mirror of
https://github.com/FoundationAgents/MetaGPT.git
synced 2026-06-14 15:25:17 +02:00
Merge branch 'geekan/dev' into feature/rebuild
This commit is contained in:
commit
5f88e12a7d
62 changed files with 1109 additions and 565 deletions
61
.github/workflows/auto-unittest.yaml
vendored
Normal file
61
.github/workflows/auto-unittest.yaml
vendored
Normal file
|
|
@ -0,0 +1,61 @@
|
|||
name: Auto Unit Tests
|
||||
|
||||
on:
|
||||
pull_request_target:
|
||||
push:
|
||||
branches:
|
||||
- 'main'
|
||||
- 'dev'
|
||||
- '*-release'
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
strategy:
|
||||
matrix:
|
||||
# python-version: ['3.9', '3.10', '3.11']
|
||||
python-version: ['3.9']
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.sha }}
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
cache: 'pip'
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
sh tests/scripts/run_install_deps.sh
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
export ALLOW_OPENAI_API_CALL=0
|
||||
mkdir -p ~/.metagpt && cp tests/config2.yaml ~/.metagpt/config2.yaml && cp tests/spark.yaml ~/.metagpt/spark.yaml
|
||||
pytest tests/ --doctest-modules --cov=./metagpt/ --cov-report=xml:cov.xml --cov-report=html:htmlcov --durations=20 | tee unittest.txt
|
||||
- name: Show coverage report
|
||||
run: |
|
||||
coverage report -m
|
||||
- name: Show failed tests and overall summary
|
||||
run: |
|
||||
grep -E "FAILED tests|ERROR tests|[0-9]+ passed," unittest.txt
|
||||
failed_count=$(grep -E "FAILED|ERROR" unittest.txt | wc -l)
|
||||
if [[ "$failed_count" -gt 0 ]]; then
|
||||
echo "$failed_count failed lines found! Task failed."
|
||||
exit 1
|
||||
fi
|
||||
- name: Upload pytest test results
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: pytest-results-${{ matrix.python-version }}
|
||||
path: |
|
||||
./unittest.txt
|
||||
./htmlcov/
|
||||
./tests/data/rsp_cache_new.json
|
||||
retention-days: 3
|
||||
if: ${{ always() }}
|
||||
- name: Upload coverage reports to Codecov
|
||||
uses: codecov/codecov-action@v3
|
||||
env:
|
||||
CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
|
||||
if: ${{ always() }}
|
||||
4
.github/workflows/unittest.yaml
vendored
4
.github/workflows/unittest.yaml
vendored
|
|
@ -5,6 +5,9 @@ on:
|
|||
pull_request_target:
|
||||
push:
|
||||
branches:
|
||||
- 'main'
|
||||
- 'dev'
|
||||
- '*-release'
|
||||
- '*-debugger'
|
||||
|
||||
jobs:
|
||||
|
|
@ -51,6 +54,7 @@ jobs:
|
|||
export ALLOW_OPENAI_API_CALL=0
|
||||
echo "${{ secrets.METAGPT_KEY_YAML }}" | base64 -d > config/key.yaml
|
||||
mkdir -p ~/.metagpt && echo "${{ secrets.METAGPT_CONFIG2_YAML }}" | base64 -d > ~/.metagpt/config2.yaml
|
||||
echo "${{ secrets.SPARK_YAML }}" | base64 -d > ~/.metagpt/spark.yaml
|
||||
pytest tests/ --doctest-modules --cov=./metagpt/ --cov-report=xml:cov.xml --cov-report=html:htmlcov --durations=20 | tee unittest.txt
|
||||
- name: Show coverage report
|
||||
run: |
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ RUN apt update &&\
|
|||
|
||||
# Install Mermaid CLI globally
|
||||
ENV CHROME_BIN="/usr/bin/chromium" \
|
||||
PUPPETEER_CONFIG="/app/metagpt/config/puppeteer-config.json"\
|
||||
puppeteer_config="/app/metagpt/config/puppeteer-config.json"\
|
||||
PUPPETEER_SKIP_CHROMIUM_DOWNLOAD="true"
|
||||
RUN npm install -g @mermaid-js/mermaid-cli &&\
|
||||
npm cache clean --force
|
||||
|
|
|
|||
43
README.md
43
README.md
|
|
@ -55,30 +55,21 @@ ## Install
|
|||
|
||||
### Pip installation
|
||||
|
||||
> Ensure that Python 3.9+ is installed on your system. You can check this by using: `python --version`.
|
||||
> You can use conda like this: `conda create -n metagpt python=3.9 && conda activate metagpt`
|
||||
|
||||
```bash
|
||||
# Step 1: Ensure that Python 3.9+ is installed on your system. You can check this by using:
|
||||
# You can use conda to initialize a new python env
|
||||
# conda create -n metagpt python=3.9
|
||||
# conda activate metagpt
|
||||
python3 --version
|
||||
pip install metagpt
|
||||
metagpt --init-config # create ~/.metagpt/config2.yaml, modify it to your own config
|
||||
metagpt "Create a 2048 game" # this will create a repo in ./workspace
|
||||
```
|
||||
|
||||
# Step 2: Clone the repository to your local machine for latest version, and install it.
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip3 install -e . # or pip3 install metagpt # for stable version
|
||||
or you can use it as library
|
||||
|
||||
# Step 3: setup your OPENAI_API_KEY, or make sure it existed in the env
|
||||
mkdir ~/.metagpt
|
||||
cp config/config.yaml ~/.metagpt/config.yaml
|
||||
vim ~/.metagpt/config.yaml
|
||||
|
||||
# Step 4: run metagpt cli
|
||||
metagpt "Create a 2048 game in python"
|
||||
|
||||
# Step 5 [Optional]: If you want to save the artifacts like diagrams such as quadrant chart, system designs, sequence flow in the workspace, you can execute the step before Step 3. By default, the framework is compatible, and the entire process can be run completely without executing this step.
|
||||
# If executing, ensure that NPM is installed on your system. Then install mermaid-js. (If you don't have npm in your computer, please go to the Node.js official website to install Node.js https://nodejs.org/ and then you will have npm tool in your computer.)
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
```python
|
||||
from metagpt.software_company import generate_repo, ProjectRepo
|
||||
repo: ProjectRepo = generate_repo("Create a 2048 game") # or ProjectRepo("<path>")
|
||||
print(repo) # it will print the repo structure with files
|
||||
```
|
||||
|
||||
detail installation please refer to [cli_install](https://docs.deepwisdom.ai/main/en/guide/get_started/installation.html#install-stable-version)
|
||||
|
|
@ -87,19 +78,19 @@ ### Docker installation
|
|||
> Note: In the Windows, you need to replace "/opt/metagpt" with a directory that Docker has permission to create, such as "D:\Users\x\metagpt"
|
||||
|
||||
```bash
|
||||
# Step 1: Download metagpt official image and prepare config.yaml
|
||||
# Step 1: Download metagpt official image and prepare config2.yaml
|
||||
docker pull metagpt/metagpt:latest
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # Change the config
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
|
||||
vim /opt/metagpt/config/config2.yaml # Change the config
|
||||
|
||||
# Step 2: Run metagpt demo with container
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
metagpt "Write a cli snake game"
|
||||
metagpt "Create a 2048 game"
|
||||
```
|
||||
|
||||
detail installation please refer to [docker_install](https://docs.deepwisdom.ai/main/en/guide/get_started/installation.html#install-with-docker)
|
||||
|
|
|
|||
|
|
@ -1,3 +1,3 @@
|
|||
llm:
|
||||
api_key: "YOUR_API_KEY"
|
||||
model: "gpt-3.5-turbo-1106"
|
||||
model: "gpt-4-turbo-preview" # or gpt-3.5-turbo-1106 / gpt-4-1106-preview
|
||||
|
|
@ -2,7 +2,7 @@ llm:
|
|||
api_type: "openai"
|
||||
base_url: "YOUR_BASE_URL"
|
||||
api_key: "YOUR_API_KEY"
|
||||
model: "gpt-3.5-turbo-1106" # or gpt-4-1106-preview
|
||||
model: "gpt-4-turbo-preview" # or gpt-3.5-turbo-1106 / gpt-4-1106-preview
|
||||
|
||||
proxy: "YOUR_PROXY"
|
||||
|
||||
|
|
@ -29,14 +29,13 @@ s3:
|
|||
bucket: "test"
|
||||
|
||||
|
||||
AZURE_TTS_SUBSCRIPTION_KEY: "YOUR_SUBSCRIPTION_KEY"
|
||||
AZURE_TTS_REGION: "eastus"
|
||||
azure_tts_subscription_key: "YOUR_SUBSCRIPTION_KEY"
|
||||
azure_tts_region: "eastus"
|
||||
|
||||
IFLYTEK_APP_ID: "YOUR_APP_ID"
|
||||
IFLYTEK_API_KEY: "YOUR_API_KEY"
|
||||
IFLYTEK_API_SECRET: "YOUR_API_SECRET"
|
||||
iflytek_api_id: "YOUR_APP_ID"
|
||||
iflytek_api_key: "YOUR_API_KEY"
|
||||
iflytek_api_secret: "YOUR_API_SECRET"
|
||||
|
||||
METAGPT_TEXT_TO_IMAGE_MODEL_URL: "YOUR_MODEL_URL"
|
||||
|
||||
PYPPETEER_EXECUTABLE_PATH: "/Applications/Google Chrome.app"
|
||||
metagpt_tti_url: "YOUR_MODEL_URL"
|
||||
|
||||
repair_llm_output: true
|
||||
|
|
|
|||
|
|
@ -14,16 +14,16 @@ paths:
|
|||
/tts/azsure:
|
||||
x-prerequisite:
|
||||
configurations:
|
||||
AZURE_TTS_SUBSCRIPTION_KEY:
|
||||
azure_tts_subscription_key:
|
||||
type: string
|
||||
description: "For more details, check out: [Azure Text-to_Speech](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts)"
|
||||
AZURE_TTS_REGION:
|
||||
azure_tts_region:
|
||||
type: string
|
||||
description: "For more details, check out: [Azure Text-to_Speech](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts)"
|
||||
required:
|
||||
allOf:
|
||||
- AZURE_TTS_SUBSCRIPTION_KEY
|
||||
- AZURE_TTS_REGION
|
||||
- azure_tts_subscription_key
|
||||
- azure_tts_region
|
||||
post:
|
||||
summary: "Convert Text to Base64-encoded .wav File Stream"
|
||||
description: "For more details, check out: [Azure Text-to_Speech](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts)"
|
||||
|
|
@ -94,9 +94,9 @@ paths:
|
|||
description: "WebAPI argument, see: `https://console.xfyun.cn/services/tts`"
|
||||
required:
|
||||
allOf:
|
||||
- IFLYTEK_APP_ID
|
||||
- IFLYTEK_API_KEY
|
||||
- IFLYTEK_API_SECRET
|
||||
- iflytek_app_id
|
||||
- iflytek_api_key
|
||||
- iflytek_api_secret
|
||||
post:
|
||||
summary: "Convert Text to Base64-encoded .mp3 File Stream"
|
||||
description: "For more details, check out: [iFlyTek](https://console.xfyun.cn/services/tts)"
|
||||
|
|
@ -242,12 +242,12 @@ paths:
|
|||
/txt2image/metagpt:
|
||||
x-prerequisite:
|
||||
configurations:
|
||||
METAGPT_TEXT_TO_IMAGE_MODEL_URL:
|
||||
metagpt_tti_url:
|
||||
type: string
|
||||
description: "Model url."
|
||||
required:
|
||||
allOf:
|
||||
- METAGPT_TEXT_TO_IMAGE_MODEL_URL
|
||||
- metagpt_tti_url
|
||||
post:
|
||||
summary: "Text to Image"
|
||||
description: "Generate an image from the provided text using the MetaGPT Text-to-Image API."
|
||||
|
|
|
|||
|
|
@ -14,10 +14,10 @@ entities:
|
|||
id: text_to_speech.text_to_speech
|
||||
x-prerequisite:
|
||||
configurations:
|
||||
AZURE_TTS_SUBSCRIPTION_KEY:
|
||||
azure_tts_subscription_key:
|
||||
type: string
|
||||
description: "For more details, check out: [Azure Text-to_Speech](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts)"
|
||||
AZURE_TTS_REGION:
|
||||
azure_tts_region:
|
||||
type: string
|
||||
description: "For more details, check out: [Azure Text-to_Speech](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts)"
|
||||
IFLYTEK_APP_ID:
|
||||
|
|
@ -32,12 +32,12 @@ entities:
|
|||
required:
|
||||
oneOf:
|
||||
- allOf:
|
||||
- AZURE_TTS_SUBSCRIPTION_KEY
|
||||
- AZURE_TTS_REGION
|
||||
- azure_tts_subscription_key
|
||||
- azure_tts_region
|
||||
- allOf:
|
||||
- IFLYTEK_APP_ID
|
||||
- IFLYTEK_API_KEY
|
||||
- IFLYTEK_API_SECRET
|
||||
- iflytek_app_id
|
||||
- iflytek_api_key
|
||||
- iflytek_api_secret
|
||||
parameters:
|
||||
text:
|
||||
description: 'The text used for voice conversion.'
|
||||
|
|
@ -103,13 +103,13 @@ entities:
|
|||
OPENAI_API_KEY:
|
||||
type: string
|
||||
description: "OpenAI API key, For more details, checkout: `https://platform.openai.com/account/api-keys`"
|
||||
METAGPT_TEXT_TO_IMAGE_MODEL_URL:
|
||||
metagpt_tti_url:
|
||||
type: string
|
||||
description: "Model url."
|
||||
required:
|
||||
oneOf:
|
||||
- OPENAI_API_KEY
|
||||
- METAGPT_TEXT_TO_IMAGE_MODEL_URL
|
||||
- metagpt_tti_url
|
||||
parameters:
|
||||
text:
|
||||
description: 'The text used for image conversion.'
|
||||
|
|
|
|||
198
docs/FAQ-EN.md
198
docs/FAQ-EN.md
|
|
@ -1,183 +1,93 @@
|
|||
Our vision is to [extend human life](https://github.com/geekan/HowToLiveLonger) and [reduce working hours](https://github.com/geekan/MetaGPT/).
