mirror of
https://github.com/FoundationAgents/MetaGPT.git
synced 2026-06-11 15:15:18 +02:00
Merge branch 'geekan:main' into test-proxy
This commit is contained in:
commit
2aef3c5f3a
76 changed files with 3060 additions and 593 deletions
|
|
@ -1,20 +1,9 @@
|
|||
default_stages: [ commit ]
|
||||
|
||||
# Install
|
||||
# 1. pip install pre-commit
|
||||
# 2. pre-commit install(the first time you download the repo, it will be cached for future use)
|
||||
repos:
|
||||
- repo: https://github.com/pycqa/flake8
|
||||
rev: 4.0.1
|
||||
hooks:
|
||||
- id: flake8
|
||||
args: [
|
||||
"--show-source",
|
||||
"--count",
|
||||
"--statistics",
|
||||
"--extend-ignore=E203,E402,C901,E501,E101,E266,E731,W291,F821,W191,E122,E125,E127,E128,W293",
|
||||
"--per-file-ignores=__init__.py:F401",
|
||||
] # when necessary, ignore errors, https://flake8.pycqa.org/en/latest/user/error-codes.html
|
||||
exclude: ^venv/ # exclude dir, e.g. (^foo/|^bar/)
|
||||
|
||||
- repo: https://github.com/pycqa/isort
|
||||
rev: 5.11.5
|
||||
hooks:
|
||||
|
|
@ -24,3 +13,14 @@ repos:
|
|||
(?x)^(
|
||||
.*__init__\.py$
|
||||
)
|
||||
|
||||
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
# Ruff version.
|
||||
rev: v0.0.284
|
||||
hooks:
|
||||
- id: ruff
|
||||
|
||||
- repo: https://github.com/psf/black
|
||||
rev: 23.3.0
|
||||
hooks:
|
||||
- id: black
|
||||
14
Dockerfile
14
Dockerfile
|
|
@ -1,10 +1,10 @@
|
|||
# Use a base image with Python3.9 and Nodejs20 slim version
|
||||
FROM nikolaik/python-nodejs:python3.9-nodejs20-slim
|
||||
|
||||
# Install Debian software needed by MetaGPT
|
||||
# Install Debian software needed by MetaGPT and clean up in one RUN command to reduce image size
|
||||
RUN apt update &&\
|
||||
apt install -y git chromium fonts-ipafont-gothic fonts-wqy-zenhei fonts-thai-tlwg fonts-kacst fonts-freefont-ttf libxss1 --no-install-recommends &&\
|
||||
apt clean
|
||||
apt clean && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# Install Mermaid CLI globally
|
||||
ENV CHROME_BIN="/usr/bin/chromium" \
|
||||
|
|
@ -15,13 +15,11 @@ RUN npm install -g @mermaid-js/mermaid-cli &&\
|
|||
|
||||
# Install Python dependencies and install MetaGPT
|
||||
COPY . /app/metagpt
|
||||
RUN cd /app/metagpt &&\
|
||||
mkdir workspace &&\
|
||||
pip install -r requirements.txt &&\
|
||||
pip cache purge &&\
|
||||
python setup.py install
|
||||
|
||||
WORKDIR /app/metagpt
|
||||
RUN mkdir workspace &&\
|
||||
pip install --no-cache-dir -r requirements.txt &&\
|
||||
python setup.py install
|
||||
|
||||
# Running with an infinite loop using the tail command
|
||||
CMD ["sh", "-c", "tail -f /dev/null"]
|
||||
|
||||
|
|
|
|||
21
README.md
21
README.md
|
|
@ -33,7 +33,7 @@ ## Examples (fully generated by GPT-4)
|
|||
|
||||

|
||||
|
||||
It requires around **$0.2** (GPT-4 api's costs) to generate one example with analysis and design, around **$2.0** to a full project.
|
||||
It costs approximately **$0.2** (in GPT-4 API fees) to generate one example with analysis and design, and around **$2.0** for a full project.
|
||||
|
||||
## Installation
|
||||
|
||||
|
|
@ -191,6 +191,25 @@ ### Code walkthrough
|
|||
|
||||
You can check `examples` for more details on single role (with knowledge base) and LLM only examples.
|
||||
|
||||
## QuickStart
|
||||
It is difficult to install and configure the local environment for some users. The following tutorials will allow you to quickly experience the charm of MetaGPT.
|
||||
|
||||
- [MetaGPT quickstart](https://deepwisdom.feishu.cn/wiki/CyY9wdJc4iNqArku3Lncl4v8n2b)
|
||||
|
||||
## Citation
|
||||
|
||||
For now, cite the [Arxiv paper](https://arxiv.org/abs/2308.00352):
|
||||
```bibtex
|
||||
@misc{hong2023metagpt,
|
||||
title={MetaGPT: Meta Programming for Multi-Agent Collaborative Framework},
|
||||
author={Sirui Hong and Xiawu Zheng and Jonathan Chen and Yuheng Cheng and Jinlin Wang and Ceyao Zhang and Zili Wang and Steven Ka Shing Yau and Zijuan Lin and Liyang Zhou and Chenyu Ran and Lingfeng Xiao and Chenglin Wu},
|
||||
year={2023},
|
||||
eprint={2308.00352},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.AI}
|
||||
}
|
||||
```
|
||||
|
||||
## Contact Information
|
||||
|
||||
If you have any questions or feedback about this project, please feel free to contact us. We highly appreciate your suggestions!
|
||||
|
|
|
|||
|
|
@ -65,4 +65,8 @@ SD_T2I_API: "/sdapi/v1/txt2img"
|
|||
|
||||
### for update_costs & calc_usage
|
||||
UPDATE_COSTS: false
|
||||
CALC_USAGE: false
|
||||
CALC_USAGE: false
|
||||
|
||||
### for Research
|
||||
MODEL_FOR_RESEARCHER_SUMMARY: gpt-3.5-turbo
|
||||
MODEL_FOR_RESEARCHER_REPORT: gpt-3.5-turbo-16k
|
||||
|
|
|
|||
181
docs/FAQ-EN.md
Normal file
181
docs/FAQ-EN.md
Normal file
|
|
@ -0,0 +1,181 @@
|
|||
Our vision is to [extend human life](https://github.com/geekan/HowToLiveLonger) and [reduce working hours](https://github.com/geekan/MetaGPT/).
|
||||
|
||||
1. ### Convenient Link for Sharing this Document:
|
||||
|
||||
```
|
||||
- MetaGPT-Index/FAQ https://deepwisdom.feishu.cn/wiki/MsGnwQBjiif9c3koSJNcYaoSnu4
|
||||
```
|
||||
|
||||
2. ### Link
|
||||
|
||||
<!---->
|
||||
|
||||
1. Code:https://github.com/geekan/MetaGPT
|
||||
|
||||
1. Roadmap:https://github.com/geekan/MetaGPT/blob/main/docs/ROADMAP.md
|
||||
|
||||
1. EN
|
||||
|
||||
1. Demo Video: [MetaGPT: Multi-Agent AI Programming Framework](https://www.youtube.com/watch?v=8RNzxZBTW8M)
|
||||
1. Tutorial: [MetaGPT: Deploy POWERFUL Autonomous Ai Agents BETTER Than SUPERAGI!](https://www.youtube.com/watch?v=q16Gi9pTG_M&t=659s)
|
||||
|
||||
1. CN
|
||||
|
||||
1. Demo Video: [MetaGPT:一行代码搭建你的虚拟公司_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1NP411C7GW/?spm_id_from=333.999.0.0&vd_source=735773c218b47da1b4bd1b98a33c5c77)
|
||||
1. Tutorial: [一个提示词写游戏 Flappy bird, 比AutoGPT强10倍的MetaGPT,最接近AGI的AI项目](https://youtu.be/Bp95b8yIH5c)
|
||||
1. Author's thoughts video(CN): [MetaGPT作者深度解析直播回放_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1Ru411V7XL/?spm_id_from=333.337.search-card.all.click)
|
||||
|
||||
<!---->
|
||||
|
||||
3. ### How to become a contributor?
|
||||
|
||||
<!---->
|
||||
|
||||
1. Choose a task from the Roadmap (or you can propose one). By submitting a PR, you can become a contributor and join the dev team.
|
||||
1. Current contributors come from backgrounds including: ByteDance AI Lab/DingDong/Didi/Xiaohongshu, Tencent/Baidu/MSRA/TikTok/BloomGPT Infra/Bilibili/CUHK/HKUST/CMU/UCB
|
||||
|
||||
<!---->
|
||||
|
||||
4. ### Chief Evangelist (Monthly Rotation)
|
||||
|
||||
MetaGPT Community - The position of Chief Evangelist rotates on a monthly basis. The primary responsibilities include:
|
||||
|
||||
1. Maintaining community FAQ documents, announcements, Github resources/READMEs.
|
||||
1. Responding to, answering, and distributing community questions within an average of 30 minutes, including on platforms like Github Issues, Discord and WeChat.
|
||||
1. Upholding a community atmosphere that is enthusiastic, genuine, and friendly.
|
||||
1. Encouraging everyone to become contributors and participate in projects that are closely related to achieving AGI (Artificial General Intelligence).
|
||||
1. (Optional) Organizing small-scale events, such as hackathons.
|
||||
|
||||
<!---->
|
||||
|
||||
5. ### FAQ
|
||||
|
||||
<!---->
|
||||
|
||||
1. Experience with the generated repo code:
|
||||
|
||||
1. https://github.com/geekan/MetaGPT/releases/tag/v0.1.0
|
||||
|
||||
1. Code truncation/ Parsing failure:
|
||||
|
||||
1. Check if it's due to exceeding length. Consider using the gpt-3.5-turbo-16k or other long token versions.
|
||||
|
||||
1. Success rate:
|
||||
|
||||
1. There hasn't been a quantitative analysis yet, but the success rate of code generated by GPT-4 is significantly higher than that of gpt-3.5-turbo.
|
||||
|
||||
1. Support for incremental, differential updates (if you wish to continue a half-done task):
|
||||
|
||||
1. Several prerequisite tasks are listed on the ROADMAP.
|
||||
|
||||
1. Can existing code be loaded?
|
||||
|
||||
1. It's not on the ROADMAP yet, but there are plans in place. It just requires some time.
|
||||
|
||||
1. Support for multiple programming languages and natural languages?
|
||||
|
||||
1. It's listed on ROADMAP.
|
||||
|
||||
1. Want to join the contributor team? How to proceed?
|
||||
|
||||
1. Merging a PR will get you into the contributor's team. The main ongoing tasks are all listed on the ROADMAP.
|
||||
|
||||
1. PRD stuck / unable to access/ connection interrupted
|
||||
|
||||
1. The official OPENAI_API_BASE address is `https://api.openai.com/v1`
|
||||
1. If the official OPENAI_API_BASE address is inaccessible in your environment (this can be verified with curl), it's recommended to configure using the reverse proxy OPENAI_API_BASE provided by libraries such as openai-forward. For instance, `OPENAI_API_BASE: "``https://api.openai-forward.com/v1``"`
|
||||
1. If the official OPENAI_API_BASE address is inaccessible in your environment (again, verifiable via curl), another option is to configure the OPENAI_PROXY parameter. This way, you can access the official OPENAI_API_BASE via a local proxy. If you don't need to access via a proxy, please do not enable this configuration; if accessing through a proxy is required, modify it to the correct proxy address. Note that when OPENAI_PROXY is enabled, don't set OPENAI_API_BASE.
|
||||
1. Note: OpenAI's default API design ends with a v1. An example of the correct configuration is: `OPENAI_API_BASE: "``https://api.openai.com/v1``"`
|
||||
|
||||
1. Absolutely! How can I assist you today?
|
||||
|
||||
1. Did you use Chi or a similar service? These services are prone to errors, and it seems that the error rate is higher when consuming 3.5k-4k tokens in GPT-4
|
||||
|
||||
1. What does Max token mean?
|
||||
|
||||
1. It's a configuration for OpenAI's maximum response length. If the response exceeds the max token, it will be truncated.
|
||||
|
||||
1. How to change the investment amount?
|
||||
|
||||
1. You can view all commands by typing `python startup.py --help`
|
||||
|
||||
1. Which version of Python is more stable?
|
||||
|
||||
1. python3.9 / python3.10
|
||||
|
||||
1. Can't use GPT-4, getting the error "The model gpt-4 does not exist."
|
||||
|
||||
1. OpenAI's official requirement: You can use GPT-4 only after spending $1 on OpenAI.
|
||||
1. Tip: Run some data with gpt-3.5-turbo (consume the free quota and $1), and then you should be able to use gpt-4.
|
||||
|
||||
1. Can games whose code has never been seen before be written?
|
||||
|
||||
1. Refer to the README. The recommendation system of Toutiao is one of the most complex systems in the world currently. Although it's not on GitHub, many discussions about it exist online. If it can visualize these, it suggests it can also summarize these discussions and convert them into code. The prompt would be something like "write a recommendation system similar to Toutiao". Note: this was approached in earlier versions of the software. The SOP of those versions was different; the current one adopts Elon Musk's five-step work method, emphasizing trimming down requirements as much as possible.
|
||||
|
||||
1. Under what circumstances would there typically be errors?
|
||||
|
||||
1. More than 500 lines of code: some function implementations may be left blank.
|
||||
1. When using a database, it often gets the implementation wrong — since the SQL database initialization process is usually not in the code.
|
||||
1. With more lines of code, there's a higher chance of false impressions, leading to calls to non-existent APIs.
|
||||
|
||||
1. Instructions for using SD Skills/UI Role:
|
||||
|
||||
1. Currently, there is a test script located in /tests/metagpt/roles. The file ui_role provides the corresponding code implementation. For testing, you can refer to the test_ui in the same directory.
|
||||
|
||||
1. The UI role takes over from the product manager role, extending the output from the 【UI Design draft】 provided by the product manager role. The UI role has implemented the UIDesign Action. Within the run of UIDesign, it processes the respective context, and based on the set template, outputs the UI. The output from the UI role includes:
|
||||
|
||||
1. UI Design Description:Describes the content to be designed and the design objectives.
|
||||
1. Selected Elements:Describes the elements in the design that need to be illustrated.
|
||||
1. HTML Layout:Outputs the HTML code for the page.
|
||||
1. CSS Styles (styles.css):Outputs the CSS code for the page.
|
||||
|
||||
1. Currently, the SD skill is a tool invoked by UIDesign. It instantiates the SDEngine, with specific code found in metagpt/tools/sd_engine.
|
||||
|
||||
1. Configuration instructions for SD Skills: The SD interface is currently deployed based on *https://github.com/AUTOMATIC1111/stable-diffusion-webui* **For environmental configurations and model downloads, please refer to the aforementioned GitHub repository. To initiate the SD service that supports API calls, run the command specified in cmd with the parameter nowebui, i.e.,
|
||||
|
||||
1. > python webui.py --enable-insecure-extension-access --port xxx --no-gradio-queue --nowebui
|
||||
1. Once it runs without errors, the interface will be accessible after approximately 1 minute when the model finishes loading.
|
||||
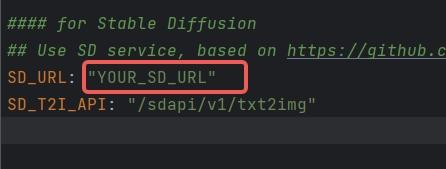
1. Configure SD_URL and SD_T2I_API in the config.yaml/key.yaml files.
|
||||
1. 
|
||||
1. SD_URL is the deployed server/machine IP, and Port is the specified port above, defaulting to 7860.
|
||||
1. > SD_URL: IP:Port
|
||||
|
||||
1. An error occurred during installation: "Another program is using this file...egg".
|
||||
|
||||
1. Delete the file and try again.
|
||||
1. Or manually execute`pip install -r requirements.txt`
|
||||
|
||||
1. The origin of the name MetaGPT?
|
||||
|
||||
1. The name was derived after iterating with GPT-4 over a dozen rounds. GPT-4 scored and suggested it.
|
||||
|
||||
1. Is there a more step-by-step installation tutorial?
|
||||
|
||||
1. Youtube(CN):[一个提示词写游戏 Flappy bird, 比AutoGPT强10倍的MetaGPT,最接近AGI的AI项目=一个软件公司产品经理+程序员](https://youtu.be/Bp95b8yIH5c)
|
||||
1. Youtube(EN)https://www.youtube.com/watch?v=q16Gi9pTG_M&t=659s
|
||||
|
||||
1. openai.error.RateLimitError: You exceeded your current quota, please check your plan and billing details
|
||||
|
||||
1. If you haven't exhausted your free quota, set RPM to 3 or lower in the settings.
|
||||
1. If your free quota is used up, consider adding funds to your account.
|
||||
|
||||
1. What does "borg" mean in n_borg?
|
||||
|
||||
1. https://en.wikipedia.org/wiki/Borg
|
||||
1. The Borg civilization operates based on a hive or collective mentality, known as "the Collective." Every Borg individual is connected to the collective via a sophisticated subspace network, ensuring continuous oversight and guidance for every member. This collective consciousness allows them to not only "share the same thoughts" but also to adapt swiftly to new strategies. While individual members of the collective rarely communicate, the collective "voice" sometimes transmits aboard ships.
|
||||
|
||||
1. How to use the Claude API?
|
||||
|
||||
1. The full implementation of the Claude API is not provided in the current code.
|
||||
1. You can use the Claude API through third-party API conversion projects like: https://github.com/jtsang4/claude-to-chatgpt
|
||||
|
||||
1. Is Llama2 supported?
|
||||
|
||||
1. On the day Llama2 was released, some of the community members began experiments and found that output can be generated based on MetaGPT's structure. However, Llama2's context is too short to generate a complete project. Before regularly using Llama2, it's necessary to expand the context window to at least 8k. If anyone has good recommendations for expansion models or methods, please leave a comment.
|
||||
|
||||
1. `mermaid-cli getElementsByTagName SyntaxError: Unexpected token '.'`
|
||||
|
||||
1. Upgrade node to version 14.x or above:
|
||||
|
||||
1. `npm install -g n`
|
||||
1. `n stable` to install the stable version of node(v18.x)
|
||||
|
|
@ -175,6 +175,11 @@ ### 代码实现
|
|||
|
||||
你可以查看`examples`,其中有单角色(带知识库)的使用例子与仅LLM的使用例子。
|
||||
|
||||
## 快速体验
|
||||
对一些用户来说,安装配置本地环境是有困难的,下面这些教程能够让你快速体验到MetaGPT的魅力。
|
||||
|
||||
- [MetaGPT快速体验](https://deepwisdom.feishu.cn/wiki/Q8ycw6J9tiNXdHk66MRcIN8Pnlg)
|
||||
|
||||
## 联系信息
|
||||
|
||||
如果您对这个项目有任何问题或反馈,欢迎联系我们。我们非常欢迎您的建议!
|
||||
|
|
@ -190,8 +195,6 @@ ## 演示
|
|||
|
||||
## 加入微信讨论群
|
||||
|
||||
<img src="resources/MetaGPT-WeChat-Group4.jpeg" width = "30%" height = "30%" alt="MetaGPT WeChat Discuss Group" align=center />
|
||||
添加运营小姐姐,拉你入群
|
||||
|
||||
如果群已满,请添加负责人微信,会邀请进群
|
||||
|
||||
<img src="resources/MetaGPT-WeChat-Personal.jpeg" width = "30%" height = "30%" alt="MetaGPT WeChat Discuss Group" align=center />
|
||||
<img src="resources/20230811-214014.jpg" width = "30%" height = "30%" alt="MetaGPT WeChat Discuss Group" align=center />
|
||||
|
|
|
|||
|
|
@ -75,25 +75,25 @@ ### Docker によるインストール
|
|||
|
||||
```bash
|
||||
# ステップ 1: metagpt 公式イメージをダウンロードし、config.yaml を準備する
|
||||
docker pull metagpt/metagpt:v0.3
|
||||
docker pull metagpt/metagpt:v0.3.1
|
||||
mkdir -p /opt/metagpt/{config,workspace}
|
||||
docker run --rm metagpt/metagpt:v0.3 cat /app/metagpt/config/config.yaml > /opt/metagpt/config/config.yaml
|
||||
vim /opt/metagpt/config/config.yaml # 設定を変更する
|
||||
docker run --rm metagpt/metagpt:v0.3.1 cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml
|
||||
vim /opt/metagpt/config/key.yaml # 設定を変更する
|
||||
|
||||
# ステップ 2: コンテナで metagpt デモを実行する
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config:/app/metagpt/config \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:v0.3 \
|
||||
metagpt/metagpt:v0.3.1 \
|
||||
python startup.py "Write a cli snake game"
|
||||
|
||||
# コンテナを起動し、その中でコマンドを実行することもできます
|
||||
docker run --name metagpt -d \
|
||||
--privileged \
|
||||
-v /opt/metagpt/config:/app/metagpt/config \
|
||||
-v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \
|
||||
-v /opt/metagpt/workspace:/app/metagpt/workspace \
|
||||
metagpt/metagpt:v0.3
|
||||
metagpt/metagpt:v0.3.1
|
||||
|
||||
docker exec -it metagpt /bin/bash
|
||||
$ python startup.py "Write a cli snake game"
|
||||
|
|
@ -111,7 +111,7 @@ ### 自分でイメージをビルドする
|
|||
```bash
|
||||
# また、自分で metagpt イメージを構築することもできます。
|
||||
git clone https://github.com/geekan/MetaGPT.git
|
||||
cd MetaGPT && docker build -t metagpt:v0.3 .
|
||||
cd MetaGPT && docker build -t metagpt:custom .
|
||||
```
|
||||
|
||||
## 設定
|
||||
|
|
@ -142,37 +142,36 @@ ### プラットフォームまたはツールの設定
|
|||
|
||||
要件を述べるときに、どのプラットフォームまたはツールを使用するかを指定できます。
|
||||
```shell
|
||||
python startup.py "Write a cli snake game based on pygame"
|
||||
python startup.py "pygame をベースとした cli ヘビゲームを書く"
|
||||
```
|
||||
|
||||
### 使用方法
|
||||
|
||||
```
|
||||
NAME
|
||||
startup.py - We are a software startup comprised of AI. By investing in us, you are empowering a future filled with limitless possibilities.
|
||||
会社名
|
||||
startup.py - 私たちは AI で構成されたソフトウェア・スタートアップです。私たちに投資することは、無限の可能性に満ちた未来に力を与えることです。
|
||||
|
||||
SYNOPSIS
|
||||
シノプシス
|
||||
startup.py IDEA <flags>
|
||||
|
||||
DESCRIPTION
|
||||
We are a software startup comprised of AI. By investing in us, you are empowering a future filled with limitless possibilities.
|
||||
説明
|
||||
私たちは AI で構成されたソフトウェア・スタートアップです。私たちに投資することは、無限の可能性に満ちた未来に力を与えることです。
|
||||
|
||||
POSITIONAL ARGUMENTS
|
||||
位置引数
|
||||
IDEA
|
||||
Type: str
|
||||
Your innovative idea, such as "Creating a snake game."
|
||||
型: str
|
||||
あなたの革新的なアイデア、例えば"スネークゲームを作る。"など
|
||||
|
||||
FLAGS
|
||||
フラグ
|
||||
--investment=INVESTMENT
|
||||
Type: float
|
||||
Default: 3.0
|
||||
As an investor, you have the opportunity to contribute a certain dollar amount to this AI company.
|
||||
型: float
|
||||
デフォルト: 3.0
|
||||
投資家として、あなたはこの AI 企業に一定の金額を拠出する機会がある。
|
||||
--n_round=N_ROUND
|
||||
Type: int
|
||||
Default: 5
|
||||
型: int
|
||||
デフォルト: 5
|
||||
|
||||
NOTES
|
||||
You can also use flags syntax for POSITIONAL ARGUMENTS
|
||||
注意事項
|
||||
位置引数にフラグ構文を使うこともできます
|
||||
```
|
||||
|
||||
### コードウォークスルー
|
||||
|
|
@ -192,6 +191,11 @@ ### コードウォークスルー
|
|||
|
||||
`examples` でシングル・ロール(ナレッジ・ベース付き)と LLM のみの例を詳しく見ることができます。
|
||||
|
||||
## クイックスタート
|
||||
ローカル環境のインストールや設定は、ユーザーによっては難しいものです。以下のチュートリアルで MetaGPT の魅力をすぐに体験できます。
|
||||
|
||||
- [MetaGPT クイックスタート](https://deepwisdom.feishu.cn/wiki/Q8ycw6J9tiNXdHk66MRcIN8Pnlg)
|
||||
|
||||
## お問い合わせ先
|
||||
|
||||
このプロジェクトに関するご質問やご意見がございましたら、お気軽にお問い合わせください。皆様のご意見をお待ちしております!
|
||||
|
|
|
|||
BIN
docs/resources/20230811-214014.jpg
Normal file
BIN
docs/resources/20230811-214014.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 58 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 276 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 91 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 164 KiB |
BIN
docs/resources/MetaGPT-WorkWeChatGroup-6.jpg
Normal file
BIN
docs/resources/MetaGPT-WorkWeChatGroup-6.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 84 KiB |
16
examples/research.py
Normal file
16
examples/research.py
Normal file
|
|
@ -0,0 +1,16 @@
|
|||
#!/usr/bin/env python
|
||||
|
||||
import asyncio
|
||||
|
||||
from metagpt.roles.researcher import RESEARCH_PATH, Researcher
|
||||
|
||||
|
||||
async def main():
|
||||
topic = "dataiku vs. datarobot"
|
||||
role = Researcher(language="en-us")
|
||||
await role.run(topic)
|
||||
print(f"save report to {RESEARCH_PATH / f'{topic}.md'}.")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
asyncio.run(main())
|
||||
|
|
@ -15,6 +15,7 @@ from metagpt.actions.design_api import WriteDesign
|
|||
from metagpt.actions.design_api_review import DesignReview
|
||||
from metagpt.actions.design_filenames import DesignFilenames
|
||||
from metagpt.actions.project_management import AssignTasks, WriteTasks
|
||||
from metagpt.actions.research import CollectLinks, WebBrowseAndSummarize, ConductResearch
|
||||
from metagpt.actions.run_code import RunCode
|
||||
from metagpt.actions.search_and_summarize import SearchAndSummarize
|
||||
from metagpt.actions.write_code import WriteCode
|
||||
|
|
@ -26,6 +27,7 @@ from metagpt.actions.write_test import WriteTest
|
|||
|
||||
class ActionType(Enum):
|
||||
"""All types of Actions, used for indexing."""
