||||
|
|
@ -110,8 +93,4 @@ class WriteTasks(Action):
|
|||
if pkg == "":
|
||||
continue
|
||||
packages.add(pkg)
|
||||
await file_repo.save(PACKAGE_REQUIREMENTS_FILENAME, content="\n".join(packages))
|
||||
|
||||
@staticmethod
|
||||
async def _save_pdf(task_doc):
|
||||
await FileRepository.save_as(doc=task_doc, with_suffix=".md", relative_path=TASK_PDF_FILE_REPO)
|
||||
await self.repo.save(filename=PACKAGE_REQUIREMENTS_FILENAME, content="\n".join(packages))
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ from pathlib import Path
|
|||
import aiofiles
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.config2 import config
|
||||
from metagpt.const import (
|
||||
AGGREGATION,
|
||||
COMPOSITION,
|
||||
|
|
@ -29,16 +29,16 @@ from metagpt.utils.graph_repository import GraphKeyword, GraphRepository
|
|||
|
||||
|
||||
class RebuildClassView(Action):
|
||||
async def run(self, with_messages=None, format=CONFIG.prompt_schema):
|
||||
graph_repo_pathname = CONFIG.git_repo.workdir / GRAPH_REPO_FILE_REPO / CONFIG.git_repo.workdir.name
|
||||
async def run(self, with_messages=None, format=config.prompt_schema):
|
||||
graph_repo_pathname = self.context.git_repo.workdir / GRAPH_REPO_FILE_REPO / self.context.git_repo.workdir.name
|
||||
graph_db = await DiGraphRepository.load_from(str(graph_repo_pathname.with_suffix(".json")))
|
||||
repo_parser = RepoParser(base_directory=Path(self.context))
|
||||
repo_parser = RepoParser(base_directory=Path(self.i_context))
|
||||
# use pylint
|
||||
class_views, relationship_views, package_root = await repo_parser.rebuild_class_views(path=Path(self.context))
|
||||
class_views, relationship_views, package_root = await repo_parser.rebuild_class_views(path=Path(self.i_context))
|
||||
await GraphRepository.update_graph_db_with_class_views(graph_db, class_views)
|
||||
await GraphRepository.update_graph_db_with_class_relationship_views(graph_db, relationship_views)
|
||||
# use ast
|
||||
direction, diff_path = self._diff_path(path_root=Path(self.context).resolve(), package_root=package_root)
|
||||
direction, diff_path = self._diff_path(path_root=Path(self.i_context).resolve(), package_root=package_root)
|
||||
symbols = repo_parser.generate_symbols()
|
||||
for file_info in symbols:
|
||||
# Align to the same root directory in accordance with `class_views`.
|
||||
|
|
@ -48,9 +48,9 @@ class RebuildClassView(Action):
|
|||
await graph_db.save()
|
||||
|
||||
async def _create_mermaid_class_views(self, graph_db):
|
||||
path = Path(CONFIG.git_repo.workdir) / DATA_API_DESIGN_FILE_REPO
|
||||
path = Path(self.context.git_repo.workdir) / DATA_API_DESIGN_FILE_REPO
|
||||
path.mkdir(parents=True, exist_ok=True)
|
||||
pathname = path / CONFIG.git_repo.workdir.name
|
||||
pathname = path / self.context.git_repo.workdir.name
|
||||
async with aiofiles.open(str(pathname.with_suffix(".mmd")), mode="w", encoding="utf-8") as writer:
|
||||
content = "classDiagram\n"
|
||||
logger.debug(content)
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ from pathlib import Path
|
|||
from typing import List
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.config2 import config
|
||||
from metagpt.const import GRAPH_REPO_FILE_REPO
|
||||
from metagpt.logs import logger
|
||||
from metagpt.utils.common import aread, list_files
|
||||
|
|
@ -21,8 +21,8 @@ from metagpt.utils.graph_repository import GraphKeyword
|
|||
|
||||
|
||||
class RebuildSequenceView(Action):
|
||||
async def run(self, with_messages=None, format=CONFIG.prompt_schema):
|
||||
graph_repo_pathname = CONFIG.git_repo.workdir / GRAPH_REPO_FILE_REPO / CONFIG.git_repo.workdir.name
|
||||
async def run(self, with_messages=None, format=config.prompt_schema):
|
||||
graph_repo_pathname = self.context.git_repo.workdir / GRAPH_REPO_FILE_REPO / self.context.git_repo.workdir.name
|
||||
graph_db = await DiGraphRepository.load_from(str(graph_repo_pathname.with_suffix(".json")))
|
||||
entries = await RebuildSequenceView._search_main_entry(graph_db)
|
||||
for entry in entries:
|
||||
|
|
@ -41,7 +41,9 @@ class RebuildSequenceView(Action):
|
|||
|
||||
async def _rebuild_sequence_view(self, entry, graph_db):
|
||||
filename = entry.subject.split(":", 1)[0]
|
||||
src_filename = RebuildSequenceView._get_full_filename(root=self.context, pathname=filename)
|
||||
src_filename = RebuildSequenceView._get_full_filename(root=self.i_context, pathname=filename)
|
||||
if not src_filename:
|
||||
return
|
||||
content = await aread(filename=src_filename, encoding="utf-8")
|
||||
content = f"```python\n{content}\n```\n\n---\nTranslate the code above into Mermaid Sequence Diagram."
|
||||
data = await self.llm.aask(
|
||||
|
|
|
|||
|
|
@ -3,17 +3,15 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import asyncio
|
||||
from typing import Callable, Optional, Union
|
||||
from typing import Any, Callable, Optional, Union
|
||||
|
||||
from pydantic import Field, parse_obj_as
|
||||
from pydantic import TypeAdapter, model_validator
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.config2 import config
|
||||
from metagpt.logs import logger
|
||||
from metagpt.provider.base_llm import BaseLLM
|
||||
from metagpt.tools.search_engine import SearchEngine
|
||||
from metagpt.tools.web_browser_engine import WebBrowserEngine, WebBrowserEngineType
|
||||
from metagpt.tools.web_browser_engine import WebBrowserEngine
|
||||
from metagpt.utils.common import OutputParser
|
||||
from metagpt.utils.text import generate_prompt_chunk, reduce_message_length
|
||||
|
||||
|
|
@ -81,12 +79,18 @@ class CollectLinks(Action):
|
|||
"""Action class to collect links from a search engine."""
|
||||
|
||||
name: str = "CollectLinks"
|
||||
context: Optional[str] = None
|
||||
i_context: Optional[str] = None
|
||||
desc: str = "Collect links from a search engine."
|
||||
|
||||
search_engine: SearchEngine = Field(default_factory=SearchEngine)
|
||||
search_func: Optional[Any] = None
|
||||
search_engine: Optional[SearchEngine] = None
|
||||
rank_func: Optional[Callable[[list[str]], None]] = None
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_engine_and_run_func(self):
|
||||
if self.search_engine is None:
|
||||
self.search_engine = SearchEngine.from_search_config(self.config.search, proxy=self.config.proxy)
|
||||
return self
|
||||
|
||||
async def run(
|
||||
self,
|
||||
topic: str,
|
||||
|
|
@ -109,7 +113,7 @@ class CollectLinks(Action):
|
|||
keywords = await self._aask(SEARCH_TOPIC_PROMPT, [system_text])
|
||||
try:
|
||||
keywords = OutputParser.extract_struct(keywords, list)
|
||||
keywords = parse_obj_as(list[str], keywords)
|
||||
keywords = TypeAdapter(list[str]).validate_python(keywords)
|
||||
except Exception as e:
|
||||
logger.exception(f"fail to get keywords related to the research topic '{topic}' for {e}")
|
||||
keywords = [topic]
|
||||
|
|
@ -129,13 +133,13 @@ class CollectLinks(Action):
|
|||
if len(remove) == 0:
|
||||
break
|
||||
|
||||
model_name = CONFIG.get_model_name(CONFIG.get_default_llm_provider_enum())
|
||||
prompt = reduce_message_length(gen_msg(), model_name, system_text, CONFIG.max_tokens_rsp)
|
||||
model_name = config.get_openai_llm().model
|
||||
prompt = reduce_message_length(gen_msg(), model_name, system_text, 4096)
|
||||
logger.debug(prompt)
|
||||
queries = await self._aask(prompt, [system_text])
|
||||
try:
|
||||
queries = OutputParser.extract_struct(queries, list)
|
||||
queries = parse_obj_as(list[str], queries)
|
||||
queries = TypeAdapter(list[str]).validate_python(queries)
|
||||
except Exception as e:
|
||||
logger.exception(f"fail to break down the research question due to {e}")
|
||||
queries = keywords
|
||||
|
|
@ -177,21 +181,20 @@ class WebBrowseAndSummarize(Action):
|
|||
"""Action class to explore the web and provide summaries of articles and webpages."""
|
||||
|
||||
name: str = "WebBrowseAndSummarize"
|
||||
context: Optional[str] = None
|
||||
llm: BaseLLM = Field(default_factory=LLM)
|
||||
i_context: Optional[str] = None
|
||||
desc: str = "Explore the web and provide summaries of articles and webpages."
|
||||
browse_func: Union[Callable[[list[str]], None], None] = None
|
||||
web_browser_engine: Optional[WebBrowserEngine] = None
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
if CONFIG.model_for_researcher_summary:
|
||||
self.llm.model = CONFIG.model_for_researcher_summary
|
||||
|
||||
self.web_browser_engine = WebBrowserEngine(
|
||||
engine=WebBrowserEngineType.CUSTOM if self.browse_func else None,
|
||||
run_func=self.browse_func,
|
||||
)
|
||||
@model_validator(mode="after")
|
||||
def validate_engine_and_run_func(self):
|
||||
if self.web_browser_engine is None:
|
||||
self.web_browser_engine = WebBrowserEngine.from_browser_config(
|
||||
self.config.browser,
|
||||
browse_func=self.browse_func,
|
||||
proxy=self.config.proxy,
|
||||
)
|
||||
return self
|
||||
|
||||
async def run(
|
||||
self,
|
||||
|
|
@ -220,9 +223,7 @@ class WebBrowseAndSummarize(Action):
|
|||
for u, content in zip([url, *urls], contents):
|
||||
content = content.inner_text
|
||||
chunk_summaries = []
|
||||
for prompt in generate_prompt_chunk(
|
||||
content, prompt_template, self.llm.model, system_text, CONFIG.max_tokens_rsp
|
||||
):
|
||||
for prompt in generate_prompt_chunk(content, prompt_template, self.llm.model, system_text, 4096):
|
||||
logger.debug(prompt)
|
||||
summary = await self._aask(prompt, [system_text])
|
||||
if summary == "Not relevant.":
|
||||
|
|
@ -247,14 +248,8 @@ class WebBrowseAndSummarize(Action):
|
|||
class ConductResearch(Action):
|
||||
"""Action class to conduct research and generate a research report."""
|
||||
|
||||
name: str = "ConductResearch"
|
||||
context: Optional[str] = None
|
||||
llm: BaseLLM = Field(default_factory=LLM)
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
if CONFIG.model_for_researcher_report:
|
||||
self.llm.model = CONFIG.model_for_researcher_report
|
||||
|
||||
async def run(
|
||||
self,
|
||||
|
|
|
|||
|
|
@ -22,7 +22,6 @@ from typing import Tuple
|
|||
from pydantic import Field
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import RunCodeContext, RunCodeResult
|
||||
from metagpt.utils.exceptions import handle_exception
|
||||
|
|
@ -49,7 +48,7 @@ WRITE ONLY ONE WORD, NoOne OR Engineer OR QaEngineer, IN THIS SECTION.
|
|||
You should fill in necessary instruction, status, send to, and finally return all content between the --- segment line.
|
||||
"""
|
||||
|
||||
CONTEXT = """
|
||||
TEMPLATE_CONTEXT = """
|
||||
## Development Code File Name
|
||||
{code_file_name}
|
||||
## Development Code
|
||||
|
|
@ -78,7 +77,7 @@ standard errors:
|
|||
|
||||
class RunCode(Action):
|
||||
name: str = "RunCode"
|
||||
context: RunCodeContext = Field(default_factory=RunCodeContext)
|
||||
i_context: RunCodeContext = Field(default_factory=RunCodeContext)
|
||||
|
||||
@classmethod
|
||||
async def run_text(cls, code) -> Tuple[str, str]:
|
||||
|
|
@ -90,13 +89,12 @@ class RunCode(Action):
|
|||
return "", str(e)
|
||||
return namespace.get("result", ""), ""
|
||||
|
||||
@classmethod
|
||||
async def run_script(cls, working_directory, additional_python_paths=[], command=[]) -> Tuple[str, str]:
|
||||
async def run_script(self, working_directory, additional_python_paths=[], command=[]) -> Tuple[str, str]:
|
||||
working_directory = str(working_directory)
|
||||
additional_python_paths = [str(path) for path in additional_python_paths]
|
||||
|
||||
# Copy the current environment variables
|
||||
env = CONFIG.new_environ()
|
||||
env = self.context.new_environ()
|
||||
|
||||
# Modify the PYTHONPATH environment variable
|
||||
additional_python_paths = [working_directory] + additional_python_paths
|
||||
|
|
@ -120,25 +118,25 @@ class RunCode(Action):
|
|||
return stdout.decode("utf-8"), stderr.decode("utf-8")
|
||||
|
||||
async def run(self, *args, **kwargs) -> RunCodeResult:
|
||||
logger.info(f"Running {' '.join(self.context.command)}")
|
||||
if self.context.mode == "script":
|
||||
logger.info(f"Running {' '.join(self.i_context.command)}")
|
||||
if self.i_context.mode == "script":
|
||||
outs, errs = await self.run_script(
|
||||
command=self.context.command,
|
||||
working_directory=self.context.working_directory,
|
||||
additional_python_paths=self.context.additional_python_paths,
|
||||
command=self.i_context.command,
|
||||
working_directory=self.i_context.working_directory,
|
||||
additional_python_paths=self.i_context.additional_python_paths,
|
||||
)
|
||||
elif self.context.mode == "text":
|
||||
outs, errs = await self.run_text(code=self.context.code)
|
||||
elif self.i_context.mode == "text":
|
||||
outs, errs = await self.run_text(code=self.i_context.code)
|
||||
|
||||
logger.info(f"{outs=}")
|
||||
logger.info(f"{errs=}")
|
||||
|
||||
context = CONTEXT.format(
|
||||
code=self.context.code,
|
||||
code_file_name=self.context.code_filename,
|
||||
test_code=self.context.test_code,
|
||||
test_file_name=self.context.test_filename,
|
||||
command=" ".join(self.context.command),
|
||||
context = TEMPLATE_CONTEXT.format(
|
||||
code=self.i_context.code,
|
||||
code_file_name=self.i_context.code_filename,
|
||||
test_code=self.i_context.test_code,
|
||||
test_file_name=self.i_context.test_filename,
|
||||
command=" ".join(self.i_context.command),
|
||||
outs=outs[:500], # outs might be long but they are not important, truncate them to avoid token overflow
|
||||
errs=errs[:10000], # truncate errors to avoid token overflow
|
||||
)
|
||||
|
|
|
|||
|
|
@ -5,16 +5,14 @@
|
|||
@Author : alexanderwu
|
||||
@File : search_google.py
|
||||
"""
|
||||
from typing import Any, Optional
|
||||
from typing import Optional
|
||||
|
||||
import pydantic
|
||||
from pydantic import Field, model_validator
|
||||
from pydantic import model_validator
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.config import CONFIG, Config
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Message
|
||||
from metagpt.tools import SearchEngineType
|
||||
from metagpt.tools.search_engine import SearchEngine
|
||||
|
||||
SEARCH_AND_SUMMARIZE_SYSTEM = """### Requirements
|
||||
|
|
@ -103,32 +101,23 @@ You are a member of a professional butler team and will provide helpful suggesti
|
|||
"""
|
||||
|
||||
|
||||
# TOTEST
|
||||
class SearchAndSummarize(Action):
|
||||
name: str = ""
|
||||
content: Optional[str] = None
|
||||
config: None = Field(default_factory=Config)
|
||||
engine: Optional[SearchEngineType] = CONFIG.search_engine
|
||||
search_func: Optional[Any] = None
|
||||
search_engine: SearchEngine = None
|
||||
result: str = ""
|
||||
|
||||
@model_validator(mode="before")
|
||||
@classmethod
|
||||
def validate_engine_and_run_func(cls, values):
|
||||
engine = values.get("engine")
|
||||
search_func = values.get("search_func")
|
||||
config = Config()
|
||||
@model_validator(mode="after")
|
||||
def validate_search_engine(self):
|
||||
if self.search_engine is None:
|
||||
try:
|
||||
config = self.config
|
||||
search_engine = SearchEngine.from_search_config(config.search, proxy=config.proxy)
|
||||
except pydantic.ValidationError:
|
||||
search_engine = None
|
||||
|
||||
if engine is None:
|
||||
engine = config.search_engine
|
||||
try:
|
||||
search_engine = SearchEngine(engine=engine, run_func=search_func)
|
||||
except pydantic.ValidationError:
|
||||
search_engine = None
|
||||
|
||||
values["search_engine"] = search_engine
|
||||
return values
|
||||
self.search_engine = search_engine
|
||||
return self
|
||||
|
||||
async def run(self, context: list[Message], system_text=SEARCH_AND_SUMMARIZE_SYSTEM) -> str:
|
||||
if self.search_engine is None:
|
||||
|
|
|
|||
|
|
@ -29,9 +29,7 @@ class ArgumentsParingAction(Action):
|
|||
|
||||
@property
|
||||
def prompt(self):
|
||||
prompt = "You are a function parser. You can convert spoken words into function parameters.\n"
|
||||
prompt += "\n---\n"
|
||||
prompt += f"{self.skill.name} function parameters description:\n"
|
||||
prompt = f"{self.skill.name} function parameters description:\n"
|
||||
for k, v in self.skill.arguments.items():
|
||||
prompt += f"parameter `{k}`: {v}\n"
|
||||
prompt += "\n---\n"
|
||||
|
|
@ -49,7 +47,10 @@ class ArgumentsParingAction(Action):
|
|||
|
||||
async def run(self, with_message=None, **kwargs) -> Message:
|
||||
prompt = self.prompt
|
||||
rsp = await self.llm.aask(msg=prompt, system_msgs=[])
|
||||
rsp = await self.llm.aask(
|
||||
msg=prompt,
|
||||
system_msgs=["You are a function parser.", "You can convert spoken words into function parameters."],
|
||||
)
|
||||
logger.debug(f"SKILL:{prompt}\n, RESULT:{rsp}")
|
||||
self.args = ArgumentsParingAction.parse_arguments(skill_name=self.skill.name, txt=rsp)
|
||||
self.rsp = Message(content=rsp, role="assistant", instruct_content=self.args, cause_by=self)
|
||||
|
|
|
|||
|
|
@ -11,11 +11,8 @@ from pydantic import Field
|
|||
from tenacity import retry, stop_after_attempt, wait_random_exponential
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import SYSTEM_DESIGN_FILE_REPO, TASK_FILE_REPO
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import CodeSummarizeContext
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
NOTICE
|
||||
|
|
@ -29,9 +26,9 @@ ATTENTION: Use '##' to SPLIT SECTIONS, not '#'. Output format carefully referenc
|
|||
{system_design}
|
||||
```
|
||||
-----
|
||||
# Tasks
|
||||
# Task
|
||||
```text
|
||||
{tasks}
|
||||
{task}
|
||||
```
|
||||
-----
|
||||
{code_blocks}
|
||||
|
|
@ -90,10 +87,9 @@ flowchart TB
|
|||
"""
|
||||
|
||||
|
||||
# TOTEST
|
||||
class SummarizeCode(Action):
|
||||
name: str = "SummarizeCode"
|
||||
context: CodeSummarizeContext = Field(default_factory=CodeSummarizeContext)
|
||||
i_context: CodeSummarizeContext = Field(default_factory=CodeSummarizeContext)
|
||||
|
||||
@retry(stop=stop_after_attempt(2), wait=wait_random_exponential(min=1, max=60))
|
||||
async def summarize_code(self, prompt):
|
||||
|
|
@ -101,20 +97,20 @@ class SummarizeCode(Action):
|
|||
return code_rsp
|
||||
|
||||
async def run(self):
|
||||
design_pathname = Path(self.context.design_filename)
|
||||
design_doc = await FileRepository.get_file(filename=design_pathname.name, relative_path=SYSTEM_DESIGN_FILE_REPO)
|
||||
task_pathname = Path(self.context.task_filename)
|
||||
task_doc = await FileRepository.get_file(filename=task_pathname.name, relative_path=TASK_FILE_REPO)
|
||||
src_file_repo = CONFIG.git_repo.new_file_repository(relative_path=CONFIG.src_workspace)
|
||||
design_pathname = Path(self.i_context.design_filename)
|
||||
design_doc = await self.repo.docs.system_design.get(filename=design_pathname.name)
|
||||
task_pathname = Path(self.i_context.task_filename)
|
||||
task_doc = await self.repo.docs.task.get(filename=task_pathname.name)
|
||||
src_file_repo = self.repo.with_src_path(self.context.src_workspace).srcs
|
||||
code_blocks = []
|
||||
for filename in self.context.codes_filenames:
|
||||
for filename in self.i_context.codes_filenames:
|
||||