|
||||
|
||||
1. ### Convenient Link for Sharing this Document:
|
||||
### Convenient Link for Sharing this Document:
|
||||
|
||||
```
|
||||
- MetaGPT-Index/FAQ https://deepwisdom.feishu.cn/wiki/MsGnwQBjiif9c3koSJNcYaoSnu4
|
||||
- MetaGPT-Index/FAQ-EN https://github.com/geekan/MetaGPT/blob/main/docs/FAQ-EN.md
|
||||
- MetaGPT-Index/FAQ-CN https://deepwisdom.feishu.cn/wiki/MsGnwQBjiif9c3koSJNcYaoSnu4
|
||||
```
|
||||
|
||||
2. ### Link
|
||||
|
||||
<!---->
|
||||
### Link
|
||||
|
||||
1. Code:https://github.com/geekan/MetaGPT
|
||||
|
||||
1. Roadmap:https://github.com/geekan/MetaGPT/blob/main/docs/ROADMAP.md
|
||||
|
||||
1. EN
|
||||
|
||||
1. Demo Video: [MetaGPT: Multi-Agent AI Programming Framework](https://www.youtube.com/watch?v=8RNzxZBTW8M)
|
||||
2. Roadmap:https://github.com/geekan/MetaGPT/blob/main/docs/ROADMAP.md
|
||||
3. EN
|
||||
1. Demo Video: [MetaGPT: Multi-Agent AI Programming Framework](https://www.youtube.com/watch?v=8RNzxZBTW8M)
|
||||
2. Tutorial: [MetaGPT: Deploy POWERFUL Autonomous Ai Agents BETTER Than SUPERAGI!](https://www.youtube.com/watch?v=q16Gi9pTG_M&t=659s)
|
||||
3. Author's thoughts video(EN): [MetaGPT Matthew Berman](https://youtu.be/uT75J_KG_aY?si=EgbfQNAwD8F5Y1Ak)
|
||||
4. CN
|
||||
1. Demo Video: [MetaGPT:一行代码搭建你的虚拟公司_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1NP411C7GW/?spm_id_from=333.999.0.0&vd_source=735773c218b47da1b4bd1b98a33c5c77)
|
||||
1. Tutorial: [一个提示词写游戏 Flappy bird, 比AutoGPT强10倍的MetaGPT,最接近AGI的AI项目](https://youtu.be/Bp95b8yIH5c)
|
||||
2. Author's thoughts video(CN): [MetaGPT作者深度解析直播回放_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1Ru411V7XL/?spm_id_from=333.337.search-card.all.click)
|
||||
|
||||
1. CN
|
||||
|
||||
1. Demo Video: [MetaGPT:一行代码搭建你的虚拟公司_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1NP411C7GW/?spm_id_from=333.999.0.0&vd_source=735773c218b47da1b4bd1b98a33c5c77)
|
||||
1. Tutorial: [一个提示词写游戏 Flappy bird, 比AutoGPT强10倍的MetaGPT,最接近AGI的AI项目](https://youtu.be/Bp95b8yIH5c)
|
||||
2. Author's thoughts video(CN): [MetaGPT作者深度解析直播回放_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1Ru411V7XL/?spm_id_from=333.337.search-card.all.click)
|
||||
|
||||
<!---->
|
||||
|
||||
3. ### How to become a contributor?
|
||||
|
||||
<!---->
|
||||
### How to become a contributor?
|
||||
|
||||
1. Choose a task from the Roadmap (or you can propose one). By submitting a PR, you can become a contributor and join the dev team.
|
||||
1. Current contributors come from backgrounds including ByteDance AI Lab/DingDong/Didi/Xiaohongshu, Tencent/Baidu/MSRA/TikTok/BloomGPT Infra/Bilibili/CUHK/HKUST/CMU/UCB
|
||||
2. Current contributors come from backgrounds including ByteDance AI Lab/DingDong/Didi/Xiaohongshu, Tencent/Baidu/MSRA/TikTok/BloomGPT Infra/Bilibili/CUHK/HKUST/CMU/UCB
|
||||
|
||||
<!---->
|
||||
|
||||
4. ### Chief Evangelist (Monthly Rotation)
|
||||
### Chief Evangelist (Monthly Rotation)
|
||||
|
||||
MetaGPT Community - The position of Chief Evangelist rotates on a monthly basis. The primary responsibilities include:
|
||||
|
||||
1. Maintaining community FAQ documents, announcements, and Github resources/READMEs.
|
||||
1. Responding to, answering, and distributing community questions within an average of 30 minutes, including on platforms like Github Issues, Discord and WeChat.
|
||||
1. Upholding a community atmosphere that is enthusiastic, genuine, and friendly.
|
||||
1. Encouraging everyone to become contributors and participate in projects that are closely related to achieving AGI (Artificial General Intelligence).
|
||||
1. (Optional) Organizing small-scale events, such as hackathons.
|
||||
2. Responding to, answering, and distributing community questions within an average of 30 minutes, including on platforms like Github Issues, Discord and WeChat.
|
||||
3. Upholding a community atmosphere that is enthusiastic, genuine, and friendly.
|
||||
4. Encouraging everyone to become contributors and participate in projects that are closely related to achieving AGI (Artificial General Intelligence).
|
||||
5. (Optional) Organizing small-scale events, such as hackathons.
|
||||
|
||||
<!---->
|
||||
|
||||
5. ### FAQ
|
||||
|
||||
<!---->
|
||||
|
||||
1. Experience with the generated repo code:
|
||||
|
||||
1. https://github.com/geekan/MetaGPT/releases/tag/v0.1.0
|
||||
### FAQ
|
||||
|
||||
1. Code truncation/ Parsing failure:
|
||||
|
||||
1. Check if it's due to exceeding length. Consider using the gpt-3.5-turbo-16k or other long token versions.
|
||||
|
||||
1. Success rate:
|
||||
|
||||
1. There hasn't been a quantitative analysis yet, but the success rate of code generated by GPT-4 is significantly higher than that of gpt-3.5-turbo.
|
||||
|
||||
1. Support for incremental, differential updates (if you wish to continue a half-done task):
|
||||
|
||||
1. Several prerequisite tasks are listed on the ROADMAP.
|
||||
|
||||
1. Can existing code be loaded?
|
||||
|
||||
1. It's not on the ROADMAP yet, but there are plans in place. It just requires some time.
|
||||
|
||||
1. Support for multiple programming languages and natural languages?
|
||||
|
||||
1. It's listed on ROADMAP.
|
||||
|
||||
1. Want to join the contributor team? How to proceed?
|
||||
|
||||
1. Check if it's due to exceeding length. Consider using the gpt-4-turbo-preview or other long token versions.
|
||||
2. Success rate:
|
||||
1. There hasn't been a quantitative analysis yet, but the success rate of code generated by gpt-4-turbo-preview is significantly higher than that of gpt-3.5-turbo.
|
||||
3. Support for incremental, differential updates (if you wish to continue a half-done task):
|
||||
1. There is now an experimental version. Specify `--inc --project-path "<path>"` or `--inc --project-name "<name>"` on the command line and enter the corresponding requirements to try it.
|
||||
4. Can existing code be loaded?
|
||||
1. We are doing this, but it is very difficult, especially when the project is large, it is very difficult to achieve a high success rate.
|
||||
5. Support for multiple programming languages and natural languages?
|
||||
1. It is now supported, but it is still in experimental version
|
||||
6. Want to join the contributor team? How to proceed?
|
||||
1. Merging a PR will get you into the contributor's team. The main ongoing tasks are all listed on the ROADMAP.
|
||||
|
||||
1. PRD stuck / unable to access/ connection interrupted
|
||||
|
||||
1. The official OPENAI_BASE_URL address is `https://api.openai.com/v1`
|
||||
1. If the official OPENAI_BASE_URL address is inaccessible in your environment (this can be verified with curl), it's recommended to configure using the reverse proxy OPENAI_BASE_URL provided by libraries such as openai-forward. For instance, `OPENAI_BASE_URL: "``https://api.openai-forward.com/v1``"`
|
||||
1. If the official OPENAI_BASE_URL address is inaccessible in your environment (again, verifiable via curl), another option is to configure the OPENAI_PROXY parameter. This way, you can access the official OPENAI_BASE_URL via a local proxy. If you don't need to access via a proxy, please do not enable this configuration; if accessing through a proxy is required, modify it to the correct proxy address. Note that when OPENAI_PROXY is enabled, don't set OPENAI_BASE_URL.
|
||||
1. Note: OpenAI's default API design ends with a v1. An example of the correct configuration is: `OPENAI_BASE_URL: "``https://api.openai.com/v1``"`
|
||||
|
||||
1. Absolutely! How can I assist you today?
|
||||
|
||||
7. PRD stuck / unable to access/ connection interrupted
|
||||
1. The official openai base_url address is `https://api.openai.com/v1`
|
||||
2. If the official openai base_url address is inaccessible in your environment (this can be verified with curl), it's recommended to configure using base_url to other "reverse-proxy" provider such as openai-forward. For instance, `openai base_url: "``https://api.openai-forward.com/v1``"`
|
||||
3. If the official openai base_url address is inaccessible in your environment (again, verifiable via curl), another option is to configure the llm.proxy in the `config2.yaml`. This way, you can access the official openai base_url via a local proxy. If you don't need to access via a proxy, please do not enable this configuration; if accessing through a proxy is required, modify it to the correct proxy address.
|
||||
4. Note: OpenAI's default API design ends with a v1. An example of the correct configuration is: `base_url: "https://api.openai.com/v1"
|
||||
8. Get reply: "Absolutely! How can I assist you today?"
|
||||
1. Did you use Chi or a similar service? These services are prone to errors, and it seems that the error rate is higher when consuming 3.5k-4k tokens in GPT-4
|
||||
|
||||
1. What does Max token mean?
|
||||
|
||||
9. What does Max token mean?
|
||||
1. It's a configuration for OpenAI's maximum response length. If the response exceeds the max token, it will be truncated.
|
||||
|
||||
1. How to change the investment amount?
|
||||
|
||||
10. How to change the investment amount?
|
||||
1. You can view all commands by typing `metagpt --help`
|
||||
|
||||
1. Which version of Python is more stable?
|
||||
|
||||
11. Which version of Python is more stable?
|
||||
1. python3.9 / python3.10
|
||||
|
||||
1. Can't use GPT-4, getting the error "The model gpt-4 does not exist."
|
||||
|
||||
12. Can't use GPT-4, getting the error "The model gpt-4 does not exist."
|
||||
1. OpenAI's official requirement: You can use GPT-4 only after spending $1 on OpenAI.
|
||||
1. Tip: Run some data with gpt-3.5-turbo (consume the free quota and $1), and then you should be able to use gpt-4.
|
||||
|
||||
1. Can games whose code has never been seen before be written?
|
||||
|
||||
13. Can games whose code has never been seen before be written?
|
||||
1. Refer to the README. The recommendation system of Toutiao is one of the most complex systems in the world currently. Although it's not on GitHub, many discussions about it exist online. If it can visualize these, it suggests it can also summarize these discussions and convert them into code. The prompt would be something like "write a recommendation system similar to Toutiao". Note: this was approached in earlier versions of the software. The SOP of those versions was different; the current one adopts Elon Musk's five-step work method, emphasizing trimming down requirements as much as possible.
|
||||
|
||||
1. Under what circumstances would there typically be errors?
|
||||
|
||||
14. Under what circumstances would there typically be errors?
|
||||
1. More than 500 lines of code: some function implementations may be left blank.
|
||||
1. When using a database, it often gets the implementation wrong — since the SQL database initialization process is usually not in the code.
|
||||
1. With more lines of code, there's a higher chance of false impressions, leading to calls to non-existent APIs.
|
||||
|
||||
1. Instructions for using SD Skills/UI Role:
|
||||
|
||||
1. Currently, there is a test script located in /tests/metagpt/roles. The file ui_role provides the corresponding code implementation. For testing, you can refer to the test_ui in the same directory.
|
||||
|
||||
1. The UI role takes over from the product manager role, extending the output from the 【UI Design draft】 provided by the product manager role. The UI role has implemented the UIDesign Action. Within the run of UIDesign, it processes the respective context, and based on the set template, outputs the UI. The output from the UI role includes:
|
||||
|
||||
1. UI Design Description: Describes the content to be designed and the design objectives.
|
||||
1. Selected Elements: Describes the elements in the design that need to be illustrated.
|
||||
1. HTML Layout: Outputs the HTML code for the page.
|
||||
1. CSS Styles (styles.css): Outputs the CSS code for the page.
|
||||
|
||||
1. Currently, the SD skill is a tool invoked by UIDesign. It instantiates the SDEngine, with specific code found in metagpt/tools/sd_engine.
|
||||
|
||||
1. Configuration instructions for SD Skills: The SD interface is currently deployed based on *https://github.com/AUTOMATIC1111/stable-diffusion-webui* **For environmental configurations and model downloads, please refer to the aforementioned GitHub repository. To initiate the SD service that supports API calls, run the command specified in cmd with the parameter nowebui, i.e.,
|
||||
|
||||
1. > python3 webui.py --enable-insecure-extension-access --port xxx --no-gradio-queue --nowebui
|
||||
1. Once it runs without errors, the interface will be accessible after approximately 1 minute when the model finishes loading.
|
||||
1. Configure SD_URL and SD_T2I_API in the config.yaml/key.yaml files.
|
||||
1. 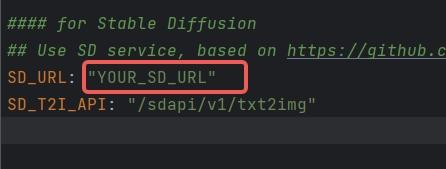
|
||||
1. SD_URL is the deployed server/machine IP, and Port is the specified port above, defaulting to 7860.
|
||||
1. > SD_URL: IP:Port
|
||||
|
||||
1. An error occurred during installation: "Another program is using this file...egg".
|
||||
|
||||
2. When using a database, it often gets the implementation wrong — since the SQL database initialization process is usually not in the code.
|
||||
3. With more lines of code, there's a higher chance of false impressions, leading to calls to non-existent APIs.
|
||||
15. An error occurred during installation: "Another program is using this file...egg".
|
||||
1. Delete the file and try again.
|
||||
1. Or manually execute`pip install -r requirements.txt`
|
||||
|
||||
1. The origin of the name MetaGPT?
|
||||
|
||||
2. Or manually execute`pip install -r requirements.txt`
|
||||
16. The origin of the name MetaGPT?
|
||||
1. The name was derived after iterating with GPT-4 over a dozen rounds. GPT-4 scored and suggested it.
|
||||
|
||||
1. Is there a more step-by-step installation tutorial?
|
||||
|
||||
1. Youtube(CN):[一个提示词写游戏 Flappy bird, 比AutoGPT强10倍的MetaGPT,最接近AGI的AI项目=一个软件公司产品经理+程序员](https://youtu.be/Bp95b8yIH5c)
|
||||
1. Youtube(EN)https://www.youtube.com/watch?v=q16Gi9pTG_M&t=659s
|
||||
2. video(EN): [MetaGPT Matthew Berman](https://youtu.be/uT75J_KG_aY?si=EgbfQNAwD8F5Y1Ak)
|
||||
|
||||
1. openai.error.RateLimitError: You exceeded your current quota, please check your plan and billing details
|
||||
|
||||
17. openai.error.RateLimitError: You exceeded your current quota, please check your plan and billing details
|
||||
1. If you haven't exhausted your free quota, set RPM to 3 or lower in the settings.
|
||||
1. If your free quota is used up, consider adding funds to your account.
|
||||
|
||||
1. What does "borg" mean in n_borg?
|
||||
|
||||
2. If your free quota is used up, consider adding funds to your account.
|
||||
18. What does "borg" mean in n_borg?
|
||||
1. [Wikipedia borg meaning ](https://en.wikipedia.org/wiki/Borg)
|
||||
1. The Borg civilization operates based on a hive or collective mentality, known as "the Collective." Every Borg individual is connected to the collective via a sophisticated subspace network, ensuring continuous oversight and guidance for every member. This collective consciousness allows them to not only "share the same thoughts" but also to adapt swiftly to new strategies. While individual members of the collective rarely communicate, the collective "voice" sometimes transmits aboard ships.
|
||||
|
||||
1. How to use the Claude API?
|
||||
|
||||
2. The Borg civilization operates based on a hive or collective mentality, known as "the Collective." Every Borg individual is connected to the collective via a sophisticated subspace network, ensuring continuous oversight and guidance for every member. This collective consciousness allows them to not only "share the same thoughts" but also to adapt swiftly to new strategies. While individual members of the collective rarely communicate, the collective "voice" sometimes transmits aboard ships.