|
||||
|
||||
ADD_REQUIREMENT = BossRequirement
|
||||
WRITE_PRD = WritePRD
|
||||
WRITE_PRD_REVIEW = WritePRDReview
|
||||
|
|
@ -40,3 +42,13 @@ class ActionType(Enum):
|
|||
WRITE_TASKS = WriteTasks
|
||||
ASSIGN_TASKS = AssignTasks
|
||||
SEARCH_AND_SUMMARIZE = SearchAndSummarize
|
||||
COLLECT_LINKS = CollectLinks
|
||||
WEB_BROWSE_AND_SUMMARIZE = WebBrowseAndSummarize
|
||||
CONDUCT_RESEARCH = ConductResearch
|
||||
|
||||
|
||||
__all__ = [
|
||||
"ActionType",
|
||||
"Action",
|
||||
"ActionOutput",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -5,15 +5,47 @@
|
|||
@Author : alexanderwu
|
||||
@File : debug_error.py
|
||||
"""
|
||||
import re
|
||||
|
||||
from metagpt.logs import logger
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.utils.common import CodeParser
|
||||
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
NOTICE
|
||||
1. Role: You are a Development Engineer or QA engineer;
|
||||
2. Task: You received this message from another Development Engineer or QA engineer who ran or tested your code.
|
||||
Based on the message, first, figure out your own role, i.e. Engineer or QaEngineer,
|
||||
then rewrite the development code or the test code based on your role, the error, and the summary, such that all bugs are fixed and the code performs well.
|
||||
Attention: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD WRITE BEFORE the test case or script and triple quotes.
|
||||
The message is as follows:
|
||||
{context}
|
||||
---
|
||||
Now you should start rewriting the code:
|
||||
## file name of the code to rewrite: Write code with triple quoto. Do your best to implement THIS IN ONLY ONE FILE.
|
||||
"""
|
||||
class DebugError(Action):
|
||||
def __init__(self, name, context=None, llm=None):
|
||||
def __init__(self, name="DebugError", context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
|
||||
async def run(self, code, error):
|
||||
prompt = f"Here is a piece of Python code:\n\n{code}\n\nThe following error occurred during execution:" \
|
||||
f"\n\n{error}\n\nPlease try to fix the error in this code."
|
||||
fixed_code = await self._aask(prompt)
|
||||
return fixed_code
|
||||
# async def run(self, code, error):
|
||||
# prompt = f"Here is a piece of Python code:\n\n{code}\n\nThe following error occurred during execution:" \
|
||||
# f"\n\n{error}\n\nPlease try to fix the error in this code."
|
||||
# fixed_code = await self._aask(prompt)
|
||||
# return fixed_code
|
||||
|
||||
async def run(self, context):
|
||||
if "PASS" in context:
|
||||
return "", "the original code works fine, no need to debug"
|
||||
|
||||
file_name = re.search("## File To Rewrite:\s*(.+\\.py)", context).group(1)
|
||||
|
||||
logger.info(f"Debug and rewrite {file_name}")
|
||||
|
||||
prompt = PROMPT_TEMPLATE.format(context=context)
|
||||
|
||||
rsp = await self._aask(prompt)
|
||||
|
||||
code = CodeParser.parse_code(block="", text=rsp)
|
||||
|
||||
return file_name, code
|
||||
|
|
|
|||
277
metagpt/actions/research.py
Normal file
277
metagpt/actions/research.py
Normal file
|
|
@ -0,0 +1,277 @@
|
|||
#!/usr/bin/env python
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import asyncio
|
||||
import json
|
||||
from typing import Callable
|
||||
|
||||
from pydantic import parse_obj_as
|
||||
|
||||
from metagpt.actions import Action
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.logs import logger
|
||||
from metagpt.tools.search_engine import SearchEngine
|
||||
from metagpt.tools.web_browser_engine import WebBrowserEngine, WebBrowserEngineType
|
||||
from metagpt.utils.text import generate_prompt_chunk, reduce_message_length
|
||||
|
||||
LANG_PROMPT = "Please respond in {language}."
|
||||
|
||||
RESEARCH_BASE_SYSTEM = """You are an AI critical thinker research assistant. Your sole purpose is to write well \
|
||||
written, critically acclaimed, objective and structured reports on the given text."""
|
||||
|
||||
RESEARCH_TOPIC_SYSTEM = "You are an AI researcher assistant, and your research topic is:\n#TOPIC#\n{topic}"
|
||||
|
||||
SEARCH_TOPIC_PROMPT = """Please provide up to 2 necessary keywords related to your research topic for Google search. \
|
||||
Your response must be in JSON format, for example: ["keyword1", "keyword2"]."""
|
||||
|
||||
SUMMARIZE_SEARCH_PROMPT = """### Requirements
|
||||
1. The keywords related to your research topic and the search results are shown in the "Search Result Information" section.
|
||||
2. Provide up to {decomposition_nums} queries related to your research topic base on the search results.
|
||||
3. Please respond in the following JSON format: ["query1", "query2", "query3", ...].
|
||||
|
||||
### Search Result Information
|
||||
{search_results}
|
||||
"""
|
||||
|
||||
COLLECT_AND_RANKURLS_PROMPT = """### Topic
|
||||
{topic}
|
||||
### Query
|
||||
{query}
|
||||
|
||||
### The online search results
|
||||
{results}
|
||||
|
||||
### Requirements
|
||||
Please remove irrelevant search results that are not related to the query or topic. Then, sort the remaining search results \
|
||||
based on the link credibility. If two results have equal credibility, prioritize them based on the relevance. Provide the
|
||||
ranked results' indices in JSON format, like [0, 1, 3, 4, ...], without including other words.
|
||||
"""
|
||||
|
||||
WEB_BROWSE_AND_SUMMARIZE_PROMPT = '''### Requirements
|
||||
1. Utilize the text in the "Reference Information" section to respond to the question "{query}".
|
||||
2. If the question cannot be directly answered using the text, but the text is related to the research topic, please provide \
|
||||
a comprehensive summary of the text.
|
||||
3. If the text is entirely unrelated to the research topic, please reply with a simple text "Not relevant."
|
||||
4. Include all relevant factual information, numbers, statistics, etc., if available.
|
||||
|
||||
### Reference Information
|
||||
{content}
|
||||
'''
|
||||
|
||||
|
||||
CONDUCT_RESEARCH_PROMPT = '''### Reference Information
|
||||
{content}
|
||||
|
||||
### Requirements
|
||||
Please provide a detailed research report in response to the following topic: "{topic}", using the information provided \
|
||||
above. The report must meet the following requirements:
|
||||
|
||||
- Focus on directly addressing the chosen topic.
|
||||
- Ensure a well-structured and in-depth presentation, incorporating relevant facts and figures where available.
|
||||
- Present data and findings in an intuitive manner, utilizing feature comparative tables, if applicable.
|
||||
- The report should have a minimum word count of 2,000 and be formatted with Markdown syntax following APA style guidelines.
|
||||
- Include all source URLs in APA format at the end of the report.
|
||||
'''
|
||||
|
||||
|
||||
class CollectLinks(Action):
|
||||
"""Action class to collect links from a search engine."""
|
||||
def __init__(
|
||||
self,
|
||||
name: str = "",
|
||||
*args,
|
||||
rank_func: Callable[[list[str]], None] | None = None,
|
||||
**kwargs,
|
||||
):
|
||||
super().__init__(name, *args, **kwargs)
|
||||
self.desc = "Collect links from a search engine."
|
||||
self.search_engine = SearchEngine()
|
||||
self.rank_func = rank_func
|
||||
|
||||
async def run(
|
||||
self,
|
||||
topic: str,
|
||||
decomposition_nums: int = 4,
|
||||
url_per_query: int = 4,
|
||||
system_text: str | None = None,
|
||||
) -> dict[str, list[str]]:
|
||||
"""Run the action to collect links.
|
||||
|
||||
Args:
|
||||
topic: The research topic.
|
||||
decomposition_nums: The number of search questions to generate.
|
||||
url_per_query: The number of URLs to collect per search question.
|
||||
system_text: The system text.
|
||||
|
||||
Returns:
|
||||
A dictionary containing the search questions as keys and the collected URLs as values.
|
||||
"""
|
||||
system_text = system_text if system_text else RESEARCH_TOPIC_SYSTEM.format(topic=topic)
|
||||
keywords = await self._aask(SEARCH_TOPIC_PROMPT, [system_text])
|
||||
try:
|
||||
keywords = json.loads(keywords)
|
||||
keywords = parse_obj_as(list[str], keywords)
|
||||
except Exception as e:
|
||||
logger.exception(f"fail to get keywords related to the research topic \"{topic}\" for {e}")
|
||||
keywords = [topic]
|
||||
results = await asyncio.gather(*(self.search_engine.run(i, as_string=False) for i in keywords))
|
||||
|
||||
def gen_msg():
|
||||
while True:
|
||||
search_results = "\n".join(f"#### Keyword: {i}\n Search Result: {j}\n" for (i, j) in zip(keywords, results))
|
||||
prompt = SUMMARIZE_SEARCH_PROMPT.format(decomposition_nums=decomposition_nums, search_results=search_results)
|
||||
yield prompt
|
||||
remove = max(results, key=len)
|
||||
remove.pop()
|
||||
if len(remove) == 0:
|
||||
break
|
||||
prompt = reduce_message_length(gen_msg(), self.llm.model, system_text, CONFIG.max_tokens_rsp)
|
||||
logger.debug(prompt)
|
||||
queries = await self._aask(prompt, [system_text])
|
||||
try:
|
||||
queries = json.loads(queries)
|
||||
queries = parse_obj_as(list[str], queries)
|
||||
except Exception as e:
|
||||
logger.exception(f"fail to break down the research question due to {e}")
|
||||
queries = keywords
|
||||
ret = {}
|
||||
for query in queries:
|
||||
ret[query] = await self._search_and_rank_urls(topic, query, url_per_query)
|
||||
return ret
|
||||
|
||||
async def _search_and_rank_urls(self, topic: str, query: str, num_results: int = 4) -> list[str]:
|
||||
"""Search and rank URLs based on a query.
|
||||
|
||||
Args:
|
||||
topic: The research topic.
|
||||
query: The search query.
|
||||
num_results: The number of URLs to collect.
|
||||
|
||||
Returns:
|
||||
A list of ranked URLs.
|
||||
"""
|
||||
max_results = max(num_results * 2, 6)
|
||||
results = await self.search_engine.run(query, max_results=max_results, as_string=False)
|
||||
_results = "\n".join(f"{i}: {j}" for i, j in zip(range(max_results), results))
|
||||
prompt = COLLECT_AND_RANKURLS_PROMPT.format(topic=topic, query=query, results=_results)
|
||||
logger.debug(prompt)
|
||||
indices = await self._aask(prompt)
|
||||
try:
|
||||
indices = json.loads(indices)
|
||||
assert all(isinstance(i, int) for i in indices)
|
||||
except Exception as e:
|
||||
logger.exception(f"fail to rank results for {e}")
|
||||
indices = list(range(max_results))
|
||||
results = [results[i] for i in indices]
|
||||
if self.rank_func:
|
||||
results = self.rank_func(results)
|
||||
return [i["link"] for i in results[:num_results]]
|
||||
|
||||
|
||||
class WebBrowseAndSummarize(Action):
|
||||
"""Action class to explore the web and provide summaries of articles and webpages."""
|
||||
def __init__(
|
||||
self,
|
||||
*args,
|
||||
browse_func: Callable[[list[str]], None] | None = None,
|
||||
**kwargs,
|
||||
):
|
||||
super().__init__(*args, **kwargs)
|
||||
if CONFIG.model_for_researcher_summary:
|
||||
self.llm.model = CONFIG.model_for_researcher_summary
|
||||
self.web_browser_engine = WebBrowserEngine(
|
||||
engine=WebBrowserEngineType.CUSTOM if browse_func else None,
|
||||
run_func=browse_func,
|
||||
)
|
||||
self.desc = "Explore the web and provide summaries of articles and webpages."
|
||||
|
||||
async def run(
|
||||
self,
|
||||
url: str,
|
||||
*urls: str,
|
||||
query: str,
|
||||
system_text: str = RESEARCH_BASE_SYSTEM,
|
||||
) -> dict[str, str]:
|
||||
"""Run the action to browse the web and provide summaries.
|
||||
|
||||
Args:
|
||||
url: The main URL to browse.
|
||||
urls: Additional URLs to browse.
|
||||
query: The research question.
|
||||
system_text: The system text.
|
||||
|
||||
Returns:
|
||||
A dictionary containing the URLs as keys and their summaries as values.
|
||||
"""
|
||||
contents = await self.web_browser_engine.run(url, *urls)
|
||||
if not urls:
|
||||
contents = [contents]
|
||||
|
||||
summaries = {}
|
||||
prompt_template = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content="{}")
|
||||
for u, content in zip([url, *urls], contents):
|
||||
content = content.inner_text
|
||||
chunk_summaries = []
|
||||
for prompt in generate_prompt_chunk(content, prompt_template, self.llm.model, system_text, CONFIG.max_tokens_rsp):
|
||||
logger.debug(prompt)
|
||||
summary = await self._aask(prompt, [system_text])
|
||||
if summary == "Not relevant.":
|
||||
continue
|
||||
chunk_summaries.append(summary)
|
||||
|
||||
if not chunk_summaries:
|
||||
summaries[u] = None
|
||||
continue
|
||||
|
||||
if len(chunk_summaries) == 1:
|
||||
summaries[u] = chunk_summaries[0]
|
||||
continue
|
||||
|
||||
content = "\n".join(chunk_summaries)
|
||||
prompt = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content=content)
|
||||
summary = await self._aask(prompt, [system_text])
|
||||
summaries[u] = summary
|
||||
return summaries
|
||||
|
||||
|
||||
class ConductResearch(Action):
|
||||
"""Action class to conduct research and generate a research report."""
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
if CONFIG.model_for_researcher_report:
|
||||
self.llm.model = CONFIG.model_for_researcher_report
|
||||
|
||||
async def run(
|
||||
self,
|
||||
topic: str,
|
||||
content: str,
|
||||
system_text: str = RESEARCH_BASE_SYSTEM,
|
||||
) -> str:
|
||||
"""Run the action to conduct research and generate a research report.
|
||||
|
||||
Args:
|
||||
topic: The research topic.
|
||||
content: The content for research.
|
||||
system_text: The system text.
|
||||
|
||||
Returns:
|
||||
The generated research report.
|
||||
"""
|
||||
prompt = CONDUCT_RESEARCH_PROMPT.format(topic=topic, content=content)
|
||||
logger.debug(prompt)
|
||||
self.llm.auto_max_tokens = True
|
||||
return await self._aask(prompt, [system_text])
|
||||
|
||||
|
||||
def get_research_system_text(topic: str, language: str):
|
||||
"""Get the system text for conducting research.
|
||||
|
||||
Args:
|
||||
topic: The research topic.
|
||||
language: The language for the system text.
|
||||
|
||||
Returns:
|
||||
The system text for conducting research.
|
||||
"""
|
||||
return " ".join((RESEARCH_TOPIC_SYSTEM.format(topic=topic), LANG_PROMPT.format(language=language)))
|
||||
|
|
@ -5,21 +5,124 @@
|
|||
@Author : alexanderwu
|
||||
@File : run_code.py
|
||||
"""
|
||||
import os
|
||||
import subprocess
|
||||
import traceback
|
||||
from typing import Tuple
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.logs import logger
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
Role: You are a senior development and qa engineer, your role is summarize the code running result.
|
||||
If the running result does not include an error, you should explicitly approve the result.
|
||||
On the other hand, if the running result indicates some error, you should point out which part, the development code or the test code, produces the error,
|
||||
and give specific instructions on fixing the errors. Here is the code info:
|
||||
{context}
|
||||
Now you should begin your analysis
|
||||
---
|
||||
## instruction:
|
||||
Please summarize the cause of the errors and give correction instruction
|
||||
## File To Rewrite:
|
||||
Determine the ONE file to rewrite in order to fix the error, for example, xyz.py, or test_xyz.py
|
||||
## Status:
|
||||
Determine if all of the code works fine, if so write PASS, else FAIL,
|
||||
WRITE ONLY ONE WORD, PASS OR FAIL, IN THIS SECTION
|
||||
## Send To:
|
||||
Please write Engineer if the errors are due to problematic development codes, and QaEngineer to problematic test codes, and NoOne if there are no errors,
|
||||
WRITE ONLY ONE WORD, Engineer OR QaEngineer OR NoOne, IN THIS SECTION.
|
||||
---
|
||||
You should fill in necessary instruction, status, send to, and finally return all content between the --- segment line.
|
||||
"""
|
||||
|
||||
CONTEXT = """
|
||||
## Development Code File Name
|
||||
{code_file_name}
|
||||
## Development Code
|
||||
```python
|
||||
{code}
|
||||
```
|
||||
## Test File Name
|
||||
{test_file_name}
|
||||
## Test Code
|
||||
```python
|
||||
{test_code}
|
||||
```
|
||||
## Running Command
|
||||
{command}
|
||||
## Running Output
|
||||
standard output: {outs};
|
||||
standard errors: {errs};
|
||||
"""
|
||||
|
||||
|
||||
class RunCode(Action):
|
||||
def __init__(self, name, context=None, llm=None):
|
||||
def __init__(self, name="RunCode", context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
|
||||
async def run(self, code):
|
||||
@classmethod
|
||||
async def run_text(cls, code) -> Tuple[str, str]:
|
||||
try:
|
||||
# We will document_store the result in this dictionary
|
||||
namespace = {}
|
||||
exec(code, namespace)
|
||||
return namespace.get('result', None)
|
||||
return namespace.get("result", ""), ""
|
||||
except Exception:
|
||||
# If there is an error in the code, return the error message
|
||||
return traceback.format_exc()
|
||||
return "", traceback.format_exc()
|
||||
|
||||
@classmethod
|
||||
async def run_script(cls, working_directory, additional_python_paths=[], command=[]) -> Tuple[str, str]:
|
||||
working_directory = str(working_directory)
|
||||
additional_python_paths = [str(path) for path in additional_python_paths]
|
||||
|
||||
# Copy the current environment variables
|
||||
env = os.environ.copy()
|
||||
|
||||
# Modify the PYTHONPATH environment variable
|
||||
additional_python_paths = [working_directory] + additional_python_paths
|
||||
additional_python_paths = ":".join(additional_python_paths)
|
||||
env["PYTHONPATH"] = additional_python_paths + ":" + env.get("PYTHONPATH", "")
|
||||
|
||||
# Start the subprocess
|
||||
process = subprocess.Popen(
|
||||
command, cwd=working_directory, stdout=subprocess.PIPE, stderr=subprocess.PIPE, env=env
|
||||
)
|
||||
|
||||
try:
|
||||
# Wait for the process to complete, with a timeout
|
||||
stdout, stderr = process.communicate(timeout=10)
|
||||
except subprocess.TimeoutExpired:
|
||||
logger.info("The command did not complete within the given timeout.")
|
||||
process.kill() # Kill the process if it times out
|
||||
stdout, stderr = process.communicate()
|
||||
return stdout.decode("utf-8"), stderr.decode("utf-8")
|
||||
|
||||
async def run(
|
||||
self, code, mode="script", code_file_name="", test_code="", test_file_name="", command=[], **kwargs
|
||||
) -> str:
|
||||
logger.info(f"Running {' '.join(command)}")
|
||||
if mode == "script":
|
||||
outs, errs = await self.run_script(command=command, **kwargs)
|
||||
elif mode == "text":
|
||||
outs, errs = await self.run_text(code=code)
|
||||
|
||||
logger.info(f"{outs=}")
|
||||
logger.info(f"{errs=}")
|
||||
|
||||
context = CONTEXT.format(
|
||||
code=code,
|
||||
code_file_name=code_file_name,
|
||||
test_code=test_code,
|
||||
test_file_name=test_file_name,
|
||||
command=" ".join(command),
|
||||
outs=outs[:500], # outs might be long but they are not important, truncate them to avoid token overflow
|
||||
errs=errs[:10000], # truncate errors to avoid token overflow
|
||||
)
|
||||
|
||||
prompt = PROMPT_TEMPLATE.format(context=context)
|
||||
rsp = await self._aask(prompt)
|
||||
|
||||
result = context + rsp
|
||||
|
||||
return result
|
||||
|
|
|
|||
214
metagpt/actions/write_docstring.py
Normal file
214
metagpt/actions/write_docstring.py
Normal file
|
|
@ -0,0 +1,214 @@
|
|||
"""Code Docstring Generator.
|
||||
|
||||
This script provides a tool to automatically generate docstrings for Python code. It uses the specified style to create
|
||||
docstrings for the given code and system text.
|
||||
|
||||
Usage:
|
||||
python3 -m metagpt.actions.write_docstring <filename> [--overwrite] [--style=<docstring_style>]
|
||||
|
||||
Arguments:
|
||||
filename The path to the Python file for which you want to generate docstrings.
|
||||
|
||||
Options:
|
||||
--overwrite If specified, overwrite the original file with the code containing docstrings.
|
||||
--style=<docstring_style> Specify the style of the generated docstrings.
|
||||
Valid values: 'google', 'numpy', or 'sphinx'.
|
||||
Default: 'google'
|
||||
|
||||
Example:
|
||||
python3 -m metagpt.actions.write_docstring startup.py --overwrite False --style=numpy
|
||||
|
||||
This script uses the 'fire' library to create a command-line interface. It generates docstrings for the given Python code using
|
||||
the specified docstring style and adds them to the code.
|
||||
"""
|
||||
import ast
|
||||
from typing import Literal
|
||||
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.utils.common import OutputParser
|
||||
from metagpt.utils.pycst import merge_docstring
|
||||
|
||||
PYTHON_DOCSTRING_SYSTEM = '''### Requirements
|
||||
1. Add docstrings to the given code following the {style} style.
|
||||
2. Replace the function body with an Ellipsis object(...) to reduce output.
|
||||
3. If the types are already annotated, there is no need to include them in the docstring.
|
||||
4. Extract only class, function or the docstrings for the module parts from the given Python code, avoiding any other text.
|
||||
|
||||
### Input Example
|
||||
```python
|
||||
def function_with_pep484_type_annotations(param1: int) -> bool:
|
||||
return isinstance(param1, int)
|
||||
|
||||
class ExampleError(Exception):
|
||||
def __init__(self, msg: str):
|
||||
self.msg = msg
|
||||
```
|
||||
|
||||
### Output Example
|
||||
```python
|
||||
{example}
|
||||
```
|
||||
'''
|
||||
|
||||
# https://www.sphinx-doc.org/en/master/usage/extensions/napoleon.html
|
||||
|
||||
PYTHON_DOCSTRING_EXAMPLE_GOOGLE = '''
|
||||
def function_with_pep484_type_annotations(param1: int) -> bool:
|
||||
"""Example function with PEP 484 type annotations.
|
||||
|
||||
Extended description of function.
|
||||
|
||||
Args:
|
||||
param1: The first parameter.
|
||||
|
||||
Returns:
|
||||
The return value. True for success, False otherwise.
|
||||
"""
|
||||
...
|
||||
|
||||
class ExampleError(Exception):
|
||||
"""Exceptions are documented in the same way as classes.
|
||||
|
||||
The __init__ method was documented in the class level docstring.
|
||||
|
||||
Args:
|
||||
msg: Human readable string describing the exception.
|
||||
|
||||
Attributes:
|
||||
msg: Human readable string describing the exception.
|
||||
"""
|
||||
...
|
||||
'''
|
||||
|
||||
PYTHON_DOCSTRING_EXAMPLE_NUMPY = '''
|
||||
def function_with_pep484_type_annotations(param1: int) -> bool:
|
||||
"""
|
||||
Example function with PEP 484 type annotations.
|
||||
|
||||
Extended description of function.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
param1
|
||||
The first parameter.
|
||||
|
||||
Returns
|
||||
-------
|
||||
bool
|
||||
The return value. True for success, False otherwise.
|
||||
"""
|
||||
...
|
||||
|
||||
class ExampleError(Exception):
|
||||
"""
|
||||
Exceptions are documented in the same way as classes.
|
||||
|
||||
The __init__ method was documented in the class level docstring.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
msg
|
||||
Human readable string describing the exception.
|
||||
|
||||
Attributes
|
||||
----------
|
||||
msg
|
||||
Human readable string describing the exception.
|
||||
"""
|
||||
...
|
||||
'''
|
||||
|
||||
PYTHON_DOCSTRING_EXAMPLE_SPHINX = '''
|
||||
def function_with_pep484_type_annotations(param1: int) -> bool:
|
||||
"""Example function with PEP 484 type annotations.
|
||||
|
||||
Extended description of function.
|
||||
|
||||
:param param1: The first parameter.
|
||||
:type param1: int
|
||||
|
||||
:return: The return value. True for success, False otherwise.
|
||||
:rtype: bool
|
||||
"""
|
||||
...
|
||||
|
||||
class ExampleError(Exception):
|
||||
"""Exceptions are documented in the same way as classes.
|
||||
|
||||
The __init__ method was documented in the class level docstring.
|
||||
|
||||
:param msg: Human-readable string describing the exception.
|
||||
:type msg: str
|
||||
"""
|
||||
...
|
||||
'''
|
||||
|
||||
_python_docstring_style = {
|
||||
"google": PYTHON_DOCSTRING_EXAMPLE_GOOGLE.strip(),
|
||||
"numpy": PYTHON_DOCSTRING_EXAMPLE_NUMPY.strip(),
|
||||
"sphinx": PYTHON_DOCSTRING_EXAMPLE_SPHINX.strip(),
|
||||
}
|
||||
|
||||
|
||||
class WriteDocstring(Action):
|
||||
"""This class is used to write docstrings for code.
|
||||
|
||||
Attributes:
|
||||
desc: A string describing the action.
|
||||
"""
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.desc = "Write docstring for code."
|
||||
|
||||
async def run(
|
||||
self, code: str,
|
||||
system_text: str = PYTHON_DOCSTRING_SYSTEM,
|
||||
style: Literal["google", "numpy", "sphinx"] = "google",
|
||||
) -> str:
|
||||
"""Writes docstrings for the given code and system text in the specified style.
|
||||
|
||||
Args:
|
||||
code: A string of Python code.
|
||||
system_text: A string of system text.
|
||||
style: A string specifying the style of the docstring. Can be 'google', 'numpy', or 'sphinx'.
|
||||
|
||||
Returns:
|
||||
The Python code with docstrings added.
|
||||
"""
|
||||
system_text = system_text.format(style=style, example=_python_docstring_style[style])
|
||||
simplified_code = _simplify_python_code(code)
|
||||
documented_code = await self._aask(f"```python\n{simplified_code}\n```", [system_text])
|
||||
documented_code = OutputParser.parse_python_code(documented_code)
|
||||
return merge_docstring(code, documented_code)
|
||||
|
||||
|
||||
def _simplify_python_code(code: str) -> None:
|
||||
"""Simplifies the given Python code by removing expressions and the last if statement.
|
||||
|
||||
Args:
|
||||
code: A string of Python code.
|
||||
|
||||
Returns:
|
||||
The simplified Python code.