code_doc = await src_file_repo.get(filename)
|
||||
code_block = f"```python\n{code_doc.content}\n```\n-----"
|
||||
code_blocks.append(code_block)
|
||||
format_example = FORMAT_EXAMPLE
|
||||
prompt = PROMPT_TEMPLATE.format(
|
||||
system_design=design_doc.content,
|
||||
tasks=task_doc.content,
|
||||
task=task_doc.content,
|
||||
code_blocks="\n".join(code_blocks),
|
||||
format_example=format_example,
|
||||
)
|
||||
|
|
|
|||
|
|
@ -9,25 +9,31 @@
|
|||
from typing import Optional
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import DEFAULT_LANGUAGE
|
||||
from metagpt.config2 import config
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Message
|
||||
|
||||
|
||||
# TOTEST
|
||||
class TalkAction(Action):
|
||||
context: str
|
||||
i_context: str
|
||||
history_summary: str = ""
|
||||
knowledge: str = ""
|
||||
rsp: Optional[Message] = None
|
||||
|
||||
@property
|
||||
def agent_description(self):
|
||||
return self.context.kwargs.agent_description
|
||||
|
||||
@property
|
||||
def language(self):
|
||||
return self.context.kwargs.language or config.language
|
||||
|
||||
@property
|
||||
def prompt(self):
|
||||
prompt = ""
|
||||
if CONFIG.agent_description:
|
||||
if self.agent_description:
|
||||
prompt = (
|
||||
f"You are {CONFIG.agent_description}. Your responses should align with the role-play agreement, "
|
||||
f"You are {self.agent_description}. Your responses should align with the role-play agreement, "
|
||||
f"maintaining the character's persona and habits. When faced with unrelated questions, playfully "
|
||||
f"decline to answer without revealing your AI nature to preserve the character's image.\n\n"
|
||||
)
|
||||
|
|
@ -36,10 +42,10 @@ class TalkAction(Action):
|
|||
prompt += (
|
||||
"If the information is insufficient, you can search in the historical conversation or knowledge above.\n"
|
||||
)
|
||||
language = CONFIG.language or DEFAULT_LANGUAGE
|
||||
language = self.language
|
||||
prompt += (
|
||||
f"Answer the following questions strictly in {language}, and the answers must follow the Markdown format.\n "
|
||||
f"{self.context}"
|
||||
f"{self.i_context}"
|
||||
)
|
||||
logger.debug(f"PROMPT: {prompt}")
|
||||
return prompt
|
||||
|
|
@ -47,11 +53,11 @@ class TalkAction(Action):
|
|||
@property
|
||||
def prompt_gpt4(self):
|
||||
kvs = {
|
||||
"{role}": CONFIG.agent_description or "",
|
||||
"{role}": self.agent_description or "",
|
||||
"{history}": self.history_summary or "",
|
||||
"{knowledge}": self.knowledge or "",
|
||||
"{language}": CONFIG.language or DEFAULT_LANGUAGE,
|
||||
"{ask}": self.context,
|
||||
"{language}": self.language,
|
||||
"{ask}": self.i_context,
|
||||
}
|
||||
prompt = TalkActionPrompt.FORMATION_LOOSE
|
||||
for k, v in kvs.items():
|
||||
|
|
@ -68,9 +74,9 @@ class TalkAction(Action):
|
|||
|
||||
@property
|
||||
def aask_args(self):
|
||||
language = CONFIG.language or DEFAULT_LANGUAGE
|
||||
language = self.language
|
||||
system_msgs = [
|
||||
f"You are {CONFIG.agent_description}.",
|
||||
f"You are {self.agent_description}.",
|
||||
"Your responses should align with the role-play agreement, "
|
||||
"maintaining the character's persona and habits. When faced with unrelated questions, playfully "
|
||||
"decline to answer without revealing your AI nature to preserve the character's image.",
|
||||
|
|
@ -82,7 +88,7 @@ class TalkAction(Action):
|
|||
format_msgs.append({"role": "assistant", "content": self.knowledge})
|
||||
if self.history_summary:
|
||||
format_msgs.append({"role": "assistant", "content": self.history_summary})
|
||||
return self.context, format_msgs, system_msgs
|
||||
return self.i_context, format_msgs, system_msgs
|
||||
|
||||
async def run(self, with_message=None, **kwargs) -> Message:
|
||||
msg, format_msgs, system_msgs = self.aask_args
|
||||
|
|
|
|||
|
|
@ -16,7 +16,6 @@
|
|||
"""
|
||||
|
||||
import json
|
||||
from typing import Literal
|
||||
|
||||
from pydantic import Field
|
||||
from tenacity import retry, stop_after_attempt, wait_random_exponential
|
||||
|
|
@ -24,21 +23,15 @@ from tenacity import retry, stop_after_attempt, wait_random_exponential
|
|||
from metagpt.actions.action import Action
|
||||
from metagpt.actions.project_management_an import REFINED_TASK_LIST, TASK_LIST
|
||||
from metagpt.actions.write_code_plan_and_change_an import REFINED_TEMPLATE
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import (
|
||||
BUGFIX_FILENAME,
|
||||
CODE_PLAN_AND_CHANGE_FILE_REPO,
|
||||
CODE_PLAN_AND_CHANGE_FILENAME,
|
||||
CODE_SUMMARIES_FILE_REPO,
|
||||
DOCS_FILE_REPO,
|
||||
REQUIREMENT_FILENAME,
|
||||
TASK_FILE_REPO,
|
||||
TEST_OUTPUTS_FILE_REPO,
|
||||
)
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import CodingContext, Document, RunCodeResult
|
||||
from metagpt.utils.common import CodeParser
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
from metagpt.utils.project_repo import ProjectRepo
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
NOTICE
|
||||
|
|
@ -50,8 +43,8 @@ ATTENTION: Use '##' to SPLIT SECTIONS, not '#'. Output format carefully referenc
|
|||
## Design
|
||||
{design}
|
||||
|
||||
## Tasks
|
||||
{tasks}
|
||||
## Task
|
||||
{task}
|
||||
|
||||
## Legacy Code
|
||||
```Code
|
||||
|
|
@ -93,7 +86,7 @@ ATTENTION: Use '##' to SPLIT SECTIONS, not '#'. Output format carefully referenc
|
|||
|
||||
class WriteCode(Action):
|
||||
name: str = "WriteCode"
|
||||
context: Document = Field(default_factory=Document)
|
||||
i_context: Document = Field(default_factory=Document)
|
||||
|
||||
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
|
||||
async def write_code(self, prompt) -> str:
|
||||
|
|
@ -102,21 +95,15 @@ class WriteCode(Action):
|
|||
return code
|
||||
|
||||
async def run(self, *args, **kwargs) -> CodingContext:
|
||||
bug_feedback = await FileRepository.get_file(filename=BUGFIX_FILENAME, relative_path=DOCS_FILE_REPO)
|
||||
coding_context = CodingContext.loads(self.context.content)
|
||||
test_doc = await FileRepository.get_file(
|
||||
filename="test_" + coding_context.filename + ".json", relative_path=TEST_OUTPUTS_FILE_REPO
|
||||
)
|
||||
code_plan_and_change_doc = await FileRepository.get_file(
|
||||
filename=CODE_PLAN_AND_CHANGE_FILENAME, relative_path=CODE_PLAN_AND_CHANGE_FILE_REPO
|
||||
)
|
||||
bug_feedback = await self.repo.docs.get(filename=BUGFIX_FILENAME)
|
||||
coding_context = CodingContext.loads(self.i_context.content)
|
||||
test_doc = await self.repo.test_outputs.get(filename="test_" + coding_context.filename + ".json")
|
||||
code_plan_and_change_doc = await self.repo.docs.code_plan_and_change.get(filename=CODE_PLAN_AND_CHANGE_FILENAME)
|
||||
code_plan_and_change = code_plan_and_change_doc.content if code_plan_and_change_doc else ""
|
||||
requirement_doc = await FileRepository.get_file(filename=REQUIREMENT_FILENAME, relative_path=DOCS_FILE_REPO)
|
||||
requirement_doc = await self.repo.docs.get(filename=REQUIREMENT_FILENAME)
|
||||
summary_doc = None
|
||||
if coding_context.design_doc and coding_context.design_doc.filename:
|
||||
summary_doc = await FileRepository.get_file(
|
||||
filename=coding_context.design_doc.filename, relative_path=CODE_SUMMARIES_FILE_REPO
|
||||
)
|
||||
summary_doc = await self.repo.docs.code_summary.get(filename=coding_context.design_doc.filename)
|
||||
logs = ""
|
||||
if test_doc:
|
||||
test_detail = RunCodeResult.loads(test_doc.content)
|
||||
|
|
@ -126,91 +113,91 @@ class WriteCode(Action):
|
|||
code_context = coding_context.code_doc.content
|
||||
elif code_plan_and_change:
|
||||
code_context = await self.get_codes(
|
||||
coding_context.task_doc, exclude=self.context.filename, mode="incremental"
|
||||
coding_context.task_doc, exclude=self.i_context.filename, project_repo=self.repo, use_inc=True
|
||||
)
|
||||
else:
|
||||
code_context = await self.get_codes(coding_context.task_doc, exclude=self.context.filename)
|
||||
code_context = await self.get_codes(
|
||||
coding_context.task_doc,
|
||||
exclude=self.i_context.filename,
|
||||
project_repo=self.repo.with_src_path(self.context.src_workspace),
|
||||
)
|
||||
|
||||
if code_plan_and_change:
|
||||
prompt = REFINED_TEMPLATE.format(
|
||||
user_requirement=requirement_doc.content if requirement_doc else "",
|
||||
code_plan_and_change=code_plan_and_change,
|
||||
design=coding_context.design_doc.content if coding_context.design_doc else "",
|
||||
tasks=coding_context.task_doc.content if coding_context.task_doc else "",
|
||||
task=coding_context.task_doc.content if coding_context.task_doc else "",
|
||||
code=code_context,
|
||||
logs=logs,
|
||||
feedback=bug_feedback.content if bug_feedback else "",
|
||||
filename=self.context.filename,
|
||||
filename=self.i_context.filename,
|
||||
summary_log=summary_doc.content if summary_doc else "",
|
||||
)
|
||||
else:
|
||||
prompt = PROMPT_TEMPLATE.format(
|
||||
design=coding_context.design_doc.content if coding_context.design_doc else "",
|
||||
tasks=coding_context.task_doc.content if coding_context.task_doc else "",
|
||||
task=coding_context.task_doc.content if coding_context.task_doc else "",
|
||||
code=code_context,
|
||||
logs=logs,
|
||||
feedback=bug_feedback.content if bug_feedback else "",
|
||||
filename=self.context.filename,
|
||||
filename=self.i_context.filename,
|
||||
summary_log=summary_doc.content if summary_doc else "",
|
||||
)
|
||||
logger.info(f"Writing {coding_context.filename}..")
|
||||
code = await self.write_code(prompt)
|
||||
if not coding_context.code_doc:
|
||||
# avoid root_path pydantic ValidationError if use WriteCode alone
|
||||
root_path = CONFIG.src_workspace if CONFIG.src_workspace else ""
|
||||
root_path = self.context.src_workspace if self.context.src_workspace else ""
|
||||
coding_context.code_doc = Document(filename=coding_context.filename, root_path=str(root_path))
|
||||
coding_context.code_doc.content = code
|
||||
return coding_context
|
||||
|
||||
@staticmethod
|
||||
async def get_codes(task_doc: Document, exclude: str, mode: Literal["normal", "incremental"] = "normal") -> str:
|
||||
async def get_codes(task_doc: Document, exclude: str, project_repo: ProjectRepo, use_inc: bool = False) -> str:
|
||||
"""
|
||||
Get code snippets based on different modes.
|
||||
Get codes for generating the exclude file in various scenarios.
|
||||
|
||||
Attributes:
|
||||
task_doc (Document): Document object of the task file.
|
||||
exclude (str): Specifies the filename to be excluded from the code snippets.
|
||||
mode (str): Specifies the mode, either "normal" or "incremental" (default is "normal").
|
||||
exclude (str): The file to be generated. Specifies the filename to be excluded from the code snippets.
|
||||
project_repo (ProjectRepo): ProjectRepo object of the project.
|
||||
use_inc (bool): Indicates whether the scenario involves incremental development. Defaults to False.
|
||||
|
||||
Returns:
|
||||
str: Code snippets.
|
||||
|
||||
Description:
|
||||
If mode is set to "normal", it returns code snippets for the regular coding phase,
|
||||
i.e., all the code generated before writing the current file.
|
||||
|
||||
If mode is set to "incremental", it returns code snippets for generating the code plan and change,
|
||||
building upon the existing code in the "normal" mode and adding code for the current file's older versions.
|
||||
str: Codes for generating the exclude file.
|
||||
"""
|
||||
if not task_doc:
|
||||
return ""
|
||||
if not task_doc.content:
|
||||
task_doc.content = FileRepository.get_file(filename=task_doc.filename, relative_path=TASK_FILE_REPO)
|
||||
task_doc = project_repo.docs.task.get(filename=task_doc.filename)
|
||||
m = json.loads(task_doc.content)
|
||||
code_filenames = m.get(TASK_LIST.key, []) if mode == "normal" else m.get(REFINED_TASK_LIST.key, [])
|
||||
code_filenames = m.get(TASK_LIST.key, []) if use_inc else m.get(REFINED_TASK_LIST.key, [])
|
||||
codes = []
|
||||
src_file_repo = CONFIG.git_repo.new_file_repository(relative_path=CONFIG.src_workspace)
|
||||
src_file_repo = project_repo.srcs
|
||||
|
||||
if mode == "incremental":
|
||||
# Incremental development scenario
|
||||
if use_inc:
|
||||
src_files = src_file_repo.all_files
|
||||
old_file_repo = CONFIG.git_repo.new_file_repository(relative_path=CONFIG.old_workspace)
|
||||
# Get the old workspace contained the old codes and old workspace are created in previous CodePlanAndChange
|
||||
old_file_repo = project_repo.git_repo.new_file_repository(relative_path=project_repo.old_workspace)
|
||||
old_files = old_file_repo.all_files
|
||||
# Get the union of the files in the src and old workspaces
|
||||
union_files_list = list(set(src_files) | set(old_files))
|
||||
for filename in union_files_list:
|
||||
# Exclude the current file from the all code snippets to get the context code snippets for generating
|
||||
# Exclude the current file from the all code snippets
|
||||
if filename == exclude:
|
||||
# If the file is in the old workspace, use the legacy code
|
||||
# If the file is in the old workspace, use the old code
|
||||
# Exclude unnecessary code to maintain a clean and focused main.py file, ensuring only relevant and
|
||||
# essential functionality is included for the project’s requirements
|
||||
if filename in old_files and filename != "main.py":
|
||||
# Use legacy code
|
||||
# Use old code
|
||||
doc = await old_file_repo.get(filename=filename)
|
||||
# If the file is in the src workspace, skip it
|
||||
else:
|
||||
continue
|
||||
codes.insert(0, f"-----Now, {filename} to be rewritten\n```{doc.content}```\n=====")
|
||||
# The context code snippets are generated from the src workspace
|
||||
# The code snippets are generated from the src workspace
|
||||
else:
|
||||
doc = await src_file_repo.get(filename=filename)
|
||||
# If the file does not exist in the src workspace, skip it
|
||||
|
|
@ -218,9 +205,10 @@ class WriteCode(Action):
|
|||
continue
|
||||
codes.append(f"----- {filename}\n```{doc.content}```")
|
||||
|
||||
elif mode == "normal":
|
||||
# Normal scenario
|
||||
else:
|
||||
for filename in code_filenames:
|
||||
# Exclude the current file to get the context code snippets for generating the current file
|
||||
# Exclude the current file to get the code snippets for generating the current file
|
||||
if filename == exclude:
|
||||
continue
|
||||
doc = await src_file_repo.get(filename=filename)
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@
|
|||
@File : write_review.py
|
||||
"""
|
||||
import asyncio
|
||||
from typing import List
|
||||
from typing import List, Literal
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
|
|
@ -21,16 +21,15 @@ REVIEW = ActionNode(
|
|||
],
|
||||
)
|
||||
|
||||
LGTM = ActionNode(
|
||||
key="LGTM",
|
||||
expected_type=str,
|
||||
instruction="LGTM/LBTM. If the code is fully implemented, "
|
||||
"give a LGTM (Looks Good To Me), otherwise provide a LBTM (Looks Bad To Me).",
|
||||
REVIEW_RESULT = ActionNode(
|
||||
key="ReviewResult",
|
||||
expected_type=Literal["LGTM", "LBTM"],
|
||||
instruction="LGTM/LBTM. If the code is fully implemented, " "give a LGTM, otherwise provide a LBTM.",
|
||||
example="LBTM",
|
||||
)
|
||||
|
||||
ACTIONS = ActionNode(
|
||||
key="Actions",
|
||||
NEXT_STEPS = ActionNode(
|
||||
key="NextSteps",
|
||||
expected_type=str,
|
||||
instruction="Based on the code review outcome, suggest actionable steps. This can include code changes, "
|
||||
"refactoring suggestions, or any follow-up tasks.",
|
||||
|
|
@ -69,7 +68,7 @@ WRITE_DRAFT = ActionNode(
|
|||
)
|
||||
|
||||
|
||||
WRITE_MOVE_FUNCTION = ActionNode(
|
||||
WRITE_FUNCTION = ActionNode(
|
||||
key="WriteFunction",
|
||||
expected_type=str,
|
||||
instruction="write code for the function not implemented.",
|
||||
|
|
@ -555,8 +554,8 @@ LBTM
|
|||
"""
|
||||
|
||||
|
||||
WRITE_CODE_NODE = ActionNode.from_children("WRITE_REVIEW_NODE", [REVIEW, LGTM, ACTIONS])
|
||||
WRITE_MOVE_NODE = ActionNode.from_children("WRITE_MOVE_NODE", [WRITE_DRAFT, WRITE_MOVE_FUNCTION])
|
||||
WRITE_CODE_NODE = ActionNode.from_children("WRITE_REVIEW_NODE", [REVIEW, REVIEW_RESULT, NEXT_STEPS])
|
||||
WRITE_MOVE_NODE = ActionNode.from_children("WRITE_MOVE_NODE", [WRITE_DRAFT, WRITE_FUNCTION])
|
||||
|
||||
|
||||
CR_FOR_MOVE_FUNCTION_BY_3 = """
|
||||
|
|
@ -579,8 +578,7 @@ class WriteCodeAN(Action):
|
|||
|
||||
async def run(self, context):
|
||||
self.llm.system_prompt = "You are an outstanding engineer and can implement any code"
|
||||
return await WRITE_MOVE_FUNCTION.fill(context=context, llm=self.llm, schema="json")
|
||||
# return await WRITE_CODE_NODE.fill(context=context, llm=self.llm, schema="markdown")
|
||||
return await WRITE_MOVE_NODE.fill(context=context, llm=self.llm, schema="json")
|
||||
|
||||
|
||||
async def main():
|
||||
|
|
|
|||
|
|
@ -11,7 +11,6 @@ from pydantic import Field
|
|||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.schema import CodePlanAndChangeContext
|
||||
|
||||
CODE_PLAN_AND_CHANGE = ActionNode(
|
||||
|
|
@ -119,8 +118,8 @@ CODE_PLAN_AND_CHANGE_CONTEXT = """
|
|||
## Design
|
||||
{design}
|
||||
|
||||
## Tasks
|
||||
{tasks}
|
||||
## Task
|
||||
{task}
|
||||
|
||||
## Legacy Code
|
||||
{code}
|
||||
|
|
@ -140,8 +139,8 @@ Role: You are a professional engineer; The main goal is to complete incremental
|
|||
## Design
|
||||
{design}
|
||||
|
||||
## Tasks
|
||||
{tasks}
|
||||
## Task
|
||||
{task}
|
||||
|
||||
## Legacy Code
|
||||
```Code
|
||||
|
|
@ -173,11 +172,11 @@ Role: You are a professional engineer; The main goal is to complete incremental
|
|||
2. COMPLETE CODE: Your code will be part of the entire project, so please implement complete, reliable, reusable code snippets.
|
||||
3. Set default value: If there is any setting, ALWAYS SET A DEFAULT VALUE, ALWAYS USE STRONG TYPE AND EXPLICIT VARIABLE. AVOID circular import.
|
||||
4. Follow design: YOU MUST FOLLOW "Data structures and interfaces". DONT CHANGE ANY DESIGN. Do not use public member functions that do not exist in your design.
|
||||
5. Follow Code Plan And Change: If there is any Incremental Change or Legacy Code files contain "{filename} to be rewritten", you must merge it into the code file according to the plan.
|
||||
5. Follow Code Plan And Change: If there is any Incremental Change that is marked by the git diff format using '+' and '-' for add/modify/delete code, or Legacy Code files contain "{filename} to be rewritten", you must merge it into the code file according to the plan.
|
||||
6. CAREFULLY CHECK THAT YOU DONT MISS ANY NECESSARY CLASS/FUNCTION IN THIS FILE.
|
||||
7. Before using a external variable/module, make sure you import it first.
|
||||
8. Write out EVERY CODE DETAIL, DON'T LEAVE TODO.
|
||||
9. Attention: Retain content that is not related to incremental development but important for consistency and clarity.".
|
||||
9. Attention: Retain details that are not related to incremental development but are important for maintaining the consistency and clarity of the old code.