|
||||
19. How to use the Claude API?
|
||||
1. The full implementation of the Claude API is not provided in the current code.
|
||||
1. You can use the Claude API through third-party API conversion projects like: https://github.com/jtsang4/claude-to-chatgpt
|
||||
|
||||
1. Is Llama2 supported?
|
||||
|
||||
20. Is Llama2 supported?
|
||||
1. On the day Llama2 was released, some of the community members began experiments and found that output can be generated based on MetaGPT's structure. However, Llama2's context is too short to generate a complete project. Before regularly using Llama2, it's necessary to expand the context window to at least 8k. If anyone has good recommendations for expansion models or methods, please leave a comment.
|
||||
|
||||
1. `mermaid-cli getElementsByTagName SyntaxError: Unexpected token '.'`
|
||||
|
||||
21. `mermaid-cli getElementsByTagName SyntaxError: Unexpected token '.'`
|
||||
1. Upgrade node to version 14.x or above:
|
||||
|
||||
1. `npm install -g n`
|
||||
1. `n stable` to install the stable version of node(v18.x)
|
||||
2. `n stable` to install the stable version of node(v18.x)
|
||||
|
|
|
|||
|
|
@ -35,50 +35,45 @@ # MetaGPT: 多智能体框架
|
|||
## 安装
|
||||
### Pip安装
|
||||
|
||||
> 确保您的系统已安装 Python 3.9 或更高版本。您可以使用以下命令来检查:`python --version`。
|
||||
> 您可以这样使用 conda:`conda create -n metagpt python=3.9 && conda activate metagpt`
|
||||
|
||||
```bash
|
||||
# 第 1 步:确保您的系统上安装了 Python 3.9+。您可以使用以下命令进行检查:
|
||||
# 可以使用conda来初始化新的python环境
|
||||
# conda create -n metagpt python=3.9
|
||||
# conda activate metagpt
|
||||
python3 --version
|
||||
|
||||
# 第 2 步:克隆最新仓库到您的本地机器,并进行安装。
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip3 install -e. # 或者 pip3 install metagpt # 安装稳定版本
|
||||
|
||||
# 第 3 步:执行metagpt
|
||||
# 拷贝config.yaml为key.yaml,并设置你自己的OPENAI_API_KEY
|
||||
metagpt "Write a cli snake game"
|
||||
|
||||
# 第 4 步【可选的】:如果你想在执行过程中保存像象限图、系统设计、序列流程等图表这些产物,可以在第3步前执行该步骤。默认的,框架做了兼容,在不执行该步的情况下,也可以完整跑完整个流程。
|
||||
# 如果执行,确保您的系统上安装了 NPM。并使用npm安装mermaid-js
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
pip install metagpt
|
||||
metagpt --init-config # 创建 ~/.metagpt/config2.yaml,根据您的需求修改它
|
||||
metagpt "创建一个 2048 游戏" # 这将在 ./workspace 创建一个仓库
|
||||
```
|
||||
|
||||
详细的安装请安装 [cli_install](https://docs.deepwisdom.ai/guide/get_started/installation.html#install-stable-version)
|
||||
或者您可以将其作为库使用
|
||||
|
||||
```python
|
||||
from metagpt.software_company import generate_repo, ProjectRepo
|
||||
repo: ProjectRepo = generate_repo("创建一个 2048 游戏") # 或 ProjectRepo("<路径>")
|
||||
print(repo) # 它将打印出仓库结构及其文件
|
||||
```
|
||||
|
||||
详细的安装请参考 [cli_install](https://docs.deepwisdom.ai/guide/get_started/installation.html#install-stable-version)
|
||||
|
||||
### Docker安装
|
||||
> 注意:在Windows中,你需要将 "/opt/metagpt" 替换为Docker具有创建权限的目录,比如"D:\Users\x\metagpt"
|
||||
|
||||
```bash
|
||||
# 步骤1: 下载metagpt官方镜像并准备好config.yaml
|
||||
# 步骤1: 下载metagpt官方镜像并准备好config2.yaml
|
||||
docker pull metagpt/metagpt:latest
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # 修改配置文件
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
|
||||
vim /opt/metagpt/config/config2.yaml # 修改配置文件
|
||||
|
||||
# 步骤2: 使用容器运行metagpt演示
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
metagpt "Write a cli snake game"
|
||||
```
|
||||
|
||||
详细的安装请安装 [docker_install](https://docs.deepwisdom.ai/main/zh/guide/get_started/installation.html#%E4%BD%BF%E7%94%A8docker%E5%AE%89%E8%A3%85)
|
||||
详细的安装请参考 [docker_install](https://docs.deepwisdom.ai/main/zh/guide/get_started/installation.html#%E4%BD%BF%E7%94%A8docker%E5%AE%89%E8%A3%85)
|
||||
|
||||
### 快速开始的演示视频
|
||||
- 在 [MetaGPT Huggingface Space](https://huggingface.co/spaces/deepwisdom/MetaGPT) 上进行体验
|
||||
|
|
|
|||
|
|
@ -57,24 +57,21 @@ ### インストールビデオガイド
|
|||
- [Matthew Berman: How To Install MetaGPT - Build A Startup With One Prompt!!](https://youtu.be/uT75J_KG_aY)
|
||||
|
||||
### 伝統的なインストール
|
||||
> Python 3.9 以上がシステムにインストールされていることを確認してください。これは `python --version` を使ってチェックできます。
|
||||
> 以下のようにcondaを使うことができます:`conda create -n metagpt python=3.9 && conda activate metagpt`
|
||||
|
||||
```bash
|
||||
# ステップ 1: Python 3.9+ がシステムにインストールされていることを確認してください。これを確認するには:
|
||||
python3 --version
|
||||
pip install metagpt
|
||||
metagpt --init-config # ~/.metagpt/config2.yaml を作成し、自分の設定に合わせて変更してください
|
||||
metagpt "2048ゲームを作成する" # これにより ./workspace にリポジトリが作成されます
|
||||
```
|
||||
|
||||
# ステップ 2: リポジトリをローカルマシンにクローンし、インストールする。
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip install -e.
|
||||
または、ライブラリとして使用することもできます
|
||||
|
||||
# ステップ 3: metagpt を実行する
|
||||
# config.yaml を key.yaml にコピーし、独自の OPENAI_API_KEY を設定します
|
||||
metagpt "Write a cli snake game"
|
||||
|
||||
# ステップ 4 [オプション]: 実行中に PRD ファイルなどのアーティファクトを保存する場合は、ステップ 3 の前にこのステップを実行できます。デフォルトでは、フレームワークには互換性があり、この手順を実行しなくてもプロセス全体を完了できます。
|
||||
# NPM がシステムにインストールされていることを確認してください。次に mermaid-js をインストールします。(お使いのコンピューターに npm がない場合は、Node.js 公式サイトで Node.js https://nodejs.org/ をインストールしてください。)
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
```python
|
||||
from metagpt.software_company import generate_repo, ProjectRepo
|
||||
repo: ProjectRepo = generate_repo("2048ゲームを作成する") # または ProjectRepo("<パス>")
|
||||
print(repo) # リポジトリの構造とファイルを出力します
|
||||
```
|
||||
|
||||
**注:**
|
||||
|
|
@ -91,8 +88,8 @@ # NPM がシステムにインストールされていることを確認して
|
|||
- config.yml に mmdc のコンフィグを記述するのを忘れないこと
|
||||
|
||||
```yml
|
||||
PUPPETEER_CONFIG: "./config/puppeteer-config.json"
|
||||
MMDC: "./node_modules/.bin/mmdc"
|
||||
puppeteer_config: "./config/puppeteer-config.json"
|
||||
path: "./node_modules/.bin/mmdc"
|
||||
```
|
||||
|
||||
- もし `pip install -e.` がエラー `[Errno 13] Permission denied: '/usr/local/lib/python3.11/dist-packages/test-easy-install-13129.write-test'` で失敗したら、代わりに `pip install -e. --user` を実行してみてください
|
||||
|
|
@ -114,12 +111,13 @@ # NPM がシステムにインストールされていることを確認して
|
|||
playwright install --with-deps chromium
|
||||
```
|
||||
|
||||
- **modify `config.yaml`**
|
||||
- **modify `config2.yaml`**
|
||||
|
||||
config.yaml から MERMAID_ENGINE のコメントを外し、`playwright` に変更する
|
||||
config2.yaml から mermaid.engine のコメントを外し、`playwright` に変更する
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: playwright
|
||||
mermaid:
|
||||
engine: playwright
|
||||
```
|
||||
|
||||
- pyppeteer
|
||||
|
|
@ -143,21 +141,23 @@ # NPM がシステムにインストールされていることを確認して
|
|||
pyppeteer-install
|
||||
```
|
||||
|
||||
- **`config.yaml` を修正**
|
||||
- **`config2.yaml` を修正**
|
||||
|
||||
config.yaml から MERMAID_ENGINE のコメントを外し、`pyppeteer` に変更する
|
||||
config2.yaml から mermaid.engine のコメントを外し、`pyppeteer` に変更する
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: pyppeteer
|
||||
mermaid:
|
||||
engine: pyppeteer
|
||||
```
|
||||
|
||||
- mermaid.ink
|
||||
- **`config.yaml` を修正**
|
||||
- **`config2.yaml` を修正**
|
||||
|
||||
config.yaml から MERMAID_ENGINE のコメントを外し、`ink` に変更する
|
||||
config2.yaml から mermaid.engine のコメントを外し、`ink` に変更する
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: ink
|
||||
mermaid:
|
||||
engine: ink
|
||||
```
|
||||
|
||||
注: この方法は pdf エクスポートに対応していません。
|
||||
|
|
@ -166,16 +166,16 @@ ### Docker によるインストール
|
|||
> Windowsでは、"/opt/metagpt"をDockerが作成する権限を持つディレクトリに置き換える必要があります。例えば、"D:\Users\x\metagpt"などです。
|
||||
|
||||
```bash
|
||||
# ステップ 1: metagpt 公式イメージをダウンロードし、config.yaml を準備する
|
||||
# ステップ 1: metagpt 公式イメージをダウンロードし、config2.yaml を準備する
|
||||
docker pull metagpt/metagpt:latest
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # 設定を変更する
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
|
||||
vim /opt/metagpt/config/config2.yaml # 設定を変更する
|
||||
|
||||
# ステップ 2: コンテナで metagpt デモを実行する
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
metagpt "Write a cli snake game"
|
||||
|
|
@ -183,7 +183,7 @@ # ステップ 2: コンテナで metagpt デモを実行する
|
|||
# コンテナを起動し、その中でコマンドを実行することもできます
|
||||
docker run --name metagpt -d \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest
|
||||
|
||||
|
|
@ -194,7 +194,7 @@ # コンテナを起動し、その中でコマンドを実行することもで
|
|||
コマンド `docker run ...` は以下のことを行います:
|
||||
|
||||
- 特権モードで実行し、ブラウザの実行権限を得る
|
||||
- ホスト設定ファイル `/opt/metagpt/config/key.yaml` をコンテナ `/app/metagpt/config/key.yaml` にマップします
|
||||
- ホスト設定ファイル `/opt/metagpt/config/config2.yaml` をコンテナ `/app/metagpt/config/config2.yaml` にマップします
|
||||
- ホストディレクトリ `/opt/metagpt/workspace` をコンテナディレクトリ `/app/metagpt/workspace` にマップするs
|
||||
- デモコマンド `metagpt "Write a cli snake game"` を実行する
|
||||
|
||||
|
|
@ -208,19 +208,14 @@ # また、自分で metagpt イメージを構築することもできます。
|
|||
|
||||
## 設定
|
||||
|
||||
- `OPENAI_API_KEY` を `config/key.yaml / config/config.yaml / env` のいずれかで設定します。
|
||||
- 優先順位は: `config/key.yaml > config/config.yaml > env` の順です。
|
||||
- `api_key` を `~/.metagpt/config2.yaml / config/config2.yaml` のいずれかで設定します。
|
||||
- 優先順位は: `~/.metagpt/config2.yaml > config/config2.yaml > env` の順です。
|
||||
|
||||
```bash
|
||||
# 設定ファイルをコピーし、必要な修正を加える。
|
||||
cp config/config.yaml config/key.yaml
|
||||
cp config/config2.yaml ~/.metagpt/config2.yaml
|
||||
```
|
||||
|
||||
| 変数名 | config/key.yaml | env |
|
||||
| --------------------------------------- | ----------------------------------------- | ----------------------------------------------- |
|
||||
| OPENAI_API_KEY # 自分のキーに置き換える | OPENAI_API_KEY: "sk-..." | export OPENAI_API_KEY="sk-..." |
|
||||
| OPENAI_BASE_URL # オプション | OPENAI_BASE_URL: "https://<YOUR_SITE>/v1" | export OPENAI_BASE_URL="https://<YOUR_SITE>/v1" |
|
||||
|
||||
## チュートリアル: スタートアップの開始
|
||||
|
||||
```shell
|
||||
|
|
|
|||
|
|
@ -9,17 +9,29 @@ ### Support System and version
|
|||
|
||||
### Detail Installation
|
||||
```bash
|
||||
# Step 1: Ensure that NPM is installed on your system. Then install mermaid-js. (If you don't have npm in your computer, please go to the Node.js official website to install Node.js https://nodejs.org/ and then you will have npm tool in your computer.)
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
|
||||
# Step 2: Ensure that Python 3.9+ is installed on your system. You can check this by using:
|
||||
# Step 1: Ensure that Python 3.9+ is installed on your system. You can check this by using:
|
||||
# You can use conda to initialize a new python env
|
||||
# conda create -n metagpt python=3.9
|
||||
# conda activate metagpt
|
||||
python3 --version
|
||||
|
||||
# Step 3: Clone the repository to your local machine, and install it.
|
||||
# Step 2: Clone the repository to your local machine for latest version, and install it.
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip install -e.
|
||||
pip3 install -e . # or pip3 install metagpt # for stable version
|
||||
|
||||
# Step 3: setup your LLM key in the config2.yaml file
|
||||
mkdir ~/.metagpt
|
||||
cp config/config2.yaml ~/.metagpt/config2.yaml
|
||||
vim ~/.metagpt/config2.yaml
|
||||
|
||||
# Step 4: run metagpt cli
|
||||
metagpt "Create a 2048 game in python"
|
||||
|
||||
# Step 5 [Optional]: If you want to save the artifacts like diagrams such as quadrant chart, system designs, sequence flow in the workspace, you can execute the step before Step 3. By default, the framework is compatible, and the entire process can be run completely without executing this step.
|
||||
# If executing, ensure that NPM is installed on your system. Then install mermaid-js. (If you don't have npm in your computer, please go to the Node.js official website to install Node.js https://nodejs.org/ and then you will have npm tool in your computer.)