|
||||
"""
|
||||
code_tree = ast.parse(code)
|
||||
code_tree.body = [i for i in code_tree.body if not isinstance(i, ast.Expr)]
|
||||
if isinstance(code_tree.body[-1], ast.If):
|
||||
code_tree.body.pop()
|
||||
return ast.unparse(code_tree)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import fire
|
||||
|
||||
async def run(filename: str, overwrite: bool = False, style: Literal["google", "numpy", "sphinx"] = "google"):
|
||||
with open(filename) as f:
|
||||
code = f.read()
|
||||
code = await WriteDocstring().run(code, style=style)
|
||||
if overwrite:
|
||||
with open(filename, "w") as f:
|
||||
f.write(code)
|
||||
return code
|
||||
|
||||
fire.Fire(run)
|
||||
|
|
@ -6,21 +6,44 @@
|
|||
@File : write_test.py
|
||||
"""
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.utils.common import CodeParser
|
||||
|
||||
PROMPT_TEMPLATE = """
|
||||
NOTICE
|
||||
1. Role: You are a QA engineer; the main goal is to design, develop, and execute PEP8 compliant, well-structured, maintainable test cases and scripts for Python 3.9. Your focus should be on ensuring the product quality of the entire project through systematic testing.
|
||||
2. Requirement: Based on the context, develop a comprehensive test suite that adequately covers all relevant aspects of the code file under review. Your test suite will be part of the overall project QA, so please develop complete, robust, and reusable test cases.
|
||||
3. Attention1: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD WRITE BEFORE the test case or script.
|
||||
4. Attention2: If there are any settings in your tests, ALWAYS SET A DEFAULT VALUE, ALWAYS USE STRONG TYPE AND EXPLICIT VARIABLE.
|
||||
5. Attention3: YOU MUST FOLLOW "Data structures and interface definitions". DO NOT CHANGE ANY DESIGN. Make sure your tests respect the existing design and ensure its validity.
|
||||
6. Think before writing: What should be tested and validated in this document? What edge cases could exist? What might fail?
|
||||
7. CAREFULLY CHECK THAT YOU DON'T MISS ANY NECESSARY TEST CASES/SCRIPTS IN THIS FILE.
|
||||
Attention: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD WRITE BEFORE the test case or script and triple quotes.
|
||||
-----
|
||||
## Given the following code, please write appropriate test cases using Python's unittest framework to verify the correctness and robustness of this code:
|
||||
```python
|
||||
{code_to_test}
|
||||
```
|
||||
Note that the code to test is at {source_file_path}, we will put your test code at {workspace}/tests/{test_file_name}, and run your test code from {workspace},
|
||||
you should correctly import the necessary classes based on these file locations!
|
||||
## {test_file_name}: Write test code with triple quoto. Do your best to implement THIS ONLY ONE FILE.
|
||||
"""
|
||||
|
||||
|
||||
class WriteTest(Action):
|
||||
def __init__(self, name="", context=None, llm=None):
|
||||
def __init__(self, name="WriteTest", context=None, llm=None):
|
||||
super().__init__(name, context, llm)
|
||||
self.code = None
|
||||
self.test_prompt_template = """
|
||||
Given the following code or function:
|
||||
{code}
|
||||
|
||||
As a test engineer, please write appropriate test cases using Python's unittest framework to verify the correctness and robustness of this code.
|
||||
"""
|
||||
async def write_code(self, prompt):
|
||||
code_rsp = await self._aask(prompt)
|
||||
code = CodeParser.parse_code(block="", text=code_rsp)
|
||||
return code
|
||||
|
||||
async def run(self, code):
|
||||
self.code = code
|
||||
prompt = self.test_prompt_template.format(code=self.code)
|
||||
test_cases = await self._aask(prompt)
|
||||
return test_cases
|
||||
async def run(self, code_to_test, test_file_name, source_file_path, workspace):
|
||||
prompt = PROMPT_TEMPLATE.format(
|
||||
code_to_test=code_to_test,
|
||||
test_file_name=test_file_name,
|
||||
source_file_path=source_file_path,
|
||||
workspace=workspace,
|
||||
)
|
||||
code = await self.write_code(prompt)
|
||||
return code
|
||||
|
|
|
|||
|
|
@ -4,14 +4,14 @@
|
|||
提供配置,单例
|
||||
"""
|
||||
import os
|
||||
import openai
|
||||
|
||||
import openai
|
||||
import yaml
|
||||
|
||||
from metagpt.const import PROJECT_ROOT
|
||||
from metagpt.logs import logger
|
||||
from metagpt.utils.singleton import Singleton
|
||||
from metagpt.tools import SearchEngineType, WebBrowserEngineType
|
||||
from metagpt.utils.singleton import Singleton
|
||||
|
||||
|
||||
class NotConfiguredException(Exception):
|
||||
|
|
@ -46,7 +46,6 @@ class Config(metaclass=Singleton):
|
|||
self.openai_api_key = self._get("OPENAI_API_KEY")
|
||||
if not self.openai_api_key or "YOUR_API_KEY" == self.openai_api_key:
|
||||
raise NotConfiguredException("Set OPENAI_API_KEY first")
|
||||
|
||||
self.openai_api_base = self._get("OPENAI_API_BASE")
|
||||
openai_proxy = self._get("OPENAI_PROXY") or self.global_proxy
|
||||
if openai_proxy:
|
||||
|
|
@ -65,22 +64,22 @@ class Config(metaclass=Singleton):
|
|||
self.google_api_key = self._get("GOOGLE_API_KEY")
|
||||
self.google_cse_id = self._get("GOOGLE_CSE_ID")
|
||||
self.search_engine = self._get("SEARCH_ENGINE", SearchEngineType.SERPAPI_GOOGLE)
|
||||
|
||||
|
||||
self.web_browser_engine = WebBrowserEngineType(self._get("WEB_BROWSER_ENGINE", "playwright"))
|
||||
self.playwright_browser_type = self._get("PLAYWRIGHT_BROWSER_TYPE", "chromium")
|
||||
self.selenium_browser_type = self._get("SELENIUM_BROWSER_TYPE", "chrome")
|
||||
|
||||
|
||||
self.long_term_memory = self._get('LONG_TERM_MEMORY', False)
|
||||
if self.long_term_memory:
|
||||
logger.warning("LONG_TERM_MEMORY is True")
|
||||
self.max_budget = self._get("MAX_BUDGET", 10.0)
|
||||
self.total_cost = 0.0
|
||||
self.puppeteer_config = self._get("PUPPETEER_CONFIG","")
|
||||
self.mmdc = self._get("MMDC","mmdc")
|
||||
self.update_costs = self._get("UPDATE_COSTS",True)
|
||||
self.calc_usage = self._get("CALC_USAGE",True)
|
||||
|
||||
|
||||
self.puppeteer_config = self._get("PUPPETEER_CONFIG", "")
|
||||
self.mmdc = self._get("MMDC", "mmdc")
|
||||
self.update_costs = self._get("UPDATE_COSTS", True)
|
||||
self.calc_usage = self._get("CALC_USAGE", True)
|
||||
self.model_for_researcher_summary = self._get("MODEL_FOR_RESEARCHER_SUMMARY")
|
||||
self.model_for_researcher_report = self._get("MODEL_FOR_RESEARCHER_REPORT")
|
||||
|
||||
def _init_with_config_files_and_env(self, configs: dict, yaml_file):
|
||||
"""从config/key.yaml / config/config.yaml / env三处按优先级递减加载"""
|
||||
|
|
|
|||
|
|
@ -32,5 +32,6 @@ UT_PY_PATH = UT_PATH / "files/ut/"
|
|||
API_QUESTIONS_PATH = UT_PATH / "files/question/"
|
||||
YAPI_URL = "http://yapi.deepwisdomai.com/"
|
||||
TMP = PROJECT_ROOT / 'tmp'
|
||||
RESEARCH_PATH = DATA_PATH / "research"
|
||||
|
||||
MEM_TTL = 24 * 30 * 3600
|
||||
|
|
|
|||
|
|
@ -7,3 +7,5 @@
|
|||
"""
|
||||
|
||||
from metagpt.document_store.faiss_store import FaissStore
|
||||
|
||||
__all__ = ["FaissStore"]
|
||||
|
|
|
|||
|
|
@ -16,7 +16,10 @@ from metagpt.schema import Message
|
|||
|
||||
|
||||
class Environment(BaseModel):
|
||||
"""环境,承载一批角色,角色可以向环境发布消息,可以被其他角色观察到"""
|
||||
"""环境,承载一批角色,角色可以向环境发布消息,可以被其他角色观察到
|
||||
Environment, hosting a batch of roles, roles can publish messages to the environment, and can be observed by other roles
|
||||
|
||||
"""
|
||||
|
||||
roles: dict[str, Role] = Field(default_factory=dict)
|
||||
memory: Memory = Field(default_factory=Memory)
|
||||
|
|
@ -26,23 +29,31 @@ class Environment(BaseModel):
|
|||
arbitrary_types_allowed = True
|
||||
|
||||
def add_role(self, role: Role):
|
||||
"""增加一个在当前环境的Role"""
|
||||
"""增加一个在当前环境的角色
|
||||
Add a role in the current environment
|
||||
"""
|
||||
role.set_env(self)
|
||||
self.roles[role.profile] = role
|
||||
|
||||
def add_roles(self, roles: Iterable[Role]):
|
||||
"""增加一批在当前环境的Role"""
|
||||
"""增加一批在当前环境的角色
|
||||
Add a batch of characters in the current environment
|
||||
"""
|
||||
for role in roles:
|
||||
self.add_role(role)
|
||||
|
||||
def publish_message(self, message: Message):
|
||||
"""向当前环境发布信息"""
|
||||
"""向当前环境发布信息
|
||||
Post information to the current environment
|
||||
"""
|
||||
# self.message_queue.put(message)
|
||||
self.memory.add(message)
|
||||
self.history += f"\n{message}"
|
||||
|
||||
async def run(self, k=1):
|
||||
"""处理一次所有Role的运行"""
|
||||
"""处理一次所有信息的运行
|
||||
Process all Role runs at once
|
||||
"""
|
||||
# while not self.message_queue.empty():
|
||||
# message = self.message_queue.get()
|
||||
# rsp = await self.manager.handle(message, self)
|
||||
|
|
@ -56,9 +67,13 @@ class Environment(BaseModel):
|
|||
await asyncio.gather(*futures)
|
||||
|
||||
def get_roles(self) -> dict[str, Role]:
|
||||
"""获得环境内的所有Role"""
|
||||
"""获得环境内的所有角色
|
||||
Process all Role runs at once
|
||||
"""
|
||||
return self.roles
|
||||
|
||||
def get_role(self, name: str) -> Role:
|
||||
"""获得环境内的指定Role"""
|
||||
"""获得环境内的指定角色
|
||||
get all the environment roles
|
||||
"""
|
||||
return self.roles.get(name, None)
|
||||
|
|
|
|||
|
|
@ -14,5 +14,7 @@ CLAUDE_LLM = Claude()
|
|||
|
||||
|
||||
async def ai_func(prompt):
|
||||
"""使用LLM进行QA"""
|
||||
"""使用LLM进行QA
|
||||
QA with LLMs
|
||||
"""
|
||||
return await DEFAULT_LLM.aask(prompt)
|
||||
|
|
|
|||
|
|
@ -14,7 +14,9 @@ from metagpt.const import PROJECT_ROOT
|
|||
|
||||
|
||||
def define_log_level(print_level="INFO", logfile_level="DEBUG"):
|
||||
"""调整日志级别到level之上"""
|
||||
"""调整日志级别到level之上
|
||||
Adjust the log level to above level
|
||||
"""
|
||||
_logger.remove()
|
||||
_logger.add(sys.stderr, level=print_level)
|
||||
_logger.add(PROJECT_ROOT / 'logs/log.txt', level=logfile_level)
|
||||
|
|
|
|||
|
|
@ -33,6 +33,7 @@ class Manager:
|
|||
async def handle(self, message: Message, environment):
|
||||
"""
|
||||
管理员处理信息,现在简单的将信息递交给下一个人
|
||||
The administrator processes the information, now simply passes the information on to the next person
|
||||
:param message:
|
||||
:param environment:
|
||||
:return:
|
||||
|
|
@ -50,6 +51,7 @@ class Manager:
|
|||
# chosen_role_name = self.llm.ask(self.prompt_template.format(context))
|
||||
|
||||
# FIXME: 现在通过简单的字典决定流向,但之后还是应该有思考过程
|
||||
#The direction of flow is now determined by a simple dictionary, but there should still be a thought process afterwards
|
||||
next_role_profile = self.role_directions[message.role]
|
||||
# logger.debug(f"{next_role_profile}")
|
||||
for _, role in roles.items():
|
||||
|
|
|
|||
|
|
@ -9,3 +9,8 @@
|
|||
from metagpt.memory.memory import Memory
|
||||
from metagpt.memory.longterm_memory import LongTermMemory
|
||||
|
||||
|
||||
__all__ = [
|
||||
"Memory",
|
||||
"LongTermMemory",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -2,12 +2,10 @@
|
|||
# -*- coding: utf-8 -*-
|
||||
# @Desc : the implement of Long-term memory
|
||||
|
||||
from typing import Iterable, Type
|
||||
|
||||
from metagpt.logs import logger
|
||||
from metagpt.schema import Message
|
||||
from metagpt.memory import Memory
|
||||
from metagpt.memory.memory_storage import MemoryStorage
|
||||
from metagpt.schema import Message
|
||||
|
||||
|
||||
class LongTermMemory(Memory):
|
||||
|
|
@ -27,10 +25,11 @@ class LongTermMemory(Memory):
|
|||
messages = self.memory_storage.recover_memory(role_id)
|
||||
self.rc = rc
|
||||
if not self.memory_storage.is_initialized:
|
||||
logger.warning(f'It may the first time to run Agent {role_id}, the long-term memory is empty')
|
||||
logger.warning(f"It may the first time to run Agent {role_id}, the long-term memory is empty")
|
||||
else:
|
||||
logger.warning(f'Agent {role_id} has existed memory storage with {len(messages)} messages '
|
||||
f'and has recovered them.')
|
||||
logger.warning(
|
||||
f"Agent {role_id} has existed memory storage with {len(messages)} messages " f"and has recovered them."
|
||||
)
|
||||
self.msg_from_recover = True
|
||||
self.add_batch(messages)
|
||||
self.msg_from_recover = False
|
||||
|
|
@ -43,13 +42,13 @@ class LongTermMemory(Memory):
|
|||
# and ignore adding messages from recover repeatedly
|
||||
self.memory_storage.add(message)
|
||||
|
||||
def remember(self, observed: list[Message], k=10) -> list[Message]:
|
||||
def remember(self, observed: list[Message], k=0) -> list[Message]:
|
||||
"""
|
||||
remember the most similar k memories from observed Messages, return all when k=0
|
||||
1. remember the short-term memory(stm) news
|
||||
2. integrate the stm news with ltm(long-term memory) news
|
||||
"""
|
||||
stm_news = super(LongTermMemory, self).remember(observed) # shot-term memory news
|
||||
stm_news = super(LongTermMemory, self).remember(observed, k=k) # shot-term memory news
|
||||
if not self.memory_storage.is_initialized:
|
||||
# memory_storage hasn't initialized, use default `remember` to get stm_news
|
||||
return stm_news
|
||||
|
|
|
|||
|
|
@ -63,7 +63,7 @@ class Memory:
|
|||
"""Return the most recent k memories, return all when k=0"""
|
||||
return self.storage[-k:]
|
||||
|
||||
def remember(self, observed: list[Message], k=10) -> list[Message]:
|
||||
def remember(self, observed: list[Message], k=0) -> list[Message]:
|
||||
"""remember the most recent k memories from observed Messages, return all when k=0"""
|
||||
already_observed = self.get(k)
|
||||
news: list[Message] = []
|
||||
|
|
|
|||
|
|
@ -7,3 +7,6 @@
|
|||
"""
|
||||
|
||||
from metagpt.provider.openai_api import OpenAIGPTAPI
|
||||
|
||||
|
||||
__all__ = ["OpenAIGPTAPI"]
|
||||
|
|
|
|||
|
|
@ -1,4 +1,3 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
@Time : 2023/5/5 23:08
|
||||
|
|
@ -7,10 +6,11 @@
|
|||
"""
|
||||
import asyncio
|
||||
import time
|
||||
from functools import wraps
|
||||
from typing import NamedTuple
|
||||
|
||||
import openai
|
||||
from openai.error import APIConnectionError
|
||||
from tenacity import retry, stop_after_attempt, after_log, wait_fixed, retry_if_exception_type
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.logs import logger
|
||||
|
|
@ -20,33 +20,22 @@ from metagpt.utils.token_counter import (
|
|||
TOKEN_COSTS,
|
||||
count_message_tokens,
|
||||
count_string_tokens,
|
||||
get_max_completion_tokens,
|
||||
)
|
||||
|
||||
|
||||
def retry(max_retries):
|
||||
def decorator(f):
|
||||
@wraps(f)
|
||||
async def wrapper(*args, **kwargs):
|
||||
for i in range(max_retries):
|
||||
try:
|
||||
return await f(*args, **kwargs)
|
||||
except Exception:
|
||||
if i == max_retries - 1:
|
||||
raise
|
||||
await asyncio.sleep(2 ** i)
|
||||
return wrapper
|
||||
return decorator
|
||||
|
||||
|
||||
class RateLimiter:
|
||||
"""Rate control class, each call goes through wait_if_needed, sleep if rate control is needed"""
|
||||
|
||||
def __init__(self, rpm):
|
||||
self.last_call_time = 0
|
||||
self.interval = 1.1 * 60 / rpm # Here 1.1 is used because even if the calls are made strictly according to time, they will still be QOS'd; consider switching to simple error retry later
|
||||
# Here 1.1 is used because even if the calls are made strictly according to time,
|
||||
# they will still be QOS'd; consider switching to simple error retry later
|
||||
self.interval = 1.1 * 60 / rpm
|
||||
self.rpm = rpm
|
||||
|
||||
def split_batches(self, batch):
|
||||
return [batch[i:i + self.rpm] for i in range(0, len(batch), self.rpm)]
|
||||
return [batch[i : i + self.rpm] for i in range(0, len(batch), self.rpm)]
|
||||
|
||||
async def wait_if_needed(self, num_requests):
|
||||
current_time = time.time()
|
||||
|
|
@ -69,6 +58,7 @@ class Costs(NamedTuple):
|
|||
|
||||
class CostManager(metaclass=Singleton):
|
||||
"""计算使用接口的开销"""
|
||||
|
||||
def __init__(self):
|
||||
self.total_prompt_tokens = 0
|
||||
self.total_completion_tokens = 0
|
||||
|
|
@ -86,13 +76,12 @@ class CostManager(metaclass=Singleton):
|
|||
"""
|
||||
self.total_prompt_tokens += prompt_tokens
|
||||
self.total_completion_tokens += completion_tokens
|
||||
cost = (
|
||||
prompt_tokens * TOKEN_COSTS[model]["prompt"]
|
||||
+ completion_tokens * TOKEN_COSTS[model]["completion"]
|
||||
) / 1000
|
||||
cost = (prompt_tokens * TOKEN_COSTS[model]["prompt"] + completion_tokens * TOKEN_COSTS[model]["completion"]) / 1000
|
||||
self.total_cost += cost
|
||||
logger.info(f"Total running cost: ${self.total_cost:.3f} | Max budget: ${CONFIG.max_budget:.3f} | "
|
||||
f"Current cost: ${cost:.3f}, {prompt_tokens=}, {completion_tokens=}")
|
||||
logger.info(
|
||||
f"Total running cost: ${self.total_cost:.3f} | Max budget: ${CONFIG.max_budget:.3f} | "
|
||||
f"Current cost: ${cost:.3f}, prompt_tokens: {prompt_tokens}, completion_tokens: {completion_tokens}"
|
||||
)
|
||||
CONFIG.total_cost = self.total_cost
|
||||
|
||||
def get_total_prompt_tokens(self):
|
||||
|
|
@ -127,14 +116,25 @@ class CostManager(metaclass=Singleton):
|
|||
return Costs(self.total_prompt_tokens, self.total_completion_tokens, self.total_cost, self.total_budget)
|
||||
|
||||
|
||||
def log_and_reraise(retry_state):
|
||||
logger.error(f"Retry attempts exhausted. Last exception: {retry_state.outcome.exception()}")
|
||||
logger.warning("""
|
||||
Recommend going to https://deepwisdom.feishu.cn/wiki/MsGnwQBjiif9c3koSJNcYaoSnu4#part-XdatdVlhEojeAfxaaEZcMV3ZniQ
|
||||
See FAQ 5.8
|
||||
""")
|
||||
raise retry_state.outcome.exception()
|
||||
|
||||
|
||||
class OpenAIGPTAPI(BaseGPTAPI, RateLimiter):
|
||||
"""
|
||||
Check https://platform.openai.com/examples for examples
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.__init_openai(CONFIG)
|
||||
self.llm = openai
|
||||
self.model = CONFIG.openai_api_model
|
||||
self.auto_max_tokens = False
|
||||
self._cost_manager = CostManager()
|
||||
RateLimiter.__init__(self, rpm=self.rpm)
|
||||
|
||||
|
|
@ -148,10 +148,7 @@ class OpenAIGPTAPI(BaseGPTAPI, RateLimiter):
|
|||
self.rpm = int(config.get("RPM", 10))
|
||||
|
||||
async def _achat_completion_stream(self, messages: list[dict]) -> str:
|
||||
response = await openai.ChatCompletion.acreate(
|
||||
**self._cons_kwargs(messages),
|
||||
stream=True
|
||||
)
|
||||
response = await openai.ChatCompletion.acreate(**self._cons_kwargs(messages), stream=True)
|
||||
|
||||
# create variables to collect the stream of chunks
|
||||
collected_chunks = []
|
||||
|
|
@ -159,41 +156,42 @@ class OpenAIGPTAPI(BaseGPTAPI, RateLimiter):
|
|||
# iterate through the stream of events
|
||||
async for chunk in response:
|
||||
collected_chunks.append(chunk) # save the event response
|
||||
chunk_message = chunk['choices'][0]['delta'] # extract the message
|
||||
chunk_message = chunk["choices"][0]["delta"] # extract the message
|
||||
collected_messages.append(chunk_message) # save the message
|
||||
if "content" in chunk_message:
|
||||
print(chunk_message["content"], end="")
|
||||
print()
|
||||
|
||||
full_reply_content = ''.join([m.get('content', '') for m in collected_messages])
|
||||
full_reply_content = "".join([m.get("content", "") for m in collected_messages])
|
||||
usage = self._calc_usage(messages, full_reply_content)
|
||||
self._update_costs(usage)
|
||||
return full_reply_content
|
||||
|
||||
def _cons_kwargs(self, messages: list[dict]) -> dict:
|
||||
if CONFIG.openai_api_type == 'azure':
|
||||
if CONFIG.openai_api_type == "azure":
|
||||
kwargs = {
|
||||
"deployment_id": CONFIG.deployment_id,
|
||||
"messages": messages,
|
||||
"max_tokens": CONFIG.max_tokens_rsp,
|
||||
"max_tokens": self.get_max_tokens(messages),
|
||||
"n": 1,
|
||||
"stop": None,
|
||||
"temperature": 0.3
|
||||
"temperature": 0.3,
|
||||
}
|
||||
else:
|
||||
kwargs = {
|
||||
"model": self.model,
|
||||
"messages": messages,
|
||||
"max_tokens": CONFIG.max_tokens_rsp,
|
||||
"max_tokens": self.get_max_tokens(messages),
|
||||
"n": 1,
|
||||
"stop": None,
|
||||
"temperature": 0.3
|
||||
"temperature": 0.3,
|
||||
}
|
||||
kwargs["timeout"] = 3
|
||||
return kwargs
|
||||
|
||||
async def _achat_completion(self, messages: list[dict]) -> dict:
|
||||
rsp = await self.llm.ChatCompletion.acreate(**self._cons_kwargs(messages))
|
||||
self._update_costs(rsp.get('usage'))
|
||||
self._update_costs(rsp.get("usage"))
|
||||
return rsp
|
||||
|
||||
def _chat_completion(self, messages: list[dict]) -> dict:
|
||||
|
|
@ -211,7 +209,13 @@ class OpenAIGPTAPI(BaseGPTAPI, RateLimiter):
|
|||
# messages = self.messages_to_dict(messages)
|
||||
return await self._achat_completion(messages)
|
||||
|
||||
@retry(max_retries=6)
|
||||
@retry(
|
||||
stop=stop_after_attempt(3),
|
||||
wait=wait_fixed(1),
|
||||
after=after_log(logger, logger.level('WARNING').name),
|
||||
retry=retry_if_exception_type(APIConnectionError),
|
||||
retry_error_callback=log_and_reraise,
|
||||
)
|
||||
async def acompletion_text(self, messages: list[dict], stream=False) -> str:
|
||||
"""when streaming, print each token in place."""
|
||||
if stream:
|
||||
|
|
@ -262,3 +266,8 @@ class OpenAIGPTAPI(BaseGPTAPI, RateLimiter):
|
|||
|
||||
def get_costs(self) -> Costs:
|
||||
return self._cost_manager.get_costs()
|
||||
|
||||
def get_max_tokens(self, messages: list[dict]):
|
||||
if not self.auto_max_tokens:
|
||||
return CONFIG.max_tokens_rsp
|
||||
return get_max_completion_tokens(messages, self.model, CONFIG.max_tokens_rsp)
|
||||
|
|
|
|||
|
|
@ -8,10 +8,21 @@
|
|||
|
||||
from metagpt.roles.role import Role
|
||||
from metagpt.roles.architect import Architect
|
||||
from metagpt.roles.product_manager import ProductManager
|
||||
from metagpt.roles.project_manager import ProjectManager
|
||||
from metagpt.roles.engineer import Engineer
|
||||
from metagpt.roles.qa_engineer import QaEngineer
|
||||
from metagpt.roles.seacher import Searcher
|
||||
from metagpt.roles.sales import Sales
|
||||
from metagpt.roles.customer_service import CustomerService
|
||||
|
||||
|
||||
__all__ = [
|
||||
"Role",
|
||||
"Architect",
|
||||
"ProjectManager",
|
||||
"Engineer",
|
||||
"QaEngineer",
|
||||
"Searcher",
|
||||
"Sales",
|
||||
"CustomerService",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -16,6 +16,7 @@ from metagpt.roles import Role
|
|||
from metagpt.actions import WriteCode, WriteCodeReview, WriteTasks, WriteDesign
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.common import CodeParser
|
||||
from metagpt.utils.special_tokens import MSG_SEP, FILENAME_CODE_SEP
|
||||
|
||||
|
||||
async def gather_ordered_k(coros, k) -> list:
|
||||
|
|
@ -71,7 +72,7 @@ class Engineer(Role):
|
|||
@classmethod
|
||||
def parse_workspace(cls, system_design_msg: Message) -> str:
|
||||
if system_design_msg.instruct_content:
|
||||
return system_design_msg.instruct_content.dict().get("Python package name")
|
||||
return system_design_msg.instruct_content.dict().get("Python package name").strip().strip("'").strip("\"")
|
||||
return CodeParser.parse_str(block="Python package name", text=system_design_msg.content)
|
||||
|
||||
def get_workspace(self) -> Path:
|
||||
|
|
@ -92,9 +93,11 @@ class Engineer(Role):
|
|||
|
||||
def write_file(self, filename: str, code: str):
|
||||
workspace = self.get_workspace()
|
||||
filename = filename.replace('"', '').replace('\n', '')
|
||||
file = workspace / filename
|
||||
file.parent.mkdir(parents=True, exist_ok=True)
|
||||
file.write_text(code)
|
||||
return file
|
||||
|
||||
def recv(self, message: Message) -> None:
|
||||
self._rc.memory.add(message)
|
||||
|
|
@ -126,23 +129,33 @@ class Engineer(Role):
|
|||
return msg
|
||||
|
||||
async def _act_sp(self) -> Message:
|
||||
code_msg_all = [] # gather all code info, will pass to qa_engineer for tests later
|
||||
for todo in self.todos:
|
||||
code_rsp = await WriteCode().run(
|
||||
code = await WriteCode().run(
|
||||
context=self._rc.history,
|
||||
filename=todo
|
||||
)
|
||||
# logger.info(todo)
|
||||
# logger.info(code_rsp)
|
||||
# code = self.parse_code(code_rsp)
|
||||
self.write_file(todo, code_rsp)
|
||||
msg = Message(content=code_rsp, role=self.profile, cause_by=type(self._rc.todo))
|
||||
file_path = self.write_file(todo, code)
|
||||
msg = Message(content=code, role=self.profile, cause_by=type(self._rc.todo))
|
||||
self._rc.memory.add(msg)
|
||||
|
||||
code_msg = todo + FILENAME_CODE_SEP + str(file_path)
|
||||
code_msg_all.append(code_msg)
|
||||
|
||||
logger.info(f'Done {self.get_workspace()} generating.')