|
||||
"""
|
||||
|
||||
WRITE_CODE_PLAN_AND_CHANGE_NODE = ActionNode.from_children("WriteCodePlanAndChange", [CODE_PLAN_AND_CHANGE])
|
||||
|
|
@ -185,25 +184,27 @@ WRITE_CODE_PLAN_AND_CHANGE_NODE = ActionNode.from_children("WriteCodePlanAndChan
|
|||
|
||||
class WriteCodePlanAndChange(Action):
|
||||
name: str = "WriteCodePlanAndChange"
|
||||
context: CodePlanAndChangeContext = Field(default_factory=CodePlanAndChangeContext)
|
||||
i_context: CodePlanAndChangeContext = Field(default_factory=CodePlanAndChangeContext)
|
||||
|
||||
async def run(self, *args, **kwargs):
|
||||
self.llm.system_prompt = "You are a professional software engineer, your primary responsibility is to "
|
||||
"meticulously craft comprehensive incremental development plan and deliver detailed incremental change"
|
||||
requirement = self.context.requirement_doc.content
|
||||
prd = "\n".join([doc.content for doc in self.context.prd_docs])
|
||||
design = "\n".join([doc.content for doc in self.context.design_docs])
|
||||
tasks = "\n".join([doc.content for doc in self.context.tasks_docs])
|
||||
prd_doc = await self.repo.docs.prd.get(filename=self.i_context.prd_filename)
|
||||
design_doc = await self.repo.docs.system_design.get(filename=self.i_context.design_filename)
|
||||
task_doc = await self.repo.docs.task.get(filename=self.i_context.task_filename)
|
||||
code_text = await self.get_old_codes()
|
||||
context = CODE_PLAN_AND_CHANGE_CONTEXT.format(
|
||||
requirement=requirement, prd=prd, design=design, tasks=tasks, code=code_text
|
||||
requirement=self.i_context.requirement,
|
||||
prd=prd_doc.content,
|
||||
design=design_doc.content,
|
||||
task=task_doc.content,
|
||||
code=code_text,
|
||||
)
|
||||
return await WRITE_CODE_PLAN_AND_CHANGE_NODE.fill(context=context, llm=self.llm, schema="json")
|
||||
|
||||
@staticmethod
|
||||
async def get_old_codes() -> str:
|
||||
CONFIG.old_workspace = CONFIG.git_repo.workdir / os.path.basename(CONFIG.project_path)
|
||||
old_file_repo = CONFIG.git_repo.new_file_repository(relative_path=CONFIG.old_workspace)
|
||||
async def get_old_codes(self) -> str:
|
||||
self.repo.old_workspace = self.repo.git_repo.workdir / os.path.basename(self.config.project_path)
|
||||
old_file_repo = self.repo.git_repo.new_file_repository(relative_path=self.repo.old_workspace)
|
||||
old_codes = await old_file_repo.get_all()
|
||||
codes = [f"----- {code.filename}\n```{code.content}```" for code in old_codes]
|
||||
return "\n".join(codes)
|
||||
|
|
|
|||
|
|
@ -13,17 +13,10 @@ from tenacity import retry, stop_after_attempt, wait_random_exponential
|
|||
|
||||
from metagpt.actions import WriteCode
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import (
|
||||
CODE_PLAN_AND_CHANGE_FILE_REPO,
|
||||
CODE_PLAN_AND_CHANGE_FILENAME,
|
||||
DOCS_FILE_REPO,
|
||||
REQUIREMENT_FILENAME,
|
||||
)
|
||||
from metagpt.const import CODE_PLAN_AND_CHANGE_FILENAME, REQUIREMENT_FILENAME
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import CodingContext
|
||||
from metagpt.utils.common import CodeParser
|
||||
from metagpt.utils.file_repository import FileRepository
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
# System
|
||||
|
|
@ -127,7 +120,7 @@ REWRITE_CODE_TEMPLATE = """
|
|||
|
||||
class WriteCodeReview(Action):
|
||||
name: str = "WriteCodeReview"
|
||||
context: CodingContext = Field(default_factory=CodingContext)
|
||||
i_context: CodingContext = Field(default_factory=CodingContext)
|
||||
|
||||
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
|
||||
async def write_code_review_and_rewrite(self, context_prompt, cr_prompt, filename):
|
||||
|
|
@ -143,39 +136,36 @@ class WriteCodeReview(Action):
|
|||
return result, code
|
||||
|
||||
async def run(self, *args, **kwargs) -> CodingContext:
|
||||
iterative_code = self.context.code_doc.content
|
||||
k = CONFIG.code_review_k_times or 1
|
||||
code_plan_and_change_doc = await FileRepository.get_file(
|
||||
filename=CODE_PLAN_AND_CHANGE_FILENAME, relative_path=CODE_PLAN_AND_CHANGE_FILE_REPO
|
||||
)
|
||||
code_plan_and_change = code_plan_and_change_doc.content if code_plan_and_change_doc else ""
|
||||
mode = "incremental" if code_plan_and_change else "normal"
|
||||
iterative_code = self.i_context.code_doc.content
|
||||
k = self.context.config.code_review_k_times or 1
|
||||
|
||||
for i in range(k):
|
||||
format_example = FORMAT_EXAMPLE.format(filename=self.context.code_doc.filename)
|
||||
task_content = self.context.task_doc.content if self.context.task_doc else ""
|
||||
code_context = await WriteCode.get_codes(self.context.task_doc, exclude=self.context.filename, mode=mode)
|
||||
format_example = FORMAT_EXAMPLE.format(filename=self.i_context.code_doc.filename)
|
||||
task_content = self.i_context.task_doc.content if self.i_context.task_doc else ""
|
||||
code_context = await WriteCode.get_codes(
|
||||
self.i_context.task_doc,
|
||||
exclude=self.i_context.filename,
|
||||
project_repo=self.repo.with_src_path(self.context.src_workspace),
|
||||
use_inc=self.config.inc,
|
||||
)
|
||||
|
||||
if not code_plan_and_change:
|
||||
if not self.config.inc:
|
||||
context = "\n".join(
|
||||
[
|
||||
"## System Design\n" + str(self.context.design_doc) + "\n",
|
||||
"## Tasks\n" + task_content + "\n",
|
||||
"## System Design\n" + str(self.i_context.design_doc) + "\n",
|
||||
"## Task\n" + task_content + "\n",
|
||||
"## Code Files\n" + code_context + "\n",
|
||||
]
|
||||
)
|
||||
else:
|
||||
requirement_doc = await FileRepository.get_file(
|
||||
filename=REQUIREMENT_FILENAME, relative_path=DOCS_FILE_REPO
|
||||
)
|
||||
user_requirement = requirement_doc.content if requirement_doc else ""
|
||||
|
||||
requirement_doc = await self.repo.docs.get(filename=REQUIREMENT_FILENAME)
|
||||
code_plan_and_change_doc = await self.repo.get(filename=CODE_PLAN_AND_CHANGE_FILENAME)
|
||||
context = "\n".join(
|
||||
[
|
||||
"## User New Requirements\n" + user_requirement + "\n",
|
||||
"## Code Plan And Change\n" + code_plan_and_change + "\n",
|
||||
"## System Design\n" + str(self.context.design_doc) + "\n",
|
||||
"## Tasks\n" + task_content + "\n",
|
||||
"## User New Requirements\n" + str(requirement_doc) + "\n",
|
||||
"## Code Plan And Change\n" + str(code_plan_and_change_doc) + "\n",
|
||||
"## System Design\n" + str(self.i_context.design_doc) + "\n",
|
||||
"## Task\n" + task_content + "\n",
|
||||
"## Code Files\n" + code_context + "\n",
|
||||
]
|
||||
)
|
||||
|
|
@ -183,27 +173,27 @@ class WriteCodeReview(Action):
|
|||
context_prompt = PROMPT_TEMPLATE.format(
|
||||
context=context,
|
||||
code=iterative_code,
|
||||
filename=self.context.code_doc.filename,
|
||||
filename=self.i_context.code_doc.filename,
|
||||
)
|
||||
cr_prompt = EXAMPLE_AND_INSTRUCTION.format(
|
||||
format_example=format_example,
|
||||
)
|
||||
len1 = len(iterative_code) if iterative_code else 0
|
||||
len2 = len(self.context.code_doc.content) if self.context.code_doc.content else 0
|
||||
len2 = len(self.i_context.code_doc.content) if self.i_context.code_doc.content else 0
|
||||
logger.info(
|
||||
f"Code review and rewrite {self.context.code_doc.filename}: {i + 1}/{k} | len(iterative_code)={len1}, "
|
||||
f"len(self.context.code_doc.content)={len2}"
|
||||
f"Code review and rewrite {self.i_context.code_doc.filename}: {i + 1}/{k} | len(iterative_code)={len1}, "
|
||||
f"len(self.i_context.code_doc.content)={len2}"
|
||||
)
|
||||
result, rewrited_code = await self.write_code_review_and_rewrite(
|
||||
context_prompt, cr_prompt, self.context.code_doc.filename
|
||||
context_prompt, cr_prompt, self.i_context.code_doc.filename
|
||||
)
|
||||
if "LBTM" in result:
|
||||
iterative_code = rewrited_code
|
||||
elif "LGTM" in result:
|
||||
self.context.code_doc.content = iterative_code
|
||||
return self.context
|
||||
self.i_context.code_doc.content = iterative_code
|
||||
return self.i_context
|
||||
# code_rsp = await self._aask_v1(prompt, "code_rsp", OUTPUT_MAPPING)
|
||||
# self._save(context, filename, code)
|
||||
# 如果rewrited_code是None(原code perfect),那么直接返回code
|
||||
self.context.code_doc.content = iterative_code
|
||||
return self.context
|
||||
self.i_context.code_doc.content = iterative_code
|
||||
return self.i_context
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ Options:
|
|||
Default: 'google'
|
||||
|
||||
Example:
|
||||
python3 -m metagpt.actions.write_docstring ./metagpt/startup.py --overwrite False --style=numpy
|
||||
python3 -m metagpt.actions.write_docstring ./metagpt/software_company.py --overwrite False --style=numpy
|
||||
|
||||
This script uses the 'fire' library to create a command-line interface. It generates docstrings for the given Python code using
|
||||
the specified docstring style and adds them to the code.
|
||||
|
|
@ -161,7 +161,7 @@ class WriteDocstring(Action):
|
|||
"""
|
||||
|
||||
desc: str = "Write docstring for code."
|
||||
context: Optional[str] = None
|
||||
i_context: Optional[str] = None
|
||||
|
||||
async def run(
|
||||
self,
|
||||
|
|
|
|||
|
|
@ -14,9 +14,7 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import json
|
||||
import uuid
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from metagpt.actions import Action, ActionOutput
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
|
|
@ -25,18 +23,13 @@ from metagpt.actions.write_prd_an import (
|
|||
COMPETITIVE_QUADRANT_CHART,
|
||||
PROJECT_NAME,
|
||||
REFINED_PRD_NODE,
|
||||
REFINED_TEMPLATE,
|
||||
WP_IS_RELATIVE_NODE,
|
||||
WP_ISSUE_TYPE_NODE,
|
||||
WRITE_PRD_NODE,
|
||||
)
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import (
|
||||
BUGFIX_FILENAME,
|
||||
COMPETITIVE_ANALYSIS_FILE_REPO,
|
||||
DOCS_FILE_REPO,
|
||||
PRD_PDF_FILE_REPO,
|
||||
PRDS_FILE_REPO,
|
||||
REQUIREMENT_FILENAME,
|
||||
)
|
||||
from metagpt.logs import logger
|
||||
|
|
@ -66,139 +59,114 @@ NEW_REQ_TEMPLATE = """
|
|||
|
||||
|
||||
class WritePRD(Action):
|
||||
name: str = "WritePRD"
|
||||
content: Optional[str] = None
|
||||
"""WritePRD deal with the following situations:
|
||||
1. Bugfix: If the requirement is a bugfix, the bugfix document will be generated.
|
||||
2. New requirement: If the requirement is a new requirement, the PRD document will be generated.
|
||||
3. Requirement update: If the requirement is an update, the PRD document will be updated.
|
||||
"""
|
||||
|
||||
async def run(self, with_messages, schema=CONFIG.prompt_schema, *args, **kwargs) -> ActionOutput | Message:
|
||||
# Determine which requirement documents need to be rewritten: Use LLM to assess whether new requirements are
|
||||
# related to the PRD. If they are related, rewrite the PRD.
|
||||
docs_file_repo = CONFIG.git_repo.new_file_repository(relative_path=DOCS_FILE_REPO)
|
||||
requirement_doc = await docs_file_repo.get(filename=REQUIREMENT_FILENAME)
|
||||
if requirement_doc and await self._is_bugfix(requirement_doc.content):
|
||||
await docs_file_repo.save(filename=BUGFIX_FILENAME, content=requirement_doc.content)
|
||||
await docs_file_repo.save(filename=REQUIREMENT_FILENAME, content="")
|
||||
bug_fix = BugFixContext(filename=BUGFIX_FILENAME)
|
||||
return Message(
|
||||
content=bug_fix.model_dump_json(),
|
||||
instruct_content=bug_fix,
|
||||
role="",
|
||||
cause_by=FixBug,
|
||||
sent_from=self,
|
||||
send_to="Alex", # the name of Engineer
|
||||
)
|
||||
async def run(self, with_messages, *args, **kwargs) -> ActionOutput | Message:
|
||||
"""Run the action."""
|
||||
req: Document = await self.repo.requirement
|
||||
docs: list[Document] = await self.repo.docs.prd.get_all()
|
||||
if not req:
|
||||
raise FileNotFoundError("No requirement document found.")
|
||||
|
||||
if await self._is_bugfix(req.content):
|
||||
logger.info(f"Bugfix detected: {req.content}")
|
||||
return await self._handle_bugfix(req)
|
||||
# remove bugfix file from last round in case of conflict
|
||||
await self.repo.docs.delete(filename=BUGFIX_FILENAME)
|
||||
|
||||
# if requirement is related to other documents, update them, otherwise create a new one
|
||||
if related_docs := await self.get_related_docs(req, docs):
|
||||
logger.info(f"Requirement update detected: {req.content}")
|
||||
return await self._handle_requirement_update(req, related_docs)
|
||||
else:
|
||||
await docs_file_repo.delete(filename=BUGFIX_FILENAME)
|
||||
logger.info(f"New requirement detected: {req.content}")
|
||||
return await self._handle_new_requirement(req)
|
||||
|
||||
prds_file_repo = CONFIG.git_repo.new_file_repository(PRDS_FILE_REPO)
|
||||
prd_docs = await prds_file_repo.get_all()
|
||||
change_files = Documents()
|
||||
for prd_doc in prd_docs:
|
||||
prd_doc = await self._update_prd(
|
||||
requirement_doc=requirement_doc, prd_doc=prd_doc, prds_file_repo=prds_file_repo, *args, **kwargs
|
||||
)
|
||||
if not prd_doc:
|
||||
continue
|
||||
change_files.docs[prd_doc.filename] = prd_doc
|
||||
logger.info(f"rewrite prd: {prd_doc.filename}")
|
||||
# If there is no existing PRD, generate one using 'docs/requirement.txt'.
|
||||
if not change_files.docs:
|
||||
prd_doc = await self._update_prd(
|
||||
requirement_doc=requirement_doc, prd_doc=None, prds_file_repo=prds_file_repo, *args, **kwargs
|
||||
)
|
||||
if prd_doc:
|
||||
change_files.docs[prd_doc.filename] = prd_doc
|
||||
logger.debug(f"new prd: {prd_doc.filename}")
|
||||
# Once all files under 'docs/prds/' have been compared with the newly added requirements, trigger the
|
||||
# 'publish' message to transition the workflow to the next stage. This design allows room for global
|
||||
# optimization in subsequent steps.
|
||||
return ActionOutput(content=change_files.model_dump_json(), instruct_content=change_files)
|
||||
async def _handle_bugfix(self, req: Document) -> Message:
|
||||
# ... bugfix logic ...
|
||||
await self.repo.docs.save(filename=BUGFIX_FILENAME, content=req.content)
|
||||
await self.repo.docs.save(filename=REQUIREMENT_FILENAME, content="")
|
||||
bug_fix = BugFixContext(filename=BUGFIX_FILENAME)
|
||||
return Message(
|
||||
content=bug_fix.model_dump_json(),
|
||||
instruct_content=bug_fix,
|
||||
role="",
|
||||
cause_by=FixBug,
|
||||
sent_from=self,
|
||||
send_to="Alex", # the name of Engineer
|
||||
)
|
||||
|
||||
async def _run_new_requirement(self, requirements, schema=CONFIG.prompt_schema) -> ActionOutput:
|
||||
# sas = SearchAndSummarize()
|
||||
# # rsp = await sas.run(context=requirements, system_text=SEARCH_AND_SUMMARIZE_SYSTEM_EN_US)
|
||||
# rsp = ""
|
||||
# info = f"### Search Results\n{sas.result}\n\n### Search Summary\n{rsp}"
|
||||
# if sas.result:
|
||||
# logger.info(sas.result)
|
||||
# logger.info(rsp)
|
||||
project_name = CONFIG.project_name or ""
|
||||
context = CONTEXT_TEMPLATE.format(requirements=requirements, project_name=project_name)
|
||||
async def _handle_new_requirement(self, req: Document) -> ActionOutput:
|
||||
"""handle new requirement"""
|
||||
project_name = self.project_name
|
||||
context = CONTEXT_TEMPLATE.format(requirements=req, project_name=project_name)
|
||||
exclude = [PROJECT_NAME.key] if project_name else []
|
||||
node = await WRITE_PRD_NODE.fill(context=context, llm=self.llm, exclude=exclude) # schema=schema
|
||||
await self._rename_workspace(node)
|
||||
return node
|
||||
new_prd_doc = await self.repo.docs.prd.save(
|
||||
filename=FileRepository.new_filename() + ".json", content=node.instruct_content.model_dump_json()
|
||||
)
|
||||
await self._save_competitive_analysis(new_prd_doc)
|
||||
await self.repo.resources.prd.save_pdf(doc=new_prd_doc)
|
||||
return Documents.from_iterable(documents=[new_prd_doc]).to_action_output()
|
||||
|
||||
async def _is_relative(self, new_requirement_doc, old_prd_doc) -> bool:
|
||||
context = NEW_REQ_TEMPLATE.format(old_prd=old_prd_doc.content, requirements=new_requirement_doc.content)
|
||||
async def _handle_requirement_update(self, req: Document, related_docs: list[Document]) -> ActionOutput:
|
||||
# ... requirement update logic ...
|
||||
for doc in related_docs:
|
||||
await self._update_prd(req, doc)
|
||||
return Documents.from_iterable(documents=related_docs).to_action_output()
|
||||
|
||||
async def _is_bugfix(self, context: str) -> bool:
|
||||
if not self.repo.code_files_exists():
|
||||
return False
|
||||
node = await WP_ISSUE_TYPE_NODE.fill(context, self.llm)
|
||||
return node.get("issue_type") == "BUG"
|
||||
|
||||
async def get_related_docs(self, req: Document, docs: list[Document]) -> list[Document]:
|
||||
"""get the related documents"""
|
||||
# refine: use gather to speed up
|
||||
return [i for i in docs if await self._is_related(req, i)]
|
||||
|
||||
async def _is_related(self, req: Document, old_prd: Document) -> bool:
|
||||
context = NEW_REQ_TEMPLATE.format(old_prd=old_prd.content, requirements=req.content)
|
||||
node = await WP_IS_RELATIVE_NODE.fill(context, self.llm)
|
||||
return node.get("is_relative") == "YES"
|
||||
|
||||
async def _merge(self, new_requirement_doc, prd_doc, schema=CONFIG.prompt_schema) -> Document:
|
||||
if not CONFIG.project_name:
|
||||
CONFIG.project_name = Path(CONFIG.project_path).name
|
||||
prompt = REFINED_TEMPLATE.format(
|
||||
requirements=new_requirement_doc.content,
|
||||
old_prd=prd_doc.content,
|
||||
project_name=CONFIG.project_name,
|
||||
)
|
||||
node = await REFINED_PRD_NODE.fill(context=prompt, llm=self.llm, schema=schema)
|
||||
prd_doc.content = node.instruct_content.model_dump_json()
|
||||
async def _merge(self, req: Document, related_doc: Document) -> Document:
|
||||
if not self.project_name:
|
||||
self.project_name = Path(self.project_path).name
|
||||
prompt = NEW_REQ_TEMPLATE.format(requirements=req.content, old_prd=related_doc.content)
|
||||
node = await REFINED_PRD_NODE.fill(context=prompt, llm=self.llm, schema=self.prompt_schema)
|
||||
related_doc.content = node.instruct_content.model_dump_json()
|
||||
await self._rename_workspace(node)
|
||||
return prd_doc
|
||||
return related_doc
|
||||
|
||||
async def _update_prd(self, requirement_doc, prd_doc, prds_file_repo, *args, **kwargs) -> Document | None:
|
||||
if not prd_doc:
|
||||
prd = await self._run_new_requirement(
|
||||
requirements=[requirement_doc.content if requirement_doc else ""], *args, **kwargs
|
||||
)
|
||||
new_prd_doc = Document(
|
||||
root_path=PRDS_FILE_REPO,
|
||||
filename=FileRepository.new_filename() + ".json",
|
||||
content=prd.instruct_content.model_dump_json(),
|
||||
)
|
||||
elif await self._is_relative(requirement_doc, prd_doc):
|
||||
new_prd_doc = await self._merge(requirement_doc, prd_doc)
|
||||
else:
|
||||
return None
|
||||
await prds_file_repo.save(filename=new_prd_doc.filename, content=new_prd_doc.content)
|
||||
async def _update_prd(self, req: Document, prd_doc: Document) -> Document:
|
||||
new_prd_doc: Document = await self._merge(req, prd_doc)
|
||||
await self.repo.docs.prd.save_doc(doc=new_prd_doc)
|
||||
await self._save_competitive_analysis(new_prd_doc)
|
||||
await self._save_pdf(new_prd_doc)
|
||||
await self.repo.resources.prd.save_pdf(doc=new_prd_doc)
|
||||
return new_prd_doc
|
||||
|
||||
@staticmethod
|
||||
async def _save_competitive_analysis(prd_doc):
|
||||
async def _save_competitive_analysis(self, prd_doc: Document):
|
||||
m = json.loads(prd_doc.content)
|
||||
quadrant_chart = m.get(COMPETITIVE_QUADRANT_CHART.key)
|
||||
if not quadrant_chart:
|
||||
return
|
||||
pathname = (
|
||||
CONFIG.git_repo.workdir / Path(COMPETITIVE_ANALYSIS_FILE_REPO) / Path(prd_doc.filename).with_suffix("")
|
||||
)
|
||||
if not pathname.parent.exists():
|
||||
pathname.parent.mkdir(parents=True, exist_ok=True)
|
||||
await mermaid_to_file(quadrant_chart, pathname)
|
||||
pathname = self.repo.workdir / COMPETITIVE_ANALYSIS_FILE_REPO / Path(prd_doc.filename).stem
|
||||
pathname.parent.mkdir(parents=True, exist_ok=True)
|
||||
await mermaid_to_file(self.config.mermaid.engine, quadrant_chart, pathname)
|
||||
|
||||
@staticmethod
|
||||
async def _save_pdf(prd_doc):
|
||||
await FileRepository.save_as(doc=prd_doc, with_suffix=".md", relative_path=PRD_PDF_FILE_REPO)
|
||||
|
||||
@staticmethod
|
||||
async def _rename_workspace(prd):
|
||||
if not CONFIG.project_name:
|
||||
async def _rename_workspace(self, prd):
|
||||
if not self.project_name:
|
||||
if isinstance(prd, (ActionOutput, ActionNode)):
|
||||
ws_name = prd.instruct_content.model_dump()["Project Name"]
|
||||
else:
|
||||
ws_name = CodeParser.parse_str(block="Project Name", text=prd)
|
||||
if ws_name:
|
||||
CONFIG.project_name = ws_name
|
||||
if not CONFIG.project_name: # The LLM failed to provide a project name, and the user didn't provide one either.