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
```
|
||||
|
||||
**Note:**
|
||||
|
|
@ -33,11 +45,12 @@ # Step 3: Clone the repository to your local machine, and install it.
|
|||
npm install @mermaid-js/mermaid-cli
|
||||
```
|
||||
|
||||
- don't forget to the configuration for mmdc in config.yml
|
||||
- don't forget to the configuration for mmdc path in config.yml
|
||||
|
||||
```yml
|
||||
PUPPETEER_CONFIG: "./config/puppeteer-config.json"
|
||||
MMDC: "./node_modules/.bin/mmdc"
|
||||
```yaml
|
||||
mermaid:
|
||||
puppeteer_config: "./config/puppeteer-config.json"
|
||||
path: "./node_modules/.bin/mmdc"
|
||||
```
|
||||
|
||||
- if `pip install -e.` fails with error `[Errno 13] Permission denied: '/usr/local/lib/python3.11/dist-packages/test-easy-install-13129.write-test'`, try instead running `pip install -e. --user`
|
||||
|
|
@ -59,12 +72,13 @@ # Step 3: Clone the repository to your local machine, and install it.
|
|||
playwright install --with-deps chromium
|
||||
```
|
||||
|
||||
- **modify `config.yaml`**
|
||||
- **modify `config2.yaml`**
|
||||
|
||||
uncomment MERMAID_ENGINE from config.yaml and change it to `playwright`
|
||||
change mermaid.engine to `playwright`
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: playwright
|
||||
mermaid:
|
||||
engine: playwright
|
||||
```
|
||||
|
||||
- pyppeteer
|
||||
|
|
@ -88,22 +102,24 @@ # Step 3: Clone the repository to your local machine, and install it.
|
|||
pyppeteer-install
|
||||
```
|
||||
|
||||
- **modify `config.yaml`**
|
||||
- **modify `config2.yaml`**
|
||||
|
||||
uncomment MERMAID_ENGINE from config.yaml and change it to `pyppeteer`
|
||||
change mermaid.engine to `pyppeteer`
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: pyppeteer
|
||||
mermaid:
|
||||
engine: pyppeteer
|
||||
```
|
||||
|
||||
- mermaid.ink
|
||||
- **modify `config.yaml`**
|
||||
|
||||
uncomment MERMAID_ENGINE from config.yaml and change it to `ink`
|
||||
- **modify `config2.yaml`**
|
||||
|
||||
change mermaid.engine to `ink`
|
||||
|
||||
```yaml
|
||||
MERMAID_ENGINE: ink
|
||||
mermaid:
|
||||
engine: ink
|
||||
```
|
||||
|
||||
Note: this method does not support pdf export.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -10,17 +10,29 @@ ### 支持的系统和版本
|
|||
### 详细安装
|
||||
|
||||
```bash
|
||||
# 第 1 步:确保您的系统上安装了 NPM。并使用npm安装mermaid-js
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
|
||||
# 第 2 步:确保您的系统上安装了 Python 3.9+。您可以使用以下命令进行检查:
|
||||
# 步骤 1: 确保您的系统安装了 Python 3.9 或更高版本。您可以使用以下命令来检查:
|
||||
# 您可以使用 conda 来初始化一个新的 Python 环境
|
||||
# conda create -n metagpt python=3.9
|
||||
# conda activate metagpt
|
||||
python3 --version
|
||||
|
||||
# 第 3 步:克隆仓库到您的本地机器,并进行安装。
|
||||
# 步骤 2: 克隆仓库到您的本地机器以获取最新版本,并安装它。
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT
|
||||
pip install -e.
|
||||
pip3 install -e . # 或 pip3 install metagpt # 用于稳定版本
|
||||
|
||||
# 步骤 3: 在 config2.yaml 文件中设置您的 LLM 密钥
|
||||
mkdir ~/.metagpt
|
||||
cp config/config2.yaml ~/.metagpt/config2.yaml
|
||||
vim ~/.metagpt/config2.yaml
|
||||
|
||||
# 步骤 4: 运行 metagpt 命令行界面
|
||||
metagpt "用 python 创建一个 2048 游戏"
|
||||
|
||||
# 步骤 5 [可选]: 如果您想保存诸如象限图、系统设计、序列流等图表作为工作空间的工件,您可以在执行步骤 3 之前执行此步骤。默认情况下,该框架是兼容的,整个过程可以完全不执行此步骤而运行。
|
||||
# 如果执行此步骤,请确保您的系统上安装了 NPM。然后安装 mermaid-js。(如果您的计算机中没有 npm,请访问 Node.js 官方网站 https://nodejs.org/ 安装 Node.js,然后您将在计算机中拥有 npm 工具。)
|
||||
npm --version
|
||||
sudo npm install -g @mermaid-js/mermaid-cli
|
||||
```
|
||||
|
||||
**注意:**
|
||||
|
|
@ -33,11 +45,12 @@ # 第 3 步:克隆仓库到您的本地机器,并进行安装。
|
|||
npm install @mermaid-js/mermaid-cli
|
||||
```
|
||||
|
||||
- 不要忘记在config.yml中为mmdc配置配置,
|
||||
- 不要忘记在config.yml中为mmdc配置
|
||||
|
||||
```yml
|
||||
PUPPETEER_CONFIG: "./config/puppeteer-config.json"
|
||||
MMDC: "./node_modules/.bin/mmdc"
|
||||
mermaid:
|
||||
puppeteer_config: "./config/puppeteer-config.json"
|
||||
path: "./node_modules/.bin/mmdc"
|
||||
```
|
||||
|
||||
- 如果`pip install -e.`失败并显示错误`[Errno 13] Permission denied: '/usr/local/lib/python3.11/dist-packages/test-easy-install-13129.write-test'`,请尝试使用`pip install -e. --user`运行。
|
||||
|
|
|
|||
|
|
@ -3,16 +3,16 @@ ## Docker Installation
|
|||
### Use default MetaGPT image
|
||||
|
||||
```bash
|
||||
# Step 1: Download metagpt official image and prepare config.yaml
|
||||
# Step 1: Download metagpt official image and prepare config2.yaml
|
||||
docker pull metagpt/metagpt:latest
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # Change the config
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
|
||||
vim /opt/metagpt/config/config2.yaml # Change the config
|
||||
|
||||
# Step 2: Run metagpt demo with container
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
metagpt "Write a cli snake game"
|
||||
|
|
@ -20,7 +20,7 @@ # Step 2: Run metagpt demo with container
|
|||
# You can also start a container and execute commands in it
|
||||
docker run --name metagpt -d \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest
|
||||
|
||||
|
|
@ -31,7 +31,7 @@ # You can also start a container and execute commands in it
|
|||
The command `docker run ...` do the following things:
|
||||
|
||||
- Run in privileged mode to have permission to run the browser
|
||||
- Map host configure file `/opt/metagpt/config/key.yaml` to container `/app/metagpt/config/key.yaml`
|
||||
- Map host configure file `/opt/metagpt/config/config2.yaml` to container `/app/metagpt/config/config2.yaml`
|
||||
- Map host directory `/opt/metagpt/workspace` to container `/app/metagpt/workspace`
|
||||
- Execute the demo command `metagpt "Write a cli snake game"`
|
||||
|
||||
|
|
|
|||
|
|
@ -3,16 +3,16 @@ ## Docker安装
|
|||
### 使用MetaGPT镜像
|
||||
|
||||
```bash
|
||||
# 步骤1: 下载metagpt官方镜像并准备好config.yaml
|
||||
# 步骤1: 下载metagpt官方镜像并准备好config2.yaml
|
||||
docker pull metagpt/metagpt:latest
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # 修改配置文件
|
||||
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
|
||||
vim /opt/metagpt/config/config2.yaml # 修改配置文件
|
||||
|
||||
# 步骤2: 使用容器运行metagpt演示
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest \
|
||||
metagpt "Write a cli snake game"
|
||||
|
|
@ -20,7 +20,7 @@ # 步骤2: 使用容器运行metagpt演示
|
|||
# 您也可以启动一个容器并在其中执行命令
|
||||
docker run --name metagpt -d \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:latest
|
||||
|
||||
|
|
@ -31,7 +31,7 @@ # 您也可以启动一个容器并在其中执行命令
|
|||
`docker run ...`做了以下事情:
|
||||
|
||||
- 以特权模式运行,有权限运行浏览器
|
||||
- 将主机文件 `/opt/metagpt/config/key.yaml` 映射到容器文件 `/app/metagpt/config/key.yaml`
|
||||
- 将主机文件 `/opt/metagpt/config/config2.yaml` 映射到容器文件 `/app/metagpt/config/config2.yaml`
|
||||
- 将主机目录 `/opt/metagpt/workspace` 映射到容器目录 `/app/metagpt/workspace`
|
||||
- 执行示例命令 `metagpt "Write a cli snake game"`
|
||||
|
||||
|
|
|
|||
|
|
@ -2,19 +2,14 @@ ## MetaGPT Usage
|
|||
|
||||
### Configuration
|
||||
|
||||
- Configure your `OPENAI_API_KEY` in any of `config/key.yaml / config/config.yaml / env`
|
||||
- Priority order: `config/key.yaml > config/config.yaml > env`
|
||||
- Configure your `api_key` in any of `~/.metagpt/config2.yaml / config/config2.yaml`
|
||||
- Priority order: `~/.metagpt/config2.yaml > config/config2.yaml`
|
||||
|
||||
```bash
|
||||
# Copy the configuration file and make the necessary modifications.
|
||||
cp config/config.yaml config/key.yaml
|
||||
cp config/config2.yaml ~/.metagpt/config2.yaml
|
||||
```
|
||||
|
||||
| Variable Name | config/key.yaml | env |
|
||||
| ------------------------------------------ | ----------------------------------------- | ----------------------------------------------- |
|
||||
| OPENAI_API_KEY # Replace with your own key | OPENAI_API_KEY: "sk-..." | export OPENAI_API_KEY="sk-..." |
|
||||
| OPENAI_BASE_URL # Optional | OPENAI_BASE_URL: "https://<YOUR_SITE>/v1" | export OPENAI_BASE_URL="https://<YOUR_SITE>/v1" |
|
||||
|
||||
### Initiating a startup
|
||||
|
||||
```shell
|
||||
|
|
@ -39,29 +34,28 @@ ### Preference of Platform or Tool
|
|||
### Usage
|
||||
|
||||
```
|
||||
NAME
|
||||
metagpt - We are a software startup comprised of AI. By investing in us, you are empowering a future filled with limitless possibilities.
|
||||
|
||||
SYNOPSIS
|
||||
metagpt IDEA <flags>
|
||||
|
||||
DESCRIPTION
|
||||
We are a software startup comprised of AI. By investing in us, you are empowering a future filled with limitless possibilities.
|
||||
|
||||
POSITIONAL ARGUMENTS
|
||||
IDEA
|
||||
Type: str
|
||||
Your innovative idea, such as "Creating a snake game."
|
||||
|
||||
FLAGS
|
||||
--investment=INVESTMENT
|
||||
Type: float
|
||||
Default: 3.0
|
||||
As an investor, you have the opportunity to contribute a certain dollar amount to this AI company.
|
||||
--n_round=N_ROUND
|
||||
Type: int
|
||||
Default: 5
|
||||
|
||||
NOTES
|
||||
You can also use flags syntax for POSITIONAL ARGUMENTS
|
||||
Usage: metagpt [OPTIONS] [IDEA]
|
||||
|
||||
Start a new project.
|
||||
|
||||
╭─ Arguments ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
|
||||
│ idea [IDEA] Your innovative idea, such as 'Create a 2048 game.' [default: None] │
|
||||
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
|
||||
╭─ Options ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
|
||||
│ --investment FLOAT Dollar amount to invest in the AI company. [default: 3.0] │
|
||||
│ --n-round INTEGER Number of rounds for the simulation. [default: 5] │
|
||||
│ --code-review --no-code-review Whether to use code review. [default: code-review] │
|
||||
│ --run-tests --no-run-tests Whether to enable QA for adding & running tests. [default: no-run-tests] │
|
||||
│ --implement --no-implement Enable or disable code implementation. [default: implement] │
|
||||
│ --project-name TEXT Unique project name, such as 'game_2048'. │
|
||||
│ --inc --no-inc Incremental mode. Use it to coop with existing repo. [default: no-inc] │
|
||||
│ --project-path TEXT Specify the directory path of the old version project to fulfill the incremental requirements. │
|
||||
│ --reqa-file TEXT Specify the source file name for rewriting the quality assurance code. │
|
||||
│ --max-auto-summarize-code INTEGER The maximum number of times the 'SummarizeCode' action is automatically invoked, with -1 indicating unlimited. This parameter is used for debugging the │
|
||||
│ workflow. │
|
||||
│ [default: 0] │
|
||||
│ --recover-path TEXT recover the project from existing serialized storage [default: None] │
|
||||
│ --init-config --no-init-config Initialize the configuration file for MetaGPT. [default: no-init-config] │
|
||||
│ --help Show this message and exit. │
|
||||
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
|
||||
```
|
||||
|
|
@ -2,19 +2,14 @@ ## MetaGPT 使用
|
|||
|
||||
### 配置
|
||||
|
||||
- 在 `config/key.yaml / config/config.yaml / env` 中配置您的 `OPENAI_API_KEY`
|
||||
- 优先级顺序:`config/key.yaml > config/config.yaml > env`
|
||||
- 在 `~/.metagpt/config2.yaml / config/config2.yaml` 中配置您的 `api_key`
|
||||
- 优先级顺序:`~/.metagpt/config2.yaml > config/config2.yaml`
|
||||
|
||||
```bash
|
||||
# 复制配置文件并进行必要的修改
|
||||
cp config/config.yaml config/key.yaml
|
||||
cp config/config2.yaml ~/.metagpt/config2.yaml
|
||||
```
|
||||
|
||||
| 变量名 | config/key.yaml | env |
|
||||
| ----------------------------------- | ----------------------------------------- | ----------------------------------------------- |
|
||||
| OPENAI_API_KEY # 用您自己的密钥替换 | OPENAI_API_KEY: "sk-..." | export OPENAI_API_KEY="sk-..." |
|
||||
| OPENAI_BASE_URL # 可选 | OPENAI_BASE_URL: "https://<YOUR_SITE>/v1" | export OPENAI_BASE_URL="https://<YOUR_SITE>/v1" |
|
||||
|
||||
### 示例:启动一个创业公司
|
||||
|
||||
```shell
|
||||
|
|
@ -35,29 +30,28 @@ ### 平台或工具的倾向性
|
|||
### 使用
|
||||
|
||||
```
|
||||
名称
|
||||
metagpt - 我们是一家AI软件创业公司。通过投资我们,您将赋能一个充满无限可能的未来。
|
||||
|
||||
概要
|
||||
metagpt IDEA <flags>
|
||||
|
||||
描述
|
||||
我们是一家AI软件创业公司。通过投资我们,您将赋能一个充满无限可能的未来。
|
||||
|
||||
位置参数
|
||||
IDEA
|
||||
类型: str
|
||||
您的创新想法,例如"写一个命令行贪吃蛇。"
|
||||
|
||||
标志
|
||||
--investment=INVESTMENT
|
||||
类型: float
|
||||
默认值: 3.0
|
||||
作为投资者,您有机会向这家AI公司投入一定的美元金额。
|
||||
--n_round=N_ROUND
|
||||
类型: int
|
||||
默认值: 5
|
||||
|
||||
备注
|
||||
您也可以用`标志`的语法,来处理`位置参数`
|
||||
Usage: metagpt [OPTIONS] [IDEA]
|
||||
|
||||
Start a new project.