|
||||
msg = Message(content="all done.", role=self.profile, cause_by=type(self._rc.todo))
|
||||
msg = Message(
|
||||
content=MSG_SEP.join(code_msg_all),
|
||||
role=self.profile,
|
||||
cause_by=type(self._rc.todo),
|
||||
send_to="QaEngineer"
|
||||
)
|
||||
return msg
|
||||
|
||||
async def _act_sp_precision(self) -> Message:
|
||||
code_msg_all = [] # gather all code info, will pass to qa_engineer for tests later
|
||||
for todo in self.todos:
|
||||
"""
|
||||
# 从历史信息中挑选必须的信息,以减少prompt长度(人工经验总结)
|
||||
|
|
@ -173,12 +186,20 @@ class Engineer(Role):
|
|||
except Exception as e:
|
||||
logger.error("code review failed!", e)
|
||||
pass
|
||||
self.write_file(todo, code)
|
||||
file_path = self.write_file(todo, code)
|
||||
msg = Message(content=code, role=self.profile, cause_by=WriteCode)
|
||||
self._rc.memory.add(msg)
|
||||
|
||||
code_msg = todo + FILENAME_CODE_SEP + str(file_path)
|
||||
code_msg_all.append(code_msg)
|
||||
|
||||
logger.info(f'Done {self.get_workspace()} generating.')
|
||||
msg = Message(content="all done.", role=self.profile, cause_by=WriteCode)
|
||||
msg = Message(
|
||||
content=MSG_SEP.join(code_msg_all),
|
||||
role=self.profile,
|
||||
cause_by=type(self._rc.todo),
|
||||
send_to="QaEngineer"
|
||||
)
|
||||
return msg
|
||||
|
||||
async def _act(self) -> Message:
|
||||
|
|
|
|||
|
|
@ -5,11 +5,175 @@
|
|||
@Author : alexanderwu
|
||||
@File : qa_engineer.py
|
||||
"""
|
||||
from metagpt.actions import WriteTest
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
from metagpt.actions import DebugError, RunCode, WriteCode, WriteDesign, WriteTest
|
||||
from metagpt.const import WORKSPACE_ROOT
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles import Role
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.common import CodeParser, parse_recipient
|
||||
from metagpt.utils.special_tokens import FILENAME_CODE_SEP, MSG_SEP
|
||||
|
||||
|
||||
class QaEngineer(Role):
|
||||
def __init__(self, name, profile, goal, constraints):
|
||||
def __init__(
|
||||
self,
|
||||
name="Edward",
|
||||
profile="QaEngineer",
|
||||
goal="Write comprehensive and robust tests to ensure codes will work as expected without bugs",
|
||||
constraints="The test code you write should conform to code standard like PEP8, be modular, easy to read and maintain",
|
||||
test_round_allowed=5,
|
||||
):
|
||||
super().__init__(name, profile, goal, constraints)
|
||||
self._init_actions([WriteTest])
|
||||
self._init_actions(
|
||||
[WriteTest]
|
||||
) # FIXME: a bit hack here, only init one action to circumvent _think() logic, will overwrite _think() in future updates
|
||||
self._watch([WriteCode, WriteTest, RunCode, DebugError])
|
||||
self.test_round = 0
|
||||
self.test_round_allowed = test_round_allowed
|
||||
|
||||
@classmethod
|
||||
def parse_workspace(cls, system_design_msg: Message) -> str:
|
||||
if not system_design_msg.instruct_content:
|
||||
return system_design_msg.instruct_content.dict().get("Python package name")
|
||||
return CodeParser.parse_str(block="Python package name", text=system_design_msg.content)
|
||||
|
||||
def get_workspace(self, return_proj_dir=True) -> Path:
|
||||
msg = self._rc.memory.get_by_action(WriteDesign)[-1]
|
||||
if not msg:
|
||||
return WORKSPACE_ROOT / "src"
|
||||
workspace = self.parse_workspace(msg)
|
||||
# project directory: workspace/{package_name}, which contains package source code folder, tests folder, resources folder, etc.
|
||||
if return_proj_dir:
|
||||
return WORKSPACE_ROOT / workspace
|
||||
# development codes directory: workspace/{package_name}/{package_name}
|
||||
return WORKSPACE_ROOT / workspace / workspace
|
||||
|
||||
def write_file(self, filename: str, code: str):
|
||||
workspace = self.get_workspace() / "tests"
|
||||
file = workspace / filename
|
||||
file.parent.mkdir(parents=True, exist_ok=True)
|
||||
file.write_text(code)
|
||||
|
||||
async def _write_test(self, message: Message) -> None:
|
||||
code_msgs = message.content.split(MSG_SEP)
|
||||
# result_msg_all = []
|
||||
for code_msg in code_msgs:
|
||||
# write tests
|
||||
file_name, file_path = code_msg.split(FILENAME_CODE_SEP)
|
||||
code_to_test = open(file_path, "r").read()
|
||||
if "test" in file_name:
|
||||
continue # Engineer might write some test files, skip testing a test file
|
||||
test_file_name = "test_" + file_name
|
||||
test_file_path = self.get_workspace() / "tests" / test_file_name
|
||||
logger.info(f"Writing {test_file_name}..")
|
||||
test_code = await WriteTest().run(
|
||||
code_to_test=code_to_test,
|
||||
test_file_name=test_file_name,
|
||||
# source_file_name=file_name,
|
||||
source_file_path=file_path,
|
||||
workspace=self.get_workspace(),
|
||||
)
|
||||
self.write_file(test_file_name, test_code)
|
||||
|
||||
# prepare context for run tests in next round
|
||||
command = ["python", f"tests/{test_file_name}"]
|
||||
file_info = {
|
||||
"file_name": file_name,
|
||||
"file_path": str(file_path),
|
||||
"test_file_name": test_file_name,
|
||||
"test_file_path": str(test_file_path),
|
||||
"command": command,
|
||||
}
|
||||
msg = Message(
|
||||
content=str(file_info),
|
||||
role=self.profile,
|
||||
cause_by=WriteTest,
|
||||
sent_from=self.profile,
|
||||
send_to=self.profile,
|
||||
)
|
||||
self._publish_message(msg)
|
||||
|
||||
logger.info(f"Done {self.get_workspace()}/tests generating.")
|
||||
|
||||
async def _run_code(self, msg):
|
||||
file_info = eval(msg.content)
|
||||
development_file_path = file_info["file_path"]
|
||||
test_file_path = file_info["test_file_path"]
|
||||
if not os.path.exists(development_file_path) or not os.path.exists(test_file_path):
|
||||
return
|
||||
|
||||
development_code = open(development_file_path, "r").read()
|
||||
test_code = open(test_file_path, "r").read()
|
||||
proj_dir = self.get_workspace()
|
||||
development_code_dir = self.get_workspace(return_proj_dir=False)
|
||||
|
||||
result_msg = await RunCode().run(
|
||||
mode="script",
|
||||
code=development_code,
|
||||
code_file_name=file_info["file_name"],
|
||||
test_code=test_code,
|
||||
test_file_name=file_info["test_file_name"],
|
||||
command=file_info["command"],
|
||||
working_directory=proj_dir, # workspace/package_name, will run tests/test_xxx.py here
|
||||
additional_python_paths=[development_code_dir], # workspace/package_name/package_name,
|
||||
# import statement inside package code needs this
|
||||
)
|
||||
|
||||
recipient = parse_recipient(result_msg) # the recipient might be Engineer or myself
|
||||
content = str(file_info) + FILENAME_CODE_SEP + result_msg
|
||||
msg = Message(content=content, role=self.profile, cause_by=RunCode, sent_from=self.profile, send_to=recipient)
|
||||
self._publish_message(msg)
|
||||
|
||||
async def _debug_error(self, msg):
|
||||
file_info, context = msg.content.split(FILENAME_CODE_SEP)
|
||||
file_name, code = await DebugError().run(context)
|
||||
if file_name:
|
||||
self.write_file(file_name, code)
|
||||
recipient = msg.sent_from # send back to the one who ran the code for another run, might be one's self
|
||||
msg = Message(
|
||||
content=file_info, role=self.profile, cause_by=DebugError, sent_from=self.profile, send_to=recipient
|
||||
)
|
||||
self._publish_message(msg)
|
||||
|
||||
async def _observe(self) -> int:
|
||||
await super()._observe()
|
||||
self._rc.news = [
|
||||
msg for msg in self._rc.news if msg.send_to == self.profile
|
||||
] # only relevant msgs count as observed news
|
||||
return len(self._rc.news)
|
||||
|
||||
async def _act(self) -> Message:
|
||||
if self.test_round > self.test_round_allowed:
|
||||
result_msg = Message(
|
||||
content=f"Exceeding {self.test_round_allowed} rounds of tests, skip (writing code counts as a round, too)",
|
||||
role=self.profile,
|
||||
cause_by=WriteTest,
|
||||
sent_from=self.profile,
|
||||
send_to="",
|
||||
)
|
||||
return result_msg
|
||||
|
||||
for msg in self._rc.news:
|
||||
# Decide what to do based on observed msg type, currently defined by human,
|
||||
# might potentially be moved to _think, that is, let the agent decides for itself
|
||||
if msg.cause_by == WriteCode:
|
||||
# engineer wrote a code, time to write a test for it
|
||||
await self._write_test(msg)
|
||||
elif msg.cause_by in [WriteTest, DebugError]:
|
||||
# I wrote or debugged my test code, time to run it
|
||||
await self._run_code(msg)
|
||||
elif msg.cause_by == RunCode:
|
||||
# I ran my test code, time to fix bugs, if any
|
||||
await self._debug_error(msg)
|
||||
self.test_round += 1
|
||||
result_msg = Message(
|
||||
content=f"Round {self.test_round} of tests done",
|
||||
role=self.profile,
|
||||
cause_by=WriteTest,
|
||||
sent_from=self.profile,
|
||||
send_to="",
|
||||
)
|
||||
return result_msg
|
||||
|
|
|
|||
93
metagpt/roles/researcher.py
Normal file
93
metagpt/roles/researcher.py
Normal file
|
|
@ -0,0 +1,93 @@
|
|||
#!/usr/bin/env python
|
||||
|
||||
import asyncio
|
||||
|
||||
from pydantic import BaseModel
|
||||
|
||||
from metagpt.actions import CollectLinks, ConductResearch, WebBrowseAndSummarize
|
||||
from metagpt.actions.research import get_research_system_text
|
||||
from metagpt.const import RESEARCH_PATH
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles import Role
|
||||
from metagpt.schema import Message
|
||||
|
||||
|
||||
class Report(BaseModel):
|
||||
topic: str
|
||||
links: dict[str, list[str]] = None
|
||||
summaries: list[tuple[str, str]] = None
|
||||
content: str = ""
|
||||
|
||||
|
||||
class Researcher(Role):
|
||||
def __init__(
|
||||
self,
|
||||
name: str = "David",
|
||||
profile: str = "Researcher",
|
||||
goal: str = "Gather information and conduct research",
|
||||
constraints: str = "Ensure accuracy and relevance of information",
|
||||
language: str = "en-us",
|
||||
**kwargs,
|
||||
):
|
||||
super().__init__(name, profile, goal, constraints, **kwargs)
|
||||
self._init_actions([CollectLinks(name), WebBrowseAndSummarize(name), ConductResearch(name)])
|
||||
self.language = language
|
||||
if language not in ("en-us", "zh-cn"):
|
||||
logger.warning(f"The language `{language}` has not been tested, it may not work.")
|
||||
|
||||
async def _think(self) -> None:
|
||||
if self._rc.todo is None:
|
||||
self._set_state(0)
|
||||
return
|
||||
|
||||
if self._rc.state + 1 < len(self._states):
|
||||
self._set_state(self._rc.state + 1)
|
||||
else:
|
||||
self._rc.todo = None
|
||||
|
||||
async def _act(self) -> Message:
|
||||
logger.info(f"{self._setting}: ready to {self._rc.todo}")
|
||||
todo = self._rc.todo
|
||||
msg = self._rc.memory.get(k=1)[0]
|
||||
if isinstance(msg.instruct_content, Report):
|
||||
instruct_content = msg.instruct_content
|
||||
topic = instruct_content.topic
|
||||
else:
|
||||
topic = msg.content
|
||||
|
||||
research_system_text = get_research_system_text(topic, self.language)
|
||||
if isinstance(todo, CollectLinks):
|
||||
links = await todo.run(topic, 4, 4)
|
||||
ret = Message("", Report(topic=topic, links=links), role=self.profile, cause_by=type(todo))
|
||||
elif isinstance(todo, WebBrowseAndSummarize):
|
||||
links = instruct_content.links
|
||||
todos = (todo.run(*url, query=query, system_text=research_system_text) for (query, url) in links.items())
|
||||
summaries = await asyncio.gather(*todos)
|
||||
summaries = list((url, summary) for i in summaries for (url, summary) in i.items() if summary)
|
||||
ret = Message("", Report(topic=topic, summaries=summaries), role=self.profile, cause_by=type(todo))
|
||||
else:
|
||||
summaries = instruct_content.summaries
|
||||
summary_text = "\n---\n".join(f"url: {url}\nsummary: {summary}" for (url, summary) in summaries)
|
||||
content = await self._rc.todo.run(topic, summary_text, system_text=research_system_text)
|
||||
ret = Message("", Report(topic=topic, content=content), role=self.profile, cause_by=type(self._rc.todo))
|
||||
self._rc.memory.add(ret)
|
||||
return ret
|
||||
|
||||
async def _react(self) -> Message:
|
||||
while True:
|
||||
await self._think()
|
||||
if self._rc.todo is None:
|
||||
break
|
||||
msg = await self._act()
|
||||
report = msg.instruct_content
|
||||
self.write_report(report.topic, report.content)
|
||||
return msg
|
||||
|
||||
def write_report(self, topic: str, content: str):
|
||||
filepath = RESEARCH_PATH / f"{topic}.md"
|
||||
filepath.write_text(content)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
role = Researcher(language="en-us")
|
||||
asyncio.run(role.run("dataiku vs. datarobot"))
|
||||
|
|
@ -70,6 +70,7 @@ class RoleContext(BaseModel):
|
|||
state: int = Field(default=0)
|
||||
todo: Action = Field(default=None)
|
||||
watch: set[Type[Action]] = Field(default_factory=set)
|
||||
news: list[Type[Message]] = Field(default=[])
|
||||
|
||||
class Config:
|
||||
arbitrary_types_allowed = True
|
||||
|
|
@ -184,15 +185,15 @@ class Role:
|
|||
|
||||
observed = self._rc.env.memory.get_by_actions(self._rc.watch)
|
||||
|
||||
news = self._rc.memory.remember(observed) # remember recent exact or similar memories
|
||||
self._rc.news = self._rc.memory.remember(observed) # remember recent exact or similar memories
|
||||
|
||||
for i in env_msgs:
|
||||
self.recv(i)
|
||||
|
||||
news_text = [f"{i.role}: {i.content[:20]}..." for i in news]
|
||||
news_text = [f"{i.role}: {i.content[:20]}..." for i in self._rc.news]
|
||||
if news_text:
|
||||
logger.debug(f'{self._setting} observed: {news_text}')
|
||||
return len(news)
|
||||
return len(self._rc.news)
|
||||
|
||||
def _publish_message(self, msg):
|
||||
"""如果role归属于env,那么role的消息会向env广播"""
|
||||
|
|
|
|||
|
|
@ -27,6 +27,8 @@ class Message:
|
|||
instruct_content: BaseModel = field(default=None)
|
||||
role: str = field(default='user') # system / user / assistant
|
||||
cause_by: Type["Action"] = field(default="")
|
||||
sent_from: str = field(default="")
|
||||
send_to: str = field(default="")
|
||||
|
||||
def __str__(self):
|
||||
# prefix = '-'.join([self.role, str(self.cause_by)])
|
||||
|
|
@ -44,21 +46,27 @@ class Message:
|
|||
|
||||
@dataclass
|
||||
class UserMessage(Message):
|
||||
"""便于支持OpenAI的消息"""
|
||||
"""便于支持OpenAI的消息
|
||||
Facilitate support for OpenAI messages
|
||||
"""
|
||||
def __init__(self, content: str):
|
||||
super().__init__(content, 'user')
|
||||
|
||||
|
||||
@dataclass
|
||||
class SystemMessage(Message):
|
||||
"""便于支持OpenAI的消息"""
|
||||
"""便于支持OpenAI的消息
|
||||
Facilitate support for OpenAI messages
|
||||
"""
|
||||
def __init__(self, content: str):
|
||||
super().__init__(content, 'system')
|
||||
|
||||
|
||||
@dataclass
|
||||
class AIMessage(Message):
|
||||
"""便于支持OpenAI的消息"""
|
||||
"""便于支持OpenAI的消息
|
||||
Facilitate support for OpenAI messages
|
||||
"""
|
||||
def __init__(self, content: str):
|
||||
super().__init__(content, 'assistant')
|
||||
|
||||
|
|
|
|||
|
|
@ -14,6 +14,7 @@ class SearchEngineType(Enum):
|
|||
SERPAPI_GOOGLE = auto()
|
||||
DIRECT_GOOGLE = auto()
|
||||
SERPER_GOOGLE = auto()
|
||||
DUCK_DUCK_GO = auto()
|
||||
CUSTOM_ENGINE = auto()
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -2,29 +2,27 @@
|
|||
# @Date : 2023/7/19 16:28
|
||||
# @Author : stellahong (stellahong@fuzhi.ai)
|
||||
# @Desc :
|
||||
import os
|
||||
import asyncio
|
||||
import base64
|
||||
import io
|
||||
import json
|
||||
import os
|
||||
from os.path import join
|
||||
from typing import List
|
||||
import json
|
||||
import io
|
||||
import base64
|
||||
|
||||
from aiohttp import ClientSession
|
||||
from PIL import Image, PngImagePlugin
|
||||
|
||||
from metagpt.logs import logger
|
||||
from metagpt.config import Config
|
||||
from metagpt.const import WORKSPACE_ROOT
|
||||
from metagpt.logs import logger
|
||||
|
||||
config = Config()
|
||||
|
||||
payload = {
|
||||
"prompt": "",
|
||||
"negative_prompt": "(easynegative:0.8),black, dark,Low resolution",
|
||||
"override_settings": {
|
||||
"sd_model_checkpoint": "galaxytimemachinesGTM_photoV20"
|
||||
},
|
||||
"override_settings": {"sd_model_checkpoint": "galaxytimemachinesGTM_photoV20"},
|
||||
"seed": -1,
|
||||
"batch_size": 1,
|
||||
"n_iter": 1,
|
||||
|
|
@ -36,21 +34,20 @@ payload = {
|
|||
"tiling": False,
|
||||
"do_not_save_samples": False,
|
||||
"do_not_save_grid": False,
|
||||
'enable_hr': False,
|
||||
'hr_scale': 2,
|
||||
'hr_upscaler': 'Latent',
|
||||
'hr_second_pass_steps': 0,
|
||||
'hr_resize_x': 0,
|
||||
'hr_resize_y': 0,
|
||||
'hr_upscale_to_x': 0,
|
||||
'hr_upscale_to_y': 0,
|
||||
'truncate_x': 0,
|
||||
'truncate_y': 0,
|
||||
'applied_old_hires_behavior_to': None,
|
||||
"enable_hr": False,
|
||||
"hr_scale": 2,
|
||||
"hr_upscaler": "Latent",
|
||||
"hr_second_pass_steps": 0,
|
||||
"hr_resize_x": 0,
|
||||
"hr_resize_y": 0,
|
||||
"hr_upscale_to_x": 0,
|
||||
"hr_upscale_to_y": 0,
|
||||
"truncate_x": 0,
|
||||
"truncate_y": 0,
|
||||
"applied_old_hires_behavior_to": None,
|
||||
"eta": None,
|
||||
|
||||
"sampler_index": "DPM++ SDE Karras",
|
||||
"alwayson_scripts": {}
|
||||
"alwayson_scripts": {},
|
||||
}
|
||||
|
||||
default_negative_prompt = "(easynegative:0.8),black, dark,Low resolution"
|
||||
|
|
@ -60,14 +57,20 @@ class SDEngine:
|
|||
def __init__(self):
|
||||
# Initialize the SDEngine with configuration
|
||||
self.config = Config()
|
||||
self.sd_url = self.config.get('SD_URL')
|
||||
self.sd_url = self.config.get("SD_URL")
|
||||
self.sd_t2i_url = f"{self.sd_url}{self.config.get('SD_T2I_API')}"
|
||||
# Define default payload settings for SD API
|
||||
self.payload = payload
|
||||
logger.info(self.sd_t2i_url)
|
||||
|
||||
def construct_payload(self, prompt, negtive_prompt=default_negative_prompt, width=512, height=512,
|
||||
sd_model="galaxytimemachinesGTM_photoV20"):
|
||||
|
||||
def construct_payload(
|
||||
self,
|
||||
prompt,
|
||||
negtive_prompt=default_negative_prompt,
|
||||
width=512,
|
||||
height=512,
|
||||
sd_model="galaxytimemachinesGTM_photoV20",
|
||||
):
|
||||
# Configure the payload with provided inputs
|
||||
self.payload["prompt"] = prompt
|
||||
self.payload["negtive_prompt"] = negtive_prompt
|
||||
|
|
@ -76,13 +79,13 @@ class SDEngine:
|
|||
self.payload["override_settings"]["sd_model_checkpoint"] = sd_model
|
||||
logger.info(f"call sd payload is {self.payload}")
|
||||
return self.payload
|
||||
|
||||
|
||||
def _save(self, imgs, save_name=""):
|
||||
save_dir = WORKSPACE_ROOT / "resources"/"SD_Output"
|
||||
save_dir = WORKSPACE_ROOT / "resources" / "SD_Output"
|
||||
if not os.path.exists(save_dir):
|
||||
os.makedirs(save_dir, exist_ok=True)
|
||||
batch_decode_base64_to_image(imgs, save_dir, save_name=save_name)
|
||||
|
||||
|
||||
async def run_t2i(self, prompts: List):
|
||||
# Asynchronously run the SD API for multiple prompts
|
||||
session = ClientSession()
|
||||
|
|
@ -90,25 +93,26 @@ class SDEngine:
|
|||
results = await self.run(url=self.sd_t2i_url, payload=payload, session=session)
|
||||
self._save(results, save_name=f"output_{payload_idx}")
|
||||
await session.close()
|
||||
|
||||
|
||||
async def run(self, url, payload, session):
|
||||
# Perform the HTTP POST request to the SD API
|
||||
async with session.post(url, json=payload, timeout=600) as rsp:
|
||||
data = await rsp.read()
|
||||
|
||||
|
||||
rsp_json = json.loads(data)
|
||||
imgs = rsp_json['images']
|
||||
imgs = rsp_json["images"]
|
||||
logger.info(f"callback rsp json is {rsp_json.keys()}")
|
||||
return imgs
|
||||
|
||||
|
||||
async def run_i2i(self):
|
||||
# todo: 添加图生图接口调用
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
async def run_sam(self):
|
||||
# todo:添加SAM接口调用
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
def decode_base64_to_image(img, save_name):
|
||||
image = Image.open(io.BytesIO(base64.b64decode(img.split(",", 1)[0])))
|
||||
pnginfo = PngImagePlugin.PngInfo()
|
||||
|
|
@ -124,12 +128,10 @@ def batch_decode_base64_to_image(imgs, save_dir="", save_name=""):
|
|||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import asyncio
|
||||
|
||||
engine = SDEngine()
|
||||
prompt = "pixel style, game design, a game interface should be minimalistic and intuitive with the score and high score displayed at the top. The snake and its food should be easily distinguishable. The game should have a simple color scheme, with a contrasting color for the snake and its food. Complete interface boundary"
|
||||
|
||||
|
||||
engine.construct_payload(prompt)
|
||||
|
||||
|
||||
event_loop = asyncio.get_event_loop()
|
||||
event_loop.run_until_complete(engine.run_t2i(prompt))
|
||||
|
|
|
|||
|
|
@ -7,122 +7,76 @@
|
|||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
import json
|
||||
import importlib
|
||||
from typing import Callable, Coroutine, Literal, overload
|
||||
|
||||
from metagpt.config import Config
|
||||
from metagpt.logs import logger
|
||||
from metagpt.tools.search_engine_serpapi import SerpAPIWrapper
|
||||
from metagpt.tools.search_engine_serper import SerperWrapper
|
||||
|
||||
config = Config()
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.tools import SearchEngineType
|
||||
|
||||
|
||||
class SearchEngine:
|
||||
"""
|
||||
TODO: 合入Google Search 并进行反代
|
||||
注:这里Google需要挂Proxifier或者类似全局代理
|
||||
- DDG: https://pypi.org/project/duckduckgo-search/
|
||||
- GOOGLE: https://programmablesearchengine.google.com/controlpanel/overview?cx=63f9de531d0e24de9
|
||||
"""
|
||||
def __init__(self, engine=None, run_func=None):
|
||||
self.config = Config()
|
||||
self.run_func = run_func
|
||||
self.engine = engine or self.config.search_engine
|
||||
"""Class representing a search engine.