|
||||
CONFIG.project_name = "app" + uuid.uuid4().hex[:16]
|
||||
CONFIG.git_repo.rename_root(CONFIG.project_name)
|
||||
|
||||
async def _is_bugfix(self, context) -> bool:
|
||||
src_workspace_path = CONFIG.git_repo.workdir / CONFIG.git_repo.workdir.name
|
||||
code_files = CONFIG.git_repo.get_files(relative_path=src_workspace_path)
|
||||
if not code_files:
|
||||
return False
|
||||
node = await WP_ISSUE_TYPE_NODE.fill(context, self.llm)
|
||||
return node.get("issue_type") == "BUG"
|
||||
self.project_name = ws_name
|
||||
self.repo.git_repo.rename_root(self.project_name)
|
||||
|
|
|
|||
|
|
@ -8,7 +8,6 @@
|
|||
from typing import List
|
||||
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
from metagpt.logs import logger
|
||||
|
||||
LANGUAGE = ActionNode(
|
||||
key="Language",
|
||||
|
|
@ -34,14 +33,15 @@ ORIGINAL_REQUIREMENTS = ActionNode(
|
|||
REFINED_REQUIREMENTS = ActionNode(
|
||||
key="Refined Requirements",
|
||||
expected_type=str,
|
||||
instruction="Place the New user's requirements here.",
|
||||
instruction="Place the New user's original requirements here.",
|
||||
example="Create a 2048 game with a new feature that ...",
|
||||
)
|
||||
|
||||
PROJECT_NAME = ActionNode(
|
||||
key="Project Name",
|
||||
expected_type=str,
|
||||
instruction="According to the content of \"Original Requirements,\" name the project using snake case style , like 'game_2048' or 'simple_crm.",
|
||||
instruction='According to the content of "Original Requirements," name the project using snake case style , '
|
||||
"like 'game_2048' or 'simple_crm.",
|
||||
example="game_2048",
|
||||
)
|
||||
|
||||
|
|
@ -186,20 +186,6 @@ REASON = ActionNode(
|
|||
key="reason", expected_type=str, instruction="Explain the reasoning process from question to answer", example="..."
|
||||
)
|
||||
|
||||
REFINED_TEMPLATE = """
|
||||
### Project Name
|
||||
{project_name}
|
||||
|
||||
### New Requirements
|
||||
{requirements}
|
||||
|
||||
### Legacy Content
|
||||
{old_prd}
|
||||
|
||||
### Search Information
|
||||
-
|
||||
"""
|
||||
|
||||
|
||||
NODES = [
|
||||
LANGUAGE,
|
||||
|
|
@ -235,14 +221,3 @@ WRITE_PRD_NODE = ActionNode.from_children("WritePRD", NODES)
|
|||
REFINED_PRD_NODE = ActionNode.from_children("RefinedPRD", REFINED_NODES)
|
||||
WP_ISSUE_TYPE_NODE = ActionNode.from_children("WP_ISSUE_TYPE", [ISSUE_TYPE, REASON])
|
||||
WP_IS_RELATIVE_NODE = ActionNode.from_children("WP_IS_RELATIVE", [IS_RELATIVE, REASON])
|
||||
|
||||
|
||||
def main():
|
||||
prompt = WRITE_PRD_NODE.compile(context="")
|
||||
logger.info(prompt)
|
||||
prompt = REFINED_PRD_NODE.compile(context="")
|
||||
logger.info(prompt)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ from metagpt.actions.action import Action
|
|||
|
||||
class WritePRDReview(Action):
|
||||
name: str = ""
|
||||
context: Optional[str] = None
|
||||
i_context: Optional[str] = None
|
||||
|
||||
prd: Optional[str] = None
|
||||
desc: str = "Based on the PRD, conduct a PRD Review, providing clear and detailed feedback"
|
||||
|
|
|
|||
|
|
@ -8,14 +8,14 @@
|
|||
from typing import Optional
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.context import Context
|
||||
from metagpt.logs import logger
|
||||
|
||||
|
||||
class WriteTeachingPlanPart(Action):
|
||||
"""Write Teaching Plan Part"""
|
||||
|
||||
context: Optional[str] = None
|
||||
i_context: Optional[str] = None
|
||||
topic: str = ""
|
||||
language: str = "Chinese"
|
||||
rsp: Optional[str] = None
|
||||
|
|
@ -24,7 +24,7 @@ class WriteTeachingPlanPart(Action):
|
|||
statement_patterns = TeachingPlanBlock.TOPIC_STATEMENTS.get(self.topic, [])
|
||||
statements = []
|
||||
for p in statement_patterns:
|
||||
s = self.format_value(p)
|
||||
s = self.format_value(p, context=self.context)
|
||||
statements.append(s)
|
||||
formatter = (
|
||||
TeachingPlanBlock.PROMPT_TITLE_TEMPLATE
|
||||
|
|
@ -35,7 +35,7 @@ class WriteTeachingPlanPart(Action):
|
|||
formation=TeachingPlanBlock.FORMATION,
|
||||
role=self.prefix,
|
||||
statements="\n".join(statements),
|
||||
lesson=self.context,
|
||||
lesson=self.i_context,
|
||||
topic=self.topic,
|
||||
language=self.language,
|
||||
)
|
||||
|
|
@ -68,20 +68,23 @@ class WriteTeachingPlanPart(Action):
|
|||
return self.topic
|
||||
|
||||
@staticmethod
|
||||
def format_value(value):
|
||||
def format_value(value, context: Context):
|
||||
"""Fill parameters inside `value` with `options`."""
|
||||
if not isinstance(value, str):
|
||||
return value
|
||||
if "{" not in value:
|
||||
return value
|
||||
|
||||
merged_opts = CONFIG.options or {}
|
||||
options = context.config.model_dump()
|
||||
for k, v in context.kwargs:
|
||||
options[k] = v # None value is allowed to override and disable the value from config.
|
||||
opts = {k: v for k, v in options.items() if v is not None}
|
||||
try:
|
||||
return value.format(**merged_opts)
|
||||
return value.format(**opts)
|
||||
except KeyError as e:
|
||||
logger.warning(f"Parameter is missing:{e}")
|
||||
|
||||
for k, v in merged_opts.items():
|
||||
for k, v in opts.items():
|
||||
value = value.replace("{" + f"{k}" + "}", str(v))
|
||||
return value
|
||||
|
||||
|
|
|
|||
|
|
@ -39,7 +39,7 @@ you should correctly import the necessary classes based on these file locations!
|
|||
|
||||
class WriteTest(Action):
|
||||
name: str = "WriteTest"
|
||||
context: Optional[TestingContext] = None
|
||||
i_context: Optional[TestingContext] = None
|
||||
|
||||
async def write_code(self, prompt):
|
||||
code_rsp = await self._aask(prompt)
|
||||
|
|
@ -55,16 +55,16 @@ class WriteTest(Action):
|
|||
return code
|
||||
|
||||
async def run(self, *args, **kwargs) -> TestingContext:
|
||||
if not self.context.test_doc:
|
||||
self.context.test_doc = Document(
|
||||
filename="test_" + self.context.code_doc.filename, root_path=TEST_CODES_FILE_REPO
|
||||
if not self.i_context.test_doc:
|
||||
self.i_context.test_doc = Document(
|
||||
filename="test_" + self.i_context.code_doc.filename, root_path=TEST_CODES_FILE_REPO
|
||||
)
|
||||
fake_root = "/data"
|
||||
prompt = PROMPT_TEMPLATE.format(
|
||||
code_to_test=self.context.code_doc.content,
|
||||
test_file_name=self.context.test_doc.filename,
|
||||
source_file_path=fake_root + "/" + self.context.code_doc.root_relative_path,
|
||||
code_to_test=self.i_context.code_doc.content,
|
||||
test_file_name=self.i_context.test_doc.filename,
|
||||
source_file_path=fake_root + "/" + self.i_context.code_doc.root_relative_path,
|
||||
workspace=fake_root,
|
||||
)
|
||||
self.context.test_doc.content = await self.write_code(prompt)
|
||||
return self.context
|
||||
self.i_context.test_doc.content = await self.write_code(prompt)
|
||||
return self.i_context
|
||||
|
|
|
|||
|
|
@ -1,288 +0,0 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
Provide configuration, singleton
|
||||
@Modified By: mashenquan, 2023/11/27.
|
||||
1. According to Section 2.2.3.11 of RFC 135, add git repository support.
|
||||
2. Add the parameter `src_workspace` for the old version project path.
|
||||
"""
|
||||
import datetime
|
||||
import json
|
||||
import os
|
||||
import warnings
|
||||
from copy import deepcopy
|
||||
from enum import Enum
|
||||
from pathlib import Path
|
||||
from typing import Any
|
||||
from uuid import uuid4
|
||||
|
||||
import yaml
|
||||
|
||||
from metagpt.const import DEFAULT_WORKSPACE_ROOT, METAGPT_ROOT, OPTIONS
|
||||
from metagpt.logs import logger
|
||||
from metagpt.tools import SearchEngineType, WebBrowserEngineType
|
||||
from metagpt.utils.common import require_python_version
|
||||
from metagpt.utils.cost_manager import CostManager
|
||||
from metagpt.utils.singleton import Singleton
|
||||
|
||||
|
||||
class NotConfiguredException(Exception):
|
||||
"""Exception raised for errors in the configuration.
|
||||
|
||||
Attributes:
|
||||
message -- explanation of the error
|
||||
"""
|
||||
|
||||
def __init__(self, message="The required configuration is not set"):
|
||||
self.message = message
|
||||
super().__init__(self.message)
|
||||
|
||||
|
||||
class LLMProviderEnum(Enum):
|
||||
OPENAI = "openai"
|
||||
ANTHROPIC = "anthropic"
|
||||
SPARK = "spark"
|
||||
ZHIPUAI = "zhipuai"
|
||||
FIREWORKS = "fireworks"
|
||||
OPEN_LLM = "open_llm"
|
||||
GEMINI = "gemini"
|
||||
METAGPT = "metagpt"
|
||||
AZURE_OPENAI = "azure_openai"
|
||||
OLLAMA = "ollama"
|
||||
|
||||
def __missing__(self, key):
|
||||
return self.OPENAI
|
||||
|
||||
|
||||
class Config(metaclass=Singleton):
|
||||
"""
|
||||
Regular usage method:
|
||||
config = Config("config.yaml")
|
||||
secret_key = config.get_key("MY_SECRET_KEY")
|
||||
print("Secret key:", secret_key)
|
||||
"""
|
||||
|
||||
_instance = None
|
||||
home_yaml_file = Path.home() / ".metagpt/config.yaml"
|
||||
key_yaml_file = METAGPT_ROOT / "config/key.yaml"
|
||||
default_yaml_file = METAGPT_ROOT / "config/config.yaml"
|
||||
|
||||
def __init__(self, yaml_file=default_yaml_file, cost_data=""):
|
||||
global_options = OPTIONS.get()
|
||||
# cli paras
|
||||
self.project_path = ""
|
||||
self.project_name = ""
|
||||
self.inc = False
|
||||
self.reqa_file = ""
|
||||
self.max_auto_summarize_code = 0
|
||||
self.git_reinit = False
|
||||
|
||||
self._init_with_config_files_and_env(yaml_file)
|
||||
# The agent needs to be billed per user, so billing information cannot be destroyed when the session ends.
|
||||
self.cost_manager = CostManager(**json.loads(cost_data)) if cost_data else CostManager()
|
||||
self._update()
|
||||
global_options.update(OPTIONS.get())
|
||||
logger.debug("Config loading done.")
|
||||
|
||||
def get_default_llm_provider_enum(self) -> LLMProviderEnum:
|
||||
"""Get first valid LLM provider enum"""
|
||||
mappings = {
|
||||
LLMProviderEnum.OPENAI: bool(
|
||||
self._is_valid_llm_key(self.OPENAI_API_KEY) and not self.OPENAI_API_TYPE and self.OPENAI_API_MODEL
|
||||
),
|
||||
LLMProviderEnum.ANTHROPIC: self._is_valid_llm_key(self.ANTHROPIC_API_KEY),
|
||||
LLMProviderEnum.ZHIPUAI: self._is_valid_llm_key(self.ZHIPUAI_API_KEY),
|
||||
LLMProviderEnum.FIREWORKS: self._is_valid_llm_key(self.FIREWORKS_API_KEY),
|
||||
LLMProviderEnum.OPEN_LLM: self._is_valid_llm_key(self.OPEN_LLM_API_BASE),
|
||||
LLMProviderEnum.GEMINI: self._is_valid_llm_key(self.GEMINI_API_KEY),
|
||||
LLMProviderEnum.METAGPT: bool(
|
||||
self._is_valid_llm_key(self.OPENAI_API_KEY) and self.OPENAI_API_TYPE == "metagpt"
|
||||
),
|
||||
LLMProviderEnum.AZURE_OPENAI: bool(
|
||||
self._is_valid_llm_key(self.OPENAI_API_KEY)
|
||||
and self.OPENAI_API_TYPE == "azure"
|
||||
and self.DEPLOYMENT_NAME
|
||||
and self.OPENAI_API_VERSION
|
||||
),
|
||||
LLMProviderEnum.OLLAMA: self._is_valid_llm_key(self.OLLAMA_API_BASE),
|
||||
}
|
||||
provider = None
|
||||
for k, v in mappings.items():
|
||||
if v:
|
||||
provider = k
|
||||
break
|
||||
if provider is None:
|
||||
if self.DEFAULT_PROVIDER:
|
||||
provider = LLMProviderEnum(self.DEFAULT_PROVIDER)
|
||||
else:
|
||||
raise NotConfiguredException("You should config a LLM configuration first")
|
||||
|
||||
if provider is LLMProviderEnum.GEMINI and not require_python_version(req_version=(3, 10)):
|
||||
warnings.warn("Use Gemini requires Python >= 3.10")
|
||||
model_name = self.get_model_name(provider=provider)
|
||||
if model_name:
|
||||
logger.info(f"{provider} Model: {model_name}")
|
||||
if provider:
|
||||
logger.info(f"API: {provider}")
|
||||
return provider
|
||||
|
||||
def get_model_name(self, provider=None) -> str:
|
||||
provider = provider or self.get_default_llm_provider_enum()
|
||||
model_mappings = {
|
||||
LLMProviderEnum.OPENAI: self.OPENAI_API_MODEL,
|
||||
LLMProviderEnum.AZURE_OPENAI: self.DEPLOYMENT_NAME,
|
||||
}
|
||||
return model_mappings.get(provider, "")
|
||||
|
||||
@staticmethod
|
||||
def _is_valid_llm_key(k: str) -> bool:
|
||||
return bool(k and k != "YOUR_API_KEY")
|
||||
|
||||
def _update(self):
|
||||
self.global_proxy = self._get("GLOBAL_PROXY")
|
||||
|
||||
self.openai_api_key = self._get("OPENAI_API_KEY")
|
||||
self.anthropic_api_key = self._get("ANTHROPIC_API_KEY")
|
||||
self.zhipuai_api_key = self._get("ZHIPUAI_API_KEY")
|
||||
self.zhipuai_api_model = self._get("ZHIPUAI_API_MODEL")
|
||||
self.open_llm_api_base = self._get("OPEN_LLM_API_BASE")
|
||||
self.open_llm_api_model = self._get("OPEN_LLM_API_MODEL")
|
||||
self.fireworks_api_key = self._get("FIREWORKS_API_KEY")
|
||||
self.gemini_api_key = self._get("GEMINI_API_KEY")
|
||||
self.ollama_api_base = self._get("OLLAMA_API_BASE")
|
||||
self.ollama_api_model = self._get("OLLAMA_API_MODEL")
|
||||
|
||||
if not self._get("DISABLE_LLM_PROVIDER_CHECK"):
|
||||
_ = self.get_default_llm_provider_enum()
|
||||
|
||||
self.openai_base_url = self._get("OPENAI_BASE_URL")
|
||||
self.openai_proxy = self._get("OPENAI_PROXY") or self.global_proxy
|
||||
self.openai_api_type = self._get("OPENAI_API_TYPE")
|
||||
self.openai_api_version = self._get("OPENAI_API_VERSION")
|
||||
self.openai_api_rpm = self._get("RPM", 3)
|
||||
self.openai_api_model = self._get("OPENAI_API_MODEL", "gpt-4-1106-preview")
|
||||
self.max_tokens_rsp = self._get("MAX_TOKENS", 2048)
|
||||
self.deployment_name = self._get("DEPLOYMENT_NAME", "gpt-4")
|
||||
|
||||
self.spark_appid = self._get("SPARK_APPID")
|
||||
self.spark_api_secret = self._get("SPARK_API_SECRET")
|
||||
self.spark_api_key = self._get("SPARK_API_KEY")
|
||||
self.domain = self._get("DOMAIN")
|
||||
self.spark_url = self._get("SPARK_URL")
|
||||
|
||||
self.fireworks_api_base = self._get("FIREWORKS_API_BASE")
|
||||
self.fireworks_api_model = self._get("FIREWORKS_API_MODEL")
|
||||
|
||||
self.claude_api_key = self._get("ANTHROPIC_API_KEY")
|
||||
self.serpapi_api_key = self._get("SERPAPI_API_KEY")
|
||||
self.serper_api_key = self._get("SERPER_API_KEY")
|
||||
self.google_api_key = self._get("GOOGLE_API_KEY")
|
||||
self.google_cse_id = self._get("GOOGLE_CSE_ID")
|
||||
self.search_engine = SearchEngineType(self._get("SEARCH_ENGINE", SearchEngineType.SERPAPI_GOOGLE))
|
||||
self.web_browser_engine = WebBrowserEngineType(self._get("WEB_BROWSER_ENGINE", WebBrowserEngineType.PLAYWRIGHT))
|
||||
self.playwright_browser_type = self._get("PLAYWRIGHT_BROWSER_TYPE", "chromium")
|
||||
self.selenium_browser_type = self._get("SELENIUM_BROWSER_TYPE", "chrome")
|
||||
|
||||
self.long_term_memory = self._get("LONG_TERM_MEMORY", False)
|
||||
if self.long_term_memory:
|
||||
logger.warning("LONG_TERM_MEMORY is True")
|
||||
self.cost_manager.max_budget = self._get("MAX_BUDGET", 10.0)
|
||||
self.code_review_k_times = 2
|
||||
|
||||
self.puppeteer_config = self._get("PUPPETEER_CONFIG", "")
|
||||
self.mmdc = self._get("MMDC", "mmdc")
|
||||
self.calc_usage = self._get("CALC_USAGE", True)
|
||||
self.model_for_researcher_summary = self._get("MODEL_FOR_RESEARCHER_SUMMARY")
|
||||
self.model_for_researcher_report = self._get("MODEL_FOR_RESEARCHER_REPORT")
|
||||
self.mermaid_engine = self._get("MERMAID_ENGINE", "nodejs")
|
||||
self.pyppeteer_executable_path = self._get("PYPPETEER_EXECUTABLE_PATH", "")
|
||||
|
||||
workspace_uid = (
|
||||
self._get("WORKSPACE_UID") or f"{datetime.datetime.now().strftime('%Y%m%d%H%M%S')}-{uuid4().hex[-8:]}"
|
||||
)
|
||||
self.repair_llm_output = self._get("REPAIR_LLM_OUTPUT", False)
|
||||
self.prompt_schema = self._get("PROMPT_FORMAT", "json")
|
||||
self.workspace_path = Path(self._get("WORKSPACE_PATH", DEFAULT_WORKSPACE_ROOT))
|
||||
val = self._get("WORKSPACE_PATH_WITH_UID")
|
||||
if val and val.lower() == "true": # for agent
|
||||
self.workspace_path = self.workspace_path / workspace_uid
|
||||
self._ensure_workspace_exists()
|
||||
self.max_auto_summarize_code = self.max_auto_summarize_code or self._get("MAX_AUTO_SUMMARIZE_CODE", 1)
|
||||
self.timeout = int(self._get("TIMEOUT", 3))
|
||||
|
||||
def update_via_cli(self, project_path, project_name, inc, reqa_file, max_auto_summarize_code):
|
||||
"""update config via cli"""
|
||||
|
||||
# Use in the PrepareDocuments action according to Section 2.2.3.5.1 of RFC 135.
|
||||
if project_path:
|
||||
inc = True
|
||||
project_name = project_name or Path(project_path).name
|
||||
self.project_path = project_path
|
||||
self.project_name = project_name
|
||||
self.inc = inc
|
||||
self.reqa_file = reqa_file
|
||||
self.max_auto_summarize_code = max_auto_summarize_code
|
||||
|
||||
def _ensure_workspace_exists(self):
|
||||
self.workspace_path.mkdir(parents=True, exist_ok=True)
|
||||
logger.debug(f"WORKSPACE_PATH set to {self.workspace_path}")
|
||||
|
||||
def _init_with_config_files_and_env(self, yaml_file):
|
||||
"""Load from config/key.yaml, config/config.yaml, and env in decreasing order of priority"""
|
||||
configs = dict(os.environ)
|
||||
|
||||
for _yaml_file in [yaml_file, self.key_yaml_file, self.home_yaml_file]:
|
||||
if not _yaml_file.exists():
|
||||
continue
|
||||
|
||||
# Load local YAML file
|
||||
with open(_yaml_file, "r", encoding="utf-8") as file:
|
||||
yaml_data = yaml.safe_load(file)
|
||||
if not yaml_data:
|
||||
continue
|
||||
configs.update(yaml_data)
|
||||
OPTIONS.set(configs)
|
||||
|
||||
@staticmethod
|
||||
def _get(*args, **kwargs):
|
||||
i = OPTIONS.get()
|
||||
return i.get(*args, **kwargs)
|
||||
|
||||
def get(self, key, *args, **kwargs):
|
||||
"""Retrieve values from config/key.yaml, config/config.yaml, and environment variables.