|
||||
|
||||
╭─ Arguments ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
|
||||
│ idea [IDEA] Your innovative idea, such as 'Create a 2048 game.' [default: None] │
|
||||
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
|
||||
╭─ Options ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
|
||||
│ --investment FLOAT Dollar amount to invest in the AI company. [default: 3.0] │
|
||||
│ --n-round INTEGER Number of rounds for the simulation. [default: 5] │
|
||||
│ --code-review --no-code-review Whether to use code review. [default: code-review] │
|
||||
│ --run-tests --no-run-tests Whether to enable QA for adding & running tests. [default: no-run-tests] │
|
||||
│ --implement --no-implement Enable or disable code implementation. [default: implement] │
|
||||
│ --project-name TEXT Unique project name, such as 'game_2048'. │
|
||||
│ --inc --no-inc Incremental mode. Use it to coop with existing repo. [default: no-inc] │
|
||||
│ --project-path TEXT Specify the directory path of the old version project to fulfill the incremental requirements. │
|
||||
│ --reqa-file TEXT Specify the source file name for rewriting the quality assurance code. │
|
||||
│ --max-auto-summarize-code INTEGER The maximum number of times the 'SummarizeCode' action is automatically invoked, with -1 indicating unlimited. This parameter is used for debugging the │
|
||||
│ workflow. │
|
||||
│ [default: 0] │
|
||||
│ --recover-path TEXT recover the project from existing serialized storage [default: None] │
|
||||
│ --init-config --no-init-config Initialize the configuration file for MetaGPT. [default: no-init-config] │
|
||||
│ --help Show this message and exit. │
|
||||
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
|
||||
```
|
||||
|
|
|
|||
49
examples/write_novel.py
Normal file
49
examples/write_novel.py
Normal file
|
|
@ -0,0 +1,49 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/2/1 12:01
|
||||
@Author : alexanderwu
|
||||
@File : write_novel.py
|
||||
"""
|
||||
import asyncio
|
||||
from typing import List
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from metagpt.actions.action_node import ActionNode
|
||||
from metagpt.llm import LLM
|
||||
|
||||
|
||||
class Novel(BaseModel):
|
||||
name: str = Field(default="The Lord of the Rings", description="The name of the novel.")
|
||||
user_group: str = Field(default="...", description="The user group of the novel.")
|
||||
outlines: List[str] = Field(
|
||||
default=["Chapter 1: ...", "Chapter 2: ...", "Chapter 3: ..."],
|
||||
description="The outlines of the novel. No more than 10 chapters.",
|
||||
)
|
||||
background: str = Field(default="...", description="The background of the novel.")
|
||||
character_names: List[str] = Field(default=["Frodo", "Gandalf", "Sauron"], description="The characters.")
|
||||
conflict: str = Field(default="...", description="The conflict of the characters.")
|
||||
plot: str = Field(default="...", description="The plot of the novel.")
|
||||
ending: str = Field(default="...", description="The ending of the novel.")
|
||||
|
||||
|
||||
class Chapter(BaseModel):
|
||||
name: str = Field(default="Chapter 1", description="The name of the chapter.")
|
||||
content: str = Field(default="...", description="The content of the chapter. No more than 1000 words.")
|
||||
|
||||
|
||||
async def generate_novel():
|
||||
instruction = (
|
||||
"Write a novel named 'Harry Potter in The Lord of the Rings'. "
|
||||
"Fill the empty nodes with your own ideas. Be creative! Use your own words!"
|
||||
"I will tip you $100,000 if you write a good novel."
|
||||
)
|
||||
novel_node = await ActionNode.from_pydantic(Novel).fill(context=instruction, llm=LLM())
|
||||
chap_node = await ActionNode.from_pydantic(Chapter).fill(
|
||||
context=f"### instruction\n{instruction}\n### novel\n{novel_node.content}", llm=LLM()
|
||||
)
|
||||
print(chap_node.content)
|
||||
|
||||
|
||||
asyncio.run(generate_novel())
|
||||
49
metagpt/actions/action_graph.py
Normal file
49
metagpt/actions/action_graph.py
Normal file
|
|
@ -0,0 +1,49 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/30 13:52
|
||||
@Author : alexanderwu
|
||||
@File : action_graph.py
|
||||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
# from metagpt.actions.action_node import ActionNode
|
||||
|
||||
|
||||
class ActionGraph:
|
||||
"""ActionGraph: a directed graph to represent the dependency between actions."""
|
||||
|
||||
def __init__(self):
|
||||
self.nodes = {}
|
||||
self.edges = {}
|
||||
self.execution_order = []
|
||||
|
||||
def add_node(self, node):
|
||||
"""Add a node to the graph"""
|
||||
self.nodes[node.key] = node
|
||||
|
||||
def add_edge(self, from_node: "ActionNode", to_node: "ActionNode"):
|
||||
"""Add an edge to the graph"""
|
||||
if from_node.key not in self.edges:
|
||||
self.edges[from_node.key] = []
|
||||
self.edges[from_node.key].append(to_node.key)
|
||||
from_node.add_next(to_node)
|
||||
to_node.add_prev(from_node)
|
||||
|
||||
def topological_sort(self):
|
||||
"""Topological sort the graph"""
|
||||
visited = set()
|
||||
stack = []
|
||||
|
||||
def visit(k):
|
||||
if k not in visited:
|
||||
visited.add(k)
|
||||
if k in self.edges:
|
||||
for next_node in self.edges[k]:
|
||||
visit(next_node)
|
||||
stack.insert(0, k)
|
||||
|
||||
for key in self.nodes:
|
||||
visit(key)
|
||||
|
||||
self.execution_order = stack
|
||||
|
|
@ -9,6 +9,7 @@ NOTE: You should use typing.List instead of list to do type annotation. Because
|
|||
we can use typing to extract the type of the node, but we cannot use built-in list to extract.
|
||||
"""
|
||||
import json
|
||||
import typing
|
||||
from enum import Enum
|
||||
from typing import Any, Dict, List, Optional, Tuple, Type, Union
|
||||
|
||||
|
|
@ -39,7 +40,6 @@ TAG = "CONTENT"
|
|||
LANGUAGE_CONSTRAINT = "Language: Please use the same language as Human INPUT."
|
||||
FORMAT_CONSTRAINT = f"Format: output wrapped inside [{TAG}][/{TAG}] like format example, nothing else."
|
||||
|
||||
|
||||
SIMPLE_TEMPLATE = """
|
||||
## context
|
||||
{context}
|
||||
|
|
@ -131,6 +131,8 @@ class ActionNode:
|
|||
|
||||
# Action Input
|
||||
key: str # Product Requirement / File list / Code
|
||||
func: typing.Callable # 与节点相关联的函数或LLM调用
|
||||
params: Dict[str, Type] # 输入参数的字典,键为参数名,值为参数类型
|
||||
expected_type: Type # such as str / int / float etc.
|
||||
# context: str # everything in the history.
|
||||
instruction: str # the instructions should be followed.
|
||||
|
|
@ -140,6 +142,10 @@ class ActionNode:
|
|||
content: str
|
||||
instruct_content: BaseModel
|
||||
|
||||
# For ActionGraph
|
||||
prevs: List["ActionNode"] # previous nodes
|
||||
nexts: List["ActionNode"] # next nodes
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
key: str,
|
||||
|
|
@ -157,6 +163,8 @@ class ActionNode:
|
|||
self.content = content
|
||||
self.children = children if children is not None else {}
|
||||
self.schema = schema
|
||||
self.prevs = []
|
||||
self.nexts = []
|
||||
|
||||
def __str__(self):
|
||||
return (
|
||||
|
|
@ -167,6 +175,14 @@ class ActionNode:
|
|||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
def add_prev(self, node: "ActionNode"):
|
||||
"""增加前置ActionNode"""
|
||||
self.prevs.append(node)
|
||||
|
||||
def add_next(self, node: "ActionNode"):
|
||||
"""增加后置ActionNode"""
|
||||
self.nexts.append(node)
|
||||
|
||||
def add_child(self, node: "ActionNode"):
|
||||
"""增加子ActionNode"""
|
||||
self.children[node.key] = node
|
||||
|
|
@ -186,41 +202,38 @@ class ActionNode:
|
|||
obj.add_children(nodes)
|
||||
return obj
|
||||
|
||||
def get_children_mapping_old(self, exclude=None) -> Dict[str, Tuple[Type, Any]]:
|
||||
"""获得子ActionNode的字典,以key索引"""
|
||||
def _get_children_mapping(self, exclude=None) -> Dict[str, Any]:
|
||||
"""获得子ActionNode的字典,以key索引,支持多级结构。"""
|
||||
exclude = exclude or []
|
||||
return {k: (v.expected_type, ...) for k, v in self.children.items() if k not in exclude}
|
||||
|
||||
def get_children_mapping(self, exclude=None) -> Dict[str, Tuple[Type, Any]]:
|
||||
"""获得子ActionNode的字典,以key索引,支持多级结构"""
|
||||
exclude = exclude or []
|
||||
mapping = {}
|
||||
|
||||
def _get_mapping(node: "ActionNode", prefix: str = ""):
|
||||
def _get_mapping(node: "ActionNode") -> Dict[str, Any]:
|
||||
mapping = {}
|
||||
for key, child in node.children.items():
|
||||
if key in exclude:
|
||||
continue
|
||||
full_key = f"{prefix}{key}"
|
||||
mapping[full_key] = (child.expected_type, ...)
|
||||
_get_mapping(child, prefix=f"{full_key}.")
|
||||
# 对于嵌套的子节点,递归调用 _get_mapping
|
||||
if child.children:
|
||||
mapping[key] = _get_mapping(child)
|
||||
else:
|
||||
mapping[key] = (child.expected_type, Field(default=child.example, description=child.instruction))
|
||||
return mapping
|
||||
|
||||
_get_mapping(self)
|
||||
return mapping
|
||||
return _get_mapping(self)
|
||||
|
||||
def get_self_mapping(self) -> Dict[str, Tuple[Type, Any]]:
|
||||
def _get_self_mapping(self) -> Dict[str, Tuple[Type, Any]]:
|
||||
"""get self key: type mapping"""
|
||||
return {self.key: (self.expected_type, ...)}
|
||||
|
||||
def get_mapping(self, mode="children", exclude=None) -> Dict[str, Tuple[Type, Any]]:
|
||||
"""get key: type mapping under mode"""
|
||||
if mode == "children" or (mode == "auto" and self.children):
|
||||
return self.get_children_mapping(exclude=exclude)
|
||||
return {} if exclude and self.key in exclude else self.get_self_mapping()
|
||||
return self._get_children_mapping(exclude=exclude)
|
||||
return {} if exclude and self.key in exclude else self._get_self_mapping()
|
||||
|
||||
@classmethod
|
||||
@register_action_outcls
|
||||
def create_model_class(cls, class_name: str, mapping: Dict[str, Tuple[Type, Any]]):
|
||||
"""基于pydantic v1的模型动态生成,用来检验结果类型正确性"""
|
||||
"""基于pydantic v2的模型动态生成,用来检验结果类型正确性"""
|
||||
|
||||
def check_fields(cls, values):
|
||||
required_fields = set(mapping.keys())
|
||||
|
|
@ -235,7 +248,17 @@ class ActionNode:
|
|||
|
||||
validators = {"check_missing_fields_validator": model_validator(mode="before")(check_fields)}
|
||||
|
||||
new_class = create_model(class_name, __validators__=validators, **mapping)
|
||||
new_fields = {}
|
||||
for field_name, field_value in mapping.items():
|
||||
if isinstance(field_value, dict):
|
||||
# 对于嵌套结构,递归创建模型类
|
||||
nested_class_name = f"{class_name}_{field_name}"
|
||||
nested_class = cls.create_model_class(nested_class_name, field_value)
|
||||
new_fields[field_name] = (nested_class, ...)
|
||||
else:
|
||||
new_fields[field_name] = field_value
|
||||
|
||||
new_class = create_model(class_name, __validators__=validators, **new_fields)
|
||||
return new_class
|
||||
|
||||
def create_class(self, mode: str = "auto", class_name: str = None, exclude=None):
|
||||
|
|
@ -243,39 +266,48 @@ class ActionNode:
|
|||
mapping = self.get_mapping(mode=mode, exclude=exclude)
|
||||
return self.create_model_class(class_name, mapping)
|
||||
|
||||
def create_children_class(self, exclude=None):
|
||||
def _create_children_class(self, exclude=None):
|
||||
"""使用object内有的字段直接生成model_class"""
|
||||
class_name = f"{self.key}_AN"
|
||||
mapping = self.get_children_mapping(exclude=exclude)
|
||||
mapping = self._get_children_mapping(exclude=exclude)
|
||||
return self.create_model_class(class_name, mapping)
|
||||
|
||||
def to_dict(self, format_func=None, mode="auto", exclude=None) -> Dict:
|
||||
"""将当前节点与子节点都按照node: format的格式组织成字典"""
|
||||
nodes = self._to_dict(format_func=format_func, mode=mode, exclude=exclude)
|
||||
if not isinstance(nodes, dict):
|
||||
nodes = {self.key: nodes}
|
||||
return nodes
|
||||
|
||||
# 如果没有提供格式化函数,使用默认的格式化方式
|
||||
def _to_dict(self, format_func=None, mode="auto", exclude=None) -> Dict:
|
||||
"""将当前节点与子节点都按照node: format的格式组织成字典"""
|
||||
|
||||
# 如果没有提供格式化函数,则使用默认的格式化函数
|
||||
if format_func is None:
|
||||
format_func = lambda node: f"{node.instruction}"
|
||||
format_func = lambda node: node.instruction
|
||||
|
||||
# 使用提供的格式化函数来格式化当前节点的值
|
||||
formatted_value = format_func(self)
|
||||
|
||||
# 创建当前节点的键值对
|
||||
if mode == "children" or (mode == "auto" and self.children):
|
||||
node_dict = {}
|
||||
if (mode == "children" or mode == "auto") and self.children:
|
||||
node_value = {}
|
||||
else:
|
||||
node_dict = {self.key: formatted_value}
|
||||
node_value = formatted_value
|
||||
|
||||
if mode == "root":
|
||||
return node_dict
|
||||
return {self.key: node_value}
|
||||
|
||||
# 遍历子节点并递归调用 to_dict 方法
|
||||
# 递归处理子节点
|
||||
exclude = exclude or []
|
||||
for _, child_node in self.children.items():
|
||||
if child_node.key in exclude:
|
||||
for child_key, child_node in self.children.items():
|
||||
if child_key in exclude:
|
||||
continue
|
||||
node_dict.update(child_node.to_dict(format_func))
|
||||
# 递归调用 to_dict 方法并更新节点字典
|
||||
child_dict = child_node._to_dict(format_func, mode, exclude)
|
||||
node_value[child_key] = child_dict
|
||||
|
||||
return node_dict
|
||||
return node_value
|
||||
|
||||
def update_instruct_content(self, incre_data: dict[str, Any]):
|
||||
assert self.instruct_content
|
||||
|
|
@ -344,6 +376,17 @@ class ActionNode:
|
|||
if schema == "raw":
|
||||
return context + "\n\n## Actions\n" + LANGUAGE_CONSTRAINT + "\n" + self.instruction
|
||||
|
||||
### 直接使用 pydantic BaseModel 生成 instruction 与 example,仅限 JSON
|
||||
# child_class = self._create_children_class()
|
||||
# node_schema = child_class.model_json_schema()
|
||||
# defaults = {
|
||||
# k: str(v)
|
||||
# for k, v in child_class.model_fields.items()
|
||||
# if k not in exclude
|
||||
# }
|
||||
# instruction = node_schema
|
||||
# example = json.dumps(defaults, indent=4)
|
||||
|
||||
# FIXME: json instruction会带来格式问题,如:"Project name": "web_2048 # 项目名称使用下划线",
|
||||
# compile example暂时不支持markdown
|
||||
instruction = self.compile_instruction(schema="markdown", mode=mode, exclude=exclude)
|
||||
|
|
@ -454,7 +497,7 @@ class ActionNode:
|
|||
continue
|
||||
child = await i.simple_fill(schema=schema, mode=mode, timeout=timeout, exclude=exclude)
|
||||
tmp.update(child.instruct_content.model_dump())
|
||||
cls = self.create_children_class()
|
||||
cls = self._create_children_class()
|
||||
self.instruct_content = cls(**tmp)
|
||||
return self
|
||||
|
||||
|
|
@ -645,49 +688,19 @@ class ActionNode:
|
|||
ActionNode: The root node of the created ActionNode tree.