|
||||
|
||||
@classmethod
|
||||
def run_google(cls, query, max_results=8):
|
||||
# results = ddg(query, max_results=max_results)
|
||||
results = google_official_search(query, num_results=max_results)
|
||||
logger.info(results)
|
||||
return results
|
||||
Args:
|
||||
engine: The search engine type. Defaults to the search engine specified in the config.
|
||||
run_func: The function to run the search. Defaults to None.
|
||||
|
||||
async def run(self, query: str, max_results=8):
|
||||
if self.engine == SearchEngineType.SERPAPI_GOOGLE:
|
||||
api = SerpAPIWrapper()
|
||||
rsp = await api.run(query)
|
||||
elif self.engine == SearchEngineType.DIRECT_GOOGLE:
|
||||
rsp = SearchEngine.run_google(query, max_results)
|
||||
elif self.engine == SearchEngineType.SERPER_GOOGLE:
|
||||
api = SerperWrapper()
|
||||
rsp = await api.run(query)
|
||||
elif self.engine == SearchEngineType.CUSTOM_ENGINE:
|
||||
rsp = self.run_func(query)
|
||||
Attributes:
|
||||
run_func: The function to run the search.
|
||||
engine: The search engine type.
|
||||
"""
|
||||
def __init__(
|
||||
self,
|
||||
engine: SearchEngineType | None = None,
|
||||
run_func: Callable[[str, int, bool], Coroutine[None, None, str | list[str]]] = None,
|
||||
):
|
||||
engine = engine or CONFIG.search_engine
|
||||
if engine == SearchEngineType.SERPAPI_GOOGLE:
|
||||
module = "metagpt.tools.search_engine_serpapi"
|
||||
run_func = importlib.import_module(module).SerpAPIWrapper().run
|
||||
elif engine == SearchEngineType.SERPER_GOOGLE:
|
||||
module = "metagpt.tools.search_engine_serper"
|
||||
run_func = importlib.import_module(module).SerperWrapper().run
|
||||
elif engine == SearchEngineType.DIRECT_GOOGLE:
|
||||
module = "metagpt.tools.search_engine_googleapi"
|
||||
run_func = importlib.import_module(module).GoogleAPIWrapper().run
|
||||
elif engine == SearchEngineType.DUCK_DUCK_GO:
|
||||
module = "metagpt.tools.search_engine_ddg"
|
||||
run_func = importlib.import_module(module).DDGAPIWrapper().run
|
||||
elif engine == SearchEngineType.CUSTOM_ENGINE:
|
||||
pass # run_func = run_func
|
||||
else:
|
||||
raise NotImplementedError
|
||||
return rsp
|
||||
self.engine = engine
|
||||
self.run_func = run_func
|
||||
|
||||
@overload
|
||||
def run(
|
||||
self,
|
||||
query: str,
|
||||
max_results: int = 8,
|
||||
as_string: Literal[True] = True,
|
||||
) -> str:
|
||||
...
|
||||
|
||||
def google_official_search(query: str, num_results: int = 8, focus=['snippet', 'link', 'title']) -> dict | list[dict]:
|
||||
"""Return the results of a Google search using the official Google API
|
||||
@overload
|
||||
def run(
|
||||
self,
|
||||
query: str,
|
||||
max_results: int = 8,
|
||||
as_string: Literal[False] = False,
|
||||
) -> list[dict[str, str]]:
|
||||
...
|
||||
|
||||
Args:
|
||||
query (str): The search query.
|
||||
num_results (int): The number of results to return.
|
||||
async def run(self, query: str, max_results: int = 8, as_string: bool = True) -> str | list[dict[str, str]]:
|
||||
"""Run a search query.
|
||||
|
||||
Returns:
|
||||
str: The results of the search.
|
||||
"""
|
||||
Args:
|
||||
query: The search query.
|
||||
max_results: The maximum number of results to return. Defaults to 8.
|
||||
as_string: Whether to return the results as a string or a list of dictionaries. Defaults to True.
|
||||
|
||||
from googleapiclient.discovery import build
|
||||
from googleapiclient.errors import HttpError
|
||||
|
||||
try:
|
||||
api_key = config.google_api_key
|
||||
custom_search_engine_id = config.google_cse_id
|
||||
|
||||
with build("customsearch", "v1", developerKey=api_key) as service:
|
||||
|
||||
result = (
|
||||
service.cse()
|
||||
.list(q=query, cx=custom_search_engine_id, num=num_results)
|
||||
.execute()
|
||||
)
|
||||
logger.info(result)
|
||||
# Extract the search result items from the response
|
||||
search_results = result.get("items", [])
|
||||
|
||||
# Create a list of only the URLs from the search results
|
||||
search_results_details = [{i: j for i, j in item_dict.items() if i in focus} for item_dict in search_results]
|
||||
|
||||
except HttpError as e:
|
||||
# Handle errors in the API call
|
||||
error_details = json.loads(e.content.decode())
|
||||
|
||||
# Check if the error is related to an invalid or missing API key
|
||||
if error_details.get("error", {}).get(
|
||||
"code"
|
||||
) == 403 and "invalid API key" in error_details.get("error", {}).get(
|
||||
"message", ""
|
||||
):
|
||||
return "Error: The provided Google API key is invalid or missing."
|
||||
else:
|
||||
return f"Error: {e}"
|
||||
# google_result can be a list or a string depending on the search results
|
||||
|
||||
# Return the list of search result URLs
|
||||
return search_results_details
|
||||
|
||||
|
||||
def safe_google_results(results: str | list) -> str:
|
||||
"""
|
||||
Return the results of a google search in a safe format.
|
||||
|
||||
Args:
|
||||
results (str | list): The search results.
|
||||
|
||||
Returns:
|
||||
str: The results of the search.
|
||||
"""
|
||||
if isinstance(results, list):
|
||||
safe_message = json.dumps(
|
||||
# FIXME: # .encode("utf-8", "ignore") 这里去掉了,但是AutoGPT里有,很奇怪
|
||||
[result for result in results]
|
||||
)
|
||||
else:
|
||||
safe_message = results.encode("utf-8", "ignore").decode("utf-8")
|
||||
return safe_message
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
SearchEngine.run(query='wtf')
|
||||
Returns:
|
||||
The search results as a string or a list of dictionaries.
|
||||
"""
|
||||
return await self.run_func(query, max_results=max_results, as_string=as_string)
|
||||
|
|
|
|||
107
metagpt/tools/search_engine_ddg.py
Normal file
107
metagpt/tools/search_engine_ddg.py
Normal file
|
|
@ -0,0 +1,107 @@
|
|||
#!/usr/bin/env python
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import asyncio
|
||||
import json
|
||||
from concurrent import futures
|
||||
from typing import Literal, overload
|
||||
|
||||
from duckduckgo_search import DDGS
|
||||
from googleapiclient.errors import HttpError
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.logs import logger
|
||||
|
||||
|
||||
class DDGAPIWrapper:
|
||||
"""Wrapper around duckduckgo_search API.
|
||||
|
||||
To use this module, you should have the `duckduckgo_search` Python package installed.
|
||||
"""
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
loop: asyncio.AbstractEventLoop | None = None,
|
||||
executor: futures.Executor | None = None,
|
||||
):
|
||||
kwargs = {}
|
||||
if CONFIG.global_proxy:
|
||||
kwargs["proxies"] = CONFIG.global_proxy
|
||||
self.loop = loop
|
||||
self.executor = executor
|
||||
self.ddgs = DDGS(**kwargs)
|
||||
|
||||
@overload
|
||||
def run(
|
||||
self,
|
||||
query: str,
|
||||
max_results: int = 8,
|
||||
as_string: Literal[True] = True,
|
||||
focus: list[str] | None = None,
|
||||
) -> str:
|
||||
...
|
||||
|
||||
@overload
|
||||
def run(
|
||||
self,
|
||||
query: str,
|
||||
max_results: int = 8,
|
||||
as_string: Literal[False] = False,
|
||||
focus: list[str] | None = None,
|
||||
) -> list[dict[str, str]]:
|
||||
...
|
||||
|
||||
async def run(
|
||||
self,
|
||||
query: str,
|
||||
max_results: int = 8,
|
||||
as_string: bool = True,
|
||||
) -> str | list[dict]:
|
||||
"""Return the results of a Google search using the official Google API
|
||||
|
||||
Args:
|
||||
query: The search query.
|
||||
max_results: The number of results to return.
|
||||
as_string: A boolean flag to determine the return type of the results. If True, the function will
|
||||
return a formatted string with the search results. If False, it will return a list of dictionaries
|
||||
containing detailed information about each search result.
|
||||
|
||||
Returns:
|
||||
The results of the search.
|
||||
"""
|
||||
loop = self.loop or asyncio.get_event_loop()
|
||||
future = loop.run_in_executor(
|
||||
self.executor,
|
||||
self._search_from_ddgs,
|
||||
query,
|
||||
max_results,
|
||||
)
|
||||
try:
|
||||
search_results = await future
|
||||
# Extract the search result items from the response
|
||||
|
||||
except HttpError as e:
|
||||
# Handle errors in the API call
|
||||
logger.exception(f"fail to search {query} for {e}")
|
||||
search_results = []
|
||||
|
||||
# Return the list of search result URLs
|
||||
if as_string:
|
||||
return json.dumps(search_results, ensure_ascii=False)
|
||||
return search_results
|
||||
|
||||
def _search_from_ddgs(self, query: str, max_results: int):
|
||||
return [
|
||||
{
|
||||
"link": i["href"],
|
||||
"snippet": i["body"],
|
||||
"title": i["title"]
|
||||
} for (_, i) in zip(range(max_results), self.ddgs.text(query))
|
||||
]
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import fire
|
||||
|
||||
fire.Fire(DDGAPIWrapper().run)
|
||||
117
metagpt/tools/search_engine_googleapi.py
Normal file
117
metagpt/tools/search_engine_googleapi.py
Normal file
|
|
@ -0,0 +1,117 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
from __future__ import annotations
|
||||
|
||||
import asyncio
|
||||
import json
|
||||
from concurrent import futures
|
||||
from urllib.parse import urlparse
|
||||
|
||||
import httplib2
|
||||
from googleapiclient.discovery import build
|
||||
from googleapiclient.errors import HttpError
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.logs import logger
|
||||
|
||||
|
||||
class GoogleAPIWrapper:
|
||||
"""Wrapper around GoogleAPI.
|
||||
|
||||
To use this module, you should have the `google-api-python-client` Python package installed
|
||||
and set property values for the configurations `GOOGLE_API_KEY` and `GOOGLE_CSE_ID`. See
|
||||
https://programmablesearchengine.google.com/controlpanel/all.
|
||||
"""
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
loop: asyncio.AbstractEventLoop | None = None,
|
||||
executor: futures.Executor | None = None,
|
||||
):
|
||||
build_kwargs = {"developerKey": CONFIG.google_api_key}
|
||||
if CONFIG.global_proxy:
|
||||
parse_result = urlparse(CONFIG.global_proxy)
|
||||
proxy_type = parse_result.scheme
|
||||
if proxy_type == "https":
|
||||
proxy_type = "http"
|
||||
build_kwargs["http"] = httplib2.Http(
|
||||
proxy_info=httplib2.ProxyInfo(
|
||||
getattr(httplib2.socks, f"PROXY_TYPE_{proxy_type.upper()}"),
|
||||
parse_result.hostname,
|
||||
parse_result.port,
|
||||
),
|
||||
)
|
||||
service = build("customsearch", "v1", **build_kwargs)
|
||||
self.google_api_client = service.cse()
|
||||
self.custom_search_engine_id = CONFIG.google_cse_id
|
||||
self.loop = loop
|
||||
self.executor = executor
|
||||
|
||||
async def run(
|
||||
self,
|
||||
query: str,
|
||||
max_results: int = 8,
|
||||
as_string: bool = True,
|
||||
focus: list[str] | None = None,
|
||||
) -> str | list[dict]:
|
||||
"""Return the results of a Google search using the official Google API.
|
||||
|
||||
Args:
|
||||
query: The search query.
|
||||
max_results: The number of results to return.
|
||||
as_string: A boolean flag to determine the return type of the results. If True, the function will
|
||||
return a formatted string with the search results. If False, it will return a list of dictionaries
|
||||
containing detailed information about each search result.
|
||||
focus: Specific information to be focused on from each search result.
|
||||
|
||||
Returns:
|
||||
The results of the search.
|
||||
"""
|
||||
loop = self.loop or asyncio.get_event_loop()
|
||||
future = loop.run_in_executor(
|
||||
self.executor,
|
||||
self.google_api_client.list(
|
||||
q=query,
|
||||
num=max_results,
|
||||
cx=self.custom_search_engine_id
|
||||
).execute
|
||||
)
|
||||
try:
|
||||
result = await future
|
||||
# Extract the search result items from the response
|
||||
search_results = result.get("items", [])
|
||||
|
||||
except HttpError as e:
|
||||
# Handle errors in the API call
|
||||
logger.exception(f"fail to search {query} for {e}")
|
||||
search_results = []
|
||||
|
||||
focus = focus or ["snippet", "link", "title"]
|
||||
details = [{i: j for i, j in item_dict.items() if i in focus} for item_dict in search_results]
|
||||
# Return the list of search result URLs
|
||||
if as_string:
|
||||
return safe_google_results(details)
|
||||
|
||||
return details
|
||||
|
||||
|
||||
def safe_google_results(results: str | list) -> str:
|
||||
"""Return the results of a google search in a safe format.
|
||||
|
||||
Args:
|
||||
results: The search results.
|
||||
|
||||
Returns:
|
||||
The results of the search.
|
||||
"""
|
||||
if isinstance(results, list):
|
||||
safe_message = json.dumps([result for result in results])
|
||||
else:
|
||||
safe_message = results.encode("utf-8", "ignore").decode("utf-8")
|
||||
return safe_message
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import fire
|
||||
|
||||
fire.Fire(GoogleAPIWrapper().run)
|
||||
|
|
@ -37,16 +37,17 @@ class SerpAPIWrapper(BaseModel):
|
|||
class Config:
|
||||
arbitrary_types_allowed = True
|
||||
|
||||
async def run(self, query: str, **kwargs: Any) -> str:
|
||||
async def run(self, query: str, max_results: int = 8, as_string: bool = True, **kwargs: Any) -> str:
|
||||
"""Run query through SerpAPI and parse result async."""
|
||||
return self._process_response(await self.results(query))
|
||||
return self._process_response(await self.results(query, max_results), as_string=as_string)
|
||||
|
||||
async def results(self, query: str) -> dict:
|
||||
async def results(self, query: str, max_results: int) -> dict:
|
||||
"""Use aiohttp to run query through SerpAPI and return the results async."""
|
||||
|
||||
def construct_url_and_params() -> Tuple[str, Dict[str, str]]:
|
||||
params = self.get_params(query)
|
||||
params["source"] = "python"
|
||||
params["num"] = max_results
|
||||
if self.serpapi_api_key:
|
||||
params["serp_api_key"] = self.serpapi_api_key
|
||||
params["output"] = "json"
|
||||
|
|
@ -74,10 +75,10 @@ class SerpAPIWrapper(BaseModel):
|
|||
return params
|
||||
|
||||
@staticmethod
|
||||
def _process_response(res: dict) -> str:
|
||||
def _process_response(res: dict, as_string: bool) -> str:
|
||||
"""Process response from SerpAPI."""
|
||||
# logger.debug(res)
|
||||
focus = ['title', 'snippet', 'link']
|
||||
focus = ["title", "snippet", "link"]
|
||||
get_focused = lambda x: {i: j for i, j in x.items() if i in focus}
|
||||
|
||||
if "error" in res.keys():
|
||||
|
|
@ -86,20 +87,11 @@ class SerpAPIWrapper(BaseModel):
|
|||
toret = res["answer_box"]["answer"]
|
||||
elif "answer_box" in res.keys() and "snippet" in res["answer_box"].keys():
|
||||
toret = res["answer_box"]["snippet"]
|
||||
elif (
|
||||
"answer_box" in res.keys()
|
||||
and "snippet_highlighted_words" in res["answer_box"].keys()
|
||||
):
|
||||
elif "answer_box" in res.keys() and "snippet_highlighted_words" in res["answer_box"].keys():
|
||||
toret = res["answer_box"]["snippet_highlighted_words"][0]
|
||||
elif (
|
||||
"sports_results" in res.keys()
|
||||
and "game_spotlight" in res["sports_results"].keys()
|
||||
):
|
||||
elif "sports_results" in res.keys() and "game_spotlight" in res["sports_results"].keys():
|
||||
toret = res["sports_results"]["game_spotlight"]
|
||||
elif (
|
||||
"knowledge_graph" in res.keys()
|
||||
and "description" in res["knowledge_graph"].keys()
|
||||
):
|
||||
elif "knowledge_graph" in res.keys() and "description" in res["knowledge_graph"].keys():
|
||||
toret = res["knowledge_graph"]["description"]
|
||||
elif "snippet" in res["organic_results"][0].keys():
|
||||
toret = res["organic_results"][0]["snippet"]
|
||||
|
|
@ -112,4 +104,10 @@ class SerpAPIWrapper(BaseModel):
|
|||
if res.get("organic_results"):
|
||||
toret_l += [get_focused(i) for i in res.get("organic_results")]
|
||||
|
||||
return str(toret) + '\n' + str(toret_l)
|
||||
return str(toret) + '\n' + str(toret_l) if as_string else toret_l
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import fire
|
||||
|
||||
fire.Fire(SerpAPIWrapper().run)
|
||||
|
|
|
|||
|
|
@ -36,16 +36,19 @@ class SerperWrapper(BaseModel):
|
|||
class Config:
|
||||
arbitrary_types_allowed = True
|
||||
|
||||
async def run(self, query: str, **kwargs: Any) -> str:
|
||||
async def run(self, query: str, max_results: int = 8, as_string: bool = True, **kwargs: Any) -> str:
|
||||
"""Run query through Serper and parse result async."""
|
||||
queries = query.split("\n")
|
||||
return "\n".join([self._process_response(res) for res in await self.results(queries)])
|
||||
if isinstance(query, str):
|
||||
return self._process_response((await self.results([query], max_results))[0], as_string=as_string)
|
||||
else:
|
||||
results = [self._process_response(res, as_string) for res in await self.results(query, max_results)]
|
||||
return "\n".join(results) if as_string else results
|
||||
|
||||
async def results(self, queries: list[str]) -> dict:
|
||||
async def results(self, queries: list[str], max_results: int = 8) -> dict:
|
||||
"""Use aiohttp to run query through Serper and return the results async."""
|
||||
|
||||
def construct_url_and_payload_and_headers() -> Tuple[str, Dict[str, str]]:
|
||||
payloads = self.get_payloads(queries)
|
||||
payloads = self.get_payloads(queries, max_results)
|
||||
url = "https://google.serper.dev/search"
|
||||
headers = self.get_headers()
|
||||
return url, payloads, headers
|
||||
|
|
@ -61,12 +64,13 @@ class SerperWrapper(BaseModel):
|
|||
|
||||
return res
|
||||
|
||||
def get_payloads(self, queries: list[str]) -> Dict[str, str]:
|
||||
def get_payloads(self, queries: list[str], max_results: int) -> Dict[str, str]:
|
||||
"""Get payloads for Serper."""
|
||||
payloads = []
|
||||
for query in queries:
|
||||
_payload = {
|
||||
"q": query,
|
||||
"num": max_results,
|
||||
}
|
||||
payloads.append({**self.payload, **_payload})
|
||||
return json.dumps(payloads, sort_keys=True)
|
||||
|
|
@ -79,7 +83,7 @@ class SerperWrapper(BaseModel):
|
|||
return headers
|
||||
|
||||
@staticmethod
|
||||
def _process_response(res: dict) -> str:
|
||||
def _process_response(res: dict, as_string: bool = False) -> str:
|
||||
"""Process response from SerpAPI."""
|
||||
# logger.debug(res)
|
||||
focus = ['title', 'snippet', 'link']
|
||||
|
|
@ -117,4 +121,10 @@ class SerperWrapper(BaseModel):
|
|||
if res.get("organic"):
|
||||
toret_l += [get_focused(i) for i in res.get("organic")]
|
||||
|
||||
return str(toret) + '\n' + str(toret_l)
|
||||
return str(toret) + '\n' + str(toret_l) if as_string else toret_l
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import fire
|
||||
|
||||
fire.Fire(SerperWrapper().run)
|
||||
|
|
|
|||
|
|
@ -1,22 +1,20 @@
|
|||
#!/usr/bin/env python
|
||||
|
||||
from __future__ import annotations
|
||||
import asyncio
|
||||
import importlib
|
||||
|
||||
from typing import Any, Callable, Coroutine, overload
|
||||
import importlib
|
||||
from typing import Any, Callable, Coroutine, Literal, overload
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.tools import WebBrowserEngineType
|
||||
from bs4 import BeautifulSoup
|
||||
from metagpt.utils.parse_html import WebPage
|
||||
|
||||
|
||||
class WebBrowserEngine:
|
||||
def __init__(
|
||||
self,
|
||||
engine: WebBrowserEngineType | None = None,
|
||||
run_func: Callable[..., Coroutine[Any, Any, str | list[str]]] | None = None,
|
||||
parse_func: Callable[[str], str] | None = None,
|
||||
run_func: Callable[..., Coroutine[Any, Any, WebPage | list[WebPage]]] | None = None,
|
||||
):
|
||||
engine = engine or CONFIG.web_browser_engine
|
||||
|
||||
|
|
@ -30,30 +28,25 @@ class WebBrowserEngine:
|
|||
run_func = run_func
|
||||
else:
|
||||
raise NotImplementedError
|
||||
self.parse_func = parse_func or get_page_content
|
||||
self.run_func = run_func
|
||||
self.engine = engine
|
||||
|
||||
@overload
|
||||
async def run(self, url: str) -> str:
|
||||
async def run(self, url: str) -> WebPage:
|
||||
...
|
||||
|
||||
@overload
|
||||
async def run(self, url: str, *urls: str) -> list[str]:
|
||||
async def run(self, url: str, *urls: str) -> list[WebPage]:
|
||||
...
|
||||
|
||||
async def run(self, url: str, *urls: str) -> str | list[str]:
|
||||
page = await self.run_func(url, *urls)
|
||||
if isinstance(page, str):
|
||||
return self.parse_func(page)
|
||||
return [self.parse_func(i) for i in page]
|
||||
|
||||
|
||||
def get_page_content(page: str):
|
||||
soup = BeautifulSoup(page, "html.parser")
|
||||
return "\n".join(i.text.strip() for i in soup.find_all(["h1", "h2", "h3", "h4", "h5", "p", "pre"]))
|
||||
async def run(self, url: str, *urls: str) -> WebPage | list[WebPage]:
|
||||
return await self.run_func(url, *urls)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
text = asyncio.run(WebBrowserEngine().run("https://fuzhi.ai/"))
|
||||
print(text)
|
||||
import fire
|
||||
|
||||
async def main(url: str, *urls: str, engine_type: Literal["playwright", "selenium"] = "playwright", **kwargs):
|
||||
return await WebBrowserEngine(WebBrowserEngineType(engine_type), **kwargs).run(url, *urls)
|
||||
|
||||
fire.Fire(main)
|
||||
|
|
|
|||
|
|
@ -2,12 +2,15 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import asyncio
|
||||
from pathlib import Path
|
||||
import sys
|
||||
from pathlib import Path
|
||||
from typing import Literal
|
||||
|
||||
from playwright.async_api import async_playwright
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.logs import logger
|
||||
from metagpt.utils.parse_html import WebPage
|
||||
|
||||
|
||||
class PlaywrightWrapper:
|
||||
|
|
@ -16,7 +19,7 @@ class PlaywrightWrapper:
|
|||
To use this module, you should have the `playwright` Python package installed and ensure that
|
||||
the required browsers are also installed. You can install playwright by running the command
|
||||
`pip install metagpt[playwright]` and download the necessary browser binaries by running the
|
||||
command `playwright install` for the first time."
|
||||
command `playwright install` for the first time.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
|
|
@ -40,27 +43,30 @@ class PlaywrightWrapper:
|
|||
self._context_kwargs = context_kwargs
|
||||
self._has_run_precheck = False
|
||||
|
||||
async def run(self, url: str, *urls: str) -> str | list[str]:
|
||||
async def run(self, url: str, *urls: str) -> WebPage | list[WebPage]:
|
||||
async with async_playwright() as ap:
|
||||
browser_type = getattr(ap, self.browser_type)
|
||||
await self._run_precheck(browser_type)
|
||||
browser = await browser_type.launch(**self.launch_kwargs)
|
||||
|
||||
async def _scrape(url):
|
||||
context = await browser.new_context(**self._context_kwargs)
|
||||
page = await context.new_page()
|
||||
async with page:
|
||||
try:
|
||||
await page.goto(url)
|
||||
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
|
||||
content = await page.content()
|
||||
return content
|
||||
except Exception as e:
|
||||
return f"Fail to load page content for {e}"
|
||||
_scrape = self._scrape
|
||||
|
||||
if urls:
|
||||
return await asyncio.gather(_scrape(url), *(_scrape(i) for i in urls))
|
||||
return await _scrape(url)
|
||||
return await asyncio.gather(_scrape(browser, url), *(_scrape(browser, i) for i in urls))
|
||||
return await _scrape(browser, url)
|
||||
|
||||
async def _scrape(self, browser, url):
|
||||
context = await browser.new_context(**self._context_kwargs)
|
||||
page = await context.new_page()
|
||||
async with page:
|
||||
try:
|
||||
await page.goto(url)
|
||||
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
|
||||
html = await page.content()
|
||||
inner_text = await page.evaluate("() => document.body.innerText")
|
||||
except Exception as e:
|
||||
inner_text = f"Fail to load page content for {e}"
|
||||
html = ""
|
||||
return WebPage(inner_text=inner_text, html=html, url=url)
|
||||
|
||||
async def _run_precheck(self, browser_type):
|
||||
if self._has_run_precheck:
|
||||
|
|
@ -72,6 +78,10 @@ class PlaywrightWrapper:
|
|||
if CONFIG.global_proxy:
|
||||
kwargs["env"] = {"ALL_PROXY": CONFIG.global_proxy}
|
||||
await _install_browsers(self.browser_type, **kwargs)
|
||||
|
||||
if self._has_run_precheck:
|
||||
return
|
||||
|
||||
if not executable_path.exists():
|
||||
parts = executable_path.parts
|
||||
available_paths = list(Path(*parts[:-3]).glob(f"{self.browser_type}-*"))
|
||||
|
|
@ -85,25 +95,37 @@ class PlaywrightWrapper:
|
|||
self._has_run_precheck = True
|
||||
|
||||
|
||||
def _get_install_lock():
|
||||
global _install_lock
|
||||
if _install_lock is None:
|
||||
_install_lock = asyncio.Lock()
|
||||
return _install_lock
|
||||
|
||||
|
||||
async def _install_browsers(*browsers, **kwargs) -> None:
|
||||
process = await asyncio.create_subprocess_exec(
|
||||
sys.executable,
|
||||
"-m",
|
||||
"playwright",
|
||||
"install",
|
||||
*browsers,
|
||||
"--with-deps",
|
||||
stdout=asyncio.subprocess.PIPE,
|
||||
stderr=asyncio.subprocess.PIPE,
|
||||
**kwargs,
|
||||
)
|
||||
async with _get_install_lock():
|
||||
browsers = [i for i in browsers if i not in _install_cache]
|
||||
if not browsers:
|
||||
return
|
||||
process = await asyncio.create_subprocess_exec(
|
||||
sys.executable,
|
||||
"-m",
|
||||
"playwright",
|
||||
"install",
|
||||
*browsers,
|
||||
# "--with-deps",
|
||||
stdout=asyncio.subprocess.PIPE,
|
||||
stderr=asyncio.subprocess.PIPE,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
await asyncio.gather(_log_stream(process.stdout, logger.info), _log_stream(process.stderr, logger.warning))
|
||||
await asyncio.gather(_log_stream(process.stdout, logger.info), _log_stream(process.stderr, logger.warning))
|
||||
|
||||
if await process.wait() == 0:
|
||||
logger.info(f"Install browser for playwright successfully.")