|
||||
Throw an error if not found."""
|
||||
value = self._get(key, *args, **kwargs)
|
||||
if value is None:
|
||||
raise ValueError(f"Key '{key}' not found in environment variables or in the YAML file")
|
||||
return value
|
||||
|
||||
def __setattr__(self, name: str, value: Any) -> None:
|
||||
OPTIONS.get()[name] = value
|
||||
|
||||
def __getattr__(self, name: str) -> Any:
|
||||
i = OPTIONS.get()
|
||||
return i.get(name)
|
||||
|
||||
def set_context(self, options: dict):
|
||||
"""Update current config"""
|
||||
if not options:
|
||||
return
|
||||
opts = deepcopy(OPTIONS.get())
|
||||
opts.update(options)
|
||||
OPTIONS.set(opts)
|
||||
self._update()
|
||||
|
||||
@property
|
||||
def options(self):
|
||||
"""Return all key-values"""
|
||||
return OPTIONS.get()
|
||||
|
||||
def new_environ(self):
|
||||
"""Return a new os.environ object"""
|
||||
env = os.environ.copy()
|
||||
i = self.options
|
||||
env.update({k: v for k, v in i.items() if isinstance(v, str)})
|
||||
return env
|
||||
|
||||
|
||||
CONFIG = Config()
|
||||
137
metagpt/config2.py
Normal file
137
metagpt/config2.py
Normal file
|
|
@ -0,0 +1,137 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/4 01:25
|
||||
@Author : alexanderwu
|
||||
@File : config2.py
|
||||
"""
|
||||
import os
|
||||
from pathlib import Path
|
||||
from typing import Dict, Iterable, List, Literal, Optional
|
||||
|
||||
from pydantic import BaseModel, model_validator
|
||||
|
||||
from metagpt.configs.browser_config import BrowserConfig
|
||||
from metagpt.configs.llm_config import LLMConfig, LLMType
|
||||
from metagpt.configs.mermaid_config import MermaidConfig
|
||||
from metagpt.configs.redis_config import RedisConfig
|
||||
from metagpt.configs.s3_config import S3Config
|
||||
from metagpt.configs.search_config import SearchConfig
|
||||
from metagpt.configs.workspace_config import WorkspaceConfig
|
||||
from metagpt.const import CONFIG_ROOT, METAGPT_ROOT
|
||||
from metagpt.utils.yaml_model import YamlModel
|
||||
|
||||
|
||||
class CLIParams(BaseModel):
|
||||
"""CLI parameters"""
|
||||
|
||||
project_path: str = ""
|
||||
project_name: str = ""
|
||||
inc: bool = False
|
||||
reqa_file: str = ""
|
||||
max_auto_summarize_code: int = 0
|
||||
git_reinit: bool = False
|
||||
|
||||
@model_validator(mode="after")
|
||||
def check_project_path(self):
|
||||
"""Check project_path and project_name"""
|
||||
if self.project_path:
|
||||
self.inc = True
|
||||
self.project_name = self.project_name or Path(self.project_path).name
|
||||
return self
|
||||
|
||||
|
||||
class Config(CLIParams, YamlModel):
|
||||
"""Configurations for MetaGPT"""
|
||||
|
||||
# Key Parameters
|
||||
llm: LLMConfig
|
||||
|
||||
# Global Proxy. Will be used if llm.proxy is not set
|
||||
proxy: str = ""
|
||||
|
||||
# Tool Parameters
|
||||
search: SearchConfig = SearchConfig()
|
||||
browser: BrowserConfig = BrowserConfig()
|
||||
mermaid: MermaidConfig = MermaidConfig()
|
||||
|
||||
# Storage Parameters
|
||||
s3: Optional[S3Config] = None
|
||||
redis: Optional[RedisConfig] = None
|
||||
|
||||
# Misc Parameters
|
||||
repair_llm_output: bool = False
|
||||
prompt_schema: Literal["json", "markdown", "raw"] = "json"
|
||||
workspace: WorkspaceConfig = WorkspaceConfig()
|
||||
enable_longterm_memory: bool = False
|
||||
code_review_k_times: int = 2
|
||||
|
||||
# Will be removed in the future
|
||||
metagpt_tti_url: str = ""
|
||||
language: str = "English"
|
||||
redis_key: str = "placeholder"
|
||||
iflytek_app_id: str = ""
|
||||
iflytek_api_secret: str = ""
|
||||
iflytek_api_key: str = ""
|
||||
azure_tts_subscription_key: str = ""
|
||||
azure_tts_region: str = ""
|
||||
|
||||
@classmethod
|
||||
def from_home(cls, path):
|
||||
"""Load config from ~/.metagpt/config2.yaml"""
|
||||
pathname = CONFIG_ROOT / path
|
||||
if not pathname.exists():
|
||||
return None
|
||||
return Config.from_yaml_file(pathname)
|
||||
|
||||
@classmethod
|
||||
def default(cls):
|
||||
"""Load default config
|
||||
- Priority: env < default_config_paths
|
||||
- Inside default_config_paths, the latter one overwrites the former one
|
||||
"""
|
||||
default_config_paths: List[Path] = [
|
||||
METAGPT_ROOT / "config/config2.yaml",
|
||||
Path.home() / ".metagpt/config2.yaml",
|
||||
]
|
||||
|
||||
dicts = [dict(os.environ)]
|
||||
dicts += [Config.read_yaml(path) for path in default_config_paths]
|
||||
final = merge_dict(dicts)
|
||||
return Config(**final)
|
||||
|
||||
def update_via_cli(self, project_path, project_name, inc, reqa_file, max_auto_summarize_code):
|
||||
"""update config via cli"""
|
||||
|
||||
# Use in the PrepareDocuments action according to Section 2.2.3.5.1 of RFC 135.
|
||||
if project_path:
|
||||
inc = True
|
||||
project_name = project_name or Path(project_path).name
|
||||
self.project_path = project_path
|
||||
self.project_name = project_name
|
||||
self.inc = inc
|
||||
self.reqa_file = reqa_file
|
||||
self.max_auto_summarize_code = max_auto_summarize_code
|
||||
|
||||
def get_openai_llm(self) -> Optional[LLMConfig]:
|
||||
"""Get OpenAI LLMConfig by name. If no OpenAI, raise Exception"""
|
||||
if self.llm.api_type == LLMType.OPENAI:
|
||||
return self.llm
|
||||
return None
|
||||
|
||||
def get_azure_llm(self) -> Optional[LLMConfig]:
|
||||
"""Get Azure LLMConfig by name. If no Azure, raise Exception"""
|
||||
if self.llm.api_type == LLMType.AZURE:
|
||||
return self.llm
|
||||
return None
|
||||
|
||||
|
||||
def merge_dict(dicts: Iterable[Dict]) -> Dict:
|
||||
"""Merge multiple dicts into one, with the latter dict overwriting the former"""
|
||||
result = {}
|
||||
for dictionary in dicts:
|
||||
result.update(dictionary)
|
||||
return result
|
||||
|
||||
|
||||
config = Config.default()
|
||||
|
|
@ -1,7 +1,7 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/5/11 14:44
|
||||
@Time : 2024/1/4 16:33
|
||||
@Author : alexanderwu
|
||||
@File : test_action.py
|
||||
@File : __init__.py
|
||||
"""
|
||||
20
metagpt/configs/browser_config.py
Normal file
20
metagpt/configs/browser_config.py
Normal file
|
|
@ -0,0 +1,20 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/4 19:06
|
||||
@Author : alexanderwu
|
||||
@File : browser_config.py
|
||||
"""
|
||||
from typing import Literal
|
||||
|
||||
from metagpt.tools import WebBrowserEngineType
|
||||
from metagpt.utils.yaml_model import YamlModel
|
||||
|
||||
|
||||
class BrowserConfig(YamlModel):
|
||||
"""Config for Browser"""
|
||||
|
||||
engine: WebBrowserEngineType = WebBrowserEngineType.PLAYWRIGHT
|
||||
browser_type: Literal["chromium", "firefox", "webkit", "chrome", "firefox", "edge", "ie"] = "chromium"
|
||||
"""If the engine is Playwright, the value should be one of "chromium", "firefox", or "webkit". If it is Selenium, the value
|
||||
should be either "chrome", "firefox", "edge", or "ie"."""
|
||||
78
metagpt/configs/llm_config.py
Normal file
78
metagpt/configs/llm_config.py
Normal file
|
|
@ -0,0 +1,78 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/4 16:33
|
||||
@Author : alexanderwu
|
||||
@File : llm_config.py
|
||||
"""
|
||||
from enum import Enum
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import field_validator
|
||||
|
||||
from metagpt.utils.yaml_model import YamlModel
|
||||
|
||||
|
||||
class LLMType(Enum):
|
||||
OPENAI = "openai"
|
||||
ANTHROPIC = "anthropic"
|
||||
SPARK = "spark"
|
||||
ZHIPUAI = "zhipuai"
|
||||
FIREWORKS = "fireworks"
|
||||
OPEN_LLM = "open_llm"
|
||||
GEMINI = "gemini"
|
||||
METAGPT = "metagpt"
|
||||
AZURE = "azure"
|
||||
OLLAMA = "ollama"
|
||||
|
||||
def __missing__(self, key):
|
||||
return self.OPENAI
|
||||
|
||||
|
||||
class LLMConfig(YamlModel):
|
||||
"""Config for LLM
|
||||
|
||||
OpenAI: https://github.com/openai/openai-python/blob/main/src/openai/resources/chat/completions.py#L681
|
||||
Optional Fields in pydantic: https://docs.pydantic.dev/latest/migration/#required-optional-and-nullable-fields
|
||||
"""
|
||||
|
||||
api_key: str
|
||||
api_type: LLMType = LLMType.OPENAI
|
||||
base_url: str = "https://api.openai.com/v1"
|
||||
api_version: Optional[str] = None
|
||||
|
||||
model: Optional[str] = None # also stands for DEPLOYMENT_NAME
|
||||
|
||||
# For Spark(Xunfei), maybe remove later
|
||||
app_id: Optional[str] = None
|
||||
api_secret: Optional[str] = None
|
||||
domain: Optional[str] = None
|
||||
|
||||
# For Chat Completion
|
||||
max_token: int = 4096
|
||||
temperature: float = 0.0
|
||||
top_p: float = 1.0
|
||||
top_k: int = 0
|
||||
repetition_penalty: float = 1.0
|
||||
stop: Optional[str] = None
|
||||
presence_penalty: float = 0.0
|
||||
frequency_penalty: float = 0.0
|
||||
best_of: Optional[int] = None
|
||||
n: Optional[int] = None
|
||||
stream: bool = False
|
||||
logprobs: Optional[bool] = None # https://cookbook.openai.com/examples/using_logprobs
|
||||
top_logprobs: Optional[int] = None
|
||||
timeout: int = 60
|
||||
|
||||
# For Network
|
||||
proxy: Optional[str] = None
|
||||
|
||||
# Cost Control
|
||||
calc_usage: bool = True
|
||||
|
||||
@field_validator("api_key")
|
||||
@classmethod
|
||||
def check_llm_key(cls, v):
|
||||
if v in ["", None, "YOUR_API_KEY"]:
|
||||
raise ValueError("Please set your API key in config2.yaml")
|
||||
return v
|
||||
19
metagpt/configs/mermaid_config.py
Normal file
19
metagpt/configs/mermaid_config.py
Normal file
|
|
@ -0,0 +1,19 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/4 19:07
|
||||
@Author : alexanderwu
|
||||
@File : mermaid_config.py
|
||||
"""
|
||||
from typing import Literal
|
||||
|
||||
from metagpt.utils.yaml_model import YamlModel
|
||||
|
||||
|
||||
class MermaidConfig(YamlModel):
|
||||
"""Config for Mermaid"""
|
||||
|
||||
engine: Literal["nodejs", "ink", "playwright", "pyppeteer"] = "nodejs"
|
||||
path: str = "mmdc" # mmdc
|
||||
puppeteer_config: str = ""
|
||||
pyppeteer_path: str = "/usr/bin/google-chrome-stable"
|
||||
26
metagpt/configs/redis_config.py
Normal file
26
metagpt/configs/redis_config.py
Normal file
|
|
@ -0,0 +1,26 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/4 19:06
|
||||
@Author : alexanderwu
|
||||
@File : redis_config.py
|
||||
"""
|
||||
from metagpt.utils.yaml_model import YamlModelWithoutDefault
|
||||
|
||||
|
||||
class RedisConfig(YamlModelWithoutDefault):
|
||||
host: str
|
||||
port: int
|
||||
username: str = ""
|
||||
password: str
|
||||
db: str
|
||||
|
||||
def to_url(self):
|
||||
return f"redis://{self.host}:{self.port}"
|
||||
|
||||
def to_kwargs(self):
|
||||
return {
|
||||
"username": self.username,
|
||||
"password": self.password,
|
||||
"db": self.db,
|
||||
}
|
||||
15
metagpt/configs/s3_config.py
Normal file
15
metagpt/configs/s3_config.py
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/4 19:07
|
||||
@Author : alexanderwu
|
||||
@File : s3_config.py
|
||||
"""
|
||||
from metagpt.utils.yaml_model import YamlModelWithoutDefault
|
||||
|
||||
|
||||
class S3Config(YamlModelWithoutDefault):
|
||||
access_key: str
|
||||
secret_key: str
|
||||
endpoint: str
|
||||
bucket: str
|
||||
20
metagpt/configs/search_config.py
Normal file
20
metagpt/configs/search_config.py
Normal file
|
|
@ -0,0 +1,20 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/4 19:06
|
||||
@Author : alexanderwu
|
||||
@File : search_config.py
|
||||
"""
|
||||
from typing import Callable, Optional
|
||||
|
||||
from metagpt.tools import SearchEngineType
|
||||
from metagpt.utils.yaml_model import YamlModel
|
||||
|
||||
|
||||
class SearchConfig(YamlModel):
|
||||
"""Config for Search"""
|
||||
|
||||
api_type: SearchEngineType = SearchEngineType.DUCK_DUCK_GO
|
||||
api_key: str = ""
|
||||
cse_id: str = "" # for google
|
||||
search_func: Optional[Callable] = None
|
||||
38
metagpt/configs/workspace_config.py
Normal file
38
metagpt/configs/workspace_config.py
Normal file
|
|
@ -0,0 +1,38 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/4 19:09
|
||||
@Author : alexanderwu
|
||||
@File : workspace_config.py
|
||||
"""
|
||||
from datetime import datetime
|
||||
from pathlib import Path
|
||||
from uuid import uuid4
|
||||
|
||||
from pydantic import field_validator, model_validator
|
||||
|
||||
from metagpt.const import DEFAULT_WORKSPACE_ROOT
|
||||
from metagpt.utils.yaml_model import YamlModel
|
||||
|
||||
|
||||
class WorkspaceConfig(YamlModel):
|
||||
path: Path = DEFAULT_WORKSPACE_ROOT
|
||||
use_uid: bool = False
|
||||
uid: str = ""
|
||||
|
||||
@field_validator("path")
|
||||
@classmethod
|
||||
def check_workspace_path(cls, v):
|
||||
if isinstance(v, str):
|
||||
v = Path(v)
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def check_uid_and_update_path(self):
|
||||
if self.use_uid and not self.uid:
|
||||
self.uid = f"{datetime.now().strftime('%Y%m%d%H%M%S')}-{uuid4().hex[-8:]}"
|
||||
self.path = self.path / self.uid
|
||||
|
||||
# Create workspace path if not exists
|
||||
self.path.mkdir(parents=True, exist_ok=True)
|
||||
return self
|
||||
|
|
@ -9,7 +9,6 @@
|
|||
@Modified By: mashenquan, 2023-11-27. Defines file repository paths according to Section 2.2.3.4 of RFC 135.
|
||||
@Modified By: mashenquan, 2023/12/5. Add directories for code summarization..
|
||||
"""
|
||||
import contextvars
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
|
|
@ -17,8 +16,6 @@ from loguru import logger
|
|||
|
||||
import metagpt
|
||||
|
||||
OPTIONS = contextvars.ContextVar("OPTIONS", default={})
|
||||
|
||||
|
||||
def get_metagpt_package_root():
|
||||
"""Get the root directory of the installed package."""
|
||||
|
|
@ -47,7 +44,7 @@ def get_metagpt_root():
|
|||
|
||||
|
||||
# METAGPT PROJECT ROOT AND VARS
|
||||
|
||||
CONFIG_ROOT = Path.home() / ".metagpt"
|
||||
METAGPT_ROOT = get_metagpt_root() # Dependent on METAGPT_PROJECT_ROOT
|
||||
DEFAULT_WORKSPACE_ROOT = METAGPT_ROOT / "workspace"
|
||||
|
||||
|
|
@ -70,13 +67,13 @@ TMP = METAGPT_ROOT / "tmp"
|
|||
SOURCE_ROOT = METAGPT_ROOT / "metagpt"
|
||||
PROMPT_PATH = SOURCE_ROOT / "prompts"
|
||||
SKILL_DIRECTORY = SOURCE_ROOT / "skills"
|
||||
|
||||
TOOL_SCHEMA_PATH = METAGPT_ROOT / "metagpt/tools/schemas"
|
||||
TOOL_LIBS_PATH = METAGPT_ROOT / "metagpt/tools/libs"
|
||||
|
||||
# REAL CONSTS
|
||||
|
||||
MEM_TTL = 24 * 30 * 3600
|
||||
|
||||
|
||||
MESSAGE_ROUTE_FROM = "sent_from"
|
||||
MESSAGE_ROUTE_TO = "send_to"
|
||||
MESSAGE_ROUTE_CAUSE_BY = "cause_by"
|
||||
|
|
@ -90,25 +87,25 @@ PACKAGE_REQUIREMENTS_FILENAME = "requirements.txt"
|
|||
CODE_PLAN_AND_CHANGE_FILENAME = "code_plan_and_change.json"
|
||||
|
||||
DOCS_FILE_REPO = "docs"
|
||||
PRDS_FILE_REPO = "docs/prds"
|
||||
PRDS_FILE_REPO = "docs/prd"
|
||||
SYSTEM_DESIGN_FILE_REPO = "docs/system_design"
|
||||
TASK_FILE_REPO = "docs/tasks"
|
||||
TASK_FILE_REPO = "docs/task"
|
||||
CODE_PLAN_AND_CHANGE_FILE_REPO = "docs/code_plan_and_change"
|
||||
COMPETITIVE_ANALYSIS_FILE_REPO = "resources/competitive_analysis"
|
||||
DATA_API_DESIGN_FILE_REPO = "resources/data_api_design"
|
||||
SEQ_FLOW_FILE_REPO = "resources/seq_flow"
|
||||
SYSTEM_DESIGN_PDF_FILE_REPO = "resources/system_design"
|
||||
PRD_PDF_FILE_REPO = "resources/prd"
|
||||
TASK_PDF_FILE_REPO = "resources/api_spec_and_tasks"
|
||||
TASK_PDF_FILE_REPO = "resources/api_spec_and_task"
|
||||
CODE_PLAN_AND_CHANGE_PDF_FILE_REPO = "resources/code_plan_and_change"
|
||||
TEST_CODES_FILE_REPO = "tests"
|
||||
TEST_OUTPUTS_FILE_REPO = "test_outputs"
|
||||
CODE_SUMMARIES_FILE_REPO = "docs/code_summaries"
|
||||
CODE_SUMMARIES_PDF_FILE_REPO = "resources/code_summaries"
|
||||
CODE_SUMMARIES_FILE_REPO = "docs/code_summary"
|
||||
CODE_SUMMARIES_PDF_FILE_REPO = "resources/code_summary"
|
||||
RESOURCES_FILE_REPO = "resources"
|
||||
SD_OUTPUT_FILE_REPO = "resources/SD_Output"
|
||||
SD_OUTPUT_FILE_REPO = "resources/sd_output"
|
||||
GRAPH_REPO_FILE_REPO = "docs/graph_repo"
|
||||
CLASS_VIEW_FILE_REPO = "docs/class_views"
|
||||
CLASS_VIEW_FILE_REPO = "docs/class_view"
|
||||
|
||||
YAPI_URL = "http://yapi.deepwisdomai.com/"
|
||||
|
||||
|
|
|
|||
97
metagpt/context.py
Normal file
97
metagpt/context.py
Normal file
|
|
@ -0,0 +1,97 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/4 16:32
|
||||
@Author : alexanderwu
|
||||
@File : context.py
|
||||
"""
|
||||
import os
|
||||
from pathlib import Path
|
||||
from typing import Any, Optional
|
||||
|
||||
from pydantic import BaseModel, ConfigDict
|
||||
|
||||
from metagpt.config2 import Config
|
||||
from metagpt.configs.llm_config import LLMConfig
|
||||
from metagpt.provider.base_llm import BaseLLM
|
||||
from metagpt.provider.llm_provider_registry import create_llm_instance
|
||||
from metagpt.utils.cost_manager import CostManager
|
||||
from metagpt.utils.git_repository import GitRepository
|
||||
from metagpt.utils.project_repo import ProjectRepo
|
||||
|
||||
|
||||
class AttrDict(BaseModel):
|
||||
"""A dict-like object that allows access to keys as attributes, compatible with Pydantic."""