|
||||
"""
|
||||
key = key or model.__name__
|
||||
root_node = cls(key=model.__name__, expected_type=Type[model], instruction="", example="")
|
||||
root_node = cls(key=key, expected_type=Type[model], instruction="", example="")
|
||||
|
||||
for field_name, field_model in model.model_fields.items():
|
||||
# Extracting field details
|
||||
expected_type = field_model.annotation
|
||||
instruction = field_model.description or ""
|
||||
example = field_model.default
|
||||
for field_name, field_info in model.model_fields.items():
|
||||
field_type = field_info.annotation
|
||||
description = field_info.description
|
||||
default = field_info.default
|
||||
|
||||
# Check if the field is a Pydantic model itself.
|
||||
# Use isinstance to avoid typing.List, typing.Dict, etc. (they are instances of type, not subclasses)
|
||||
if isinstance(expected_type, type) and issubclass(expected_type, BaseModel):
|
||||
# Recursively process the nested model
|
||||
child_node = cls.from_pydantic(expected_type, key=field_name)
|
||||
# Recursively handle nested models if needed
|
||||
if not isinstance(field_type, typing._GenericAlias) and issubclass(field_type, BaseModel):
|
||||
child_node = cls.from_pydantic(field_type, key=field_name)
|
||||
else:
|
||||
child_node = cls(key=field_name, expected_type=expected_type, instruction=instruction, example=example)
|
||||
child_node = cls(key=field_name, expected_type=field_type, instruction=description, example=default)
|
||||
|
||||
root_node.add_child(child_node)
|
||||
|
||||
return root_node
|
||||
|
||||
|
||||
class ToolUse(BaseModel):
|
||||
tool_name: str = Field(default="a", description="tool name", examples=[])
|
||||
|
||||
|
||||
class Task(BaseModel):
|
||||
task_id: int = Field(default="1", description="task id", examples=[1, 2, 3])
|
||||
name: str = Field(default="Get data from ...", description="task name", examples=[])
|
||||
dependent_task_ids: List[int] = Field(default=[], description="dependent task ids", examples=[1, 2, 3])
|
||||
tool: ToolUse = Field(default=ToolUse(), description="tool use", examples=[])
|
||||
|
||||
|
||||
class Tasks(BaseModel):
|
||||
tasks: List[Task] = Field(default=[], description="tasks", examples=[])
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
node = ActionNode.from_pydantic(Tasks)
|
||||
print("Tasks")
|
||||
print(Tasks.model_json_schema())
|
||||
print("Task")
|
||||
print(Task.model_json_schema())
|
||||
print(node)
|
||||
prompt = node.compile(context="")
|
||||
node.create_children_class()
|
||||
print(prompt)
|
||||
|
|
|
|||
|
|
@ -117,4 +117,4 @@ class WriteDesign(Action):
|
|||
|
||||
async def _save_mermaid_file(self, data: str, pathname: Path):
|
||||
pathname.parent.mkdir(parents=True, exist_ok=True)
|
||||
await mermaid_to_file(self.config.mermaid_engine, data, pathname)
|
||||
await mermaid_to_file(self.config.mermaid.engine, data, pathname)
|
||||
|
|
|
|||
|
|
@ -42,8 +42,8 @@ Determine the ONE file to rewrite in order to fix the error, for example, xyz.py
|
|||
Determine if all of the code works fine, if so write PASS, else FAIL,
|
||||
WRITE ONLY ONE WORD, PASS OR FAIL, IN THIS SECTION
|
||||
## Send To:
|
||||
Please write Engineer if the errors are due to problematic development codes, and QaEngineer to problematic test codes, and NoOne if there are no errors,
|
||||
WRITE ONLY ONE WORD, Engineer OR QaEngineer OR NoOne, IN THIS SECTION.
|
||||
Please write NoOne if there are no errors, Engineer if the errors are due to problematic development codes, else QaEngineer,
|
||||
WRITE ONLY ONE WORD, NoOne OR Engineer OR QaEngineer, IN THIS SECTION.
|
||||
---
|
||||
You should fill in necessary instruction, status, send to, and finally return all content between the --- segment line.
|
||||
"""
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ Options:
|
|||
Default: 'google'
|
||||
|
||||
Example:
|
||||
python3 -m metagpt.actions.write_docstring ./metagpt/startup.py --overwrite False --style=numpy
|
||||
python3 -m metagpt.actions.write_docstring ./metagpt/software_company.py --overwrite False --style=numpy
|
||||
|
||||
This script uses the 'fire' library to create a command-line interface. It generates docstrings for the given Python code using
|
||||
the specified docstring style and adds them to the code.
|
||||
|
|
|
|||
|
|
@ -159,7 +159,7 @@ class WritePRD(Action):
|
|||
return
|
||||
pathname = self.repo.workdir / COMPETITIVE_ANALYSIS_FILE_REPO / Path(prd_doc.filename).stem
|
||||
pathname.parent.mkdir(parents=True, exist_ok=True)
|
||||
await mermaid_to_file(self.config.mermaid_engine, quadrant_chart, pathname)
|
||||
await mermaid_to_file(self.config.mermaid.engine, quadrant_chart, pathname)
|
||||
|
||||
async def _rename_workspace(self, prd):
|
||||
if not self.project_name:
|
||||
|
|
|
|||
|
|
@ -67,24 +67,18 @@ class Config(CLIParams, YamlModel):
|
|||
code_review_k_times: int = 2
|
||||
|
||||
# Will be removed in the future
|
||||
llm_for_researcher_summary: str = "gpt3"
|
||||
llm_for_researcher_report: str = "gpt3"
|
||||
METAGPT_TEXT_TO_IMAGE_MODEL_URL: str = ""
|
||||
metagpt_tti_url: str = ""
|
||||
language: str = "English"
|
||||
redis_key: str = "placeholder"
|
||||
mmdc: str = "mmdc"
|
||||
puppeteer_config: str = ""
|
||||
pyppeteer_executable_path: str = ""
|
||||
IFLYTEK_APP_ID: str = ""
|
||||
IFLYTEK_API_SECRET: str = ""
|
||||
IFLYTEK_API_KEY: str = ""
|
||||
AZURE_TTS_SUBSCRIPTION_KEY: str = ""
|
||||
AZURE_TTS_REGION: str = ""
|
||||
mermaid_engine: str = "nodejs"
|
||||
iflytek_app_id: str = ""
|
||||
iflytek_api_secret: str = ""
|
||||
iflytek_api_key: str = ""
|
||||
azure_tts_subscription_key: str = ""
|
||||
azure_tts_region: str = ""
|
||||
|
||||
@classmethod
|
||||
def from_home(cls, path):
|
||||
"""Load config from ~/.metagpt/config.yaml"""
|
||||
"""Load config from ~/.metagpt/config2.yaml"""
|
||||
pathname = CONFIG_ROOT / path
|
||||
if not pathname.exists():
|
||||
return None
|
||||
|
|
|
|||
|
|
@ -74,5 +74,5 @@ class LLMConfig(YamlModel):
|
|||
@classmethod
|
||||
def check_llm_key(cls, v):
|
||||
if v in ["", None, "YOUR_API_KEY"]:
|
||||
raise ValueError("Please set your API key in config.yaml")
|
||||
raise ValueError("Please set your API key in config2.yaml")
|
||||
return v
|
||||
|
|
|
|||
|
|
@ -14,5 +14,6 @@ class MermaidConfig(YamlModel):
|
|||
"""Config for Mermaid"""
|
||||
|
||||
engine: Literal["nodejs", "ink", "playwright", "pyppeteer"] = "nodejs"
|
||||
path: str = ""
|
||||
puppeteer_config: str = "" # Only for nodejs engine
|
||||
path: str = "mmdc" # mmdc
|
||||
puppeteer_config: str = ""
|
||||
pyppeteer_path: str = "/usr/bin/google-chrome-stable"
|
||||
|
|
|
|||
|
|
@ -8,5 +8,5 @@ async def google_search(query: str, max_results: int = 6, **kwargs):
|
|||
:param max_results: The number of search results to retrieve
|
||||
:return: The web search results in markdown format.
|
||||
"""
|
||||
results = await SearchEngine().run(query, max_results=max_results, as_string=False)
|
||||
results = await SearchEngine(**kwargs).run(query, max_results=max_results, as_string=False)
|
||||
return "\n".join(f"{i}. [{j['title']}]({j['link']}): {j['snippet']}" for i, j in enumerate(results, 1))
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ async def text_to_image(text, size_type: str = "512x512", config: Config = metag
|
|||
"""
|
||||
image_declaration = "data:image/png;base64,"
|
||||
|
||||
model_url = config.METAGPT_TEXT_TO_IMAGE_MODEL_URL
|
||||
model_url = config.metagpt_tti_url
|
||||
if model_url:
|
||||
binary_data = await oas3_metagpt_text_to_image(text, size_type, model_url)
|
||||
elif config.get_openai_llm():
|
||||
|
|
|
|||
|
|
@ -39,8 +39,8 @@ async def text_to_speech(
|
|||
|
||||
"""
|
||||
|
||||
subscription_key = config.AZURE_TTS_SUBSCRIPTION_KEY
|
||||
region = config.AZURE_TTS_REGION
|
||||
subscription_key = config.azure_tts_subscription_key
|
||||
region = config.azure_tts_region
|
||||
if subscription_key and region:
|
||||
audio_declaration = "data:audio/wav;base64,"
|
||||
base64_data = await oas3_azsure_tts(text, lang, voice, style, role, subscription_key, region)
|
||||
|
|
@ -50,9 +50,9 @@ async def text_to_speech(
|
|||
return f"[{text}]({url})"
|
||||
return audio_declaration + base64_data if base64_data else base64_data
|
||||
|
||||
iflytek_app_id = config.IFLYTEK_APP_ID
|
||||
iflytek_api_key = config.IFLYTEK_API_KEY
|
||||
iflytek_api_secret = config.IFLYTEK_API_SECRET
|
||||
iflytek_app_id = config.iflytek_app_id
|
||||
iflytek_api_key = config.iflytek_api_key
|
||||
iflytek_api_secret = config.iflytek_api_secret
|
||||
if iflytek_app_id and iflytek_api_key and iflytek_api_secret:
|
||||
audio_declaration = "data:audio/mp3;base64,"
|
||||
base64_data = await oas3_iflytek_tts(
|
||||
|
|
@ -65,5 +65,5 @@ async def text_to_speech(
|
|||
return audio_declaration + base64_data if base64_data else base64_data
|
||||
|
||||
raise ValueError(
|
||||
"AZURE_TTS_SUBSCRIPTION_KEY, AZURE_TTS_REGION, IFLYTEK_APP_ID, IFLYTEK_API_KEY, IFLYTEK_API_SECRET error"
|
||||
"azure_tts_subscription_key, azure_tts_region, iflytek_app_id, iflytek_api_key, iflytek_api_secret error"
|
||||
)
|
||||
|
|
|
|||
|
|
@ -108,7 +108,7 @@ class BaseLLM(ABC):
|
|||
|
||||
def get_choice_delta_text(self, rsp: dict) -> str:
|
||||
"""Required to provide the first text of stream choice"""
|
||||
return rsp.get("choices")[0]["delta"]["content"]
|
||||
return rsp.get("choices", [{}])[0].get("delta", {}).get("content", "")
|
||||
|
||||
def get_choice_function(self, rsp: dict) -> dict:
|
||||
"""Required to provide the first function of choice
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import asyncio
|
||||
import shutil
|
||||
from pathlib import Path
|
||||
|
|
@ -9,24 +10,25 @@ import typer
|
|||
from metagpt.config2 import config
|
||||
from metagpt.const import CONFIG_ROOT, METAGPT_ROOT
|
||||
from metagpt.context import Context
|
||||
from metagpt.utils.project_repo import ProjectRepo
|
||||
|
||||
app = typer.Typer(add_completion=False, pretty_exceptions_show_locals=False)
|
||||
|
||||
|
||||
def generate_repo(
|
||||
idea,
|
||||
investment,
|
||||
n_round,
|
||||
code_review,
|
||||
run_tests,
|
||||
implement,
|
||||
project_name,
|
||||
inc,
|
||||
project_path,
|
||||
reqa_file,
|
||||
max_auto_summarize_code,
|
||||
recover_path,
|
||||
):
|
||||
investment=3.0,
|
||||
n_round=5,
|
||||
code_review=True,
|
||||
run_tests=False,
|
||||
implement=True,
|
||||
project_name="",
|
||||
inc=False,
|
||||
project_path="",
|
||||
reqa_file="",
|
||||
max_auto_summarize_code=0,
|
||||
recover_path=None,
|
||||
) -> ProjectRepo:
|
||||
"""Run the startup logic. Can be called from CLI or other Python scripts."""
|
||||
from metagpt.roles import (
|
||||
Architect,
|
||||
|
|
@ -67,6 +69,8 @@ def generate_repo(
|
|||
company.run_project(idea)
|
||||
asyncio.run(company.run(n_round=n_round))
|
||||
|
||||
return ctx.repo
|
||||
|
||||
|
||||
@app.command("", help="Start a new project.")
|
||||
def startup(
|
||||
20
metagpt/strategy/search_space.py
Normal file
20
metagpt/strategy/search_space.py
Normal file
|
|
@ -0,0 +1,20 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/30 17:15
|
||||
@Author : alexanderwu
|
||||
@File : search_space.py
|
||||
"""
|
||||
|
||||
|
||||
class SearchSpace:
|
||||
"""SearchSpace: 用于定义一个搜索空间,搜索空间中的节点是 ActionNode 类。"""
|
||||
|
||||
def __init__(self):
|
||||
self.search_space = {}
|
||||
|
||||
def add_node(self, node):
|
||||
self.search_space[node.key] = node
|
||||
|
||||
def get_node(self, key):
|
||||
return self.search_space[key]
|
||||
77
metagpt/strategy/solver.py
Normal file
77
metagpt/strategy/solver.py
Normal file
|
|
@ -0,0 +1,77 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/30 17:13
|
||||
@Author : alexanderwu
|
||||
@File : solver.py
|
||||
"""
|
||||
from abc import abstractmethod
|
||||
|
||||
from metagpt.actions.action_graph import ActionGraph
|
||||
from metagpt.provider.base_llm import BaseLLM
|
||||
from metagpt.strategy.search_space import SearchSpace
|
||||
|
||||
|
||||
class BaseSolver:
|
||||
"""AbstractSolver: defines the interface of a solver."""
|
||||
|
||||
def __init__(self, graph: ActionGraph, search_space: SearchSpace, llm: BaseLLM, context):
|
||||
"""
|
||||
:param graph: ActionGraph
|
||||
:param search_space: SearchSpace
|
||||
:param llm: BaseLLM
|
||||
:param context: Context
|
||||
"""
|
||||
self.graph = graph
|
||||
self.search_space = search_space
|
||||
self.llm = llm
|
||||
self.context = context
|
||||
|
||||
@abstractmethod
|
||||
async def solve(self):
|
||||
"""abstract method to solve the problem."""
|
||||
|
||||
|
||||
class NaiveSolver(BaseSolver):
|
||||
"""NaiveSolver: Iterate all the nodes in the graph and execute them one by one."""