|
||||
else:
|
||||
logger.warning(f"Fail to install browser for playwright.")
|
||||
if await process.wait() == 0:
|
||||
logger.info("Install browser for playwright successfully.")
|
||||
else:
|
||||
logger.warning("Fail to install browser for playwright.")
|
||||
_install_cache.update(browsers)
|
||||
|
||||
|
||||
async def _log_stream(sr, log_func):
|
||||
|
|
@ -114,8 +136,14 @@ async def _log_stream(sr, log_func):
|
|||
log_func(f"[playwright install browser]: {line.decode().strip()}")
|
||||
|
||||
|
||||
_install_lock: asyncio.Lock = None
|
||||
_install_cache = set()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
for i in ("chromium", "firefox", "webkit"):
|
||||
text = asyncio.run(PlaywrightWrapper(i).run("https://httpbin.org/ip"))
|
||||
print(text)
|
||||
print(i)
|
||||
import fire
|
||||
|
||||
async def main(url: str, *urls: str, browser_type: str = "chromium", **kwargs):
|
||||
return await PlaywrightWrapper(browser_type, **kwargs).run(url, *urls)
|
||||
|
||||
fire.Fire(main)
|
||||
|
|
|
|||
|
|
@ -2,16 +2,17 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import asyncio
|
||||
from copy import deepcopy
|
||||
import importlib
|
||||
from concurrent import futures
|
||||
from copy import deepcopy
|
||||
from typing import Literal
|
||||
from metagpt.config import CONFIG
|
||||
import asyncio
|
||||
|
||||
from selenium.webdriver.common.by import By
|
||||
from selenium.webdriver.support import expected_conditions as EC
|
||||
from selenium.webdriver.support.wait import WebDriverWait
|
||||
from concurrent import futures
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.utils.parse_html import WebPage
|
||||
|
||||
|
||||
class SeleniumWrapper:
|
||||
|
|
@ -48,7 +49,7 @@ class SeleniumWrapper:
|
|||
self.loop = loop
|
||||
self.executor = executor
|
||||
|
||||
async def run(self, url: str, *urls: str) -> str | list[str]:
|
||||
async def run(self, url: str, *urls: str) -> WebPage | list[WebPage]:
|
||||
await self._run_precheck()
|
||||
|
||||
_scrape = lambda url: self.loop.run_in_executor(self.executor, self._scrape_website, url)
|
||||
|
|
@ -69,9 +70,15 @@ class SeleniumWrapper:
|
|||
|
||||
def _scrape_website(self, url):
|
||||
with self._get_driver() as driver:
|
||||
driver.get(url)
|
||||
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.TAG_NAME, "body")))
|
||||
return driver.page_source
|
||||
try:
|
||||
driver.get(url)
|
||||
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.TAG_NAME, "body")))
|
||||
inner_text = driver.execute_script("return document.body.innerText;")
|
||||
html = driver.page_source
|
||||
except Exception as e:
|
||||
inner_text = f"Fail to load page content for {e}"
|
||||
html = ""
|
||||
return WebPage(inner_text=inner_text, html=html, url=url)
|
||||
|
||||
|
||||
_webdriver_manager_types = {
|
||||
|
|
@ -97,6 +104,7 @@ def _gen_get_driver_func(browser_type, *args, executable_path=None):
|
|||
def _get_driver():
|
||||
options = Options()
|
||||
options.add_argument("--headless")
|
||||
options.add_argument("--enable-javascript")
|
||||
if browser_type == "chrome":
|
||||
options.add_argument("--no-sandbox")
|
||||
for i in args:
|
||||
|
|
@ -107,5 +115,9 @@ def _gen_get_driver_func(browser_type, *args, executable_path=None):
|
|||
|
||||
|
||||
if __name__ == "__main__":
|
||||
text = asyncio.run(SeleniumWrapper("chrome").run("https://fuzhi.ai/"))
|
||||
print(text)
|
||||
import fire
|
||||
|
||||
async def main(url: str, *urls: str, browser_type: str = "chrome", **kwargs):
|
||||
return await SeleniumWrapper(browser_type, **kwargs).run(url, *urls)
|
||||
|
||||
fire.Fire(main)
|
||||
|
|
|
|||
|
|
@ -13,3 +13,12 @@ from metagpt.utils.token_counter import (
|
|||
count_message_tokens,
|
||||
count_string_tokens,
|
||||
)
|
||||
|
||||
|
||||
__all__ = [
|
||||
"read_docx",
|
||||
"Singleton",
|
||||
"TOKEN_COSTS",
|
||||
"count_message_tokens",
|
||||
"count_string_tokens",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -6,6 +6,7 @@
|
|||
@File : common.py
|
||||
"""
|
||||
import ast
|
||||
import contextlib
|
||||
import inspect
|
||||
import os
|
||||
import re
|
||||
|
|
@ -78,6 +79,23 @@ class OutputParser:
|
|||
else:
|
||||
tasks = text.split("\n")
|
||||
return tasks
|
||||
|
||||
@staticmethod
|
||||
def parse_python_code(text: str) -> str:
|
||||
for pattern in (
|
||||
r'(.*?```python.*?\s+)?(?P<code>.*)(```.*?)',
|
||||
r'(.*?```python.*?\s+)?(?P<code>.*)',
|
||||
):
|
||||
match = re.search(pattern, text, re.DOTALL)
|
||||
if not match:
|
||||
continue
|
||||
code = match.group("code")
|
||||
if not code:
|
||||
continue
|
||||
with contextlib.suppress(Exception):
|
||||
ast.parse(code)
|
||||
return code
|
||||
raise ValueError("Invalid python code")
|
||||
|
||||
@classmethod
|
||||
def parse_data(cls, data):
|
||||
|
|
@ -183,7 +201,7 @@ class CodeParser:
|
|||
def parse_file_list(cls, block: str, text: str, lang: str = "") -> list[str]:
|
||||
# Regular expression pattern to find the tasks list.
|
||||
code = cls.parse_code(block, text, lang)
|
||||
print(code)
|
||||
# print(code)
|
||||
pattern = r'\s*(.*=.*)?(\[.*\])'
|
||||
|
||||
# Extract tasks list string using regex.
|
||||
|
|
@ -230,3 +248,9 @@ def print_members(module, indent=0):
|
|||
print(f'{prefix}Function: {name}')
|
||||
elif inspect.ismethod(obj):
|
||||
print(f'{prefix}Method: {name}')
|
||||
|
||||
|
||||
def parse_recipient(text):
|
||||
pattern = r"## Send To:\s*([A-Za-z]+)\s*?" # hard code for now
|
||||
recipient = re.search(pattern, text)
|
||||
return recipient.group(1) if recipient else ""
|
||||
|
|
|
|||
|
|
@ -5,9 +5,9 @@
|
|||
@Author : alexanderwu
|
||||
@File : mermaid.py
|
||||
"""
|
||||
import os
|
||||
import subprocess
|
||||
from pathlib import Path
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.const import PROJECT_ROOT
|
||||
from metagpt.logs import logger
|
||||
|
|
@ -24,25 +24,36 @@ def mermaid_to_file(mermaid_code, output_file_without_suffix, width=2048, height
|
|||
:return: 0 if succed, -1 if failed
|
||||
"""
|
||||
# Write the Mermaid code to a temporary file
|
||||
tmp = Path(f'{output_file_without_suffix}.mmd')
|
||||
tmp.write_text(mermaid_code, encoding='utf-8')
|
||||
tmp = Path(f"{output_file_without_suffix}.mmd")
|
||||
tmp.write_text(mermaid_code, encoding="utf-8")
|
||||
|
||||
if check_cmd_exists('mmdc') != 0:
|
||||
logger.warning(
|
||||
"RUN `npm install -g @mermaid-js/mermaid-cli` to install mmdc")
|
||||
if check_cmd_exists("mmdc") != 0:
|
||||
logger.warning("RUN `npm install -g @mermaid-js/mermaid-cli` to install mmdc")
|
||||
return -1
|
||||
|
||||
for suffix in ['pdf', 'svg', 'png']:
|
||||
output_file = f'{output_file_without_suffix}.{suffix}'
|
||||
for suffix in ["pdf", "svg", "png"]:
|
||||
output_file = f"{output_file_without_suffix}.{suffix}"
|
||||
# Call the `mmdc` command to convert the Mermaid code to a PNG
|
||||
logger.info(f"Generating {output_file}..")
|
||||
|
||||
if CONFIG.puppeteer_config:
|
||||
subprocess.run([CONFIG.mmdc, '-p', CONFIG.puppeteer_config, '-i', str(tmp), '-o',
|
||||
output_file, '-w', str(width), '-H', str(height)])
|
||||
subprocess.run(
|
||||
[
|
||||
CONFIG.mmdc,
|
||||
"-p",
|
||||
CONFIG.puppeteer_config,
|
||||
"-i",
|
||||
str(tmp),
|
||||
"-o",
|
||||
output_file,
|
||||
"-w",
|
||||
str(width),
|
||||
"-H",
|
||||
str(height),
|
||||
]
|
||||
)
|
||||
else:
|
||||
subprocess.run([CONFIG.mmdc, '-i', str(tmp), '-o',
|
||||
output_file, '-w', str(width), '-H', str(height)])
|
||||
subprocess.run([CONFIG.mmdc, "-i", str(tmp), "-o", output_file, "-w", str(width), "-H", str(height)])
|
||||
return 0
|
||||
|
||||
|
||||
|
|
@ -97,7 +108,7 @@ MMC2 = """sequenceDiagram
|
|||
SE-->>M: return summary"""
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
# logger.info(print_members(print_members))
|
||||
mermaid_to_file(MMC1, PROJECT_ROOT / 'tmp/1.png')
|
||||
mermaid_to_file(MMC2, PROJECT_ROOT / 'tmp/2.png')
|
||||
mermaid_to_file(MMC1, PROJECT_ROOT / "tmp/1.png")
|
||||
mermaid_to_file(MMC2, PROJECT_ROOT / "tmp/2.png")
|
||||
|
|
|
|||
57
metagpt/utils/parse_html.py
Normal file
57
metagpt/utils/parse_html.py
Normal file
|
|
@ -0,0 +1,57 @@
|
|||
#!/usr/bin/env python
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Generator, Optional
|
||||
from urllib.parse import urljoin, urlparse
|
||||
|
||||
from bs4 import BeautifulSoup
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
class WebPage(BaseModel):
|
||||
inner_text: str
|
||||
html: str
|
||||
url: str
|
||||
|
||||
class Config:
|
||||
underscore_attrs_are_private = True
|
||||
|
||||
_soup : Optional[BeautifulSoup] = None
|
||||
_title: Optional[str] = None
|
||||
|
||||
@property
|
||||
def soup(self) -> BeautifulSoup:
|
||||
if self._soup is None:
|
||||
self._soup = BeautifulSoup(self.html, "html.parser")
|
||||
return self._soup
|
||||
|
||||
@property
|
||||
def title(self):
|
||||
if self._title is None:
|
||||
title_tag = self.soup.find("title")
|
||||
self._title = title_tag.text.strip() if title_tag is not None else ""
|
||||
return self._title
|
||||
|
||||
def get_links(self) -> Generator[str, None, None]:
|
||||
for i in self.soup.find_all("a", href=True):
|
||||
url = i["href"]
|
||||
result = urlparse(url)
|
||||
if not result.scheme and result.path:
|
||||
yield urljoin(self.url, url)
|
||||
elif url.startswith(("http://", "https://")):
|
||||
yield urljoin(self.url, url)
|
||||
|
||||
|
||||
def get_html_content(page: str, base: str):
|
||||
soup = _get_soup(page)
|
||||
|
||||
return soup.get_text(strip=True)
|
||||
|
||||
|
||||
def _get_soup(page: str):
|
||||
soup = BeautifulSoup(page, "html.parser")
|
||||
# https://stackoverflow.com/questions/1936466/how-to-scrape-only-visible-webpage-text-with-beautifulsoup
|
||||
for s in soup(["style", "script", "[document]", "head", "title"]):
|
||||
s.extract()
|
||||
|
||||
return soup
|
||||
166
metagpt/utils/pycst.py
Normal file
166
metagpt/utils/pycst.py
Normal file
|
|
@ -0,0 +1,166 @@
|
|||
from __future__ import annotations
|
||||
|
||||
from typing import Union
|
||||
|
||||
import libcst as cst
|
||||
from libcst._nodes.module import Module
|
||||
|
||||
DocstringNode = Union[cst.Module, cst.ClassDef, cst.FunctionDef]
|
||||
|
||||
|
||||
def get_docstring_statement(body: DocstringNode) -> cst.SimpleStatementLine:
|
||||
"""Extracts the docstring from the body of a node.
|
||||
|
||||
Args:
|
||||
body: The body of a node.
|
||||
|
||||
Returns:
|
||||
The docstring statement if it exists, None otherwise.
|
||||
"""
|
||||
if isinstance(body, cst.Module):
|
||||
body = body.body
|
||||
else:
|
||||
body = body.body.body
|
||||
|
||||
if not body:
|
||||
return
|
||||
|
||||
statement = body[0]
|
||||
if not isinstance(statement, cst.SimpleStatementLine):
|
||||
return
|
||||
|
||||
expr = statement
|
||||
while isinstance(expr, (cst.BaseSuite, cst.SimpleStatementLine)):
|
||||
if len(expr.body) == 0:
|
||||
return None
|
||||
expr = expr.body[0]
|
||||
|
||||
if not isinstance(expr, cst.Expr):
|
||||
return None
|
||||
|
||||
val = expr.value
|
||||
if not isinstance(val, (cst.SimpleString, cst.ConcatenatedString)):
|
||||
return None
|
||||
|
||||
evaluated_value = val.evaluated_value
|
||||
if isinstance(evaluated_value, bytes):
|
||||
return None
|
||||
|
||||
return statement
|
||||
|
||||
|
||||
class DocstringCollector(cst.CSTVisitor):
|
||||
"""A visitor class for collecting docstrings from a CST.
|
||||
|
||||
Attributes:
|
||||
stack: A list to keep track of the current path in the CST.
|
||||
docstrings: A dictionary mapping paths in the CST to their corresponding docstrings.
|
||||
"""
|
||||
def __init__(self):
|
||||
self.stack: list[str] = []
|
||||
self.docstrings: dict[tuple[str, ...], cst.SimpleStatementLine] = {}
|
||||
|
||||
def visit_Module(self, node: cst.Module) -> bool | None:
|
||||
self.stack.append("")
|
||||
|
||||
def leave_Module(self, node: cst.Module) -> None:
|
||||
return self._leave(node)
|
||||
|
||||
def visit_ClassDef(self, node: cst.ClassDef) -> bool | None:
|
||||
self.stack.append(node.name.value)
|
||||
|
||||
def leave_ClassDef(self, node: cst.ClassDef) -> None:
|
||||
return self._leave(node)
|
||||
|
||||
def visit_FunctionDef(self, node: cst.FunctionDef) -> bool | None:
|
||||
self.stack.append(node.name.value)
|
||||
|
||||
def leave_FunctionDef(self, node: cst.FunctionDef) -> None:
|
||||
return self._leave(node)
|
||||
|
||||
def _leave(self, node: DocstringNode) -> None:
|
||||
key = tuple(self.stack)
|
||||
self.stack.pop()
|
||||
if hasattr(node, "decorators") and any(i.decorator.value == "overload" for i in node.decorators):
|
||||
return
|
||||
|
||||
statement = get_docstring_statement(node)
|
||||
if statement:
|
||||
self.docstrings[key] = statement
|
||||
|
||||
|
||||
class DocstringTransformer(cst.CSTTransformer):
|
||||
"""A transformer class for replacing docstrings in a CST.
|
||||
|
||||
Attributes:
|
||||
stack: A list to keep track of the current path in the CST.
|
||||
docstrings: A dictionary mapping paths in the CST to their corresponding docstrings.
|
||||
"""
|
||||
def __init__(
|
||||
self,
|
||||
docstrings: dict[tuple[str, ...], cst.SimpleStatementLine],
|
||||
):
|
||||
self.stack: list[str] = []
|
||||
self.docstrings = docstrings
|
||||
|
||||
def visit_Module(self, node: cst.Module) -> bool | None:
|
||||
self.stack.append("")
|
||||
|
||||
def leave_Module(self, original_node: Module, updated_node: Module) -> Module:
|
||||
return self._leave(original_node, updated_node)
|
||||
|
||||
def visit_ClassDef(self, node: cst.ClassDef) -> bool | None:
|
||||
self.stack.append(node.name.value)
|
||||
|
||||
def leave_ClassDef(self, original_node: cst.ClassDef, updated_node: cst.ClassDef) -> cst.CSTNode:
|
||||
return self._leave(original_node, updated_node)
|
||||
|
||||
def visit_FunctionDef(self, node: cst.FunctionDef) -> bool | None:
|
||||
self.stack.append(node.name.value)
|
||||
|
||||
def leave_FunctionDef(self, original_node: cst.FunctionDef, updated_node: cst.FunctionDef) -> cst.CSTNode:
|
||||
return self._leave(original_node, updated_node)
|
||||
|
||||
def _leave(self, original_node: DocstringNode, updated_node: DocstringNode) -> DocstringNode:
|
||||
key = tuple(self.stack)
|
||||
self.stack.pop()
|
||||
|
||||
if hasattr(updated_node, "decorators") and any((i.decorator.value == "overload") for i in updated_node.decorators):
|
||||
return updated_node
|
||||
|
||||
statement = self.docstrings.get(key)
|
||||
if not statement:
|
||||
return updated_node
|
||||
|
||||
original_statement = get_docstring_statement(original_node)
|
||||
|
||||
if isinstance(updated_node, cst.Module):
|
||||
body = updated_node.body
|
||||
if original_statement:
|
||||
return updated_node.with_changes(body=(statement, *body[1:]))
|
||||
else:
|
||||
updated_node = updated_node.with_changes(body=(statement, cst.EmptyLine(), *body))
|
||||
return updated_node
|
||||
|
||||
body = updated_node.body.body[1:] if original_statement else updated_node.body.body
|
||||
return updated_node.with_changes(body=updated_node.body.with_changes(body=(statement, *body)))
|
||||
|
||||
|
||||
def merge_docstring(code: str, documented_code: str) -> str:
|
||||
"""Merges the docstrings from the documented code into the original code.
|
||||
|
||||
Args:
|
||||
code: The original code.
|
||||
documented_code: The documented code.
|
||||
|
||||
Returns:
|
||||
The original code with the docstrings from the documented code.
|
||||
"""
|
||||
code_tree = cst.parse_module(code)
|
||||
documented_code_tree = cst.parse_module(documented_code)
|
||||
|
||||
visitor = DocstringCollector()
|
||||
documented_code_tree.visit(visitor)
|
||||
transformer = DocstringTransformer(visitor.docstrings)
|
||||
modified_tree = code_tree.visit(transformer)
|
||||
return modified_tree.code
|
||||
|
|
@ -3,14 +3,11 @@
|
|||
# @Desc : the implement of serialization and deserialization
|
||||
|
||||
import copy
|
||||
from typing import Tuple, List, Type, Union, Dict
|
||||
import pickle
|
||||
from collections import defaultdict
|
||||
from pydantic import create_model
|
||||
from typing import Dict, List, Tuple
|
||||
|
||||
from metagpt.schema import Message
|
||||
from metagpt.actions.action import Action
|
||||
from metagpt.actions.action_output import ActionOutput
|
||||
from metagpt.schema import Message
|
||||
|
||||
|
||||
def actionoutout_schema_to_mapping(schema: Dict) -> Dict:
|
||||
|
|
@ -34,12 +31,12 @@ def actionoutout_schema_to_mapping(schema: Dict) -> Dict:
|
|||
```
|
||||
"""
|
||||
mapping = dict()
|
||||
for field, property in schema['properties'].items():
|
||||
if property['type'] == 'string':
|
||||
for field, property in schema["properties"].items():
|
||||
if property["type"] == "string":
|
||||
mapping[field] = (str, ...)
|
||||
elif property['type'] == 'array' and property['items']['type'] == 'string':
|
||||
elif property["type"] == "array" and property["items"]["type"] == "string":
|
||||
mapping[field] = (List[str], ...)
|
||||
elif property['type'] == 'array' and property['items']['type'] == 'array':
|
||||
elif property["type"] == "array" and property["items"]["type"] == "array":
|
||||
# here only consider the `Tuple[str, str]` situation
|
||||
mapping[field] = (List[Tuple[str, str]], ...)
|
||||
return mapping
|
||||
|
|
@ -53,11 +50,7 @@ def serialize_message(message: Message):
|
|||
schema = ic.schema()
|
||||
mapping = actionoutout_schema_to_mapping(schema)
|
||||
|
||||
message_cp.instruct_content = {
|
||||
'class': schema['title'],
|
||||
'mapping': mapping,
|
||||
'value': ic.dict()
|
||||
}
|
||||
message_cp.instruct_content = {"class": schema["title"], "mapping": mapping, "value": ic.dict()}
|
||||
msg_ser = pickle.dumps(message_cp)
|
||||
|
||||
return msg_ser
|
||||
|
|
@ -67,9 +60,8 @@ def deserialize_message(message_ser: str) -> Message:
|
|||
message = pickle.loads(message_ser)
|
||||
if message.instruct_content:
|
||||
ic = message.instruct_content
|
||||
ic_obj = ActionOutput.create_model_class(class_name=ic['class'],
|
||||
mapping=ic['mapping'])
|
||||
ic_new = ic_obj(**ic['value'])
|
||||
ic_obj = ActionOutput.create_model_class(class_name=ic["class"], mapping=ic["mapping"])
|
||||
ic_new = ic_obj(**ic["value"])
|
||||
message.instruct_content = ic_new
|
||||
|
||||
return message
|
||||
|
|
|
|||
4
metagpt/utils/special_tokens.py
Normal file
4
metagpt/utils/special_tokens.py
Normal file
|
|
@ -0,0 +1,4 @@
|
|||
# token to separate different code messages in a WriteCode Message content
|
||||
MSG_SEP = "#*000*#"
|
||||
# token to seperate file name and the actual code text in a code message
|
||||
FILENAME_CODE_SEP = "#*001*#"
|
||||
124
metagpt/utils/text.py
Normal file
124
metagpt/utils/text.py
Normal file
|
|
@ -0,0 +1,124 @@
|
|||
from typing import Generator, Sequence
|
||||
|
||||
from metagpt.utils.token_counter import TOKEN_MAX, count_string_tokens
|
||||
|
||||
|
||||
def reduce_message_length(msgs: Generator[str, None, None], model_name: str, system_text: str, reserved: int = 0,) -> str:
|
||||
"""Reduce the length of concatenated message segments to fit within the maximum token size.
|
||||
|
||||
Args:
|
||||
msgs: A generator of strings representing progressively shorter valid prompts.
|
||||
model_name: The name of the encoding to use. (e.g., "gpt-3.5-turbo")
|
||||
system_text: The system prompts.
|
||||
reserved: The number of reserved tokens.
|
||||
|
||||
Returns:
|
||||
The concatenated message segments reduced to fit within the maximum token size.
|
||||
|
||||
Raises:
|
||||
RuntimeError: If it fails to reduce the concatenated message length.
|
||||
"""
|
||||
max_token = TOKEN_MAX.get(model_name, 2048) - count_string_tokens(system_text, model_name) - reserved
|
||||
for msg in msgs:
|
||||
if count_string_tokens(msg, model_name) < max_token:
|
||||
return msg
|
||||
|
||||
raise RuntimeError("fail to reduce message length")
|
||||
|
||||
|
||||
def generate_prompt_chunk(
|
||||
text: str,
|
||||
prompt_template: str,
|
||||
model_name: str,
|
||||
system_text: str,
|
||||
reserved: int = 0,
|
||||
) -> Generator[str, None, None]:
|
||||
"""Split the text into chunks of a maximum token size.
|
||||
|
||||
Args:
|
||||
text: The text to split.
|
||||
prompt_template: The template for the prompt, containing a single `{}` placeholder. For example, "### Reference\n{}".
|
||||
model_name: The name of the encoding to use. (e.g., "gpt-3.5-turbo")
|
||||
system_text: The system prompts.
|
||||
reserved: The number of reserved tokens.
|
||||
|
||||
Yields:
|
||||
The chunk of text.
|
||||
"""
|
||||
paragraphs = text.splitlines(keepends=True)
|
||||
current_token = 0
|
||||
current_lines = []
|
||||
|
||||
reserved = reserved + count_string_tokens(prompt_template+system_text, model_name)
|
||||
# 100 is a magic number to ensure the maximum context length is not exceeded
|
||||
max_token = TOKEN_MAX.get(model_name, 2048) - reserved - 100
|
||||
|
||||
while paragraphs:
|
||||
paragraph = paragraphs.pop(0)
|
||||
token = count_string_tokens(paragraph, model_name)
|
||||
if current_token + token <= max_token:
|
||||
current_lines.append(paragraph)
|
||||
current_token += token
|
||||
elif token > max_token:
|
||||
paragraphs = split_paragraph(paragraph) + paragraphs
|
||||
continue
|
||||
else:
|
||||
yield prompt_template.format("".join(current_lines))
|
||||
current_lines = [paragraph]
|
||||
current_token = token
|
||||
|
||||
if current_lines:
|
||||
yield prompt_template.format("".join(current_lines))
|
||||
|
||||
|
||||
def split_paragraph(paragraph: str, sep: str = ".,", count: int = 2) -> list[str]:
|
||||
"""Split a paragraph into multiple parts.
|
||||
|
||||
Args:
|
||||
paragraph: The paragraph to split.
|
||||
sep: The separator character.