|
||||
|
||||
model_config = ConfigDict(extra="allow")
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self.__dict__.update(kwargs)
|
||||
|
||||
def __getattr__(self, key):
|
||||
return self.__dict__.get(key, None)
|
||||
|
||||
def __setattr__(self, key, value):
|
||||
self.__dict__[key] = value
|
||||
|
||||
def __delattr__(self, key):
|
||||
if key in self.__dict__:
|
||||
del self.__dict__[key]
|
||||
else:
|
||||
raise AttributeError(f"No such attribute: {key}")
|
||||
|
||||
def set(self, key, val: Any):
|
||||
self.__dict__[key] = val
|
||||
|
||||
def get(self, key, default: Any = None):
|
||||
return self.__dict__.get(key, default)
|
||||
|
||||
def remove(self, key):
|
||||
if key in self.__dict__:
|
||||
self.__delattr__(key)
|
||||
|
||||
|
||||
class Context(BaseModel):
|
||||
"""Env context for MetaGPT"""
|
||||
|
||||
model_config = ConfigDict(arbitrary_types_allowed=True)
|
||||
|
||||
kwargs: AttrDict = AttrDict()
|
||||
config: Config = Config.default()
|
||||
|
||||
repo: Optional[ProjectRepo] = None
|
||||
git_repo: Optional[GitRepository] = None
|
||||
src_workspace: Optional[Path] = None
|
||||
cost_manager: CostManager = CostManager()
|
||||
|
||||
_llm: Optional[BaseLLM] = None
|
||||
|
||||
def new_environ(self):
|
||||
"""Return a new os.environ object"""
|
||||
env = os.environ.copy()
|
||||
# i = self.options
|
||||
# env.update({k: v for k, v in i.items() if isinstance(v, str)})
|
||||
return env
|
||||
|
||||
# def use_llm(self, name: Optional[str] = None, provider: LLMType = LLMType.OPENAI) -> BaseLLM:
|
||||
# """Use a LLM instance"""
|
||||
# self._llm_config = self.config.get_llm_config(name, provider)
|
||||
# self._llm = None
|
||||
# return self._llm
|
||||
|
||||
def llm(self) -> BaseLLM:
|
||||
"""Return a LLM instance, fixme: support cache"""
|
||||
# if self._llm is None:
|
||||
self._llm = create_llm_instance(self.config.llm)
|
||||
if self._llm.cost_manager is None:
|
||||
self._llm.cost_manager = self.cost_manager
|
||||
return self._llm
|
||||
|
||||
def llm_with_cost_manager_from_llm_config(self, llm_config: LLMConfig) -> BaseLLM:
|
||||
"""Return a LLM instance, fixme: support cache"""
|
||||
# if self._llm is None:
|
||||
llm = create_llm_instance(llm_config)
|
||||
if llm.cost_manager is None:
|
||||
llm.cost_manager = self.cost_manager
|
||||
return llm
|
||||
101
metagpt/context_mixin.py
Normal file
101
metagpt/context_mixin.py
Normal file
|
|
@ -0,0 +1,101 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/11 17:25
|
||||
@Author : alexanderwu
|
||||
@File : context_mixin.py
|
||||
"""
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import BaseModel, ConfigDict, Field, model_validator
|
||||
|
||||
from metagpt.config2 import Config
|
||||
from metagpt.context import Context
|
||||
from metagpt.provider.base_llm import BaseLLM
|
||||
|
||||
|
||||
class ContextMixin(BaseModel):
|
||||
"""Mixin class for context and config"""
|
||||
|
||||
model_config = ConfigDict(arbitrary_types_allowed=True, extra="allow")
|
||||
|
||||
# Pydantic has bug on _private_attr when using inheritance, so we use private_* instead
|
||||
# - https://github.com/pydantic/pydantic/issues/7142
|
||||
# - https://github.com/pydantic/pydantic/issues/7083
|
||||
# - https://github.com/pydantic/pydantic/issues/7091
|
||||
|
||||
# Env/Role/Action will use this context as private context, or use self.context as public context
|
||||
private_context: Optional[Context] = Field(default=None, exclude=True)
|
||||
# Env/Role/Action will use this config as private config, or use self.context.config as public config
|
||||
private_config: Optional[Config] = Field(default=None, exclude=True)
|
||||
|
||||
# Env/Role/Action will use this llm as private llm, or use self.context._llm instance
|
||||
private_llm: Optional[BaseLLM] = Field(default=None, exclude=True)
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_context_mixin_extra(self):
|
||||
self._process_context_mixin_extra()
|
||||
return self
|
||||
|
||||
def _process_context_mixin_extra(self):
|
||||
"""Process the extra field"""
|
||||
kwargs = self.model_extra or {}
|
||||
self.set_context(kwargs.pop("context", None))
|
||||
self.set_config(kwargs.pop("config", None))
|
||||
self.set_llm(kwargs.pop("llm", None))
|
||||
|
||||
def set(self, k, v, override=False):
|
||||
"""Set attribute"""
|
||||
if override or not self.__dict__.get(k):
|
||||
self.__dict__[k] = v
|
||||
|
||||
def set_context(self, context: Context, override=True):
|
||||
"""Set context"""
|
||||
self.set("private_context", context, override)
|
||||
|
||||
def set_config(self, config: Config, override=False):
|
||||
"""Set config"""
|
||||
self.set("private_config", config, override)
|
||||
if config is not None:
|
||||
_ = self.llm # init llm
|
||||
|
||||
def set_llm(self, llm: BaseLLM, override=False):
|
||||
"""Set llm"""
|
||||
self.set("private_llm", llm, override)
|
||||
|
||||
@property
|
||||
def config(self) -> Config:
|
||||
"""Role config: role config > context config"""
|
||||
if self.private_config:
|
||||
return self.private_config
|
||||
return self.context.config
|
||||
|
||||
@config.setter
|
||||
def config(self, config: Config) -> None:
|
||||
"""Set config"""
|
||||
self.set_config(config)
|
||||
|
||||
@property
|
||||
def context(self) -> Context:
|
||||
"""Role context: role context > context"""
|
||||
if self.private_context:
|
||||
return self.private_context
|
||||
return Context()
|
||||
|
||||
@context.setter
|
||||
def context(self, context: Context) -> None:
|
||||
"""Set context"""
|
||||
self.set_context(context)
|
||||
|
||||
@property
|
||||
def llm(self) -> BaseLLM:
|
||||
"""Role llm: if not existed, init from role.config"""
|
||||
# print(f"class:{self.__class__.__name__}({self.name}), llm: {self._llm}, llm_config: {self._llm_config}")
|
||||
if not self.private_llm:
|
||||
self.private_llm = self.context.llm_with_cost_manager_from_llm_config(self.config.llm)
|
||||
return self.private_llm
|
||||
|
||||
@llm.setter
|
||||
def llm(self, llm: BaseLLM) -> None:
|
||||
"""Set llm"""
|
||||
self.private_llm = llm
|
||||
|
|
@ -8,8 +8,6 @@
|
|||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
|
||||
from metagpt.config import Config
|
||||
|
||||
|
||||
class BaseStore(ABC):
|
||||
"""FIXME: consider add_index, set_index and think about granularity."""
|
||||
|
|
@ -31,7 +29,6 @@ class LocalStore(BaseStore, ABC):
|
|||
def __init__(self, raw_data_path: Path, cache_dir: Path = None):
|
||||
if not raw_data_path:
|
||||
raise FileNotFoundError
|
||||
self.config = Config()
|
||||
self.raw_data_path = raw_data_path
|
||||
self.fname = self.raw_data_path.stem
|
||||
if not cache_dir:
|
||||
|
|
|
|||
|
|
@ -9,14 +9,13 @@ import asyncio
|
|||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
from langchain.vectorstores import FAISS
|
||||
from langchain_core.embeddings import Embeddings
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.document import IndexableDocument
|
||||
from metagpt.document_store.base_store import LocalStore
|
||||
from metagpt.logs import logger
|
||||
from metagpt.utils.embedding import get_embedding
|
||||
|
||||
|
||||
class FaissStore(LocalStore):
|
||||
|
|
@ -25,9 +24,7 @@ class FaissStore(LocalStore):
|
|||
):
|
||||
self.meta_col = meta_col
|
||||
self.content_col = content_col
|
||||
self.embedding = embedding or OpenAIEmbeddings(
|
||||
openai_api_key=CONFIG.openai_api_key, openai_api_base=CONFIG.openai_base_url
|
||||
)
|
||||
self.embedding = embedding or get_embedding()
|
||||
super().__init__(raw_data, cache_dir)
|
||||
|
||||
def _load(self) -> Optional["FaissStore"]:
|
||||
|
|
|
|||
|
|
@ -1,168 +0,0 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/5/11 22:12
|
||||
@Author : alexanderwu
|
||||
@File : environment.py
|
||||
@Modified By: mashenquan, 2023-11-1. According to Chapter 2.2.2 of RFC 116:
|
||||
1. Remove the functionality of `Environment` class as a public message buffer.
|
||||
2. Standardize the message forwarding behavior of the `Environment` class.
|
||||
3. Add the `is_idle` property.
|
||||
@Modified By: mashenquan, 2023-11-4. According to the routing feature plan in Chapter 2.2.3.2 of RFC 113, the routing
|
||||
functionality is to be consolidated into the `Environment` class.
|
||||
"""
|
||||
import asyncio
|
||||
from pathlib import Path
|
||||
from typing import Iterable, Set
|
||||
|
||||
from pydantic import BaseModel, ConfigDict, Field, SerializeAsAny, model_validator
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles.role import Role
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.common import is_subscribed, read_json_file, write_json_file
|
||||
|
||||
|
||||
class Environment(BaseModel):
|
||||
"""环境,承载一批角色,角色可以向环境发布消息,可以被其他角色观察到
|
||||
Environment, hosting a batch of roles, roles can publish messages to the environment, and can be observed by other roles
|
||||
"""
|
||||
|
||||
model_config = ConfigDict(arbitrary_types_allowed=True)
|
||||
|
||||
desc: str = Field(default="") # 环境描述
|
||||
roles: dict[str, SerializeAsAny[Role]] = Field(default_factory=dict, validate_default=True)
|
||||
members: dict[Role, Set] = Field(default_factory=dict, exclude=True)
|
||||
history: str = "" # For debug
|
||||
|
||||
@model_validator(mode="after")
|
||||
def init_roles(self):
|
||||
self.add_roles(self.roles.values())
|
||||
return self
|
||||
|
||||
def serialize(self, stg_path: Path):
|
||||
roles_path = stg_path.joinpath("roles.json")
|
||||
roles_info = []
|
||||
for role_key, role in self.roles.items():
|
||||
roles_info.append(
|
||||
{
|
||||
"role_class": role.__class__.__name__,
|
||||
"module_name": role.__module__,
|
||||
"role_name": role.name,
|
||||
"role_sub_tags": list(self.members.get(role)),
|
||||
}
|
||||
)
|
||||
role.serialize(stg_path=stg_path.joinpath(f"roles/{role.__class__.__name__}_{role.name}"))
|
||||
write_json_file(roles_path, roles_info)
|
||||
|
||||
history_path = stg_path.joinpath("history.json")
|
||||
write_json_file(history_path, {"content": self.history})
|
||||
|
||||
@classmethod
|
||||
def deserialize(cls, stg_path: Path) -> "Environment":
|
||||
"""stg_path: ./storage/team/environment/"""
|
||||
roles_path = stg_path.joinpath("roles.json")
|
||||
roles_info = read_json_file(roles_path)
|
||||
roles = []
|
||||
for role_info in roles_info:
|
||||
# role stored in ./environment/roles/{role_class}_{role_name}
|
||||
role_path = stg_path.joinpath(f"roles/{role_info.get('role_class')}_{role_info.get('role_name')}")
|
||||
role = Role.deserialize(role_path)
|
||||
roles.append(role)
|
||||
|
||||
history = read_json_file(stg_path.joinpath("history.json"))
|
||||
history = history.get("content")
|
||||
|
||||
environment = Environment(**{"history": history})
|
||||
environment.add_roles(roles)
|
||||
|
||||
return environment
|
||||
|
||||
def add_role(self, role: Role):
|
||||
"""增加一个在当前环境的角色
|
||||
Add a role in the current environment
|
||||
"""
|
||||
self.roles[role.profile] = role
|
||||
role.set_env(self)
|
||||
|
||||
def add_roles(self, roles: Iterable[Role]):
|
||||
"""增加一批在当前环境的角色
|
||||
Add a batch of characters in the current environment
|
||||
"""
|
||||
for role in roles:
|
||||
self.roles[role.profile] = role
|
||||
|
||||
for role in roles: # setup system message with roles
|
||||
role.set_env(self)
|
||||
|
||||
def publish_message(self, message: Message, peekable: bool = True) -> bool:
|
||||
"""
|
||||
Distribute the message to the recipients.
|
||||
In accordance with the Message routing structure design in Chapter 2.2.1 of RFC 116, as already planned
|
||||
in RFC 113 for the entire system, the routing information in the Message is only responsible for
|
||||
specifying the message recipient, without concern for where the message recipient is located. How to
|
||||
route the message to the message recipient is a problem addressed by the transport framework designed
|
||||
in RFC 113.
|
||||
"""
|
||||
logger.debug(f"publish_message: {message.dump()}")
|
||||
found = False
|
||||
# According to the routing feature plan in Chapter 2.2.3.2 of RFC 113
|
||||
for role, subscription in self.members.items():
|
||||
if is_subscribed(message, subscription):
|
||||
role.put_message(message)
|
||||
found = True
|
||||
if not found:
|
||||
logger.warning(f"Message no recipients: {message.dump()}")
|
||||
self.history += f"\n{message}" # For debug
|
||||
|
||||
return True
|
||||
|
||||
async def run(self, k=1):
|
||||
"""处理一次所有信息的运行
|
||||
Process all Role runs at once
|
||||
"""
|
||||
for _ in range(k):
|
||||
futures = []
|
||||
for role in self.roles.values():
|
||||
future = role.run()
|
||||
futures.append(future)
|
||||
|
||||
await asyncio.gather(*futures)
|
||||
logger.debug(f"is idle: {self.is_idle}")
|
||||
|
||||
def get_roles(self) -> dict[str, Role]:
|
||||
"""获得环境内的所有角色
|
||||
Process all Role runs at once
|
||||
"""
|
||||
return self.roles
|
||||
|
||||
def get_role(self, name: str) -> Role:
|
||||
"""获得环境内的指定角色
|
||||
get all the environment roles
|
||||
"""
|
||||
return self.roles.get(name, None)
|
||||
|
||||
def role_names(self) -> list[str]:
|
||||
return [i.name for i in self.roles.values()]
|
||||
|
||||
@property
|
||||
def is_idle(self):
|
||||
"""If true, all actions have been executed."""
|
||||
for r in self.roles.values():
|
||||
if not r.is_idle:
|
||||
return False
|
||||
return True
|
||||
|
||||
def get_subscription(self, obj):
|
||||
"""Get the labels for messages to be consumed by the object."""
|
||||
return self.members.get(obj, {})
|
||||
|
||||
def set_subscription(self, obj, tags):
|
||||
"""Set the labels for message to be consumed by the object"""
|
||||
self.members[obj] = tags
|
||||
|
||||
@staticmethod
|
||||
def archive(auto_archive=True):
|
||||
if auto_archive and CONFIG.git_repo:
|
||||
CONFIG.git_repo.archive()
|
||||
38
metagpt/environment/README.md
Normal file
38
metagpt/environment/README.md
Normal file
|
|
@ -0,0 +1,38 @@
|
|||
Here is a environment description of MetaGPT env for different situation.
|
||||
For now, the code only define the environment and still some todos like migrate roles/actions to current version.
|
||||
|
||||
## Function
|
||||
- Define `ExtEnv`(Base Class) which help users to integrate with external environment like games through apis or construct the game logics.
|
||||
- Define `Environment`(Base Class) which is the env that MetaGPT directly used. And it includes roles and so on.
|
||||
- Define the `EnvAPIRegistry` to mark the read/write apis that `ExtEnv` provide observe/step ability. And then, users can call the particular one to get observation from env or feedback to env.