|
||||
|
||||
async def solve(self):
|
||||
self.graph.topological_sort()
|
||||
for key in self.graph.execution_order:
|
||||
op = self.graph.nodes[key]
|
||||
await op.fill(self.context, self.llm, mode="root")
|
||||
|
||||
|
||||
class TOTSolver(BaseSolver):
|
||||
"""TOTSolver: Tree of Thought"""
|
||||
|
||||
async def solve(self):
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class CodeInterpreterSolver(BaseSolver):
|
||||
"""CodeInterpreterSolver: Write&Run code in the graph"""
|
||||
|
||||
async def solve(self):
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class ReActSolver(BaseSolver):
|
||||
"""ReActSolver: ReAct algorithm"""
|
||||
|
||||
async def solve(self):
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class IOSolver(BaseSolver):
|
||||
"""IOSolver: use LLM directly to solve the problem"""
|
||||
|
||||
async def solve(self):
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class COTSolver(BaseSolver):
|
||||
"""COTSolver: Chain of Thought"""
|
||||
|
||||
async def solve(self):
|
||||
raise NotImplementedError
|
||||
|
|
@ -61,9 +61,11 @@ class SerpAPIWrapper(BaseModel):
|
|||
if not self.aiosession:
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(url, params=params) as response:
|
||||
response.raise_for_status()
|
||||
res = await response.json()
|
||||
else:
|
||||
async with self.aiosession.get(url, params=params) as response:
|
||||
response.raise_for_status()
|
||||
res = await response.json()
|
||||
|
||||
return res
|
||||
|
|
|
|||
|
|
@ -55,9 +55,11 @@ class SerperWrapper(BaseModel):
|
|||
if not self.aiosession:
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(url, data=payloads, headers=headers) as response:
|
||||
response.raise_for_status()
|
||||
res = await response.json()
|
||||
else:
|
||||
async with self.aiosession.get.post(url, data=payloads, headers=headers) as response:
|
||||
response.raise_for_status()
|
||||
res = await response.json()
|
||||
|
||||
return res
|
||||
|
|
|
|||
|
|
@ -35,10 +35,10 @@ async def mermaid_to_file(engine, mermaid_code, output_file_without_suffix, widt
|
|||
# tmp.write_text(mermaid_code, encoding="utf-8")
|
||||
|
||||
if engine == "nodejs":
|
||||
if check_cmd_exists(config.mmdc) != 0:
|
||||
if check_cmd_exists(config.mermaid.path) != 0:
|
||||
logger.warning(
|
||||
"RUN `npm install -g @mermaid-js/mermaid-cli` to install mmdc,"
|
||||
"or consider changing MERMAID_ENGINE to `playwright`, `pyppeteer`, or `ink`."
|
||||
"or consider changing engine to `playwright`, `pyppeteer`, or `ink`."
|
||||
)
|
||||
return -1
|
||||
|
||||
|
|
@ -47,11 +47,11 @@ async def mermaid_to_file(engine, mermaid_code, output_file_without_suffix, widt
|
|||
# Call the `mmdc` command to convert the Mermaid code to a PNG
|
||||
logger.info(f"Generating {output_file}..")
|
||||
|
||||
if config.puppeteer_config:
|
||||
if config.mermaid.puppeteer_config:
|
||||
commands = [
|
||||
config.mmdc,
|
||||
config.mermaid.path,
|
||||
"-p",
|
||||
config.puppeteer_config,
|
||||
config.mermaid.puppeteer_config,
|
||||
"-i",
|
||||
str(tmp),
|
||||
"-o",
|
||||
|
|
@ -62,7 +62,7 @@ async def mermaid_to_file(engine, mermaid_code, output_file_without_suffix, widt
|
|||
str(height),
|
||||
]
|
||||
else:
|
||||
commands = [config.mmdc, "-i", str(tmp), "-o", output_file, "-w", str(width), "-H", str(height)]
|
||||
commands = [config.mermaid.path, "-i", str(tmp), "-o", output_file, "-w", str(width), "-H", str(height)]
|
||||
process = await asyncio.create_subprocess_shell(
|
||||
" ".join(commands), stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE
|
||||
)
|
||||
|
|
|
|||
|
|
@ -30,14 +30,14 @@ async def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048,
|
|||
suffixes = ["png", "svg", "pdf"]
|
||||
__dirname = os.path.dirname(os.path.abspath(__file__))
|
||||
|
||||
if config.pyppeteer_executable_path:
|
||||
if config.mermaid.pyppeteer_path:
|
||||
browser = await launch(
|
||||
headless=True,
|
||||
executablePath=config.pyppeteer_executable_path,
|
||||
executablePath=config.mermaid.pyppeteer_path,
|
||||
args=["--disable-extensions", "--no-sandbox"],
|
||||
)
|
||||
else:
|
||||
logger.error("Please set the environment variable:PYPPETEER_EXECUTABLE_PATH.")
|
||||
logger.error("Please set the var mermaid.pyppeteer_path in the config2.yaml.")
|
||||
return -1
|
||||
page = await browser.newPage()
|
||||
device_scale_factor = 1.0
|
||||
|
|
|
|||
|
|
@ -102,6 +102,13 @@ class ProjectRepo(FileRepository):
|
|||
self.tests = self._git_repo.new_file_repository(relative_path=TEST_CODES_FILE_REPO)
|
||||
self.test_outputs = self._git_repo.new_file_repository(relative_path=TEST_OUTPUTS_FILE_REPO)
|
||||
self._srcs_path = None
|
||||
self.code_files_exists()
|
||||
|
||||
def __str__(self):
|
||||
repo_str = f"ProjectRepo({self._git_repo.workdir})"
|
||||
docs_str = f"Docs({self.docs.all_files})"
|
||||
srcs_str = f"Srcs({self.srcs.all_files})"
|
||||
return f"{repo_str}\n{docs_str}\n{srcs_str}"
|
||||
|
||||
@property
|
||||
async def requirement(self):
|
||||
|
|
|
|||
|
|
@ -119,15 +119,22 @@ def repair_json_format(output: str) -> str:
|
|||
logger.info(f"repair_json_format: {'}]'}")
|
||||
elif output.startswith("{") and output.endswith("]"):
|
||||
output = output[:-1] + "}"
|
||||
|
||||
# remove `#` in output json str, usually appeared in `glm-4`
|
||||
# remove comments in output json string, after json value content, maybe start with #, maybe start with //
|
||||
arr = output.split("\n")
|
||||
new_arr = []
|
||||
for line in arr:
|
||||
idx = line.find("#")
|
||||
if idx >= 0:
|
||||
line = line[:idx]
|
||||
new_arr.append(line)
|
||||
for json_line in arr:
|
||||
# look for # or // comments and make sure they are not inside the string value
|
||||
comment_index = -1
|
||||
for match in re.finditer(r"(\".*?\"|\'.*?\')|(#|//)", json_line):
|
||||
if match.group(1): # if the string value
|
||||
continue
|
||||
if match.group(2): # if comments
|
||||
comment_index = match.start(2)
|
||||
break
|
||||
# if comments, then delete them
|
||||
if comment_index != -1:
|
||||
json_line = json_line[:comment_index].rstrip()
|
||||
new_arr.append(json_line)
|
||||
output = "\n".join(new_arr)
|
||||
return output
|
||||
|
||||
|
|
|
|||
|
|
@ -42,7 +42,7 @@ class YamlModelWithoutDefault(YamlModel):
|
|||
@model_validator(mode="before")
|
||||
@classmethod
|
||||
def check_not_default_config(cls, values):
|
||||
"""Check if there is any default config in config.yaml"""
|
||||
"""Check if there is any default config in config2.yaml"""
|
||||
if any(["YOUR" in v for v in values]):
|
||||
raise ValueError("Please set your config in config.yaml")
|
||||
raise ValueError("Please set your config in config2.yaml")
|
||||
return values
|
||||
|
|
|
|||
2
setup.py
2
setup.py
|
|
@ -76,7 +76,7 @@ setup(
|
|||
},
|
||||
entry_points={
|
||||
"console_scripts": [
|
||||
"metagpt=metagpt.startup:app",
|
||||
"metagpt=metagpt.software_company:app",
|
||||
],
|
||||
},
|
||||
)
|
||||
|
|
|
|||
27
tests/config2.yaml
Normal file
27
tests/config2.yaml
Normal file
|
|
@ -0,0 +1,27 @@
|
|||
llm:
|
||||
base_url: "https://api.openai.com/v1"
|
||||
api_key: "sk-xxx"
|
||||
model: "gpt-3.5-turbo-1106"
|
||||
|
||||
search:
|
||||
api_type: "serpapi"
|
||||
api_key: "xxx"
|
||||
|
||||
s3:
|
||||
access_key: "MOCK_S3_ACCESS_KEY"
|
||||
secret_key: "MOCK_S3_SECRET_KEY"
|
||||
endpoint: "http://mock:9000"
|
||||
secure: false
|
||||
bucket: "mock"
|
||||
|
||||
azure_tts_subscription_key: "xxx"
|
||||
azure_tts_region: "eastus"
|
||||
|
||||
iflytek_app_id: "xxx"
|
||||
iflytek_api_key: "xxx"
|
||||
iflytek_api_secret: "xxx"
|
||||
|
||||
metagpt_tti_url: "http://mock.com"
|
||||
|
||||
repair_llm_output: true
|
||||
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
|
|
@ -8,7 +8,7 @@
|
|||
from typing import List, Tuple
|
||||
|
||||
import pytest
|
||||
from pydantic import ValidationError
|
||||
from pydantic import BaseModel, Field, ValidationError
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.actions.action_node import ActionNode, ReviewMode, ReviseMode
|
||||
|
|
@ -241,6 +241,47 @@ def test_create_model_class_with_mapping():
|
|||
assert value == ["game.py", "app.py", "static/css/styles.css", "static/js/script.js", "templates/index.html"]
|
||||
|
||||
|
||||
class ToolDef(BaseModel):
|
||||
tool_name: str = Field(default="a", description="tool name", examples=[])
|
||||
description: str = Field(default="b", description="tool description", examples=[])
|
||||
|
||||
|
||||
class Task(BaseModel):
|
||||
task_id: int = Field(default=1, description="task id", examples=[1, 2, 3])
|
||||
name: str = Field(default="Get data from ...", description="task name", examples=[])
|
||||
dependent_task_ids: List[int] = Field(default=[], description="dependent task ids", examples=[1, 2, 3])
|
||||
tool: ToolDef = Field(default=ToolDef(), description="tool use", examples=[])
|
||||
|
||||
|
||||
class Tasks(BaseModel):
|
||||
tasks: List[Task] = Field(default=[], description="tasks", examples=[])
|
||||
|
||||
|
||||
def test_action_node_from_pydantic_and_print_everything():
|
||||
node = ActionNode.from_pydantic(Task)
|
||||
print("1. Tasks")
|
||||
print(Task().model_dump_json(indent=4))
|
||||
print(Tasks.model_json_schema())
|
||||
print("2. Task")
|
||||
print(Task.model_json_schema())
|
||||
print("3. ActionNode")
|
||||
print(node)
|
||||
print("4. node.compile prompt")
|
||||
prompt = node.compile(context="")
|
||||
assert "tool_name" in prompt, "tool_name should be in prompt"
|
||||
print(prompt)
|
||||
print("5. node.get_children_mapping")
|
||||
print(node._get_children_mapping())
|
||||
print("6. node.create_children_class")
|
||||
children_class = node._create_children_class()
|
||||
print(children_class)
|
||||
import inspect
|
||||
|
||||
code = inspect.getsource(Tasks)
|
||||
print(code)
|
||||
assert "tasks" in code, "tasks should be in code"
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_create_model_class()
|
||||
test_create_model_class_with_mapping()
|
||||
|
|
|
|||
|
|
@ -29,9 +29,9 @@ async def test_rebuild(context):
|
|||
@pytest.mark.parametrize(
|
||||
("path", "direction", "diff", "want"),
|
||||
[
|
||||
("metagpt/startup.py", "=", ".", "metagpt/startup.py"),
|
||||
("metagpt/startup.py", "+", "MetaGPT", "MetaGPT/metagpt/startup.py"),
|
||||
("metagpt/startup.py", "-", "metagpt", "startup.py"),
|
||||
("metagpt/software_company.py", "=", ".", "metagpt/software_company.py"),
|
||||
("metagpt/software_company.py", "+", "MetaGPT", "MetaGPT/metagpt/software_company.py"),
|
||||
("metagpt/software_company.py", "-", "metagpt", "software_company.py"),
|
||||
],
|
||||
)
|
||||
def test_align_path(path, direction, diff, want):
|
||||
|
|
|
|||
|
|
@ -38,7 +38,7 @@ async def test_run_script(context):
|
|||
@pytest.mark.asyncio
|
||||
async def test_run(context):
|
||||
inputs = [
|
||||
(RunCodeContext(mode="text", code_filename="a.txt", code="print('Hello, World')"), "PASS"),
|
||||
(RunCodeContext(mode="text", code_filename="a.txt", code="result = 'helloworld'"), "PASS"),
|
||||
(
|
||||
RunCodeContext(
|
||||
mode="script",
|
||||
|
|
|
|||
|
|
@ -23,9 +23,9 @@ class TestSkillAction:
|
|||
"type": "string",
|
||||
"description": "OpenAI API key, For more details, checkout: `https://platform.openai.com/account/api-keys`",
|
||||
},
|
||||
"METAGPT_TEXT_TO_IMAGE_MODEL_URL": {"type": "string", "description": "Model url."},
|
||||
"metagpt_tti_url": {"type": "string", "description": "Model url."},
|
||||
},
|
||||
"required": {"oneOf": ["OPENAI_API_KEY", "METAGPT_TEXT_TO_IMAGE_MODEL_URL"]},
|
||||
"required": {"oneOf": ["OPENAI_API_KEY", "metagpt_tti_url"]},
|
||||
},
|
||||
parameters={
|
||||
"text": Parameter(type="string", description="The text used for image conversion."),
|
||||
|
|
|
|||
|
|
@ -1,27 +1,21 @@
|
|||
import asyncio
|
||||
|
||||
import pytest
|
||||
from pydantic import BaseModel
|
||||
|
||||
from metagpt.learn.google_search import google_search
|
||||
from metagpt.tools import SearchEngineType
|
||||
|
||||
|
||||
async def mock_google_search():
|
||||
@pytest.mark.asyncio
|
||||
async def test_google_search(search_engine_mocker):
|
||||
class Input(BaseModel):
|
||||
input: str
|
||||
|
||||
inputs = [{"input": "ai agent"}]
|
||||
|
||||
for i in inputs:
|
||||
seed = Input(**i)
|
||||
result = await google_search(seed.input)
|
||||
result = await google_search(
|
||||
seed.input,
|
||||
engine=SearchEngineType.SERPER_GOOGLE,
|
||||
serper_api_key="mock-serper-key",
|
||||
)
|
||||
assert result != ""
|
||||
|
||||
|
||||
def test_suite():
|
||||
loop = asyncio.get_event_loop()
|
||||
task = loop.create_task(mock_google_search())
|
||||