|
||||
count: The number of parts to split the paragraph into.
|
||||
|
||||
Returns:
|
||||
A list of split parts of the paragraph.
|
||||
"""
|
||||
for i in sep:
|
||||
sentences = list(_split_text_with_ends(paragraph, i))
|
||||
if len(sentences) <= 1:
|
||||
continue
|
||||
ret = ["".join(j) for j in _split_by_count(sentences, count)]
|
||||
return ret
|
||||
return _split_by_count(paragraph, count)
|
||||
|
||||
|
||||
def decode_unicode_escape(text: str) -> str:
|
||||
"""Decode a text with unicode escape sequences.
|
||||
|
||||
Args:
|
||||
text: The text to decode.
|
||||
|
||||
Returns:
|
||||
The decoded text.
|
||||
"""
|
||||
return text.encode("utf-8").decode("unicode_escape", "ignore")
|
||||
|
||||
|
||||
def _split_by_count(lst: Sequence , count: int):
|
||||
avg = len(lst) // count
|
||||
remainder = len(lst) % count
|
||||
start = 0
|
||||
for i in range(count):
|
||||
end = start + avg + (1 if i < remainder else 0)
|
||||
yield lst[start:end]
|
||||
start = end
|
||||
|
||||
|
||||
def _split_text_with_ends(text: str, sep: str = "."):
|
||||
parts = []
|
||||
for i in text:
|
||||
parts.append(i)
|
||||
if i == sep:
|
||||
yield "".join(parts)
|
||||
parts = []
|
||||
if parts:
|
||||
yield "".join(parts)
|
||||
|
|
@ -25,6 +25,21 @@ TOKEN_COSTS = {
|
|||
}
|
||||
|
||||
|
||||
TOKEN_MAX = {
|
||||
"gpt-3.5-turbo": 4096,
|
||||
"gpt-3.5-turbo-0301": 4096,
|
||||
"gpt-3.5-turbo-0613": 4096,
|
||||
"gpt-3.5-turbo-16k": 16384,
|
||||
"gpt-3.5-turbo-16k-0613": 16384,
|
||||
"gpt-4-0314": 8192,
|
||||
"gpt-4": 8192,
|
||||
"gpt-4-32k": 32768,
|
||||
"gpt-4-32k-0314": 32768,
|
||||
"gpt-4-0613": 8192,
|
||||
"text-embedding-ada-002": 8192,
|
||||
}
|
||||
|
||||
|
||||
def count_message_tokens(messages, model="gpt-3.5-turbo-0613"):
|
||||
"""Return the number of tokens used by a list of messages."""
|
||||
try:
|
||||
|
|
@ -39,7 +54,7 @@ def count_message_tokens(messages, model="gpt-3.5-turbo-0613"):
|
|||
"gpt-4-32k-0314",
|
||||
"gpt-4-0613",
|
||||
"gpt-4-32k-0613",
|
||||
}:
|
||||
}:
|
||||
tokens_per_message = 3
|
||||
tokens_per_name = 1
|
||||
elif model == "gpt-3.5-turbo-0301":
|
||||
|
|
@ -79,3 +94,18 @@ def count_string_tokens(string: str, model_name: str) -> int:
|
|||
"""
|
||||
encoding = tiktoken.encoding_for_model(model_name)
|
||||
return len(encoding.encode(string))
|
||||
|
||||
|
||||
def get_max_completion_tokens(messages: list[dict], model: str, default: int) -> int:
|
||||
"""Calculate the maximum number of completion tokens for a given model and list of messages.
|
||||
|
||||
Args:
|
||||
messages: A list of messages.
|
||||
model: The model name.
|
||||
|
||||
Returns:
|
||||
The maximum number of completion tokens.
|
||||
"""
|
||||
if model not in TOKEN_MAX:
|
||||
return default
|
||||
return TOKEN_MAX[model] - count_message_tokens(messages)
|
||||
|
|
|
|||
69
pyproject.toml
Normal file
69
pyproject.toml
Normal file
|
|
@ -0,0 +1,69 @@
|
|||
[project]
|
||||
name = "chatgit"
|
||||
version = "0.1.0"
|
||||
description = "chatgit is an LLM model-based open source project competition analysis research project, it can help you find the most suitable open source project for your needs"
|
||||
authors = [
|
||||
{name = "hezz", email = "hezhaozhaog@gmail.com"},
|
||||
]
|
||||
dependencies = [
|
||||
"requests>=2.31.0",
|
||||
]
|
||||
requires-python = ">=3.11"
|
||||
readme = "README.md"
|
||||
license = {text = "Apache"}
|
||||
|
||||
[build-system]
|
||||
requires = ["setuptools>=61", "wheel"]
|
||||
build-backend = "setuptools.build_meta"
|
||||
|
||||
[tool.black]
|
||||
line-length = 119
|
||||
target-version = ['py39']
|
||||
|
||||
|
||||
[tool.ruff]
|
||||
# Enable pycodestyle (`E`) and Pyflakes (`F`) codes by default.
|
||||
select = ["E", "F"]
|
||||
ignore = ["E501", "E712", "E722", "F821", "E731"]
|
||||
|
||||
# Allow autofix for all enabled rules (when `--fix`) is provided.
|
||||
fixable = ["A", "B", "C", "D", "E", "F", "G", "I", "N", "Q", "S", "T", "W", "ANN", "ARG", "BLE", "COM", "DJ", "DTZ", "EM", "ERA", "EXE", "FBT", "ICN", "INP", "ISC", "NPY", "PD", "PGH", "PIE", "PL", "PT", "PTH", "PYI", "RET", "RSE", "RUF", "SIM", "SLF", "TCH", "TID", "TRY", "UP", "YTT"]
|
||||
unfixable = []
|
||||
|
||||
# Exclude a variety of commonly ignored directories.
|
||||
exclude = [
|
||||
".bzr",
|
||||
".direnv",
|
||||
".eggs",
|
||||
".git",
|
||||
".git-rewrite",
|
||||
".hg",
|
||||
".mypy_cache",
|
||||
".nox",
|
||||
".pants.d",
|
||||
".pytype",
|
||||
".ruff_cache",
|
||||
".svn",
|
||||
".tox",
|
||||
".venv",
|
||||
"__pypackages__",
|
||||
"_build",
|
||||
"buck-out",
|
||||
"build",
|
||||
"dist",
|
||||
"node_modules",
|
||||
"venv",
|
||||
]
|
||||
|
||||
# Same as Black.
|
||||
line-length = 119
|
||||
|
||||
# Allow unused variables when underscore-prefixed.
|
||||
dummy-variable-rgx = "^(_+|(_+[a-zA-Z0-9_]*[a-zA-Z0-9]+?))$"
|
||||
|
||||
# Assume Python 3.9
|
||||
target-version = "py39"
|
||||
|
||||
[tool.ruff.mccabe]
|
||||
# Unlike Flake8, default to a complexity level of 10.
|
||||
max-complexity = 10
|
||||
|
|
@ -35,3 +35,4 @@ tqdm==4.64.0
|
|||
anthropic==0.3.6
|
||||
typing-inspect==0.8.0
|
||||
typing_extensions==4.5.0
|
||||
libcst==1.0.1
|
||||
|
|
|
|||
2
setup.py
2
setup.py
|
|
@ -44,7 +44,7 @@ setup(
|
|||
install_requires=requirements,
|
||||
extras_require={
|
||||
"playwright": ["playwright>=1.26", "beautifulsoup4"],
|
||||
"selenium": ["selenium>4", "webdriver_manager<3.9", "beautifulsoup4"],
|
||||
"selenium": ["selenium>4", "webdriver_manager", "beautifulsoup4"],
|
||||
},
|
||||
cmdclass={
|
||||
"install_mermaid": InstallMermaidCLI,
|
||||
|
|
|
|||
12
startup.py
12
startup.py
|
|
@ -4,23 +4,27 @@ import asyncio
|
|||
|
||||
import fire
|
||||
|
||||
from metagpt.roles import Architect, Engineer, ProductManager, ProjectManager
|
||||
from metagpt.roles import Architect, Engineer, ProductManager, ProjectManager, QaEngineer
|
||||
from metagpt.software_company import SoftwareCompany
|
||||
|
||||
|
||||
async def startup(idea: str, investment: float = 3.0, n_round: int = 5, code_review: bool = False):
|
||||
async def startup(idea: str, investment: float = 3.0, n_round: int = 5,
|
||||
code_review: bool = False, run_tests: bool = False):
|
||||
"""Run a startup. Be a boss."""
|
||||
company = SoftwareCompany()
|
||||
company.hire([ProductManager(),
|
||||
Architect(),
|
||||
ProjectManager(),
|
||||
Engineer(n_borg=5, use_code_review=code_review)])
|
||||
if run_tests:
|
||||
# developing features: run tests on the spot and identify bugs (bug fixing capability comes soon!)
|
||||
company.hire([QaEngineer()])
|
||||
company.invest(investment)
|
||||
company.start_project(idea)
|
||||
await company.run(n_round=n_round)
|
||||
|
||||
|
||||
def main(idea: str, investment: float = 3.0, n_round: int = 5, code_review: bool = False):
|
||||
def main(idea: str, investment: float = 3.0, n_round: int = 5, code_review: bool = False, run_tests: bool = False):
|
||||
"""
|
||||
We are a software startup comprised of AI. By investing in us, you are empowering a future filled with limitless possibilities.
|
||||
:param idea: Your innovative idea, such as "Creating a snake game."
|
||||
|
|
@ -29,7 +33,7 @@ def main(idea: str, investment: float = 3.0, n_round: int = 5, code_review: bool
|
|||
:param code_review: Whether to use code review.
|
||||
:return:
|
||||
"""
|
||||
asyncio.run(startup(idea, investment, n_round, code_review))
|
||||
asyncio.run(startup(idea, investment, n_round, code_review, run_tests))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
|
|
|||
|
|
@ -9,15 +9,147 @@ import pytest
|
|||
|
||||
from metagpt.actions.debug_error import DebugError
|
||||
|
||||
EXAMPLE_MSG_CONTENT = '''
|
||||
---
|
||||
## Development Code File Name
|
||||
player.py
|
||||
## Development Code
|
||||
```python
|
||||
from typing import List
|
||||
from deck import Deck
|
||||
from card import Card
|
||||
|
||||
class Player:
|
||||
"""
|
||||
A class representing a player in the Black Jack game.
|
||||
"""
|
||||
|
||||
def __init__(self, name: str):
|
||||
"""
|
||||
Initialize a Player object.
|
||||
|
||||
Args:
|
||||
name (str): The name of the player.
|
||||
"""
|
||||
self.name = name
|
||||
self.hand: List[Card] = []
|
||||
self.score = 0
|
||||
|
||||
def draw(self, deck: Deck):
|
||||
"""
|
||||
Draw a card from the deck and add it to the player's hand.
|
||||
|
||||
Args:
|
||||
deck (Deck): The deck of cards.
|
||||
"""
|
||||
card = deck.draw_card()
|
||||
self.hand.append(card)
|
||||
self.calculate_score()
|
||||
|
||||
def calculate_score(self) -> int:
|
||||
"""
|
||||
Calculate the score of the player's hand.
|
||||
|
||||
Returns:
|
||||
int: The score of the player's hand.
|
||||
"""
|
||||
self.score = sum(card.value for card in self.hand)
|
||||
# Handle the case where Ace is counted as 11 and causes the score to exceed 21
|
||||
if self.score > 21 and any(card.rank == 'A' for card in self.hand):
|
||||
self.score -= 10
|
||||
return self.score
|
||||
|
||||
```
|
||||
## Test File Name
|
||||
test_player.py
|
||||
## Test Code
|
||||
```python
|
||||
import unittest
|
||||
from blackjack_game.player import Player
|
||||
from blackjack_game.deck import Deck
|
||||
from blackjack_game.card import Card
|
||||
|
||||
class TestPlayer(unittest.TestCase):
|
||||
## Test the Player's initialization
|
||||
def test_player_initialization(self):
|
||||
player = Player("Test Player")
|
||||
self.assertEqual(player.name, "Test Player")
|
||||
self.assertEqual(player.hand, [])
|
||||
self.assertEqual(player.score, 0)
|
||||
|
||||
## Test the Player's draw method
|
||||
def test_player_draw(self):
|
||||
deck = Deck()
|
||||
player = Player("Test Player")
|
||||
player.draw(deck)
|
||||
self.assertEqual(len(player.hand), 1)
|
||||
self.assertEqual(player.score, player.hand[0].value)
|
||||
|
||||
## Test the Player's calculate_score method
|
||||
def test_player_calculate_score(self):
|
||||
deck = Deck()
|
||||
player = Player("Test Player")
|
||||
player.draw(deck)
|
||||
player.draw(deck)
|
||||
self.assertEqual(player.score, sum(card.value for card in player.hand))
|
||||
|
||||
## Test the Player's calculate_score method with Ace card
|
||||
def test_player_calculate_score_with_ace(self):
|
||||
deck = Deck()
|
||||
player = Player("Test Player")
|
||||
player.hand.append(Card('A', 'Hearts', 11))
|
||||
player.hand.append(Card('K', 'Hearts', 10))
|
||||
player.calculate_score()
|
||||
self.assertEqual(player.score, 21)
|
||||
|
||||
## Test the Player's calculate_score method with multiple Aces
|
||||
def test_player_calculate_score_with_multiple_aces(self):
|
||||
deck = Deck()
|
||||
player = Player("Test Player")
|
||||
player.hand.append(Card('A', 'Hearts', 11))
|
||||
player.hand.append(Card('A', 'Diamonds', 11))
|
||||
player.calculate_score()
|
||||
self.assertEqual(player.score, 12)
|
||||
|
||||
if __name__ == '__main__':
|
||||
unittest.main()
|
||||
|
||||
```
|
||||
## Running Command
|
||||
python tests/test_player.py
|
||||
## Running Output
|
||||
standard output: ;
|
||||
standard errors: ..F..
|
||||
======================================================================
|
||||
FAIL: test_player_calculate_score_with_multiple_aces (__main__.TestPlayer)
|
||||
----------------------------------------------------------------------
|
||||
Traceback (most recent call last):
|
||||
File "tests/test_player.py", line 46, in test_player_calculate_score_with_multiple_aces
|
||||
self.assertEqual(player.score, 12)
|
||||
AssertionError: 22 != 12
|
||||
|
||||
----------------------------------------------------------------------
|
||||
Ran 5 tests in 0.007s
|
||||
|
||||
FAILED (failures=1)
|
||||
;
|
||||
## instruction:
|
||||
The error is in the development code, specifically in the calculate_score method of the Player class. The method is not correctly handling the case where there are multiple Aces in the player's hand. The current implementation only subtracts 10 from the score once if the score is over 21 and there's an Ace in the hand. However, in the case of multiple Aces, it should subtract 10 for each Ace until the score is 21 or less.
|
||||
## File To Rewrite:
|
||||
player.py
|
||||
## Status:
|
||||
FAIL
|
||||
## Send To:
|
||||
Engineer
|
||||
---
|
||||
'''
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_debug_error():
|
||||
code = "def add(a, b):\n return a - b"
|
||||
error = "AssertionError: Expected add(1, 1) to equal 2 but got 0"
|
||||
|
||||
debug_error = DebugError("debug_error")
|
||||
|
||||
result = await debug_error.run(code, error)
|
||||
file_name, rewritten_code = await debug_error.run(context=EXAMPLE_MSG_CONTENT)
|
||||
|
||||
# mock_llm.ask.assert_called_once_with(prompt)
|
||||
assert len(result) > 0
|
||||
assert "class Player" in rewritten_code # rewrite the same class
|
||||
assert "while self.score > 21" in rewritten_code # a key logic to rewrite to (original one is "if self.score > 12")
|
||||
|
|
|
|||
|
|
@ -11,28 +11,61 @@ from metagpt.actions.run_code import RunCode
|
|||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_run_code():
|
||||
code = """
|
||||
def add(a, b):
|
||||
return a + b
|
||||
result = add(1, 2)
|
||||
"""
|
||||
run_code = RunCode("run_code")
|
||||
async def test_run_text():
|
||||
result, errs = await RunCode.run_text("result = 1 + 1")
|
||||
assert result == 2
|
||||
assert errs == ""
|
||||
|
||||
result = await run_code.run(code)
|
||||
|
||||
assert result == 3
|
||||
result, errs = await RunCode.run_text("result = 1 / 0")
|
||||
assert result == ""
|
||||
assert "ZeroDivisionError" in errs
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_run_code_with_error():
|
||||
code = """
|
||||
def add(a, b):
|
||||
return a + b
|
||||
result = add(1, '2')
|
||||
"""
|
||||
run_code = RunCode("run_code")
|
||||
async def test_run_script():
|
||||
# Successful command
|
||||
out, err = await RunCode.run_script(".", command=["echo", "Hello World"])
|
||||
assert out.strip() == "Hello World"
|
||||
assert err == ""
|
||||
|
||||
result = await run_code.run(code)
|
||||
# Unsuccessful command
|
||||
out, err = await RunCode.run_script(".", command=["python", "-c", "print(1/0)"])
|
||||
assert "ZeroDivisionError" in err
|
||||
|
||||
assert "TypeError: unsupported operand type(s) for +" in result
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_run():
|
||||
action = RunCode()
|
||||
result = await action.run(mode="text", code="print('Hello, World')")
|
||||
assert "PASS" in result
|
||||
|
||||
result = await action.run(
|
||||
mode="script",
|
||||
code="echo 'Hello World'",
|
||||
code_file_name="",
|
||||
test_code="",
|
||||
test_file_name="",
|
||||
command=["echo", "Hello World"],
|
||||
working_directory=".",
|
||||
additional_python_paths=[],
|
||||
)
|
||||
assert "PASS" in result
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_run_failure():
|
||||
action = RunCode()
|
||||
result = await action.run(mode="text", code="result = 1 / 0")
|
||||
assert "FAIL" in result
|
||||
|
||||
result = await action.run(
|
||||
mode="script",
|
||||
code='python -c "print(1/0)"',
|
||||
code_file_name="",
|
||||
test_code="",
|
||||
test_file_name="",
|
||||
command=["python", "-c", "print(1/0)"],
|
||||
working_directory=".",
|
||||
additional_python_paths=[],
|
||||
)
|
||||
assert "FAIL" in result
|
||||
|
|
|
|||
|
|
@ -8,8 +8,6 @@
|
|||
import pytest
|
||||
|
||||
from metagpt.actions.write_code_review import WriteCodeReview
|
||||
from metagpt.logs import logger
|
||||
from tests.metagpt.actions.mock import SEARCH_CODE_SAMPLE
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
|
|
@ -20,11 +18,7 @@ def add(a, b):
|
|||
"""
|
||||
# write_code_review = WriteCodeReview("write_code_review")
|
||||
|
||||
code = await WriteCodeReview().run(
|
||||
context="编写一个从a加b的函数,返回a+b",
|
||||
code=code,
|
||||
filename="math.py"
|
||||
)
|
||||
code = await WriteCodeReview().run(context="编写一个从a加b的函数,返回a+b", code=code, filename="math.py")
|
||||
|
||||
# 我们不能精确地预测生成的代码评审,但我们可以检查返回的是否为字符串
|
||||
assert isinstance(code, str)
|
||||
|
|
@ -33,6 +27,7 @@ def add(a, b):
|
|||
captured = capfd.readouterr()
|
||||
print(f"输出内容: {captured.out}")
|
||||
|
||||
|
||||
# @pytest.mark.asyncio
|
||||
# async def test_write_code_review_directly():
|
||||
# code = SEARCH_CODE_SAMPLE
|
||||
|
|
|
|||
32
tests/metagpt/actions/test_write_docstring.py
Normal file
32
tests/metagpt/actions/test_write_docstring.py
Normal file
|
|
@ -0,0 +1,32 @@
|
|||
import pytest
|
||||
|
||||
from metagpt.actions.write_docstring import WriteDocstring
|
||||
|
||||
code = '''
|
||||
def add_numbers(a: int, b: int):
|
||||
return a + b
|
||||
|
||||
|
||||
class Person:
|
||||
def __init__(self, name: str, age: int):
|
||||
self.name = name
|
||||
self.age = age
|
||||
|
||||
def greet(self):
|
||||
return f"Hello, my name is {self.name} and I am {self.age} years old."
|
||||
'''
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@pytest.mark.parametrize(
|
||||
("style", "part"),
|
||||
[
|
||||
("google", "Args:"),
|
||||
("numpy", "Parameters"),
|
||||
("sphinx", ":param name:"),
|
||||
],
|
||||
ids=["google", "numpy", "sphinx"]
|
||||
)
|
||||
async def test_write_docstring(style: str, part: str):
|
||||
ret = await WriteDocstring().run(code, style=style)
|
||||
assert part in ret
|
||||
|
|
@ -8,19 +8,35 @@
|
|||
import pytest
|
||||
|
||||
from metagpt.actions.write_test import WriteTest
|
||||
from metagpt.logs import logger
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_write_test():
|
||||
code = """
|
||||
def add(a, b):
|
||||
return a + b
|
||||
import random
|
||||
from typing import Tuple
|
||||
|
||||
class Food:
|
||||
def __init__(self, position: Tuple[int, int]):
|
||||
self.position = position
|
||||
|
||||
def generate(self, max_y: int, max_x: int):
|
||||
self.position = (random.randint(1, max_y - 1), random.randint(1, max_x - 1))
|
||||
"""
|
||||
|
||||
write_test = WriteTest("write_test")
|
||||
write_test = WriteTest()
|
||||
|
||||
test_cases = await write_test.run(code)
|
||||
test_code = await write_test.run(
|
||||
code_to_test=code,
|
||||
test_file_name="test_food.py",
|
||||
source_file_path="/some/dummy/path/cli_snake_game/cli_snake_game/food.py",
|
||||
workspace="/some/dummy/path/cli_snake_game"
|
||||
)
|
||||
logger.info(test_code)
|
||||
|
||||
# We cannot exactly predict the generated test cases, but we can check if it is a string and if it is not empty
|
||||
assert isinstance(test_cases, str)
|
||||
assert len(test_cases) > 0
|
||||
assert isinstance(test_code, str)
|
||||
assert "from cli_snake_game.food import Food" in test_code
|
||||
assert "class TestFood(unittest.TestCase)" in test_code
|
||||
assert "def test_generate" in test_code
|
||||
|
|
|
|||
32
tests/metagpt/roles/test_researcher.py
Normal file
32
tests/metagpt/roles/test_researcher.py
Normal file
|
|
@ -0,0 +1,32 @@
|
|||
from pathlib import Path
|
||||
from random import random
|
||||
from tempfile import TemporaryDirectory
|
||||
|
||||
import pytest
|
||||
|
||||
from metagpt.roles import researcher
|
||||
|
||||
|
||||
async def mock_llm_ask(self, prompt: str, system_msgs):
|
||||
if "Please provide up to 2 necessary keywords" in prompt:
|
||||
return '["dataiku", "datarobot"]'
|
||||
elif "Provide up to 4 queries related to your research topic" in prompt:
|
||||
return '["Dataiku machine learning platform", "DataRobot AI platform comparison", ' \
|
||||
'"Dataiku vs DataRobot features", "Dataiku and DataRobot use cases"]'
|
||||
elif "sort the remaining search results" in prompt:
|
||||
return '[1,2]'
|
||||
elif "Not relevant." in prompt:
|
||||
return "Not relevant" if random() > 0.5 else prompt[-100:]
|
||||
elif "provide a detailed research report" in prompt:
|
||||
return f"# Research Report\n## Introduction\n{prompt}"
|
||||
return ""
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_researcher(mocker):
|
||||
with TemporaryDirectory() as dirname:
|
||||
topic = "dataiku vs. datarobot"
|
||||
mocker.patch("metagpt.provider.base_gpt_api.BaseGPTAPI.aask", mock_llm_ask)
|
||||
researcher.RESEARCH_PATH = Path(dirname)
|
||||
await researcher.Researcher().run(topic)
|
||||
assert (researcher.RESEARCH_PATH / f"{topic}.md").read_text().startswith("# Research Report")
|
||||
|
|
@ -2,22 +2,19 @@
|
|||
# @Date : 2023/7/15 16:40
|
||||
# @Author : stellahong (stellahong@fuzhi.ai)
|
||||
# @Desc :
|
||||
import re
|
||||
import os
|
||||
from importlib import import_module
|
||||
import re
|
||||
from functools import wraps
|
||||
from importlib import import_module
|
||||
|
||||
from metagpt.logs import logger
|
||||
from metagpt.actions import Action, ActionOutput
|
||||
from metagpt.roles import ProductManager, Role
|
||||
from metagpt.schema import Message
|
||||
from metagpt.actions import Action, ActionOutput, WritePRD
|
||||
from metagpt.const import WORKSPACE_ROOT
|
||||
|
||||
from metagpt.actions import WritePRD
|
||||
from metagpt.software_company import SoftwareCompany
|
||||
from metagpt.logs import logger
|
||||
from metagpt.roles import Role
|
||||
from metagpt.schema import Message
|
||||
from metagpt.tools.sd_engine import SDEngine
|
||||
|
||||
PROMPT_TEMPLATE = '''
|
||||
PROMPT_TEMPLATE = """
|
||||
# Context
|
||||
{context}
|
||||
|
||||
|
|
@ -34,9 +31,9 @@ Attention: Use '##' to split sections, not '#', and '## <SECTION_NAME>' SHOULD W
|
|||
## CSS Styles (styles.css):Provide as Plain text,use standard css code
|
||||
## Anything UNCLEAR:Provide as Plain text. Make clear here.
|
||||
|
||||
'''
|
||||
"""
|
||||
|
||||
FORMAT_EXAMPLE = '''
|
||||
FORMAT_EXAMPLE = """
|
||||
|
||||
## UI Design Description
|
||||
```Snake games are classic and addictive games with simple yet engaging elements. Here are the main elements commonly found in snake games ```
|
||||
|
|
@ -126,7 +123,7 @@ body {
|
|||
## Anything UNCLEAR
|
||||
There are no unclear points.
|
||||
|
||||
'''
|
||||
"""
|
||||
|
||||
OUTPUT_MAPPING = {
|
||||
"UI Design Description": (str, ...),
|
||||
|
|
@ -139,25 +136,25 @@ OUTPUT_MAPPING = {
|
|||
|
||||
def load_engine(func):
|
||||
"""Decorator to load an engine by file name and engine name."""
|
||||
|
||||
|
||||
@wraps(func)
|
||||
def wrapper(*args, **kwargs):
|
||||
file_name, engine_name = func(*args, **kwargs)
|
||||
engine_file = import_module(file_name, package='metagpt')
|
||||
engine_file = import_module(file_name, package="metagpt")
|
||||
ip_module_cls = getattr(engine_file, engine_name)
|
||||
try:
|
||||
engine = ip_module_cls()
|
||||
except:
|
||||
engine = None
|
||||
|
||||
|
||||
return engine
|
||||
|
||||
|
||||
return wrapper
|
||||
|
||||
|
||||
def parse(func):
|
||||
"""Decorator to parse information using regex pattern."""