|
||||
|
||||
## Usage
|
||||
|
||||
init environment
|
||||
```
|
||||
android_env = env.create(EnvType.ANDROID)
|
||||
|
||||
assistant = Role(name="Bob", profile="android assistant")
|
||||
team = Team(investment=10.0, env=android_env, roles=[assistant])
|
||||
```
|
||||
|
||||
observe & step inside role's actions
|
||||
```
|
||||
from metagpt.environment.api.env_api import EnvAPIAbstract
|
||||
|
||||
# get screenshot from ExtEnv
|
||||
screenshot_path: Path = env.observe(
|
||||
EnvAPIAbstract(
|
||||
api_name="get_screenshot", kwargs={"ss_name": f"{round_count}_before", "local_save_dir": task_dir}
|
||||
)
|
||||
)
|
||||
|
||||
# do a `tap` action on the screen
|
||||
res = env.step(EnvAPIAbstract("system_tap", kwargs={"x": x, "y": y}))
|
||||
```
|
||||
|
||||
## TODO
|
||||
- add android app operation assistant under `examples/android_assistant`
|
||||
- migrate roles/actions of werewolf game from old version into current version
|
||||
- migrate roles/actions of mincraft game from old version into current version
|
||||
- migrate roles/actions of stanford_town game from old version into current version
|
||||
13
metagpt/environment/__init__.py
Normal file
13
metagpt/environment/__init__.py
Normal file
|
|
@ -0,0 +1,13 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc :
|
||||
|
||||
from metagpt.environment.base_env import Environment
|
||||
from metagpt.environment.android_env.android_env import AndroidEnv
|
||||
from metagpt.environment.mincraft_env.mincraft_env import MincraftExtEnv
|
||||
from metagpt.environment.werewolf_env.werewolf_env import WerewolfEnv
|
||||
from metagpt.environment.stanford_town_env.stanford_town_env import StanfordTownEnv
|
||||
from metagpt.environment.software_env.software_env import SoftwareEnv
|
||||
|
||||
|
||||
__all__ = ["AndroidEnv", "MincraftExtEnv", "WerewolfEnv", "StanfordTownEnv", "SoftwareEnv", "Environment"]
|
||||
3
metagpt/environment/android_env/__init__.py
Normal file
3
metagpt/environment/android_env/__init__.py
Normal file
|
|
@ -0,0 +1,3 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc :
|
||||
13
metagpt/environment/android_env/android_env.py
Normal file
13
metagpt/environment/android_env/android_env.py
Normal file
|
|
@ -0,0 +1,13 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : MG Android Env
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.environment.android_env.android_ext_env import AndroidExtEnv
|
||||
from metagpt.environment.base_env import Environment
|
||||
|
||||
|
||||
class AndroidEnv(Environment, AndroidExtEnv):
|
||||
rows: int = Field(default=0, description="rows of a grid on the screenshot")
|
||||
cols: int = Field(default=0, description="cols of a grid on the screenshot")
|
||||
157
metagpt/environment/android_env/android_ext_env.py
Normal file
157
metagpt/environment/android_env/android_ext_env.py
Normal file
|
|
@ -0,0 +1,157 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : The Android external environment to integrate with Android apps
|
||||
|
||||
import subprocess
|
||||
from pathlib import Path
|
||||
from typing import Any, Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from metagpt.environment.android_env.const import ADB_EXEC_FAIL
|
||||
from metagpt.environment.base_env import ExtEnv, mark_as_readable, mark_as_writeable
|
||||
|
||||
|
||||
class AndroidExtEnv(ExtEnv):
|
||||
device_id: Optional[str] = Field(default=None)
|
||||
screenshot_dir: Optional[Path] = Field(default=None)
|
||||
xml_dir: Optional[Path] = Field(default=None)
|
||||
width: int = Field(default=720, description="device screen width")
|
||||
height: int = Field(default=1080, description="device screen height")
|
||||
|
||||
def __init__(self, **data: Any):
|
||||
super().__init__(**data)
|
||||
if data.get("device_id"):
|
||||
(width, height) = self.device_shape
|
||||
self.width = data.get("width", width)
|
||||
self.height = data.get("height", height)
|
||||
|
||||
@property
|
||||
def adb_prefix_si(self):
|
||||
"""adb cmd prefix with `device_id` and `shell input`"""
|
||||
return f"adb -s {self.device_id} shell input "
|
||||
|
||||
@property
|
||||
def adb_prefix_shell(self):
|
||||
"""adb cmd prefix with `device_id` and `shell`"""
|
||||
return f"adb -s {self.device_id} shell "
|
||||
|
||||
@property
|
||||
def adb_prefix(self):
|
||||
"""adb cmd prefix with `device_id`"""
|
||||
return f"adb -s {self.device_id} "
|
||||
|
||||
def execute_adb_with_cmd(self, adb_cmd: str) -> str:
|
||||
res = subprocess.run(adb_cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
|
||||
exec_res = ADB_EXEC_FAIL
|
||||
if not res.returncode:
|
||||
exec_res = res.stdout.strip()
|
||||
return exec_res
|
||||
|
||||
@property
|
||||
def device_shape(self) -> tuple[int, int]:
|
||||
adb_cmd = f"{self.adb_prefix_shell} wm size"
|
||||
shape = (0, 0)
|
||||
shape_res = self.execute_adb_with_cmd(adb_cmd)
|
||||
if shape_res != ADB_EXEC_FAIL:
|
||||
shape = tuple(map(int, shape_res.split(": ")[1].split("x")))
|
||||
return shape
|
||||
|
||||
def list_devices(self):
|
||||
adb_cmd = "adb devices"
|
||||
res = self.execute_adb_with_cmd(adb_cmd)
|
||||
devices = []
|
||||
if res != ADB_EXEC_FAIL:
|
||||
devices = res.split("\n")[1:]
|
||||
devices = [device.split()[0] for device in devices]
|
||||
return devices
|
||||
|
||||
@mark_as_readable
|
||||
def get_screenshot(self, ss_name: str, local_save_dir: Path) -> Path:
|
||||
"""
|
||||
ss_name: screenshot file name
|
||||
local_save_dir: local dir to store image from virtual machine
|
||||
"""
|
||||
assert self.screenshot_dir
|
||||
ss_remote_path = Path(self.screenshot_dir).joinpath(f"{ss_name}.png")
|
||||
ss_cmd = f"{self.adb_prefix_shell} screencap -p {ss_remote_path}"
|
||||
ss_res = self.execute_adb_with_cmd(ss_cmd)
|
||||
|
||||
res = ADB_EXEC_FAIL
|
||||
if ss_res != ADB_EXEC_FAIL:
|
||||
ss_local_path = Path(local_save_dir).joinpath(f"{ss_name}.png")
|
||||
pull_cmd = f"{self.adb_prefix} pull {ss_remote_path} {ss_local_path}"
|
||||
pull_res = self.execute_adb_with_cmd(pull_cmd)
|
||||
if pull_res != ADB_EXEC_FAIL:
|
||||
res = ss_local_path
|
||||
return Path(res)
|
||||
|
||||
@mark_as_readable
|
||||
def get_xml(self, xml_name: str, local_save_dir: Path) -> Path:
|
||||
xml_remote_path = Path(self.xml_dir).joinpath(f"{xml_name}.xml")
|
||||
dump_cmd = f"{self.adb_prefix_shell} uiautomator dump {xml_remote_path}"
|
||||
xml_res = self.execute_adb_with_cmd(dump_cmd)
|
||||
|
||||
res = ADB_EXEC_FAIL
|
||||
if xml_res != ADB_EXEC_FAIL:
|
||||
xml_local_path = Path(local_save_dir).joinpath(f"{xml_name}.xml")
|
||||
pull_cmd = f"{self.adb_prefix} pull {xml_remote_path} {xml_local_path}"
|
||||
pull_res = self.execute_adb_with_cmd(pull_cmd)
|
||||
if pull_res != ADB_EXEC_FAIL:
|
||||
res = xml_local_path
|
||||
return Path(res)
|
||||
|
||||
@mark_as_writeable
|
||||
def system_back(self) -> str:
|
||||
adb_cmd = f"{self.adb_prefix_si} keyevent KEYCODE_BACK"
|
||||
back_res = self.execute_adb_with_cmd(adb_cmd)
|
||||
return back_res
|
||||
|
||||
@mark_as_writeable
|
||||
def system_tap(self, x: int, y: int) -> str:
|
||||
adb_cmd = f"{self.adb_prefix_si} tap {x} {y}"
|
||||
tap_res = self.execute_adb_with_cmd(adb_cmd)
|
||||
return tap_res
|
||||
|
||||
@mark_as_writeable
|
||||
def user_input(self, input_txt: str) -> str:
|
||||
input_txt = input_txt.replace(" ", "%s").replace("'", "")
|
||||
adb_cmd = f"{self.adb_prefix_si} text {input_txt}"
|
||||
input_res = self.execute_adb_with_cmd(adb_cmd)
|
||||
return input_res
|
||||
|
||||
@mark_as_writeable
|
||||
def user_longpress(self, x: int, y: int, duration: int = 500) -> str:
|
||||
adb_cmd = f"{self.adb_prefix_si} swipe {x} {y} {x} {y} {duration}"
|
||||
press_res = self.execute_adb_with_cmd(adb_cmd)
|
||||
return press_res
|
||||
|
||||
@mark_as_writeable
|
||||
def user_swipe(self, x: int, y: int, orient: str = "up", dist: str = "medium", if_quick: bool = False) -> str:
|
||||
dist_unit = int(self.width / 10)
|
||||
if dist == "long":
|
||||
dist_unit *= 3
|
||||
elif dist == "medium":
|
||||
dist_unit *= 2
|
||||
|
||||
if orient == "up":
|
||||
offset = 0, -2 * dist_unit
|
||||
elif orient == "down":
|
||||
offset = 0, 2 * dist_unit
|
||||
elif orient == "left":
|
||||
offset = -1 * dist_unit, 0
|
||||
elif orient == "right":
|
||||
offset = dist_unit, 0
|
||||
else:
|
||||
return ADB_EXEC_FAIL
|
||||
|
||||
duration = 100 if if_quick else 400
|
||||
adb_cmd = f"{self.adb_prefix_si} swipe {x} {y} {x + offset[0]} {y + offset[1]} {duration}"
|
||||
swipe_res = self.execute_adb_with_cmd(adb_cmd)
|
||||
return swipe_res
|
||||
|
||||
@mark_as_writeable
|
||||
def user_swipe_to(self, start: tuple[int, int], end: tuple[int, int], duration: int = 400):
|
||||
adb_cmd = f"{self.adb_prefix_si} swipe {start[0]} {start[1]} {end[0]} {end[1]} {duration}"
|
||||
swipe_res = self.execute_adb_with_cmd(adb_cmd)
|
||||
return swipe_res
|
||||
6
metagpt/environment/android_env/const.py
Normal file
6
metagpt/environment/android_env/const.py
Normal file
|
|
@ -0,0 +1,6 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc :
|
||||
|
||||
# For Android Assistant Agent
|
||||
ADB_EXEC_FAIL = "FAILED"
|
||||
3
metagpt/environment/api/__init__.py
Normal file
3
metagpt/environment/api/__init__.py
Normal file
|
|
@ -0,0 +1,3 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc :
|
||||
60
metagpt/environment/api/env_api.py
Normal file
60
metagpt/environment/api/env_api.py
Normal file
|
|
@ -0,0 +1,60 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : the environment api store
|
||||
|
||||
from typing import Any, Callable, Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
class EnvAPIAbstract(BaseModel):
|
||||
"""api/interface summary description"""
|
||||
|
||||
api_name: str = Field(default="", description="the api function name or id")
|
||||
args: set = Field(default={}, description="the api function `args` params")
|
||||
kwargs: dict = Field(default=dict(), description="the api function `kwargs` params")
|
||||
|
||||
|
||||
class EnvAPIRegistry(BaseModel):
|
||||
"""the registry to store environment w&r api/interface"""
|
||||
|
||||
registry: dict[str, dict[str, Union[dict, Any, str]]] = Field(default=dict(), exclude=True)
|
||||
|
||||
def get(self, api_name: str):
|
||||
if api_name not in self.registry:
|
||||
raise ValueError
|
||||
return self.registry.get(api_name)
|
||||
|
||||
def __getitem__(self, api_name: str) -> Callable:
|
||||
return self.get(api_name)
|
||||
|
||||
def __setitem__(self, api_name: str, func: Callable):
|
||||
self.registry[api_name] = func
|
||||
|
||||
def __len__(self):
|
||||
return len(self.registry)
|
||||
|
||||
def get_apis(self, as_str=True) -> dict[str, dict[str, Union[dict, Any, str]]]:
|
||||
"""return func schema without func instance"""
|
||||
apis = dict()
|
||||
for func_name, func_schema in self.registry.items():
|
||||
new_func_schema = dict()
|
||||
for key, value in func_schema.items():
|
||||
if key == "func":
|
||||
continue
|
||||
new_func_schema[key] = str(value) if as_str else value
|
||||
new_func_schema = new_func_schema
|
||||
apis[func_name] = new_func_schema
|
||||
return apis
|
||||
|
||||
|
||||
class WriteAPIRegistry(EnvAPIRegistry):
|
||||
"""just as a explicit class name"""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
class ReadAPIRegistry(EnvAPIRegistry):
|
||||
"""just as a explicit class name"""
|
||||
|
||||
pass
|
||||
212
metagpt/environment/base_env.py
Normal file
212
metagpt/environment/base_env.py
Normal file
|
|
@ -0,0 +1,212 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : base env of executing environment
|
||||
|
||||
import asyncio
|
||||
from enum import Enum
|
||||
from typing import TYPE_CHECKING, Any, Dict, Iterable, Optional, Set, Union
|
||||
|
||||
from pydantic import BaseModel, ConfigDict, Field, SerializeAsAny, model_validator
|
||||
|
||||
from metagpt.context import Context
|
||||
from metagpt.environment.api.env_api import (
|
||||
EnvAPIAbstract,
|
||||
ReadAPIRegistry,
|
||||
WriteAPIRegistry,
|
||||
)
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.common import get_function_schema, is_coroutine_func, is_send_to
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from metagpt.roles.role import Role # noqa: F401
|
||||
|
||||
|
||||
class EnvType(Enum):
|
||||
ANDROID = "Android"
|
||||
GYM = "Gym"
|
||||
WEREWOLF = "Werewolf"
|
||||
MINCRAFT = "Mincraft"
|
||||
STANFORDTOWN = "StanfordTown"
|
||||
|
||||
|
||||
env_write_api_registry = WriteAPIRegistry()
|
||||
env_read_api_registry = ReadAPIRegistry()
|
||||
|
||||
|
||||
def mark_as_readable(func):
|
||||
"""mark functionn as a readable one in ExtEnv, it observes something from ExtEnv"""
|
||||
env_read_api_registry[func.__name__] = get_function_schema(func)
|
||||
return func
|
||||
|
||||
|
||||
def mark_as_writeable(func):
|
||||
"""mark functionn as a writeable one in ExtEnv, it does something to ExtEnv"""
|
||||
env_write_api_registry[func.__name__] = get_function_schema(func)
|
||||
return func
|
||||
|
||||
|
||||
class ExtEnv(BaseModel):
|
||||
"""External Env to intergate actual game environment"""
|
||||
|
||||
def _check_api_exist(self, rw_api: Optional[str] = None):
|
||||
if not rw_api:
|
||||
raise ValueError(f"{rw_api} not exists")
|
||||
|
||||
def get_all_available_apis(self, mode: str = "read") -> list[Any]:
|
||||
"""get available read/write apis definition"""
|
||||
assert mode in ["read", "write"]
|
||||
if mode == "read":
|
||||
return env_read_api_registry.get_apis()
|
||||
else:
|
||||
return env_write_api_registry.get_apis()
|
||||
|
||||
async def observe(self, env_action: Union[str, EnvAPIAbstract]):
|
||||
"""get observation from particular api of ExtEnv"""
|
||||
if isinstance(env_action, str):
|
||||
read_api = env_read_api_registry.get(api_name=env_action)["func"]
|
||||
self._check_api_exist(read_api)
|
||||
if is_coroutine_func(read_api):
|
||||
res = await read_api(self)
|
||||
else:
|
||||
res = read_api(self)
|
||||
elif isinstance(env_action, EnvAPIAbstract):
|
||||
read_api = env_read_api_registry.get(api_name=env_action.api_name)["func"]
|
||||
self._check_api_exist(read_api)
|
||||
if is_coroutine_func(read_api):
|
||||
res = await read_api(self, *env_action.args, **env_action.kwargs)
|
||||
else:
|
||||
res = read_api(self, *env_action.args, **env_action.kwargs)
|
||||
return res
|
||||
|
||||
async def step(self, env_action: Union[str, Message, EnvAPIAbstract, list[EnvAPIAbstract]]):
|
||||
"""execute through particular api of ExtEnv"""
|
||||
res = None
|
||||
if isinstance(env_action, Message):
|
||||
self.publish_message(env_action)
|
||||
elif isinstance(env_action, EnvAPIAbstract):
|
||||
write_api = env_write_api_registry.get(env_action.api_name)["func"]
|
||||
self._check_api_exist(write_api)
|
||||
if is_coroutine_func(write_api):
|
||||
res = await write_api(self, *env_action.args, **env_action.kwargs)
|
||||
else:
|
||||
res = write_api(self, *env_action.args, **env_action.kwargs)
|
||||
|
||||
return res
|
||||
|
||||
|
||||
class Environment(ExtEnv):
|
||||
"""环境,承载一批角色,角色可以向环境发布消息,可以被其他角色观察到
|
||||
Environment, hosting a batch of roles, roles can publish messages to the environment, and can be observed by other roles
|
||||
"""
|
||||
|
||||
model_config = ConfigDict(arbitrary_types_allowed=True)
|
||||
|
||||
desc: str = Field(default="") # 环境描述
|
||||
roles: dict[str, SerializeAsAny["Role"]] = Field(default_factory=dict, validate_default=True)
|
||||
member_addrs: Dict["Role", Set] = Field(default_factory=dict, exclude=True)
|
||||
history: str = "" # For debug
|
||||
context: Context = Field(default_factory=Context, exclude=True)
|
||||
|
||||
@model_validator(mode="after")
|
||||
def init_roles(self):
|
||||
self.add_roles(self.roles.values())
|
||||
return self
|
||||
|
||||
def add_role(self, role: "Role"):
|
||||
"""增加一个在当前环境的角色
|
||||
Add a role in the current environment
|
||||
"""
|
||||
self.roles[role.profile] = role
|
||||
role.set_env(self)
|
||||
role.context = self.context
|
||||
|
||||
def add_roles(self, roles: Iterable["Role"]):
|
||||
"""增加一批在当前环境的角色
|
||||
Add a batch of characters in the current environment
|
||||
"""
|
||||
for role in roles:
|
||||
self.roles[role.profile] = role
|
||||
|
||||
for role in roles: # setup system message with roles
|
||||
role.set_env(self)
|
||||
role.context = self.context
|
||||
|
||||
def publish_message(self, message: Message, peekable: bool = True) -> bool:
|
||||
"""
|
||||
Distribute the message to the recipients.
|
||||
In accordance with the Message routing structure design in Chapter 2.2.1 of RFC 116, as already planned
|
||||
in RFC 113 for the entire system, the routing information in the Message is only responsible for
|
||||
specifying the message recipient, without concern for where the message recipient is located. How to
|
||||
route the message to the message recipient is a problem addressed by the transport framework designed
|
||||
in RFC 113.
|
||||
"""
|
||||
logger.debug(f"publish_message: {message.dump()}")
|
||||
found = False
|
||||
# According to the routing feature plan in Chapter 2.2.3.2 of RFC 113
|
||||
for role, addrs in self.member_addrs.items():
|
||||
if is_send_to(message, addrs):
|
||||
role.put_message(message)
|
||||
found = True
|
||||
if not found:
|
||||
logger.warning(f"Message no recipients: {message.dump()}")
|
||||
self.history += f"\n{message}" # For debug
|
||||
|
||||
return True
|
||||
|
||||
async def run(self, k=1):
|
||||
"""处理一次所有信息的运行
|
||||
Process all Role runs at once
|
||||
"""
|
||||
for _ in range(k):
|
||||
futures = []
|
||||
for role in self.roles.values():
|
||||
future = role.run()
|
||||
futures.append(future)
|
||||
|
||||
await asyncio.gather(*futures)
|
||||
logger.debug(f"is idle: {self.is_idle}")
|
||||
|
||||
def get_roles(self) -> dict[str, "Role"]:
|
||||
"""获得环境内的所有角色
|
||||
Process all Role runs at once
|
||||
"""
|
||||
return self.roles
|
||||
|
||||
def get_role(self, name: str) -> "Role":
|
||||
"""获得环境内的指定角色
|
||||
get all the environment roles
|
||||
"""
|
||||
return self.roles.get(name, None)
|
||||
|
||||
def role_names(self) -> list[str]:
|
||||
return [i.name for i in self.roles.values()]
|
||||
|
||||
@property
|
||||
def is_idle(self):
|
||||
"""If true, all actions have been executed."""
|
||||
for r in self.roles.values():
|
||||
if not r.is_idle:
|
||||
return False
|
||||
return True
|
||||
|
||||
def get_addresses(self, obj):
|
||||
"""Get the addresses of the object."""
|
||||
return self.member_addrs.get(obj, {})
|
||||
|
||||
def set_addresses(self, obj, addresses):
|
||||
"""Set the addresses of the object"""
|
||||
self.member_addrs[obj] = addresses
|
||||
|
||||
def archive(self, auto_archive=True):
|
||||
if auto_archive and self.context.git_repo:
|
||||
self.context.git_repo.archive()
|
||||
|
||||
@classmethod
|
||||
def model_rebuild(cls, **kwargs):
|
||||
from metagpt.roles.role import Role # noqa: F401
|
||||
|
||||
super().model_rebuild(**kwargs)
|
||||
|
||||
|
||||
Environment.model_rebuild()
|
||||
3
metagpt/environment/mincraft_env/__init__.py
Normal file
3
metagpt/environment/mincraft_env/__init__.py
Normal file
|
|
@ -0,0 +1,3 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc :
|
||||
44
metagpt/environment/mincraft_env/const.py
Normal file
44
metagpt/environment/mincraft_env/const.py
Normal file
|
|
@ -0,0 +1,44 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc :
|
||||
|
||||
from metagpt.const import METAGPT_ROOT
|
||||
|
||||
# For Mincraft Game Agent
|
||||
MC_CKPT_DIR = METAGPT_ROOT / "data/mincraft/ckpt"
|
||||
MC_LOG_DIR = METAGPT_ROOT / "logs"
|
||||
MC_DEFAULT_WARMUP = {
|
||||
"context": 15,
|
||||
"biome": 10,
|
||||
"time": 15,
|
||||
"nearby_blocks": 0,
|
||||
"other_blocks": 10,
|
||||
"nearby_entities": 5,
|
||||
"health": 15,
|
||||
"hunger": 15,
|
||||
"position": 0,
|
||||
"equipment": 0,
|
||||
"inventory": 0,
|
||||
"optional_inventory_items": 7,
|
||||
"chests": 0,
|
||||
"completed_tasks": 0,
|
||||
"failed_tasks": 0,
|
||||
}
|
||||
MC_CURRICULUM_OB = [
|
||||
"context",
|
||||
"biome",
|
||||
"time",
|
||||
"nearby_blocks",
|
||||
"other_blocks",
|
||||
"nearby_entities",
|
||||
"health",
|
||||
"hunger",
|
||||
"position",
|
||||
"equipment",
|
||||
"inventory",
|
||||
"chests",
|
||||
"completed_tasks",
|
||||
"failed_tasks",
|
||||
]
|
||||
MC_CORE_INVENTORY_ITEMS = r".*_log|.*_planks|stick|crafting_table|furnace"
|
||||
r"|cobblestone|dirt|coal|.*_pickaxe|.*_sword|.*_axe", # curriculum_agent: only show these items in inventory before optional_inventory_items reached in warm up
|
||||
391
metagpt/environment/mincraft_env/mincraft_env.py
Normal file
391
metagpt/environment/mincraft_env/mincraft_env.py
Normal file
|
|
@ -0,0 +1,391 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : MG Mincraft Env
|
||||
# refs to `voyager voyager.py`
|
||||
|
||||
import json
|
||||
import re
|
||||
import time
|
||||
from typing import Any, Iterable
|
||||
|
||||
from langchain.embeddings.openai import OpenAIEmbeddings
|
||||
from langchain.vectorstores import Chroma
|
||||
from pydantic import ConfigDict, Field
|
||||
|
||||
from metagpt.config2 import config as CONFIG
|
||||
from metagpt.environment.base_env import Environment
|
||||
from metagpt.environment.mincraft_env.const import MC_CKPT_DIR
|
||||
from metagpt.environment.mincraft_env.mincraft_ext_env import MincraftExtEnv
|
||||
from metagpt.logs import logger
|
||||
from metagpt.utils.common import load_mc_skills_code, read_json_file, write_json_file
|
||||
|
||||
|
||||
class MincraftEnv(Environment, MincraftExtEnv):
|
||||
"""MincraftEnv, including shared memory of cache and infomation between roles"""
|
||||
|
||||
model_config = ConfigDict(arbitrary_types_allowed=True)
|
||||
|
||||
event: dict[str, Any] = Field(default_factory=dict)
|
||||
current_task: str = Field(default="Mine 1 wood log")
|
||||
task_execution_time: float = Field(default=float)
|
||||
context: str = Field(default="You can mine one of oak, birch, spruce, jungle, acacia, dark oak, or mangrove logs.")
|
||||
code: str = Field(default="")
|
||||
program_code: str = Field(default="") # write in skill/code/*.js
|
||||
program_name: str = Field(default="")
|
||||
critique: str = Field(default="")
|
||||
skills: dict = Field(default_factory=dict) # for skills.json
|
||||
retrieve_skills: list[str] = Field(default_factory=list)
|
||||
event_summary: str = Field(default="")
|
||||
|
||||
qa_cache: dict[str, str] = Field(default_factory=dict)
|
||||
completed_tasks: list[str] = Field(default_factory=list) # Critique things
|
||||
failed_tasks: list[str] = Field(default_factory=list)
|
||||
|
||||
skill_desp: str = Field(default="")
|
||||
|
||||
chest_memory: dict[str, Any] = Field(default_factory=dict) # eg: {'(1344, 64, 1381)': 'Unknown'}
|
||||
chest_observation: str = Field(default="") # eg: "Chests: None\n\n"
|
||||
|
||||
runtime_status: bool = False # equal to action execution status: success or failed
|
||||
|
||||
vectordb: Chroma = Field(default_factory=Chroma)
|
||||
|
||||
qa_cache_questions_vectordb: Chroma = Field(default_factory=Chroma)
|
||||
|
||||
@property
|
||||
def progress(self):
|
||||
# return len(self.completed_tasks) + 10 # Test only
|
||||
return len(self.completed_tasks)
|
||||
|
||||
@property
|
||||
def programs(self):
|
||||
programs = ""
|
||||
if self.code == "":
|
||||
return programs # TODO: maybe fix 10054 now, a better way is isolating env.step() like voyager
|
||||
for skill_name, entry in self.skills.items():
|
||||
programs += f"{entry['code']}\n\n"
|
||||
for primitives in load_mc_skills_code(): # TODO add skills_dir
|
||||
programs += f"{primitives}\n\n"
|
||||
return programs
|
||||
|
||||
def set_mc_port(self, mc_port):
|
||||
super().set_mc_port(mc_port)
|
||||
self.set_mc_resume()
|
||||
|
||||
def set_mc_resume(self):
|
||||
self.qa_cache_questions_vectordb = Chroma(
|
||||
collection_name="qa_cache_questions_vectordb",
|
||||
embedding_function=OpenAIEmbeddings(),
|
||||
persist_directory=f"{MC_CKPT_DIR}/curriculum/vectordb",
|
||||
)
|
||||
|
||||
self.vectordb = Chroma(
|
||||
collection_name="skill_vectordb",
|
||||
embedding_function=OpenAIEmbeddings(),
|
||||
persist_directory=f"{MC_CKPT_DIR}/skill/vectordb",
|
||||
)
|
||||
|
||||
if CONFIG.resume:
|
||||
logger.info(f"Loading Action Developer from {MC_CKPT_DIR}/action")
|
||||
self.chest_memory = read_json_file(f"{MC_CKPT_DIR}/action/chest_memory.json")
|
||||
|
||||
logger.info(f"Loading Curriculum Agent from {MC_CKPT_DIR}/curriculum")
|
||||
self.completed_tasks = read_json_file(f"{MC_CKPT_DIR}/curriculum/completed_tasks.json")
|
||||
self.failed_tasks = read_json_file(f"{MC_CKPT_DIR}/curriculum/failed_tasks.json")
|
||||
|
||||
logger.info(f"Loading Skill Manager from {MC_CKPT_DIR}/skill\033[0m")
|
||||
self.skills = read_json_file(f"{MC_CKPT_DIR}/skill/skills.json")
|
||||
|
||||
logger.info(f"Loading Qa Cache from {MC_CKPT_DIR}/curriculum\033[0m")
|
||||
self.qa_cache = read_json_file(f"{MC_CKPT_DIR}/curriculum/qa_cache.json")
|
||||
|
||||
if self.vectordb._collection.count() == 0:
|
||||
logger.info(self.vectordb._collection.count())
|
||||
# Set vdvs for skills & qa_cache
|
||||
skill_desps = [skill["description"] for program_name, skill in self.skills.items()]
|
||||
program_names = [program_name for program_name, skill in self.skills.items()]
|
||||
metadatas = [{"name": program_name} for program_name in program_names]
|
||||
# add vectordb from file
|
||||
self.vectordb.add_texts(
|
||||
texts=skill_desps,
|
||||
ids=program_names,
|
||||
metadatas=metadatas,
|
||||
)
|
||||
self.vectordb.persist()
|
||||
|
||||
logger.info(self.qa_cache_questions_vectordb._collection.count())
|
||||
if self.qa_cache_questions_vectordb._collection.count() == 0:
|
||||
questions = [question for question, answer in self.qa_cache.items()]
|
||||
|
||||
self.qa_cache_questions_vectordb.add_texts(texts=questions)
|
||||
|
||||
self.qa_cache_questions_vectordb.persist()
|
||||
|
||||
logger.info(
|
||||
f"INIT_CHECK: There are {self.vectordb._collection.count()} skills in vectordb and {len(self.skills)} skills in skills.json."