loop.run_until_complete(task)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_suite()
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ async def test_text_to_image(mocker):
|
|||
mocker.patch.object(S3, "cache", return_value="http://mock/s3")
|
||||
|
||||
config = Config.default()
|
||||
assert config.METAGPT_TEXT_TO_IMAGE_MODEL_URL
|
||||
assert config.metagpt_tti_url
|
||||
|
||||
data = await text_to_image("Panda emoji", size_type="512x512", config=config)
|
||||
assert "base64" in data or "http" in data
|
||||
|
|
@ -52,7 +52,7 @@ async def test_openai_text_to_image(mocker):
|
|||
mocker.patch.object(S3, "cache", return_value="http://mock.s3.com/0.png")
|
||||
|
||||
config = Config.default()
|
||||
config.METAGPT_TEXT_TO_IMAGE_MODEL_URL = None
|
||||
config.metagpt_tti_url = None
|
||||
assert config.get_openai_llm()
|
||||
|
||||
data = await text_to_image("Panda emoji", size_type="512x512", config=config)
|
||||
|
|
|
|||
|
|
@ -20,9 +20,9 @@ from metagpt.utils.s3 import S3
|
|||
async def test_azure_text_to_speech(mocker):
|
||||
# mock
|
||||
config = Config.default()
|
||||
config.IFLYTEK_API_KEY = None
|
||||
config.IFLYTEK_API_SECRET = None
|
||||
config.IFLYTEK_APP_ID = None
|
||||
config.iflytek_api_key = None
|
||||
config.iflytek_api_secret = None
|
||||
config.iflytek_app_id = None
|
||||
mock_result = mocker.Mock()
|
||||
mock_result.audio_data = b"mock audio data"
|
||||
mock_result.reason = ResultReason.SynthesizingAudioCompleted
|
||||
|
|
@ -32,11 +32,11 @@ async def test_azure_text_to_speech(mocker):
|
|||
mocker.patch.object(S3, "cache", return_value="http://mock.s3.com/1.wav")
|
||||
|
||||
# Prerequisites
|
||||
assert not config.IFLYTEK_APP_ID
|
||||
assert not config.IFLYTEK_API_KEY
|
||||
assert not config.IFLYTEK_API_SECRET
|
||||
assert config.AZURE_TTS_SUBSCRIPTION_KEY and config.AZURE_TTS_SUBSCRIPTION_KEY != "YOUR_API_KEY"
|
||||
assert config.AZURE_TTS_REGION
|
||||
assert not config.iflytek_app_id
|
||||
assert not config.iflytek_api_key
|
||||
assert not config.iflytek_api_secret
|
||||
assert config.azure_tts_subscription_key and config.azure_tts_subscription_key != "YOUR_API_KEY"
|
||||
assert config.azure_tts_region
|
||||
|
||||
config.copy()
|
||||
# test azure
|
||||
|
|
@ -48,8 +48,8 @@ async def test_azure_text_to_speech(mocker):
|
|||
async def test_iflytek_text_to_speech(mocker):
|
||||
# mock
|
||||
config = Config.default()
|
||||
config.AZURE_TTS_SUBSCRIPTION_KEY = None
|
||||
config.AZURE_TTS_REGION = None
|
||||
config.azure_tts_subscription_key = None
|
||||
config.azure_tts_region = None
|
||||
mocker.patch.object(IFlyTekTTS, "synthesize_speech", return_value=None)
|
||||
mock_data = mocker.AsyncMock()
|
||||
mock_data.read.return_value = b"mock iflytek"
|
||||
|
|
@ -58,11 +58,11 @@ async def test_iflytek_text_to_speech(mocker):
|
|||
mocker.patch.object(S3, "cache", return_value="http://mock.s3.com/1.mp3")
|
||||
|
||||
# Prerequisites
|
||||
assert config.IFLYTEK_APP_ID
|
||||
assert config.IFLYTEK_API_KEY
|
||||
assert config.IFLYTEK_API_SECRET
|
||||
assert not config.AZURE_TTS_SUBSCRIPTION_KEY or config.AZURE_TTS_SUBSCRIPTION_KEY == "YOUR_API_KEY"
|
||||
assert not config.AZURE_TTS_REGION
|
||||
assert config.iflytek_app_id
|
||||
assert config.iflytek_api_key
|
||||
assert config.iflytek_api_secret
|
||||
assert not config.azure_tts_subscription_key or config.azure_tts_subscription_key == "YOUR_API_KEY"
|
||||
assert not config.azure_tts_region
|
||||
|
||||
# test azure
|
||||
data = await text_to_speech("panda emoji", config=config)
|
||||
|
|
|
|||
47
tests/metagpt/strategy/test_solver.py
Normal file
47
tests/metagpt/strategy/test_solver.py
Normal file
|
|
@ -0,0 +1,47 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2024/1/31 13:54
|
||||
@Author : alexanderwu
|
||||
@File : test_solver.py
|
||||
"""
|
||||
import pytest
|
||||
|
||||
from metagpt.actions.action_graph import ActionGraph
|
||||
from metagpt.llm import LLM
|
||||
from metagpt.strategy.search_space import SearchSpace
|
||||
from metagpt.strategy.solver import NaiveSolver
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_solver():
|
||||
from metagpt.actions.write_prd_an import (
|
||||
COMPETITIVE_ANALYSIS,
|
||||
ISSUE_TYPE,
|
||||
PRODUCT_GOALS,
|
||||
REQUIREMENT_POOL,
|
||||
)
|
||||
|
||||
graph = ActionGraph()
|
||||
graph.add_node(ISSUE_TYPE)
|
||||
graph.add_node(PRODUCT_GOALS)
|
||||
graph.add_node(COMPETITIVE_ANALYSIS)
|
||||
graph.add_node(REQUIREMENT_POOL)
|
||||
graph.add_edge(ISSUE_TYPE, PRODUCT_GOALS)
|
||||
graph.add_edge(PRODUCT_GOALS, COMPETITIVE_ANALYSIS)
|
||||
graph.add_edge(PRODUCT_GOALS, REQUIREMENT_POOL)
|
||||
graph.add_edge(COMPETITIVE_ANALYSIS, REQUIREMENT_POOL)
|
||||
search_space = SearchSpace()
|
||||
llm = LLM()
|
||||
context = "Create a 2048 game"
|
||||
solver = NaiveSolver(graph, search_space, llm, context)
|
||||
await solver.solve()
|
||||
|
||||
print("## graph.nodes")
|
||||
print(graph.nodes)
|
||||
for k, v in graph.nodes.items():
|
||||
print(f"{v.key} | prevs: {[i.key for i in v.prevs]} | nexts: {[i.key for i in v.nexts]}")
|
||||
|
||||
assert len(graph.nodes) == 4
|
||||
assert len(graph.execution_order) == 4
|
||||
assert graph.execution_order == [ISSUE_TYPE.key, PRODUCT_GOALS.key, COMPETITIVE_ANALYSIS.key, REQUIREMENT_POOL.key]
|
||||
|
|
@ -14,7 +14,7 @@ from typer.testing import CliRunner
|
|||
|
||||
from metagpt.const import TEST_DATA_PATH
|
||||
from metagpt.logs import logger
|
||||
from metagpt.startup import app
|
||||
from metagpt.software_company import app
|
||||
|
||||
runner = CliRunner()
|
||||
|
||||
|
|
|
|||
|
|
@ -3,13 +3,13 @@
|
|||
"""
|
||||
@Time : 2023/5/15 11:40
|
||||
@Author : alexanderwu
|
||||
@File : test_startup.py
|
||||
@File : test_software_company.py
|
||||
"""
|
||||
import pytest
|
||||
from typer.testing import CliRunner
|
||||
|
||||
from metagpt.logs import logger
|
||||
from metagpt.startup import app
|
||||
from metagpt.software_company import app
|
||||
from metagpt.team import Team
|
||||
|
||||
runner = CliRunner()
|
||||
|
|
@ -23,7 +23,7 @@ async def test_empty_team(new_filename):
|
|||
logger.info(history)
|
||||
|
||||
|
||||
def test_startup(new_filename):
|
||||
def test_software_company(new_filename):
|
||||
args = ["Make a cli snake game"]
|
||||
result = runner.invoke(app, args)
|
||||
logger.info(result)
|
||||
|
|
@ -28,10 +28,10 @@ async def test_azure_tts(mocker):
|
|||
mocker.patch.object(Path, "exists", return_value=True)
|
||||
|
||||
# Prerequisites
|
||||
assert config.AZURE_TTS_SUBSCRIPTION_KEY and config.AZURE_TTS_SUBSCRIPTION_KEY != "YOUR_API_KEY"
|
||||
assert config.AZURE_TTS_REGION
|
||||
assert config.azure_tts_subscription_key and config.azure_tts_subscription_key != "YOUR_API_KEY"
|
||||
assert config.azure_tts_region
|
||||
|
||||
azure_tts = AzureTTS(subscription_key=config.AZURE_TTS_SUBSCRIPTION_KEY, region=config.AZURE_TTS_REGION)
|
||||
azure_tts = AzureTTS(subscription_key=config.azure_tts_subscription_key, region=config.azure_tts_region)
|
||||
text = """
|
||||
女儿看见父亲走了进来,问道:
|
||||
<mstts:express-as role="YoungAdultFemale" style="calm">
|
||||
|
|
|
|||
|
|
@ -15,8 +15,8 @@ from metagpt.tools.iflytek_tts import IFlyTekTTS, oas3_iflytek_tts
|
|||
async def test_iflytek_tts(mocker):
|
||||
# mock
|
||||
config = Config.default()
|
||||
config.AZURE_TTS_SUBSCRIPTION_KEY = None
|
||||
config.AZURE_TTS_REGION = None
|
||||
config.azure_tts_subscription_key = None
|
||||
config.azure_tts_region = None
|
||||
mocker.patch.object(IFlyTekTTS, "synthesize_speech", return_value=None)
|
||||
mock_data = mocker.AsyncMock()
|
||||
mock_data.read.return_value = b"mock iflytek"
|
||||
|
|
@ -24,15 +24,15 @@ async def test_iflytek_tts(mocker):
|
|||
mock_reader.return_value.__aenter__.return_value = mock_data
|
||||
|
||||
# Prerequisites
|
||||
assert config.IFLYTEK_APP_ID
|
||||
assert config.IFLYTEK_API_KEY
|
||||
assert config.IFLYTEK_API_SECRET
|
||||
assert config.iflytek_app_id
|
||||
assert config.iflytek_api_key
|
||||
assert config.iflytek_api_secret
|
||||
|
||||
result = await oas3_iflytek_tts(
|
||||
text="你好,hello",
|
||||
app_id=config.IFLYTEK_APP_ID,
|
||||
api_key=config.IFLYTEK_API_KEY,
|
||||
api_secret=config.IFLYTEK_API_SECRET,
|
||||
app_id=config.iflytek_app_id,
|
||||
api_key=config.iflytek_api_key,
|
||||
api_secret=config.iflytek_api_secret,
|
||||
)
|
||||
assert result
|
||||
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ async def test_draw(mocker):
|
|||
mock_post.return_value.__aenter__.return_value = mock_response
|
||||
|
||||
# Prerequisites
|
||||
assert config.METAGPT_TEXT_TO_IMAGE_MODEL_URL
|
||||
assert config.metagpt_tti_url
|
||||
|
||||
binary_data = await oas3_metagpt_text_to_image("Panda emoji")
|
||||
assert binary_data
|
||||
|
|
|
|||
|
|
@ -8,6 +8,17 @@
|
|||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
from openai.resources.chat.completions import AsyncCompletions
|
||||
from openai.types import CompletionUsage
|
||||
from openai.types.chat.chat_completion import (
|
||||
ChatCompletion,
|
||||
ChatCompletionMessage,
|
||||
Choice,
|
||||
)
|
||||
from openai.types.chat.chat_completion_message_tool_call import (
|
||||
ChatCompletionMessageToolCall,
|
||||
Function,
|
||||
)
|
||||
|
||||
from metagpt.config2 import config
|
||||
from metagpt.const import API_QUESTIONS_PATH, UT_PY_PATH
|
||||
|
|
@ -16,7 +27,43 @@ from metagpt.tools.ut_writer import YFT_PROMPT_PREFIX, UTGenerator
|
|||
|
||||
class TestUTWriter:
|
||||
@pytest.mark.asyncio
|
||||
async def test_api_to_ut_sample(self):
|
||||
async def test_api_to_ut_sample(self, mocker):
|
||||
async def mock_create(*args, **kwargs):
|
||||
return ChatCompletion(
|
||||
id="chatcmpl-8n5fAd21w2J1IIFkI4qxWlNfM7QRC",
|
||||
choices=[
|
||||
Choice(
|
||||
finish_reason="stop",
|
||||
index=0,
|
||||
logprobs=None,
|
||||
message=ChatCompletionMessage(
|
||||
content=None,
|
||||
role="assistant",
|
||||
function_call=None,
|
||||
tool_calls=[
|
||||
ChatCompletionMessageToolCall(
|
||||
id="call_EjjmIY7GMspHu3r9mx8gPA2k",
|
||||
function=Function(
|
||||
arguments='{"code":"import string\\nimport random\\n\\ndef random_string'
|
||||
"(length=10):\\n return ''.join(random.choice(string.ascii_"
|
||||
'lowercase) for i in range(length))"}',
|
||||
name="execute",
|
||||
),
|
||||
type="function",
|
||||
)
|
||||
],
|
||||
),
|
||||
)
|
||||
],
|
||||
created=1706710532,
|
||||
model="gpt-3.5-turbo-1106",
|
||||
object="chat.completion",
|
||||
system_fingerprint="fp_04f9a1eebf",
|
||||
usage=CompletionUsage(completion_tokens=35, prompt_tokens=1982, total_tokens=2017),
|
||||
)
|
||||
|
||||
mocker.patch.object(AsyncCompletions, "create", mock_create)
|
||||
|
||||
# Prerequisites
|
||||
swagger_file = Path(__file__).parent / "../../data/ut_writer/yft_swaggerApi.json"
|
||||
assert swagger_file.exists()
|
||||
|
|
|
|||
|
|
@ -141,6 +141,32 @@ def test_repair_json_format():
|
|||
output = repair_llm_raw_output(output=raw_output, req_keys=[None], repair_type=RepairType.JSON)
|
||||
assert output == target_output
|
||||
|
||||
raw_output = """
|
||||
{
|
||||
"Language": "en_us", // define language
|
||||
"Programming Language": "Python" # define code language
|
||||
}
|
||||
"""
|
||||
target_output = """{
|
||||
"Language": "en_us",
|
||||
"Programming Language": "Python"
|
||||
}"""
|
||||
output = repair_llm_raw_output(output=raw_output, req_keys=[None], repair_type=RepairType.JSON)
|
||||
assert output == target_output
|
||||
|
||||
raw_output = """
|
||||
{
|
||||
"Language": "#en_us#", // define language
|
||||
"Programming Language": "//Python # Code // Language//" # define code language
|
||||
}
|
||||
"""
|
||||
target_output = """{
|
||||
"Language": "#en_us#",
|
||||
"Programming Language": "//Python # Code // Language//"
|
||||
}"""
|
||||
output = repair_llm_raw_output(output=raw_output, req_keys=[None], repair_type=RepairType.JSON)
|
||||
assert output == target_output
|
||||
|
||||
|
||||
def test_repair_invalid_json():
|
||||
from metagpt.utils.repair_llm_raw_output import repair_invalid_json
|
||||
|
|
|
|||
|
|
@ -39,3 +39,7 @@ class MockAioResponse:
|
|||
data = await self.response.json(*args, **kwargs)
|
||||
self.rsp_cache[self.key] = data
|
||||
return data
|
||||
|
||||
def raise_for_status(self):
|
||||
if self.response:
|
||||
self.response.raise_for_status()
|
||||
|
|
|
|||
7
tests/spark.yaml
Normal file
7
tests/spark.yaml
Normal file
|
|
@ -0,0 +1,7 @@
|
|||
llm:
|
||||
api_type: "spark"
|
||||
app_id: "xxx"
|
||||
api_key: "xxx"
|
||||
api_secret: "xxx"
|
||||
domain: "generalv2"
|
||||
base_url: "wss://spark-api.xf-yun.com/v3.1/chat"
|
||||
Loading…
Add table
Add a link
Reference in a new issue