|
||||
|
||||
|
||||
@wraps(func)
|
||||
def wrapper(*args, **kwargs):
|
||||
context, pattern = func(*args, **kwargs)
|
||||
|
|
@ -168,30 +165,30 @@ def parse(func):
|
|||
else:
|
||||
text_info = context
|
||||
logger.info("未找到匹配的内容")
|
||||
|
||||
|
||||
return text_info
|
||||
|
||||
|
||||
return wrapper
|
||||
|
||||
|
||||
class UIDesign(Action):
|
||||
"""Class representing the UI Design action."""
|
||||
|
||||
|
||||
def __init__(self, name, context=None, llm=None):
|
||||
super().__init__(name, context, llm) # 需要调用LLM进一步丰富UI设计的prompt
|
||||
|
||||
|
||||
@parse
|
||||
def parse_requirement(self, context: str):
|
||||
"""Parse UI Design draft from the context using regex."""
|
||||
pattern = r"## UI Design draft.*?\n(.*?)## Anything UNCLEAR"
|
||||
return context, pattern
|
||||
|
||||
|
||||
@parse
|
||||
def parse_ui_elements(self, context: str):
|
||||
"""Parse Selected Elements from the context using regex."""
|
||||
pattern = r"## Selected Elements.*?\n(.*?)## HTML Layout"
|
||||
return context, pattern
|
||||
|
||||
|
||||
@parse
|
||||
def parse_css_code(self, context: str):
|
||||
pattern = r"```css.*?\n(.*?)## Anything UNCLEAR"
|
||||
|
|
@ -201,7 +198,7 @@ class UIDesign(Action):
|
|||
def parse_html_code(self, context: str):
|
||||
pattern = r"```html.*?\n(.*?)```"
|
||||
return context, pattern
|
||||
|
||||
|
||||
async def draw_icons(self, context, *args, **kwargs):
|
||||
"""Draw icons using SDEngine."""
|
||||
engine = SDEngine()
|
||||
|
|
@ -215,20 +212,20 @@ class UIDesign(Action):
|
|||
prompts_batch.append(prompt)
|
||||
await engine.run_t2i(prompts_batch)
|
||||
logger.info("Finish icon design using StableDiffusion API")
|
||||
|
||||
|
||||
async def _save(self, css_content, html_content):
|
||||
save_dir = WORKSPACE_ROOT / "resources" / 'codes'
|
||||
save_dir = WORKSPACE_ROOT / "resources" / "codes"
|
||||
if not os.path.exists(save_dir):
|
||||
os.makedirs(save_dir, exist_ok=True)
|
||||
# Save CSS and HTML content to files
|
||||
css_file_path = save_dir / f"ui_design.css"
|
||||
html_file_path = save_dir / f"ui_design.html"
|
||||
|
||||
with open(css_file_path, 'w') as css_file:
|
||||
css_file_path = save_dir / "ui_design.css"
|
||||
html_file_path = save_dir / "ui_design.html"
|
||||
|
||||
with open(css_file_path, "w") as css_file:
|
||||
css_file.write(css_content)
|
||||
with open(html_file_path, 'w') as html_file:
|
||||
with open(html_file_path, "w") as html_file:
|
||||
html_file.write(html_content)
|
||||
|
||||
|
||||
async def run(self, requirements: list[Message], *args, **kwargs) -> ActionOutput:
|
||||
"""Run the UI Design action."""
|
||||
# fixme: update prompt (根据需求细化prompt)
|
||||
|
|
@ -249,23 +246,27 @@ class UIDesign(Action):
|
|||
|
||||
class UI(Role):
|
||||
"""Class representing the UI Role."""
|
||||
|
||||
def __init__(self, name="Catherine", profile="UI Design",
|
||||
goal="Finish a workable and good User Interface design based on a product design",
|
||||
constraints="Give clear layout description and use standard icons to finish the design",
|
||||
skills=["SD"]):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
name="Catherine",
|
||||
profile="UI Design",
|
||||
goal="Finish a workable and good User Interface design based on a product design",
|
||||
constraints="Give clear layout description and use standard icons to finish the design",
|
||||
skills=["SD"],
|
||||
):
|
||||
super().__init__(name, profile, goal, constraints)
|
||||
self.load_skills(skills)
|
||||
self._init_actions([UIDesign])
|
||||
self._watch([WritePRD])
|
||||
|
||||
|
||||
@load_engine
|
||||
def load_sd_engine(self):
|
||||
"""Load the SDEngine."""
|
||||
file_name = ".tools.sd_engine"
|
||||
engine_name = "SDEngine"
|
||||
return file_name, engine_name
|
||||
|
||||
|
||||
def load_skills(self, skills):
|
||||
"""Load skills for the UI Role."""
|
||||
# todo: 添加其他出图engine
|
||||
|
|
@ -273,4 +274,3 @@ class UI(Role):
|
|||
if skill == "SD":
|
||||
self.sd_engine = self.load_sd_engine()
|
||||
logger.info(f"load skill engine {self.sd_engine}")
|
||||
|
||||
|
|
|
|||
|
|
@ -5,24 +5,44 @@
|
|||
@Author : alexanderwu
|
||||
@File : test_search_engine.py
|
||||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
import pytest
|
||||
|
||||
from metagpt.logs import logger
|
||||
from metagpt.tools import SearchEngineType
|
||||
from metagpt.tools.search_engine import SearchEngine
|
||||
|
||||
|
||||
class MockSearchEnine:
|
||||
async def run(self, query: str, max_results: int = 8, as_string: bool = True) -> str | list[dict[str, str]]:
|
||||
rets = [{"url": "https://metagpt.com/mock/{i}", "title": query, "snippet": query * i} for i in range(max_results)]
|
||||
return "\n".join(rets) if as_string else rets
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@pytest.mark.usefixtures("llm_api")
|
||||
async def test_search_engine(llm_api):
|
||||
search_engine = SearchEngine()
|
||||
poetries = [
|
||||
# ("北京美食", "北京"),
|
||||
("屈臣氏", "屈臣氏")
|
||||
]
|
||||
for i, j in poetries:
|
||||
rsp = await search_engine.run(i)
|
||||
# rsp = context.llm.ask_batch([prompt])
|
||||
logger.info(rsp)
|
||||
# assert any(j in k['body'] for k in rsp)
|
||||
assert len(rsp) > 0
|
||||
@pytest.mark.parametrize(
|
||||
("search_engine_typpe", "run_func", "max_results", "as_string"),
|
||||
[
|
||||
(SearchEngineType.SERPAPI_GOOGLE, None, 8, True),
|
||||
(SearchEngineType.SERPAPI_GOOGLE, None, 4, False),
|
||||
(SearchEngineType.DIRECT_GOOGLE, None, 8, True),
|
||||
(SearchEngineType.DIRECT_GOOGLE, None, 6, False),
|
||||
(SearchEngineType.SERPER_GOOGLE, None, 8, True),
|
||||
(SearchEngineType.SERPER_GOOGLE, None, 6, False),
|
||||
(SearchEngineType.DUCK_DUCK_GO, None, 8, True),
|
||||
(SearchEngineType.DUCK_DUCK_GO, None, 6, False),
|
||||
(SearchEngineType.CUSTOM_ENGINE, MockSearchEnine().run, 8, False),
|
||||
(SearchEngineType.CUSTOM_ENGINE, MockSearchEnine().run, 6, False),
|
||||
|
||||
],
|
||||
)
|
||||
async def test_search_engine(search_engine_typpe, run_func, max_results, as_string, ):
|
||||
search_engine = SearchEngine(search_engine_typpe, run_func)
|
||||
rsp = await search_engine.run("metagpt", max_results=max_results, as_string=as_string)
|
||||
logger.info(rsp)
|
||||
if as_string:
|
||||
assert isinstance(rsp, str)
|
||||
else:
|
||||
assert isinstance(rsp, list)
|
||||
assert len(rsp) == max_results
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
import pytest
|
||||
from metagpt.config import Config
|
||||
from metagpt.tools import web_browser_engine, WebBrowserEngineType
|
||||
|
||||
from metagpt.tools import WebBrowserEngineType, web_browser_engine
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
import pytest
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.tools import web_browser_engine_playwright
|
||||
|
||||
|
|
@ -20,6 +21,7 @@ async def test_scrape_web_page(browser_type, use_proxy, kwagrs, url, urls, proxy
|
|||
CONFIG.global_proxy = proxy
|
||||
browser = web_browser_engine_playwright.PlaywrightWrapper(browser_type, **kwagrs)
|
||||
result = await browser.run(url)
|
||||
result = result.inner_text
|
||||
assert isinstance(result, str)
|
||||
assert "Deepwisdom" in result
|
||||
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
import pytest
|
||||
|
||||
from metagpt.config import CONFIG
|
||||
from metagpt.tools import web_browser_engine_selenium
|
||||
|
||||
|
|
@ -20,6 +21,7 @@ async def test_scrape_web_page(browser_type, use_proxy, url, urls, proxy, capfd)
|
|||
CONFIG.global_proxy = proxy
|
||||
browser = web_browser_engine_selenium.SeleniumWrapper(browser_type)
|
||||
result = await browser.run(url)
|
||||
result = result.inner_text
|
||||
assert isinstance(result, str)
|
||||
assert "Deepwisdom" in result
|
||||
|
||||
|
|
@ -27,7 +29,7 @@ async def test_scrape_web_page(browser_type, use_proxy, url, urls, proxy, capfd)
|
|||
results = await browser.run(url, *urls)
|
||||
assert isinstance(results, list)
|
||||
assert len(results) == len(urls) + 1
|
||||
assert all(("Deepwisdom" in i) for i in results)
|
||||
assert all(("Deepwisdom" in i.inner_text) for i in results)
|
||||
if use_proxy:
|
||||
assert "Proxy:" in capfd.readouterr().out
|
||||
finally:
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ def test_parse_blocks():
|
|||
|
||||
|
||||
def test_parse_code():
|
||||
test_text = "```python\nprint('Hello, world!')\n```"
|
||||
test_text = "```python\nprint('Hello, world!')```"
|
||||
expected_result = "print('Hello, world!')"
|
||||
assert OutputParser.parse_code(test_text, 'python') == expected_result
|
||||
|
||||
|
|
@ -27,6 +27,22 @@ def test_parse_code():
|
|||
OutputParser.parse_code(test_text, 'java')
|
||||
|
||||
|
||||
def test_parse_python_code():
|
||||
expected_result = "print('Hello, world!')"
|
||||
assert OutputParser.parse_python_code("```python\nprint('Hello, world!')```") == expected_result
|
||||
assert OutputParser.parse_python_code("```python\nprint('Hello, world!')") == expected_result
|
||||
assert OutputParser.parse_python_code("print('Hello, world!')") == expected_result
|
||||
assert OutputParser.parse_python_code("print('Hello, world!')```") == expected_result
|
||||
assert OutputParser.parse_python_code("print('Hello, world!')```") == expected_result
|
||||
expected_result = "print('```Hello, world!```')"
|
||||
assert OutputParser.parse_python_code("```python\nprint('```Hello, world!```')```") == expected_result
|
||||
assert OutputParser.parse_python_code("The code is: ```python\nprint('```Hello, world!```')```") == expected_result
|
||||
assert OutputParser.parse_python_code("xxx.\n```python\nprint('```Hello, world!```')```\nxxx") == expected_result
|
||||
|
||||
with pytest.raises(ValueError):
|
||||
OutputParser.parse_python_code("xxx =")
|
||||
|
||||
|
||||
def test_parse_str():
|
||||
test_text = "name = 'Alice'"
|
||||
expected_result = 'Alice'
|
||||
|
|
|
|||
68
tests/metagpt/utils/test_parse_html.py
Normal file
68
tests/metagpt/utils/test_parse_html.py
Normal file
|
|
@ -0,0 +1,68 @@
|
|||
from metagpt.utils import parse_html
|
||||
|
||||
PAGE = """
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<title>Random HTML Example</title>
|
||||
</head>
|
||||
<body>
|
||||
<h1>This is a Heading</h1>
|
||||
<p>This is a paragraph with <a href="test">a link</a> and some <em>emphasized</em> text.</p>
|
||||
<ul>
|
||||
<li>Item 1</li>
|
||||
<li>Item 2</li>
|
||||
<li>Item 3</li>
|
||||
</ul>
|
||||
<ol>
|
||||
<li>Numbered Item 1</li>
|
||||
<li>Numbered Item 2</li>
|
||||
<li>Numbered Item 3</li>
|
||||
</ol>
|
||||
<table>
|
||||
<tr>
|
||||
<th>Header 1</th>
|
||||
<th>Header 2</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Row 1, Cell 1</td>
|
||||
<td>Row 1, Cell 2</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Row 2, Cell 1</td>
|
||||
<td>Row 2, Cell 2</td>
|
||||
</tr>
|
||||
</table>
|
||||
<img src="image.jpg" alt="Sample Image">
|
||||
<form action="/submit" method="post">
|
||||
<label for="name">Name:</label>
|
||||
<input type="text" id="name" name="name" required>
|
||||
<label for="email">Email:</label>
|
||||
<input type="email" id="email" name="email" required>
|
||||
<button type="submit">Submit</button>
|
||||
</form>
|
||||
<div class="box">
|
||||
<p>This is a div with a class "box".</p>
|
||||
<p><a href="https://metagpt.com">a link</a></p>
|
||||
<p><a href="#section2"></a></p>
|
||||
<p><a href="ftp://192.168.1.1:8080"></a></p>
|
||||
<p><a href="javascript:alert('Hello');"></a></p>
|
||||
</div>
|
||||
</body>
|
||||
</html>
|
||||
"""
|
||||
|
||||
CONTENT = 'This is a HeadingThis is a paragraph witha linkand someemphasizedtext.Item 1Item 2Item 3Numbered Item 1Numbered '\
|
||||
'Item 2Numbered Item 3Header 1Header 2Row 1, Cell 1Row 1, Cell 2Row 2, Cell 1Row 2, Cell 2Name:Email:SubmitThis is a div '\
|
||||
'with a class "box".a link'
|
||||
|
||||
|
||||
def test_web_page():
|
||||
page = parse_html.WebPage(inner_text=CONTENT, html=PAGE, url="http://example.com")
|
||||
assert page.title == "Random HTML Example"
|
||||
assert list(page.get_links()) == ["http://example.com/test", "https://metagpt.com"]
|
||||
|
||||
|
||||
def test_get_page_content():
|
||||
ret = parse_html.get_html_content(PAGE, "http://example.com")
|
||||
assert ret == CONTENT
|
||||
136
tests/metagpt/utils/test_pycst.py
Normal file
136
tests/metagpt/utils/test_pycst.py
Normal file
|
|
@ -0,0 +1,136 @@
|
|||
from metagpt.utils import pycst
|
||||
|
||||
code = '''
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
from typing import overload
|
||||
|
||||
@overload
|
||||
def add_numbers(a: int, b: int):
|
||||
...
|
||||
|
||||
@overload
|
||||
def add_numbers(a: float, b: float):
|
||||
...
|
||||
|
||||
def add_numbers(a: int, b: int):
|
||||
return a + b
|
||||
|
||||
|
||||
class Person:
|
||||
def __init__(self, name: str, age: int):
|
||||
self.name = name
|
||||
self.age = age
|
||||
|
||||
def greet(self):
|
||||
return f"Hello, my name is {self.name} and I am {self.age} years old."
|
||||
'''
|
||||
|
||||
documented_code = '''
|
||||
"""
|
||||
This is an example module containing a function and a class definition.
|
||||
"""
|
||||
|
||||
|
||||
def add_numbers(a: int, b: int):
|
||||
"""This function is used to add two numbers and return the result.
|
||||
|
||||
Parameters:
|
||||
a: The first integer.
|
||||
b: The second integer.
|
||||
|
||||
Returns:
|
||||
int: The sum of the two numbers.
|
||||
"""
|
||||
return a + b
|
||||
|
||||
class Person:
|
||||
"""This class represents a person's information, including name and age.
|
||||
|
||||
Attributes:
|
||||
name: The person's name.
|
||||
age: The person's age.
|
||||
"""
|
||||
|
||||
def __init__(self, name: str, age: int):
|
||||
"""Creates a new instance of the Person class.
|
||||
|
||||
Parameters:
|
||||
name: The person's name.
|
||||
age: The person's age.
|
||||
"""
|
||||
...
|
||||
|
||||
def greet(self):
|
||||
"""
|
||||
Returns a greeting message including the name and age.
|
||||
|
||||
Returns:
|
||||
str: The greeting message.
|
||||
"""
|
||||
...
|
||||
'''
|
||||
|
||||
|
||||
merged_code = '''
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
This is an example module containing a function and a class definition.
|
||||
"""
|
||||
|
||||
from typing import overload
|
||||
|
||||
@overload
|
||||
def add_numbers(a: int, b: int):
|
||||
...
|
||||
|
||||
@overload
|
||||
def add_numbers(a: float, b: float):
|
||||
...
|
||||
|
||||
def add_numbers(a: int, b: int):
|
||||
"""This function is used to add two numbers and return the result.
|
||||
|
||||
Parameters:
|
||||
a: The first integer.
|
||||
b: The second integer.
|
||||
|
||||
Returns:
|
||||
int: The sum of the two numbers.
|
||||
"""
|
||||
return a + b
|
||||
|
||||
|
||||
class Person:
|
||||
"""This class represents a person's information, including name and age.
|
||||
|
||||
Attributes:
|
||||
name: The person's name.
|
||||
age: The person's age.
|
||||
"""
|
||||
def __init__(self, name: str, age: int):
|
||||
"""Creates a new instance of the Person class.
|
||||
|
||||
Parameters:
|
||||
name: The person's name.
|
||||
age: The person's age.
|
||||
"""
|
||||
self.name = name
|
||||
self.age = age
|
||||
|
||||
def greet(self):
|
||||
"""
|
||||
Returns a greeting message including the name and age.
|
||||
|
||||
Returns:
|
||||
str: The greeting message.
|
||||
"""
|
||||
return f"Hello, my name is {self.name} and I am {self.age} years old."
|
||||
'''
|
||||
|
||||
|
||||
def test_merge_docstring():
|
||||
data = pycst.merge_docstring(code, documented_code)
|
||||
print(data)
|
||||
assert data == merged_code
|
||||
|
|
@ -3,94 +3,64 @@
|
|||
# @Desc : the unittest of serialize
|
||||
|
||||
from typing import List, Tuple
|
||||
import pytest
|
||||
|
||||
from pydantic import create_model
|
||||
|
||||
from metagpt.actions.action_output import ActionOutput
|
||||
from metagpt.actions import WritePRD
|
||||
from metagpt.actions.action_output import ActionOutput
|
||||
from metagpt.schema import Message
|
||||
from metagpt.utils.serialize import actionoutout_schema_to_mapping, serialize_message, deserialize_message
|
||||
from metagpt.utils.serialize import (
|
||||
actionoutout_schema_to_mapping,
|
||||
deserialize_message,
|
||||
serialize_message,
|
||||
)
|
||||
|
||||
|
||||
def test_actionoutout_schema_to_mapping():
|
||||
schema = {
|
||||
'title': 'test',
|
||||
'type': 'object',
|
||||
'properties': {
|
||||
'field': {
|
||||
'title': 'field',
|
||||
'type': 'string'
|
||||
}
|
||||
}
|
||||
}
|
||||
schema = {"title": "test", "type": "object", "properties": {"field": {"title": "field", "type": "string"}}}
|
||||
mapping = actionoutout_schema_to_mapping(schema)
|
||||
assert mapping['field'] == (str, ...)
|
||||
assert mapping["field"] == (str, ...)
|
||||
|
||||
schema = {
|
||||
'title': 'test',
|
||||
'type': 'object',
|
||||
'properties': {
|
||||
'field': {
|
||||
'title': 'field',
|
||||
'type': 'array',
|
||||
'items': {
|
||||
'type': 'string'
|
||||
}
|
||||
}
|
||||
}
|
||||
"title": "test",
|
||||
"type": "object",
|
||||
"properties": {"field": {"title": "field", "type": "array", "items": {"type": "string"}}},
|
||||
}
|
||||
mapping = actionoutout_schema_to_mapping(schema)
|
||||
assert mapping['field'] == (List[str], ...)
|
||||
assert mapping["field"] == (List[str], ...)
|
||||
|
||||
schema = {
|
||||
'title': 'test',
|
||||
'type': 'object',
|
||||
'properties': {
|
||||
'field': {
|
||||
'title': 'field',
|
||||
'type': 'array',
|
||||
'items': {
|
||||
'type': 'array',
|
||||
'minItems': 2,
|
||||
'maxItems': 2,
|
||||
'items': [
|
||||
{
|
||||
'type': 'string'
|
||||
},
|
||||
{
|
||||
'type': 'string'
|
||||
}
|
||||
]
|
||||
}
|
||||
"title": "test",
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"field": {
|
||||
"title": "field",
|
||||
"type": "array",
|
||||
"items": {
|
||||
"type": "array",
|
||||
"minItems": 2,
|
||||
"maxItems": 2,
|
||||
"items": [{"type": "string"}, {"type": "string"}],
|
||||
},
|
||||
}
|
||||
}
|
||||
},
|
||||
}
|
||||
mapping = actionoutout_schema_to_mapping(schema)
|
||||
assert mapping['field'] == (List[Tuple[str, str]], ...)
|
||||
assert mapping["field"] == (List[Tuple[str, str]], ...)
|
||||
|
||||
assert True, True
|
||||
|
||||
|
||||
def test_serialize_and_deserialize_message():
|
||||
out_mapping = {
|
||||
'field1': (str, ...),
|
||||
'field2': (List[str], ...)
|
||||
}
|
||||
out_data = {
|
||||
'field1': 'field1 value',
|
||||
'field2': ['field2 value1', 'field2 value2']
|
||||
}
|
||||
ic_obj = ActionOutput.create_model_class('prd', out_mapping)
|
||||
out_mapping = {"field1": (str, ...), "field2": (List[str], ...)}
|
||||
out_data = {"field1": "field1 value", "field2": ["field2 value1", "field2 value2"]}
|
||||
ic_obj = ActionOutput.create_model_class("prd", out_mapping)
|
||||
|
||||
message = Message(content='prd demand',
|
||||
instruct_content=ic_obj(**out_data),
|
||||
role='user',
|
||||
cause_by=WritePRD) # WritePRD as test action
|
||||
message = Message(
|
||||
content="prd demand", instruct_content=ic_obj(**out_data), role="user", cause_by=WritePRD
|
||||
) # WritePRD as test action
|
||||
|
||||
message_ser = serialize_message(message)
|
||||
|
||||
new_message = deserialize_message(message_ser)
|
||||
assert new_message.content == message.content
|
||||
assert new_message.cause_by == message.cause_by
|
||||
assert new_message.instruct_content.field1 == out_data['field1']
|
||||
assert new_message.instruct_content.field1 == out_data["field1"]
|
||||
|
|
|
|||
77
tests/metagpt/utils/test_text.py
Normal file
77
tests/metagpt/utils/test_text.py
Normal file
|
|
@ -0,0 +1,77 @@
|
|||
import pytest
|
||||
|
||||
from metagpt.utils.text import (
|
||||
decode_unicode_escape,
|
||||
generate_prompt_chunk,
|
||||
reduce_message_length,
|
||||
split_paragraph,
|
||||
)
|
||||
|
||||
|
||||
def _msgs():
|
||||
length = 20
|
||||
while length:
|
||||
yield "Hello," * 1000 * length
|
||||
length -= 1
|
||||
|
||||
|
||||
def _paragraphs(n):
|
||||
return " ".join("Hello World." for _ in range(n))
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"msgs, model_name, system_text, reserved, expected",
|
||||
[
|
||||
(_msgs(), "gpt-3.5-turbo", "System", 1500, 1),
|
||||
(_msgs(), "gpt-3.5-turbo-16k", "System", 3000, 6),
|
||||
(_msgs(), "gpt-3.5-turbo-16k", "Hello," * 1000, 3000, 5),
|
||||
(_msgs(), "gpt-4", "System", 2000, 3),
|
||||
(_msgs(), "gpt-4", "Hello," * 1000, 2000, 2),
|
||||
(_msgs(), "gpt-4-32k", "System", 4000, 14),
|
||||
(_msgs(), "gpt-4-32k", "Hello," * 2000, 4000, 12),
|
||||
]
|
||||
)
|
||||
def test_reduce_message_length(msgs, model_name, system_text, reserved, expected):
|
||||
assert len(reduce_message_length(msgs, model_name, system_text, reserved)) / (len("Hello,")) / 1000 == expected
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"text, prompt_template, model_name, system_text, reserved, expected",
|
||||
[
|
||||
(" ".join("Hello World." for _ in range(1000)), "Prompt: {}", "gpt-3.5-turbo", "System", 1500, 2),
|
||||
(" ".join("Hello World." for _ in range(1000)), "Prompt: {}", "gpt-3.5-turbo-16k", "System", 3000, 1),
|
||||
(" ".join("Hello World." for _ in range(4000)), "Prompt: {}", "gpt-4", "System", 2000, 2),
|
||||
(" ".join("Hello World." for _ in range(8000)), "Prompt: {}", "gpt-4-32k", "System", 4000, 1),
|
||||
]
|
||||
)
|
||||
def test_generate_prompt_chunk(text, prompt_template, model_name, system_text, reserved, expected):
|
||||
ret = list(generate_prompt_chunk(text, prompt_template, model_name, system_text, reserved))
|
||||
assert len(ret) == expected
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"paragraph, sep, count, expected",
|
||||
[
|
||||
(_paragraphs(10), ".", 2, [_paragraphs(5), f" {_paragraphs(5)}"]),
|
||||
(_paragraphs(10), ".", 3, [_paragraphs(4), f" {_paragraphs(3)}", f" {_paragraphs(3)}"]),
|
||||
(f"{_paragraphs(5)}\n{_paragraphs(3)}", "\n.", 2, [f"{_paragraphs(5)}\n", _paragraphs(3)]),
|
||||
("......", ".", 2, ["...", "..."]),
|
||||
("......", ".", 3, ["..", "..", ".."]),
|
||||
(".......", ".", 2, ["....", "..."]),
|
||||
]
|
||||
)
|
||||
def test_split_paragraph(paragraph, sep, count, expected):
|
||||
ret = split_paragraph(paragraph, sep, count)
|
||||
assert ret == expected
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"text, expected",
|
||||
[
|
||||
("Hello\\nWorld", "Hello\nWorld"),
|
||||
("Hello\\tWorld", "Hello\tWorld"),
|
||||
("Hello\\u0020World", "Hello World"),
|
||||
]
|
||||
)
|
||||
def test_decode_unicode_escape(text, expected):
|
||||
assert decode_unicode_escape(text) == expected
|
||||
Loading…
Add table
Add a link
Reference in a new issue