|
||||
)
|
||||
# Check if Skill Manager's vectordb right using
|
||||
assert self.vectordb._collection.count() == len(self.skills), (
|
||||
f"Skill Manager's vectordb is not synced with skills.json.\n"
|
||||
f"There are {self.vectordb._collection.count()} skills in vectordb but {len(self.skills)} skills in skills.json.\n"
|
||||
f"Did you set resume=False when initializing the manager?\n"
|
||||
f"You may need to manually delete the vectordb directory for running from scratch."
|
||||
)
|
||||
|
||||
logger.info(
|
||||
f"INIT_CHECK: There are {self.qa_cache_questions_vectordb._collection.count()} qa_cache in vectordb and {len(self.qa_cache)} questions in qa_cache.json."
|
||||
)
|
||||
assert self.qa_cache_questions_vectordb._collection.count() == len(self.qa_cache), (
|
||||
f"Curriculum Agent's qa cache question vectordb is not synced with qa_cache.json.\n"
|
||||
f"There are {self.qa_cache_questions_vectordb._collection.count()} questions in vectordb "
|
||||
f"but {len(self.qa_cache)} questions in qa_cache.json.\n"
|
||||
f"Did you set resume=False when initializing the agent?\n"
|
||||
f"You may need to manually delete the qa cache question vectordb directory for running from scratch.\n"
|
||||
)
|
||||
|
||||
def register_roles(self, roles: Iterable["Minecraft"]):
|
||||
for role in roles:
|
||||
role.set_memory(self)
|
||||
|
||||
def update_event(self, event: dict):
|
||||
if self.event == event:
|
||||
return
|
||||
self.event = event
|
||||
self.update_chest_memory(event)
|
||||
self.update_chest_observation()
|
||||
# self.event_summary = self.summarize_chatlog(event)
|
||||
|
||||
def update_task(self, task: str):
|
||||
self.current_task = task
|
||||
|
||||
def update_context(self, context: str):
|
||||
self.context = context
|
||||
|
||||
def update_program_code(self, program_code: str):
|
||||
self.program_code = program_code
|
||||
|
||||
def update_code(self, code: str):
|
||||
self.code = code # action_developer.gen_action_code to HERE
|
||||
|
||||
def update_program_name(self, program_name: str):
|
||||
self.program_name = program_name
|
||||
|
||||
def update_critique(self, critique: str):
|
||||
self.critique = critique # critic_agent.check_task_success to HERE
|
||||
|
||||
def append_skill(self, skill: dict):
|
||||
self.skills[self.program_name] = skill # skill_manager.retrieve_skills to HERE
|
||||
|
||||
def update_retrieve_skills(self, retrieve_skills: list):
|
||||
self.retrieve_skills = retrieve_skills
|
||||
|
||||
def update_skill_desp(self, skill_desp: str):
|
||||
self.skill_desp = skill_desp
|
||||
|
||||
async def update_qa_cache(self, qa_cache: dict):
|
||||
self.qa_cache = qa_cache
|
||||
|
||||
def update_chest_memory(self, events: dict):
|
||||
"""
|
||||
Input: events: Dict
|
||||
Result: self.chest_memory update & save to json
|
||||
"""
|
||||
nearbyChests = events[-1][1]["nearbyChests"]
|
||||
for position, chest in nearbyChests.items():
|
||||
if position in self.chest_memory:
|
||||
if isinstance(chest, dict):
|
||||
self.chest_memory[position] = chest
|
||||
if chest == "Invalid":
|
||||
logger.info(f"Action Developer removing chest {position}: {chest}")
|
||||
self.chest_memory.pop(position)
|
||||
else:
|
||||
if chest != "Invalid":
|
||||
logger.info(f"Action Developer saving chest {position}: {chest}")
|
||||
self.chest_memory[position] = chest
|
||||
|
||||
write_json_file(f"{MC_CKPT_DIR}/action/chest_memory.json", self.chest_memory)
|
||||
|
||||
def update_chest_observation(self):
|
||||
"""
|
||||
update chest_memory to chest_observation.
|
||||
Refer to @ https://github.com/MineDojo/Voyager/blob/main/voyager/agents/action.py
|
||||
"""
|
||||
|
||||
chests = []
|
||||
for chest_position, chest in self.chest_memory.items():
|
||||
if isinstance(chest, dict) and len(chest) > 0:
|
||||
chests.append(f"{chest_position}: {chest}")
|
||||
for chest_position, chest in self.chest_memory.items():
|
||||
if isinstance(chest, dict) and len(chest) == 0:
|
||||
chests.append(f"{chest_position}: Empty")
|
||||
for chest_position, chest in self.chest_memory.items():
|
||||
if isinstance(chest, str):
|
||||
assert chest == "Unknown"
|
||||
chests.append(f"{chest_position}: Unknown items inside")
|
||||
assert len(chests) == len(self.chest_memory)
|
||||
if chests:
|
||||
chests = "\n".join(chests)
|
||||
self.chest_observation = f"Chests:\n{chests}\n\n"
|
||||
else:
|
||||
self.chest_observation = "Chests: None\n\n"
|
||||
|
||||
def summarize_chatlog(self, events):
|
||||
def filter_item(message: str):
|
||||
craft_pattern = r"I cannot make \w+ because I need: (.*)"
|
||||
craft_pattern2 = r"I cannot make \w+ because there is no crafting table nearby"
|
||||
mine_pattern = r"I need at least a (.*) to mine \w+!"
|
||||
if re.match(craft_pattern, message):
|
||||
self.event_summary = re.match(craft_pattern, message).groups()[0]
|
||||
elif re.match(craft_pattern2, message):
|
||||
self.event_summary = "a nearby crafting table"
|
||||
elif re.match(mine_pattern, message):
|
||||
self.event_summary = re.match(mine_pattern, message).groups()[0]
|
||||
else:
|
||||
self.event_summary = ""
|
||||
return self.event_summary
|
||||
|
||||
chatlog = set()
|
||||
for event_type, event in events:
|
||||
if event_type == "onChat":
|
||||
item = filter_item(event["onChat"])
|
||||
if item:
|
||||
chatlog.add(item)
|
||||
self.event_summary = "I also need " + ", ".join(chatlog) + "." if chatlog else ""
|
||||
|
||||
def reset_block_info(self):
|
||||
# revert all the placing event in the last step
|
||||
pass
|
||||
|
||||
def update_exploration_progress(self, success: bool):
|
||||
"""
|
||||
Split task into completed_tasks or failed_tasks
|
||||
Args: info = {
|
||||
"task": self.task,
|
||||
"success": success,
|
||||
"conversations": self.conversations,
|
||||
}
|
||||
"""
|
||||
self.runtime_status = success
|
||||
task = self.current_task
|
||||
if task.startswith("Deposit useless items into the chest at"):
|
||||
return
|
||||
if success:
|
||||
logger.info(f"Completed task {task}.")
|
||||
self.completed_tasks.append(task)
|
||||
else:
|
||||
logger.info(f"Failed to complete task {task}. Skipping to next task.")
|
||||
self.failed_tasks.append(task)
|
||||
# when not success, below to update event!
|
||||
# revert all the placing event in the last step
|
||||
blocks = []
|
||||
positions = []
|
||||
for event_type, event in self.event:
|
||||
if event_type == "onSave" and event["onSave"].endswith("_placed"):
|
||||
block = event["onSave"].split("_placed")[0]
|
||||
position = event["status"]["position"]
|
||||
blocks.append(block)
|
||||
positions.append(position)
|
||||
new_events = self.step(
|
||||
f"await givePlacedItemBack(bot, {json.dumps(blocks)}, {json.dumps(positions)})",
|
||||
programs=self.programs,
|
||||
)
|
||||
self.event[-1][1]["inventory"] = new_events[-1][1]["inventory"]
|
||||
self.event[-1][1]["voxels"] = new_events[-1][1]["voxels"]
|
||||
|
||||
self.save_sorted_tasks()
|
||||
|
||||
def save_sorted_tasks(self):
|
||||
updated_completed_tasks = []
|
||||
# record repeated failed tasks
|
||||
updated_failed_tasks = self.failed_tasks
|
||||
# dedup but keep order
|
||||
for task in self.completed_tasks:
|
||||
if task not in updated_completed_tasks:
|
||||
updated_completed_tasks.append(task)
|
||||
|
||||
# remove completed tasks from failed tasks
|
||||
for task in updated_completed_tasks:
|
||||
while task in updated_failed_tasks:
|
||||
updated_failed_tasks.remove(task)
|
||||
|
||||
self.completed_tasks = updated_completed_tasks
|
||||
self.failed_tasks = updated_failed_tasks
|
||||
|
||||
# dump to json
|
||||
write_json_file(f"{MC_CKPT_DIR}/curriculum/completed_tasks.json", self.completed_tasks)
|
||||
write_json_file(f"{MC_CKPT_DIR}/curriculum/failed_tasks.json", self.failed_tasks)
|
||||
|
||||
async def on_event_retrieve(self, *args):
|
||||
"""
|
||||
Retrieve Minecraft events.
|
||||
|
||||
Returns:
|
||||
list: A list of Minecraft events.
|
||||
|
||||
Raises:
|
||||
Exception: If there is an issue retrieving events.
|
||||
"""
|
||||
try:
|
||||
self.reset(
|
||||
options={
|
||||
"mode": "soft",
|
||||
"wait_ticks": 20,
|
||||
}
|
||||
)
|
||||
# difficulty = "easy" if len(self.completed_tasks) > 15 else "peaceful"
|
||||
difficulty = "peaceful"
|
||||
|
||||
events = self.step("bot.chat(`/time set ${getNextTime()}`);\n" + f"bot.chat('/difficulty {difficulty}');")
|
||||
self.update_event(events)
|
||||
return events
|
||||
except Exception as e:
|
||||
time.sleep(3) # wait for mineflayer to exit
|
||||
# reset bot status here
|
||||
events = self.reset(
|
||||
options={
|
||||
"mode": "hard",
|
||||
"wait_ticks": 20,
|
||||
"inventory": self.event[-1][1]["inventory"],
|
||||
"equipment": self.event[-1][1]["status"]["equipment"],
|
||||
"position": self.event[-1][1]["status"]["position"],
|
||||
}
|
||||
)
|
||||
self.update_event(events)
|
||||
logger.error(f"Failed to retrieve Minecraft events: {str(e)}")
|
||||
return events
|
||||
|
||||
async def on_event_execute(self, *args):
|
||||
"""
|
||||
Execute Minecraft events.
|
||||
|
||||
This function is used to obtain events from the Minecraft environment. Check the implementation in
|
||||
the 'voyager/env/bridge.py step()' function to capture events generated within the game.
|
||||
|
||||
Returns:
|
||||
list: A list of Minecraft events.
|
||||
|
||||
Raises:
|
||||
Exception: If there is an issue retrieving events.
|
||||
"""
|
||||
try:
|
||||
events = self.step(
|
||||
code=self.code,
|
||||
programs=self.programs,
|
||||
)
|
||||
self.update_event(events)
|
||||
return events
|
||||
except Exception as e:
|
||||
time.sleep(3) # wait for mineflayer to exit
|
||||
# reset bot status here
|
||||
events = self.reset(
|
||||
options={
|
||||
"mode": "hard",
|
||||
"wait_ticks": 20,
|
||||
"inventory": self.event[-1][1]["inventory"],
|
||||
"equipment": self.event[-1][1]["status"]["equipment"],
|
||||
"position": self.event[-1][1]["status"]["position"],
|
||||
}
|
||||
)
|
||||
self.update_event(events)
|
||||
logger.error(f"Failed to execute Minecraft events: {str(e)}")
|
||||
return events
|
||||
180
metagpt/environment/mincraft_env/mincraft_ext_env.py
Normal file
180
metagpt/environment/mincraft_env/mincraft_ext_env.py
Normal file
|
|
@ -0,0 +1,180 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Desc : The Mincraft external environment to integrate with Mincraft game
|
||||
# refs to `voyager bridge.py`
|
||||
|
||||
import json
|
||||
import time
|
||||
from typing import Optional
|
||||
|
||||
import requests
|
||||
from pydantic import ConfigDict, Field, model_validator
|
||||
|
||||
from metagpt.environment.base_env import ExtEnv, mark_as_writeable
|
||||
from metagpt.environment.mincraft_env.const import (
|
||||
MC_CKPT_DIR,
|
||||
MC_CORE_INVENTORY_ITEMS,
|
||||
MC_CURRICULUM_OB,
|
||||
MC_DEFAULT_WARMUP,
|
||||
METAGPT_ROOT,
|
||||
)
|
||||
from metagpt.environment.mincraft_env.process_monitor import SubprocessMonitor
|
||||
from metagpt.logs import logger
|
||||
|
||||
|
||||
class MincraftExtEnv(ExtEnv):
|
||||
model_config = ConfigDict(arbitrary_types_allowed=True)
|
||||
|
||||
mc_port: Optional[int] = Field(default=None)
|
||||
server_host: str = Field(default="http://127.0.0.1")
|
||||
server_port: str = Field(default=3000)
|
||||
request_timeout: int = Field(default=600)
|
||||
|
||||
mineflayer: Optional[SubprocessMonitor] = Field(default=None, validate_default=True)
|
||||
|
||||
has_reset: bool = Field(default=False)
|
||||
reset_options: Optional[dict] = Field(default=None)
|
||||
connected: bool = Field(default=False)
|
||||
server_paused: bool = Field(default=False)
|
||||
warm_up: dict = Field(default=dict())
|
||||
|
||||
@property
|
||||
def server(self) -> str:
|
||||
return f"{self.server_host}:{self.server_port}"
|
||||
|
||||
@model_validator(mode="after")
|
||||
def _post_init_ext_env(self):
|
||||
if not self.mineflayer:
|
||||
self.mineflayer = SubprocessMonitor(
|
||||
commands=[
|
||||
"node",
|
||||
METAGPT_ROOT.joinpath("metagpt", "environment", "mincraft_env", "mineflayer", "index.js"),
|
||||
str(self.server_port),
|
||||
],
|
||||
name="mineflayer",
|
||||
ready_match=r"Server started on port (\d+)",
|
||||
)
|
||||
if not self.warm_up:
|
||||
warm_up = MC_DEFAULT_WARMUP
|
||||
if "optional_inventory_items" in warm_up:
|
||||
assert MC_CORE_INVENTORY_ITEMS is not None
|
||||
# self.core_inv_items_regex = re.compile(MC_CORE_INVENTORY_ITEMS)
|
||||
self.warm_up["optional_inventory_items"] = warm_up["optional_inventory_items"]
|
||||
else:
|
||||
self.warm_up["optional_inventory_items"] = 0
|
||||
for key in MC_CURRICULUM_OB:
|
||||
self.warm_up[key] = warm_up.get(key, MC_DEFAULT_WARMUP[key])
|
||||
self.warm_up["nearby_blocks"] = 0
|
||||
self.warm_up["inventory"] = 0
|
||||
self.warm_up["completed_tasks"] = 0
|
||||
self.warm_up["failed_tasks"] = 0
|
||||
|
||||
# init ckpt sub-forders
|
||||
MC_CKPT_DIR.joinpath("curriculum/vectordb").mkdir(parents=True, exist_ok=True)
|
||||
MC_CKPT_DIR.joinpath("action").mkdir(exist_ok=True)
|
||||
MC_CKPT_DIR.joinpath("skill/code").mkdir(parents=True, exist_ok=True)
|
||||
MC_CKPT_DIR.joinpath("skill/description").mkdir(exist_ok=True)
|
||||
MC_CKPT_DIR.joinpath("skill/vectordb").mkdir(exist_ok=True)
|
||||
|
||||
def set_mc_port(self, mc_port: int):
|
||||
self.mc_port = mc_port
|
||||
|
||||
@mark_as_writeable
|
||||
def close(self) -> bool:
|
||||
self.unpause()
|
||||
if self.connected:
|
||||
res = requests.post(f"{self.server}/stop")
|
||||
if res.status_code == 200:
|
||||
self.connected = False
|
||||
self.mineflayer.stop()
|
||||
return not self.connected
|
||||
|
||||
@mark_as_writeable
|
||||
def check_process(self) -> dict:
|
||||
retry = 0
|
||||
while not self.mineflayer.is_running:
|
||||
logger.info("Mineflayer process has exited, restarting")
|
||||
self.mineflayer.run()
|
||||
if not self.mineflayer.is_running:
|
||||
if retry > 3:
|
||||
logger.error("Mineflayer process failed to start")
|
||||
raise {}
|
||||
else:
|
||||
retry += 1
|
||||
continue
|
||||
logger.info(self.mineflayer.ready_line)
|
||||
res = requests.post(
|
||||
f"{self.server}/start",
|
||||
json=self.reset_options,
|
||||
timeout=self.request_timeout,
|
||||
)
|
||||
if res.status_code != 200:
|
||||
self.mineflayer.stop()
|
||||
logger.error(f"Minecraft server reply with code {res.status_code}")
|
||||
raise {}
|
||||
return res.json()
|
||||
|
||||
@mark_as_writeable
|
||||
def reset(self, *, seed=None, options=None) -> dict:
|
||||
if options is None:
|
||||
options = {}
|
||||
if options.get("inventory", {}) and options.get("mode", "hard") != "hard":
|
||||
logger.error("inventory can only be set when options is hard")
|
||||
raise {}
|
||||
|
||||
self.reset_options = {
|
||||
"port": self.mc_port,
|
||||
"reset": options.get("mode", "hard"),
|
||||
"inventory": options.get("inventory", {}),
|
||||
"equipment": options.get("equipment", []),
|
||||
"spread": options.get("spread", False),
|
||||
"waitTicks": options.get("wait_ticks", 5),
|
||||
"position": options.get("position", None),
|
||||
}
|
||||
|
||||
self.unpause()
|
||||
self.mineflayer.stop()
|
||||
time.sleep(1) # wait for mineflayer to exit
|
||||
|
||||
returned_data = self.check_process()
|
||||
self.has_reset = True
|
||||
self.connected = True
|
||||
# All the reset in step will be soft
|
||||
self.reset_options["reset"] = "soft"
|
||||
self.pause()
|
||||
return json.loads(returned_data)
|
||||
|
||||
@mark_as_writeable
|
||||
def step(self, code: str, programs: str = "") -> dict:
|
||||
if not self.has_reset:
|
||||
raise RuntimeError("Environment has not been reset yet")
|
||||
self.check_process()
|
||||
self.unpause()
|
||||
data = {
|
||||
"code": code,
|
||||
"programs": programs,
|
||||
}
|
||||
res = requests.post(f"{self.server}/step", json=data, timeout=self.request_timeout)
|
||||
if res.status_code != 200:
|
||||
raise RuntimeError("Failed to step Minecraft server")
|
||||
returned_data = res.json()
|
||||
self.pause()
|
||||
return json.loads(returned_data)
|
||||
|
||||
@mark_as_writeable
|
||||
def pause(self) -> bool:
|
||||
if self.mineflayer.is_running and not self.server_paused:
|
||||
res = requests.post(f"{self.server}/pause")
|
||||
if res.status_code == 200:
|
||||
self.server_paused = True
|
||||
return self.server_paused
|
||||
|
||||
@mark_as_writeable
|
||||
def unpause(self) -> bool:
|
||||
if self.mineflayer.is_running and self.server_paused:
|
||||
res = requests.post(f"{self.server}/pause")
|
||||
if res.status_code == 200:
|
||||
self.server_paused = False
|
||||
else:
|
||||
logger.info(f"mineflayer pause result: {res.json()}")
|
||||
return self.server_paused
|
||||
Some files were not shown because too many files have changed in this diff Show more
Loading…
Add table
Add a link
Reference in a new issue